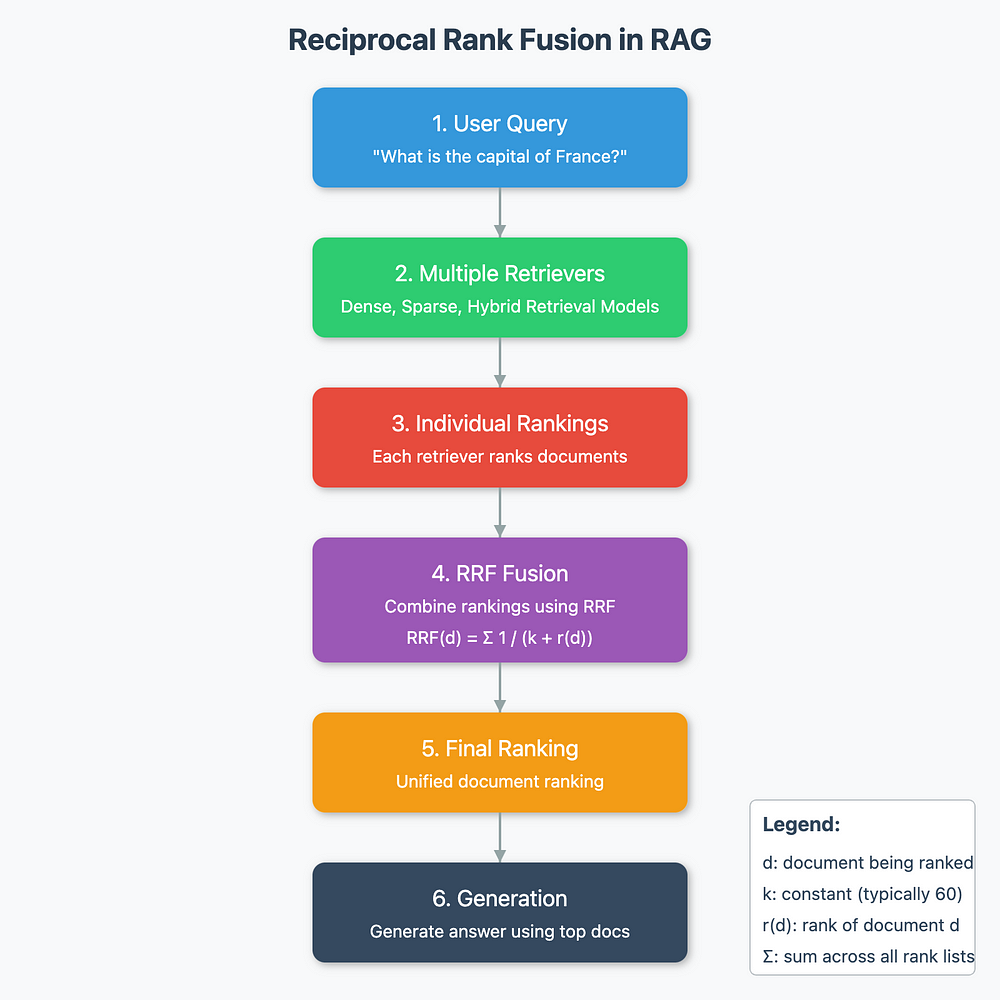
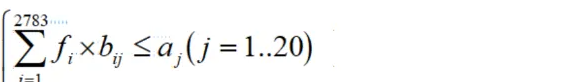一、数据爬取模块(Python示例)
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Accept-Language': 'en-US'
}
def scrape_amazon_reviews(product_id, max_pages=5):
base_url = f"https://www.amazon.com/product-reviews/{product_id}"
reviews = []
for page in range(1, max_pages + 1):
url = f"{base_url}/?pageNumber={page}"
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'html.parser')
for review in soup.find_all('div', {'data-hook': 'review'}):
review_data = {
'rating': float(review.find('i', {'data-hook': 'review-star-rating'}).text.split()[0]),
'title': review.find('a', {'data-hook': 'review-title'}).text.strip(),
'body': review.find('span', {'data-hook': 'review-body'}).text.strip(),
'date': review.find('span', {'data-hook': 'review-date'}).text
}
reviews.append(review_data)
