🌐 编程基础第一期《9-30》–使用python中的第三方模块requests,和三个内置模块(re、json、pprint),实现百度地图的近15天天气信息抓取
记得安装
pip install requests
📑 项目介绍
网络爬虫是Python最受欢迎的应用场景之一,通过爬虫技术,我们可以自动获取互联网上的各种数据资源。本文将带您实现一个简易爬虫,抓取百度地图的15天天气预报数据,这是一个非常实用的入门级爬虫项目。
🔍 爬虫实现思路
爬虫开发的核心步骤通常包括:网页分析、构造请求、数据提取和数据处理。下面我们将按照这个流程来实现我们的天气数据爬虫。
1. 网页结构分析
首先,我们需要分析目标网页的结构,找出我们需要的数据在哪里。
步骤一:访问目标页面

步骤二:查看页面内容
步骤三:打开开发者工具
进入浏览器控制台,可以按F12,或者鼠标右键 —》检查
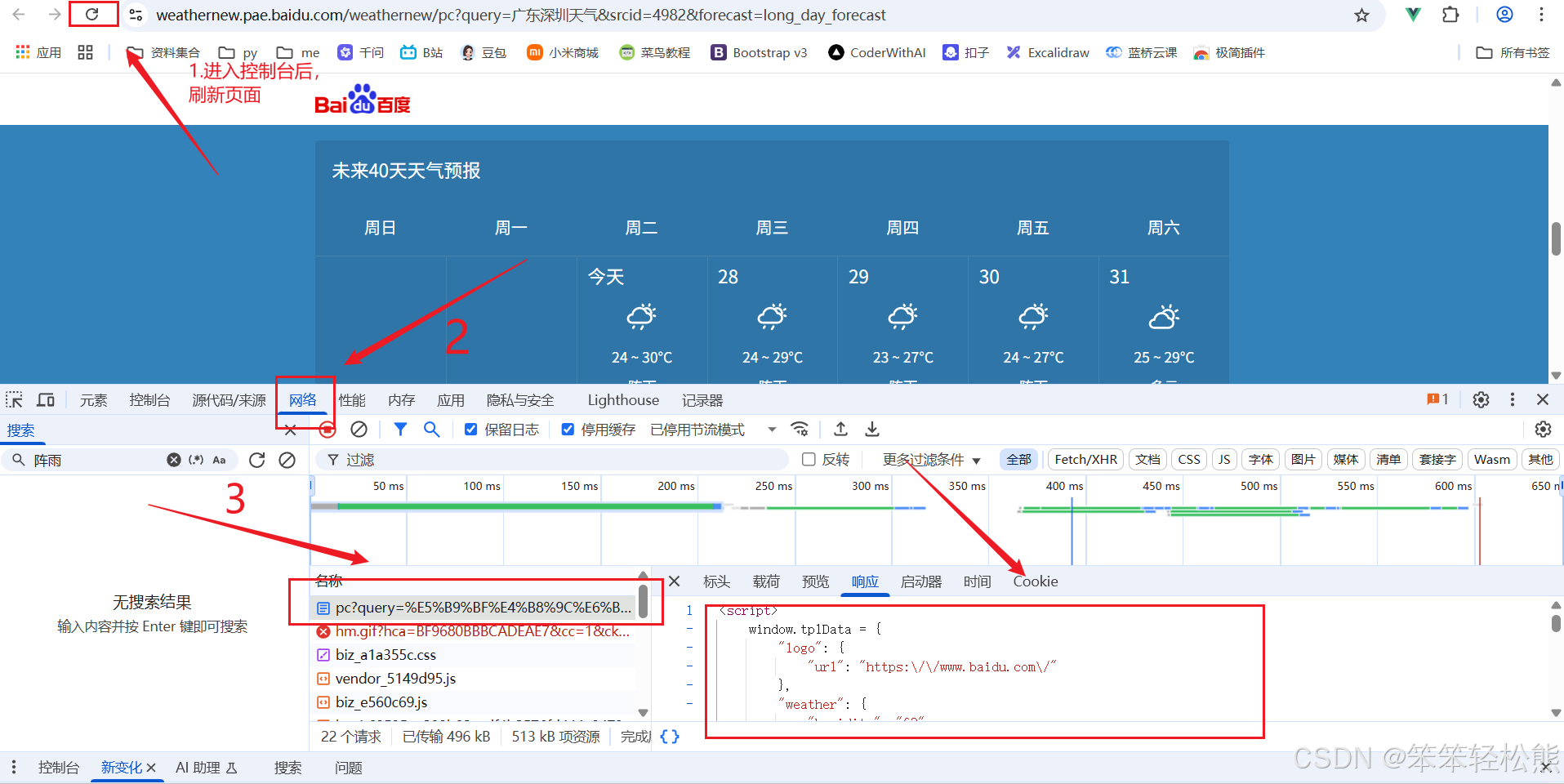
步骤四:定位数据元素
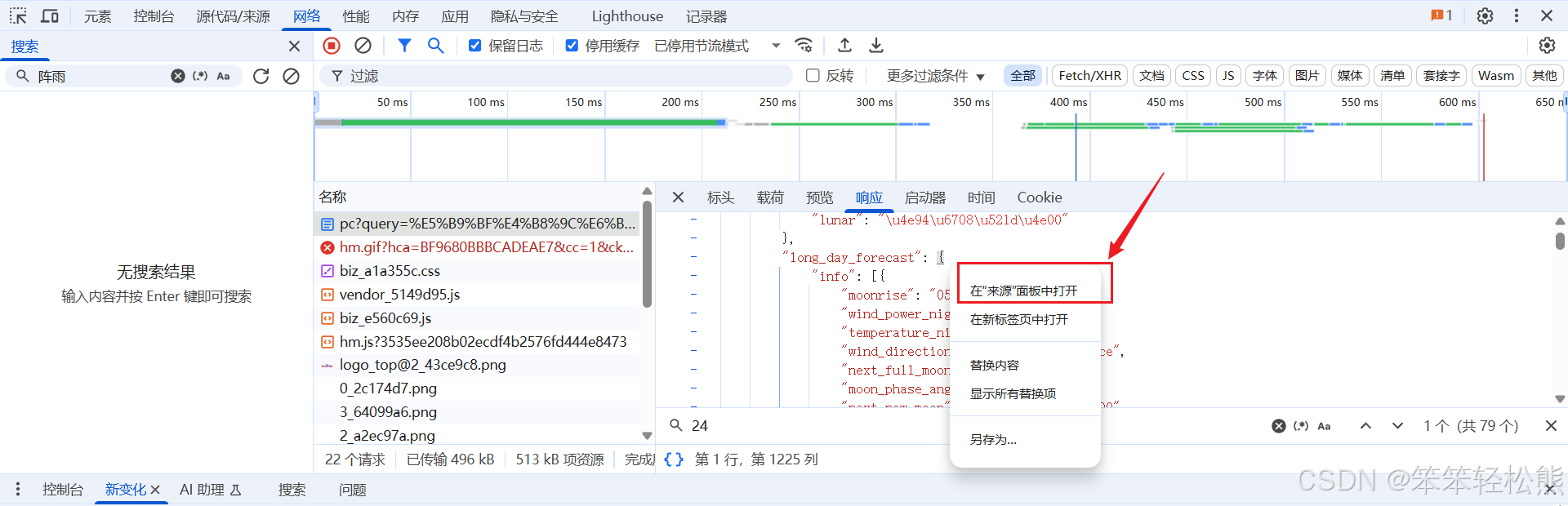
这个案例是需要获取天气的【日期、温度、天气】,这三个字段
如果是直接搜索相应的数据的话,是搜不到的,而且有点乱【Ctrl+F:搜索】,所以就用最笨的方法查看数据了,博主也是很快定位到了数据【15_day_forecast】
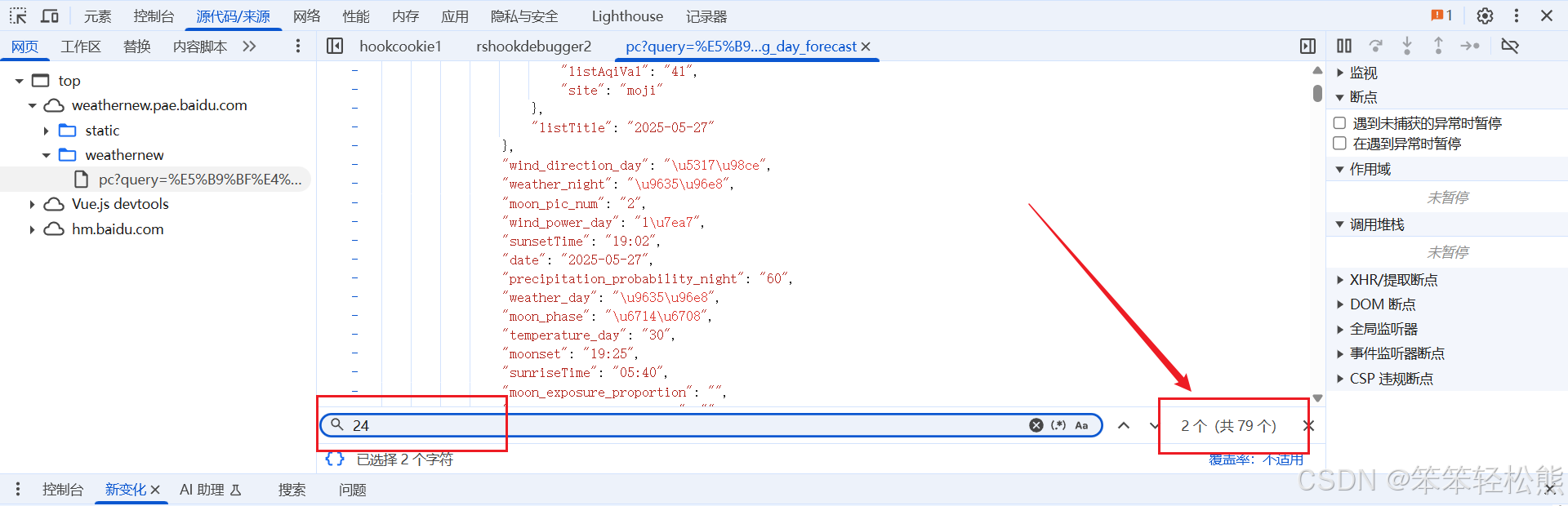
通过分析,我们发现天气数据是通过JavaScript动态加载的,数据存储在window.tplData变量中,具体是在15_day_forecast对象里。这意味着我们需要使用正则表达式从页面源码中提取这部分数据。
2. 获取请求参数
为了模拟浏览器发送请求,我们需要获取完整的请求参数,包括headers、cookies等。
