一、说明
先来一首创作的歌:
在大模型和生成式AI模型大规模发达的今天,利用大模型生成音乐也是其中一个重要的发展方向。今天我们就介绍一个这样的音乐生成模型ACE-Step,可基于关键字和歌词生成歌曲;基于歌曲生成伴奏等等功能。
1、概述
ACE-Step——一款突破性的开源音乐生成基础模型,通过整体架构设计克服了现有方法的固有缺陷,实现了业界领先的性能。当前音乐生成技术普遍面临生成速度、音乐连贯性与可控性之间的矛盾:基于大语言模型的方法(如Yue、SongGen)虽擅长歌词对齐,但存在推理速度慢和结构失真问题;而扩散模型(如DiffRhythm)虽能快速合成,却常缺乏长程结构连贯性。
ACE-Step创新性地融合了基于扩散的生成范式、Sana深度压缩自动编码器(DCAE)和轻量级线性Transformer架构,并引入MERT与m-hubert实现语义表征对齐(REPA)训练机制,显著加速模型收敛。实验表明,该模型在A100 GPU上仅需20秒即可生成长达4分钟的音乐,生成速度较基于LLM的基线模型提升15倍,同时在旋律、和声与节奏等维度展现出卓越的音乐连贯性和歌词对齐能力。更重要的是,ACE-Step完整保留了音乐信号的精细声学细节,支持音色克隆、歌词编辑、混音重构及分轨生成(如歌词转人声、歌声转伴奏)等高级控制功能。
不同于传统的端到端文本到音乐生成框架,我们的愿景是构建音乐AI的基础设施:打造一个高速、通用、高效且灵活的架构,使其能够便捷支持各类子任务的训练开发。这将为音乐人、制作人和内容创作者提供无缝融入创作流程的强大工具,最终实现音乐生成领域的"Stable Diffusion时刻"——让音乐创作民主化真正触手可及。
2、架构
现有的基于LLM的音乐生成模型,比如Yue、SongGen等虽然在歌词对齐方面表现出色,但推理速度慢且存在结构性问题。基于扩散模型,比如DiffRhythm虽然能够实现更快的合成速度,但通常缺乏较长段落的结构连贯性。为了克服这些现有模型的局限性,ACE-Step通过统一的架构设计实现了最佳性能,在生成速度、音乐连贯性和可控性之间多方面的改善。
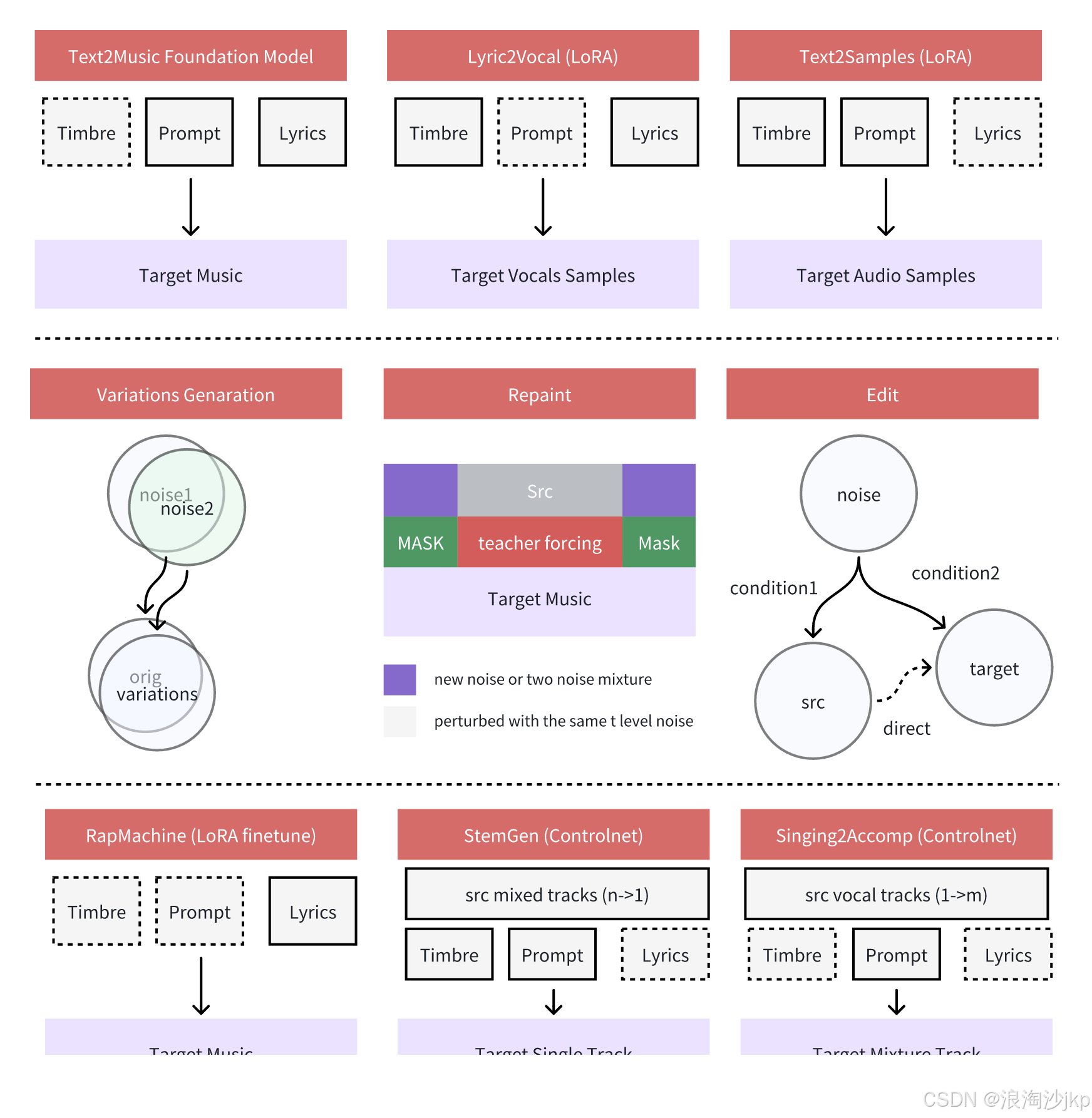
ACE-Step通过diffusion生成与Sana的深度压缩自动编码器 (DCAE) 和轻量级线性变换器相结合,并利用MERT和m-hubert在训练过程中对齐语义表示 (REPA),从而实现快速收敛。整体结构图如下:
 3、硬件测试
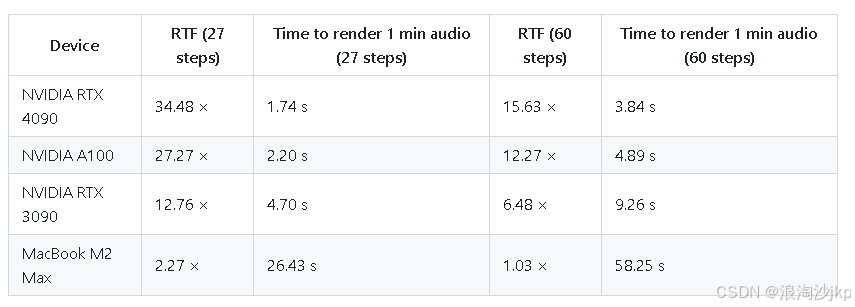
3、硬件测试
ACE-Step可实现在A100 GPU上仅需20秒即可合成一首4分钟的音乐。这比基于LLM的基准快15倍。同时还在旋律、和声和节奏指标上实现了完美的连贯性和歌词对齐。对不同硬件条件下的其系能表现得对比基准测试:
4、功能组成
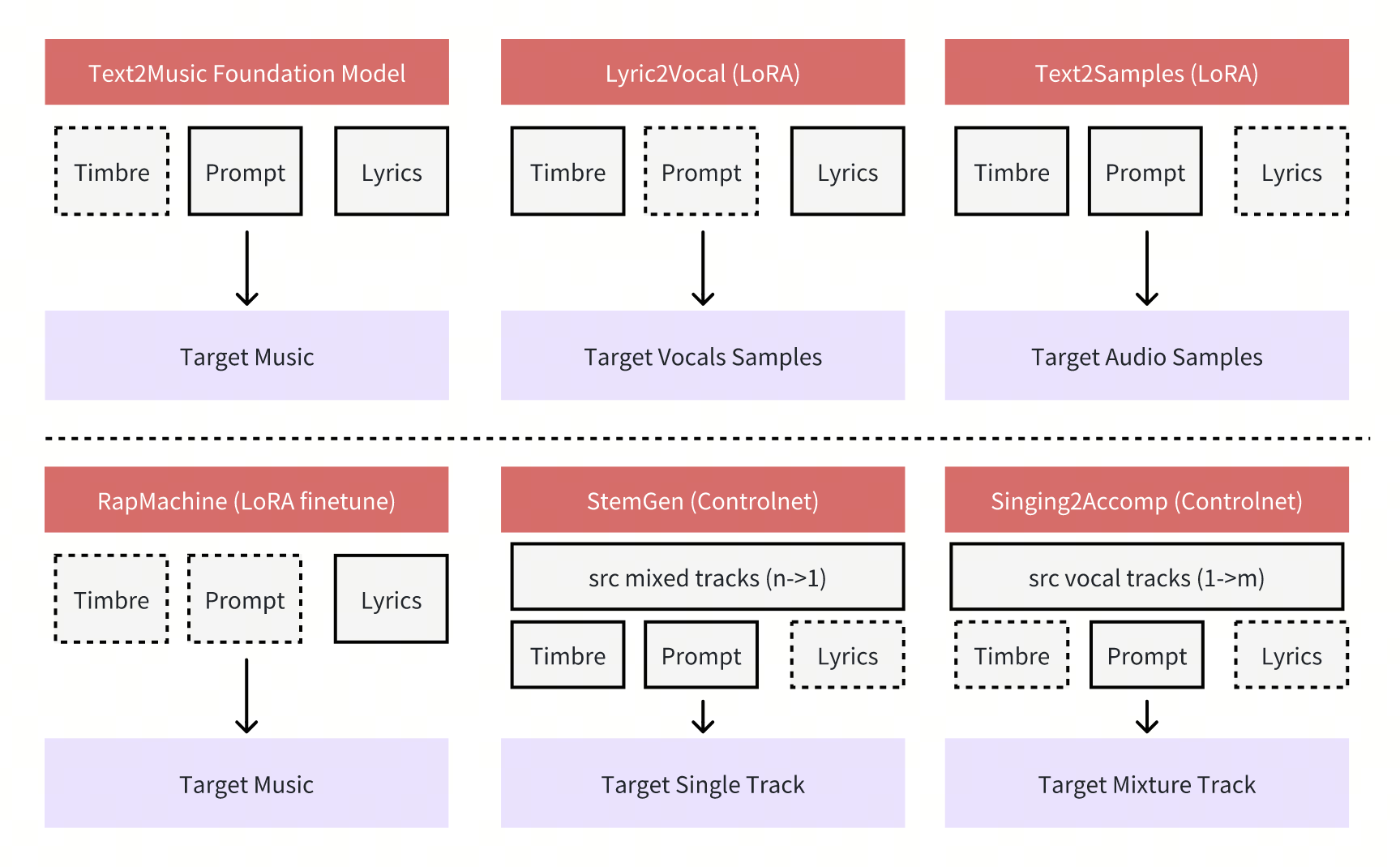
