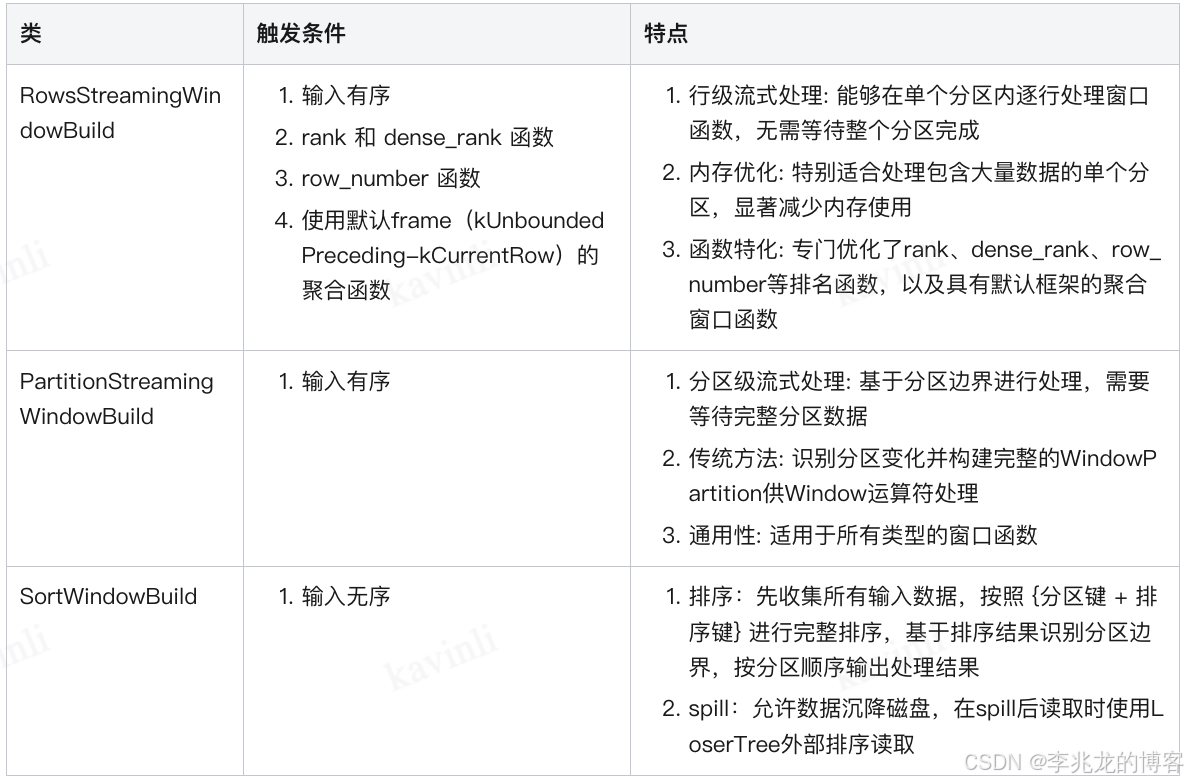
文章简介
在 AI 应用开发中,集成 OpenAI、Anthropic Claude 等多大型语言模型(LLM)常面临 API 碎片化、请求路由复杂等挑战。本文将介绍如何通过 ** 消息代理(Message Broker)** 实现高效的 LLM 管理,以开源工具 KubeMQ 为例,演示从环境搭建、路由逻辑开发到高可用设计的全流程。通过这种架构,开发者可轻松实现模型扩展、负载均衡与故障容错,大幅提升多 LLM 应用的开发效率与稳定性。
一、多 LLM 集成的核心挑战与破局思路
1.1 传统集成方式的痛点
- API 协议碎片化:OpenAI 使用 REST API,Claude 支持 gRPC 与 HTTP 双协议,需为每个模型编写独立适配代码。
- 请求路由复杂:多模型场景下(如摘要用 Claude、代码生成用 GPT-4),客户端需硬编码路由逻辑,扩展性差。
- 高并发瓶颈:直接调用模型 API 易引发流量尖峰,导致超时或服务降级。
1.2 消息代理的破局价值
核心优势:
- 协议抽象层:统一不同模型的通信协议,客户端仅需与消息代理交互。
- 智能路由引擎:基于规则(如模型类型、请求内容)动态分配请求,支持 A/B 测试与模型权重配置。
- 异步处理能力:通过消息队列缓冲请求,削峰填谷,提升系统吞吐量。
- 弹性容错机制:自动重试失败请求,支持多模型冗余切换,保障服务可用性。
二、基于 KubeMQ 的 LLM 路由系统搭建
2.1 环境准备与依赖安装
必备工具:
- KubeMQ:开源消息代理,支持 gRPC/REST 协议与多语言 SDK(本文用 Python)。
- LangChain:简化 LLM 集成的开发框架,封装 OpenAI 与 Claude 的 API 细节。
- Docker:快速部署 KubeMQ 服务。
安装步骤:
-
拉取 KubeMQ 镜像:
docker run -d --rm \ -p 8080:8080 -p 50000:50000 -p 9090:9090 \ -e KUBEMQ_TOKEN="your-token" \ # 替换为KubeMQ官网申请的Token kubemq/kubemq-community:latest -
安装 Python 依赖:
pip install kubemq-cq langchain openai anthropic python-dotenv -
配置环境变量
(.env 文件):
OPENAI_API_KEY=sk-xxx # OpenAI API密钥 ANTHROPIC_API_KEY=claude-xxx # Claude API密钥
2.2 构建 LLM 路由服务器
核心逻辑:监听不同模型通道,解析请求并调用对应 LLM,返回处理结果。
# server.py
import time
from kubemq.cq import Client, QueryMessageReceived, QueryResponseMessage
from langchain.chat_models import ChatOpenAI
from langchain.llms import Anthropic
import os
from dotenv import load_dotenv
import threading
load_dotenv()
class LLMRouter:
def __init__(self):
# 初始化LLM客户端
self.openai_llm = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0.7
)
self.claude_llm = Anthropic(
model="claude-3",
max_tokens_to_sample=1024
)
# 连接KubeMQ
self.client = Client(address="localhost:50000")
def handle_query(self, request: QueryMessageReceived, model):
"""通用请求处理函数"""
try:
prompt = request.body.decode("utf-8")
# 根据模型类型调用对应LLM
if model == "openai":
response = self.openai_llm.predict(prompt)
elif model == "claude":