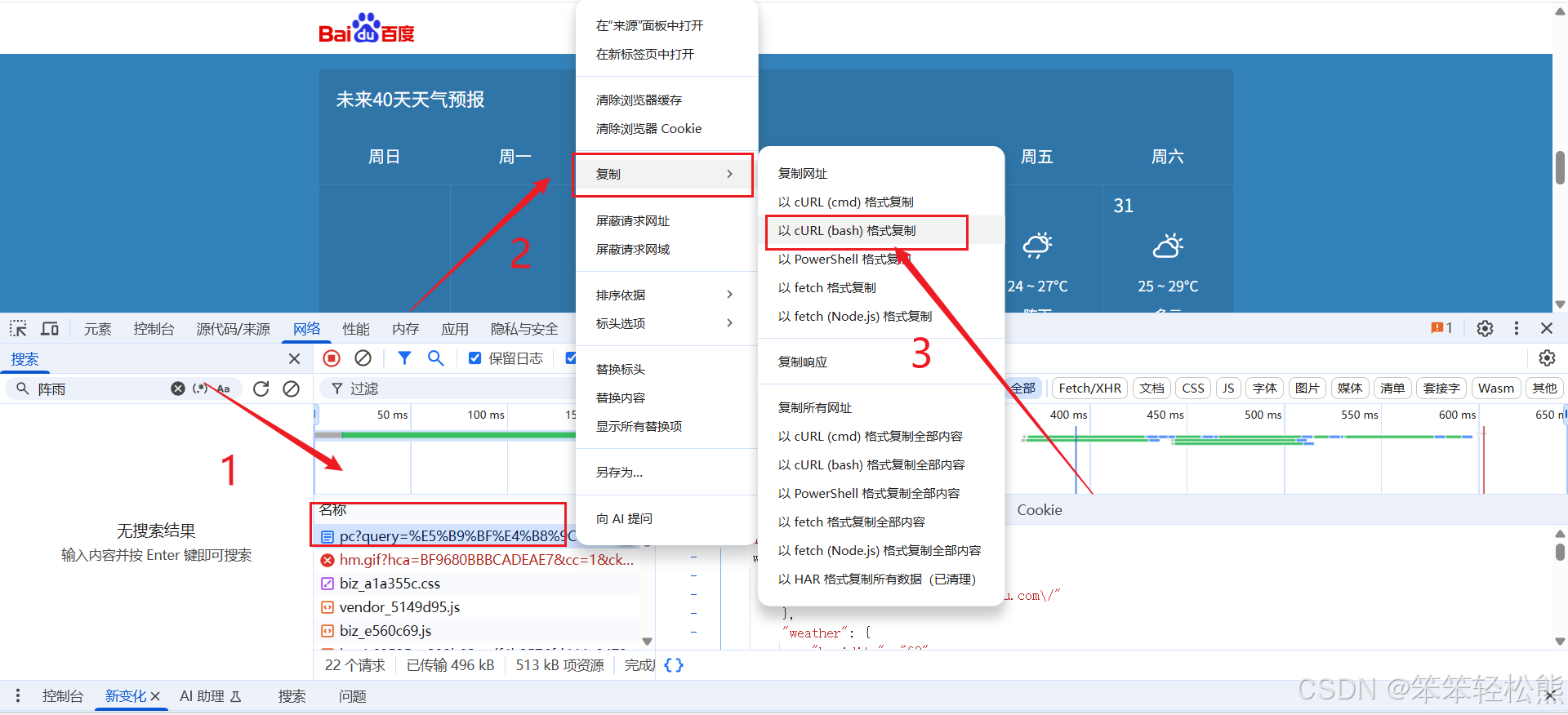
使用工具转换请求格式
我们可以使用curlconverter.com工具,将浏览器复制的curl命令转换为Python代码:
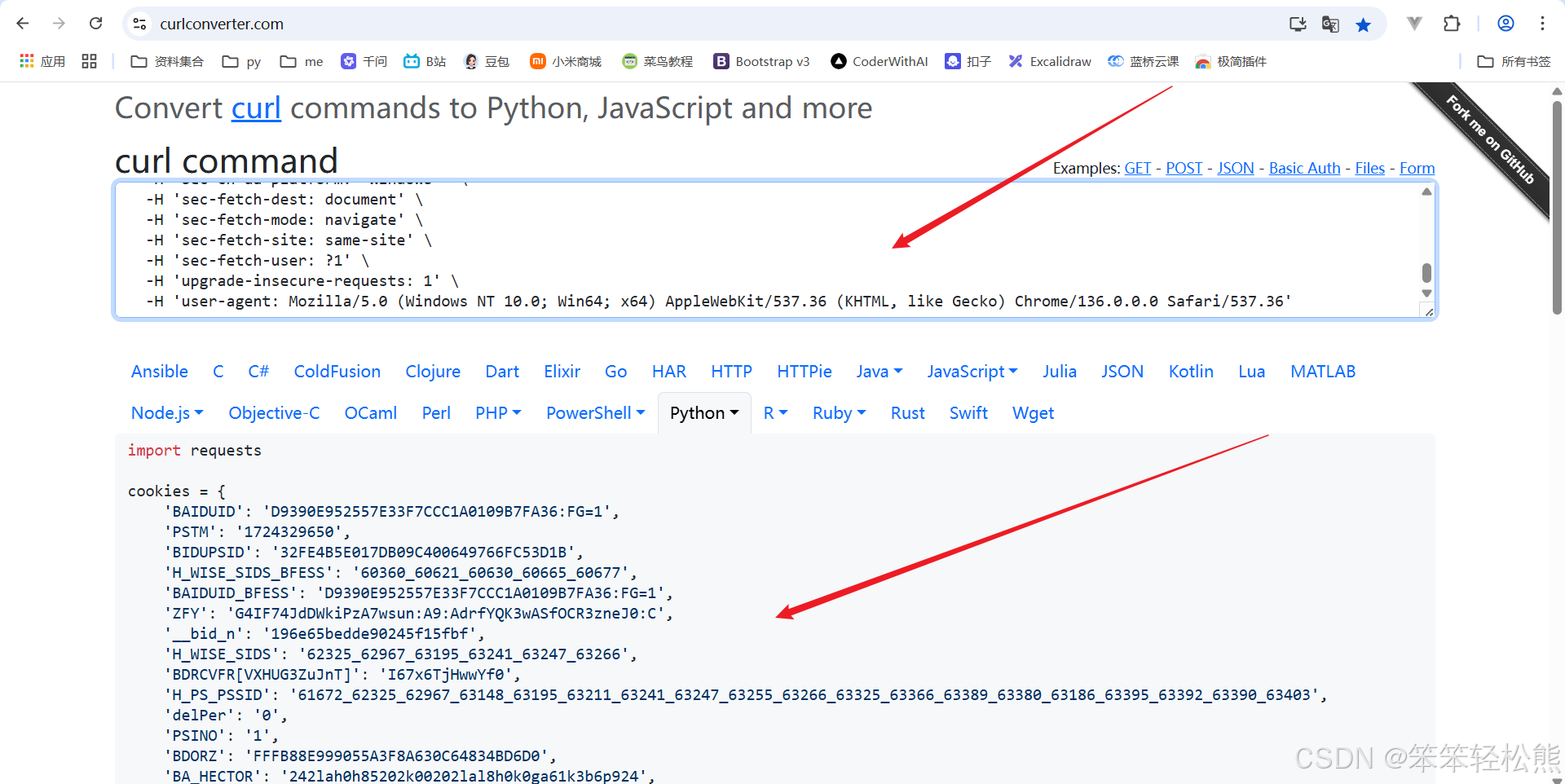
这个工具可以帮助我们快速生成请求所需的cookies、headers和params等参数,大大简化了爬虫开发过程。
3. 代码实现
下面是完整的Python爬虫代码实现:
import requests
import re
import json
from pprint import pprint
cookies = {
'BAIDUID': 'D9390E952557E33F7CCC1A0109B7FA36:FG=1',
'PSTM': '1724329650',
'BIDUPSID': '32FE4B5E017DB09C400649766FC53D1B',
'H_WISE_SIDS_BFESS': '60360_60621_60630_60665_60677',
'BAIDUID_BFESS': 'D9390E952557E33F7CCC1A0109B7FA36:FG=1',
'ZFY': 'G4IF74JdDWkiPzA7wsun:A9:AdrfYQK3wASfOCR3zneJ0:C',
'__bid_n': '196e65bedde90245f15fbf',
'H_WISE_SIDS': '62325_62967_63195_63241_63247_63266',
'BDRCVFR[VXHUG3ZuJnT]': 'I67x6TjHwwYf0',
