上一篇![]() https://blog.csdn.net/Small_entreprene/article/details/148143494?fromshare=blogdetail&sharetype=blogdetail&sharerId=148143494&sharerefer=PC&sharesource=Small_entreprene&sharefrom=from_link
https://blog.csdn.net/Small_entreprene/article/details/148143494?fromshare=blogdetail&sharetype=blogdetail&sharerId=148143494&sharerefer=PC&sharesource=Small_entreprene&sharefrom=from_link

上文学习了传输层的协议之一UDP,接下来我们来好好学习一下传输层另外一个更加重要的协议 --- TCP协议:
TCP协议
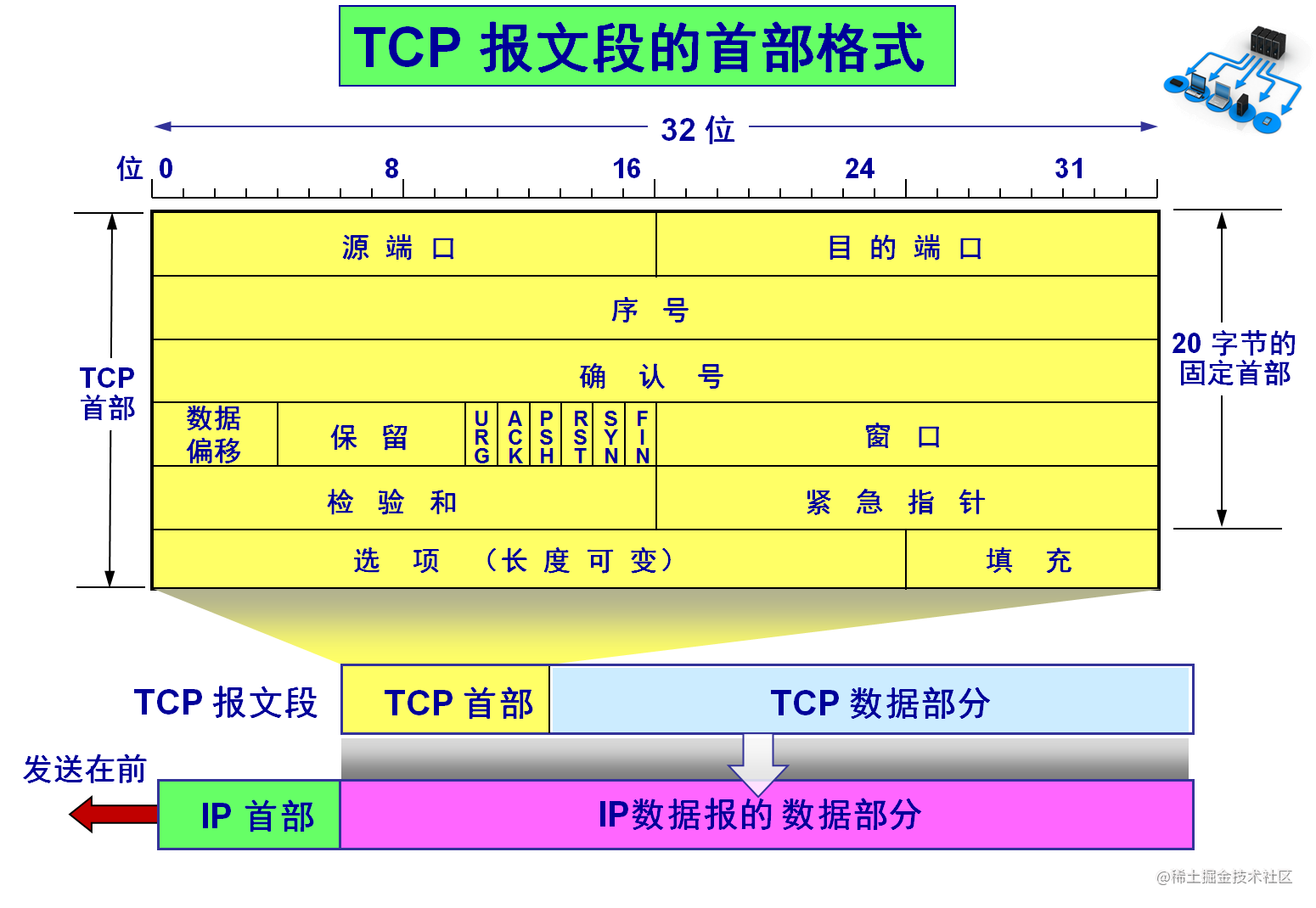
TCP协议段格式
tcphdr
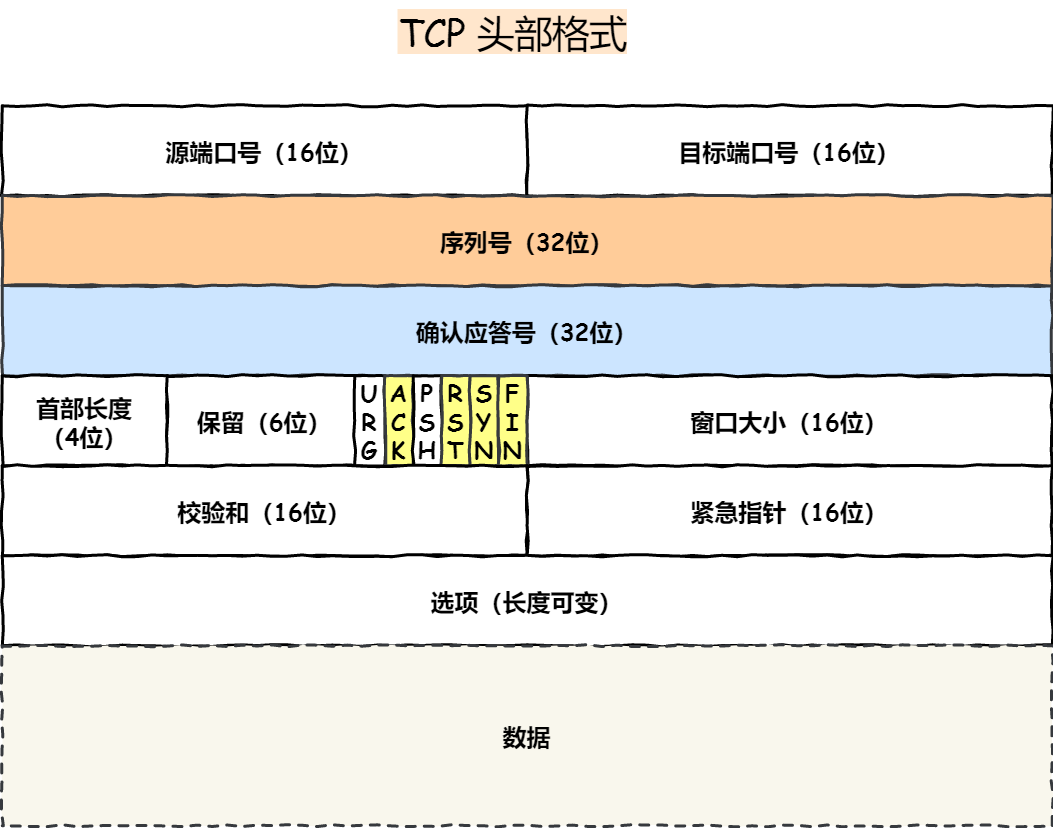
struct tcphdr {
__be16 source; // 16位源端口号
__be16 dest; // 16位目的端口号
__be32 seq; // 32位序列号
__be32 ack_seq; // 32位确认号
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u16 res1:4, // 保留位
doff:4, // TCP头长度,单位为4字节
fin:1, // FIN标志
syn:1, // SYN标志
rst:1, // RST标志
psh:1, // PSH标志
ack:1, // ACK标志
urg:1, // URG标志
ece:1, // ECE标志(用于拥塞控制)
cwr:1; // CWR标志(用于拥塞控制)
#elif defined(__BIG_ENDIAN_BITFIELD)
__u16 doff:4,
res1:4,
cwr:1,
ece:1,
urg:1,
ack:1,
psh:1,
rst:1,
syn:1,
fin:1;
#else
#error "Adjust your <asm/byteorder.h> defines"
#endif
__be16 window; // 16位滑动窗口大小
__sum16 check; // 16位校验和
__be16 urg_ptr; // 16位紧急指针
};标准问题
