Transformer 神经网络
Self-Attention 的提出动机
传统的循环神经网络(RNN)处理序列信息依赖时间步的先后顺序,无法并行,而且在捕捉长距离依赖关系时存在明显困难。为了解决这些问题,Transformer 引入了 Self-Attention(自注意力) 机制,彻底摆脱了循环结构。
核心思想是:
- 输入序列中的每个位置都可以同时关注其他所有位置的信息
- 依赖“注意力权重”来决定每个位置对其他位置的依赖程度
这项机制的提出奠定了后续 GPT、BERT 等大型语言模型的基础,其口号正是:
Attention is all you need.
Self-Attention 的基本形式
输入序列为 x 1 , x 2 , x 3 , x 4 x_1, x_2, x_3, x_4 x1,x2,x3,x4,我们首先将其映射为特征表示 a 1 , a 2 , a 3 , a 4 a_1, a_2, a_3, a_4 a1,a2,a3,a4。
然后,为了执行注意力计算,每个位置的表示 a i a_i ai 会被分别映射成三个向量:
- 查询向量(Query): q i = W Q a i q_i = W_Q a_i qi=WQai
- 键向量(Key): k i = W K a i k_i = W_K a_i ki=WKai
- 值向量(Value): v i = W V a i v_i = W_V a_i vi=WVai
这些向量的作用分别是:
- q q q:表示当前要“提问”的内容(to match others)
- k k k:表示其他位置的信息索引(to be matched)
- v v v:表示其他位置的具体内容信息(information to be extracted)
这些投影矩阵 W Q , W K , W V W_Q, W_K, W_V WQ,WK,WV 都是可训练参数。
Scaled Dot-Product Attention 计算过程
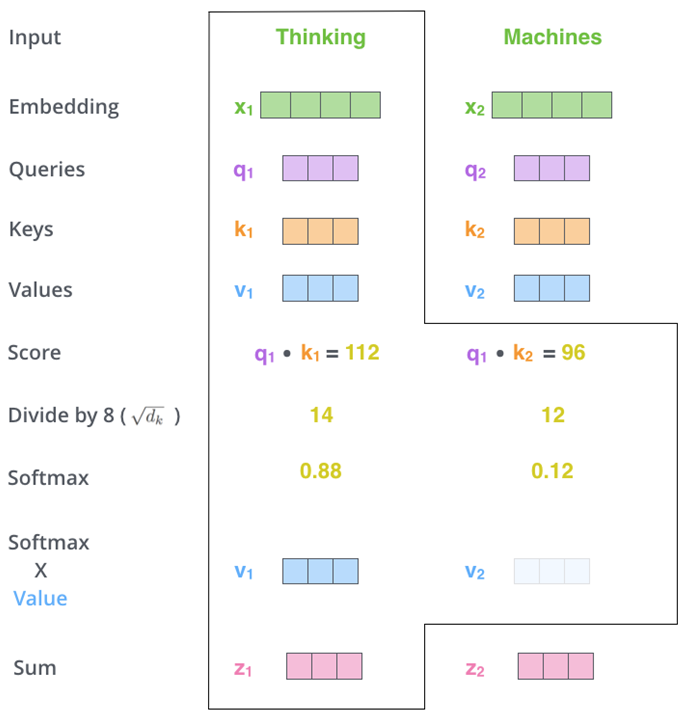
对于每一个查询 q i q_i qi,我们计算它与序列中每一个键 k j k_j kj 的相似度:
α i , j = q i ⊤ k j d \alpha_{i,j} = \frac{q_i^\top k_j}{\sqrt{d}} αi,j=dqi⊤kj
其中 d d d 是向量的维度,用 d \sqrt{d} d 来进行缩放,防止 dot product 值过大。
然后对所有 α i , j \alpha_{i,j} αi,j 做 softmax,得到归一化注意力分布:
softmax ( α i , 1 , α i , 2 , . . . , α i , n ) \text{softmax}(\alpha_{i,1}, \alpha_{i,2}, ..., \alpha_{i,n}) softmax(αi,1,αi,2,...,αi,n)
最后,用这些权重对值向量 v j v_j vj 加权求和,得到当前输出表示 b i b_i bi:
b i = ∑ j softmax ( α i , j ) ⋅ v j b_i = \sum_j \text{softmax}(\alpha_{i,j}) \cdot v_j bi=j∑softmax(αi,j)⋅vj
这种机制允许模型根据输入内容自适应地提取相关信息。
Self-Attention 的并行优势
由于 self-attention 的所有位置间的权重可以同时计算,因此整个计算过程高度并行化,不再像 RNN 那样必须按序列顺序逐步执行。
这一优势为 Transformer 模型带来了巨大的训练速度提升和更强的长距离建模能力。
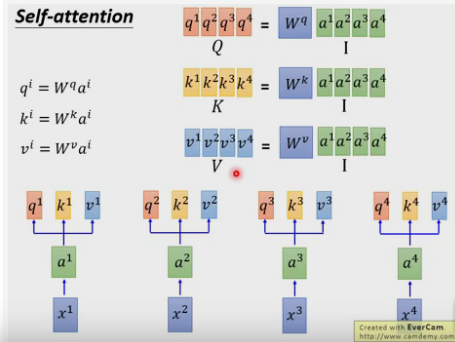
Self-Attention 结构矩阵形式
将所有 a i a_i ai 构成矩阵 A A A 后,统一投影为 Q = A W Q Q = AW_Q Q=AWQ, K = A W K K = AW_K K=AWK, V = A W V V = AW_V V=AWV。
注意力输出矩阵表示为:
Attention ( Q , K , V ) = softmax ( Q K ⊤ d ) V \text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^\top}{\sqrt{d}} \right) V Attention(Q,K,V)=softmax(dQK⊤)V
这种矩阵形式便于实现多头注意力机制(Multi-head Attention)。
多头注意力机制(Multi-head Self-Attention)