'H_PS_PSSID': '61672_62325_62967_63148_63195_63211_63241_63247_63255_63266_63325_63366_63389_63380_63186_63395_63392_63390_63403',
'delPer': '0',
'PSINO': '1',
'BDORZ': 'FFFB88E999055A3F8A630C64834BD6D0',
'BA_HECTOR': '242lah0h85202k00202lal8h0k0ga61k3b6p924',
'Hm_lvt_3535ee208b02ecdf4b2576fd444e8473': '1748343601',
'Hm_lpvt_3535ee208b02ecdf4b2576fd444e8473': '1748343601',
'HMACCOUNT': 'BF9680BBBCADEAE7',
}
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'priority': 'u=0, i',
'referer': 'https://www.baidu.com/link?url=ajB3uWQlmNXyVidQRV-1nepXkS-ZUJDTJP3_HkueruWRBti13-iGBZJC1qMnR8pVgkLXHUxRWG8iv9tlJZFuVD0UqvTN1KpXcH5Sjltgq93cArc4Ocpl5irtWM2zRTYi0nVOHUeSWeV3ArpliNJvgErF2AaOpuWN6Jzb_yPJd3_DDH4uDBSFAENIXFV98SgaWmQyD7eE7wSJtPaZK-Y_5a&wd=&eqid=e24cffc50001782a0000000368359b29',
