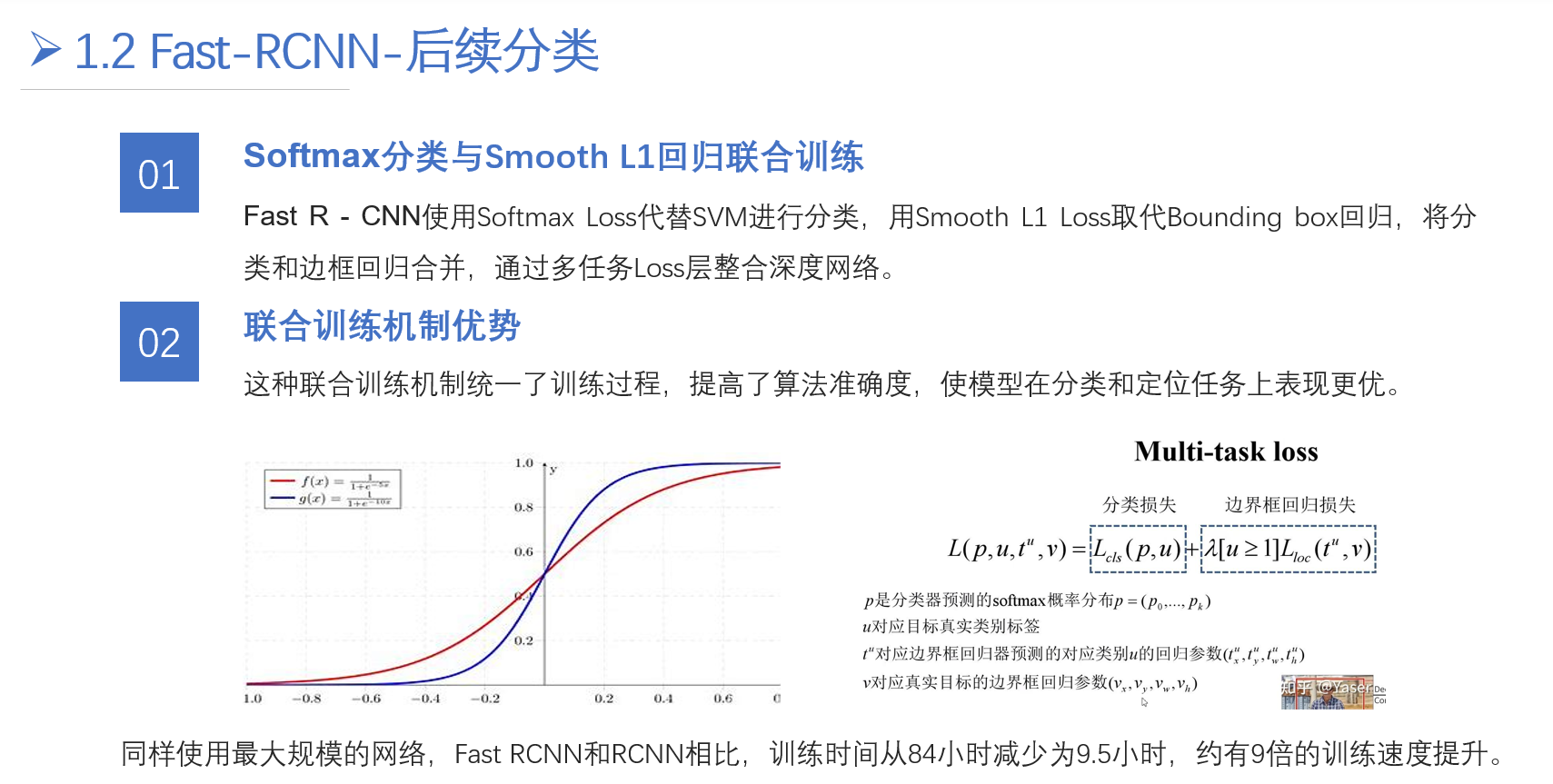
模式识别期末展示大作业,做个记录,希望大家喜欢。
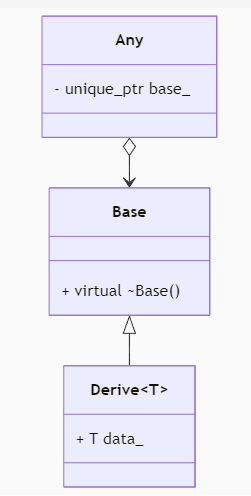
R-CNN


Fast R-CNN
R-FCN
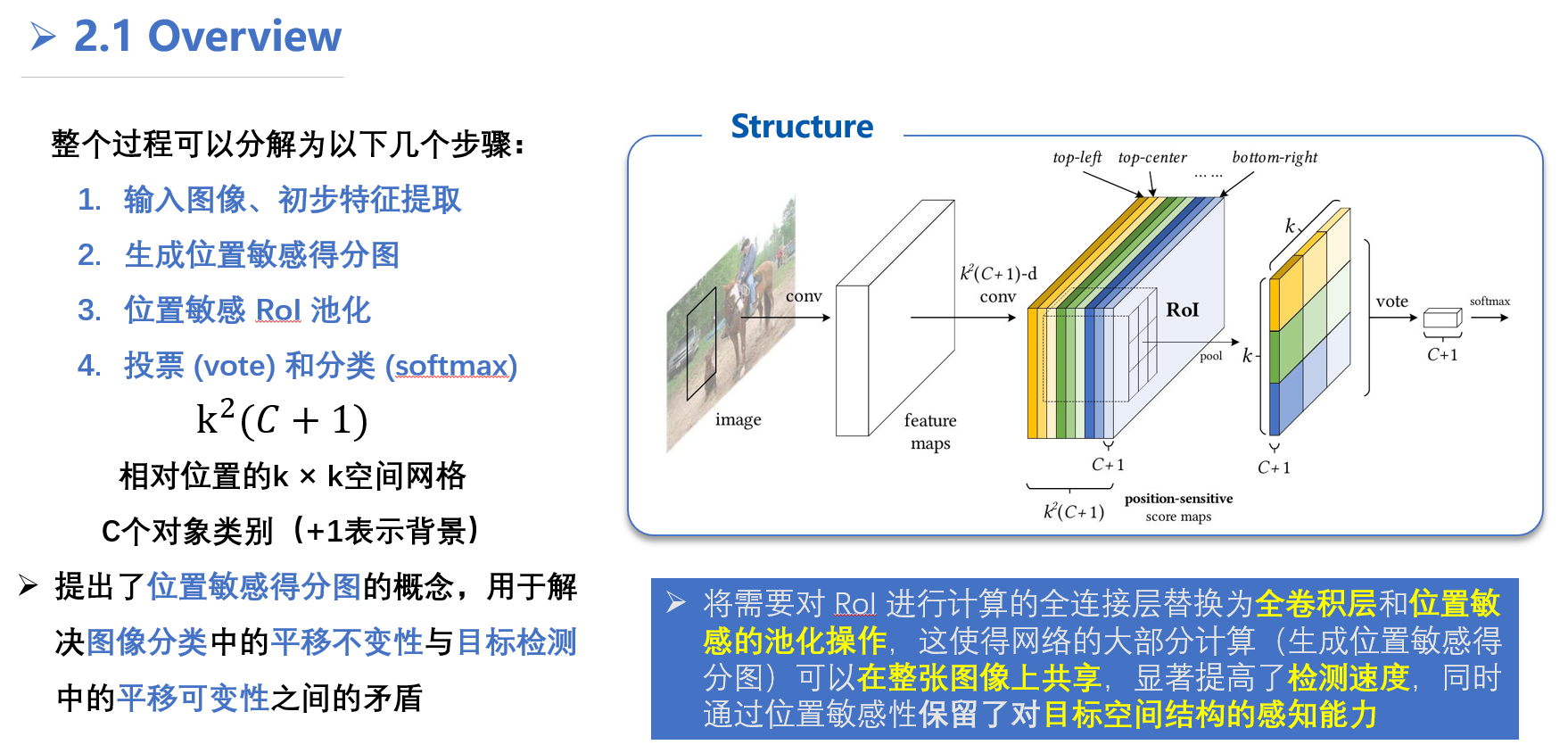
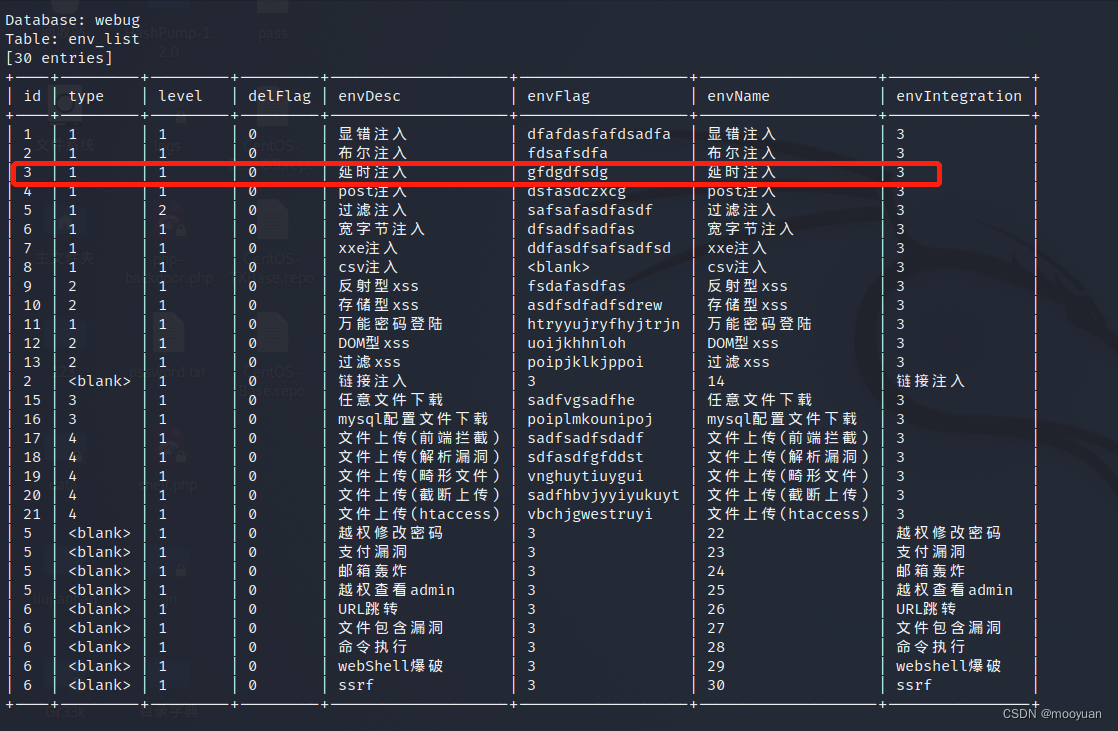
整个过程可以分解为以下几个步骤:
- 输入图像 (image) 和初步特征提取 (conv, feature maps):
- 首先,输入一张原始图像,经过一系列卷积层(没有全连接层)输出一组特征图 (feature maps),这些特征图包含了图像中丰富的视觉信息。
- 生成位置敏感得分图 (k^2(C+1)-d conv, position-sensitive score maps):
- 在标准的全卷积网络之后,R-FCN 引入了一个特殊的卷积层。这个卷积层的输出通道数是 k^2×(C+1)。
- 这里的 k 是一个预设的参数,表示我们将把一个感兴趣区域 (RoI) 划分为一个 k×k 的网格。在图示中,k=3,所以网格大小是 3×3=9 个单元格 (bins)。