time.sleep(2) # 降低请求频率
return pd.DataFrame(reviews)关键点说明:
-
需替换
product_id为目标商品ASIN码 -
通过
time.sleep()规避反爬机制 -
使用
data-hook属性精准定位评论元素
二、情感分析模块(NLP示例)
from textblob import TextBlob
def analyze_sentiment(review_text):
analysis = TextBlob(review_text)
return {
'polarity': analysis.sentiment.polarity, # 情感极性(-1到1)
'subjectivity': analysis.sentiment.subjectivity # 主观性(0到1)
}输出应用:
-
极性>0.3判定为积极评论
-
极性<-0.3判定为消极评论
三、数据可视化(Matplotlib示例)
import matplotlib.pyplot as plt
def plot_rating_distribution(df):
plt.figure(figsize=(8, 4))
df['rating'].value_counts().sort_index().plot(kind='bar', color='#FF9900')
plt.title('Amazon Review Rating Distribution')
plt.xlabel('Star Rating')
plt.ylabel('Count')
plt.xticks(rotation=0)
plt.show()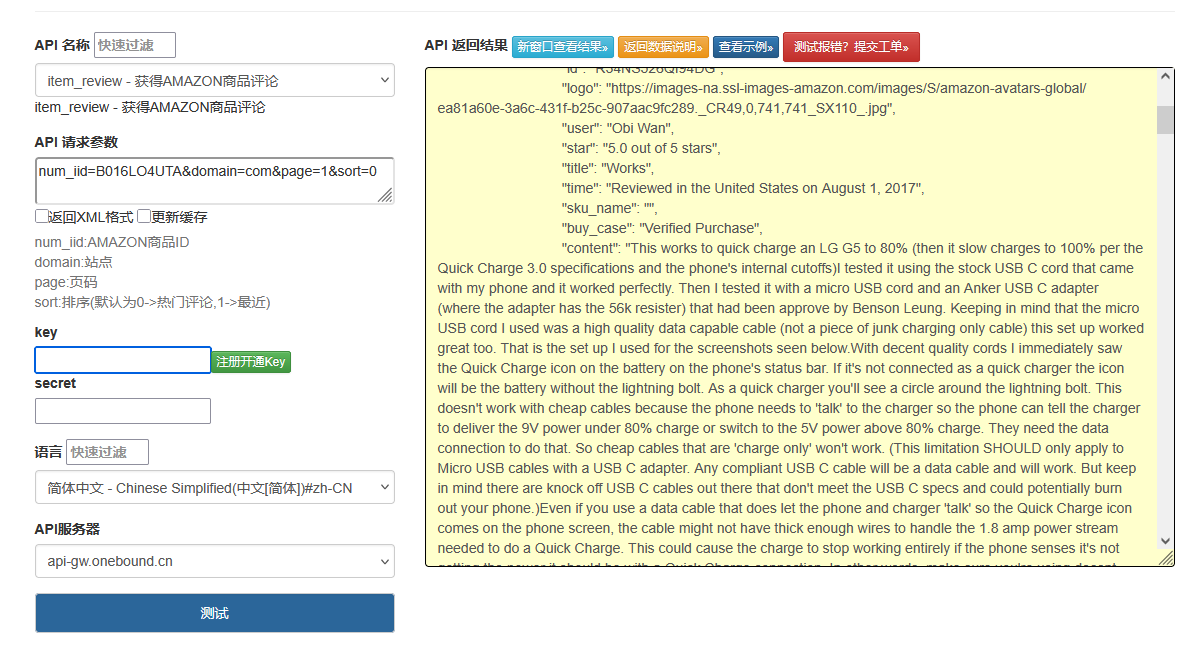
四、合规性注意事项
-
遵守亚马逊Robots协议(检查
/robots.txt) -
单IP请求频率建议≤2次/秒
-
商业用途需申请官方API(MWS或SP-API)