在基础的 Self-Attention 结构中,所有位置的注意力都是通过一组 W Q , W K , W V W_Q, W_K, W_V WQ,WK,WV 矩阵计算的。为了增强模型的表达能力,Transformer 引入了**多头注意力(Multi-head Attention)**机制。
基本思想是:
- 不止使用一组查询/键/值矩阵,而是使用多个不同的投影子空间
- 每个头(head)有独立的 W Q ( h ) , W K ( h ) , W V ( h ) W_Q^{(h)}, W_K^{(h)}, W_V^{(h)} WQ(h),WK(h),WV(h)
- 每个头计算一个独立的 Attention 输出,然后将所有头的输出拼接后,再通过线性变换整合
多头计算公式:
设有 h h h 个头,每个头输出 b ( i ) b^{(i)} b(i),则:
MultiHead ( Q , K , V ) = Concat ( b ( 1 ) , b ( 2 ) , . . . , b ( h ) ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(b^{(1)}, b^{(2)}, ..., b^{(h)}) W^O MultiHead(Q,K,V)=Concat(b(1),b(2),...,b(h))WO
其中 W O W^O WO 是最终输出线性层的权重。
这种结构的优势在于:
- 每个头可以捕捉不同维度、不同位置之间的依赖关系
- 实现信息多角度理解,提升模型表示能力
位置编码(Positional Encoding)
由于 Transformer 完全抛弃了 RNN 的序列性结构,模型本身不具备位置感知能力,因此需要通过显式地添加**位置编码(Positional Encoding)**来注入顺序信息。
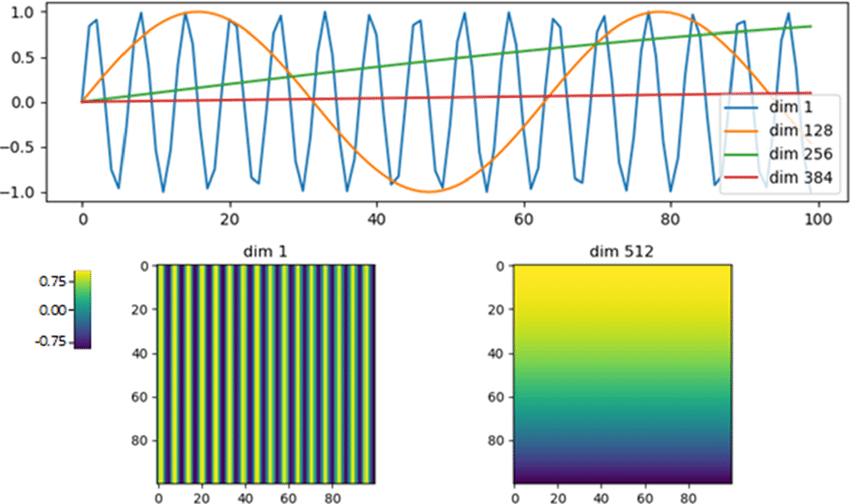
原理
对于输入序列 x 1 , x 2 , . . . , x n x_1, x_2, ..., x_n x1,x2,...,xn,我们给每个位置添加一个位置向量 p i p_i pi,得到输入表示:
a i = x i + p i a_i = x_i + p_i ai=xi+pi
原论文中的位置编码设计为:
P E ( i , 2 j ) = sin ( i 10000 2 j / d ) PE(i, 2j) = \sin\left(\frac{i}{10000^{2j/d}}\right) PE(i,2j)=sin(100002j/di)
P E ( i , 2 j + 1 ) = cos ( i 10000 2 j / d ) PE(i, 2j+1) = \cos\left(\frac{i}{10000^{2j/d}}\right) PE(i,2j+1)=cos(100002j/di)
其中 i i i 是位置索引, j j j 是维度索引, d d d 是维度总数。
该方法具有以下优点:
- 每个位置对应的编码唯一
- 可以推广到任意序列长度
- 可以通过位置间的函数关系捕捉相对距离
编码器 - 解码器结构
Transformer 模型整体结构为 Encoder-Decoder 框架:
- Encoder:由若干层 Self-Attention 和前馈网络(Feed-Forward)组成
- Decoder:在 Encoder 基础上引入 Masked Self-Attention,以防止看到未来的词
每一层都包含:
- 多头注意力层
- 残差连接 + 层归一化(Layer Normalization)
- 前馈全连接层(Feed-Forward Network)
Encoder 和 Decoder 都堆叠多层(如 6 层)构成深度网络。
解码器中的 Masked Self-Attention
在解码器中,为了保证生成过程的自回归特性,我们使用 Masking 机制屏蔽掉当前词右侧的词:
- 即 y 3 y_3 y3 只能看到 y 1 , y 2 y_1, y_2 y1,y2
- 实现方法:将未来位置的 attention score 设置为 − ∞ -\infty −∞
这样可以确保每个位置只能访问“过去的词”。
Layer Normalization 和残差连接
在每个子层(如 Attention 或 Feed-Forward)之后,Transformer 都加入了:
-
残差连接(Residual Connection):
Output = LayerNorm ( x + Sublayer ( x ) ) \text{Output} = \text{LayerNorm}(x + \text{Sublayer}(x)) Output=LayerNorm(x+Sublayer(x)) -