response = self.claude_llm(prompt)
# 构造响应
return QueryResponseMessage(
query_received=request,
body=response.encode("utf-8"),
is_executed=True
)
except Exception as e:
return QueryResponseMessage(
query_received=request,
error=str(e),
is_executed=False
)
def run(self):
# 订阅OpenAI通道
def subscribe_openai():
self.client.subscribe_to_queries(
channel="openai-queue",
on_receive_query_callback=lambda req: self.handle_query(req, "openai")
)
# 订阅Claude通道
def subscribe_claude():
self.client.subscribe_to_queries(
channel="claude-queue",
on_receive_query_callback=lambda req: self.handle_query(req, "claude")
)
# 启动多线程订阅
threading.Thread(target=subscribe_openai).start()
threading.Thread(target=subscribe_claude).start()
print("LLM路由器已启动,监听通道:openai-queue, claude-queue")
time.sleep(1e9) # 保持进程运行
if __name__ == "__main__":
router = LLMRouter()
router.run()
代码解析:
- 模型初始化:使用 LangChain 封装的 LLM 客户端,支持模型参数(如 temperature)动态调整。
- 通道订阅:通过 KubeMQ 的
subscribe_to_queries方法监听指定通道,实现请求与模型的解耦。 - 错误处理:捕获 LLM 调用异常,返回包含错误信息的响应,便于客户端排查问题。
2.3 开发客户端应用
功能:向消息代理发送请求,指定目标模型并获取响应。
# client.py
from kubemq.cq import Client
import argparse
class LLMConsumer:
def __init__(self, broker_addr="localhost:50000"):
self.client = Client(address=broker_addr)
def send_prompt(self, prompt: str, model: str):
"""发送请求到指定模型通道"""
channel = f"{model}-queue" # 通道名与模型绑定
response = self.client.send_query_request(
QueryMessage(
channel=channel,
body=prompt.encode("utf-8"),
timeout_in_seconds=60 # 长时请求支持
)
)
if response.is_error:
raise RuntimeError(f"模型调用失败:{response.error}")
return response.body.decode("utf-8")
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--prompt", required=True, help="输入查询内容")
parser.add_argument("--model", choices=["openai", "claude"], required=True, help="选择模型")
args = parser.parse_args()
client = LLMConsumer()
try:
result = client.send_prompt(args.prompt, args.model)
print(f"[{args.model.upper()}] 响应:{result}")
except Exception as e:
print(f"错误:{str(e)}")
使用示例:
