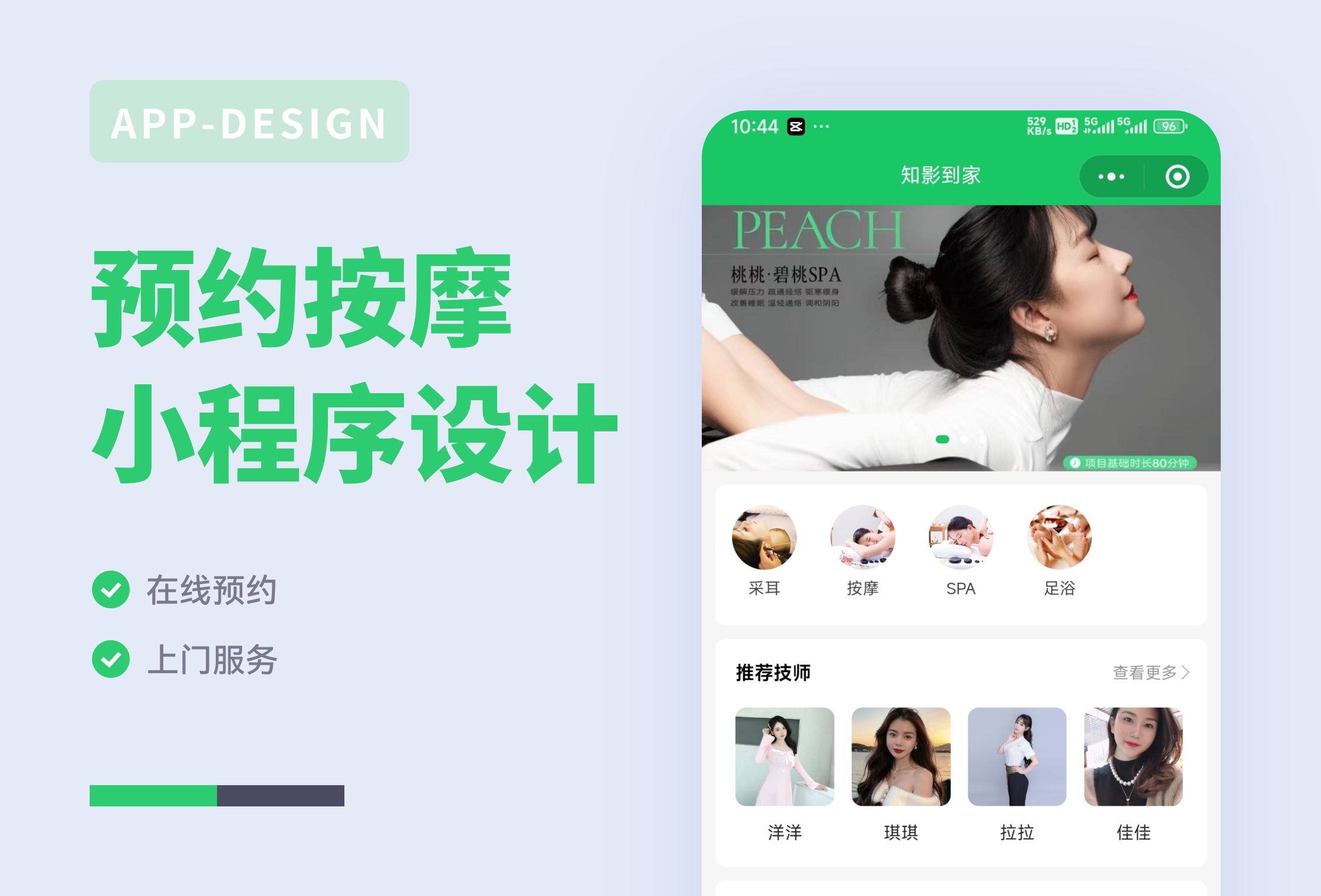
先看效果
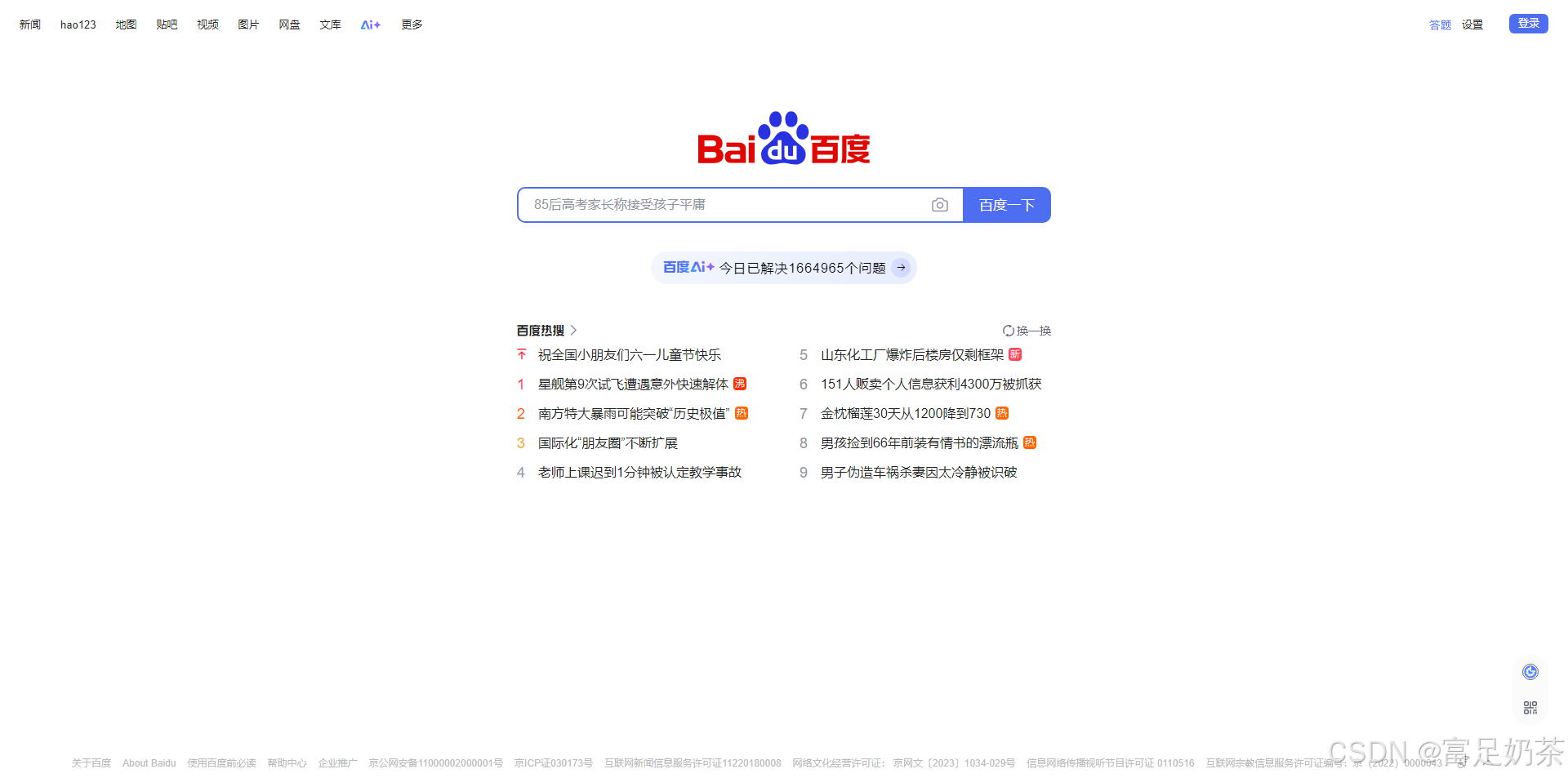
程序实现的功能为:截取目标网址对应的页面,并将截取后的页面图片返回到用户端,用户可自由保存该截图。
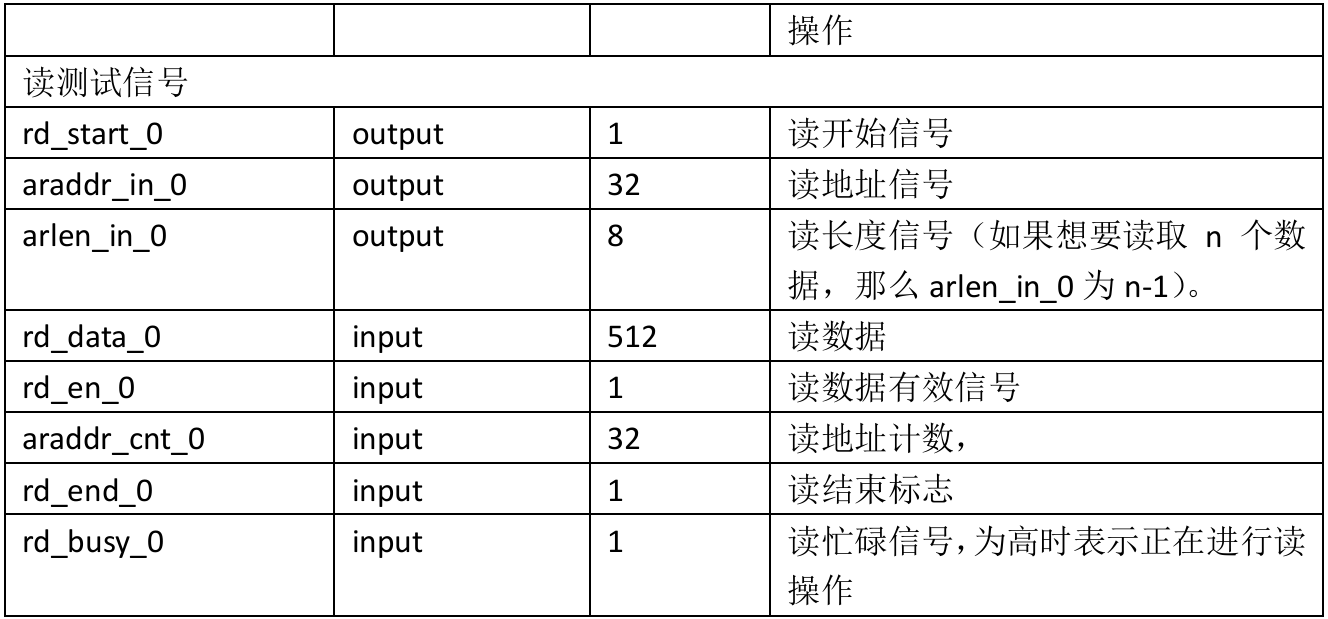
支持的url参数如下:
url:目标网址(必填项),字符串类型,如:https://www.baidu.com
w:截图宽度(选填项),默认为浏览器的可视窗口宽度,数值类型
h:截图高度(选填项),默认为浏览器的可视窗口高度(包含滚动区域),数值类型
p:截取的屏幕数量,默认为全部(选填项),数值类型
offset:最后一屏的偏差高度,默认为 0(选填项),数值类型
headless:是否打开浏览器,默认为 静默运行(选填项),两者的区别如下:
显式运行:截图更精确,但占用的系统资源相对多一点。
静默运行:在截图精度上有一点丢失(肉眼几乎看不出),但占用更少的系统资源。
最简请求示例:
以静默状态截取百度首页
http://127.0.0.1:8181/?url=https://www.baidu.com
完整请求示例:
以显式状态按指定的宽高截取百度首页