TCP是如何实现将报头和有效载荷进行分离的?
前提说明:TCP设置为面向字节流,主要是为了其可靠性这个TCP的特性!!!
TCP协议的标准的报头的长度是20个字节,也就是一般而言,TCP报头也是一个定长的报头!也就是将来来一个TCP报文,我们只需要进行data指针位置的加20个字节,就可以提取出来了。不过TCP协议当中还有一个选项字段,可以为0字节,也可以有字节,这个后面我们自会理解!所以一个TCP报头的完整长度是20个字节加上选项字段,这个选项字段正常是为0字节的。因为有不定长的选项字段存在,我们该如何保证报文的报头和有效载荷进行分离呢?所以在标准报头20字节当中,存在一个叫做数据偏移的字段,也叫做4位首部长度,就是4个比特位,当成无符号来算,就是【0000,1111】总共是【0,15】个数据范围,TCP协议规定【0,15】的数据范围的单位是4字节,也就是说TCP报头的大小是【0,15*4】>>>【0,60】字节,但是对于TCP来说,其报头的标准长度最少都是20个字节,所以TCP的报头长度应该是x*4=20字节,也就是4位首部长度的范围应该是【0101,1111】,即【20,60】字节!
又因为TCP的报头的基本单位是4个字节,所以后面的TCP报头是肯定可以整除4个字节的【20,24,28,32,......,60】!所以将来选项的基本单位也是4字节的!!!
所以报头和有效载荷是如何进行分离的呢?就是我们首先无脑读取报文的前20个字节,然后提取4为首部长度,直接*4,然后减去20,剩下的就是选项的所占字节大小,最后剩下的就是有效载荷了!
我们在谈UDP协议的报文格式的时候,UDP有其对应的报头长度8字节定长,其中报头中还有整个UDP报文的长度的,但是为什么TCP协议格式中为什么没有报文大小,只有报头大小呢? 没有对应的数据部分的长度?其实从这里我们就可以窥探出一个认知了:
在操作系统内部,操作系统可以知道UDP报文的边界的,知道UDP报文从哪里开始,从哪里结束,可以知道一个完整的UDP报文!因为UDP是面向数据报的!不过TCP是面向字节流的,在操作系统内部,发送了许多TCP数据段,他也区分不清楚是不是一个完整的报文,所以TCP不能够来表示一个报文完整的长度!
所以对于TCP协议来说,不需要,也不能设置一个叫做报文长度的字段,因为将来来的TCP报文是不是一个完整报文我操作系统吃不准!只能是将报头拿走,剩下的数据交给接收缓冲区当中,由用户上层自行去分析这么多个按序拼接好的有效载荷!
可是就不会说数据和下一个报头黏在一堆的情况嘛???
这种情况是不可能存在的,因为每收到一个报文,都是一个独立的sk_buff!!!
