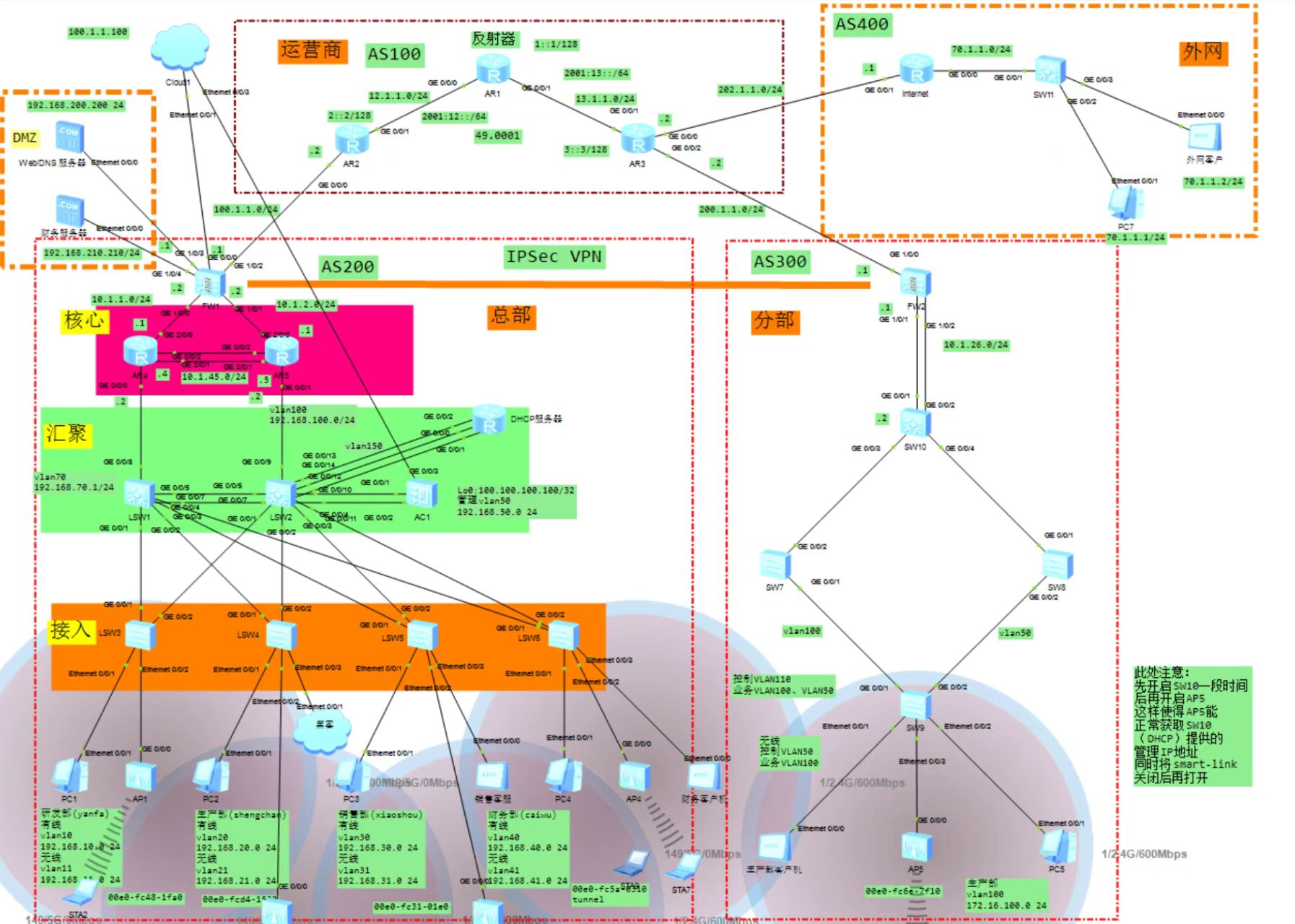
一、MongoDB高可用核心架构:副本集(Replica Set)设计
(一)副本集角色与拓扑结构
1. 三大核心角色
| 角色 | 职责描述 | 资源占用 | 选举权重 | 数据存储 |
|---|---|---|---|---|
| Primary | 唯一接收写请求的节点,将操作日志(Oplog)同步到Secondary节点 | 高 | 1 | 是 |
| Secondary | 异步复制Primary的Oplog,可提供读服务(默认只读) | 中 | 可配置 | 是 |
| Arbiter | 仅参与选举投票,不存储数据,解决偶数节点选举僵局 | 低 | 1 | 否 |
2. 典型部署拓扑(3节点+仲裁节点)
3. 节点配置示例(mongod.conf)
# Primary节点配置
replication:
replSetName: "rs0"
bindIp: 192.168.1.101
port: 27017
priority: 20 # 选举优先级(0-100,默认10)
# Secondary节点配置
replication:
replSetName: "rs0"
bindIp: 192.168.1.102
port: 27017
priority: 5
readOnly: true # 配置为只读节点
(二)自动故障转移机制
1. 选举流程解析
- 心跳检测:节点间通过
ping命令检测状态,默认每2秒发送一次心跳 - 故障判定:Primary节点超过
electionTimeoutMillis(默认10秒)未响应,触发选举 - 投票阶段:
- Secondary节点向其他节点发送选举请求
- 需获得**多数节点投票(N/2+1)**才能成为新Primary
- 角色切换:选举成功后,新Primary开始接收写请求,旧Primary降为Secondary
2. 防脑裂设计
- 多数派原则:3节点副本集允许1节点故障,5节点允许2节点故障
- 仲裁节点作用:在3节点集群中,仲裁节点不存储数据但参与投票,确保选举结果有效
# 添加仲裁节点命令 rs.addArb("192.168.1.103:27017")
二、数据同步与一致性控制
(一)Oplog机制深度解析
1. Oplog存储结构
- 本质:一个固定大小的环形缓冲区(默认大小为磁盘空间的5%,可通过
--oplogSize调整) - 存储位置:每个节点的
local.oplog.rs集合,记录所有写操作(插入、更新、删除) - 同步流程:
2. 初始同步(Initial Sync)
- 触发场景:新加入的Secondary节点或Oplog追赶超时
- 流程:
- 全量复制Primary数据(通过
mongodump/mongorestore) - 增量同步Oplog直至追上Primary
- 全量复制Primary数据(通过
(二)写入关注(Write Concern)与读关注(Read Concern)
1. 写入语义级别
| 级别 | 描述 | 一致性强度 | 延迟(ms) | 适用场景 |
|---|---|---|---|---|
w: 1 | 仅Primary确认写入成功 | 弱 | 1-5 | 非关键业务(如日志) |
w: majority | 多数节点(Primary+至少半数Secondary)确认写入 | 强 | 5-20 | 金融交易、订单系统 |
w: "majority" + j: true | 多数节点确认且写入磁盘持久化日志(Journal) | 最强 | 20-50 | 资产变更、事务性操作 |