http://127.0.0.1:8181/?url=https://www.baidu.com&w=800&h=500&p=1&offset=0&headless=0
实现代码
import io
import os
import time
import logging
from uuid import uuid4
from PIL import Image
from screeninfo import get_monitors
from flask import Flask, request, send_file
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# 网页截图存储目录
image_folder = "static"
app = Flask(__name__)
# 禁止控制台输出请求信息
logging.getLogger('werkzeug').disabled = True
# 设置总的日志输出级别
app.logger.setLevel(logging.ERROR)
# 404错误处理
@app.errorhandler(404)
def page_not_found(e):
# 直接返回字符串
return "您请求的资源不存在!", 404
# 500错误处理
@app.errorhandler(500)
def internal_error(e):
return "服务器内部错误!", 500
# 捕获所有未处理异常
@app.errorhandler(Exception)
def handle_exception(e):
return "发生错误,请稍后再试!", 500
@app.route('/')
def process_request():
url = request.args.get('url')
if not url:
return '无效的请求参数!'
args = request.args
# 截取的屏数,默认为全部
pages = int(args.get('p', 0))
# 最后一屏的偏差高度
offset_height = int(args.get('offset', 0))
# 默认使用无头模式,headless=0 表示使用有头模式
headless = args.get('headless')
# 捕获网页截图
img_file = init(url, pages, offset_height, headless)
if img_file is None:
return '网页截取失败!'
