文章目录
- 前言
- 一、Cypher简介
- 二、数据库操作
- 1. 创建数据库
- 2. 查看数据库
- 3. 删除数据库
- 4. 切换数据库
- 三、节点、关系及属性操作
- 1. 创建节点与关系
- 1.1 语法
- 1.2 示例
- 2. 查询数据
- 2.1 语法
- 2.2 示例
- 3. 更新数据
- 3.1 语法
- 3.2 示例
- 4. 删除节点与关系
- 4.1 语法
- 4.2 示例
- 5. 合并数据
- 5.1 语法
- 5.2 示例
前言
本文将系统介绍 Cypher 的核心语法与操作逻辑,涵盖数据库管理、节点与关系的创建、查询、更新及删除等基础操作,同时结合具体示例演示如何利用 Cypher 解决实际场景中的数据问题。通过理论与实践的结合,帮助读者快速掌握图数据库的核心操作范式,为进一步探索图技术在大数据分析、人工智能等领域的应用奠定基础。
一、Cypher简介
Cypher 是一种声明式图数据库查询语言,由 Neo4j 公司开发,用于高效地查询和更新图数据库中的数据。它使得开发者可以通过简洁、直观的语法来操作图数据库,而无需关心底层实现细节。Cypher 的设计目标是为了让图数据的操作变得简单且强大,使非技术用户也能轻松理解并使用。
Cypher 主要特点
- 模式匹配:Cypher 提供了强大的模式匹配能力,允许用户通过图形结构而非仅基于属性或索引来查询数据。