ACE-Step主要有两个大的功能应用构成,后续会陆续推出Rap机,StemGen和唱歌伴奏等功能。
Lyric2Vocal(LoRA):
基于对纯语音数据进行微调LoRA,可直接从歌词生成语音样本。
提供众多实用应用,如人声演示、指南曲目、歌曲创作辅助和人声编排实验。
提供一种快速测试歌词演唱效果的方法,帮助歌曲创作者更快地进行迭代。
Text2Samples (LoRA):
与Lyric2Vocal类似,但针对纯乐器和样本数据进行了微调。
能够根据文本描述生成概念音乐制作样本。
有助于快速创建乐器循环、音效和音乐元素以供制作。
二、模型特点
ACE-Step 具备高效多元创作能力、强可控性和易于拓展的三大核心特色
1、高效多元创作支持
ACE-Step 具备出色的多语言支持、极速生成能力以及高质量的音乐创作表现,确保创作者能够实现跨文化创作与高质量交付。
-
音乐质量与表现力兼顾
ACE-Step 支持多种主流音乐风格的创作,并能够生成丰富多样且兼具表现力的演唱、器乐编排,确保音乐的连贯性与和谐,并展现出风格的多样性。
-
支持快速生成
ACE-Step 提供两种生成模式:快速和慢速模式。最快 15 秒即可生成一整首歌,慢速模式也仅需 32 秒。
-
支持快速生成
ACE-Step 提供两种生成模式:快速和慢速模式。最快 15 秒即可生成一整首歌,慢速模式也仅需 32 秒。
-
支持多语言生成
ACE-Step 支持 19 种语言(如中文、英文、西班牙语等)的歌曲生成,满足跨文化创作的需求。无论是本地化定制还是跨语言创作,ACE-Step 都能提供强大支持,帮助创作者轻松应对全球化的音乐创作需求。
ACE-Step 能精准捕捉每个乐器的音色和表现力,确保每个音符栩栩如生,并灵活展现不同歌唱技巧和音乐风格,让每一首歌都充满独特的韵味与深度。
2、全能编辑器:可控性强
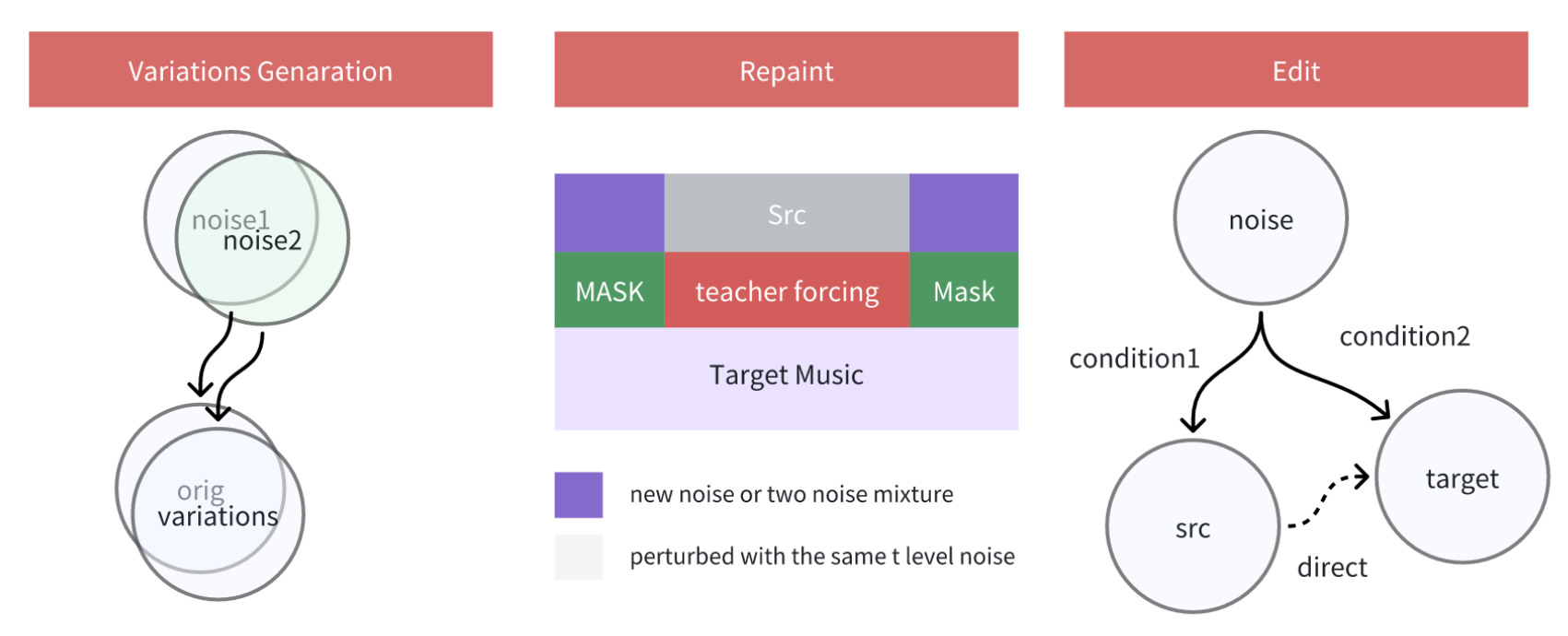
ACE-Step 不仅仅是一个“生成器”,它还是一个全能的“编辑器”,在创作过程中提供高度的可控性。它为创作者提供了两个关键功能:Edit 和 Retake/Repaint,使得创作过程既精确又灵活。
-
Edit 功能:精准歌词调整
创作者可以在不改变旋律的情况下,精确修改已生成歌曲的歌词内容、语气或情感表达,确保每行歌词与整体音乐风格完美契合。
-
Retake/Repaint 功能:灵活创作优化
如果生成的作品不完全符合创作需求,创作者可以使用 Retake 功能重新生成一首风格相似、结构类似的歌曲,或者通过 Repaint 对特定部分(如旋律或歌词)进行局部调整,进一步优化作品。
无论你想微调歌词,还是想重新构思整个作品,ACE-Step 都能帮助创作者在不同创段精确打磨作品。从而让创作更加高效灵活,加速创作的实用性。
3、灵活拓展,覆盖多样创作需求
ACE-Step 拥有高度的可拓展性,支持 LoRA、ControlNet 等主流微调方式,轻松适配多种音乐创作场景,满足个性化定制需求。
