MySQL之约束和表的增删查改
- 一.数据库约束
- 1.1数据库约束的概念
- 1.2NOT NULL 非空约束
- 1.3DEFAULT 默认约束
- 1.4唯一约束
- 1.5主键约束和自增约束
- 1.6自增约束
- 1.7外键约束
- 1.8CHECK约束
- 二.表的增删查改
- 2.1Create创建
- 2.2Retrieve读取
- 2.3Update更新
- 2.4Delete删除和Truncate截断
一.数据库约束
1.1数据库约束的概念
C++中对于我们定义的数据有着一套检查的逻辑,当数据不符合你数据类型的范围时就会产生报错那么MySQL中是否也有这种设计呢?C++中对于数据的检查一般是编译器自己进行产生报错而MySQL则会通过约束来让强制程序员自己合法插入数据。
数据库约束是指对数据库表中的数据所施加的规则或条件,⽤于确保数据的准确性和可靠性。这
些约束可以是基于数据类型、值范围、唯⼀性、⾮空等规则,以确保数据的正确性和相容性。简单来说约束类似于我们的法律法规来让我们程序员自己遵守,只要不违反这个规定MySQL就不会发出警告。
例如我们之前介绍MySQL中数据类型时提到过不同类型的取值范围这就算是一种约束,只要我们插入的数据不符合这个范围MySQL也会发出警告。
1.2NOT NULL 非空约束
对于某些数据将其设为空是没有意义所以我们可以使用非空约束来让其不可能为空。
例如对于学生来说他的名字学号身份证这些都不可能为空,也不会将其设为空因为这样就没有意义了。