- 易于阅读和编写:其语法设计接近自然语言,尤其是对于那些具有图形化思维的人来说更加直观。
- 灵活的数据查询与更新:无论是简单的查询还是复杂的图形遍历,Cypher 都能提供支持。
- 高效的执行计划:Neo4j 会根据 Cypher 查询自动生成高效的执行计划,以确保快速的数据检索速度。
使用场景
- 社交网络分析:利用 Cypher 可以很容易地找到人与人之间的关系网,比如朋友的朋友等。
- 推荐系统:通过分析用户的行为和偏好,为用户提供个性化的产品或内容推荐。
- 路径查找:在运输和物流行业,可以用来查找两点之间的最优路径。
- 风险管理与欺诈检测:通过分析实体间的关系,识别潜在的风险或欺诈行为。
Cypher 作为图数据库 Neo4j 的核心查询语言,极大地简化了图数据的管理和分析过程,使得图数据库技术更易于被广泛接受和应用。
二、数据库操作
在 Neo4j 中,数据库操作包括创建、查看和删除数据库等。不过需要注意的是,Neo4j 的社区版(Community Edition)通常只支持单个默认数据库,即 neo4j 数据库,并不支持创建多个数据库。但是,从 Neo4j 4.0 版本开始,企业版支持多数据库特性,允许用户创建和管理多个数据库实例。
1. 创建数据库
要创建一个新的数据库,可以使用以下 Cypher 命令。
CREATE DATABASE database_name
