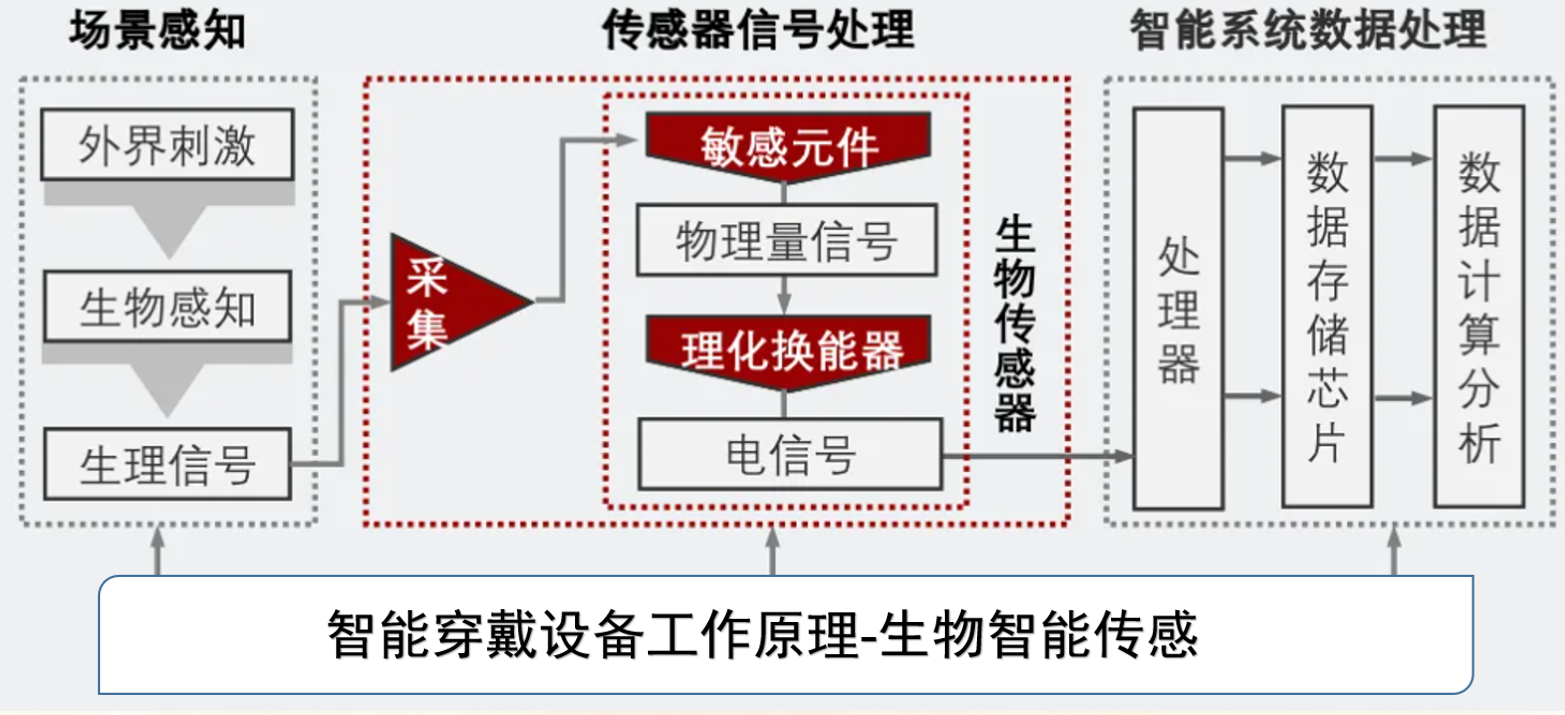
高性能 OpenSearch 数据导入
- 1.导入依赖库
- 2.配置参数
- 3.OpenSearch 客户端初始化
- 4.创建索引函数
- 5.数据生成器
- 6.批量处理函数
- 7.主导入函数
- 7.1 函数定义和索引创建
- 7.2 优化索引设置(导入前)
- 7.3 初始化变量和打印开始信息
- 7.4 线程池设置
- 7.5 主数据生成和导入循环
- 7.6 批次提交条件判断
- 7.7 进度显示
- 7.8 数据量达标检查
- 7.9 处理剩余批次
- 7.10 等待所有任务完成
- 7.11 恢复索引设置(导入后)
- 7.12 段合并优化
- 7.13 统计结果输出
- 8.问题分析
- 8.1 问题根源分析
- 8.2 修正后的代码方案
- 方案1:持续生成文档直到达到目标大小
- 方案2:预先计算需要的文档数量
- 8.3 关键修改点说明
- 8.4 其他可能的优化
- 9.性能优化关键点
- 10.使用建议
以下是一个高性能的 Python 脚本,用于向 OpenSearch 实例批量导入约 10GB 的数据。这个脚本使用了最佳实践来优化写入性能。
import json
import gzip
import time
from concurrent.futures import ThreadPoolExecutor
from opensearchpy import OpenSearch, helpers
from faker import Faker
import random
from datetime import datetime, timedelta
# 配置 OpenSearch 连接
OPENSEARCH_HOSTS = [{'host': 'localhost', 'port': 9200}] # 替换为你的 OpenSearch 实例地址
OPENSEARCH_AUTH = ('admin', 'admin') # 替换为你的认证信息
INDEX_NAME = 'large_data_index'
BULK_SIZE = 1000 # 每批次文档数量
THREAD_COUNT = 8 # 并发线程数
TARGET_DATA_SIZE = 10 * 1024 * 1024 * 1024 # 10GB 目标数据量
# 初始化 OpenSearch 客户端
client = OpenSearch(
hosts=OPENSEARCH_HOSTS,
http_auth=OPENSEARCH_AUTH,
use_ssl=False, # 根据你的配置调整
verify_certs=False,
timeout=30,
max_retries=10,
retry_on_timeout=True
)
# 创建索引(如果不存在)
def create_index():
if not client.indices.exists(INDEX_NAME):
index_body = {
"settings": {
"index": {
"number_of_shards": 5, # 根据你的集群规模调整
"number_of_replicas": 1,
"refresh_interval": "30s", # 导入期间减少刷新频率
}
},
"mappings": {
"properties": {
"user_id": {"type": "keyword"},
"name": {"type": "text"},
