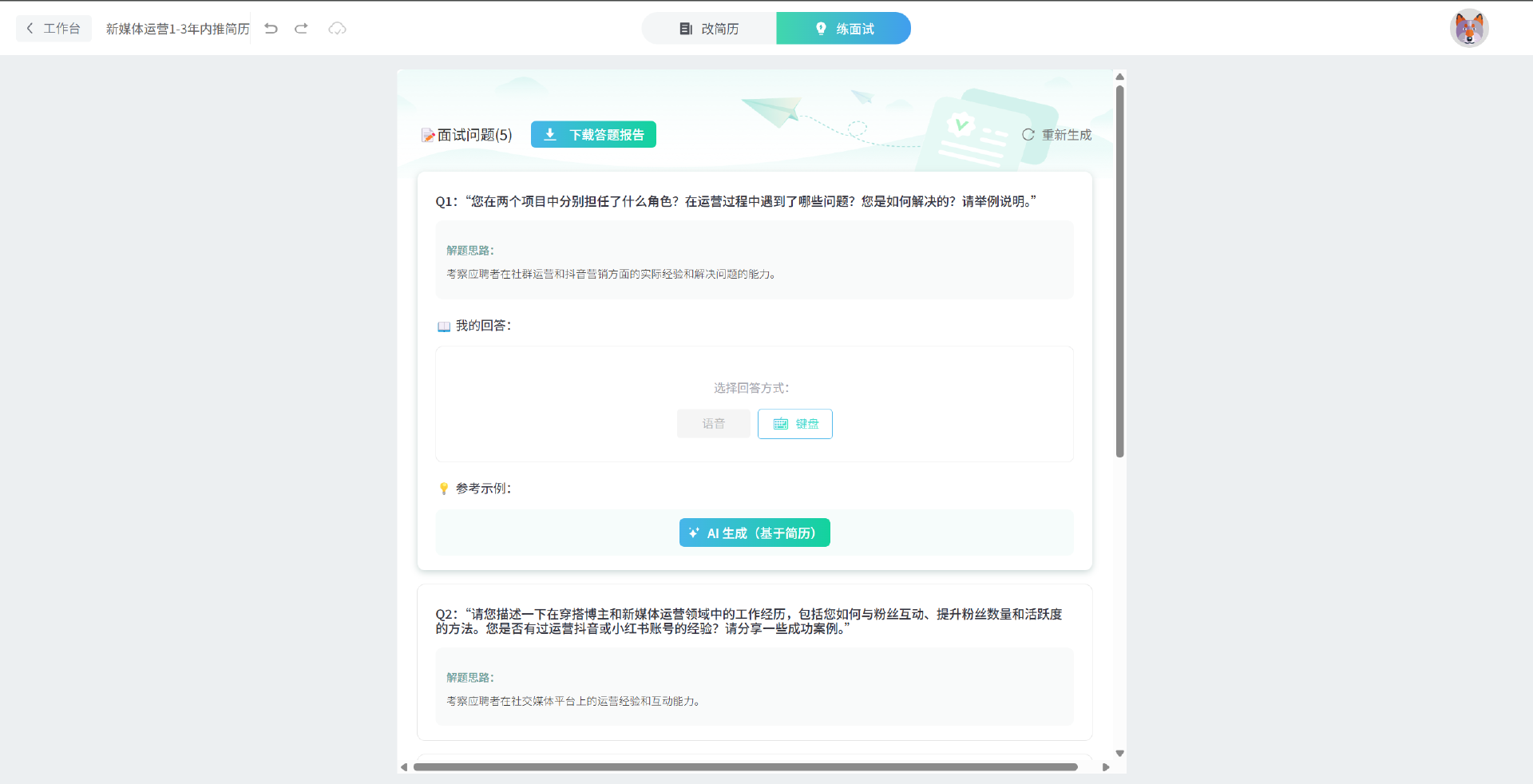
目录
一、算法核心特点
二、使用场景
三、代码示例(以 Python 的 scikit - learn 库为例)
四、与其他分类算法对比
SVC 即 Support Vector Classification,是支持向量机(SVM)在分类任务中的具体实现。在你正在阅读的关于支持向量机算法的介绍中,已经涵盖了 SVC 算法的核心原理,这里将从 SVC 算法的特点、使用场景、代码示例等方面进一步展开。
一、算法核心特点
-
基于 SVM 原理:SVC 完全遵循支持向量机寻找最优分类超平面的理念。在面对线性可分数据时,它致力于找到一个超平面,不仅能将不同类别的数据点分开,还能使该超平面与最近的数据点之间的间隔最大化。对于线性不可分数据,则引入松弛变量和惩罚参数(C),在最大化间隔与允许一定程度误分类之间进行权衡。例如,在一个简单的二维数据分类场景中,两类数据点呈现出部分重叠的情况,SVC 会根据(C)值的设定,在尽量扩大间隔的同时,对落入错误一侧的数据点进行适当 “容忍”。
-
灵活运用核函数:和 SVM 一样,SVC 借助核函数来处理非线性分类问题。通过将低维原始特征空间映射到高维空间,原本线性不可分的数据在高维空间中可能变得线性可分。不同的核函数如线性核函数、多项式核函数、高斯核函数、Sigmoid 核函数等,为处理各种复杂的数据分布提供了多样的选择。例如在图像分类任务中,数据往往具有高度复杂的特征关系,使用高斯核函数的 SVC 能够有效将图像特征映射到合适的高维空间,实现精准分类。
二、使用场景
-
小样本分类:由于 SVC 在小样本情况下也能通过最大化间隔找到较为鲁棒的分类超平面,具备良好的泛化能力,所以在小样本分类场景中表现出色。比如在珍稀物种的识别研究中,由于可获取的样本数量有限,SVC 可以基于这些少量样本构建有效的分类模型,准确识别物种类别。
-
高维数据分类:在处理高维数据时,SVC 利用核函数能够将数据映射到高维空间而无需担心维度灾难问题,使其在高维数据分类领域得到广泛应用。像在基因数据分析中,基因数据维度极高,SVC 能够对大量的基因特征进行分析,区分不同的基因表达模式类别。
-
复杂边界分类:当数据的分类边界呈现复杂的非线性形状时,SVC 通过合适的核函数可以很好地拟合这种复杂边界。例如在手写字符识别中,不同手写风格的字符数据边界复杂,SVC 能够通过选择恰当的核函数,精确划分不同字符类别。