但是TCP是面向字节流的,报文的有效载荷在接收缓冲区当中会黏在一起!!!如果UDP有接收缓冲区,我们可以理解为数据报是由一个一个的队列维护的,这样就不会产生和字节流的黏在一起的问题了。
TCP如何将自己的有效载荷交付给上一层?
当 TCP 数据段到达时,内核会根据目的端口号找到对应的套接字(socket),并将数据传递给该套接字关联的应用程序。这个过程是通过内核的协议栈和套接字管理机制实现的,确保数据能够准确地到达正确的应用程序。
可靠性的本质
确认应答(ACK)机制
给个实际的例子,两名同学在相距100m的操场上:
小B:吃了吗?
小S:吃了!
其实如果小S没有回复的话,那么小S可以看成是没有收到小B给小S发送的消息的!
但是小B回复了,也没办法确定说小N听到了,所以:
小S:好!
但是又这么保证说小N听到了呢?😥😥😥😥😥😥😥😥😥😥😥😥
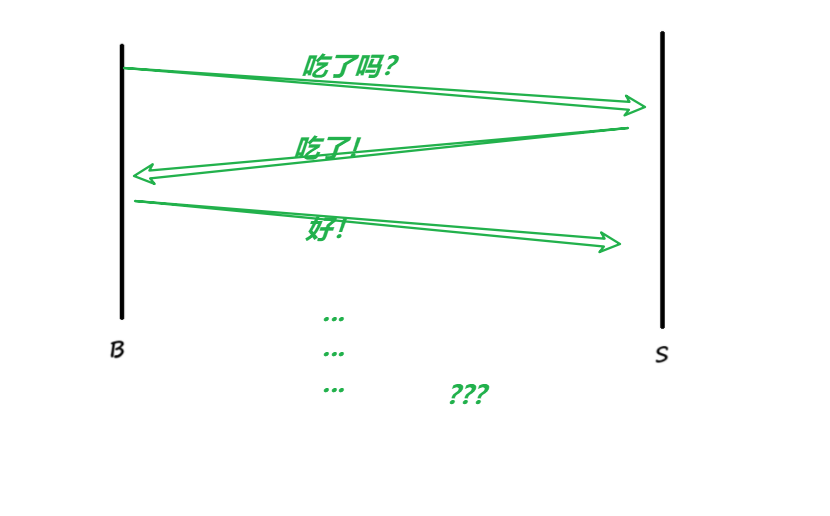
所以这个世界上,在长距离传输的时候,根本就不存在100%可靠的协议!所以:
正确理解可靠性:
- 具有应答,可以保证对历史消息的可靠性,是100%的:
- 通信中,最新的报文,永远没有应答,最新可靠性无法保证!
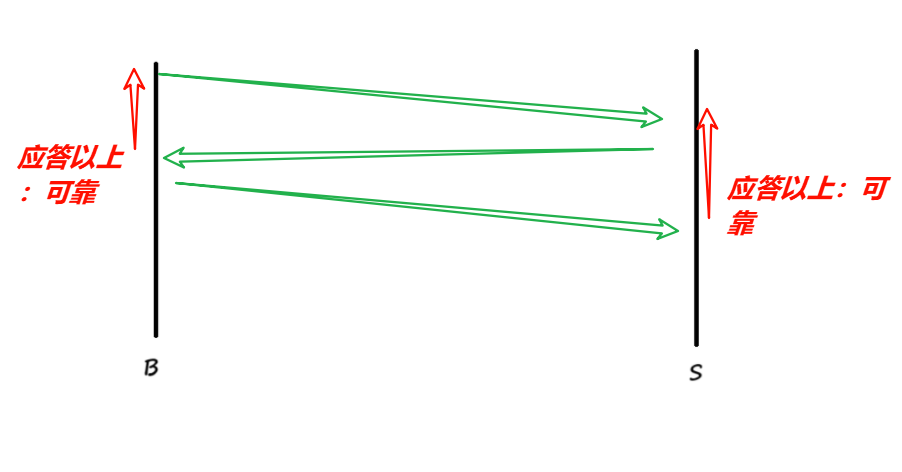
TCP一般的通信过程(暂时这么说,后面会更加正确理解)(最朴素的认识)
在TCP当中,如果要保证可靠性,处于核心地位的可靠性,叫做确认应答机制!