"email": {"type": "keyword"},
"age": {"type": "integer"},
"address": {"type": "text"},
"is_active": {"type": "boolean"},
"created_at": {"type": "date"},
"transaction_amount": {"type": "double"},
"tags": {"type": "keyword"},
"description": {"type": "text", "index": False} # 不索引大文本字段
}
}
}
client.indices.create(INDEX_NAME, body=index_body)
# 生成模拟数据的生成器
def generate_documents(num_docs):
fake = Faker()
start_date = datetime.now() - timedelta(days=365*5)
for _ in range(num_docs):
created_at = start_date + timedelta(days=random.randint(0, 365*5))
doc = {
"user_id": fake.uuid4(),
"name": fake.name(),
"email": fake.email(),
"age": random.randint(18, 80),
"address": fake.address().replace('\n', ', '),
"is_active": random.choice([True, False]),
"created_at": created_at.isoformat(),
"transaction_amount": round(random.uniform(1.0, 10000.0), 2),
"tags": random.sample(["premium", "standard", "vip", "new", "old", "active", "inactive"], 2),
"description": fake.text(max_nb_chars=200)
}
yield doc
# 批量处理函数
def process_batch(batch):
actions = [
{
"_op_type": "index",
"_index": INDEX_NAME,
"_source": doc
}
for doc in batch
]
try:
success, failed = helpers.bulk(
client,
actions,
chunk_size=BULK_SIZE,
request_timeout=60,
raise_on_error=False
)
return len(actions), failed
except Exception as e:
print(f"批量写入失败: {str(e)}")
return 0, len(actions)
# 主导入函数
def import_data():
create_index()
# 临时调整索引设置以提高写入性能
client.indices.put_settings(index=INDEX_NAME, body={
"index": {
"refresh_interval": "-1", # 禁用刷新
"number_of_replicas": "0" # 禁用副本
}
})
print("开始数据导入...")