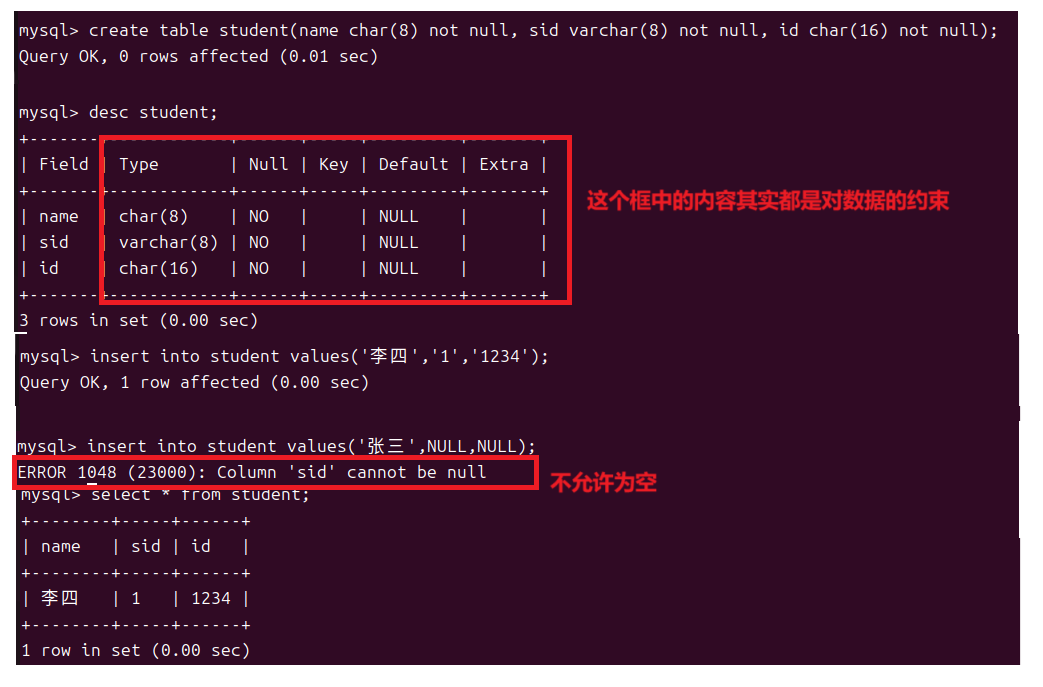
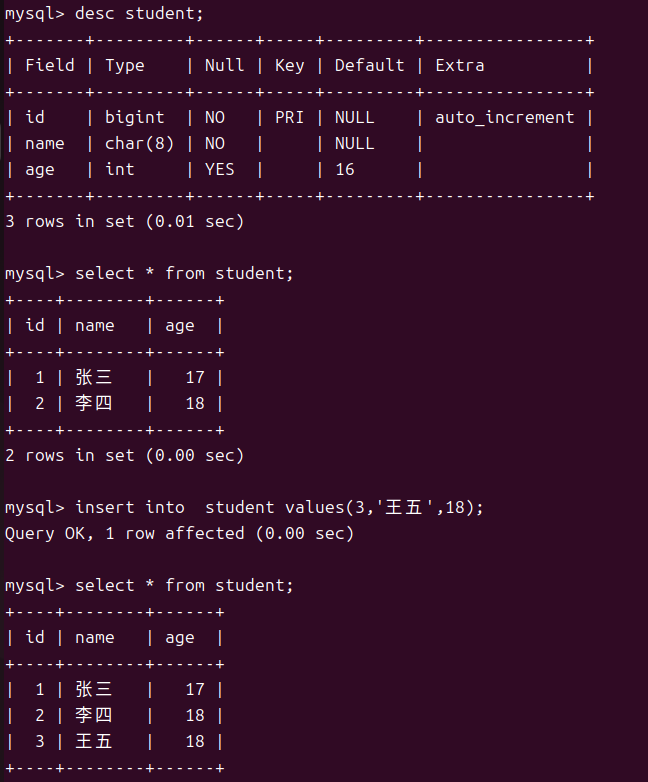
从图片中我们也可以发现想要对某列加约束的话我们只需要在创建表时在列后增加关键字即可,非空约束就是not null。
想要判断表中某列是否可以为空我们只需要使用desc来查看表结构其中的NULL为yes则说明可以为空no就是不可以。
1.3DEFAULT 默认约束
我们同样可以为一列增加一个默认值类似于我们C++中的缺省参数,只要我们不显式设置列的值那么它就是默认值。
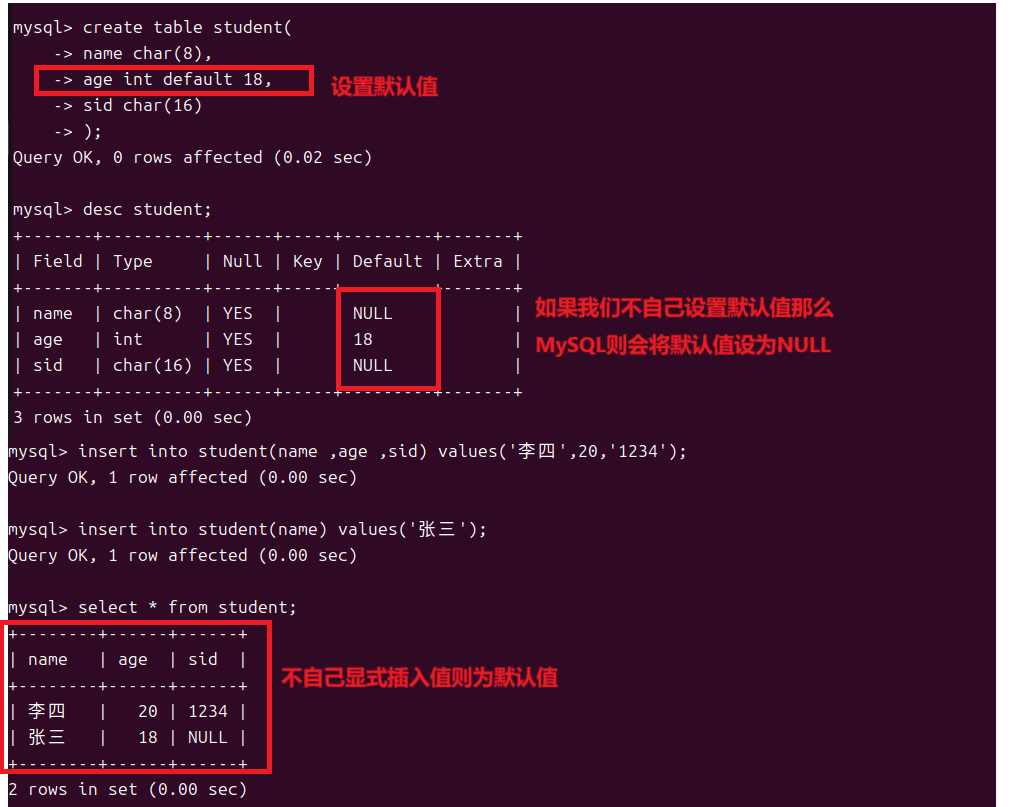
1.4唯一约束
对于数据来说我们有时候需要它是不重复的所以我们也可以将一个列增加唯一约束。这时候这列就被叫做唯一键。
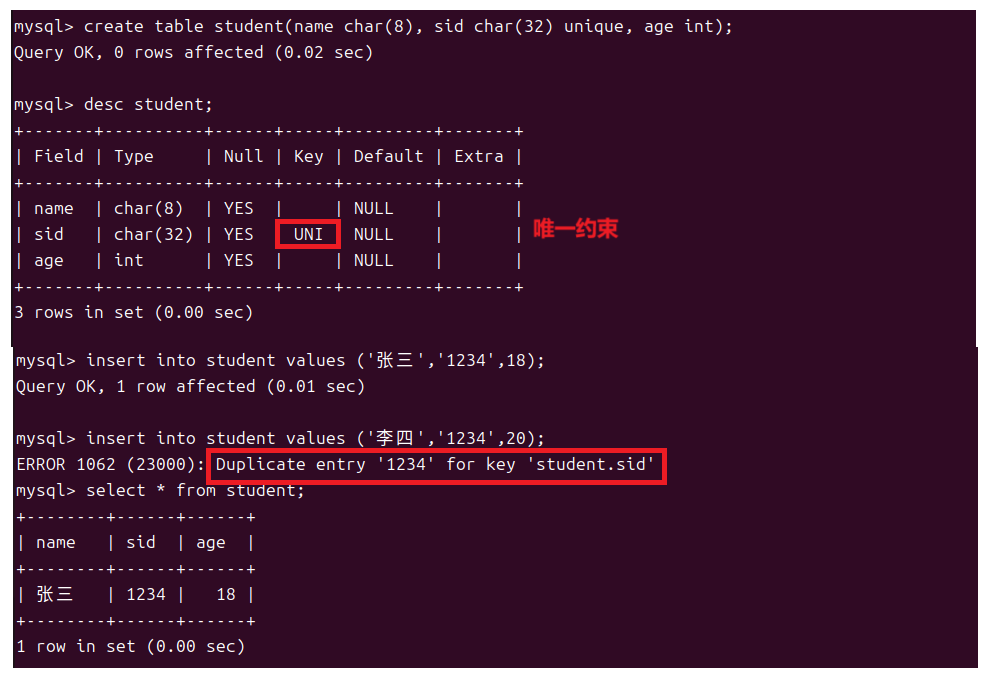
1.5主键约束和自增约束
对于一个表来说我们有时候对于存储的数据我们是有轻重之分的,有些数据是这个表中最重要的数据例如学生表中的学号,即使其他的数据都为空工作人员也可以通过学号来找到一个学生。有些数据的存在又是比较无所谓的就像学生表中学生的爱好,这些数据就算不存在也不会影响什么。所以这些重要的数据我们需要来特别关注不能让它重复也不能为空,这就是主键。
主键约束用来标明一张表中的每条记录,主键既不能为空也不能重复并且一个表中只能有一个主键而主键可以由一列或者多列组成。
