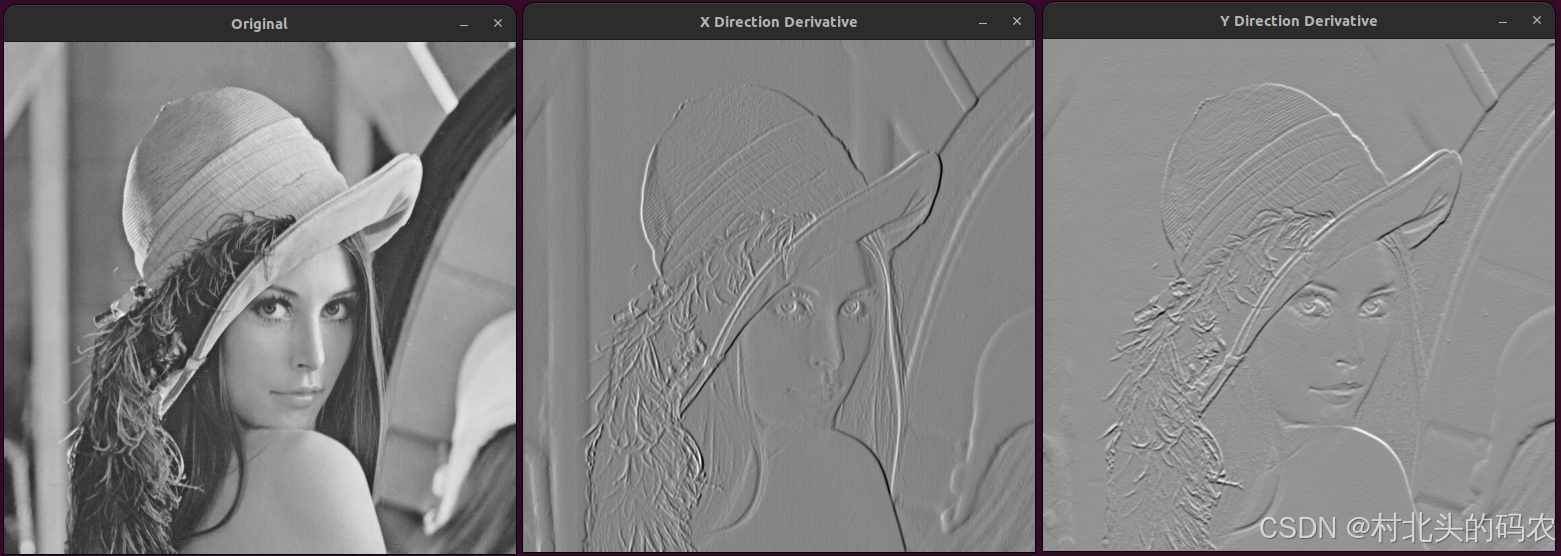
DeepSpeed-Ulysses:支持极长序列 Transformer 模型训练的系统优化方法
flyfish
名字 Ulysses
“Ulysses” 和 “奥德修斯(Odysseus)” 指的是同一人物,“Ulysses” 是 “Odysseus” 的拉丁化版本
《尤利西斯》(詹姆斯·乔伊斯著,1922年出版)
以古希腊英雄奥德修斯(拉丁名“尤利西斯”)的神话为框架,将故事置于现代(20世纪初)的都柏林,通过三位主角一天内的经历,映射奥德修斯的十年漂泊。
奥德修斯(古希腊神话核心人物)
奥德修斯是古希腊城邦伊萨卡的国王,以智慧著称(如“特洛伊木马”计策的设计者)。特洛伊战争结束后,他因触怒海神波塞冬,踏上长达十年的返乡漂泊,故事集中于《奥德赛》(荷马史诗)。
“DeepSpeed-Ulysses”的借用“奥德修斯/尤利西斯”的“长途探索与克服挑战”意象,象征长序列模型训练的技术突破。
长序列Transformer模型训练是指针对输入序列长度极长(如包含数万至百万级 tokens)的Transformer模型进行优化训练的过程,其核心挑战在于平衡计算效率、内存使用和通信开销。
一、长序列Transformer模型的定义与应用场景
1. 模型特征
Transformer模型以自注意力机制为核心,传统模型的序列长度通常限制在数千tokens(如512或2048),而长序列模型需处理远超这一范围的输入。其计算复杂度随序列长度呈二次增长(注意力计算需遍历所有token对),导致训练时内存占用和通信开销剧增。
2. 关键应用领域
- 生成式AI:
- 对话系统:处理长对话历史(需支持多轮交互的上下文)。
- 长文档处理:对书籍、学术论文等进行摘要生成(序列长度可达数万词)。
- 多模态任务:视频生成、语音识别等需处理时空维度的长序列输入。
- 科学AI:
- 基因组学:分析人类基因组的64亿碱基对序列。
- 气候预测:处理长时间序列的气象数据。
- 医疗诊断:基于患者全病程记录的预测模型。
二、长序列训练的核心挑战
1. 内存与通信效率瓶颈
- 激活值内存爆炸:Transformer的中间激活值(如注意力计算中的QKV张量)随序列长度平方增长,单GPU内存无法容纳极长序列。
- 通信开销线性增长:现有序列并行方法(如Megatron-LM)在注意力计算时需进行全聚集(all-gather)通信,通信量随序列长度线性增加,导致训练效率随序列长度下降。
2. 现有并行技术的局限性
- 数据/张量/流水线并行不适用:这些并行方式分别针对批量大小、隐藏维度、模型层数优化,但未考虑序列维度的划分,无法解决长序列特有的内存和通信问题。
- 传统序列并行方法低效:如ColAI-SP采用环形通信,Megatron-LM依赖全聚集操作,均无法在扩展序列长度时保持通信效率,且需大量代码重构。
DeepSpeed-Ulysses解决长序列Transformer模型训练难题的方案
DeepSpeed-Ulysses针对长序列Transformer训练的四大核心创新,可拆解为数据划分策略、通信原语重构、内存分层优化、注意力模块化设计四大技术模块
DeepSpeed-Ulysses通过序列分片解耦计算与存储、全对全通信重构带宽效率、ZeRO-3扩展内存边界、注意力抽象层屏蔽多样性,形成了从硬件通信到算法逻辑的端到端优化。
一、序列维度数据划分:动态分片与负载均衡
1. 分片粒度设计
- 均匀切分:将输入序列按长度均分为P份(P为GPU数),每个GPU处理
N/Ptokens(如N=1M,P=64时,单卡处理15,625 tokens),确保计算负载均衡。 - 细粒度对齐:结合注意力头数(H),将每个分片的QKV张量按头维度切分,实现“序列分片×头分片”的二维并行(如H=32,P=8时,每卡处理4个头的完整序列分片),避免头间通信冗余。