-
LoRA 微调(定制音乐风格):通过 LoRA 微调技术,ACE-Step 可以根据创作者的需求进行特定风格的定制化训练,如生成符合 rap 风格的歌词,确保输出内容与目标风格高度一致。
-
ControlNet 微调(人声驱动伴奏生成):结合 ControlNet 技术,ACE-Step 能根据输入的旋律或人声自动生成相匹配的伴奏,提升音乐创作的个性化和灵活性。
三、技术亮点
上述特点的实现得益于 ACE-Step 在技术上的创新,借助先进的架构和训练策略,显著提升了生成质量、训练效率和模型的可扩展性,同时确保了音乐生成的速度、质量与灵活性。
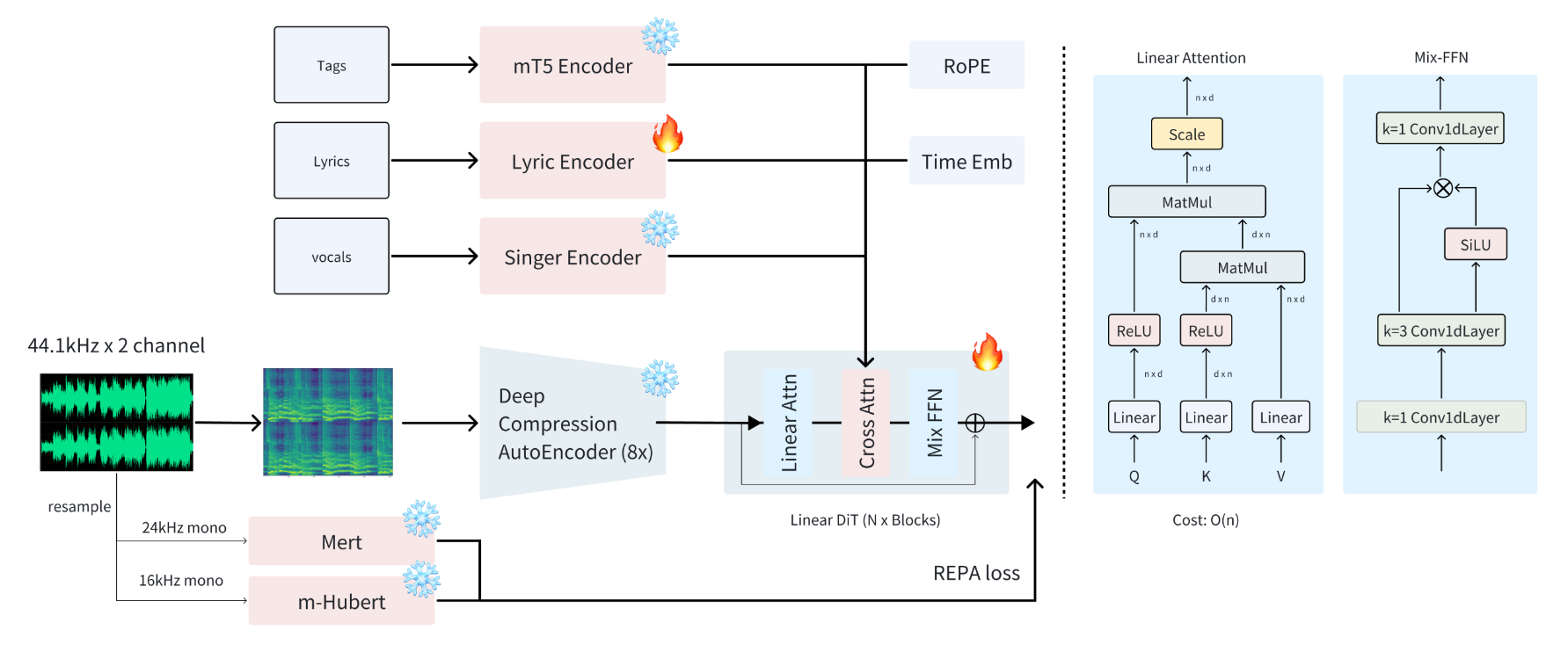
ACE-Step 模型架构图
技术亮点一:一阶段 DiT 架构 + REPA 提升音乐结构性
传统的开源音乐生成模型大多采用两阶段架构:第一阶段生成语义代码,第二阶段通过 Diffusion 生成音频。这种方法在歌词发音的准确性和旋律的连贯性上存在限制,尤其在歌声的清晰度和乐器细节的表现上不足。
ACE-Step 采用一阶段 DiT 架构,并结合 REPA 技术,通过语义约束提升生成的音频质量。这个创新解决了传统模型的瓶颈,使得音频生成更加精确,且无需依赖声伴分离技术或歌词时间戳对齐,极大提高了生成的灵活性和训练效率。
技术亮点二:DCAE 与线性 Transformer 结合,提升生成速度与效率
在音频生成方面,ACE-Step 采用 DCAE(深度压缩自编码器)技术,通过压缩 Mel 频率,将 44.1kHz 的数据压缩至原来的 1/8,既减少了数据量,又保持了音质的细腻度,显著提升了训练收敛速度和生成效率。
同时,ACE-Step 引入线性 Transformer 架构,减少了显存占用并优化了计算复杂度,提高了训练的稳定性和效率。这两项技术不仅加速了音频生成,还能处理更长的音频数据,满足大规模创作的需求。
四、本地部署
1、环境准备
ACE-Step推荐使用Python 3.10版本,并建议通过虚拟环境(Conda或venv)管理项目依赖
# 使用Conda创建环境
conda create -n ace python=3.10 -y
conda activate ace
#conda remove --name ace --all
# 根据自己的cuda选择,我的是12.0,但是没有cu120 所以我们用cu121 这里安装不好,会导致错误
pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu1212、下载源码与依耐安装
git clone https://github.com/ace-step/ACE-Step.git
cd ACE-Step
#pip install -r requirements.txt
pip install -e .