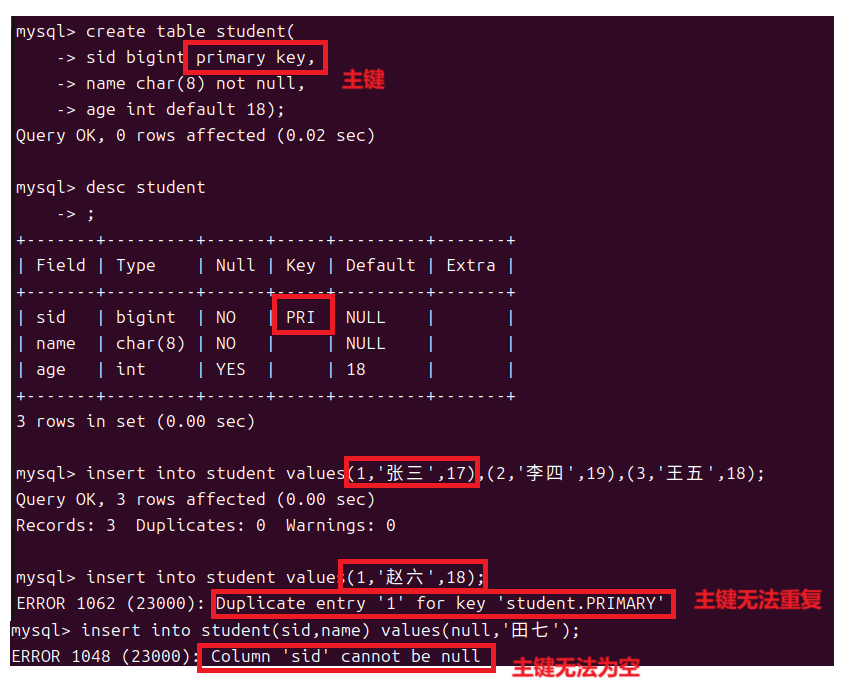
主键同样可以设为多列此时只要多列的内容不是完全相同则不算是重复,但是多列中每一个的内容都不可以为空。
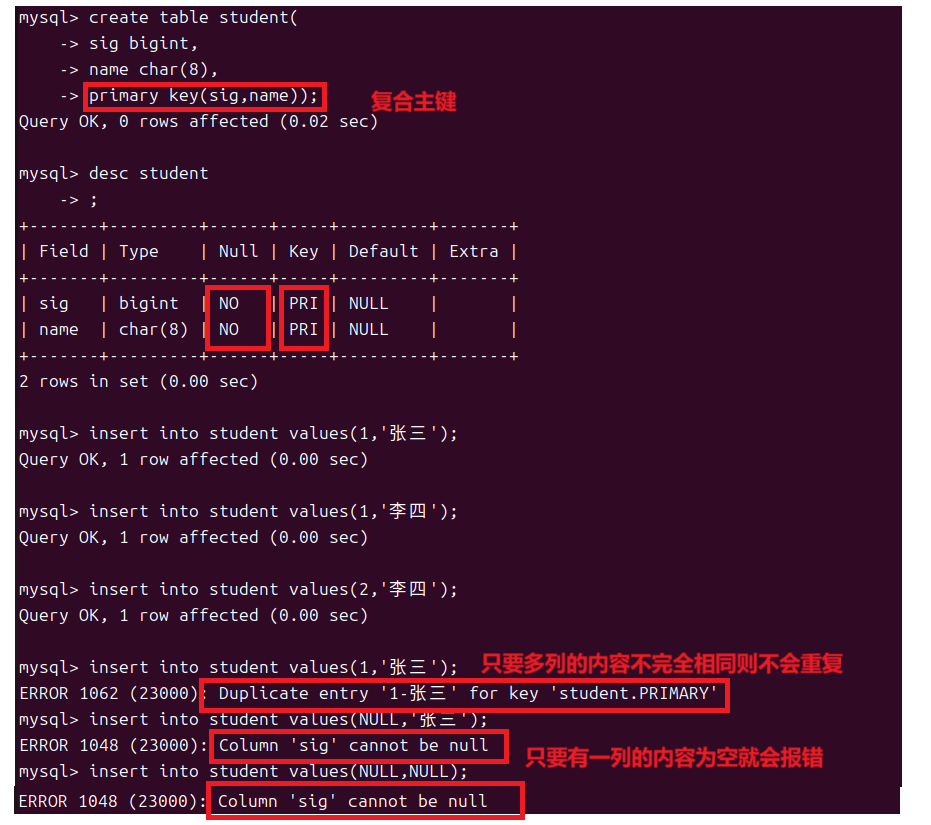
一个表中只能有一个主键

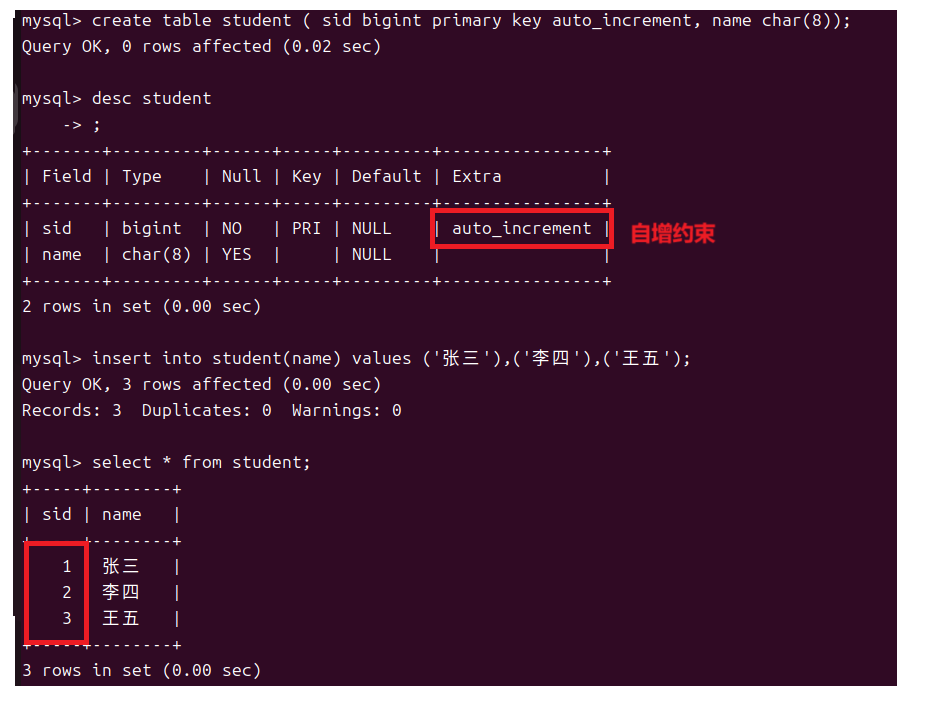
1.6自增约束
因为主键是用来标识表中的每个记录所以它一般搭配则自增约束来使用,它允许数据库自动为新插入行的特定列生成一个唯一的数字。这通常用于主键列,以确保每条记录都有一个唯一的标识符。
因为只有数字可以自增所以自增列必须是整数类型并且只能用于键列即唯一键,主键或者外键同时一个表中只能设置一个自增列。
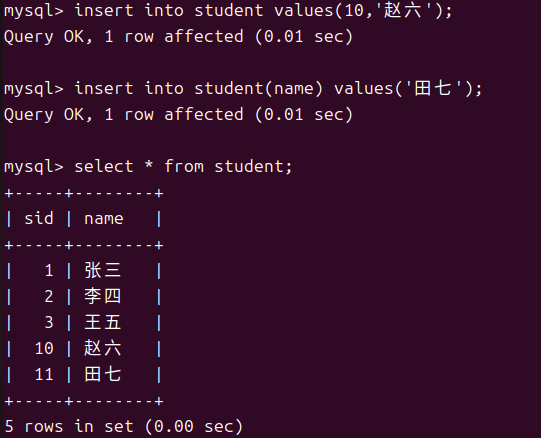
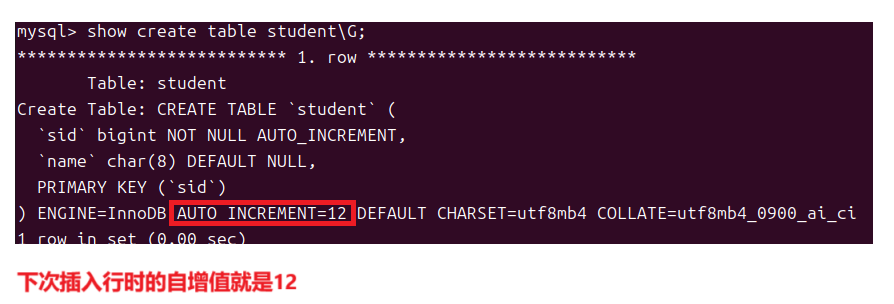
在一个键列被设为自增后我们仍然可以主动去设置它的值不过之后会在你设置的值的基础上进行自增。我们可以使用show create table table_name 来查看这个表的创建语句以及此时它的自增值是多少
1.7外键约束
人与人之间是有联系的同理表与表之间也是有联系的例如我是二班的学生那么这里就会有两个表一个为班级表一个是二班的成员表。那么这两个表不就形成了一种主从关系,主表是班级表而从表就是各班的成员表也可以说从表是对主表中对应内容的扩展。所以主表和从表中可以通过两表中各自的一列建立联系就像班级表中的班级编号和成员表中的班级编号。