start_time = time.time()
total_docs = 0
total_bytes = 0
batch = []
avg_doc_size = 0
# 使用线程池并行处理
with ThreadPoolExecutor(max_workers=THREAD_COUNT) as executor:
futures = []
for doc in generate_documents(10**6): # 生成足够多的文档
batch.append(doc)
# 估算文档大小
if avg_doc_size == 0:
avg_doc_size = len(json.dumps(doc).encode('utf-8'))
# 当批次达到大小时提交
if len(batch) >= BULK_SIZE or total_bytes + (len(batch) * avg_doc_size) >= TARGET_DATA_SIZE:
futures.append(executor.submit(process_batch, batch.copy()))
total_docs += len(batch)
total_bytes += len(batch) * avg_doc_size
batch = []
# 显示进度
if len(futures) % 10 == 0:
processed = sum(f.result()[0] for f in futures if f.done())
print(f"进度: {processed:,} 文档, {total_bytes/(1024**3):.2f} GB")
if total_bytes >= TARGET_DATA_SIZE:
break
# 处理剩余批次
if batch:
futures.append(executor.submit(process_batch, batch))
total_docs += len(batch)
total_bytes += len(batch) * avg_doc_size
# 等待所有任务完成
for future in futures:
processed, failed = future.result()
if failed > 0:
print(f"警告: {failed} 文档写入失败")
# 恢复索引设置
client.indices.put_settings(index=INDEX_NAME, body={
"index": {
"refresh_interval": "30s",
"number_of_replicas": "1"
}
})
# 强制合并段以优化存储
client.indices.forcemerge(index=INDEX_NAME, max_num_segments=5)
end_time = time.time()
duration = end_time - start_time
print(f"\n导入完成!")
print(f"总文档数: {total_docs:,}")
print(f"总数据量: {total_bytes/(1024**3):.2f} GB")
print(f"耗时: {duration:.2f} 秒")
print(f"写入速度: {total_docs/duration:,.0f} 文档/秒")
print(f"吞吐量: {total_bytes/(1024**2)/duration:.2f} MB/秒")
if __name__ == "__main__":
import_data()
1.导入依赖库
pip install opensearch-py faker
import json
import gzip
import time
from concurrent.futures import ThreadPoolExecutor
from opensearchpy import OpenSearch, helpers
from faker import Faker
import random
from datetime import datetime, timedelta
json:用于处理 JSON 格式数据。gzip:可选,用于压缩数据(虽然脚本中未实际使用)。time:计算导入耗时。ThreadPoolExecutor:实现多线程并发处理。OpenSearch和helpers:OpenSearch Python 客户端库。Faker:生成模拟测试数据。random和datetime:生成随机数据和日期。
2.配置参数
OPENSEARCH_HOSTS = [{'host': 'localhost', 'port': 9200}]
OPENSEARCH_AUTH = ('admin', 'xxxxx')
INDEX_NAME = 'large_data_index'
BULK_SIZE = 1000
THREAD_COUNT = 8
TARGET_DATA_SIZE = 10 * 1024 * 1024 * 1024
- 连接参数:主机、端口、认证信息。
- 目标索引名称。
- 批量大小:每次批量写入的文档数。
- 线程数:并发处理的工作线程数。
- 目标数据量:10GB(用于控制导入总量)。
3.OpenSearch 客户端初始化
client = OpenSearch(
hosts=OPENSEARCH_HOSTS,
http_auth=OPENSEARCH_AUTH,
use_ssl=False,
verify_certs=False,
timeout=30,
max_retries=10,
retry_on_timeout=True
)
配置了客户端连接参数,包括:
- 禁用 SSL(仅用于测试环境)。
- 30 秒超时。
- 最大重试次数。
- 超时后自动重试。
4.创建索引函数
def create_index():
if not client.indices.exists(INDEX_NAME):
index_body = {
"settings": {
"index": {
"number_of_shards": 5, # 根据你的集群规模调整
"number_of_replicas": 1,
"refresh_interval": "30s", # 导入期间减少刷新频率
}
},
"mappings": {
"properties": {
"user_id": {"type": "keyword"},
"name": {"type": "text"},
"email": {"type": "keyword"},
"age": {"type": "integer"},
"address": {"type": "text"},