2. 分片生命周期管理
- 前向传播:分片在嵌入层后立即生成,贯穿注意力计算全流程,减少中间复制开销。
- 反向传播:梯度按分片聚合,通过通信原语自动对齐,无需显式分片重组(对比Megatron-LM需手动拼接梯度)。
二、通信原语重构:全对全替代全聚合
1. 两次全对全(All-to-All)通信
- 第一次All-to-All(QKV收集):
- 输入:各GPU持有
(N/P, b, d)的Q/K/V分片(b为微批量,d为隐藏维度)。 - 操作:通过高效的NVLink/IB网络,交换分片形成
(N, b, d/P)的全局QKV(每个GPU获取完整序列的1/P头数据)。 - 优势:通信量为
3Nh/P(h为头维度),对比Megatron-LM的全聚合(3Nh)减少P倍。
- 输入:各GPU持有
- 第二次All-to-All(结果分发):
- 输入:注意力计算后的
(N, b, d/P)输出。 - 操作:重组为
(N/P, b, d)分片,供后续MLP层处理,通信量Nh/P。 - 总通信量:
4Nh/P,复杂度O(N/P),当N与P同比增长时保持恒定(如N×2,P×2,通信量不变)。
- 输入:注意力计算后的
2. 通信拓扑优化
- 节点内NVSwitch优先:利用GPU间高速互联,将All-to-All拆分为节点内(低延迟)和节点间(高带宽)两阶段,实测减少通信时间
- 异步通信隐藏延迟:在注意力计算前预启动通信,与计算重叠(如FlashAttention的分块计算与通信流水线)。
三、内存分层优化:ZeRO-3×序列并行
1. 参数分片策略
- 跨组划分:ZeRO-3原仅在数据并行组(DP组)分片参数,Ulysses扩展至DP组×序列并行组(SP组),形成二维分片(如DP=8,SP=8时,每个参数被分为64片)。
- 动态聚合:仅在参数更新时,通过All-Gather收集分片梯度,平时仅保留本地分片,显存占用降低
DP×SP倍。
2. 激活内存压缩
- 分片激活:每个GPU仅存储
N/Ptokens的激活值,总激活内存从O(N²)降至O((N/P)²),支持N=1M时单卡激活内存仅为全序列的1/64(P=64)。 - 与激活重计算协同:结合FlashAttention的分块重计算,进一步将激活内存降至O(N/P)。
四、注意力模块化设计:统一接口与动态适配
1. 注意力计算抽象层
- 输入标准化:无论密集/稀疏,输入均为
(N, b, d/P)的分片QKV(N为全局序列长度)。 - 头级并行:每个GPU负责H/P个头的完整注意力计算,支持任意头数分片(如H=96,P=8时每卡12头)。
- 输出重组:通过第二次All-to-All自动对齐头维度,屏蔽底层注意力实现差异。
2. 稀疏注意力特化优化
- 块对角通信:针对滑动窗口等稀疏模式,仅交换相邻分片的K/V,通信量进一步降至O(N/P×W)(W为窗口大小)。
- 与Blockwise Attention协同:支持将序列划分为块,块内全连接、块间稀疏连接,通信量减少70%(对比全局密集)。
3. 兼容性验证
- FlashAttention v2集成:通过分片QKV直接输入FlashAttention内核,实测长序列(N=512K)吞吐量提升1.8倍
- 稀疏模式扩展:支持BigBird的全局+局部混合注意力,无需修改通信逻辑,仅替换注意力计算函数
五、工程实现细节:易用性与扩展性
1. 代码侵入性
- 零修改集成:仅需在模型定义中添加
@sequence_parallel装饰器,自动替换原生Attention为分布式版本 - 并行组抽象:自动管理DP/SP组的创建与销毁,用户无需显式管理通信域。
2. 故障恢复机制
- 分片检查点:仅保存本地分片参数,检查点大小减少
DP×SP倍,支持1024卡集群下30B模型的快速恢复
注意力集成
DeepSpeed-Ulysses通过优化多种注意力机制,系统性解决了长序列Transformer训练的效率瓶颈。