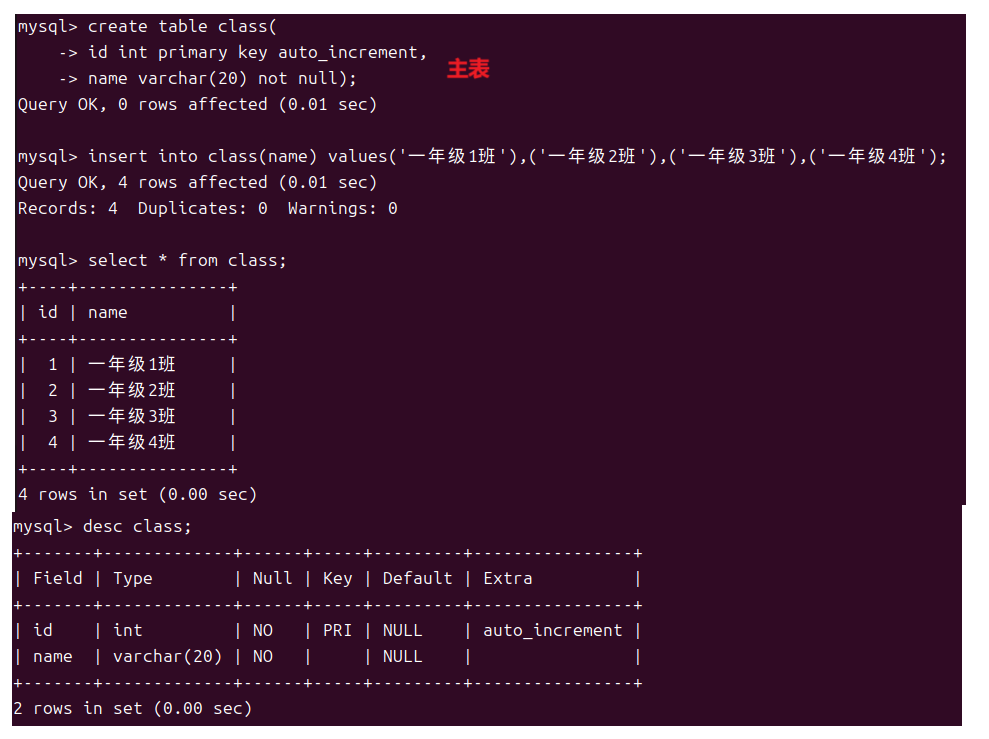
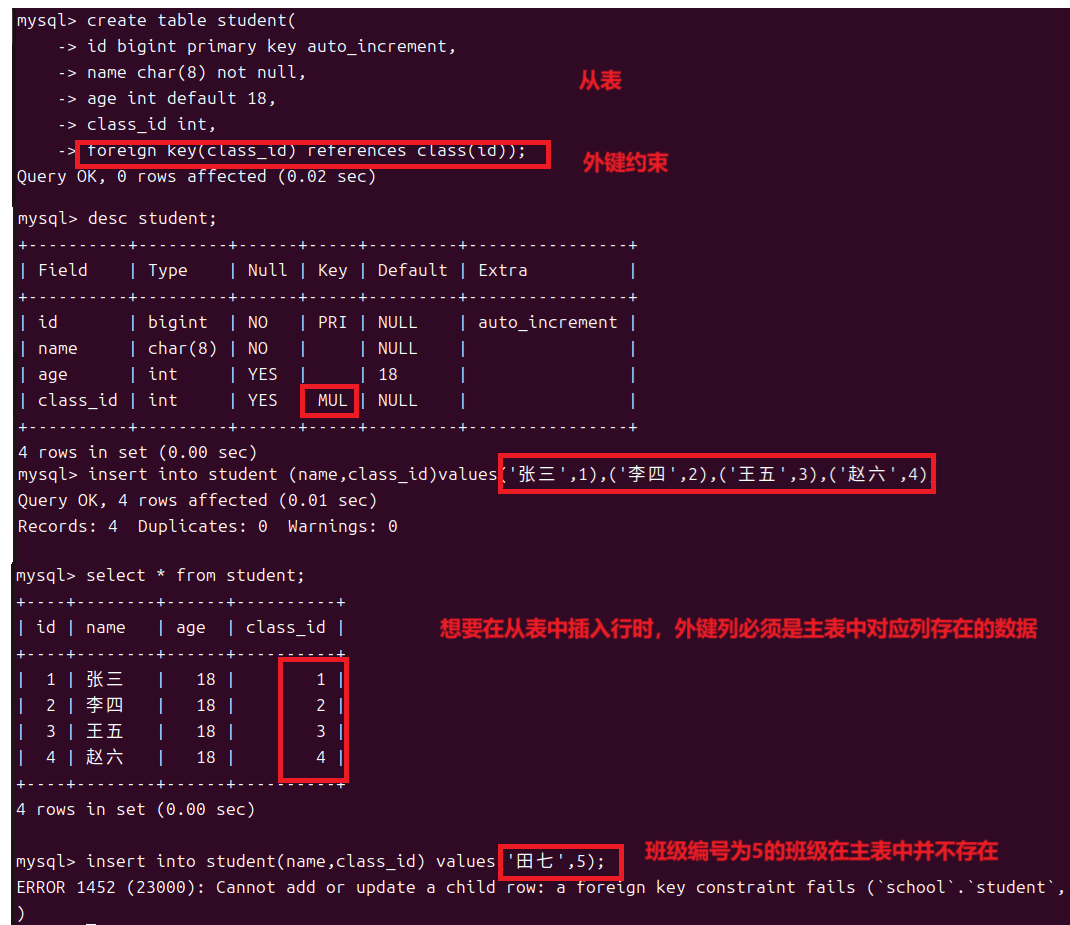
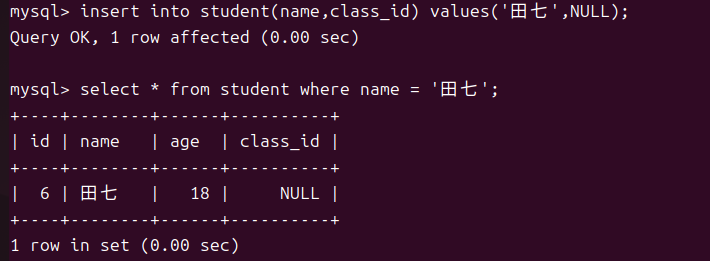
但是我们可以将从表中班级编号设为空来插入行
所以在使用外键约束时我们需要注意:
- 主表和从表对应的列数据类型必须相同
- 在从表插入行时外键列的值必须在主表中存在或者为空
- 在删除主表中某行时从表不能存在对这行的引用
- 删除主表前必须删除从表
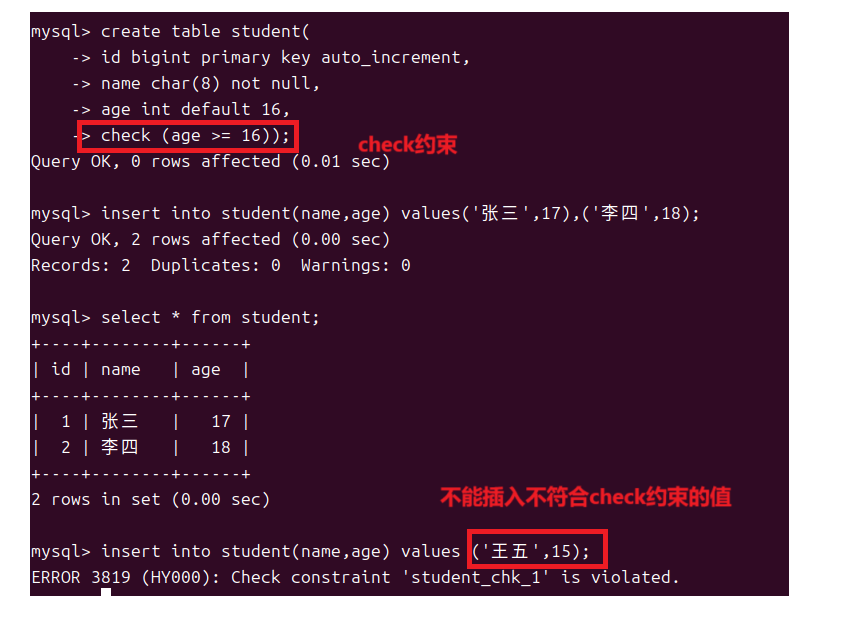
1.8CHECK约束
可以应⽤于⼀个或多个列,⽤于限制列中可接受的数据值,从⽽确保数据的完整性和准确性。
二.表的增删查改
对数据库中表的内容做操作一般被分为四类:Create,Retrieve,Update,Delete,简称CRUD。
2.1Create创建
insert
[into]
table_name #表名
[(column [,column],...)] #是否指定列
values (vast_list) [,(vast_list)],...#插入的数据以行为单位
vast_list: value[,value] ...