"is_active": {"type": "boolean"},
"created_at": {"type": "date"},
"transaction_amount": {"type": "double"},
"tags": {"type": "keyword"},
"description": {"type": "text", "index": False} # 不索引大文本字段
}
}
}
client.indices.create(INDEX_NAME, body=index_body)
- 检查索引是否存在,不存在则创建。
- 配置了分片数、副本数和刷新间隔。
- 定义了字段映射(数据类型等)。
5.数据生成器
def generate_documents(num_docs):
fake = Faker()
start_date = datetime.now() - timedelta(days=365*5)
for _ in range(num_docs):
created_at = start_date + timedelta(days=random.randint(0, 365*5))
doc = {
"user_id": fake.uuid4(),
"name": fake.name(),
"email": fake.email(),
"age": random.randint(18, 80),
"address": fake.address().replace('\n', ', '),
"is_active": random.choice([True, False]),
"created_at": created_at.isoformat(),
"transaction_amount": round(random.uniform(1.0, 10000.0), 2),
"tags": random.sample(["premium", "standard", "vip", "new", "old", "active", "inactive"], 2),
"description": fake.text(max_nb_chars=200)
}
yield doc
- 使用
Faker生成真实模拟数据。 - 生成器模式按需产生文档,节省内存。
- 创建随机日期、ID、文本等数据。
6.批量处理函数
def process_batch(batch):
actions = [
{
"_op_type": "index",
"_index": INDEX_NAME,
"_source": doc
}
for doc in batch
]
try:
success, failed = helpers.bulk(
client,
actions,
chunk_size=BULK_SIZE,
request_timeout=60,
raise_on_error=False
)
return len(actions), failed
except Exception as e:
print(f"批量写入失败: {str(e)}")
return 0, len(actions)
- 将文档列表转换为批量操作格式。
- 使用
helpers.bulk高效执行批量操作。 - 处理可能的错误,并返回成功/失败计数。
7.主导入函数
def import_data():
create_index()
# 临时调整索引设置以提高写入性能
client.indices.put_settings(index=INDEX_NAME, body={
"index": {
"refresh_interval": "-1", # 禁用刷新
"number_of_replicas": "0" # 禁用副本
}
})
print("开始数据导入...")
start_time = time.time()
total_docs = 0
total_bytes = 0
batch = []
avg_doc_size = 0
# 使用线程池并行处理
with ThreadPoolExecutor(max_workers=THREAD_COUNT) as executor:
futures = []
for doc in generate_documents(10**6): # 生成足够多的文档
batch.append(doc)
# 估算文档大小
if avg_doc_size == 0:
avg_doc_size = len(json.dumps(doc).encode('utf-8'))
# 当批次达到大小时提交
if len(batch) >= BULK_SIZE or total_bytes + (len(batch) * avg_doc_size) >= TARGET_DATA_SIZE:
futures.append(executor.submit(process_batch, batch.copy()))
total_docs += len(batch)
total_bytes += len(batch) * avg_doc_size
batch = []
# 显示进度
if len(futures) % 10 == 0:
processed = sum(f.result()[0] for f in futures if f.done())
print(f"进度: {processed:,} 文档, {total_bytes/(1024**3):.2f} GB")
if total_bytes >= TARGET_DATA_SIZE:
break
# 处理剩余批次
if batch:
futures.append(executor.submit(process_batch, batch))
total_docs += len(batch)
total_bytes += len(batch) * avg_doc_size
# 等待所有任务完成
for future in futures:
processed, failed = future.result()
if failed > 0:
print(f"警告: {failed} 文档写入失败")
# 恢复索引设置
client.indices.put_settings(index=INDEX_NAME, body={
"index": {
"refresh_interval": "30s",
"number_of_replicas": "1"
}
})
# 强制合并段以优化存储
client.indices.forcemerge(index=INDEX_NAME, max_num_segments=5)
end_time = time.time()
duration = end_time - start_time
print(f"\n导入完成!")