- C 是需要检测的对象类别数量,+1 表示包括背景类别。
- 这个特殊的卷积层输出的特征图被称为“位置敏感得分图” (position-sensitive score maps)。这组得分图总共有 k^2×(C+1) 个通道。
- 这些通道可以被理解为 k^2 个组,每组有 C+1 个通道。每个组对应于 RoI 网格中的一个特定空间位置(例如,左上角、中心、右下角等),而组内的每个通道则对应于一个类别(包括背景)。
- 例如,对于 k=3 和 C+1 个类别,总共有 9×(C+1) 个得分图。图示中展示了其中的一部分,并用不同颜色表示对应 RoI 中不同位置(如 top-left, top-center, bottom-right 等)。
- 位置敏感 RoI 池化 (RoI, pool):
- 接下来,对于从区域提议网络获得的每一个感兴趣区域 (RoI),我们对其进行位置敏感的 RoI 池化操作。
- 首先,将 RoI 划分为 k×k 个大小相同的空间单元格(bins)。
- 然后,对于 RoI 中的每一个单元格 (i,j)(其中 i,j∈{0,1,…,k−1}),我们只从位置敏感得分图中提取与该单元格对应的特定通道组进行池化。具体来说,对于 RoI 中的单元格 (i,j) 和类别 c,我们仅从那些对应于 RoI 中 (i,j) 位置的得分图通道中提取特征。例如,图示中 RoI 被划分为 3×3 网格,左上角的单元格只从对应“top-left”位置的得分图中池化。
- 最终,位置敏感 RoI 池化输出一个 k×k×(C+1) 维的特征张量。图示中将其表示为 k×k 个空间位置,每个位置有 C+1 个维度。
- 投票 (vote) 和分类 (softmax):
- 对于每一个类别 c,我们将 RoI 中所有 k×k 个单元格对应类别 c 的池化结果相加或求平均,得到一个最终的类别得分。
- 这个投票过程将 k×k×(C+1) 维的特征聚合成一个 C+1 维的向量 (C+1),其中每个元素代表该 RoI 属于对应类别的总得分。
- 最后,将这个 C+1 维的得分向量通过 Softmax 函数,得到 RoI 属于每一个类别的概率。 Softmax 函数将得分转换为介于 0 到 1 之间的概率分布,所有类别的概率之和为 1。