三、代码示例(以 Python 的 scikit - learn 库为例)
from sklearn import svm
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 生成模拟分类数据集
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=0, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建SVC分类器对象,使用默认参数(线性核函数)
clf = svm.SVC()
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("模型准确率:", accuracy)在上述代码中,首先使用make_classification函数生成了一个模拟的分类数据集。接着将数据集划分为训练集和测试集,然后创建了一个默认使用线性核函数的 SVC 分类器对象。通过调用fit方法对训练集进行训练,再使用训练好的模型对测试集进行预测,最后计算并输出模型在测试集上的准确率。如果需要使用其他核函数,只需在创建SVC对象时指定kernel参数,例如clf = svm.SVC(kernel='rbf')即可使用高斯核函数。
四、与其他分类算法对比
-
与决策树对比:决策树算法的决策边界是基于特征的阈值划分,呈现出矩形区域,对于复杂的非线性边界拟合能力有限,且容易出现过拟合。而 SVC 借助核函数能够构建更复杂、平滑的决策边界,在处理非线性问题上更具优势。不过决策树算法计算速度快,对数据的解释性非常直观,而 SVC 计算复杂度较高,可解释性相对较弱。
-
与 K 近邻对比:K 近邻算法属于基于实例的学习算法,在预测时需要计算待预测样本与所有训练样本的距离,计算量较大,且对 K 值的选择非常敏感。SVC 在训练后得到一个固定的决策边界,预测时计算量小,并且在小样本、高维数据场景下表现优于 K 近邻算法。但 K 近邻算法不需要对数据进行复杂的训练过程,对于数据分布变化的适应性较强。


![[JVM] JVM内存调优](https://i-blog.csdnimg.cn/direct/bc16459a966d410c8ffaf9d52c0c9bd8.png)