就是在客户端和服务端,客户端向服务端发送消息,硬性规定说服务端要给客户端应答,这就是确定了客户端向服务端的可靠性;服务端向客户端发送消息,客户端响应服务端,给服务端做应答,这就保证说服务端到客户端的可靠性的保证:
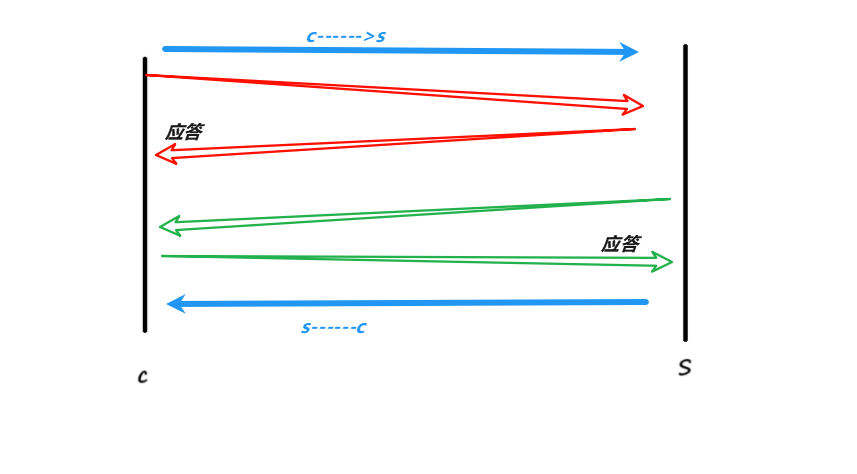
不过这种模式是一个一个串行的走的,效率太低下了,所以我们就有了TCP传递信息时,更加通用的过程:
TCP传递信息时,更加通用的过程:
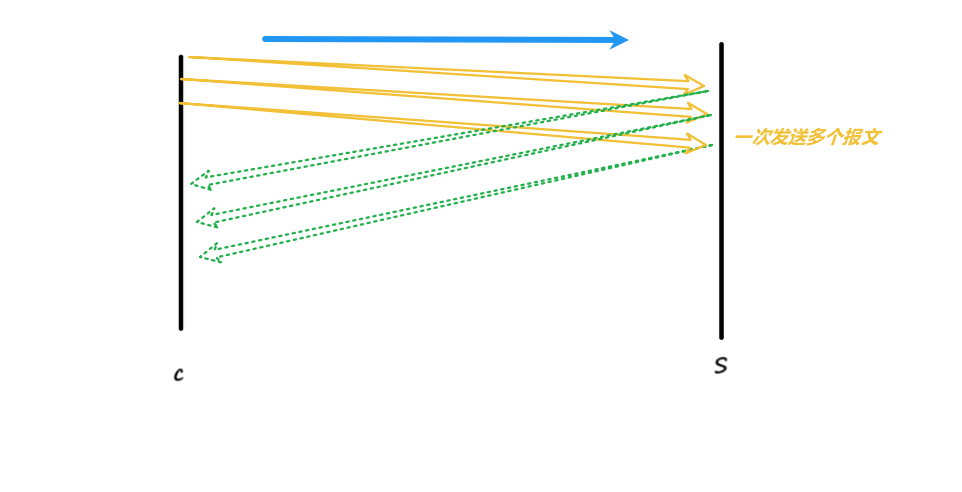
我们可以一次性发送多个报文,这就相当于是并行的由客户端向服务端发报文信息,这样的效率是明显提高了,但是一系列问题也就随之而来:
假设一次性发送过来的这么多报文数据当中,有其中一两条没有发送到服务端,服务端就没办法做应答,造成客户端没法接收到对应的应答!哪一个呢,客户端怎么知道!
所以为了能够更加细致的确认应答,TCP协议报头中就引入了32位序号和32位确认序号!
我们来好好说说:
假设客户端需要向服务端发送一系列数据包,每个数据包包含一个报文。为了提高效率,客户端选择一次性发送多个报文,而不是逐个发送。
客户端发送报文:
客户端(C)一次性发送多个报文(黄色实线箭头)到服务端(S)。这些报文可能包含不同的数据,如请求、命令或数据更新。
服务端接收报文:
服务端(S)接收到这些报文后,需要确认每个报文是否成功接收。服务端通过发送确认应答(绿色虚线箭头)来告知客户端哪些报文已经成功接收。
确认应答的作用:
确认应答(绿色虚线箭头)包含一个确认序号,表示服务端期望接收的下一个字节的序号。例如,如果服务端成功接收了序号为1到10的报文,它会发送一个确认序号为11的应答。
客户端收到确认应答后,知道序号为1到10的报文已经被服务端成功接收,可以继续发送后续报文。(指定报文序号之前的所用信息,已经全部收到!!!---这个一条很重要的规定!!!)
处理丢失的报文:
如果服务端发现某个报文丢失(例如,序号为5的报文没有收到),它不会发送确认序号为6的应答,而是继续发送确认序号为5的应答,告知客户端需要重传序号为5的报文。
客户端收到这个重复的确认应答后,知道序号为5的报文丢失,需要重新发送该报文。
那么为什么会有两个序号,一个序号一个确认序号呢?
说人话:其实双方发送的是一个TCP报文,应答正常来说是TCP报头,总不能说客户端向服务器发送后,服务端只做应答,也就是报头,所以有捎带应答=报头+有效载荷,所以需要两个序号来,不然这么区分
详细说明:
在TCP协议中,数据传输的可靠性是通过序号和确认序号来保证的。这两个序号在TCP报文段中扮演着不同的角色:
1. 序号是用来标识TCP报文段中的数据字节流的位置。目的是为了确保数据的顺序性,允许接收方正确地重新组装从发送方接收到的数据片段。是标识本报文段的数据的第一个字节的序号。
2. 确认序号是用来指示接收方期望从发送方接收的下一个字节的序号。目的是为了告知发送方哪些数据已经被成功接收,从而触发发送方发送更多的数据或重传丢失的数据。如果ACK标志位被设置,此字段值加1即是下一个期望接收的字节序号。
TCP报文由TCP报头和可能的有效载荷(数据)组成。TCP报头包含了序号和确认序号等重要信息。
捎带应答(Piggybacking)
在TCP中,捎带应答是一种优化技术,它允许接收方在发送数据(即有数据要发送给发送方)时,将对先前接收数据的应答包含在同一个报文中。这样可以减少单独发送应答报文的次数,提高网络效率。(报头:确认应答+有效载荷:数据)(不是单单的只有报头,即只有单纯的应答!)
客户端发送数据:客户端发送一个TCP报文,序号为100,包含数据字节101到105。
服务端接收并发送数据:服务端接收到数据后,发送一个TCP报文作为应答,其中包含:
-
确认序号:106(表示已成功接收到序号为105的数据,并期望接收下一个序号为106的数据)。
-
有效载荷:如果服务端也有数据要发送给客户端,这些数据将作为有效载荷包含在同一个报文中。
为什么需要两个序号来区分?
