目录
引言
示例程序分析
代码结构剖析
导入模块解读
智能体配置详情
提示词模板说明
主程序功能解析
异步聊天功能实现
检索信息展示
技术要点总结
ollama 本地部署nomic-embed-text
运行测试
结语
引言
这段时间一直在学习CangjieMagic。前几天完成了在CangjieMagic智能体框架中集成华为云的DeepSeek服务-CSDN博客,今天研究了一下本地部署。CangjieMagic支持两种本地部署:Ollma和Llama.cpp。CangjieMagic提供了一个有趣的例子markdown_qa,它根据本项目的文档实现问答助手。今天就来测试一下它。
示例程序分析
例子的链接在:项目目录预览 - CangjieMagic:基于仓颉编程语言构建的 LLM Agent 开发框架,其主要特点包括:Agent DSL、支持 MCP 协议,支持模块化调用,支持任务智能规划。 - GitCode
这段代码是一个使用 Magic DSL 框架开发的智能问答机器人程序,它能借助 RAG 技术从指定文档里获取信息来回答问题。下面是对代码的详细解释:
代码结构剖析
package magic.examples.markdown_qa
- 此程序属于
magic.examples.markdown_qa包,这表明它是 Magic 框架示例的一部分。
导入模块解读
import magic.dsl.*
import magic.prelude.*
import magic.config.Config
import magic.model.ModelManager
import log.LogLevel
- 导入了 Magic DSL 框架的核心功能,像 DSL 注解、基础函数、配置类以及模型管理工具等都包含在内。
- 同时还导入了日志级别配置模块。
智能体配置详情
@agent[
model: "deepseek:deepseek-chat",
executor: "naive",
rag: {
source: "./docs/tutorial.md",
mode: "static"
}
]
class QABot { ... }
- 这是一个基于 DeepSeek-chat 模型的智能体,它采用了简单的执行器。
- 配置了 RAG(检索增强生成)功能,会从
./docs/tutorial.md这个 Markdown 文档中获取知识,并且使用静态模式,这意味着文档内容会被预加载。
提示词模板说明
@prompt[pattern: ERA] (
expectation: "代码块被标签 ```cangjie 和 ```包裹",
role: "简单问答助手",
action: "搜索文档获取知识并回答问题"
)
- 运用 ERA(期望 - 角色 - 行动)模式构建提示词模板。
- 期望生成的代码块使用特定的 Cangjie 标记。
- 该智能体的角色是作为简单问答助手,其主要行动是搜索文档并生成回答。
主程序功能解析
main () {
Config.logLevel = LogLevel.INFO
Config.defaultEmbeddingModel = ModelManager.createEmbeddingModel("ollama:nomic-embed-text")
- 把日志级别设定为 INFO,这样可以显示执行过程中的信息。
- 配置了嵌入模型,用于生成文本的向量表示,这里使用的是 Ollama 平台的 nomic-embed-text 模型。
异步聊天功能实现
let bot = QABot()
let aresp = bot.asyncChat("Agent RAG 怎么编写")
for (chunk in aresp) {
print(chunk)
}
- 创建了 QABot 实例,并异步询问 "Agent RAG 怎么编写" 这个问题。
- 采用流式输出的方式打印回答内容。
检索信息展示
if (let Some(info) <- aresp.execInfo) {
for (info in info.retrievalInfo) {
for (doc in info.retrieval.sources) {
println(doc.metadata)
}
}
}
}
- 展示了回答所依据的文档元数据,这体现了 RAG 的可解释性。
- 能看到哪些文档片段被用作了回答的参考。
技术要点总结
- RAG 技术:该程序将检索和大语言模型相结合,利用本地文档来增强回答的准确性。
- 异步处理:采用异步聊天接口
asyncChat,支持流式响应,提升了用户体验。 - 模块化设计:
- 智能体配置与业务逻辑是分离的。
- 提示词工程采用了标准化的模板。
- 模型生态集成:
- 支持 DeepSeek 等 LLM 模型。
- 与 Ollama 平台的嵌入模型进行集成。
- 知识来源:以静态 Markdown 文档作为知识来源,适合特定领域的问答场景。
这个程序展示了如何使用 Magic DSL 框架开发一个基于文档的智能问答系统,它具备可配置、可扩展以及可解释的特点。
ollama 本地部署nomic-embed-text
首先下载安装Ollma:
developer@developer:~/IDEProjects$ curl https://ollama.com/install.sh | sh
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 5503 0 5503 0 0 7219 0 --:--:-- --:--:-- --:--:-- 7212>>> Cleaning up old version at /usr/local/lib/ollama
>>> Installing ollama to /usr/local
100 13281 0 13281 0 0 16854 0 --:--:-- --:--:-- --:--:-- 16854
>>> Downloading Linux amd64 bundle
######################################################################## 100.0%
>>> Creating ollama user...