3、界面汉化
汉化界面在路径/workspace/ACE-Step/acestep/ui/components.py
components.py 修改,大部分都label,button 上的字符修改为中文即可
csdn 下载地址
https://download.csdn.net/download/jiangkp/90903826![]() https://download.csdn.net/download/jiangkp/90903826
https://download.csdn.net/download/jiangkp/90903826
4、运行及使用
frpc_linux_amd64_v0.3下载地址:
https://download.csdn.net/download/jiangkp/90568217![]() https://download.csdn.net/download/jiangkp/90568217
https://download.csdn.net/download/jiangkp/90568217
上传frpc_linux_amd64_v0.3
cp frpc_linux_amd64_v0.3 /root/.cache/huggingface/gradio/frpc
chmod +x /root/.cache/huggingface/gradio/frpc/frpc_linux_amd64_v0.3
添加环境变量
nano ~/.bashrc
export HF_ENDPOINT=https://hf-mirror.com
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
source ~/.bashrc
# 执行
acestep --checkpoint_path /workspace/ACE-Step/checkpoint --port 7865 --device_id 0 --share true --torch_compile true --bf16 false
用户可以通过以下参数调整模型行为:
--checkpoint_path:指定模型检查点路径(默认自动下载)
--server_name:设置Gradio服务器绑定的IP地址或主机名
--port:指定运行Gradio服务器的端口
--device_id:指定使用的GPU设备ID
--share:启用Gradio共享链接
--bf16:使用bfloat16精度加速推理
--torch_compile:使用torch.compile()优化模型(Windows不支持)

5、高级使用与界面指南
浏览器输入
https://pwqmct--7865.ap-shanghai.cloudstudio.work/
或者
ACE-Step Model 1.0 DEMO![]() https://16ae346bf063f39247.gradio.live/
https://16ae346bf063f39247.gradio.live/
两个网址都可以在外网访问
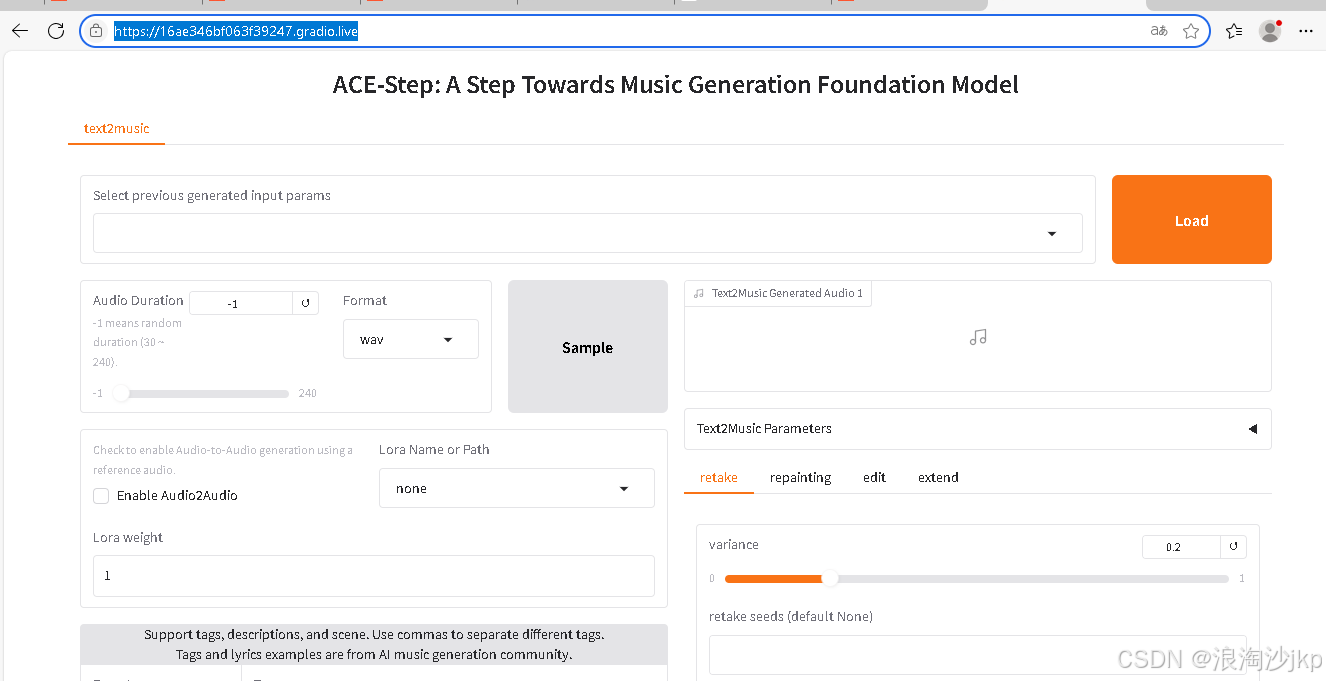
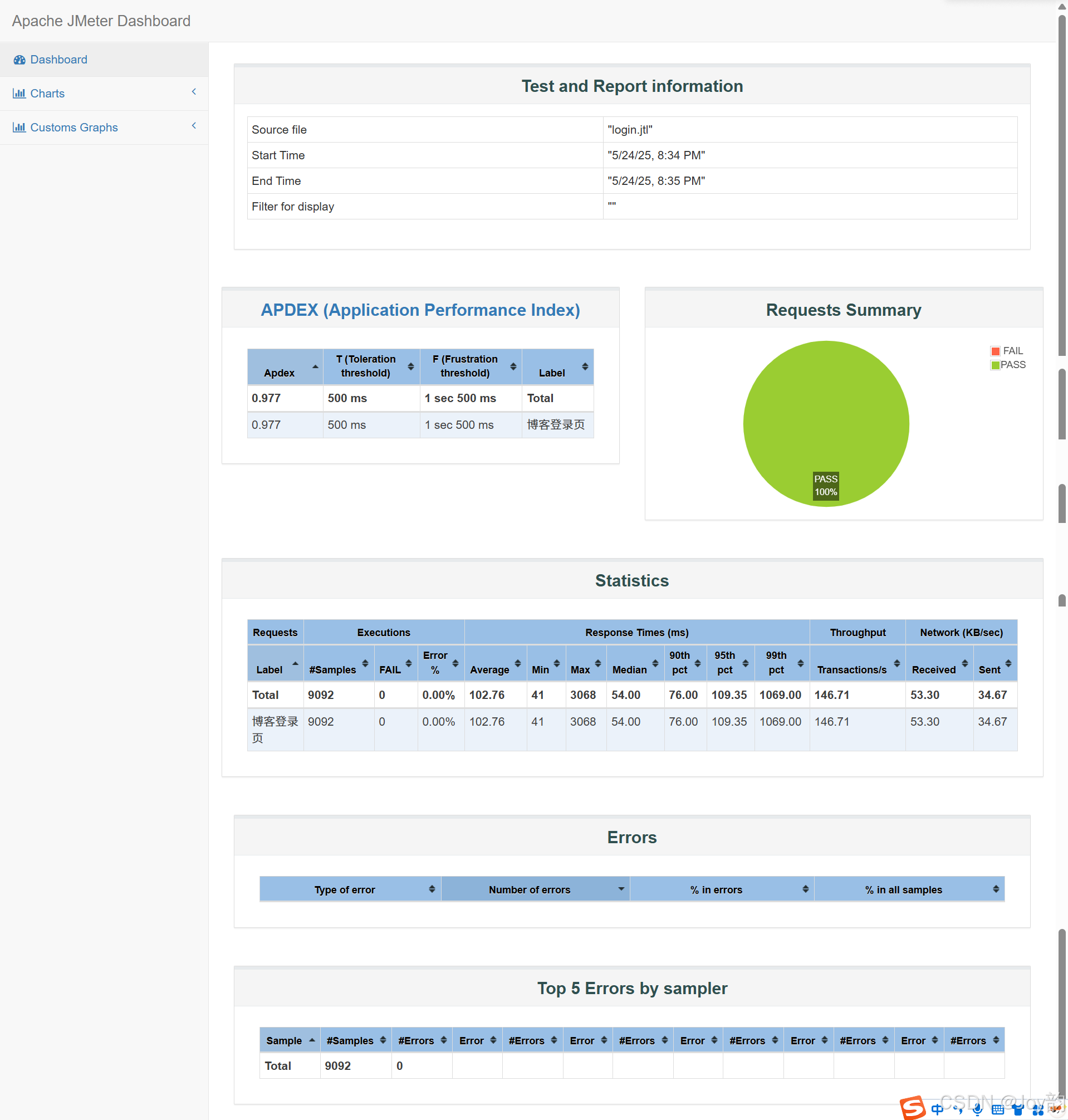