例如,如果你想创建一个名为 mydatabase 的新数据库,你可以运行:
CREATE DATABASE mydatabase
注意:这个命令仅适用于 Neo4j 企业版。
2. 查看数据库
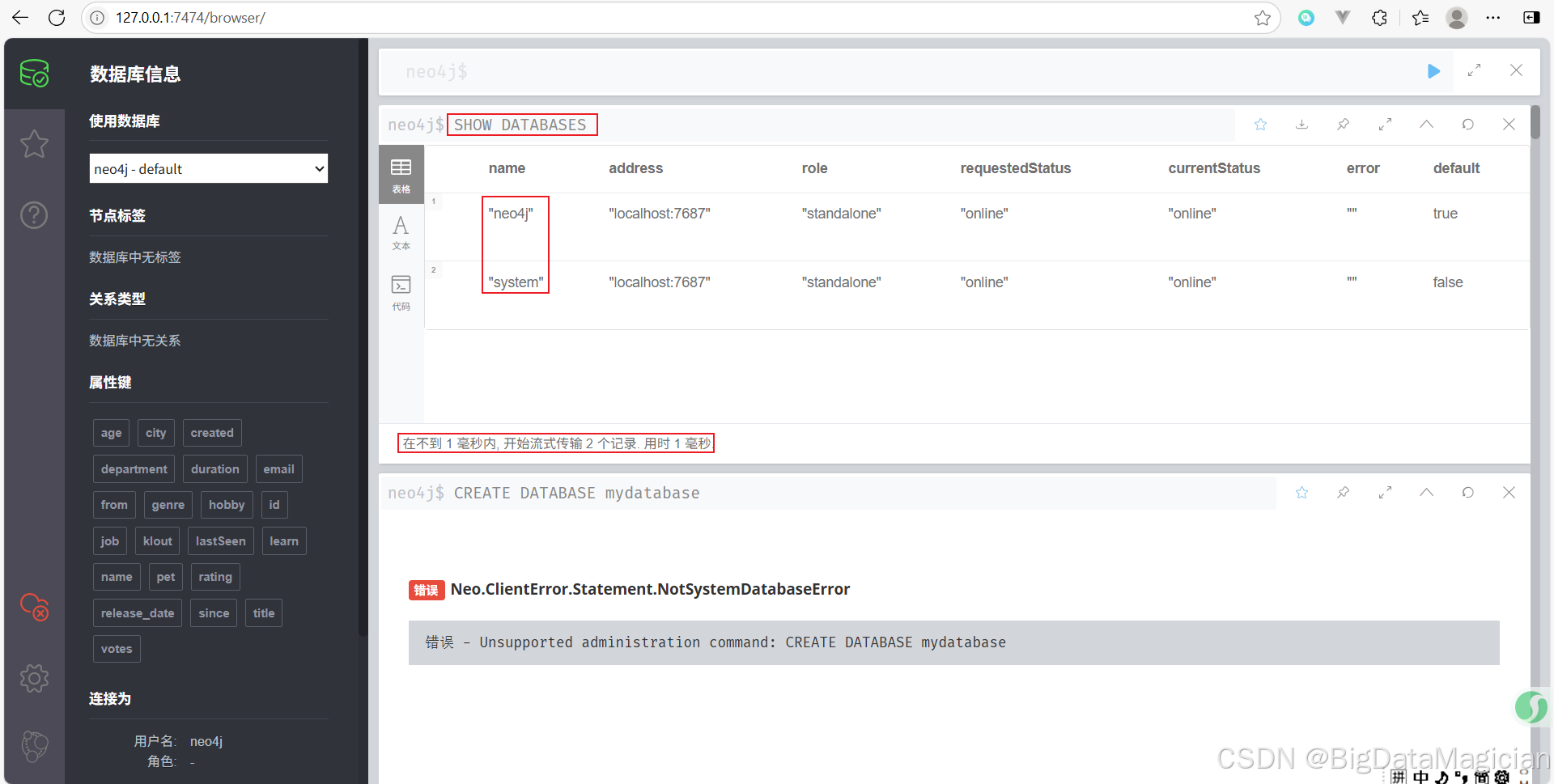
查看当前系统中存在的所有数据库,可以使用如下命令。
SHOW DATABASES
这将列出所有数据库的信息,包括名称、状态(如在线或离线)、是否为主数据库等。
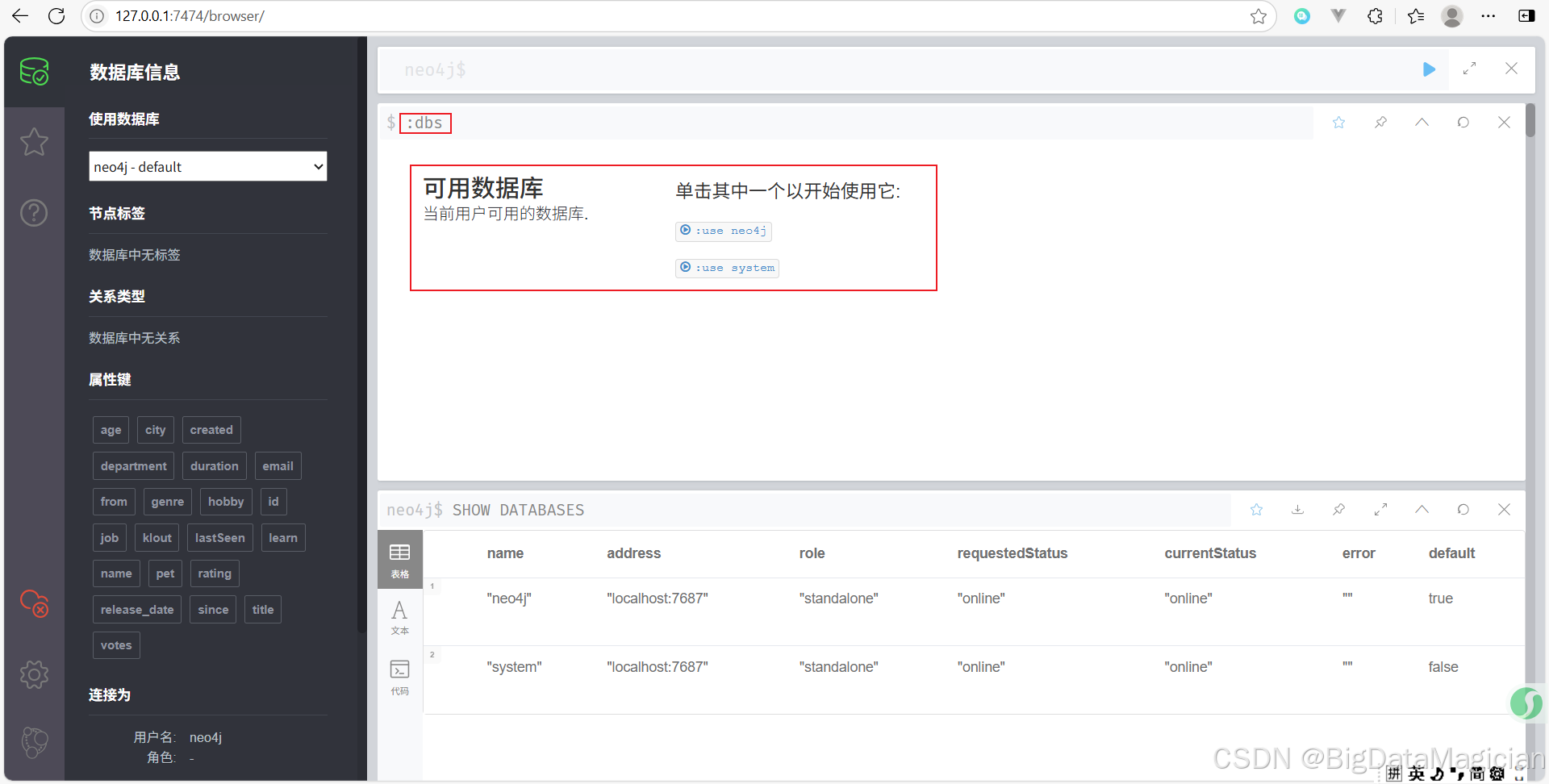
也可以使用如下命令查看可用数据库。
:dbs
3. 删除数据库
如果需要删除一个数据库,可以使用以下命令:
DROP DATABASE database_name
例如,删除名为 mydatabase 的数据库:
DROP DATABASE mydatabase
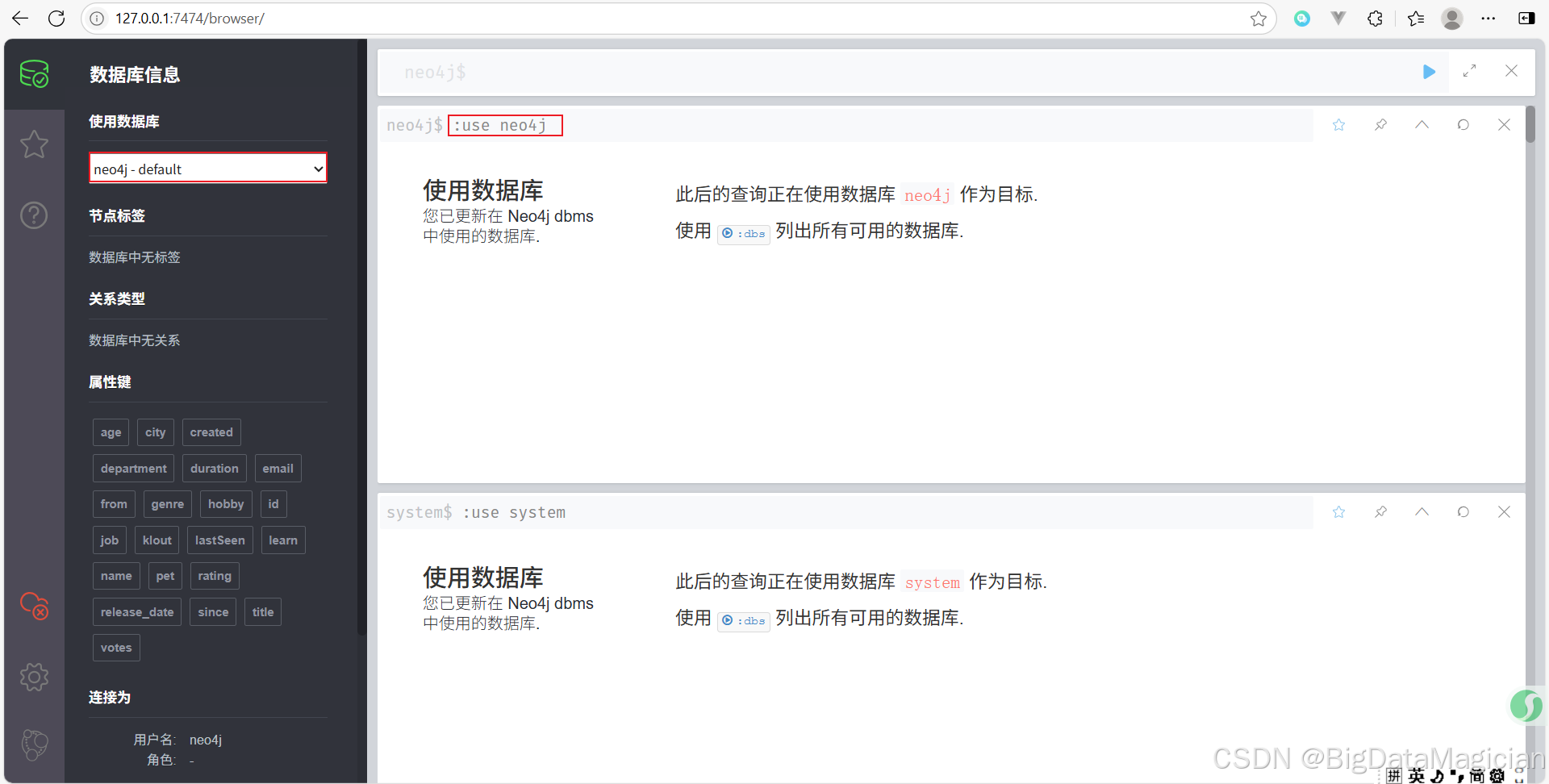
4. 切换数据库
切换到数据库neo4j。
:use neo4j
三、节点、关系及属性操作
1. 创建节点与关系
在 Cypher 中,图数据库中的基本元素是 节点(Node) 和 关系(Relationship)。使用 CREATE 命令可以创建节点和关系。
1.1 语法
创建节点的语法如下:
CREATE (variableName:Label {property1: value1, property2: value2, ...})
Label是节点的标签,用于分类。{property1: value1}是节点的属性集合,可选。variableName是标签变量,用于后续操作中引用该节点。
创建关系的语法如下:
CREATE (node1)-[relVariable:RELATIONSHIP_TYPE {prop: value}]->(node2)
relVariable是关系变量。RELATIONSHIP_TYPE是关系类型,表示两个节点之间的连接方式,关系类型是自定义的。- 箭头方向表示关系的方向(
->表示从 node1 到 node2,<-表示反向)。
1.2 示例
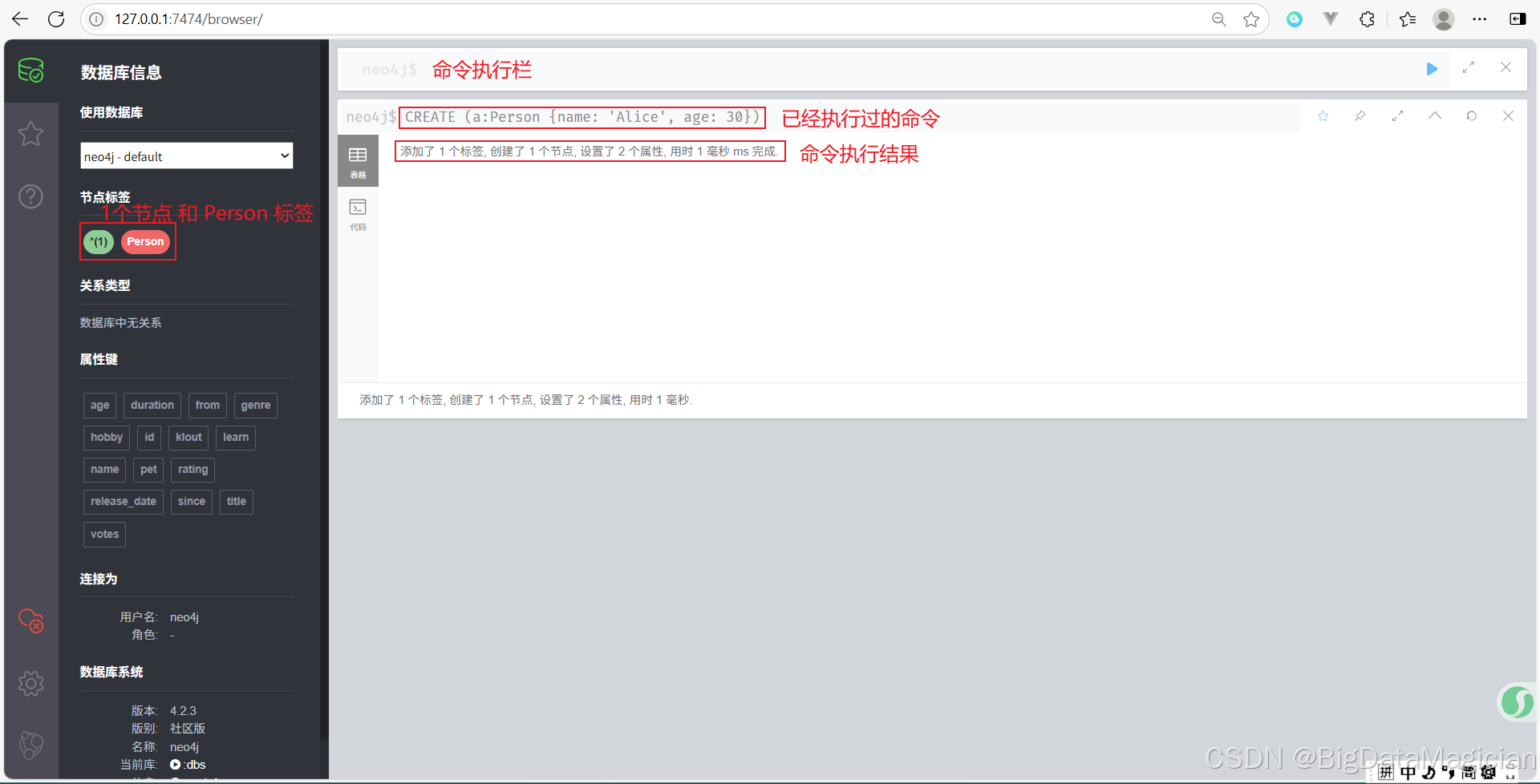
示例 1:创建一个简单的节点
CREATE (a:Person {name: 'Alice', age: 30})
- 这个命令创建了一个带有
Person标签的节点,并赋予它两个属性:name和age。 - 节点变量为
a,可以在后续查询中引用这个节点。
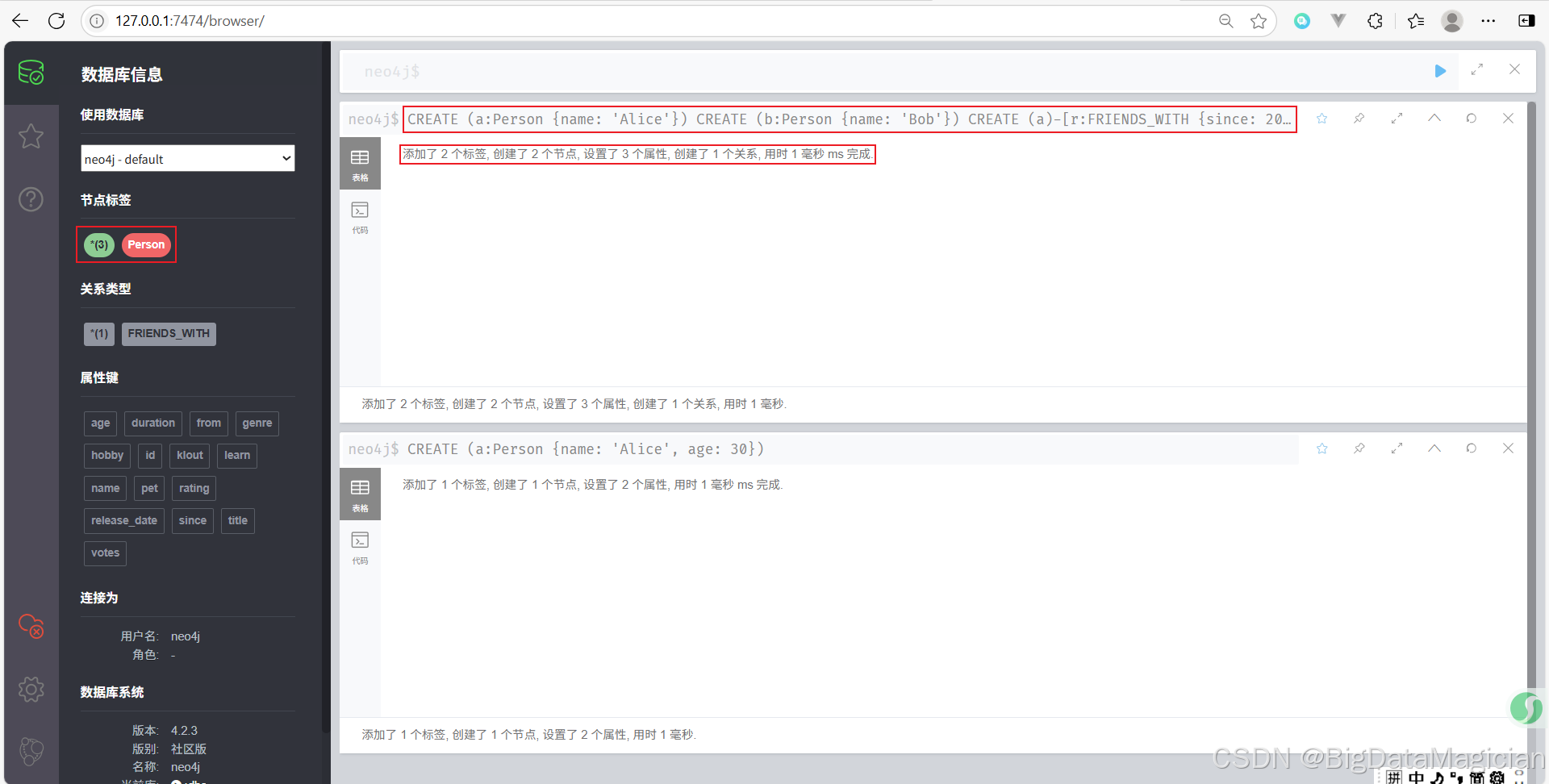
示例 2:创建两个节点并建立关系
// 创建第一个节点 Alice
CREATE (a:Person {name: 'Alice'})
// 创建第二个节点 Bob