-
序号:用于标识发送的数据字节流,确保接收方可以正确地重新组装数据。
-
确认序号:用于告知发送方哪些数据已经被成功接收,触发发送方的后续动作(如发送更多数据或重传丢失的数据)。
通过使用两个序号,TCP协议能够确保数据的可靠传输,同时通过捎带应答优化网络通信效率。这种设计允许TCP在保证数据完整性和顺序性的同时,也能够有效利用网络带宽。
好了,对应TCP,数据从发送端的发送缓冲区"拷贝"到对端的接收缓冲区中,这就有一问题,上面也说过了,在对端接收缓冲区如果满了的话,那么就会导致发送的报文被丢弃,这已经不是可不可靠性的问题了,因为可以通过超时重传等等的机制来保证,但是这里带来的问题不就是浪费,是一种低效的吗,如果满了的话,还一次性又发来一大推,然后又丢了???这不就很低效,浪费吗???所以发送端是需要知道对端的接收缓冲区的当前接收能力!!!是由对端接收缓冲区中剩余空间的大小所决定的!
其实,我们上面也说了,发送端发送消息,对端原则上是需要给发送端做应答的,不管是捎带还是普通应答,而只要对端给应答,那么不就是双方互相在进行报头/报文的传输吗!双方就需要知道对应对端的接收缓冲区的剩余空间大小!然而TCP协议中有一个关键字段 --- 16位窗口大小!
这个16位窗口大小的内容就是接收缓冲区剩余空间的大小,是自己的!!!不是对端的接收缓冲区的剩余空间的大小!!!(我们所构建的报文一定是给对方的,当然将自己的剩余缓冲区空间大小告诉对方!)
所以尽管可以一次性并行的给对端发送报文,但是也是有上限的,这个上限取决于对端接收缓冲区剩余空间的大小!
我们将这种按照对端接收缓冲区的接受能力来动态调整我们发送速度的机制称为 --- 流量控制! (多发多,少发少,合理控制的机制)(考虑了可靠性,一定程度上防止了丢包,但是流量控制更加考虑的是效率问题)
TCP协议当中还有一个校验和,这个我们不用关心:
TCP协议中的校验和是一个重要的机制,用于确保数据在传输过程中的完整性和准确性。以下是关于TCP校验和的简单介绍:
-
检测数据完整性:TCP校验和的主要功能是检测数据在传输过程中是否发生了错误。由于网络传输可能会受到干扰(如电磁干扰、硬件故障等),数据可能会被损坏。通过校验和机制,接收端可以验证数据是否与发送端发送的数据一致。
-
提高可靠性:TCP是一个面向连接的可靠协议,校验和是其可靠性机制的重要组成部分。如果接收端发现校验和不匹配,可以要求发送端重新发送数据,从而确保数据的正确性。
还有一个16位紧急指针,需要了解这个,我们就需要将剩下的标志位谈清楚!
TCP协议报头中有一个保留位(6位),也就是还没想好该怎么用!知道我们想使用再用!除了保留的6位,后面还有6个标志位!
协议的本质就是结构体,tcphdr结构体当中含有条件编译,是对与位段的,这也说明了内核已经可以自己进行大小端的区分了,其中位段是一种数据结构,通常用于将一个字节(8位)或多个字节划分为多个字段,每个字段可以表示不同的信息。位段的设计允许在有限的空间内存储多个标志或状态信息。这是我们C语言所学习的,现在知道了吧!位段主要应用在网络通信中!其实所谓的标志位本质就是报头中的比特位!!!
我们先来说说为什么需要有标志位???
我们先简单谈谈TCP的三次握手,后面会谈到TCP的三次握手的详细过程:
在这个世界上,我们正常通信之前有许多准备工作,有的是没有准备工作的,比如发送邮件,这种直接发送的我们称之为面向数据报,但是如果要打电话进行双方间的通信的话,需要先拨通电话,拨通之后,对方需要将电话接起来,这样的话,电话就建立好通信了。
TCP也是如此,TCP在正常通信之前需要进行三次握手:你可以做我女朋友吗(建立连接的请求)---可以呀,什么时候---就现在!连接关系建立本质就是达成共识!往后就是正常通信了!