R-FCN 的核心优势在于,它将需要对 RoI 进行计算的全连接层替换为全卷积层和位置敏感的池化操作,这使得网络的大部分计算(生成位置敏感得分图)可以在整张图像上共享,显著提高了检测速度,同时通过位置敏感性保留了对目标空间结构的感知能力。
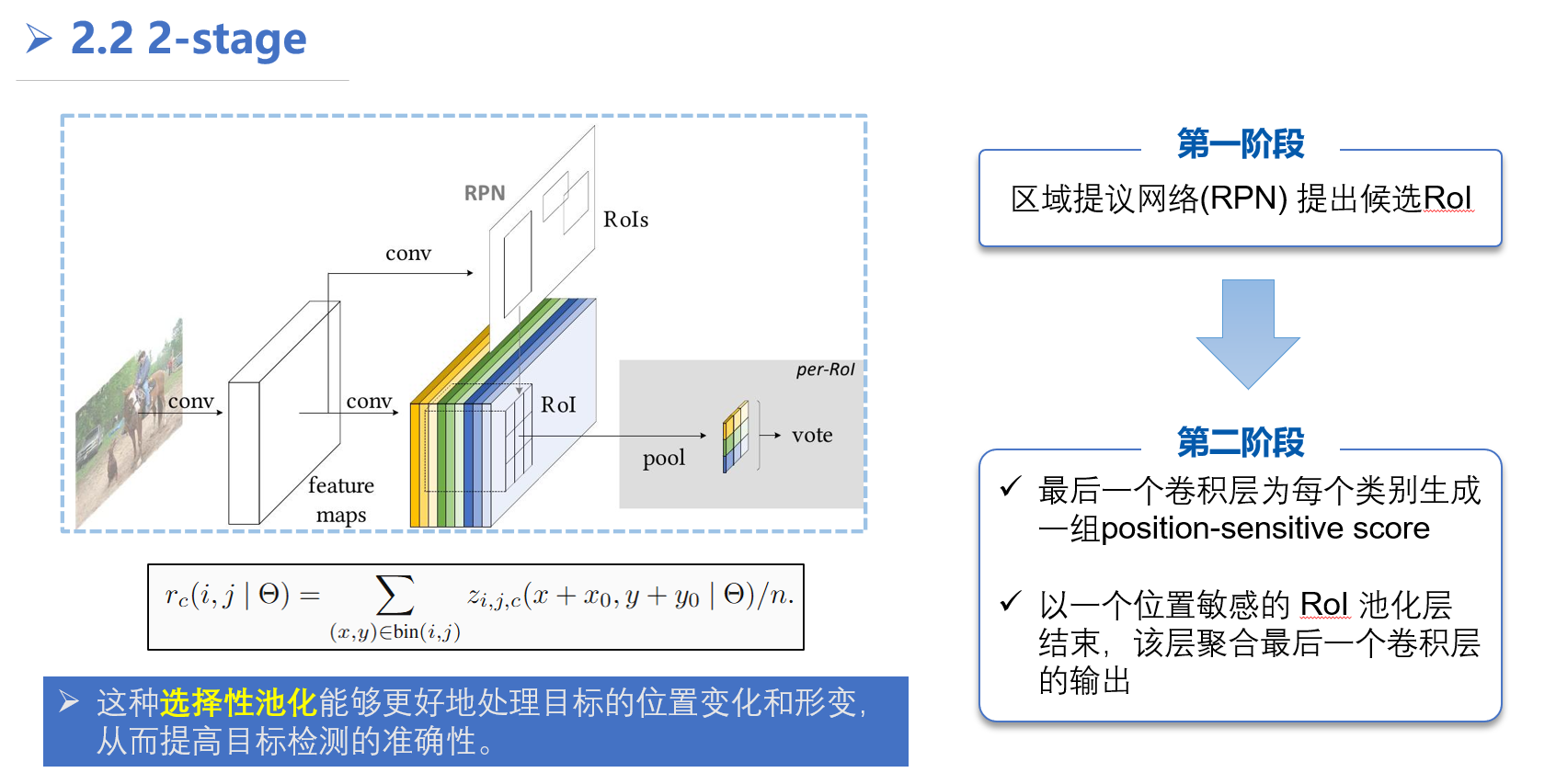
位置敏感RoI池化层的核心思想是区分目标的不同位置信息,这与之前的方法有所不同。具体来说,该层将RoI(Region of Interest,感兴趣区域)划分为 k × k 个bin(子区域),每个bin负责对目标特定位置的响应进行聚合。
选择性池化是指,对于每个bin,它只从 k × k 个score map(得分图)中选择一个特定的score map进行池化操作,而不是像传统RoI池化那样对所有score map进行池化。这里的每个score map对应于目标的一个特定相对位置(例如,目标的左上角、中心、右下角等)。通过这种方式,网络可以学习到每个bin应该关注哪个位置的信息,从而实现对不同位置信息的区分。
例如,如果 k = 3,那么就有 3 × 3 = 9 个bin和9个score map。左上角的bin可能只聚合第一个score map的响应,该score map负责检测目标的左上角;而中心bin可能只聚合第五个score map的响应,该score map负责检测目标的中心。