文章目录
- 前言
- 一、核心参数全景解析
- 1.1 基础网络层参数
- 1.2 内存管理参数
- 1.3 水位线控制
- 1.4 高级参数与系统级优化
- 二、生产级优化策略
- 2.1 高并发场景优化
- 2.2 低延迟场景优化
- 总结
前言
在分布式系统和高并发场景中,Netty作为高性能网络通信框架的核心地位无可替代。但仅仅掌握基础API远远不够,参数的精细化配置直接决定了系统能否从"能用"跃升到"好用"。本文将从核心参数解析入手,结合真实生产案例,揭示Netty性能优化的底层逻辑与实践经验。
一、核心参数全景解析
Netty的参数配置体系是其高性能的核心支撑,涉及网络协议栈、内存管理、流量控制等多个维度。以下从三个核心模块展开深度解析:
1.1 基础网络层参数
这些参数直接影响TCP连接的建立、数据传输效率及资源利用率,需结合操作系统层配置进行优化。
- SO_BACKLOG
- 作用域: ServerChannel(服务端)
- 默认值: 128
- 生产建议值: 4096+
- 核心作用:定义已完成三次握手但未被应用层Accept的连接队列长度(即accept队列)。当并发连接请求突增时,若队列满,新连接将被拒绝。
- 深度陷阱:
- 操作系统限制: 实际生效值取min(SO_BACKLOG, net.core.somaxconn)。需同步修改系统参数: sysctl -w net.core.somaxconn=65535。
- 洪峰场景: 在秒杀、IM登录等场景中,建议设置为max_expected_connections × 1.2。
- SO_REUSEADDR
- 作用域: ServerChannel
- 默认值: false
- 生产建议值: true
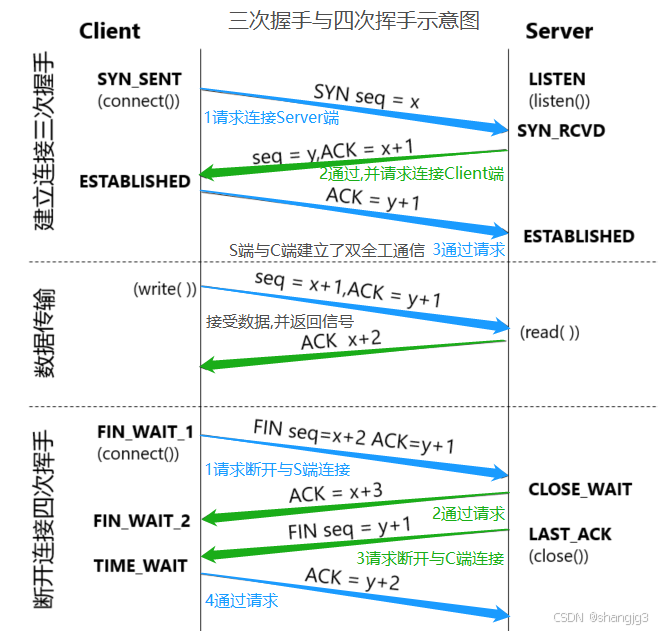
- 核心作用:允许绑定处于TIME_WAIT状态的端口,解决服务重启时因端口未释放导致的绑定失败问题。
- 底层原理:
- TIME_WAIT是TCP四次挥手的正常状态,持续2MSL(默认60秒)。
- 启用后,新连接可复用处于TIME_WAIT状态的端口,避免服务重启等待。
- TCP_NODELAY
- 作用域: SocketChannel
- 默认值: true
- 生产建议值: 保持true(特殊场景例外)
- 核心作用:禁用Nagle算法,避免小数据包合并延迟。
- 适用场景:
- 实时性要求高的场景(如游戏指令、金融交易)必须开启。
- 日志传输等可容忍延迟的场景可关闭以降低包数量。
- SO_KEEPALIVE
- 作用域: SocketChannel
- 默认值: false
- 生产建议值: 按需开启(建议配合应用层心跳)
- 核心作用:开启TCP层心跳探测,自动检测死连接。
- 注意事项:
- 探测间隔依赖系统参数(如Linux的tcp_keepalive_time,默认7200秒)
- 生产建议:
// 应用层自定义心跳协议,更精准控制
pipeline.addLast(new IdleStateHandler(60, 0, 0)); // 60秒读空闲检测
1.2 内存管理参数
Netty的零拷贝与内存池设计是其性能优势的关键,参数配置直接影响GC压力与内存利用率。
- ByteBufAllocator
- 核心实现类:
- PooledByteBufAllocator(默认启用池化)
- UnpooledByteBufAllocator(非池化,测试用)
- 生产配置示例:
// 显式配置内存分配器
bootstrap.option(ChannelOption.ALLOCATOR, new PooledByteBufAllocator(
true, // 优先堆外内存(DirectByteBuffer)
16, // 堆外Arena数量(通常设为CPU核心数)
16, // 堆内Arena数量(按需调整)
8192, // Page大小(默认8KB,大文件传输可调大)
11, // 内存树层级(影响小对象分配效率)
false // 禁用线程本地缓存(高并发下减少内存碎片)
));
- 内存结构解析:
- Arena:内存分配区域,每个EventLoop绑定一个Arena,避免锁竞争。
- Chunk:Arena内部分为多个16MB的Chunk,是内存申请的基本单位。
- Page:Chunk进一步拆分为8KB的Page,用于中小型对象分配。
- 关键调优点:
- 线程本地缓存(ThreadLocalCache):高并发下线程频繁创建/销毁时,缓存会导致内存碎片。通过JVM参数关闭:
-Dio.netty.allocator.useCacheForAllThreads=false - 内存泄漏检测:开启PARANOID级别检测,对所有对象进行跟踪,并定期输出可疑日志(性能损耗大,仅调试使用):