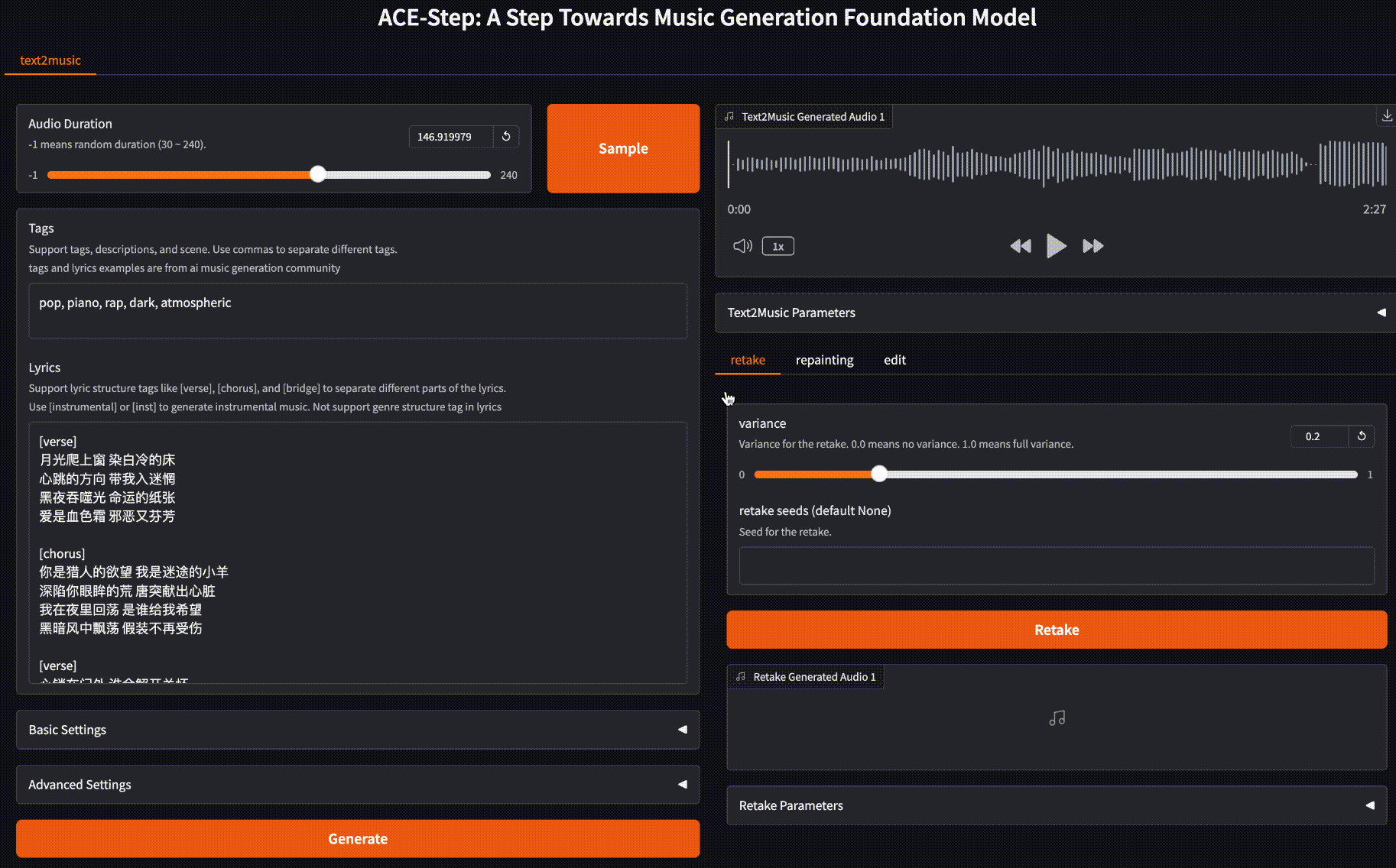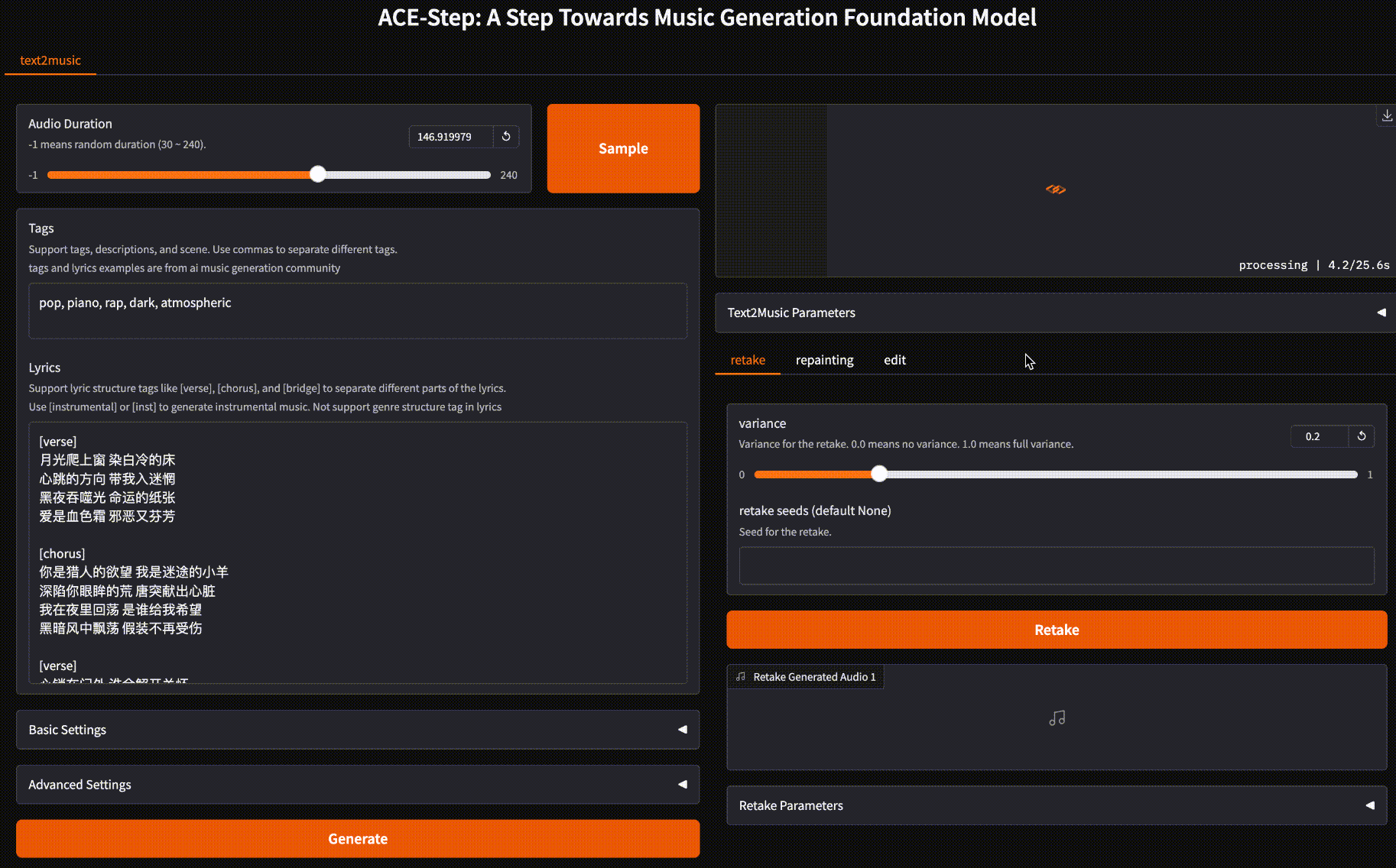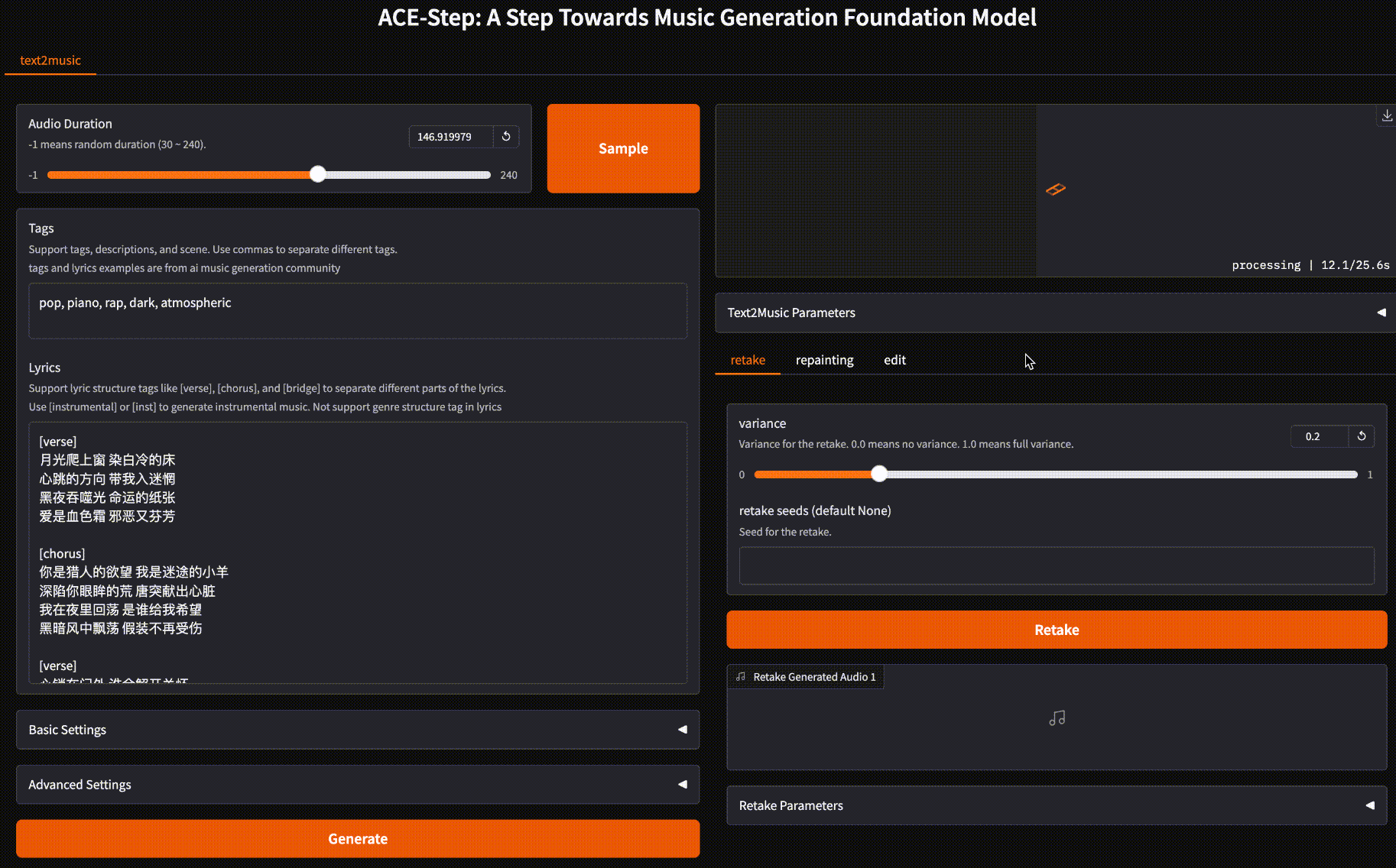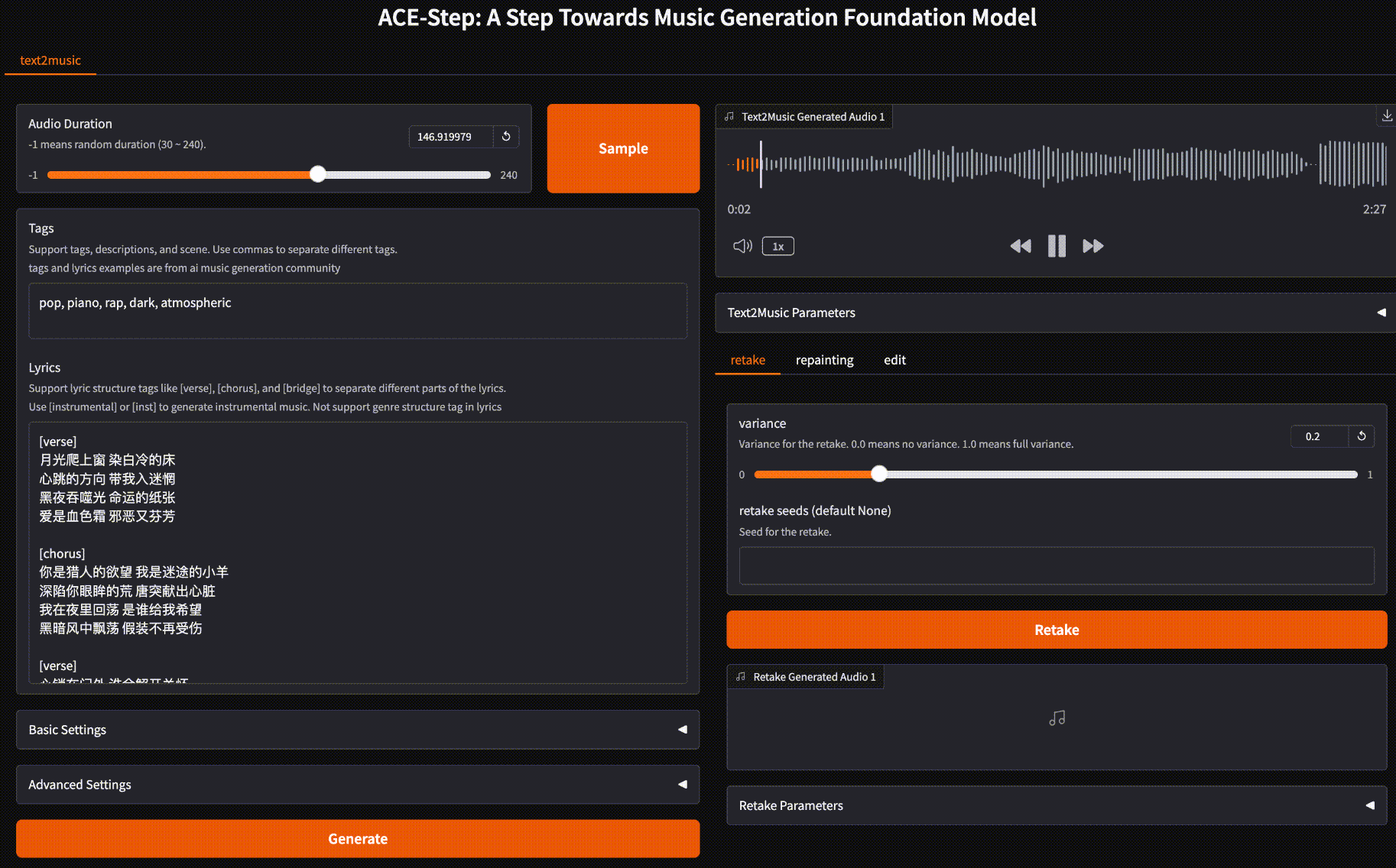
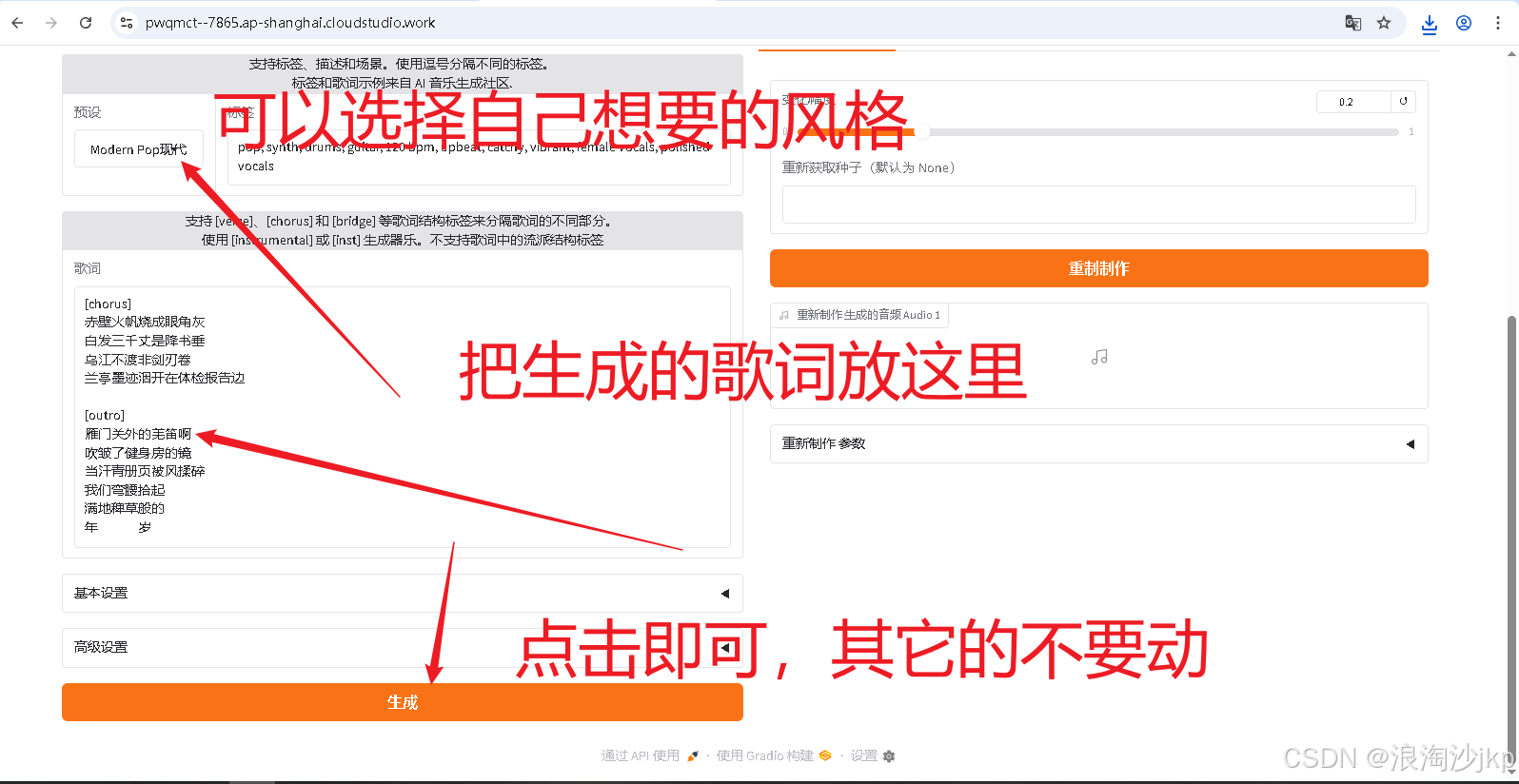
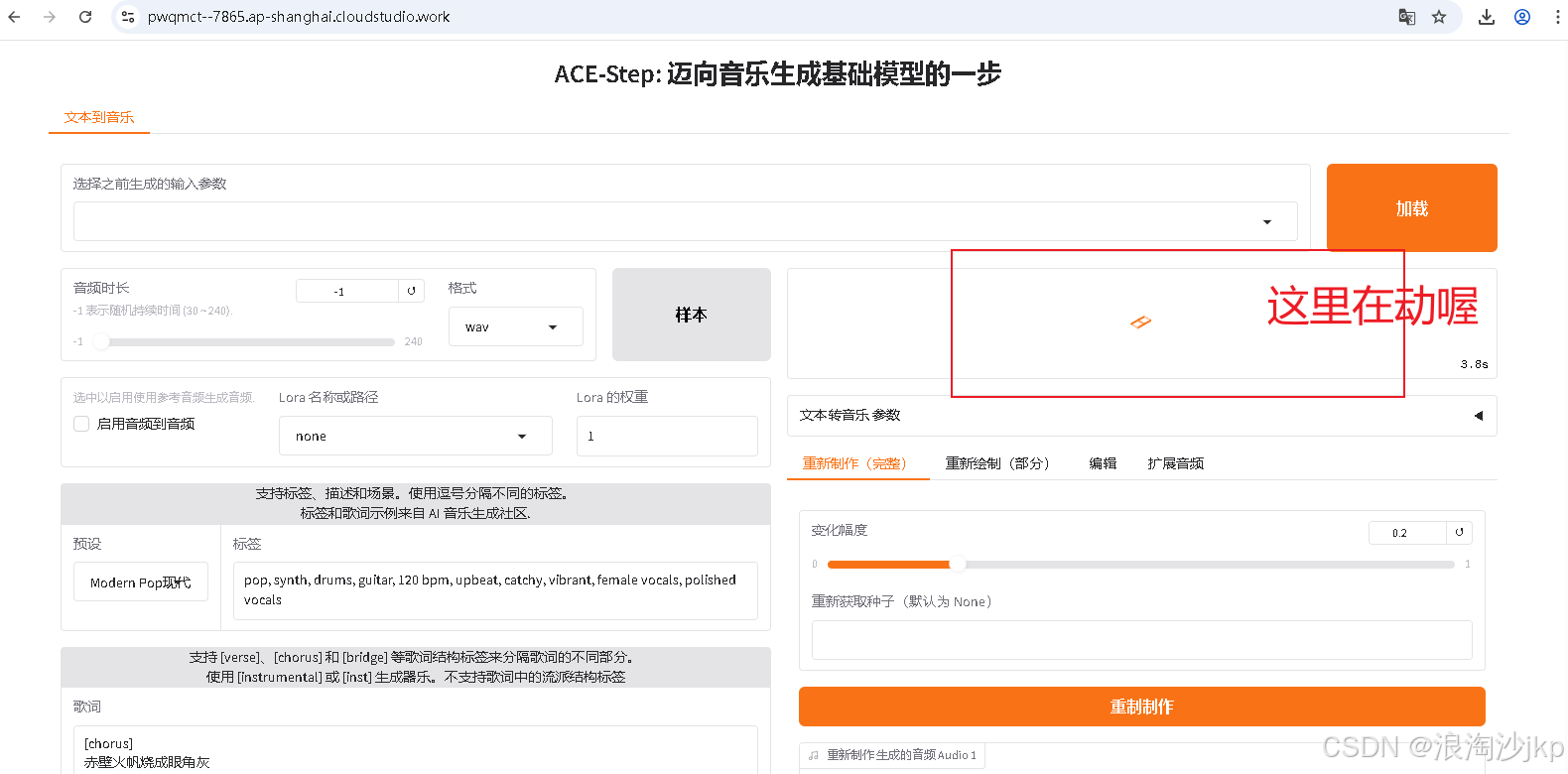
ACE-Step提供了多个标签页以支持不同的音乐生成和编辑任务:
Text2Music标签页:基于文本描述生成音乐,支持通过标签、歌词和音频时长等参数控制生成结果。
Retake标签页:使用不同种子重新生成音乐,实现基于原始生成的变体创作。
Repainting标签页:选择性地重新生成音乐的特定部分,通过指定开始和结束时间实现局部修改。
Edit标签页:通过修改标签或歌词来调整现有音乐,支持仅修改歌词(保持旋律)或全面混音(改变旋律)两种模式。
Extend标签页:在现有音乐作品的开头或结尾添加音乐,扩展音乐长度。
tag 输入:funk, pop, soul, rock, melodic, guitar, drums, bass, keyboard, percussion, 105 BPM, energetic, upbeat, groovy, vibrant, dynamic
6、界面讲解
给大家推荐一个视频,不是我的视频,只是不想写这部分,大家看看