通过这种选择性池化,位置敏感RoI池化层能够更好地处理目标的位置变化和形变,从而提高目标检测的准确性。

在两张图片中,可视化了当k × k = 3 × 3时,R-FCN学习到的位置敏感得分图。这些专门的图预计会在对象的特定相对位置被强烈激活。例如,“顶-中心-敏感”得分图在大致靠近对象顶部中心的位置表现出高分。如果候选框与真实对象精确重叠,则RoI中的大多数k^2个bin会被强烈激活,并且它们的投票会导致高分。相反,如果候选框未与真实对象正确重叠,则RoI中的某些k^2个bin不会被激活,并且投票得分较低。
训练
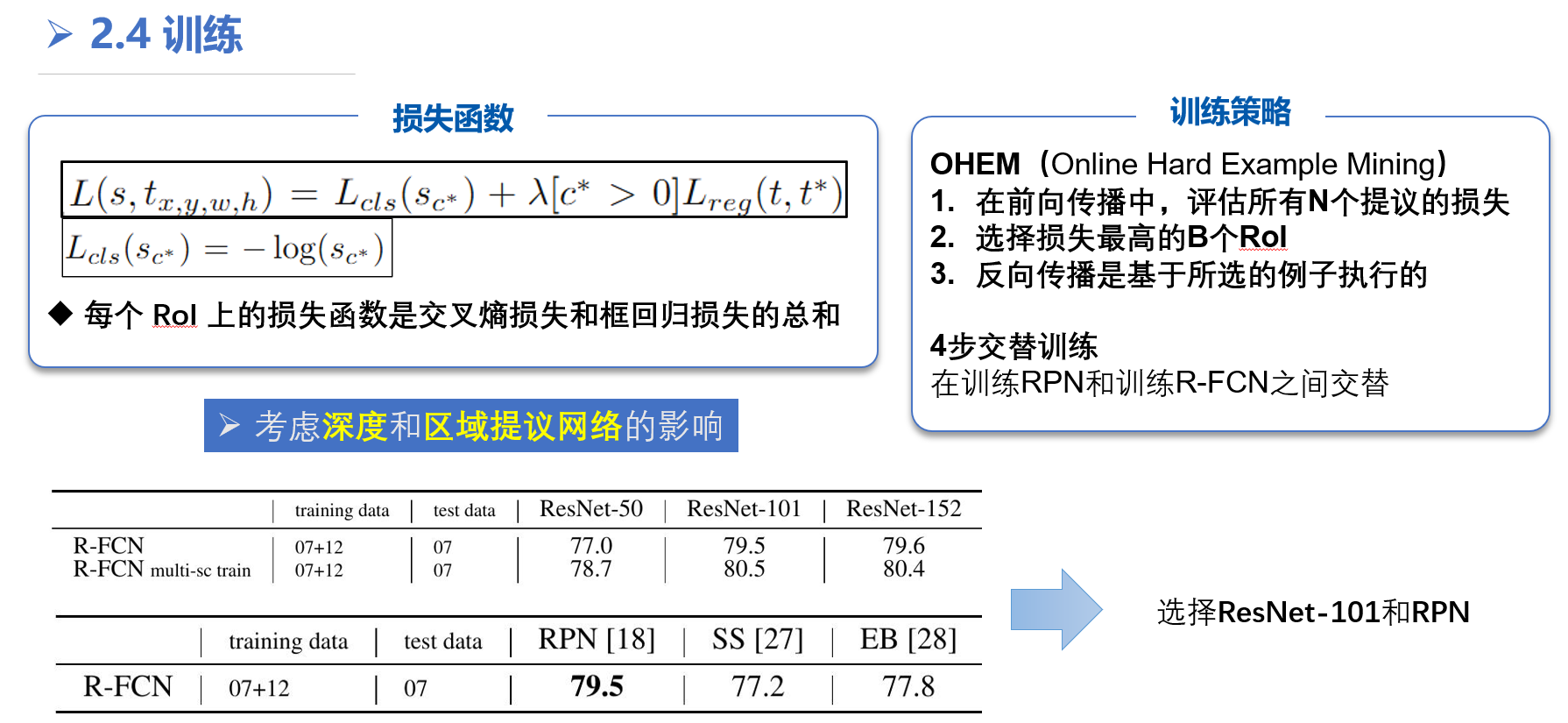
c∗ 是 RoI 的真实标签 (c∗ = 0 表示背景)。
[c∗ > 0] 是一个指示器,如果参数为真则等于 1,否则为 0
设置平衡权重 λ = 1
因为我们的每RoI计算可以忽略不计,所以前向时间几乎不受N的影响,这与中的OHEM Fast R-CNN相反,后者可能会使训练时间加倍。
为了使R-FCN与RPN共享特征
结果