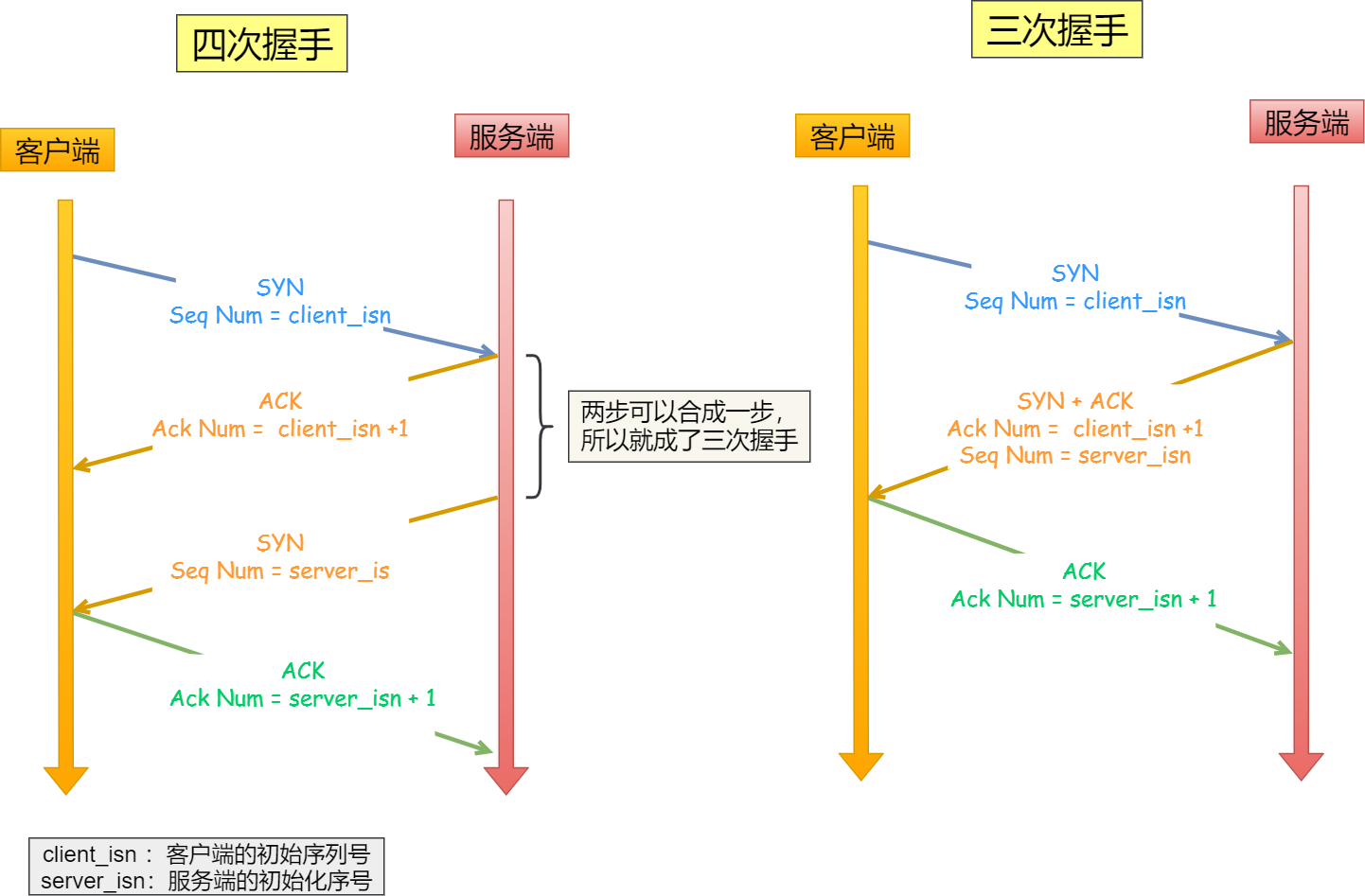
这样客户端在某一时刻向接收端发送报文的类型是不一样的!那么可以有多个客户端同时向服务端发送各种各样的报文数据,这样就会导致:接收方收到的TCP报文,一定会存在不同的类型,针对不同的报文类型,接收方要有对应的不同的做法!
双方传输的至少是含有报头的,所以报头当中一定存在标志报文类型的字段!
在TCP协议中,6个标志位(也称为控制位)是TCP头部的重要组成部分,用于控制TCP连接的建立、维护和终止等操作。以下是这6个标志位的详细介绍:
1. SYN(Synchronize Sequence Numbers)
作用:用于建立连接。当SYN标志位被设置为1时,表示这是一个连接请求或连接接受报文。
应用场景:
-
在TCP的三次握手过程中,第一次握手(客户端向服务器发送连接请求)和第二次握手(服务器接受连接请求并回复)都会设置SYN标志位。
-
客户端发送SYN报文时,表示请求建立连接;服务器收到SYN报文后,也会发送一个带有SYN标志位的报文作为响应。
2. ACK(Acknowledgment)
作用:确认号(Acknowledgment Number)字段是否有效。如果ACK标志位被设置为1,则表示确认号字段是有效的,接收方通过确认号来确认已收到的数据。表示该报文是一个应答报文!
应用场景:
-
在TCP通信中,除了第一次握手的SYN报文外,几乎所有的TCP报文都会设置ACK标志位。
-
例如,服务器在收到客户端的SYN报文后,会发送一个带有ACK标志位的SYN-ACK报文,表示确认收到了客户端的连接请求。
三次握手建立之前,不能正常通信,前两次握手不能发送像"Hello World"的数据,就是三次握手没有完成,也就是只能互发报头了!
那么客户端给服务端发送消息之前不是要进行流量控制吗?那么第一次发送报文的时候不是还不清楚对端的接收缓冲区的剩余空间大小吗???注意!我们第一次发数据是第一次给对端服务器发报文吗???并不是报文!!!而是说双方在通信之前就已经完成三次握手了,三次握手期间已经发送过报头了!!!绝对不会出现数据溢出,丢弃的问题了!!!