想亲手谱写一首动听的歌曲吗?ACE-Step来帮你!1分钟原创歌曲创作!用法简单,一键启动!_哔哩哔哩_bilibili想写歌的不可错过!-----------------------------------------------------------------------------夸克:https://pan.quark.cn/s/3cc0297d5f3e 提取码:SsfF💥WildCard | 虚拟Visa卡(全球通用):https://bewildcard.com/i/0YEZDB4X💥PS A, 视频播放量 750、弹幕量 3、点赞数 32、投硬币枚数 21、收藏人数 50、转发人数 7, 视频作者 十个骑士, 作者简介 ,相关视频:AI生成歌曲工具整合包ACE-Step,Suno平替,可以通过提示词和歌词生成歌曲,工具已打包好,一键启动即可,最强AI图片数字人,腾讯Sonic,中文对口型效果超强!音频驱动人物图片说话+唱歌!一键启动整合包! | 数字人 | Avatar,最新AI数字人模型,OmniHuman-1太强大了,面部细节太牛了,简直颠覆认知了!,最强AI纯音乐生成,InspireMusic,阿里开源, 超级强大!一键启动整合包!,f5-tts-20250508声音克隆最新一键整合包,支持自定义停顿时长,新版速度更快,断句更好,实时AI演唱永不跑掉 感受科技的力量家人们实时Ai出来了 随时暂停 随时开启 可以实时呈现出人声和ai的演唱 嘴巴停ai就停! #实时ai #ai唱歌生成,阿里黑科技!AI自动剪辑视频神器,1小时工作量缩到3分钟(附保姆级避坑指南),免费开源零基础也能秒变音乐制作人!ACE-Step AI 音乐生成器, LLM歌词创作+歌曲数字人 ComfyUI本地部署教程,AI原创歌曲且替换成自己的声音只需10分钟,FramePack最新整合包,增加首尾帧功能,速度提高40%,6G显卡可用![]() https://www.bilibili.com/video/BV1yFEBzkEaM?t=221.1