一、自注意力(Self-Attention)
1. 密集自注意力(Dense Self-Attention)
-
数学公式:
Attention ( Q , K , V ) = Softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=Softmax(dkQKT)V
其中:- Q ∈ R N × d Q \in \mathbb{R}^{N \times d} Q∈RN×d, K ∈ R N × d K \in \mathbb{R}^{N \times d} K∈RN×d, V ∈ R N × d V \in \mathbb{R}^{N \times d} V∈RN×d
- N N N 为序列长度, d d d 为隐藏维度
-
解决的问题:
- 传统实现瓶颈:计算复杂度 O ( N 2 ) O(N^2) O(N2) 和内存占用 O ( N 2 ) O(N^2) O(N2),难以处理超长序列(如 N > 10 k N > 10k N>10k)
- DeepSpeed-Ulysses优化:
- 通过序列并行(Sequence Parallelism)将 N N N 划分为 N / P N/P N/P( P P P 为GPU数)
- 两次All-to-All通信将计算复杂度降至 O ( N / P ) O(N/P) O(N/P)(
2. 稀疏自注意力(Sparse Self-Attention)
-
数学公式:
Attention ( Q , K , V ) = Softmax ( Q K T ⊙ M d k ) V \text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T \odot M}{\sqrt{d_k}}\right)V Attention(Q,K,V)=Softmax(dkQKT⊙M)V
其中:- M M M 为稀疏掩码矩阵,仅保留部分非零连接
-
解决的问题:
- 传统密集注意力缺陷:长序列下计算和内存开销爆炸
- DeepSpeed-Ulysses优化:
- 支持滑动窗口(Sliding Window)、块对角(Block Diagonal)等稀疏模式
- 通信量降至 O ( N / P × W ) O(N/P \times W) O(N/P×W)( W W W 为窗口大小)
二、交叉注意力(Cross-Attention)
数学公式:
CrossAttention
(
Q
,
K
enc
,
V
enc
)
=
Softmax
(
Q
K
enc
T
d
k
)
V
enc
\text{CrossAttention}(Q, K_{\text{enc}}, V_{\text{enc}}) = \text{Softmax}\left(\frac{QK_{\text{enc}}^T}{\sqrt{d_k}}\right)V_{\text{enc}}
CrossAttention(Q,Kenc,Venc)=Softmax(dkQKencT)Venc
其中:
-
Q Q Q 来自解码器, K enc , V enc K_{\text{enc}}, V_{\text{enc}} Kenc,Venc 来自编码器
-
解决的问题:
- 长序列跨模态挑战:生成式任务中,解码器需高效关注超长编码序列
- DeepSpeed-Ulysses优化:
- 通过序列分片和分布式通信,支持 N enc × N dec N_{\text{enc}} \times N_{\text{dec}} Nenc×Ndec 规模的交叉注意力
- 结合ZeRO-3减少参数内存占用,支持万亿级参数模型
三、因果注意力(Causal Attention)
数学公式:
CausalAttention
(
Q
,
K
,
V
)
=
Softmax
(
Q
K
T
+
Mask
d
k
)