-Dio.netty.leakDetection.level=PARANOID
- 线程本地缓存(ThreadLocalCache):高并发下线程频繁创建/销毁时,缓存会导致内存碎片。通过JVM参数关闭:
1.3 水位线控制
通过写缓冲区水位实现背压(Backpressure)机制,防止生产者压垮消费者。
- 水位线参数
- 设置方式:
// 设置高低水位线(单位:字节)
channel.config().setWriteBufferWaterMark(
new WriteBufferWaterMark(32 * 1024, 64 * 1024)
);
- 触发机制:
- 低水位线(32KB):当缓冲区数据量低于此值时,channel.isWritable()返回true。
- 高水位线(64KB):超过此值时,触发channelWritabilityChanged事件,应暂停写入。
- 流量控制策略
- 动态调整:根据消息体大小动态设置水位差。
// 假设最大消息体为10KB
int maxMessageSize = 10 * 1024;
waterMarkLow = maxMessageSize * 2; // 20KB
waterMarkHigh = maxMessageSize * 4; // 40KB
- 事件处理:
public void channelWritabilityChanged(ChannelHandlerContext ctx) {
if (!ctx.channel().isWritable()) {
// 1. 记录堆积日志
// 2. 暂停消息生产(如关闭消息监听)
// 3. 设置监听器恢复生产
ctx.channel().flush().addListener(future -> {
if (future.isSuccess()) {
resumeMessageProduction();
}
});
}
}
1.4 高级参数与系统级优化
- Epoll参数(Linux专属)
- 启用Epoll:
EventLoopGroup group = new EpollEventLoopGroup();
- 关键参数:
- EPOLLET(边缘触发模式):需配合Channel.read()手动触发读取。
- SO_REUSEPORT:允许多进程绑定相同端口,提升连接处理能力。
- 系统参数调优
- 文件描述符限制: ulimit -n 1000000 # 设置单个进程最大文件描述符数
- TCP缓冲区调整:
sysctl -w net.ipv4.tcp_rmem="4096 87380 16777216" # 读缓冲区
sysctl -w net.ipv4.tcp_wmem="4096 65536 16777216" # 写缓冲区
通过精准配置这些参数,可让Netty在百万级并发场景下仍保持毫秒级响应。实际生产中需结合APM工具(如SkyWalking)持续观测,形成“配置→压测→监控→调优”的闭环。
二、生产级优化策略
2.1 高并发场景优化
典型场景:IM消息推送、金融交易行情分发
- 连接风暴防御
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.option(ChannelOption.SO_BACKLOG, 8192) // 需同步调整系统参数
.childOption(ChannelOption.SO_REUSEADDR, true) // 快速端口复用
.childOption(ChannelOption.RCVBUF_ALLOCATOR,
new AdaptiveRecvByteBufAllocator(1024, 8192, 65536)); // 动态缓冲区
关键技术点:
- 动态缓冲区扩容:
AdaptiveRecvByteBufAllocator根据历史读取数据量自动调整缓冲区大小,避免固定大小导致的内存浪费或频繁扩容。 - 连接限流:
在ChannelInitializer中实现令牌桶算法,拒绝超额连接:
pipeline.addLast(new ConnectionRateLimiter(1000)); // 每秒最多1000新连接
- 线程模型调优
EventLoopGroup bossGroup = new EpollEventLoopGroup(2); // 专用物理核
EventLoopGroup workerGroup = new EpollEventLoopGroup(16); // 超线程数×2
// 业务线程池隔离(避免阻塞EventLoop)