python client.py --prompt "撰写Python冒泡排序代码" --model openai
# 输出:[OPENAI] 响应:以下是Python实现的冒泡排序代码...
python client.py --prompt "分析用户评论情感" --model claude
# 输出:[CLAUDE] 响应:这条评论的情感倾向为积极,主要依据是...
三、进阶能力:构建高可用 LLM 路由系统
3.1 负载均衡与流量控制
场景:当单一模型实例无法处理高并发请求时,通过 KubeMQ 的队列机制实现请求分发。
配置步骤:
- 启动多个 LLM 服务实例,监听同一通道(如 “openai-queue”)。
- KubeMQ 自动将请求轮询分配至不同实例,实现负载均衡。
# 启动3个OpenAI服务实例
python server.py --model openai --instance 1 &
python server.py --model openai --instance 2 &
python server.py --model openai --instance 3 &
3.2 故障容错与动态切换
场景:当 OpenAI API 超时或限流时,自动切换至 Claude 处理请求。
实现逻辑:
# 客户端增加故障切换逻辑
class FaultTolerantClient:
def send_with_fallback(self, prompt: str, primary: str, fallback: str):
try:
return self.send_prompt(prompt, primary)
except Exception:
print(f"主模型{primary}调用失败,切换至{fallback}")
return self.send_prompt(prompt, fallback)
# 使用示例
client = FaultTolerantClient()
response = client.send_with_fallback("生成营销文案", "openai", "claude")
3.3 REST API 兼容支持
场景:为不支持 gRPC 的客户端提供 REST 接口。
请求示例(curl):
curl -X POST http://localhost:9090/send/request \
-H "Content-Type: application/json" \
-d '{
"RequestTypeData": 2,
"ClientID": "web-client",
"Channel": "claude-queue",
"BodyString": "翻译以下英文为中文:Hello, world!",
"Timeout": 30000
}'
响应结果:
{
"Body": "你好,世界!",
"IsError": false,
"Error": null
}
四、生产环境最佳实践
4.1 安全增强
- 认证机制:通过 KubeMQ Token 验证客户端身份,结合 API 密钥白名单限制调用来源。
- 数据加密:在消息代理层启用 TLS 加密,防止 LLM 请求与响应被嗅探。
4.2 监控与日志
- 内置指标:通过 KubeMQ Dashboard 查看通道吞吐量、请求延迟、错误率等指标。
- 分布式追踪:集成 OpenTelemetry,追踪请求在客户端、消息代理、LLM 服务间的完整链路。
4.3 弹性扩展
- 容器化部署:使用 Kubernetes 编排 KubeMQ 与 LLM 服务,实现自动扩缩容。
- 多区域容灾:在不同云厂商(如 AWS、Azure)部署 LLM 实例,通过 KubeMQ 的跨集群同步功能实现异地灾备。
总结
通过消息代理构建 LLM 路由系统,可将多模型集成的复杂度从 O (n²) 降至 O (n),显著提升开发效率与系统稳定性。KubeMQ 作为开源工具,不仅提供了可靠的消息通信能力,还通过通道机制、负载均衡、容错策略等特性,为多 LLM 应用提供了一站式解决方案。未来,随着更多模型(如 Google Gemini、Meta Llama)的加入,这种松耦合架构将成为企业级 AI 应用的标配。开发者只需关注业务逻辑,而模型管理、流量调度等底层细节均可交由消息代理处理,真正实现 “一次开发,多模兼容” 的高效开发模式。