V
\text{CausalAttention}(Q, K, V) = \text{Softmax}\left(\frac{QK^T + \text{Mask}}{\sqrt{d_k}}\right)V
CausalAttention(Q,K,V)=Softmax(dkQKT+Mask)V
其中:
-
Mask i , j = { 0 if i ≥ j − ∞ otherwise \text{Mask}_{i,j} = \begin{cases} 0 & \text{if } i \geq j \\ -\infty & \text{otherwise} \end{cases} Maski,j={0−∞if i≥jotherwise
-
解决的问题:
- 自回归生成的信息泄露:防止未来token影响当前预测
- DeepSpeed-Ulysses优化:
- 在分布式环境下高效应用掩码,避免跨分片的未来信息泄露
- 支持超长上下文生成
四、Blockwise Attention(分块注意力)
数学公式:
BlockwiseAttention
(
Q
,
K
,
V
)
=
∑
i
=
1
B
Softmax
(
Q
i
K
i
T
d
k
)
V
i
+
∑
i
≠
j
Softmax
(
Q
i
K
j
T
d
k
)
V
j
⋅
M
i
,
j
\text{BlockwiseAttention}(Q, K, V) = \sum_{i=1}^{B} \text{Softmax}\left(\frac{Q_i K_i^T}{\sqrt{d_k}}\right)V_i + \sum_{i \neq j} \text{Softmax}\left(\frac{Q_i K_j^T}{\sqrt{d_k}}\right)V_j \cdot M_{i,j}
BlockwiseAttention(Q,K,V)=i=1∑BSoftmax(dkQiKiT)Vi+i=j∑Softmax(dkQiKjT)Vj⋅Mi,j
其中:
-
B B B 为块数, M i , j M_{i,j} Mi,j 为块间连接掩码
-
解决的问题:
- 长序列计算碎片化:将序列划分为块,块内密集计算,块间稀疏交互
- DeepSpeed-Ulysses优化:
- 块内通信量 O ( N block 2 ) O(N_{\text{block}}^2) O(Nblock2),块间通信量 O ( N block × K ) O(N_{\text{block}} \times K) O(Nblock×K)( K K K 为稀疏度)
- 实验显示通信量减少70%,支持块间全局连接(如BigBird)
五、FlashAttention优化
数学公式:
FlashAttention
(
Q
,
K
,
V
)
=
∑
i
=
1
T
Softmax
(
Q
i
K
i
T
d
k
)
V
i
\text{FlashAttention}(Q, K, V) = \sum_{i=1}^{T} \text{Softmax}\left(\frac{Q_i K_i^T}{\sqrt{d_k}}\right)V_i
FlashAttention(Q,K,V)=i=1∑TSoftmax(dkQiKiT)Vi
其中:
-
T T T 为内存块数,通过分块计算减少峰值内存
-
解决的问题:
- 长序列内存瓶颈:传统注意力的激活值内存占用 O ( N 2 ) O(N^2) O(N2)
- DeepSpeed-Ulysses优化:
- 结合序列并行,将内存降至 O ( N / P ) O(N/P) O(N/P)
- 分块计算与通信重叠,提升计算效率
六、DeepSpeed-Ulysses的核心优化公式
1. 分布式注意力计算
Output
=
AllToAll
(
Softmax
(
AllToAll
(
Q
i
,
K
i
,
V
i
)
d
k
)
)