CREATE (b:Person {name: 'Bob'})
// 在 Alice 和 Bob 之间创建 FRIENDS_WITH 关系
CREATE (a)-[r:FRIENDS_WITH {since: 2020}]->(b)
- 这组命令首先创建了两个
Person节点,分别代表 Alice 和 Bob。 - 然后在这两个节点之间创建了一个类型为
FRIENDS_WITH的关系,并设置了关系属性since,表示他们成为朋友的时间是 2020 年。 - 关系变量为
r,可以用于进一步操作或查询这条关系。
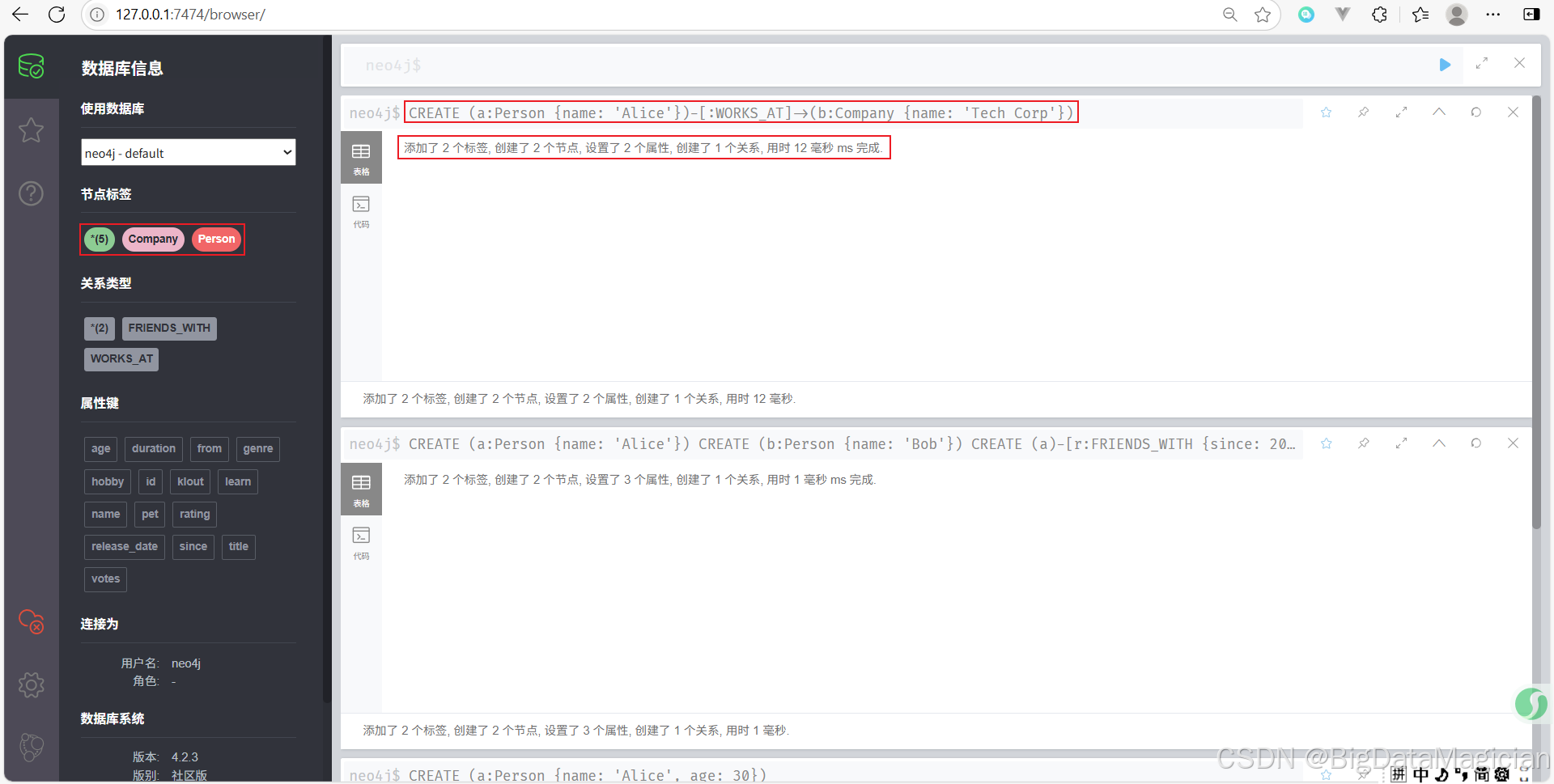
示例 3:在一个命令中创建节点和关系
CREATE (a:Person {name: 'Alice'})-[:WORKS_AT]->(b:Company {name: 'Tech Corp'})
- 此命令同时创建了两个节点(一个
Person节点和一个Company节点)以及它们之间的WORKS_AT关系。 - 注意这里没有给关系指定变量,这意味着我们不能直接引用这条关系进行后续操作,除非再次通过查询找到它。
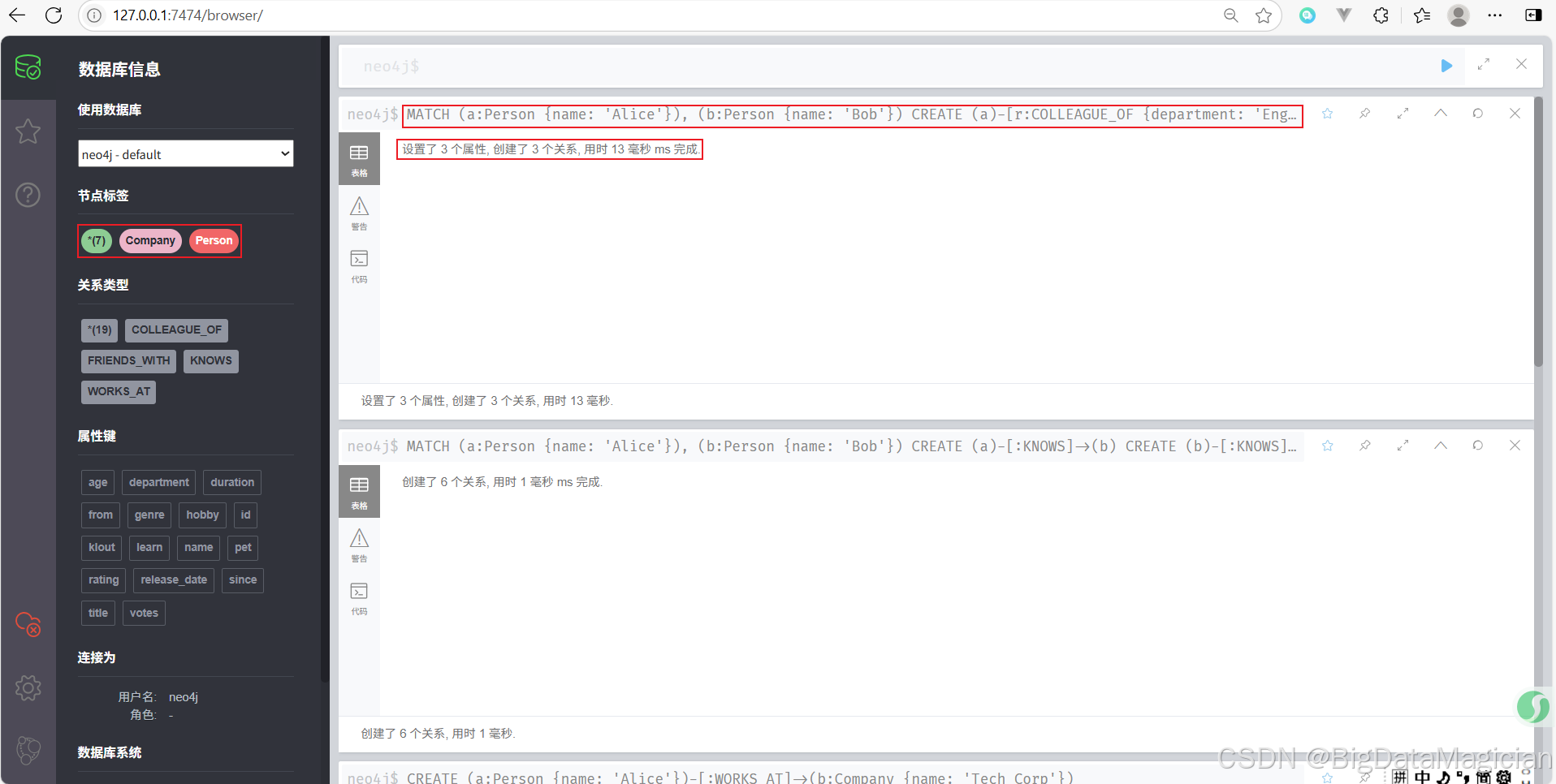
示例 4:使用已存在的节点创建关系
MATCH (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'})