2. 代码示例(Node.js驱动)
// 写入多数节点并等待持久化
db.collection.insertOne(
{ item: "book", qty: 10 },
{ writeConcern: { w: "majority", j: true, wtimeout: 5000 } } // 5秒超时
);
// 从Secondary节点读取数据(最终一致性)
db.collection.find({}).readConcern("local");
三、分片集群(Sharding)与水平扩展
(一)分片集群架构组件
1. 三大核心组件
| 组件 | 职责描述 | 高可用设计 |
|---|---|---|
| mongos | 查询路由节点,解析客户端请求并路由到对应Shard | 无状态,可部署多个实例 |
| Shard | 数据存储节点,每个Shard是一个副本集,负责存储部分数据 | 每个Shard至少3节点(1主2从) |
| Config Server | 存储元数据(分片键范围、Chunk分布、节点拓扑),支持副本集部署 | 3节点副本集,避免单点故障 |
2. 分片键设计原则
| 类型 | 示例 | 优势 | 劣势 |
|---|---|---|---|
| 哈希分片 | { user_id: "hashed" } | 数据均匀分布,适合高并发写入 | 范围查询性能差 |
| 范围分片 | { date: 1 } | 范围查询高效,适合时间序列数据 | 可能导致热点分片 |
3. 分片键配置示例
// 启用分片并设置哈希分片键
sh.addShard("rs0/192.168.1.101:27017,192.168.1.102:27017")
sh.enableSharding("mydb")
sh.shardCollection("mydb.orders", { user_id: "hashed" })
(二)自动负载均衡
1. 块(Chunk)管理
- 默认块大小:128MB,可通过
sh.config.settings调整 - 分裂条件:块数据量超过阈值或文档数超过平均值1.3倍
- 迁移流程:
2. 手动平衡控制
# 禁止自动平衡(维护期间)
sh.setBalancerState(false)
# 强制平衡指定数据库
sh.startBalancer("mydb")
四、读扩展与多数据中心部署
(一)读偏好(Read Preference)策略
1. 五种模式对比
| 模式 | 节点选择 | 一致性 | 适用场景 |
|---|---|---|---|
primary | 仅从Primary节点读取(默认) | 强一致 | 交易查询、实时数据 |
primaryPreferred | 优先Primary,故障时允许从Secondary读取 | 最终一致 | 高可用读扩展 |
secondary | 仅从Secondary节点读取 | 最终一致 | 报表生成、非实时分析 |
secondaryPreferred | 优先Secondary,故障时允许从Primary读取 | 最终一致 | 低优先级读请求 |
nearest | 选择网络延迟最低的节点(无论角色) | 最终一致 | 全球分布式部署 |
2. 代码示例(Java驱动)
MongoClient client = new MongoClient(
Arrays.asList(new ServerAddress("rs0/192.168.1.101:27017")),
new ReadPreference(ReadPreferenceMode.SECONDARY_PREFERRED)
);
(二)跨机房容灾部署