'sec-ch-ua': '"Chromium";v="136", "Google Chrome";v="136", "Not.A/Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-site',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36',
# 'cookie': 'BAIDUID=D9390E952557E33F7CCC1A0109B7FA36:FG=1; PSTM=1724329650; BIDUPSID=32FE4B5E017DB09C400649766FC53D1B; H_WISE_SIDS_BFESS=60360_60621_60630_60665_60677; BAIDUID_BFESS=D9390E952557E33F7CCC1A0109B7FA36:FG=1; ZFY=G4IF74JdDWkiPzA7wsun:A9:AdrfYQK3wASfOCR3zneJ0:C; __bid_n=196e65bedde90245f15fbf; H_WISE_SIDS=62325_62967_63195_63241_63247_63266; BDRCVFR[VXHUG3ZuJnT]=I67x6TjHwwYf0; H_PS_PSSID=61672_62325_62967_63148_63195_63211_63241_63247_63255_63266_63325_63366_63389_63380_63186_63395_63392_63390_63403; delPer=0; PSINO=1; BDORZ=FFFB88E999055A3F8A630C64834BD6D0; BA_HECTOR=242lah0h85202k00202lal8h0k0ga61k3b6p924; Hm_lvt_3535ee208b02ecdf4b2576fd444e8473=1748343601; Hm_lpvt_3535ee208b02ecdf4b2576fd444e8473=1748343601; HMACCOUNT=BF9680BBBCADEAE7',
}