CREATE (a)-[r:COLLEAGUE_OF {department: 'Engineering'}]->(b)
- 首先通过
MATCH查找数据库中名为 Alice 和 Bob 的节点。 - 然后在找到的这两个节点之间创建了一个
COLLEAGUE_OF类型的关系,并添加了一个department属性说明他们在同一个部门工作。 - 给关系指定了变量
r,方便之后对这条关系进行修改或查询。
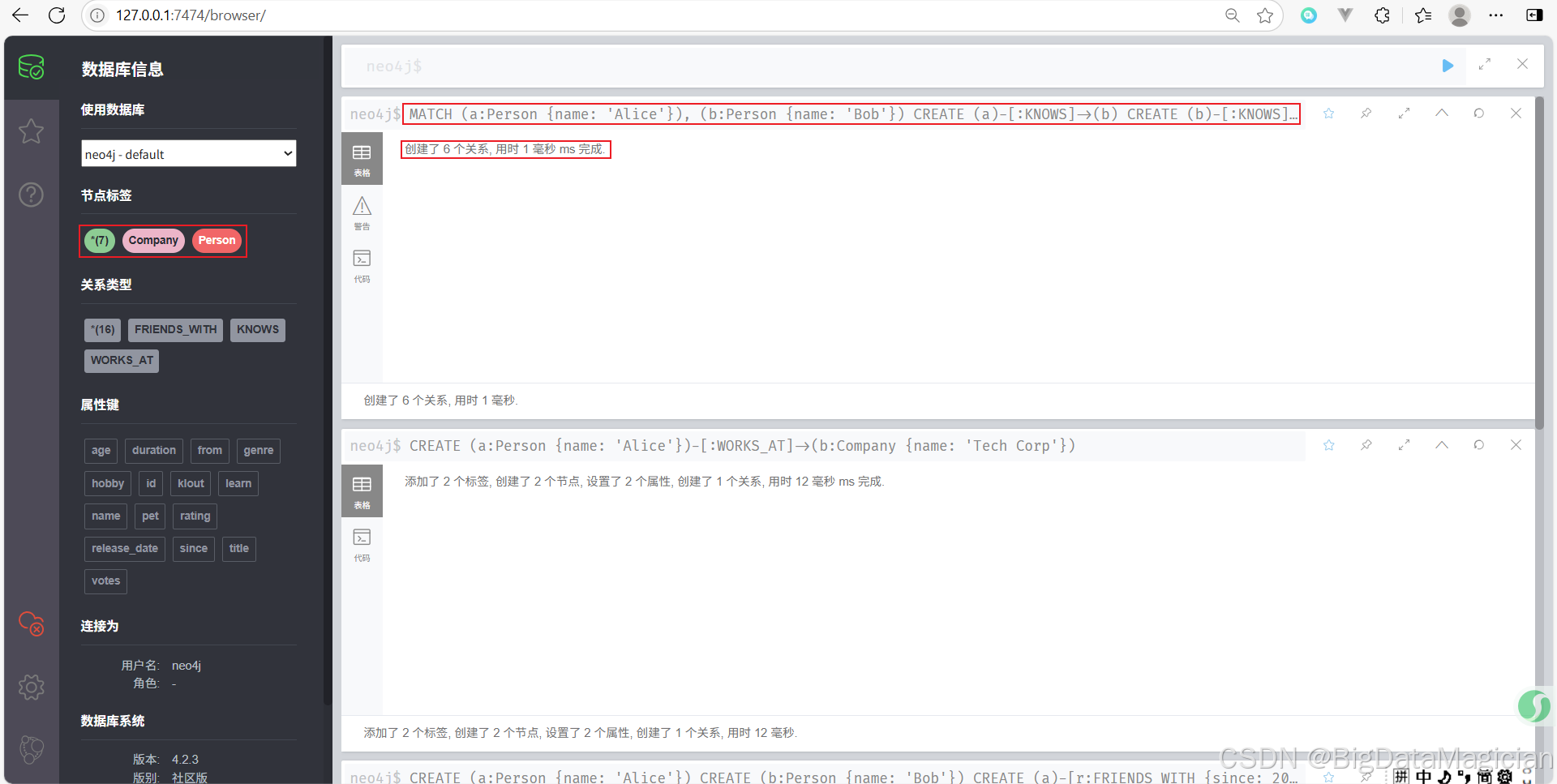
示例 5:创建双向关系
虽然在 Cypher 中默认定义的关系是有方向性的,但可以通过创建两条相反方向的关系来模拟双向关系:
MATCH (a:Person {name: 'Alice'}), (b:Person {name: 'Bob'})
CREATE (a)-[:KNOWS]->(b)
CREATE (b)-[:KNOWS]->(a)
- 这段代码创建了两个
KNOWS关系,一条从 Alice 到 Bob,另一条从 Bob 到 Alice,从而实现了双向关系的效果。
2. 查询数据
在 Neo4j 中,MATCH 是用于查询图数据的核心命令。它通过模式匹配(Pattern Matching) 来查找符合特定结构的节点、关系及其属性。
2.1 语法
基本语法结构如下:
MATCH (variable1:Label1 {property1: value1})
RETURN variable1
(variable1:Label1 {property1: value1}):表示一个带有标签和属性的节点。RETURN:指定你想返回的数据内容。
匹配带关系的结构语法如下:
MATCH (variable1:Label1)-[:RELATIONSHIP_TYPE]->(variable2:Label2)
RETURN variable1, variable2
-[:RELATIONSHIP_TYPE]->:表示两个节点之间的关系,方向可变(->或<-)。RELATIONSHIP_TYPE:是你定义的关系类型,如KNOWS,WORKS_AT等。
使用 WHERE 进行过滤语法如下:
MATCH (n:Person)
WHERE n.age > 30
RETURN n.name
WHERE子句用于添加条件过滤查询结果。
2.2 示例
示例 1:查询所有 Person 节点
MATCH (p:Person)
RETURN p
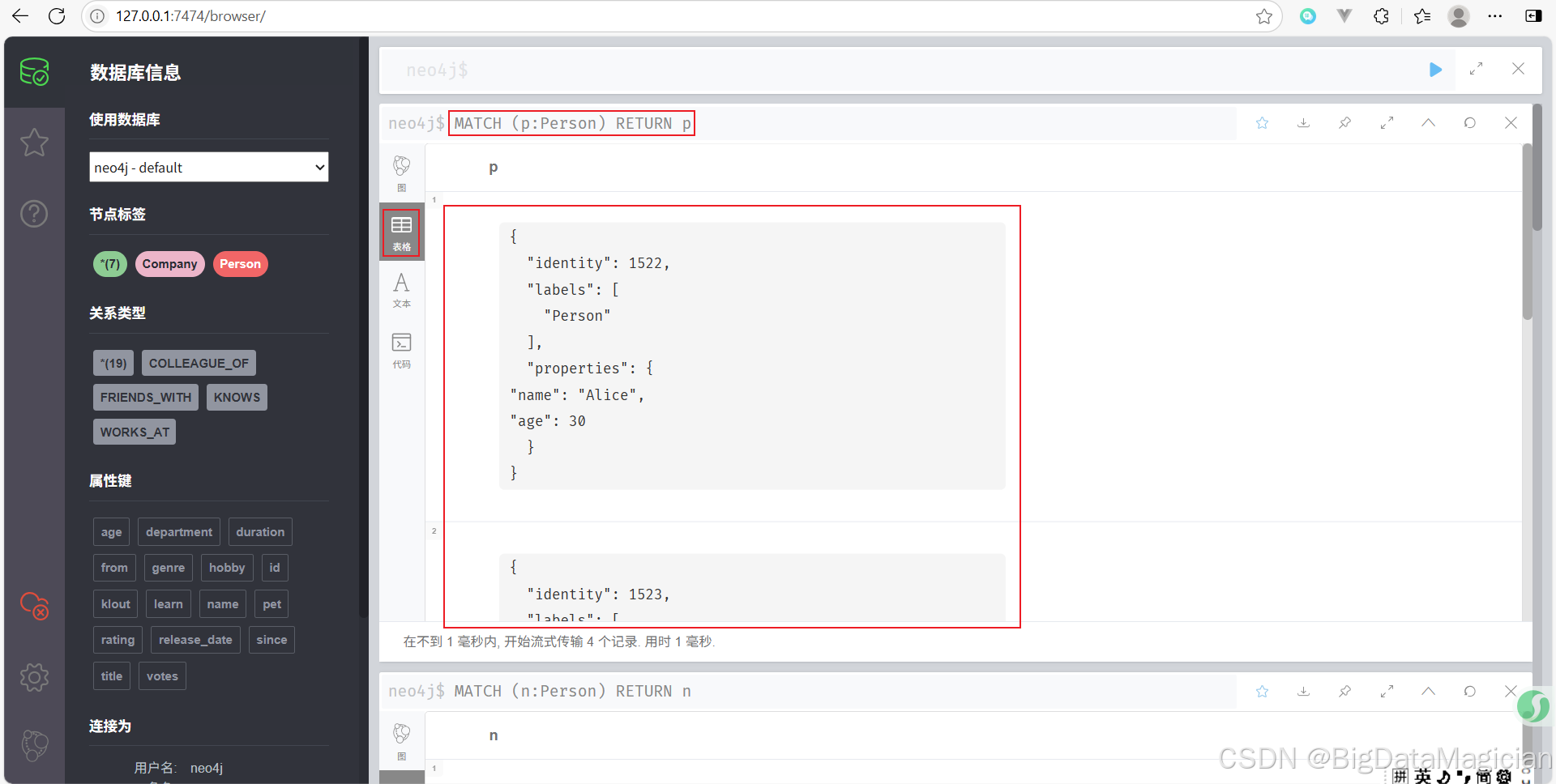
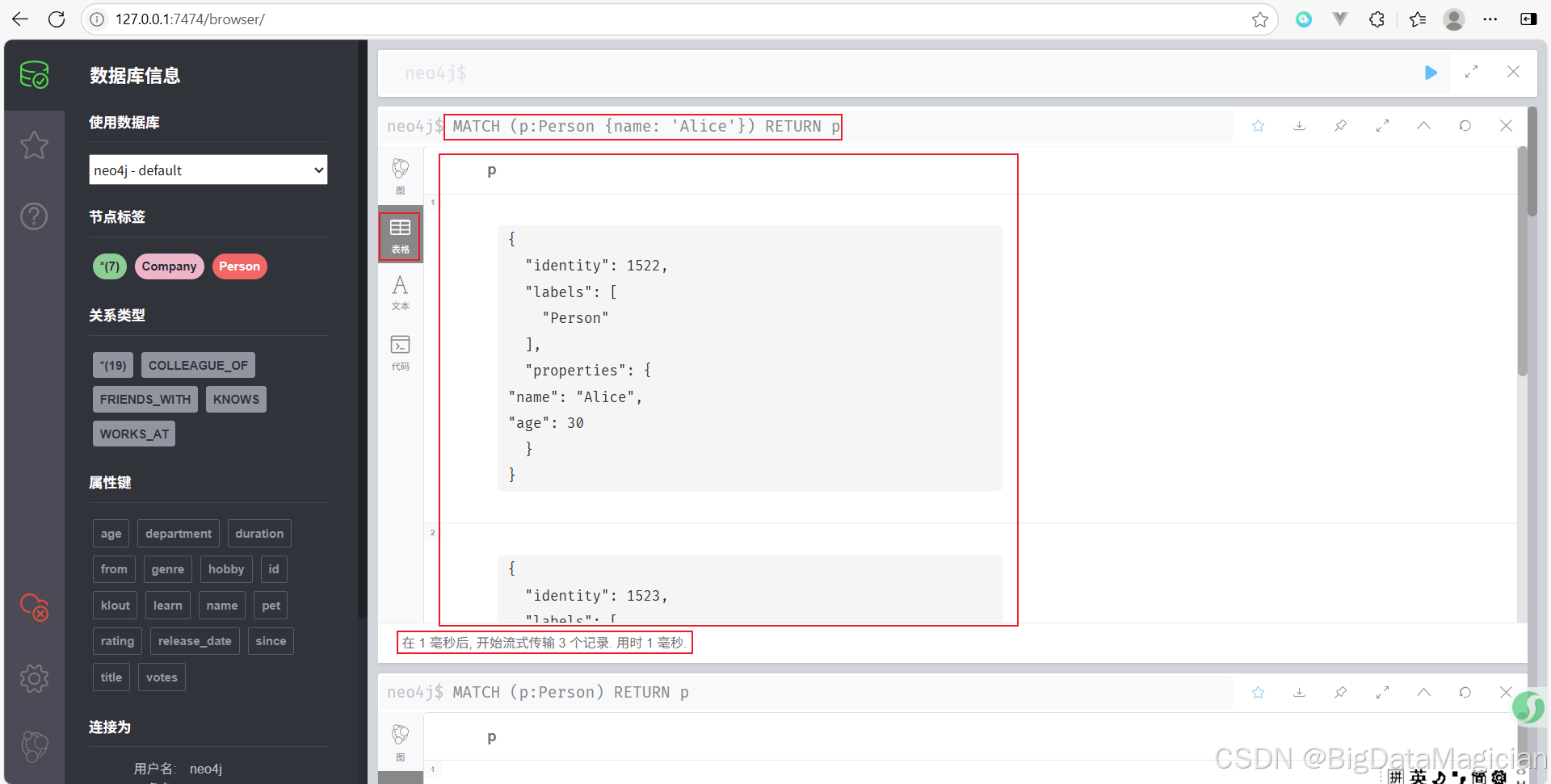
示例 2:查询具有特定属性的节点
查找名字为 Alice 的 Person 节点。