1. 三机房部署拓扑
2. 节点优先级配置
// 配置机房A节点为高优先级
rs.conf().members[0].priority = 20
rs.reconfig(rs.conf())
// 配置机房B/C节点为低优先级(仅用于读)
rs.conf().members[1].priority = 5
rs.conf().members[2].priority = 5
五、运维监控与故障处理
(一)关键运维命令
1. 副本集状态检查
rs.status() # 查看节点角色、同步延迟、选举状态
rs.printReplicationInfo() # 查看Oplog使用情况
2. 手动故障转移
# 强制主节点降级(需在Secondary节点执行)
rs.stepDown(60) # 60秒内禁止该节点重新选举
# 紧急切换主节点(绕过选举)
rs.reconfig({
_id: "rs0",
members: [
{ _id: 0, host: "192.168.1.102:27017", priority: 20 },
{ _id: 1, host: "192.168.1.101:27017", priority: 5 }
]
}, { force: true })
(二)核心监控指标
| 指标名称 | 采集方式 | 健康阈值 | 告警处理 |
|---|---|---|---|
| 副本集状态 | rs.status().ok | 1(所有节点在线) | 检查故障节点网络/磁盘 |
| Oplog剩余空间比例 | db.oplog.rs.stats().spaceUsed | >20% | 扩容Oplog或清理历史操作 |
| 选举次数/小时 | 日志分析 | <3次/小时 | 排查网络波动或节点性能问题 |
| 写入延迟(w:majority) | 慢查询日志 | <50ms | 优化写入语义或增加节点资源 |
六、数据备份与恢复策略
(一)逻辑备份(mongodump)
1. 全量备份
# 备份单个数据库
mongodump -h rs0/192.168.1.101:27017 -d mydb -o /backup/mydb_$(date +%Y%m%d)
# 备份分片集群(通过mongos路由)
mongodump -h mongos:27017 -d mydb --sharded
2. 增量备份(基于Oplog)
# 导出Oplog日志
mongodump -d local -c oplog.rs --query '{"ts": {"$gt": ISODate("2023-10-01T00:00:00Z")}}'
(二)物理备份(文件系统快照)
1. 操作步骤
# 1. 锁定数据库(阻止写操作)
db.fsyncLock()
# 2. 执行快照(如LVM快照或云盘快照)
lvcreate -L 10G -s /dev/mapper/vol_es -n vol_es_snap
# 3. 解锁数据库
db.fsyncUnlock()
2. 云服务集成(AWS示例)
# 使用MongoDB Atlas自动备份
1. 在Atlas控制台启用连续备份(默认保留7天)
2. 通过API恢复至指定时间点:
atlas clusters restore --clusterId=cluster1 --snapshotId=snapshot_123
七、高可用最佳实践与场景适配
(一)金融交易场景
1. 架构设计
- 副本集配置:5节点(3数据节点+2仲裁节点),
writeConcern: {w: "majority", j: true} - 分片策略:哈希分片键