print(f"总文档数: {total_docs:,}")
print(f"总数据量: {total_bytes/(1024**3):.2f} GB")
print(f"耗时: {duration:.2f} 秒")
print(f"写入速度: {total_docs/duration:,.0f} 文档/秒")
print(f"吞吐量: {total_bytes/(1024**2)/duration:.2f} MB/秒")
7.1 函数定义和索引创建
def import_data():
create_index()
- 定义主导入函数
import_data()。 - 首先调用
create_index()函数确保目标索引存在。
7.2 优化索引设置(导入前)
# 临时调整索引设置以提高写入性能
client.indices.put_settings(index=INDEX_NAME, body={
"index": {
"refresh_interval": "-1", # 禁用刷新
"number_of_replicas": "0" # 禁用副本
}
})
- 使用
put_settings临时修改索引配置。 refresh_interval="-1":禁用自动刷新,减少写入开销。number_of_replicas="0":禁用副本,提高写入速度。
7.3 初始化变量和打印开始信息
print("开始数据导入...")
start_time = time.time()
total_docs = 0
total_bytes = 0
batch = []
avg_doc_size = 0
- 打印开始信息。
- 记录开始时间用于计算总耗时。
- 初始化计数器:总文档数、总字节数。
- 初始化批量列表和平均文档大小变量。
7.4 线程池设置
# 使用线程池并行处理
with ThreadPoolExecutor(max_workers=THREAD_COUNT) as executor:
futures = []
- 创建线程池,最大线程数为
THREAD_COUNT(之前定义为 8)。 - 初始化
futures列表用于跟踪异步任务。
7.5 主数据生成和导入循环
for doc in generate_documents(10**6): # 生成足够多的文档
batch.append(doc)
# 估算文档大小
if avg_doc_size == 0:
avg_doc_size = len(json.dumps(doc).encode('utf-8'))
- 遍历数据生成器产生的文档。
- 将文档添加到当前批次。
- 首次循环时计算单个文档的平均大小(字节数)。
7.6 批次提交条件判断
# 当批次达到大小时提交
if len(batch) >= BULK_SIZE or total_bytes + (len(batch) * avg_doc_size) >= TARGET_DATA_SIZE:
futures.append(executor.submit(process_batch, batch.copy()))
total_docs += len(batch)
total_bytes += len(batch) * avg_doc_size
batch = []
- 当批次达到
BULK_SIZE( 1000 1000 1000)或总数据量接近目标时:- 提交批次到线程池处理。
- 更新总文档数和总字节数。
- 清空当前批次。
7.7 进度显示
# 显示进度
if len(futures) % 10 == 0:
processed = sum(f.result()[0] for f in futures if f.done())
print(f"进度: {processed:,} 文档, {total_bytes/(1024**3):.2f} GB")
- 每完成 10 个批次显示一次进度。
- 计算已处理的文档数和数据量(GB)。
7.8 数据量达标检查
if total_bytes >= TARGET_DATA_SIZE:
break
- 如果总数据量达到目标(10GB),退出循环。
7.9 处理剩余批次
# 处理剩余批次
if batch:
futures.append(executor.submit(process_batch, batch))
total_docs += len(batch)
total_bytes += len(batch) * avg_doc_size
- 循环结束后处理最后未满的批次。
7.10 等待所有任务完成
# 等待所有任务完成
for future in futures:
processed, failed = future.result()
if failed > 0:
print(f"警告: {failed} 文档写入失败")
- 等待所有异步任务完成。
- 检查并报告失败的文档。
7.11 恢复索引设置(导入后)
# 恢复索引设置
client.indices.put_settings(index=INDEX_NAME, body={
"index": {
"refresh_interval": "30s",
"number_of_replicas": "1"
}
})
- 恢复正常的刷新间隔(30秒)。
- 重新启用副本(1个)。
7.12 段合并优化
# 强制合并段以优化存储
client.indices.forcemerge(index=INDEX_NAME, max_num_segments=5)
- 强制合并 Lucene 段文件,减少段数量(至多 5 个)。
- 提高后续查询性能。
7.13 统计结果输出
end_time = time.time()
duration = end_time - start_time
print(f"\n导入完成!")