params = {
'query': '广东深圳天气',
'srcid': '4982',
'forecast': 'long_day_forecast',
}
response = requests.get('https://weathernew.pae.baidu.com/weathernew/pc', params=params, cookies=cookies,
headers=headers)
# 获取天气数据
tplData = re.findall(r'window.tplData = (.*?);', response.text)[0]
# 这个数据是`str`类型,所以需要转换成json数据类型,然后再获取数据
tpl_15_day_forecast = json.loads(tplData)['15_day_forecast']['info']
# 定义一个空列表
recently_data = []
for tpl in tpl_15_day_forecast:
date = tpl['date']
temperature = tpl['temperature_night'] + ' ~ ' + tpl['temperature_day'] + '°C'
weather = tpl['weather_night']
recently_data.append({"date": date, "temperature": temperature, "weather": weather})
# 整齐输出
pprint(recently_data)
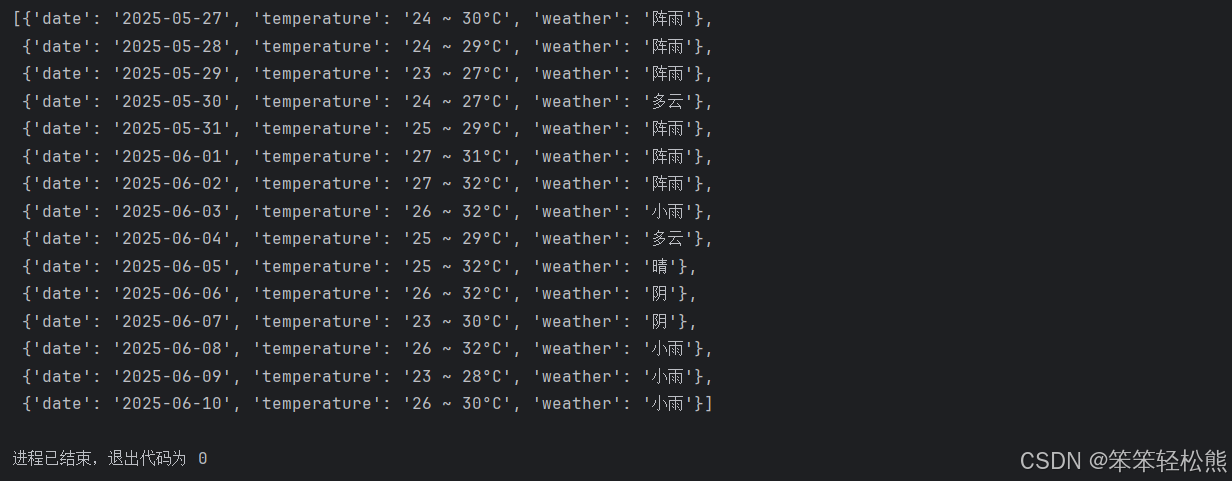
4. 运行效果
执行上述代码后,我们可以得到格式化的15天天气预报数据:
🔎 代码解析与知识点
这个简单的爬虫项目涵盖了多个Python爬虫开发的关键知识点,下面我们来详细分析:
1. HTTP请求与网络通信
- requests模块应用:使用Python最流行的HTTP客户端库发送GET请求
- 请求参数构造:通过params、cookies和headers参数模拟浏览器行为
- 防反爬策略:通过设置User-Agent、Referer等头信息,避免被目标网站识别为爬虫
# 发送HTTP GET请求示例
response = requests.get('https://weathernew.pae.baidu.com/weathernew/pc',
params=params,
cookies=cookies,
headers=headers)
2. 正则表达式数据提取
- re模块应用:使用Python内置的正则表达式模块提取特定模式的文本
- 贪婪与非贪婪匹配:使用
.*?进行非贪婪匹配,精确定位目标数据 - 捕获组:使用括号
()创建捕获组,提取匹配的内容
# 正则表达式提取示例
tplData = re.findall(r'window.tplData = (.*?);', response.text)[0]
3. JSON数据处理
- json模块应用:使用Python内置的JSON模块解析字符串为Python对象
- 数据序列化与反序列化:将字符串转换为Python对象(反序列化)
- 复杂数据结构访问:通过键名访问嵌套的JSON数据
# JSON解析示例
tpl_15_day_forecast = json.loads(tplData)['15_day_forecast']['info']