https://www.bilibili.com/video/BV1yFEBzkEaM?t=221.1
7、deepseek 生成歌词
输入:
模仿刀郎的曲风
创作一首中年男人相关的歌曲
表达男人们无奈的状态
歌曲的名字要有深度
歌曲的内容要有一些中国历史典故,历史文化,名著,历史书籍的元素
歌曲中不要出来刀郎和他代表作的名字
支持 [verse]、[chorus] 和 [bridge] 等歌词结构标签来分隔歌词的不同部分
输出
《长河饮马人》
[verse]
铜镜锈蚀了少年眉锋
铁衣苔痕爬上旧缰绳
太史公笔尖悬着三十八根耻骨
我们却把傲骨折成算珠声声[verse]
案头炊烟熏黄了出师表
锦官城的柏叶落进降压药
浔阳江头那把无弦琵琶
在房贷单上 拨响四更雨潇潇[chorus]
赤壁火帆烧成眼角灰
白发三千丈是降书垂
乌江不渡非剑刃卷
兰亭墨迹洇开在体检报告边[bridge]
范公舟枕着洞庭忧乐
韩愈云横不过秦岭车贷
陶公菊酿成酒桌恭维
谁在青铜鼎纹里刻下柴米年轮[verse]
河西走廊驼铃碎成打卡钟
阳关三叠叠不起学区房价重
敦煌飞天袖间漏下的星斗
坠在啤酒沫里 泛起盐碱地的梦[chorus]
赤壁火帆烧成眼角灰
白发三千丈是降书垂
乌江不渡非剑刃卷
兰亭墨迹洇开在体检报告边[outro]
雁门关外的羌笛啊
吹皱了健身房的镜
当汗青册页被风揉碎
我们弯腰拾起
满地稗草般的
年 岁
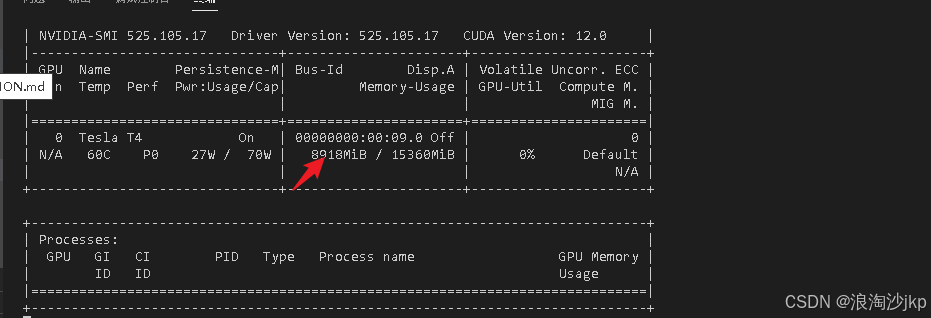
8、生成音乐
显卡占用 不到10g