>>> Adding ollama user to render group...
>>> Adding ollama user to video group...
>>> Adding current user to ollama group...
>>> Creating ollama systemd service...
>>> Enabling and starting ollama service...
Created symlink /etc/systemd/system/default.target.wants/ollama.service → /etc/systemd/system/ollama.service.
>>> The Ollama API is now available at 127.0.0.1:11434.
>>> Install complete. Run "ollama" from the command line.
WARNING: No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.
developer@developer:~/IDEProjects$
安装成功后它会自动启动服务器。
这个实例需要 Nomic-embed-text模型。Nomic-embed-text 是一个基于 Sentence Transformers 库的句子嵌入模型,专门用于特征提取和句子相似度计算。该模型在多个任务上表现出色,特别是在分类、检索和聚类任务中,能够生成高质量的句子嵌入,这些嵌入在语义上非常接近,从而在相似度计算和分类任务中表现优异。
执行下面的语句下载该模型:
ollama pull nomic-embed-text运行测试
然后就可以修改程序适配华为版的DeepSeek,具体做法参考:在CangjieMagic智能体框架中集成华为云的DeepSeek服务-CSDN博客。
这个程序实际上先用本地的Nomic-embed-text模型提取文档中有用的部分,然后把它和用户问题一起发给DeepSeek。下面是简单的原理示意。
"messages": [
{
"role": "system",
"content": "## Expectation\n代码块被标签 ```cangjie 和 ```包裹\n## Role\n简单问答助手\n## Action\n搜索文档获取知识并回答问题\n\n\n# Retrieved Content\n除了系统提示词,外部知识也可以增强 Agent 的解决问题的能力。 Agent 能够从各类知识源中提取必要和有用的信息。\n目前,Agent 的 `rag` 属性表明外部知识的数据源,它接受多个数据源配置,每个数据源包含如下的键值对:\n| 属性 | 属性值 | 说明 |\n|---|---|---|\n| `source` | `String \\| Expr` | 数据源 |\n| `mode` | `String` | 使用模式,支持 `\"static\"` 和 `\"dynamic\"` 两种;默认为 `\"static\"` |\n| `description` | `String` | 可进一步描述数据源,帮助 Agent 更加精准地获取数据 |\n属性 `source` 表明数据的实际来源,支持两种类型:\n- 合法路径指向*预置的文件类型*\n - 当前支持的文件类型包括 markdown, Sqlite 数据库\n- 类型为 `Retriever` 的表达式\n```cangjie\n@agent[\n rag: { source: \"path/to/some.db\" }\n]\nclass Foo { }\n```\n⚠️注意:使用 Sqlite 数据库的功能需要配置 `cfg.toml` 中 `sqlite = \"enable\"`,且由于数据库使用了 Sqlite,所以需要安装三方依赖。详见 [third_party_libs.md](./third_party_libs.md)\n[使用示例](../src/examples/mini_rag/main.cj)\n除了通过 `@agent` 定义 Agent 之外,当前框架内置如下的几种 Agent。\n目前,我们使用宏 `@agent` 修饰 `class` 类型来定义一个 Agent 类型。