层归一化(LayerNorm):标准化子层输出,稳定训练
这种结构让深层网络训练更加稳定,并避免信息在深层网络中衰减。
总结
Transformer 通过以下关键组件实现了对序列的建模:
- 自注意力机制:实现信息全局交互
- 多头注意力:提高表达维度
- 位置编码:引入序列顺序
- 残差连接 + LayerNorm:提升训练效率
- 并行结构:大幅提高计算效率
这些设计使得 Transformer 成为大规模语言建模的核心骨架。
ELMo:上下文词表示的革命性模型
本教程将详细介绍 ELMo(Embeddings from Language Models)模型的提出背景、结构原理、数学表达、实际应用及其对自然语言处理(NLP)领域的深远影响。ELMo 是第一个广泛应用于工业界的上下文词表示方法,在 NLP 中具有划时代的意义。
词向量的背景与局限
在 ELMo 出现之前,词向量的主流方法是 Word2Vec、GloVe 等,这些模型为每个词生成一个固定向量表示,不考虑上下文语义。
例如,词语 “bank” 在下面两个句子中的意思完全不同:
- He sat on the bank of the river.(河岸)
- He deposited money in the bank.(银行)
然而,Word2Vec 或 GloVe 中的 “bank” 向量是唯一的,无法根据上下文调整。
这导致传统词向量在表示歧义词、多义词时存在局限。
ELMo 的基本思想
ELMo(Peters et al., 2018)提出了一种上下文相关的动态词向量表示方法。
其核心思想为:
- 每个词的表示是函数 f ( word , context ) f(\text{word}, \text{context}) f(word,context),由所在上下文动态决定;
- 使用**双向语言模型(BiLM)**获得上下文信息;
- 将不同层的表示融合(非简单拼接)。
因此,同一个词在不同句子中的向量将不同,有效捕捉多义词的含义。
模型结构概览
ELMo 基于一个双向 LSTM(bi-LSTM)语言模型,其整体结构如下:
- 字符级嵌入:使用 CNN 处理每个单词的字符,生成词表示;
- 双向 LSTM:分别从左到右、从右到左处理句子;
- 上下文融合:将每层 LSTM 输出进行加权求和,得到最终的 ELMo 向量。
结构流程如下:
- 输入句子 → 字符嵌入(CharCNN)
- → 前向 LSTM + 后向 LSTM
- → 每层输出加权融合
- → 上下文词向量(ELMo 表示)
数学表达与权重组合
ELMo 的词向量是多个 LSTM 层输出的加权和。对第 k k k 个词,其向量为:
E L M o k t a s k = γ t a s k ∑ j = 0 L s j t a s k ⋅ h k , j ELMo_k^{task} = \gamma^{task} \sum_{j=0}^{L} s_j^{task} \cdot h_{k,j} ELMoktask=γtask∑j=0Lsjtask⋅hk,j
其中:
- h k , j h_{k,j} hk,j 表示第 j j j 层输出(第 0 层为词嵌入,后续为 LSTM 层);
- s j t a s k s_j^{task} sjtask 是 softmax 权重,控制每层贡献度;
- γ t a s k \gamma^{task} γtask 是缩放因子,调节整体表示;
- 所有权重是任务相关的,可通过微调学习。
该机制使模型能自动选择更有信息的层级表示,提升下游任务效果。
与 Word2Vec、BERT 的对比
| 模型 | 是否上下文相关 | 表示方式 | 参数共享 | 应用时代 |
|---|---|---|---|---|
| Word2Vec / GloVe | 否 | 固定向量 | 是 | 2013-2015 |
| ELMo | 是 | 动态加权层组合 | 是 | 2018 |
| BERT | 是 | 深层 Transformer 表示 | 否 | 2018-至今 |
ELMo 是第一个提出将多个语言模型层表示加权组合的思路,直接启发了后续的 BERT、GPT 等模型的层融合机制。
预训练语言模型:BERT 和 GPT
基于 Transformer 架构,涌现出一系列强大的预训练语言模型,它们以不同方式利用 Transformer 的编码器和解码器模块。
BERT(Bidirectional Encoder Representations from Transformers)