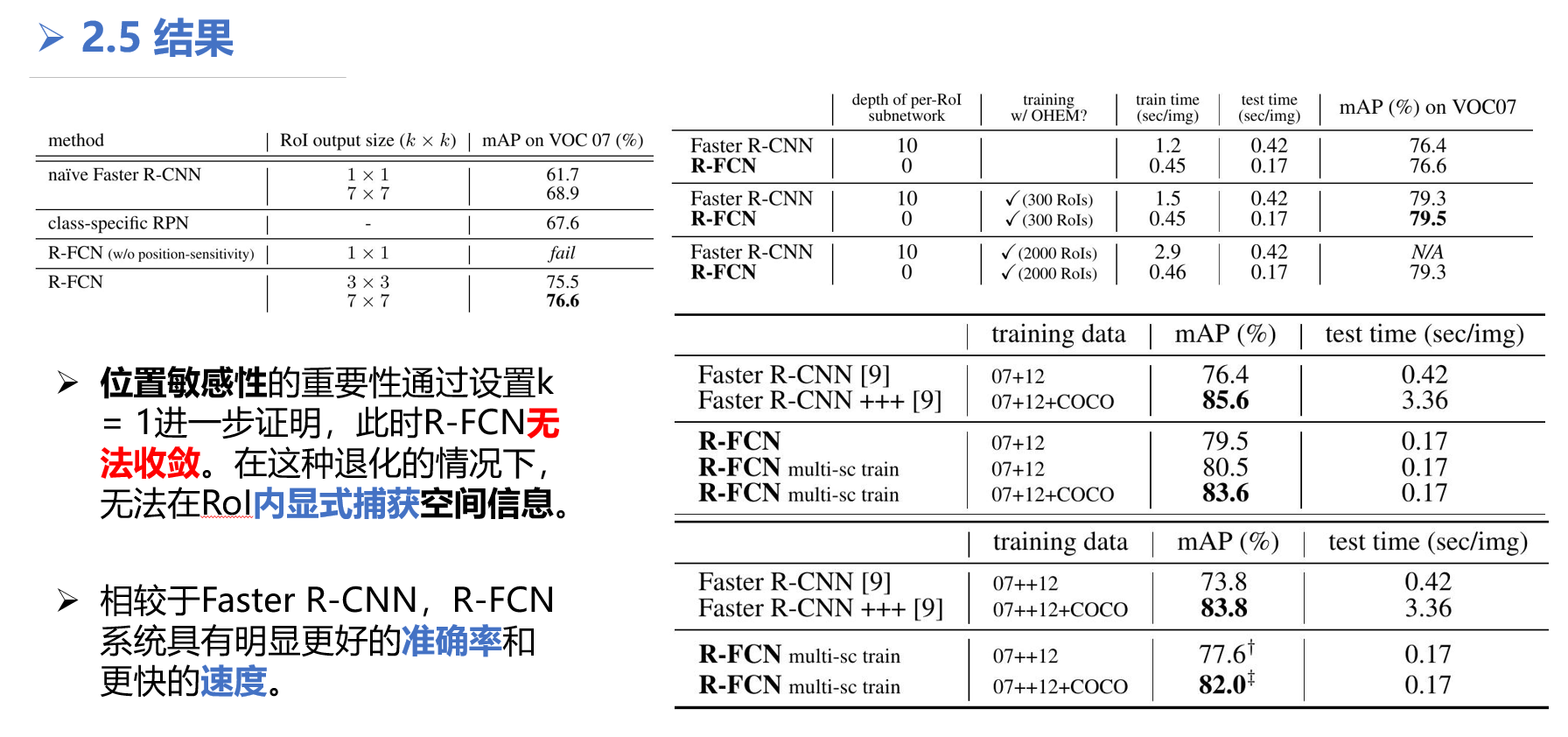
使用ResNet-101的Faster R-CNN和R-FCN之间的比较。时间评估在单个Nvidia K40 GPU上进行。使用OHEM时,在前向传播中计算每个图像N个RoI,并选择128个样本用于反向传播。按照[18],测试使用300个RoI。
使用 ResNet-101 在 PASCAL VOC 2007 测试集上的比较。“Faster R-CNN +++” [9] 使用迭代框回归、上下文和多尺度测试。
使用ResNet-101在PASCAL VOC 2012测试集上的比较。
“07++12” [6] denotes the union set of 07 trainval+test and 12 trainval.
总结
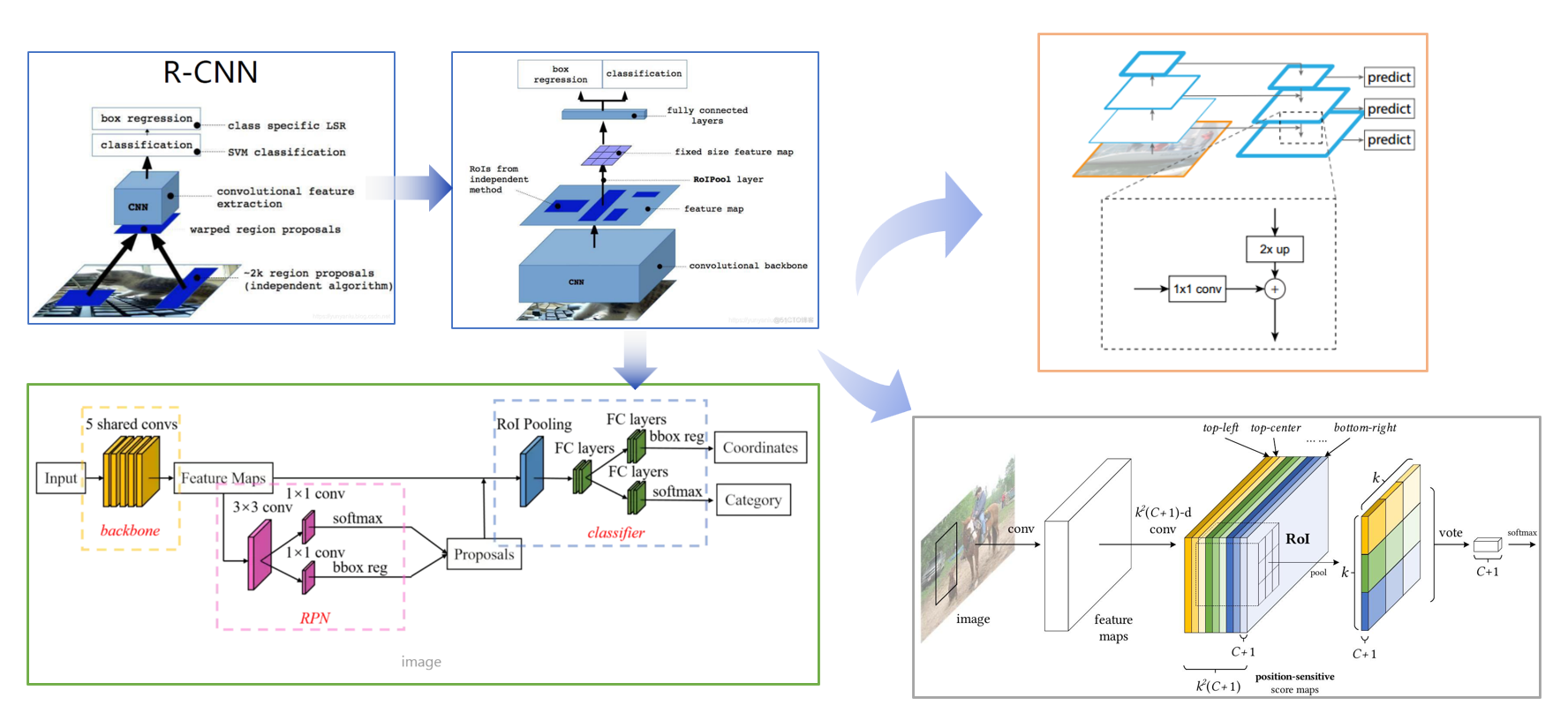
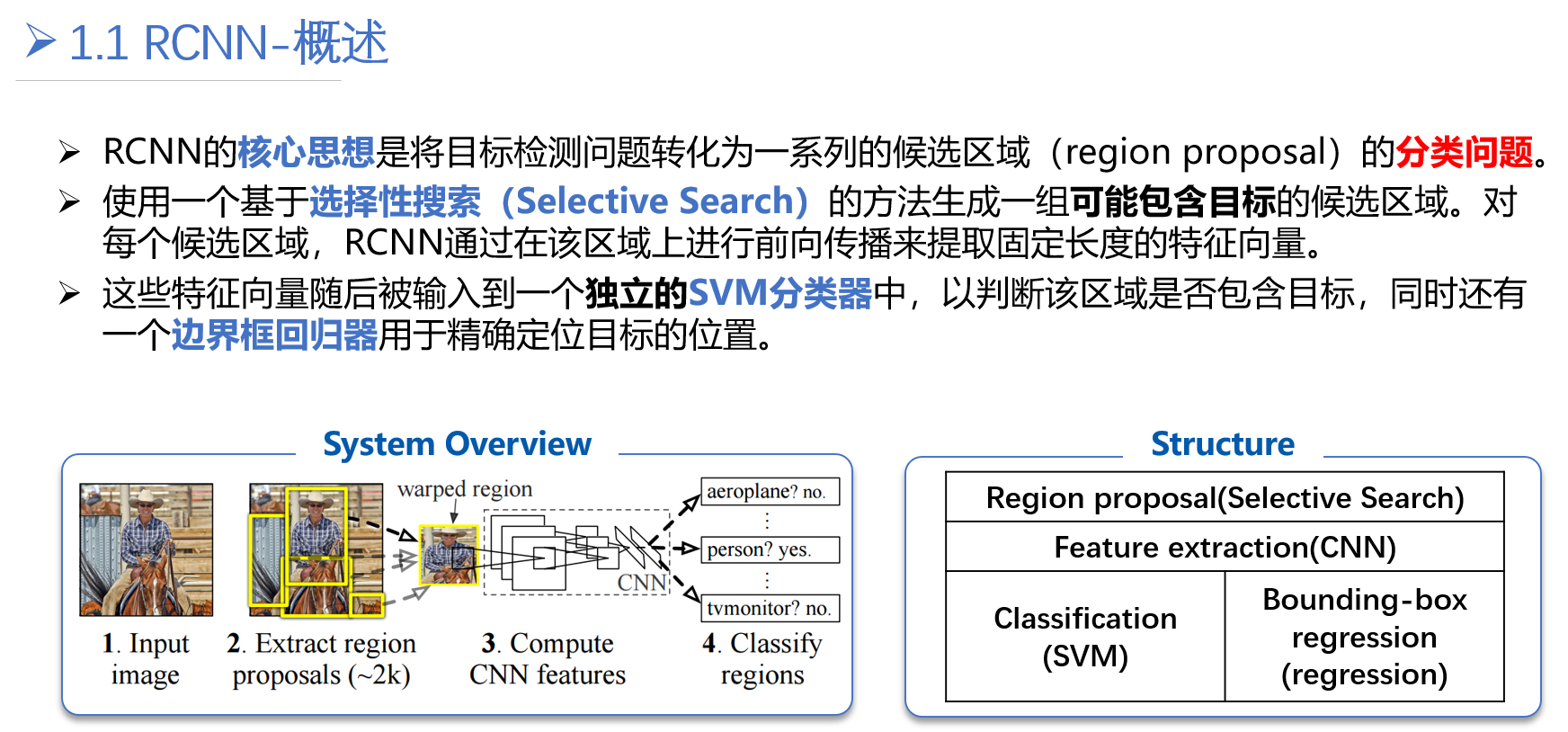
在 R - CNN出现之前,目标检测主要依赖传统计算机视觉方法,如滑动窗口等,效果不理想。R - CNN的出现是目标检测领域的一个重要突破。