\text{Output} = \text{AllToAll}\left(\text{Softmax}\left(\frac{\text{AllToAll}(Q_i, K_i, V_i)}{\sqrt{d_k}}\right)\right)
Output=AllToAll(Softmax(dkAllToAll(Qi,Ki,Vi)))
其中:
-
Q i , K i , V i Q_i, K_i, V_i Qi,Ki,Vi 为第 i i i 个GPU的序列分片
-
解决的问题:
- 传统数据并行的通信瓶颈:全聚集(All-Gather)通信量 O ( N ) O(N) O(N)
- 优化后:两次All-to-All通信量降至 O ( N / P ) O(N/P) O(N/P)
2. 内存优化公式
Memory
=
Params
+
Activations
+
Gradients
\text{Memory} = \text{Params} + \text{Activations} + \text{Gradients}
Memory=Params+Activations+Gradients
其中:
-
Params = TotalParams P × S \text{Params} = \frac{\text{TotalParams}}{P \times S} Params=P×STotalParams( S S S 为ZeRO-3分片因子)
-
Activations = O ( N P ) \text{Activations} = O\left(\frac{N}{P}\right) Activations=O(PN)(通过序列分片和激活重计算)
-
解决的问题:
- 长序列训练的内存墙:传统方法无法支持 N > 100 k N > 100k N>100k 的序列
- 优化后:在7B模型上支持 N = 512 k N=512k N=512k,内存效率提升4倍
All-to-All通信
分布式计算中的All-to-All通信与DeepSpeed-Ulysses优化
DeepSpeed-Ulysses通过两次All-to-All通信,实现了长序列Transformer训练的三大突破:
将O(N)复杂度降为O(N/P),打破长序列训练的带宽瓶颈; 利用NVSwitch/IB拓扑和异步流水线,将GPU算力利用率提升至硬件峰值的54%; 支持1M token序列与万亿参数模型的联合训练,为科学AI(如基因组分析)和生成式AI(如长文本生成)提供底层支撑。
一、All-to-All通信的核心概念
1. 通信机制本质
All-to-All是分布式系统中一种数据交换模式:网络中的每个节点(如GPU)同时向其他所有节点发送自身数据分片,并接收所有节点发来的分片。例如,当有P个GPU时,每个GPU初始持有数据切片X₁, X₂, …, Xₚ,通信后每个GPU都会获得完整的[X₁, X₂, …, Xₚ],相当于每个节点都收集到全局所有数据分片,形成完整数据集。
2. 与其他通信方式的区别
- All-Gather:所有节点仅收集同一数据的不同分片(如多个GPU共同组成完整模型参数),通信量随数据规模线性增长。
- All-to-All:节点间双向交换各自分片,通信量随节点数P成反比,适合数据并行场景下的高效同步。
二、DeepSpeed-Ulysses的两次All-to-All通信设计
1. 第一次通信:QKV张量聚合(注意力计算前)
- 输入状态:每个GPU持有序列长度为N/P的Q/K/V张量(形状为(N/P, b, d),b为微批量,d为隐藏维度)。
- 通信过程:
- 每个GPU向其他P-1个GPU发送自己的Q/K/V分片;
- 每个GPU接收所有分片后,拼接成全局序列的Q/K/V张量(形状变为(N, b, d/P)),其中每个GPU负责d/P维度的注意力头计算。
- 核心作用:使每个GPU获取完整序列的部分注意力头数据,为并行计算注意力做准备。