# 调整图片尺寸
img = Image.open(img_file)
(width, height) = get_image_size(img, args.get('w'), args.get('h'))
# 高质量抗锯齿
img = img.resize((width, height), Image.Resampling.LANCZOS)
# 转换为字节流返回
img_io = io.BytesIO()
img.save(img_io, 'PNG')
img_io.seek(0)
return send_file(img_io, mimetype='image/png')
def init(url, pages=0, offset_height=0, headless=None):
chrome_options = webdriver.ChromeOptions()
# 截图时建议关闭无头模式
if headless is None:
chrome_options.add_argument('--headless=new')
chrome_options.add_argument('log-level=3')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--disable-infobars')
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_experimental_option('excludeSwitches', ['enable-logging', 'enable-automation'])
service = Service()
service.path = 'ChromeV123/chromedriver.exe'
chrome_options.binary_location = 'ChromeV123/chrome-win64/chrome.exe'
driver = webdriver.Chrome(options=chrome_options, service=service)
if headless is None:
# 无头模式需要设置窗口尺寸
set_window_size(driver)
else:
driver.maximize_window()
try:
driver.get(url)
time.sleep(2)
file_name = capture_full_page(driver, pages, offset_height)
finally:
driver.quit()
return file_name
# 设置浏览器窗口宽高
def set_window_size(driver):
primary_monitor = get_monitors()[0]
width = primary_monitor.width + 16
height = primary_monitor.height - 31
driver.set_window_size(width, height)
'''
截取整个网页,包含滚动部分,保存路径为当前项目的{image_folder}/screenshot目录下
pages 截取的屏数,默认为全部
offset_height 偏差纠正,处理最后一屏的特殊参数,需传入合适的数值(注意:无头模式和界面模式该参数值可能是不同的)
'''
def capture_full_page(driver, pages=0, offset_height=0):
file_name = None
try:
date = time.strftime("%Y%m%d", time.localtime(time.time()))
root_path = f'{image_folder}/screenshot/{date}'
if not os.path.exists(root_path):
os.makedirs(root_path)
file_name = '{}/{}.png'.format(root_path, uuid4())
# 获取网页可视区域宽高
inner_width = driver.execute_script("return window.innerWidth")
inner_height = driver.execute_script("return window.innerHeight")
# 获取网页高度
height = get_page_height(driver, pages)
# 滚动截图,创建一个指定宽高的白色背景,用于在上面拼接图片
screenshot = Image.new('RGB', (inner_width, height if pages == 0 else min(inner_height*pages, height)), (255, 255, 255))
scroll_total = 0
num = 0
# 每次滚动一屏,一屏的高度为 inner_height
for scroll_height in range(0, height, inner_height):
if pages > 0 and num >= pages:
break
driver.execute_script("window.scrollTo(0, %d)" % scroll_height)
time.sleep(0.5)
screenshot_part = driver.get_screenshot_as_png()
img = Image.open(io.BytesIO(screenshot_part))
screenshot.paste(img, (0, scroll_height, img.width, scroll_height + img.height))
scroll_total = scroll_height
num += 1
# 最后一屏需要特殊处理
if scroll_total > 0 and scroll_total < height and height-scroll_total < inner_height:
driver.execute_script(f"window.scrollTo(0, {height})")
time.sleep(0.5)
# 截取剩余区域
img_file = capture_region(driver, 0, inner_height - (height - scroll_total) - offset_height, inner_width, inner_height)
if img_file is not None:
img = Image.open(img_file)
screenshot.paste(img, (0, scroll_total, img.width, scroll_total + img.height))
os.remove(img_file)
# 保存截图
screenshot.save(file_name)
except:
pass
return file_name
'''
截取指定区域,保存路径为当前项目的screenshot/region目录下
left_top_x 左上角X轴坐标
left_top_y 左上角Y轴坐标
right_bottom_x 右下角X轴坐标
right_bottom_y 右下角Y轴坐标
'''
def capture_region(driver, left_top_x, left_top_y, right_bottom_x, right_bottom_y):
try:
date = time.strftime("%Y%m%d", time.localtime(time.time()))
root_path = f'{image_folder}/screenshot/{date}'
if not os.path.exists(root_path):
os.makedirs(root_path)
file_name = '{}/{}.png'.format(root_path, uuid4())
screenshot = driver.get_screenshot_as_png()
img = Image.open(io.BytesIO(screenshot))
region = img.crop((left_top_x, left_top_y, right_bottom_x, right_bottom_y))
region.save(file_name)
return file_name
except Exception:
pass
return None
# 计算图片宽高
def get_image_size(img, target_width=None, target_height=None):
original_width, original_height = img.size
# 默认为图片原始宽高
if not target_width and not target_height:
return (original_width, original_height)
# 计算目标尺寸
if target_width and target_height:
# 情况1:指定宽高参数
crop_width = min(int(target_width), original_width)
crop_height = min(int(target_height), original_height)
elif target_width:
# 情况2:仅指定宽度,高度按比例计算
crop_width = min(int(target_width), original_width)
crop_height = int(original_height * (crop_width / original_width))
else:
# 情况3:仅指定高度,宽度按比例计算
crop_height = min(int(target_height), original_height)
crop_width = int(original_width * (crop_height / original_height))
return (crop_width, crop_height)
# 获取页面实际高度(包含滚动区域)
def get_page_height(driver, pages):
last_scroll_height = 0
# 获取浏览器可视窗口高度
inner_height = driver.execute_script("return window.innerHeight")
total_height = inner_height
num = 0
while True:
if pages > 0 and num >= pages+1:
break
scroll_height = driver.execute_script("return window.scrollY") + inner_height
if scroll_height == last_scroll_height:
break
last_scroll_height = scroll_height
# 之所以每次滚动一屏,是因为某些网站的图片资源,只有在滚动到当前可视窗口时,才会加载出来
driver.execute_script(f"window.scrollTo(0, {total_height})")
total_height += inner_height
num += 1
time.sleep(2)
return last_scroll_height
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8181)🏷️ 如有疑问,可以关注 我的知识库,直接提问即可。