对于使用insert插入行我们可以完成单行数据全列插入,单行数据指定列插入以及多行数据指定列插入。
-
单行数据全列插入
-
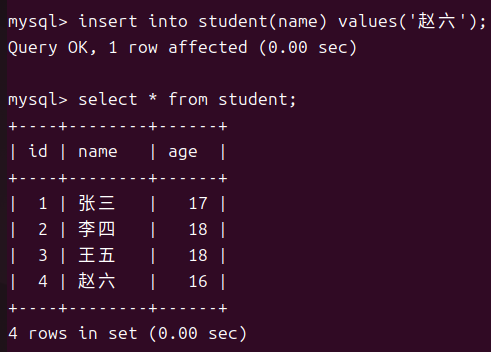
单行数据指定列插入
使用单行指定列插入时要注意没有被插入的列是否有非空约束或者主键约束以免出现报错
-
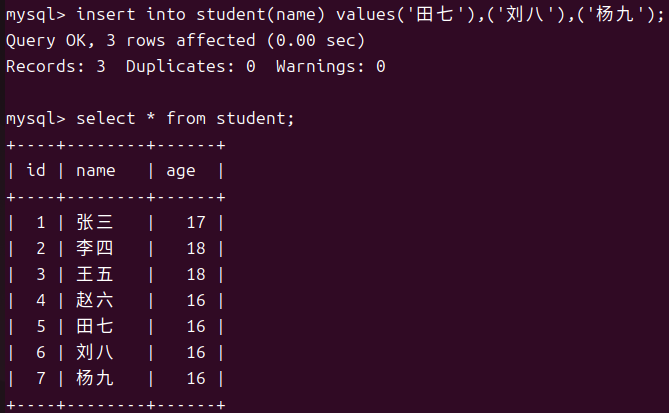
多行数据指定列插入
使用多行数据指定列插入时要注意每行的数据要用()各自包裹起来。
2.2Retrieve读取
SELECT
[DISTINCT] #是否去重
select_expr [, select_expr] ... #读取的列
[FROM table_references] #是否从某个表中读取
[WHERE where_condition] #是否有判断条件
[GROUP BY {col_name | expr}, ...] #是否进行分表
[HAVING where_condition] #在完成读取后是否再进行条件判断
[ORDER BY {col_name | expr } [ASC | DESC], ... ] #是否进行排序
[LIMIT {[offset,] row_count | row_count OFFSET offset}] #限制返回记录数量
在了解了语法后我们从简单的开始慢慢入手,用例子来为大家讲解语法中各个字段的作用
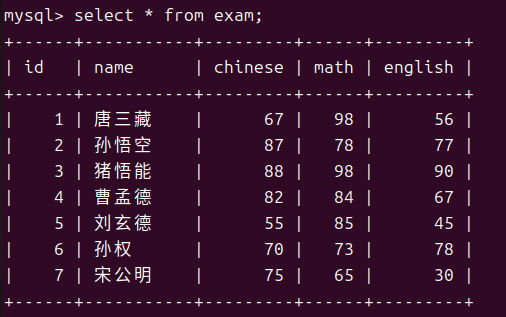
首先是最简单的查询,我们可以完成全列查询或者指定列查询亦或者我们可以查询一个表达式的结果。
- 全列查询
- 指定列查询
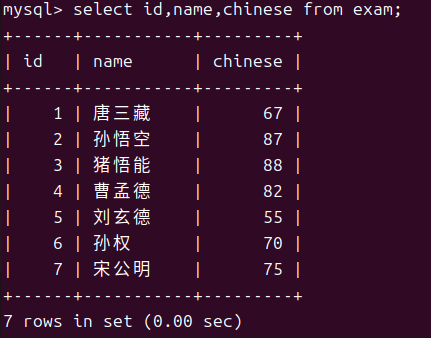
- 查询表达式结果
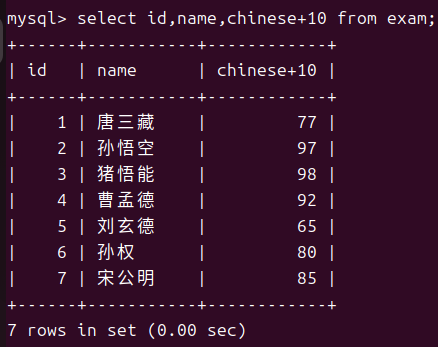
这其中chinese+10就算是一个表达式,有了这项特性我们就可以利用这些零碎的数据来完成需求例如我们想要知道总分。
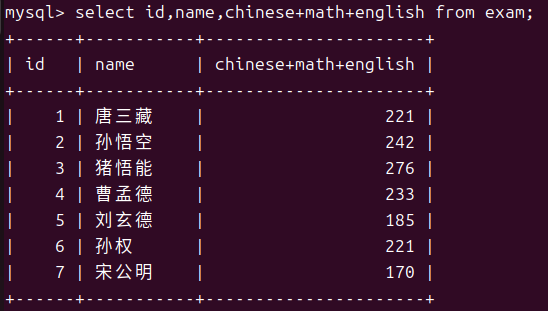
但是我们发现chinese+math+english的可读性也太差了所以我们还可以将这个表达式修改名称。
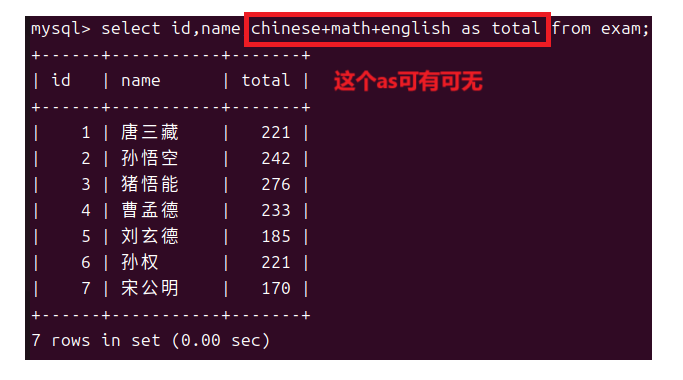
这就是最基础的查询工作接下来我们融合哪些可选性的字段来对查询进行升级
-
[DISTINCT] #是否去重
我们可以使用distinct来在查询的时候完成对表的去重
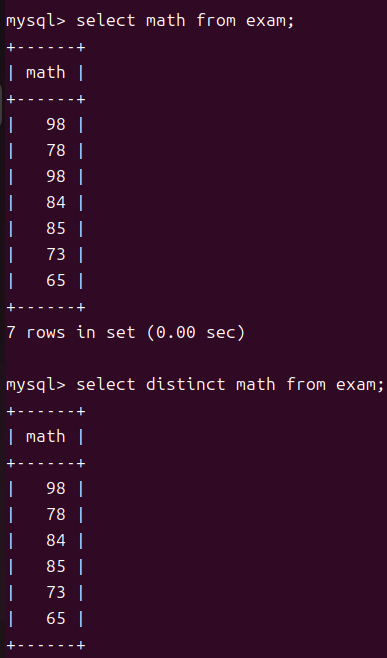
在使用math的时候要注意只要表中有任何一列的内容是不重复的那就不会被去重,同时我也希望大家可以理解表这个概念,表不但指存储在磁盘中数据库文件中的表文件,在MySQL中一切都是表都可以当做表比如我们完成查询后输出的内容也是一个表只不过我们可以将其分为逻辑表以及存储表。对表的理解会影响到后续我们对复合查询以及内外连接的理解。 -
[WHERE where_condition] #是否有判断条件
MySQL中我们一样可以在查询时进行条件判断来完成对数据的筛选工作,既然有判断功能那么我们就需要使用运算符,其中被分为两种:比较运算符和逻辑运算符。同时我们搭配例子来给大家说明
比较运算符:
| 运算符 | 说明 |
|---|---|
| >, >=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,对于NULL的比较不安全,比如NULL=NULL的结果一样为NULL |
| <=> | 等于,对于NULL的比较是安全的,比如NULL <=>NULL的结果是TRUE |
| !=,<> | 不等于 |
| value BETWEEN a0AND a1 | 范围匹配,[a0, a1],如果a0 <= value <= a1,返回TRUE或1,NOT BETWEEN则取反 |
| value IN (option, … | 如果value 在optoin列表中,则返回TRUE(1),NOT IN则取反 |
| IS NULL | 是NULL |
| IS NOT NULL | 不是NULL |
| LIKE | 模糊匹配,%表示任意多个字符包括零个,_表示任意一个字符,NOT LIKE则取反 |
#英语成绩大于60分
mysql> select * from exam where english > 60;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 6 | 孙权 | 70 | 73 | 78 |
+------+-----------+---------+------+---------+
4 rows in set (0.00 sec)
#语文成绩大于英语成绩
mysql> select * from exam where chinese > english;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘⽞德 | 55 | 85 | 45 |
| 7 | 宋公明 | 75 | 65 | 30 |
+------+-----------+---------+------+---------+
5 rows in set (0.00 sec)
#总分大于200分
mysql> select id,name,chinese+math+english total from exam where chinese+math+english > 200;
+------+-----------+-------+
| id | name | total |
+------+-----------+-------+
| 1 | 唐三藏 | 221 |
| 2 | 孙悟空 | 242 |
| 3 | 猪悟能 | 276 |
| 4 | 曹孟德 | 233 |
| 6 | 孙权 | 221 |
+------+-----------+-------+
5 rows in set (0.00 sec)
#注意:虽然我们给chinese+math+english重命名为total了但是这是在我们查询完成后输出表结构时完成的
#而where判断是在查询过程中进行的此时重命名并没有完成,所以我们仍然只能使用chinese+math+english来代表总分
#语文成绩在60到80分之间
mysql> select id,name,chinese from exam where chinese between 60 and 80;
+------+-----------+---------+
| id | name | chinese |
+------+-----------+---------+
| 1 | 唐三藏 | 67 |
| 6 | 孙权 | 70 |
| 7 | 宋公明 | 75 |
+------+-----------+---------+
3 rows in set (0.00 sec)
#语文成绩在67,70,71,72,73中任意一个
mysql> select id,name,chinese from exam where chinese in (67,70,71,72,73);
+------+-----------+---------+
| id | name | chinese |
+------+-----------+---------+
| 1 | 唐三藏 | 67 |
| 6 | 孙权 | 70 |
+------+-----------+---------+
2 rows in set (0.00 sec)
#名字是孙某某,某某可以是零个字也可以是一个两个多个
mysql> select id,name from exam where name like '孙%';
+------+-----------+
| id | name |
+------+-----------+
| 2 | 孙悟空 |
| 6 | 孙权 |
+------+-----------+
2 rows in set (0.00 sec)
#名字是孙某,某只能是一个字
mysql> select id,name from exam where name like '孙_';
+------+--------+
| id | name |
+------+--------+
| 6 | 孙权 |
+------+--------+
1 row in set (0.00 sec)
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为TRUE,结果都是TRUE |
| NOT | 条件为TRUE,结果为FALSE |
#语文和英语成绩都大于80