它的基本思想是先通过选择性搜索(Selective Search)算法生成大约2000个候选区域(Region Proposal),然后对每个候选区域进行特征提取,再通过 SVM(支持向量机)进行分类,同时使用回归模型来精修候选框的位置。
每个区域独立地进行特征提取和分类等操作,但这也导致了其计算效率较低,因为每个候选区域都要单独通过 CNN。
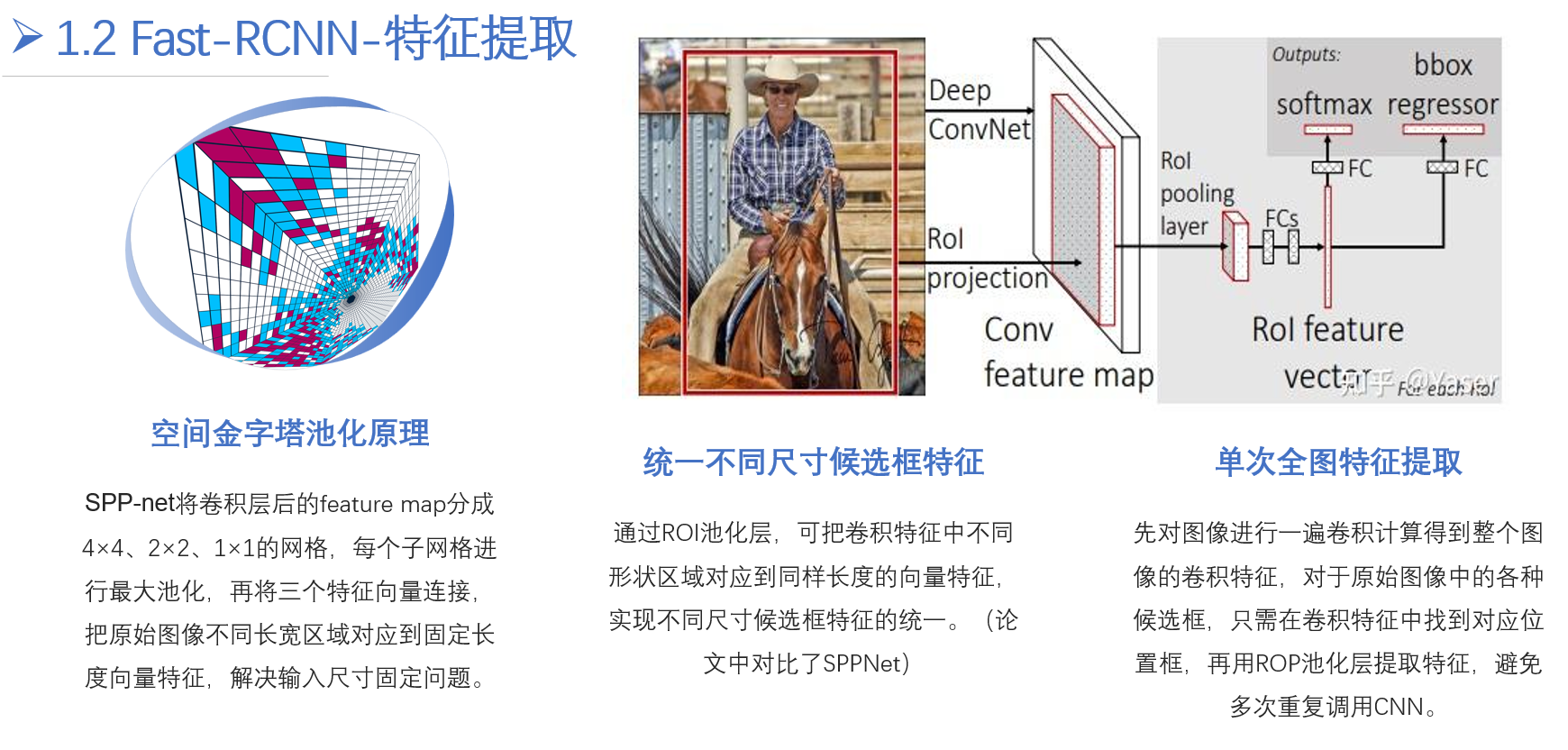
R - CNN的一个主要缺点是速度慢,因为它对每个候选区域都单独进行 CNN前向传播计算特征。Fast R - CNN为了解决这个问题,提出了一种更高效的方式。
它先将整个图像输入 CNN提取特征,得到一个特征映射(Feature Map)。然后,将候选区域映射到这个特征映射上,通过 ROIPool层(Region of Interest Pooling)来获取每个候选区域的固定大小的特征。接着,这些特征被送入全连接层进行分类和回归。这样就避免了对每个候选区域都单独进行 CNN计算,大大提高了速度。
虽然 Fast R - CNN提高了速度,但其仍依赖于外部的候选区域生成方法(如选择性搜索),这在一定程度上限制了速度和精度。Faster R - CNN的主要动机是将候选区域生成网络(RPN,Region Proposal Network)集成到整个检测网络中,实现端到端的训练和检测。
在目标检测任务中,目标的尺度变化较大。传统的 CNN会产生不同层次的特征,但这些特征在尺度适应性上存在不足。例如,浅层特征对小目标检测有帮助,但语义信息较弱;深层特征语义信息丰富,但对于小目标检测可能会丢失细节。FPN通过自下而上的路径(原始 CNN的特征提取过程)生成不同尺度的特征图,然后通过自上而下的路径(上采样等操作)和横向连接(将自上而下路径和自下而上路径的特征进行融合)构建特征金字塔。这样可以将高语义信息的深层特征和高分辨率的浅层特征结合起来,使得网络在不同尺度目标的检测上都有较好的性能。
Faster R - CNN虽然在速度和精度上有了很大的提升,但它仍然依赖于 ROI pooling层后的全连接层,这在一定程度上限制了其在不同尺度输入下的灵活性,且全连接层的参数较多。R - FCN摒弃了全连接层,采用全卷积网络的结构。它在特征映射上为每个位置生成位置敏感的分数图(Position - Sensitive Score Maps),然后通过 ROI pooling等操作来获取候选区域的特征。