ExecutorService businessExecutor = Executors.newFixedThreadPool(32);
pipeline.addLast(businessExecutor, new BusinessHandler());
关键技术点:
- IO与计算分离:耗时操作(如加解密、DB访问)必须提交到独立线程池。
- Epoll优势:相比NIO,Epoll在万级连接下减少100+系统调用/秒。
- 内存分配策略
// 显式配置内存分配器
ByteBufAllocator allocator = new PooledByteBufAllocator(
true, // 优先堆外内存
false, // 禁用线程本地缓存
16, // Arena数量=CPU核心数
16,
8192, // Page大小
10
);
bootstrap.option(ChannelOption.ALLOCATOR, allocator);
关键技术点:
- 内存预分配:启动时预热内存池,避免运行时分配延迟:
ByteBuf buffer = allocator.buffer(1024);
buffer.release(); // 触发Chunk预分配
- 泄漏检测:生产环境开启SIMPLE级别检测:
-Dio.netty.allocator.type=pooled
-Dio.netty.leakDetection.level=SIMPLE
2.2 低延迟场景优化
典型场景:高频交易系统、实时竞技游戏
- 写队列优化
// 禁用自动读取,手动控制流速
channel.config().setAutoRead(false);
// 动态水位线调整(根据网络状况)
channel.config().setWriteBufferWaterMark(
new WriteBufferWaterMark(8 * 1024, 32 * 1024)
);
// 优先发送高优先级消息
public void channelWritabilityChanged(ChannelHandlerContext ctx) {
if (ctx.channel().isWritable()) {
sendHighPriorityMessagesFirst();
}
}
关键技术点:
- 精细化流量控制:根据RTT(Round-Trip Time)动态调整水位线。
- 消息优先级队列:实现自定义的MessagePriorityComparator排序待发送消息。
- 零拷贝优化
// 文件传输零拷贝
FileRegion region = new DefaultFileRegion(file, 0, file.length());
channel.writeAndFlush(region);
// CompositeByteBuf合并小包(底层采用编排)
ByteBuf header = allocator.directBuffer(16);
ByteBuf body = allocator.directBuffer(128);
CompositeByteBuf composite = Unpooled.wrappedBuffer(header, body);
channel.writeAndFlush(composite);
关键技术点:
- sendfile系统调用:通过FileRegion直接在内核态完成文件数据传输。
- 内存复用:使用CompositeByteBuf合并协议头与业务数据,避免数据复制。
总结
Netty参数优化是一门平衡的艺术,需要结合具体业务特征进行持续调优。建议在生产环境中建立完善的监控体系,重点关注:
- 内存分配速率(PooledByteBufAllocator.metric())
- 事件循环时延(EventLoop.getPendingTasks())
- TCP重传率(通过ss -ti命令观测)
优化永无止境,只有深入理解每个参数背后的网络原理,才能让Netty真正释放出百万级并发的潜力。
下期预告:基于Netty构建高性能IM系统——从零实现万人聊天室





![[特殊字符]《Qt实战:基于QCustomPlot的装药燃面动态曲线绘制(附右键菜单/样式美化/完整源码)》](https://i-blog.csdnimg.cn/direct/221b201d8c6049afa7fa8767fdb193f4.png)

![[免费]微信小程序宠物医院管理系统(uni-app+SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】](https://i-blog.csdnimg.cn/direct/6e930f3dde3c4f2bb9cf4501c8642e1c.jpeg)