print(f"总文档数: {total_docs:,}")
print(f"总数据量: {total_bytes/(1024**3):.2f} GB")
print(f"耗时: {duration:.2f} 秒")
print(f"写入速度: {total_docs/duration:,.0f} 文档/秒")
print(f"吞吐量: {total_bytes/(1024**2)/duration:.2f} MB/秒")
这个函数精心设计了数据流和控制逻辑,确保在保持高性能的同时,也具有良好的可靠性和可观测性。
8.问题分析
如果实践了的同学会发现,程序可能在未达到 10GB 数据量前就停止了,原因在于数据生成逻辑的设计问题。让我们详细分析原因并提供修复方案:
8.1 问题根源分析
在当前的 generate_documents() 函数中:
def generate_documents(num_docs): # num_docs=10**6
for _ in range(num_docs): # 只生成100万文档
yield doc
- 固定文档数量限制:函数只生成固定数量(100万)的文档,而不是持续生成直到达到 10GB。
- 文档大小估算不准确:脚本使用首个文档大小估算所有文档大小,但实际文档可能有大小差异。
- 循环终止条件:主循环会在生成器耗尽或达到 10GB 时停止,但生成器先耗尽了。
8.2 修正后的代码方案
方案1:持续生成文档直到达到目标大小
def import_data():
# ...前面的初始化代码不变...
with ThreadPoolExecutor(max_workers=THREAD_COUNT) as executor:
futures = []
# 修改为无限循环,通过break条件退出
for doc in generate_documents(float('inf')): # 无限生成文档
batch.append(doc)
# 实时计算当前文档大小,而不是估算
doc_size = len(json.dumps(doc).encode('utf-8'))
total_bytes += doc_size
if len(batch) >= BULK_SIZE or total_bytes >= TARGET_DATA_SIZE:
futures.append(executor.submit(process_batch, batch.copy()))
total_docs += len(batch)
batch = []
# 显示进度(使用实际数据量)
if len(futures) % 10 == 0:
processed = sum(f.result()[0] for f in futures if f.done())
print(f"进度: {processed:,} 文档, {total_bytes/(1024**3):.2f} GB")
if total_bytes >= TARGET_DATA_SIZE:
break # 达到目标数据量才退出
# ...后续恢复设置和统计代码不变...
方案2:预先计算需要的文档数量
def calculate_required_docs():
# 生成样本文档计算平均大小
sample_doc = next(generate_documents(1))
avg_size = len(json.dumps(sample_doc).encode('utf-8'))
return int(TARGET_DATA_SIZE / avg_size)
def import_data():
required_docs = calculate_required_docs()
with ThreadPoolExecutor(max_workers=THREAD_COUNT) as executor:
# 修改为使用精确计算的文档数量
for doc in generate_documents(required_docs):
# ...其余处理逻辑不变...
8.3 关键修改点说明
- 无限生成器:
generate_documents(float('inf'))会持续生成文档直到外部中断。 - 精确大小计算:实时计算每个文档的大小,而不是使用首个文档估算。
- 严格大小检查:只有达到目标数据量才会退出循环。
- 内存安全:仍然保持批处理模式,避免内存爆炸。
8.4 其他可能的优化
-
动态调整批量大小:根据文档实际大小动态调整
BULK_SIZE。if avg_doc_size > 1024: # 如果文档较大 BULK_SIZE = 500 # 减少批量大小 else: BULK_SIZE = 1000 -
更精确的进度显示:
print(f"进度: {total_docs:,} 文档, {total_bytes/(1024**3):.2f}/{TARGET_DATA_SIZE/(1024**3):.2f} GB") -
提前终止检查:在长时间运行中增加键盘中断检查。
try: # 主循环代码 except KeyboardInterrupt: print("\n用户中断,正在保存进度...")
选择哪种方案取决于你的具体需求:
- 方案 1 更适合精确控制总数据量。
- 方案 2 更适合预先知道需要多少文档的场景。
两种方案都能确保生成足够 10GB 的数据后才停止程序。
9.性能优化关键点
- 批量处理:减少网络往返次数。
- 多线程:充分利用 CPU 和网络资源。
- 临时禁用刷新和副本:减少写入开销。
- 生成器模式:避免内存爆炸。
- 合理的超时和重试:提高稳定性。
- 后期优化:强制合并段提高查询性能。
10.使用建议
- 根据集群规模调整分片数。
- 根据网络和硬件调整批量大小和线程数。
- 生产环境应启用 SSL 和正确证书。
- 大数据量导入建议分多次进行。
这个脚本设计用于高效导入大量数据到 OpenSearch,同时保持代码清晰和可维护性。