3. FIN(Finish)
作用:用于终止连接。当FIN标志位被设置为1时,表示发送方已经完成数据发送,希望关闭连接。
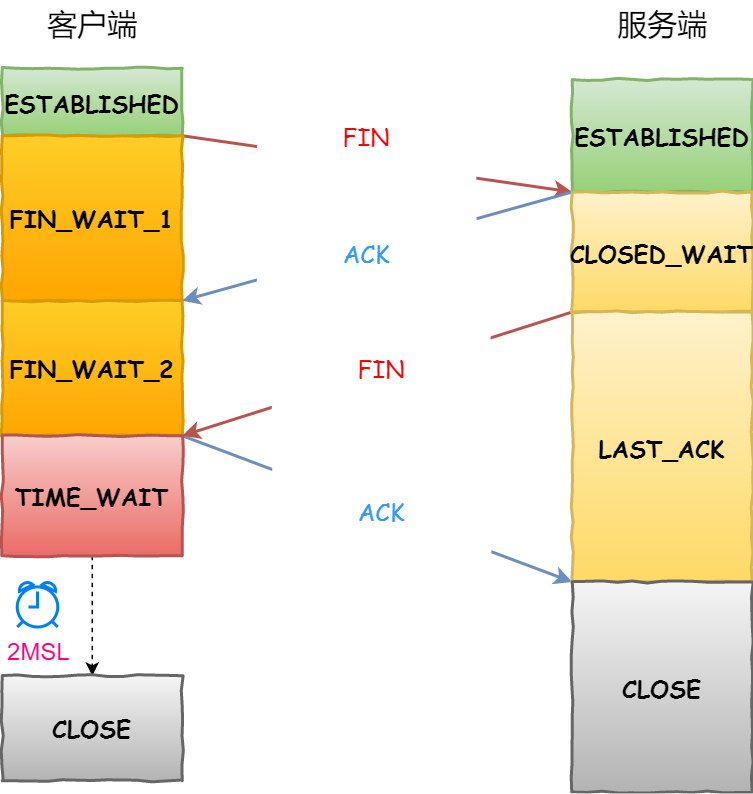
和三次握手类似,客户端给服务端说:我不想玩了,想要断开连接;
服务端:好呀;
服务端:我也要跟你断开连接;
客户端:好呀。
为什么是4次,主要是TCP是全双工的,一方关闭就是只关闭一个通信信道,如果服务端有的还没发完,客户端发完了,那就客户段信道关了,等服务端发完了,也就双发一起实现了完全关闭了!
应用场景:
-
在TCP的四次挥手过程中,发送方(客户端或服务器)在完成数据传输后,会发送一个带有FIN标志位的报文,通知对方自己已经没有数据要发送了。
-
对方收到FIN报文后,会发送一个ACK报文作为确认,然后自己也会发送一个FIN报文,最终完成连接的关闭。
4. PSH(Push)
作用:表示接收方应尽快将数据推送给上层应用。当PSH标志位被设置为1时,接收方会立即将数据传递给上层应用,而不是等待缓冲区填满后再传递。
应用场景:
-
通常用于实时性要求较高的数据传输,例如在HTTP协议中,当服务器向客户端发送响应数据时,可能会设置PSH标志位,以便客户端尽快处理这些数据。
对端上层应用层很忙,接收缓冲区的所剩空间越来越少,直至为0,那么发送端就只能不发了,但是不发总不能就傻傻的等着吧?!还有如果接收端读走了部分缓冲区的数据,那么发送端又怎么知道?!(我们后面会说到:一旦数据读走了,窗口更新了,这个接收端/服务端,就会主动向客户端发送报文,还有一种方式时客户端会定期像服务端发送一个不携带数据的报文,一发数据就需要ACK,那么客户端也就清楚现在服务端的接收缓冲区的状态了)
PSH就是叫接收方应尽快将数据推送给上层应用!!!是一种催促的机制!!!注意:我们举得例子比较极端,准确来说:当PSH标志位被设置为1时,接收方会立即将数据传递给上层应用,而不是等待缓冲区填满后再传递。
什么是叫对端操作系统赶快读???缓冲区没有数据的时候读取会阻塞,其实有数据的时候也可能会阻塞,就是我们后面会谈到的低水位线和高水位线的问题,举例就是需要满50个字节才会触发read的条件,我们后面提到IO时间就绪的概念的时候详谈!所以PSH的作用就是让对端的read/...条件就绪!
5. RST(Reset)
作用:用于重置连接。当RST标志位被设置为1时,表示当前连接出现了问题,需要强制断开连接。
应用场景:
-
如果接收方收到一个错误的报文(例如,报文中的序号或确认号不正确),或者接收方没有建立对应的TCP连接,它会发送一个带有RST标志位的报文,通知对方终止连接。
-
例如,当客户端尝试连接一个不存在的端口时,服务器会发送一个RST报文,拒绝连接。
我们知道TCP建立连接的三次握手的第三次握手是没有应答的,也就是前两次握手尽管丢包了也不怕,因为有应答,能知道,其实客户端在最后一次握手的时候,将第三次握手的ACK发送出去的时候,就已经是客户端三次握手成功了,但是如果在第三次握手的时候丢包了的话,客户端是不知道的,双方只是站在自己的立场,三次握手是看自己有没有发送和收到的(发-收-发;收-发-收)双发三次握手完成是有时间差的:
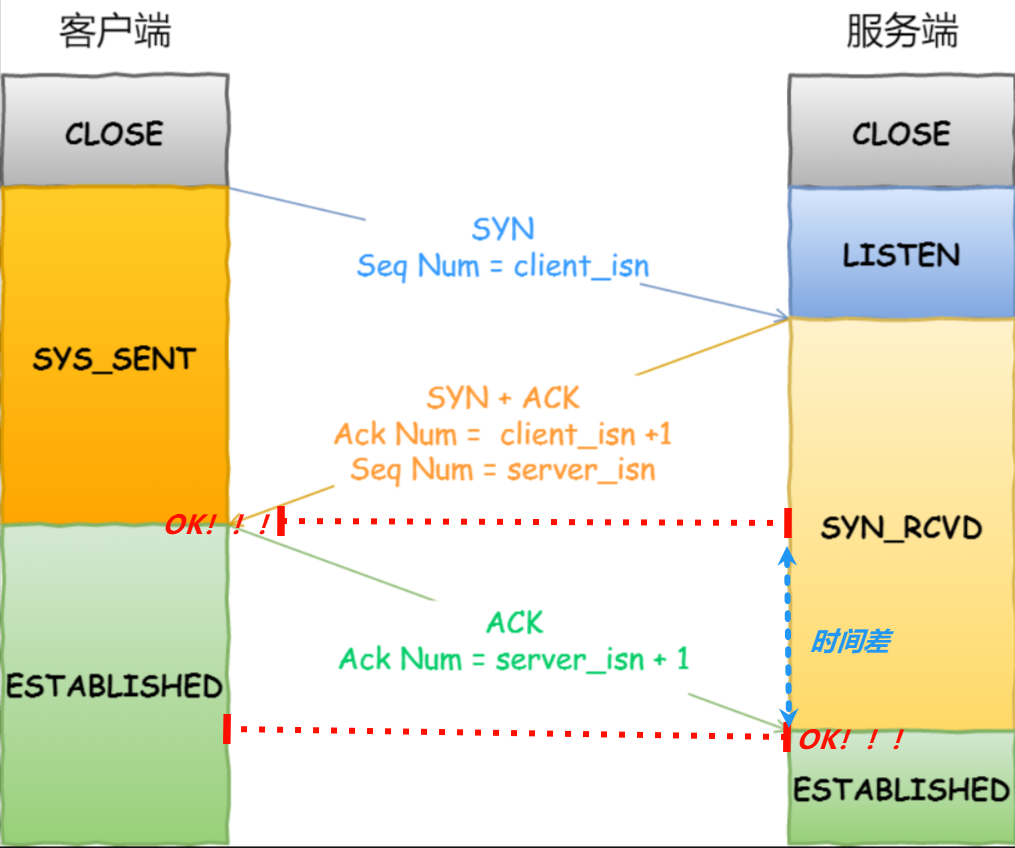
如果第三次的ACK丢了的话,客户端认为建立成功,但是服务端认为连接失败了,导致连接是否成功的判定不一致, 那么客户端接下来就极有可能向服务器发送数据!!!可是服务器说不是三次握手还没有好吗?于是服务器就会向客户端发送一个RST置为1的报文,表示当前连接出现了问题,需要强制断开连接。