\n```cangjie\n@agent class Foo { }\n```\n宏 `@agent` 支持如下属性。具体属性可参考相应章节内容\n| 属性名 | 值类型 | 说明 |\n|-------|-------|-------|\n| `description` | `String` | Agent 的功能描述;默认未设置时,将由 LLM 从提示词中自动总结出 |\n| `model` | `String` | 配置使用到的 LLM 模型服务;默认使用 gpt-4o |\n| `tools` | `Array` | 配置能够使用的外部工具 |\n| `mcp` | `Array` | 配置接入的 MCP 服务器 |\n| `rag` | `Map` | 配置外部的知识源 |\n| `memory` | `Bool` | 是否使用记忆,即保存 Agent 的多次问答记录(目前记忆仅支持 in-memory 非持久化数据);默认为 `false` |\n| `executor` | `String` | 规划模式;默认为 `react` |\n| `temperature` | `Float` | Agent 使用 LLM 时的 temperature 值;默认为 `0.5` |\n| `enableToolFilter` | `Bool` | 启用工具过滤功能,Agent 在执行前会自动根据输入问题选择合适的工具集合;默认 `false` |\n| `dump` | `Bool` | 调试代码用,是否打印 Agent 变换后的 AST;默认为 `false` |\n工具可以理解为 Agent 执行过程中能够执行的代码。当前 Agent 工具有两个来源:\n- 使用 DSL 直接编写的工具函数\n- 由 MCP 服务器提供的工具(MCP 服务器可视为*一组工具的集合*)。\n---end of Retrieved Content---\n\n\n\n\n"
},
{
"role": "user",
"content": "Agent RAG 怎么编写"
}
],
DeepSeek收到我们提供的数据和用户的问题,就会生成解答。
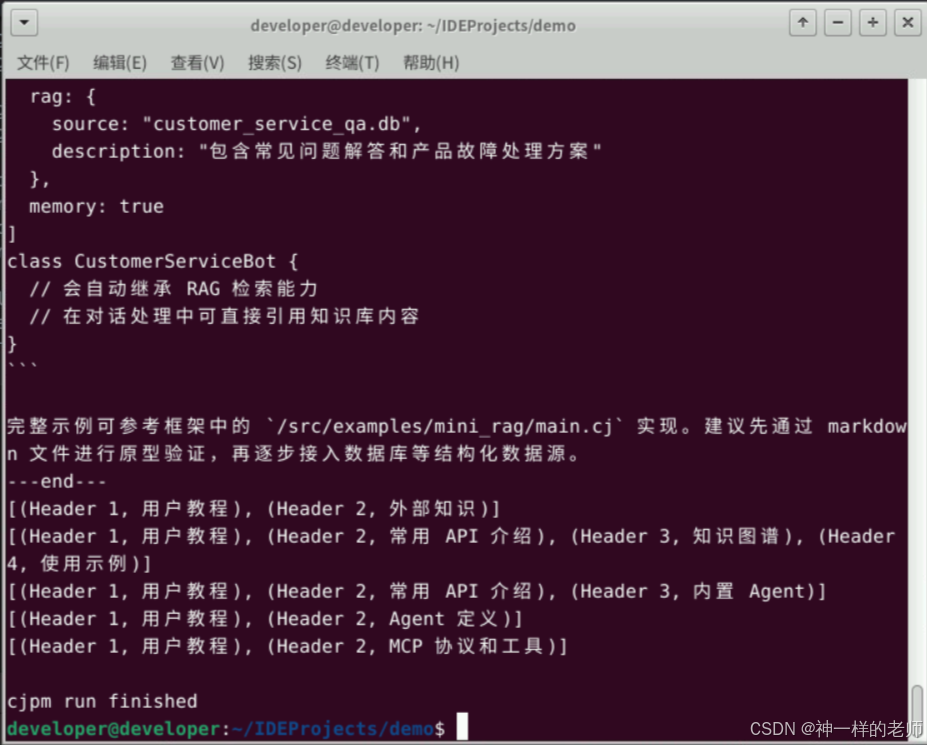
下面是日志中解答的部分。
| `temperature` | `Float` | Agent 使用 LLM 时的 temperature 值;默认为 `0.5` |
| `enableToolFilter` | `Bool` | 启用工具过滤功能,Agent 在执行前会自动根据输入问题选择合适的工具集合;默认 `false` |
| `dump` | `Bool` | 调试代码用,是否打印 Agent 变换后的 AST;默认为 `false` |
工具可以理解为 Agent 执行过程中能够执行的代码。当前 Agent 工具有两个来源:
- 使用 DSL 直接编写的工具函数
- 由 MCP 服务器提供的工具(MCP 服务器可视为*一组工具的集合*)。
---end of Retrieved Content---
2025/05/30 17:33:17.562631 INFO logger QABot: Chat Message[ user ]: Agent RAG 怎么编写
嗯,用户问的是如何编写Agent的RAG部分。我需要先回忆一下之前学过的相关知识。根据检索到的内容,RAG属性在Agent中用于配置外部知识源。首先,RAG接受多个数据源配置,每个数据源需要指定source、mode和description等属性。
source可以是文件路径或者Retriever表达式。比如,用户可能想连接一个数据库或者Markdown文件。例如,使用source: "path/to/some.db"来指定SQLite数据库。但要注意,使用SQLite需要配置cfg.toml中的sqlite选项为enable,并且安装相关依赖。
mode有static和dynamic两种模式,默认是static。static可能是指数据源在初始化时加载,而dynamic可能在运行时动态获取。需要确认用户是否需要实时更新的数据,从而选择合适的模式。
description用来进一步描述数据源,帮助Agent更准确地获取信息。这部分可能需要用户提供详细的描述,比如数据内容或结构。
