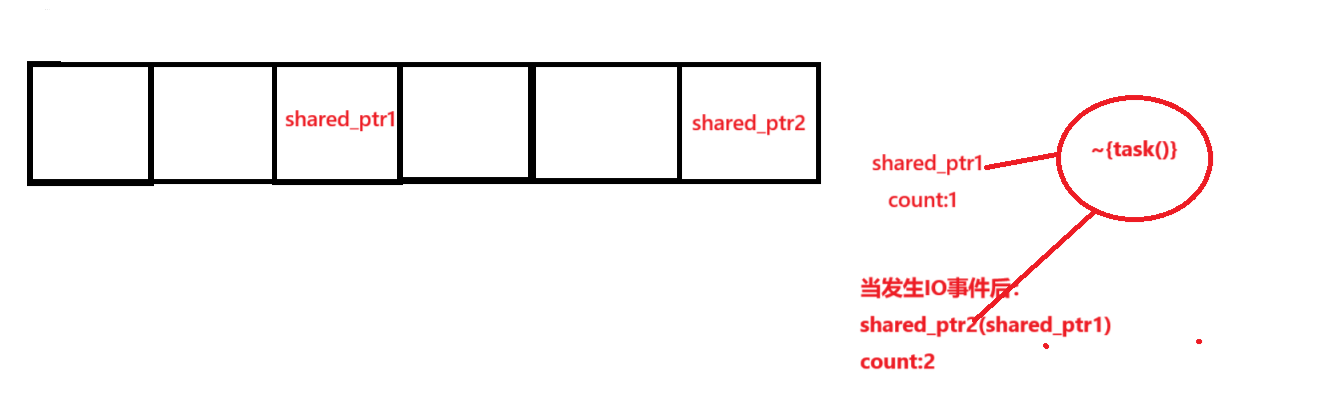
摘要
本文提出了一种整体方法,利用逆强化学习(IRL)从系统级审计日志中对攻击者偏好进行建模。对抗建模是网络安全中的一项重要能力,它使防御者能够描述潜在攻击者的行为特征,从而能够归因于已知的网络对抗团体。现有方法依赖于记录不断发展的攻击者工具和技术集合,以跟踪已知的威胁行为者。尽管攻击不断演变,但攻击者的行为偏好是内在的且不易变化。我们的方法从关于网络对抗者的工具和技术的取证数据中学习其行为偏好。我们将攻击者建模为具有未知行为偏好且位于计算机主机中的专家决策代理。我们利用审计日志的攻击溯源图来推导出攻击的状态-动作轨迹。我们在包含真实攻击数据的开放审计日志数据集上测试了我们的方法。我们的结果首次证明,底层取证数据可以自动揭示对抗者的主观偏好,这为建模和记录网络对抗者提供了一个额外的维度。攻击者的偏好往往是不变的,尽管他们使用的工具不同,并且表明了攻击者固有的倾向。因此,这些推断出的偏好可能作为攻击者的独特行为签名,并提高威胁归因的准确性。
1 引言
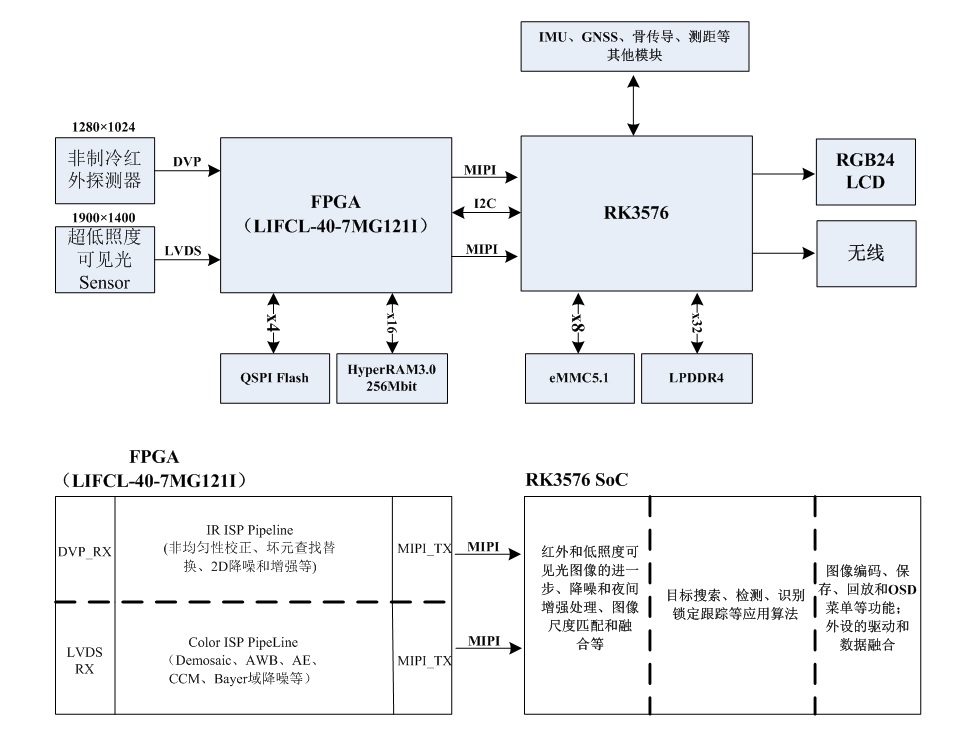
复杂的网络攻击者越来越多地将大型组织和关键基础设施作为攻击目标。这些威胁行为者,也被称为高级持续性威胁(APT),具有隐蔽性、足智多谋,并且经常采用新颖的利用技术来实现其目标。记录、分析和建模此类威胁行为者对于改进针对他们的防御至关重要。最近,审计日志数据的溯源图已经成为一种流行的计算表示,用于分析APT的攻击[King and Chen, 2003; Hossain et al., 2017]。溯源图是内核级对象(如进程、线程和文件)之间交互的因果表示,它通过连接相互作用的对象来促进分析。最近的研究工作采用了基于人工智能的技术来自动检测APT [Wang et al., 2022; Milajerdi et al., 2019b]。
关于网络威胁的战术信息对于检测和及时响应至关重要。然而,拥有这种特定情报的优势是短暂的,因为攻击者的工具和技术不断发展。对攻击者进行建模的方法缺乏对攻击者行为特征和偏好的更广泛的洞察。