mysql> select id,name,chinese,english from exam where chinese >80 and english > 80;
+------+-----------+---------+---------+
| id | name | chinese | english |
+------+-----------+---------+---------+
| 3 | 猪悟能 | 88 | 90 |
+------+-----------+---------+---------+
1 row in set (0.00 sec)
#语文或者英语成绩大于80
mysql> select id,name,chinese,english from exam where chinese >80 or english > 80;
+------+-----------+---------+---------+
| id | name | chinese | english |
+------+-----------+---------+---------+
| 2 | 孙悟空 | 87 | 77 |
| 3 | 猪悟能 | 88 | 90 |
| 4 | 曹孟德 | 82 | 67 |
+------+-----------+---------+---------+
3 rows in set (0.00 sec)
#语文成绩不大于80
mysql> select id,name,chinese,english from exam where not chinese >80 ;
+------+-----------+---------+---------+
| id | name | chinese | english |
+------+-----------+---------+---------+
| 1 | 唐三藏 | 67 | 56 |
| 5 | 刘⽞德 | 55 | 45 |
| 6 | 孙权 | 70 | 78 |
| 7 | 宋公明 | 75 | 30 |
+------+-----------+---------+---------+
4 rows in set (0.00 sec)
- [HAVING where_condition] #在完成读取后是否再进行条件判断
在where中我们提到过where是在查询过程中进行条件判断而having则是在查询完成后再进行条件判断,除了这方面不同例如运算符什么的都是相同的使用方式。
#总分超过200
#由于是在查询完成后进行判断所以having就可以使用列的别名来进行条件判断
mysql> select id,name,chinese+math+english total from exam having total > 200;
+------+-----------+-------+
| id | name | total |
+------+-----------+-------+
| 1 | 唐三藏 | 221 |
| 2 | 孙悟空 | 242 |
| 3 | 猪悟能 | 276 |
| 4 | 曹孟德 | 233 |
| 6 | 孙权 | 221 |
+------+-----------+-------+
5 rows in set (0.00 sec)
- [ORDER BY {col_name | expr } [ASC | DESC], … ] #是否进行排序
想要进行排序时我们需要指出你想要进行排序的列并且也可以选择是升序还是降序,其中ASC是升序,DESC是降序。MySQL默认是进行升序排序
#默认是升序
mysql> select * from exam order by chinese;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 5 | 刘⽞德 | 55 | 85 | 45 |
| 1 | 唐三藏 | 67 | 98 | 56 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)
#显式升序
mysql> select * from exam order by chinese asc;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 5 | 刘⽞德 | 55 | 85 | 45 |
| 1 | 唐三藏 | 67 | 98 | 56 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)
#降序
mysql> select * from exam order by chinese desc;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 3 | 猪悟能 | 88 | 98 | 90 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 7 | 宋公明 | 75 | 65 | 30 |
| 6 | 孙权 | 70 | 73 | 78 |
| 1 | 唐三藏 | 67 | 98 | 56 |
| 5 | 刘⽞德 | 55 | 85 | 45 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)
#总成绩降序
mysql> select id,name,chinese+math+english total from exam order by total desc;
+------+-----------+-------+
| id | name | total |
+------+-----------+-------+
| 3 | 猪悟能 | 276 |
| 2 | 孙悟空 | 242 |
| 4 | 曹孟德 | 233 |
| 1 | 唐三藏 | 221 |
| 6 | 孙权 | 221 |
| 5 | 刘⽞德 | 185 |
| 7 | 宋公明 | 170 |
+------+-----------+-------+
7 rows in set (0.00 sec)
#为什么这里我们又可以使用别名(给列重命名就是取别名)来进行排序了呢?
#这是因为排序是在查询之后完成的这时候别名也已经取好了自然可以使用了
- [LIMIT {[offset,] row_count | row_count OFFSET offset}] #限制返回记录数量
我们可以在查询完成后限制输出表的行数以及从哪行开始输出,直接上例子
#从0开始显式五行
mysql> select * from exam limit 5;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘⽞德 | 55 | 85 | 45 |
+------+-----------+---------+------+---------+
5 rows in set (0.00 sec)
#从2开始显示5行
#注意:表结构的行数是从0开始算的
mysql> select * from exam limit 2,5;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘⽞德 | 55 | 85 | 45 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
+------+-----------+---------+------+---------+
5 rows in set (0.00 sec)
#从5开始显示两行
mysql> select * from exam limit 2 offset 5;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
+------+-----------+---------+------+---------+
2 rows in set (0.00 sec)
- [GROUP BY {col_name | expr}, …] #是否进行分表
在日常中我们可能面临一些数据是可以根据某列划分成不同的组的,例如我们在工作中不同的部门学校中不同的班级都是这种情况。所以group by通常是被叫做分组但是大家还记得我之前说的MySQL中一切都是表所以我觉得分表更加好理解,大家可以将其理解成根据某列将一个大表划分成几个小表但是它还是个表。
mysql> select * from emp;
+----+-----------+--------+------------+
| id | name | role | salary |
+----+-----------+--------+------------+