然后,用户需要在@agent宏中设置rag属性。例如,@agent[rag: { source: "data.md" }]来引入Markdown文件作为知识源。如果使用多个数据源,可能需要用数组形式,但检索到的内容里提到rag是Map类型,可能需要确认是否支持多个配置。
另外,用户可能需要知道如何结合工具和RAG。比如,在工具函数中调用检索到的内容,或者在回答问题时引用这些数据。示例中的代码片段展示了如何将数据库作为RAG源,用户可能需要参考示例代码来编写自己的Agent。
还要注意,使用SQLite数据库需要安装第三方库,用户可能需要查看third_party_libs.md文档。此外,示例中的main.cj文件可能提供了具体的实现方法,建议用户参考。
总结来说,编写Agent的RAG需要配置rag属性,指定数据源路径或表达式,选择合适的模式,添加描述,并确保依赖项正确安装。用户可能需要根据具体的数据类型和需求调整配置,同时参考提供的示例代码进行实现。
在 Cangjie DSL 中编写 Agent 的 RAG 功能需要以下步骤:
1. **基本结构定义**
使用 `@agent` 宏修饰 class 来定义 Agent:
```cangjie
@agent[
rag: {
source: "path/to/your_data.md", // 数据源路径
mode: "static", // 使用模式
description: "产品知识库" // 数据源描述
}
]
class MyAssistant {
// Agent 的具体实现...
}
```
2. **关键参数配置**:
- `source`:支持两种形式
```cangjie
// 文件路径形式(支持 markdown/sqlite)
source: "data/product_manual.db"
// Retriever 表达式形式
source: Retriever.new("https://api.example.com/knowledge-base")
```
- `mode` 模式选择:
```cangjie
mode: "static" // 静态加载(默认)
mode: "dynamic" // 动态实时检索
```
3. **多数据源配置**(使用数组):
```cangjie
@agent[
rag: [
{
source: "internal_knowledge.db",
description: "公司内部技术文档"
},
{
source: Retriever.new(API_ENDPOINT),
mode: "dynamic",
description: "实时市场数据接口"
}
]
]
```
4. **SQLite 数据库注意事项**:
- 在 `cfg.toml` 中启用:
```toml
sqlite = "enable"
```
- 需要安装依赖:
```bash
pip install sqlalchemy datasets
```
5. **典型使用场景示例**:
```cangjie
// 客户服务 Agent 示例
@agent[
rag: {
source: "customer_service_qa.db",
description: "包含常见问题解答和产品故障处理方案"
},
memory: true
]
class CustomerServiceBot {
// 会自动继承 RAG 检索能力
// 在对话处理中可直接引用知识库内容
}
```
完整示例可参考框架中的 `/src/examples/mini_rag/main.cj` 实现。建议先通过 markdown 文件进行原型验证,再逐步接入数据库等结构化数据源。
---end---
[(Header 1, 用户教程), (Header 2, 外部知识)]
[(Header 1, 用户教程), (Header 2, 常用 API 介绍), (Header 3, 知识图谱), (Header 4, 使用示例)]
[(Header 1, 用户教程), (Header 2, 常用 API 介绍), (Header 3, 内置 Agent)]
[(Header 1, 用户教程), (Header 2, Agent 定义)]
[(Header 1, 用户教程), (Header 2, MCP 协议和工具)]
cjpm run finished
结语
RAG模型的优势在于可实现即时的知识更新,从而提供更高效和精准的信息服务。 CangjieMagic在这方面做得很不错,值得进一步挖掘。