在战略层面,过去的工作采用了博弈论框架[Ferguson-Walter et al., 2019; Schlenker et al., 2018]和决策论框架[Sarraute et al., 2012; Shinde and Doshi, 2024]来对网络攻击者进行建模。然而,大多数用于网络安全的意图识别方法只专注于最终目标识别。这些努力并没有针对攻击者行为隐含揭示的更广泛的偏好。它们还依赖于一些假设,例如攻击者的意图被限制在一组先前已知的候选奖励函数中[Mirsky et al., 2019; Shinde et al., 2021]。
本文提出了一种新颖的端到端方法,使用逆强化学习 (IRL) 从原始取证数据中建模对手偏好 [Arora and Doshi, 2021]。我们使用低级审计日志,因为它们通常是漏洞攻击后场景中唯一与攻击相关的数据源,并且通常用于网络安全。我们的方法利用系统级审计日志的溯源图表示。我们将主机中的攻击者建模为马尔可夫决策过程 (MDP) 中的专家决策代理。然后,我们利用子图同构将溯源图的部分映射到基于流行的 MITRE ATT&CK 矩阵的攻击者行为。ATT&CK 矩阵是由各种攻击者使用的技术和策略的综合目录 [Strom et al., 2018]。通过这样做,我们弥合了原始安全日志数据与应用于网络安全的决策模型中普遍存在的符号动作表示之间的差距。这些映射使我们能够生成观察到的攻击者行为的轨迹。随后,我们使用 IRL 从这些审计日志中推断攻击者的行为偏好。这是 IRL 在对手建模中的一种新颖应用,是现代网络防御中的一个相关目标。我们通过行为特征(如可发现性、持续时间、可归因性、复杂性和影响)来建模对手的偏好。这些信息丰富的特征在高于其工具和技术的层面上包含了攻击者更广泛的偏好,并充当了对手的独特签名。
随后,我们利用逆强化学习(IRL)从轨迹中计算先前所述偏好特征的权重。我们在多个开放数据集[Keromytis, 2018]上测试此流程,这些数据集包含针对不同目标主机的真实网络攻击。通常无法获得关于攻击者偏好的真实数据!为了解决这个难题,我们使用了两种不同的逆强化学习技术,并分析了方法间的一致性。我们的结果表明,这种新方法在从低级日志数据中提取关于攻击者行为的更广泛且可能的恒定见解方面的优势。这种使用逆强化学习(IRL)识别攻击者偏好的自动化方法,能够在不对攻击者目标进行假设的情况下,研究网络攻击者的行为方面。