user_id,每个Shard独立副本集 - 监控重点:Oplog延迟、选举频率、事务冲突率
2. 故障恢复流程

(二)电商订单场景
1. 性能优化
- 读偏好:
secondaryPreferred,分流60%读请求到从节点 - 分片键:
order_date范围分片,提升按日期查询效率 - 索引优化:对
status、user_id创建复合索引
2. 容灾演练
# 模拟主节点故障
ssh primary-node "sudo service mongod stop"
# 验证故障转移
rs.status().primary.should.be("secondary-node-1:27017")
# 恢复原主节点
sudo service mongod start
rs.status().primary.should.be("secondary-node-1:27017") # 原主节点降为从节点
八、面试核心考点与应答策略
(一)基础问题
-
Q:MongoDB如何实现高可用?
A:通过副本集(Replica Set)实现自动故障转移,至少3节点(1主2从或含仲裁节点),利用Oplog同步数据,结合分片集群实现水平扩展。 -
Q:仲裁节点的作用是什么?
A:仲裁节点不存储数据,仅参与选举投票,解决偶数节点的选举僵局,例如3节点集群中仲裁节点可确保多数派投票有效。
(二)进阶问题
-
Q:如何保证数据不丢失?
A:- 设置写入关注
writeConcern: {w: "majority", j: true},确保数据写入多数节点并持久化到磁盘 - 定期备份(mongodump + 快照),结合Oplog实现点恢复
- 设置写入关注
-
Q:分片集群中如何避免热点分片?
A:- 选择哈希分片键(如用户ID哈希)实现数据均匀分布
- 监控块分布,通过
sh.rebalanceShard()手动迁移热点块 - 启用自动平衡器(默认开启),设置合理块大小(如256MB)
(三)架构设计问题
Q:设计一个支持全球部署的高可用MongoDB集群,你会考虑哪些因素?
回答思路:
- 多数据中心部署:每个区域部署独立副本集,通过
priority配置优先选举本地节点 - 读写分离:使用
nearest读偏好降低跨区域延迟 - 数据同步:跨区域副本集通过异步复制(如AWS Direct Connect)同步数据
- 容灾切换:配置DNS切换策略,结合客户端驱动自动重定向
- 监控覆盖:跨区域延迟、Oplog滞后、节点心跳状态
九、总结:高可用架构的三维保障模型
(一)数据冗余层
- 副本集:至少3节点,确保数据多副本存储
- 分片集群:每个Shard独立副本集,实现双重高可用
(二)故障容错层
- 自动选举:基于Raft变种协议,10秒内完成主节点切换
- 客户端适配:驱动自动重定向(如MongoDB Java Driver支持拓扑感知)
(三)运维保障层
- 监控体系:Prometheus+Grafana采集节点指标(如
mongodb_oplog_window) - 备份策略:逻辑备份+物理快照+云服务集成,满足RPO/RTO要求




![[Dify] 如何应对明道云API数据过长带来的Token超限问题](https://i-blog.csdnimg.cn/direct/bc8af2b52f824fc8b23621e6504fc4be.png)

![[Godot][游戏开发] 如何在 Godot 中配置 Android 环境(适配新版 Android Studio)](https://i-blog.csdnimg.cn/direct/ce93c81563624b849c8d313b6f8033e0.png)