4. 数据结构与处理
- 列表操作:创建空列表并使用append方法添加元素
- 字典操作:创建包含多个键值对的字典对象
- 循环遍历:使用for循环遍历列表中的每个元素
- 字符串拼接:使用
+运算符连接多个字符串
# 数据处理示例
recently_data = []
for tpl in tpl_15_day_forecast:
date = tpl['date']
temperature = tpl['temperature_night'] + ' ~ ' + tpl['temperature_day'] + '°C'
weather = tpl['weather_night']
recently_data.append({"date": date, "temperature": temperature, "weather": weather})
5. 格式化输出
- pprint模块应用:使用Python的美化打印模块,以更易读的方式显示复杂数据结构
- 数据可视化:将提取的数据以结构化、易读的方式展示
# 格式化输出示例
pprint(recently_data)
📚 学习要点总结
- 网络爬虫基础:HTTP请求、响应处理、模拟浏览器行为
- 数据提取技术:正则表达式、JSON解析
- Python模块应用:requests、re、json、pprint
- 网页分析方法:使用开发者工具定位数据元素
- 数据处理技巧:列表、字典操作,数据结构转换
- 爬虫伦理与合规:遵守网站robots.txt规则,合理控制请求频率
通过这个项目,您可以掌握Python爬虫开发的基本流程和技术要点,为进一步学习更复杂的爬虫项目打下坚实基础。
今日分享语录
与其攀比他人,不如攀比昨天的自己