| 1 | 马云 | 老板 | 1500000.00 |
| 2 | 马化腾 | 老板 | 1300000.00 |
| 3 | 张三 | 经理 | 13000.00 |
| 4 | 赵四 | 经理 | 11000.00 |
| 5 | 王五 | 员工 | 5000.00 |
| 6 | 田七 | 员工 | 6000.00 |
| 7 | 路人甲 | 保安 | 2000.00 |
| 8 | 路人乙 | 保安 | 2000.00 |
+----+-----------+--------+------------+
8 rows in set (0.00 sec)
#根据role来进行分表
mysql> select role from emp group by role;
+--------+
| role |
+--------+
| 老板 |
| 经理 |
| 员工 |
| 保安 |
+--------+
4 rows in set (0.00 sec)
#根据role分表后我们还可以通过聚合函数来对分表进行处理
mysql> select role,count(*) from emp group by role;
+--------+----------+
| role | count(*) |
+--------+----------+
| 老板 | 2 |
| 经理 | 2 |
| 员工 | 2 |
| 保安 | 2 |
+--------+----------+
4 rows in set (0.00 sec)
mysql> select role,max(salary),min(salary),avg(salary) from emp group by role;
+--------+-------------+-------------+----------------+
| role | max(salary) | min(salary) | avg(salary) |
+--------+-------------+-------------+----------------+
| 老板 | 1500000.00 | 1300000.00 | 1400000.000000 |
| 经理 | 13000.00 | 11000.00 | 12000.000000 |
| 员工 | 6000.00 | 5000.00 | 5500.000000 |
| 保安 | 2000.00 | 2000.00 | 2000.000000 |
+--------+-------------+-------------+----------------+
4 rows in set (0.00 sec)
2.3Update更新
UPDATE
[LOW_PRIORITY] #是否将updata设为低优先级操作
[IGNORE] #是否忽略遇到不可重复键时的错误
table_reference #表的名称
SET assignment [, assignment] ... #更新的内容
[WHERE where_condition] #是否进行条件判断
[ORDER BY ...] #是否进行排序
[LIMIT row_count] #是否控制输出的内容
我们先举一些简单的例子来让大家知道怎么使用updata再讲解其中的比较重要的可选项。
mysql> select * from exam;
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘⽞德 | 55 | 85 | 45 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
+------+-----------+---------+------+---------+
7 rows in set (0.00 sec)
//给孙悟空的语文更新为30分
mysql> update exam set chinese = 30 where name = '孙悟空';
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from exam where name = '孙悟空';
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 2 | 孙悟空 | 30 | 78 | 77 |
+------+-----------+---------+------+---------+
1 row in set (0.00 sec)
//给曹孟德的英语更新为60数学更新为70
mysql> update exam set english = 60,math = 70 where name = '曹孟德';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from exam where name = '曹孟德';
+------+-----------+---------+------+---------+
| id | name | chinese | math | english |
+------+-----------+---------+------+---------+
| 4 | 曹孟德 | 82 | 70 | 60 |
+------+-----------+---------+------+---------+
1 row in set (0.00 sec)
mysql> select id,name,math,chinese+math+english total from exam order by chinese+math+english asc;
+------+-----------+------+-------+
| id | name | math | total |
+------+-----------+------+-------+
| 5 | 刘⽞德 | 115 | 215 |
| 1 | 唐三藏 | 98 | 221 |
| 6 | 孙权 | 73 | 221 |
| 7 | 宋公明 | 125 | 230 |
| 4 | 曹孟德 | 100 | 242 |
| 2 | 孙悟空 | 138 | 245 |
| 3 | 猪悟能 | 98 | 276 |
+------+-----------+------+-------+
7 rows in set (0.00 sec)
//给总分最低的三名数学各加30分
mysql> update exam set math =math + 30 where chinese+math+english is not null order by chinese+math+english asc limit 3;
Query OK, 3 rows affected (0.00 sec)
Rows matched: 3 Changed: 3 Warnings: 0
mysql> select id,name,math,chinese+math+english total from exam order by chinese+math+english asc;
+------+-----------+------+-------+
| id | name | math | total |
+------+-----------+------+-------+
| 7 | 宋公明 | 125 | 230 |
| 4 | 曹孟德 | 100 | 242 |
| 2 | 孙悟空 | 138 | 245 |
| 5 | 刘⽞德 | 145 | 245 |
| 1 | 唐三藏 | 128 | 251 |
| 6 | 孙权 | 103 | 251 |
| 3 | 猪悟能 | 98 | 276 |
+------+-----------+------+-------+
7 rows in set (0.00 sec)
要注意在使用update时更新数据不能使用math += 30这种语法只能使用math = math + 30。并且我们使用update的时候一般都是需要搭配where来进行条件判断的不然更新就会造成全列数据的改变所以要更新数据要慎重。
update的使用比较简单但是它的两个可选项是需要我们说一下的。
- [LOW_PRIORITY]
这个可选项是是否将update以低优先度的方式进行,想要理解这个概念我们就需要先知道MySQL中优先度是如何进行设计的。从我们C++的经验中有优先级一般我们都会涉及到锁的概念所以在MySQL中也不例外,当我们进行CURD时需要SQL先申请锁申请成功之后才能进行操作否则就需要等待。如果我们不设置锁让CURD随意进行那么在高并发的情况下MySQL写入和读取数据就会变得很混乱可能此时我读取的数据是这个但是实际并不是这样的因为被其他人修改了,所以我们需要锁来完成MySQL中语句的调度。