上面这个例子也是比较极端的,其实在通信的过程中,连接出现任何问题,都可以进行重置!
6. URG(Urgent)
作用:表示报文中有紧急数据。当URG标志位被设置为1时,表示TCP报文中的数据是紧急数据,接收方应优先处理这些数据。
应用场景:
-
紧急数据通常用于控制信息,例如在Telnet协议中,用户可以通过发送紧急数据来中断当前的操作。
-
当URG标志位被设置时,TCP会使用紧急指针(Urgent Pointer)来指示当前报文的有效载荷中紧急数据的起始位置。
接受缓冲区可以看成是字节流式的接收队列还有因为序号按序到达的机制,那么我们如果有数据想要优先读取并处理的话,直接是行不通的!在计算机网络当中,什么情况是需要被优先处理的呢?
有一种情形:就是上传资料到百度网盘,大小大概是一个G的文件,就会像服务端发送大量的报文,对端缓存区也是收到了该文件的部分的报文,上层会进行备份保存在指定文件当中,但是上传到一半的时候,发现传错了,要取消上传,尽管该文件是一个报文来完成,也是需要死板的到对端接收缓冲区,等待前面的报文处理了,才到该报文,现在就是表示取消上传的报文想要优先被处理,因为前面部分报文是属于同一文件的,上层还需要将前面的报文处理了,但是处理这些报文已经是没有意义的了,所以对端接收缓冲区一旦接收到了含有紧急数据的报文就直接优先处理了,就像我们的取消还有暂停等等!!!
URG是比较不常用的,URG标志位通常是要与TCP报文协议当中的16位紧急指针相配合,如果URG标志位被置为0,表示该16位紧急指针是无效的,为1就是有效了,下面我们来看看16位紧急指针的源码:
__be16 urg_ptr; // 16位紧急指针紧急数据并不属于正常数据,他是带外数据!
URG只是代表紧急指针有无效,本质还是需要看16位紧急指针!
紧急指针来指示当前报文的有效载荷中紧急数据的起始位置,本质就是偏移量!紧急数据只有一个字节!也就是因为一个字节,所以他往往可以用来设置状态码!
暂停,取消,继续上传不就可以使用0,1,2来表示嘛!不同的状态码来表示不同的控制命令!
标志位的组合
TCP标志位可以组合使用,以实现不同的功能。例如:
-
SYN-ACK:SYN和ACK标志位同时被设置,表示接受连接请求并确认。
-
FIN-ACK:FIN和ACK标志位同时被设置,表示完成数据传输并确认对方的FIN报文。
TCP的6个标志位是TCP协议的核心控制机制,通过这些标志位,TCP能够实现连接的建立、数据传输、连接终止以及错误处理等功能。这些标志位在TCP的三次握手和四次挥手过程中起着关键作用,确保了TCP协议的可靠性和高效性。
至此,我们TCP包头协议的主要字段我们就谈完了,剩下的字段我们后续会在利用到的时候谈起!
🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔更多精彩请看下文!!!
🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔🤔
![WeakAuras Lua Script [ICC BOSS 11 - Sindragosa]](https://i-blog.csdnimg.cn/direct/a02aaf95d6454d4d909f50b614bdc66f.png)


![[ARM][架构] 02.AArch32 程序状态](https://i-blog.csdnimg.cn/direct/aeae11a204fe4081b3876d1c76a8b00b.png)