BERT 使用 Transformer 的 Encoder 堆叠结构,强调从上下文中双向建模词语含义,其关键特点如下:
- 输入同时包含左右上下文(不像传统语言模型只看左边)
- 适用于句子级别和段落级别的理解任务(如问答、情感分析)
BERT 的输入结构
BERT 输入由三个部分组成:
- Token Embedding:词语本身的表示
- Segment Embedding:区分句子 A 和句子 B(用于句对任务)
- Position Embedding:位置编码
最终输入为三者之和:
Input i = Token i + Segment i + Position i \text{Input}_i = \text{Token}_i + \text{Segment}_i + \text{Position}_i Inputi=Tokeni+Segmenti+Positioni
BERT 的训练任务
BERT 采用两种预训练目标:
-
Masked Language Modeling (MLM):
- 输入中随机遮蔽一些词(如 15%),模型预测这些被 mask 的词
- 例如输入 “I have a [MASK] car”,目标是预测 “red”
-
Next Sentence Prediction (NSP):
- 判断句子 B 是否是句子 A 的下一个句子(用于建模句子间关系)
这种预训练方式使 BERT 能更好地捕捉句子结构与上下文依赖。
GPT(Generative Pre-trained Transformer)
GPT 使用 Transformer 的 Decoder 堆叠结构,强调自回归生成语言,适用于生成类任务,如对话、写作、摘要。
其主要特点:
- 输入为单向序列,预测下一个词
- 无 NSP 任务,专注语言建模
GPT 的每个解码器层使用 Masked Self-Attention,避免泄露未来信息。
GPT 的训练目标
GPT 的训练任务是标准的语言建模目标:
max ∑ t log P ( w t ∣ w 1 , . . . , w t − 1 ) \max \sum_{t} \log P(w_t | w_1, ..., w_{t-1}) maxt∑logP(wt∣w1,...,wt−1)
即,给定前面所有词,预测下一个词。
GPT vs BERT 的核心差异
| 模型 | 结构 | 训练任务 | 输入方式 | 主要用途 |
|---|---|---|---|---|
| BERT | Encoder | MLM + NSP | 双向 | 分类、抽取、匹配 |
| GPT | Decoder | 自回归语言建模 | 单向 | 生成类任务(文本生成) |
T5:Text-To-Text Transfer Transformer
T5 提出一种统一的 文本到文本 框架,将所有任务(分类、翻译、摘要等)都转换为文本生成问题。
- 输入输出都是文本字符串
- 训练数据包括翻译、问答、情感分类、摘要等任务
T5 的架构
T5 使用标准的 Transformer Encoder-Decoder 结构:
- 编码器读取输入文本
- 解码器逐步生成目标文本
这种设计统一了任务格式,利于大规模预训练与下游迁移。
T5 示例任务:
-
翻译:
- 输入:
translate English to German: That is good. - 输出:
Das ist gut.
- 输入:
-
分类:
- 输入:
sst2 sentence: This movie is great! - 输出:
positive
- 输入:
-
摘要:
- 输入:
summarize: The article discusses... - 输出:
Main idea is...
- 输入:
总结:从 Transformer 到大型语言模型
| 模型 | 核心结构 | 预训练方式 | 使用方向 |
|---|---|---|---|
| Transformer | Encoder-Decoder | 无预训练,原始结构 | 序列建模,翻译等 |
| BERT | Encoder 堆叠 | MLM + NSP | 理解类任务 |
| GPT | Decoder 堆叠 | 自回归语言建模 | 文本生成、对话系统 |
| T5 | Encoder-Decoder | 多任务文本到文本训练 | 通用性强,可迁移学习 |
Transformer 模型的出现彻底改变了 NLP 的范式:从 RNN 到 Attention,从编码器到预训练,从理解到生成,推动了大模型时代的来临。
这一系列模型均依赖 Transformer 架构的强大表达力,通过自注意力机制和深层堆叠结构,成功实现了语言理解与生成的统一建模。