那么我们可以使用读写者模型来对表的增删查改进行分类,我们将select也就是读取作为读取者,而insert,update和delete都是写入者。MySQL中默认的调度是这样的:写入操作优先级大于读取操作,写入操作在同一时刻只能发生一次并且写入请求需要按时间来进行排队,读取操作在可以多个同时进行的。而low_priority则是MySQL提供的更改调度策略的字段,在update后添加low_priority后就会将其的优先度调整的比读取操作低这就会导致如果一直有读取操作在进行因为update的优先度低所以它必须等所有的读取操作完成后才能进行也就是将update阻塞住了。 - [IGNORE]
这个可选项的作用是防止遇到不可重复键时的错误,我们知道表中有些列是不可重复键例如主键,唯一键,正常当我们使用update更新表中的数据时我们更新的数据如果原来的数据是重复的就会发生报错此时我们在update后添加IGNORE就会避免这个报错的产生。
2.4Delete删除和Truncate截断
DELETE
FROM
tbl_name #表名
[WHERE where_condition] #是否进行条件判断
[ORDER BY ...] #是否进行排序
[LIMIT row_count] #是否进行输出内容的控制
删除我就不进行演示了只是大家要注意如果我们不加条件判断就会将整个表的数据删除了所以无论是更新还是删除大家都最好加上where以防出现无法挽回的情况。
TRUNCATE [TABLE] tbl_name
截断和删除不同截断只能对整个表进行它无法进行条件判断从而对某行来进行。不仅如此截断还有和删除不同的地方,我直接给大家上例子
mysql> select * from student;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 张三 | 17 |
| 2 | 李四 | 18 |
| 3 | 王五 | 18 |
| 4 | 赵六 | 16 |
| 5 | 田七 | 16 |
| 6 | 刘八 | 16 |
| 7 | 杨九 | 16 |
+----+--------+------+
7 rows in set (0.00 sec)
mysql> show create table student\G;
*************************** 1. row ***************************
Table: student
Create Table: CREATE TABLE `student` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` char(8) NOT NULL,
`age` int DEFAULT '16',
PRIMARY KEY (`id`),
CONSTRAINT `student_chk_1` CHECK ((`age` >= 16))
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
mysql> delete from student;
Query OK, 7 rows affected (0.01 sec)
mysql> show create table student\G;
*************************** 1. row ***************************
Table: student
Create Table: CREATE TABLE `student` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` char(8) NOT NULL,
`age` int DEFAULT '16',
PRIMARY KEY (`id`),
CONSTRAINT `student_chk_1` CHECK ((`age` >= 16))
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
mysql> insert into student (name) values('张三'),('李四');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from student;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 8 | 张三 | 16 |
| 9 | 李四 | 16 |
+----+--------+------+
2 rows in set (0.00 sec)
大家现在把关注点转移到表的创建语句中我们可以发现在使用delete删除表的数据后表的auto_increment也就是自增值是没有被清零的这点我们在上面讲自增约束的时候也提到过。现在我们去看看truncate的情况。
mysql> show create table student\G;
*************************** 1. row ***************************
Table: student
Create Table: CREATE TABLE `student` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` char(8) NOT NULL,
`age` int DEFAULT '16',
PRIMARY KEY (`id`),
CONSTRAINT `student_chk_1` CHECK ((`age` >= 16))
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
ERROR:
No query specified
mysql> select * from student;
Empty set (0.01 sec)
mysql> insert into student (name) values('张三'),('李四');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from student;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 8 | 张三 | 16 |
| 9 | 李四 | 16 |
+----+--------+------+
2 rows in set (0.00 sec)
mysql> truncate table student;
Query OK, 0 rows affected (0.02 sec)
mysql> select * from student;
Empty set (0.00 sec)
mysql> show create table student\G;
*************************** 1. row ***************************
Table: student
Create Table: CREATE TABLE `student` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` char(8) NOT NULL,
`age` int DEFAULT '16',
PRIMARY KEY (`id`),
CONSTRAINT `student_chk_1` CHECK ((`age` >= 16))
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
mysql> insert into student (name) values('张三'),('李四');
Query OK, 2 rows affected (0.00 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from student;
+----+--------+------+
| id | name | age |
+----+--------+------+
| 1 | 张三 | 16 |
| 2 | 李四 | 16 |
+----+--------+------+
2 rows in set (0.00 sec)
大家可以发现在我们截断了表后不光表的数据被清空了表的自增值一样被清空了变成从零开始了。并且TRUNCATE命令通常比DELETE命令更快,因为它不记录单个行的删除操作。DELETE命令会为表中的每一行生成一个删除操作,而TRUNCATE命令则一次性删除表中的所有数据,因此执行速度更快。