2. 第二次通信:注意力结果重分配(计算后)
- 输入状态:注意力计算后的输出张量形状为(N, b, d/P)。
- 通信过程:
- 每个GPU将输出按序列维度重新切分为N/P长度的分片;
- 通过All-to-All将分片发送至对应GPU,最终每个GPU持有(N/P, b, d)的张量,供后续MLP层处理。
- 核心作用:将注意力计算结果按序列维度重新分配,确保后续操作的并行性。
三、通信量优化的数学逻辑
1. 传统方法(如Megatron-LM)的瓶颈
采用All-Gather+Reduce-Scatter组合:
- 每次注意力计算需2次All-Gather(收集QKV)和2次Reduce-Scatter(聚合结果),总通信量为4Nh(N为序列长度,h为隐藏维度),复杂度为O(N)。
- 问题:当N从16K增至1M时,通信量增长62.5倍,极易造成网络拥塞。
2. DeepSpeed-Ulysses的优化公式
两次All-to-All的通信量计算:
- 第一次通信(QKV收集):3Nh/P(Q、K、V三个张量);
- 第二次通信(结果分发):Nh/P;
- 总通信量:4Nh/P,复杂度降为O(N/P)。
- 关键优势:当N与P同比增长时(如N×2,P×2),通信量保持不变。例如:
- N=256K,P=64时,传统方法通信量为1024Kh,DeepSpeed仅为16Kh(减少64倍);
- N=1M,P=64时,传统方法为4000Kh,DeepSpeed为62.5Kh(仅为1.56%)。
四、硬件拓扑与效率优化
1. 现代集群的网络架构支持
- 节点内:通过NVSwitch高速互联,All-to-All分解为节点内低延迟交换(如8个GPU间的直接数据传输);
- 节点间:采用胖树IB拓扑,支持高带宽批量数据传输,避免跨节点通信瓶颈。
2. 通信-计算流水线机制
- 异步执行模式:
- GPU在发送Q/K/V分片的同时,启动部分计算任务;
- 接收完整Q/K/V后,立即开始注意力计算,将通信延迟隐藏在计算过程中。
- 效果:实测显示,该机制可使通信效率提升30%-40%,尤其适用于长序列的分块计算。
五、实验验证与实际价值
1. 性能对比数据
- 在70亿参数GPT模型上,DeepSpeed-Ulysses支持512K序列长度,而Megatron-LM仅支持128K;
- 吞吐量方面,DeepSpeed达175 TFlops/GPU,是Megatron-LM的2.5倍(硬件峰值利用率54%)。
2. 长序列训练的扩展性
- 当序列长度从64K增至1M时,DeepSpeed通过增加GPU数量(如从16增至256),保持通信量恒定,实现线性扩展;
- 内存占用方面,结合ZeRO-3优化,单GPU显存占用从O(N²)降至O((N/P)²),支持百万级token训练。
![Docker 使用镜像[SpringBoot之Docker实战系列] - 第537篇](https://i-blog.csdnimg.cn/img_convert/482e1f7c534731cfe0fbc734a8d94d58.png)

![Error in beforeDestroy hook: “Error: [ElementForm]unpected width “](https://i-blog.csdnimg.cn/direct/1727a2e78fc24efb89a3ecebcec3198a.png)
![[spring] spring 框架、IOC和AOP思想](https://i-blog.csdnimg.cn/direct/206b161627a7466e8fb0f288b549f2e7.png)
![[浏览器]缓存策略机制详解](https://i-blog.csdnimg.cn/direct/e7f339e8e5d94ae0929382d2304ad96e.png)