MATCH (p:Person {name: 'Alice'})
RETURN p
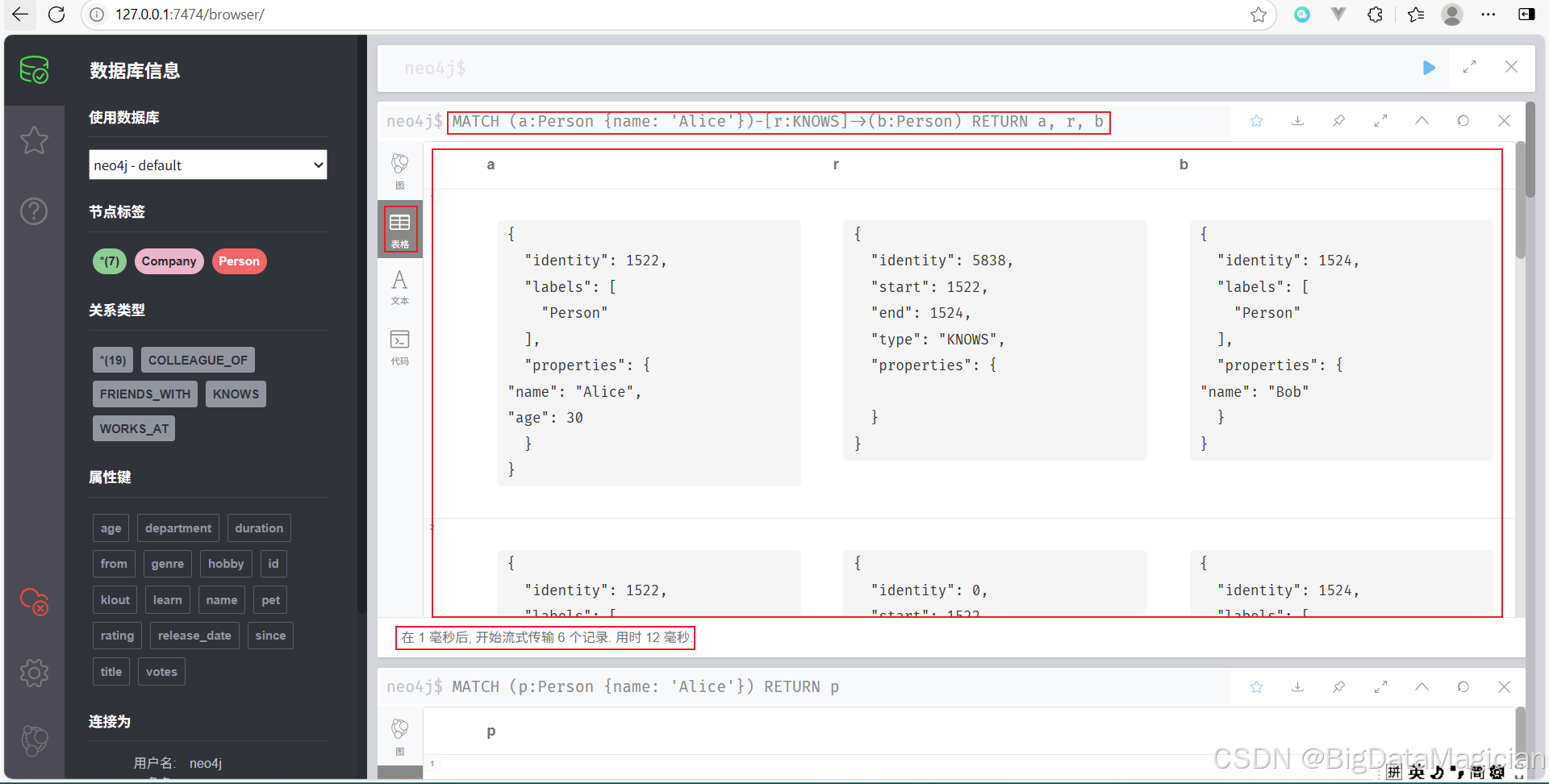
示例 3:查询节点和其关系
查找 Alice 所认识的所有人,并返回 Alice、KNOWS 关系以及对方节点。
MATCH (a:Person {name: 'Alice'})-[r:KNOWS]->(b:Person)
RETURN a, r, b
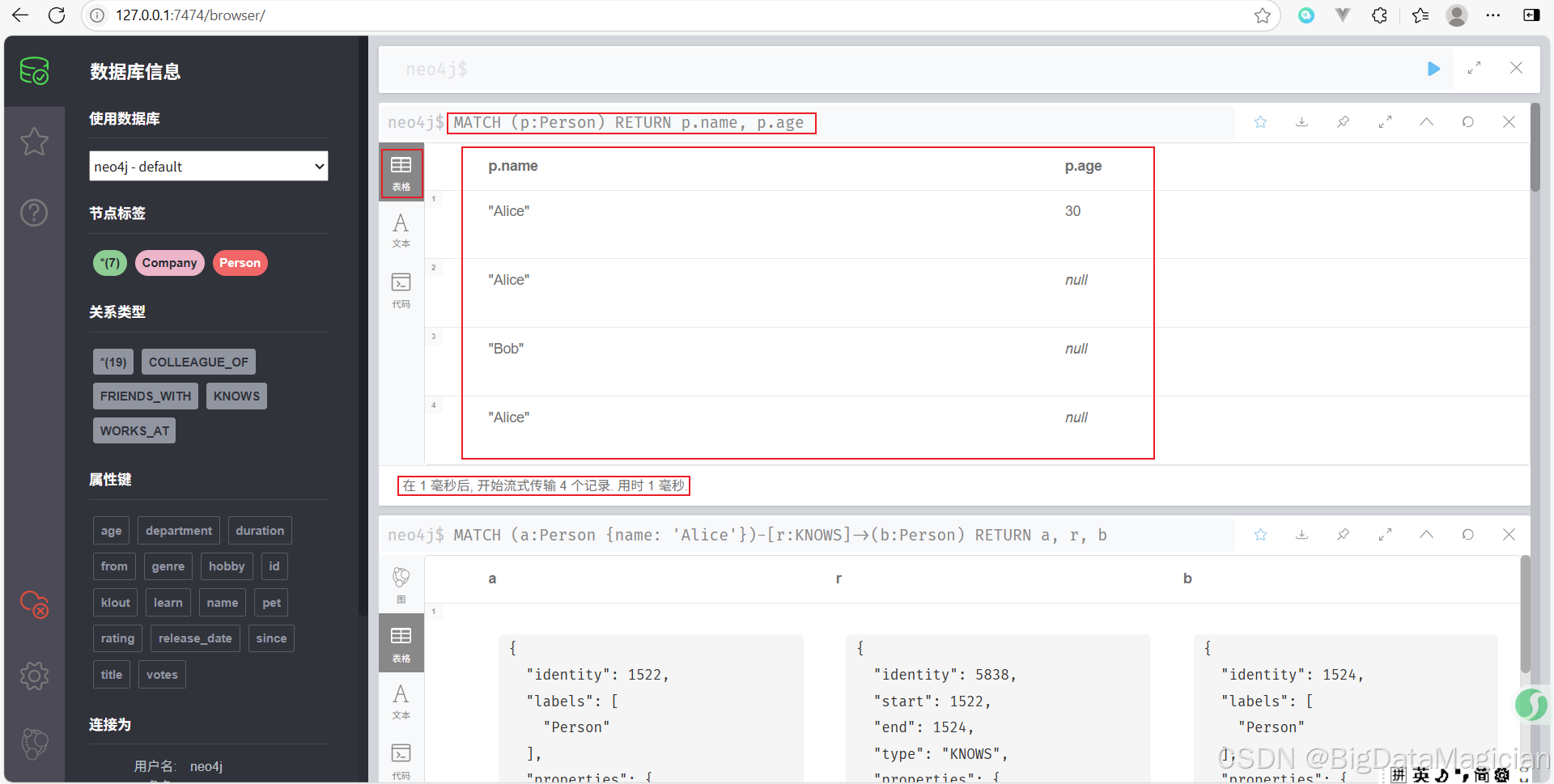
示例 4:仅返回某些字段或属性
只返回 Person 节点的 name 和 age 属性。
MATCH (p:Person)
RETURN p.name, p.age
示例 5:使用 WHERE 过滤年龄大于 30 的人
查找并返回年龄大于 20 的人。
MATCH (p:Person)
WHERE p.age > 20
RETURN p.name, p.age
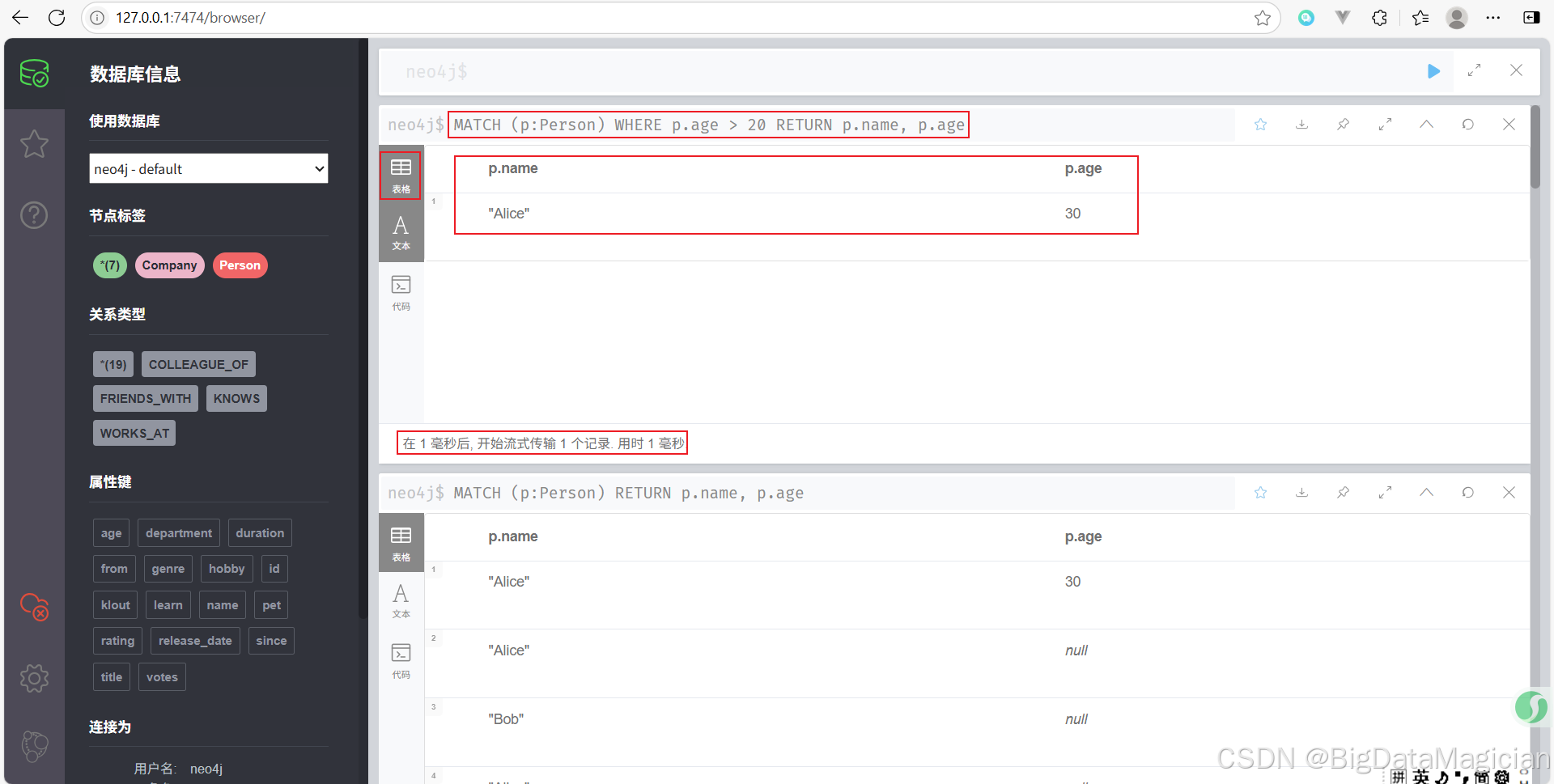
示例 6:查找双向关系(比如互为好友)
MATCH (a:Person {name: 'Alice'})-[r1:KNOWS]->(b:Person {name: 'Bob'})
MATCH (b)-[r2:KNOWS]->(a)
RETURN a, r1, b, r2
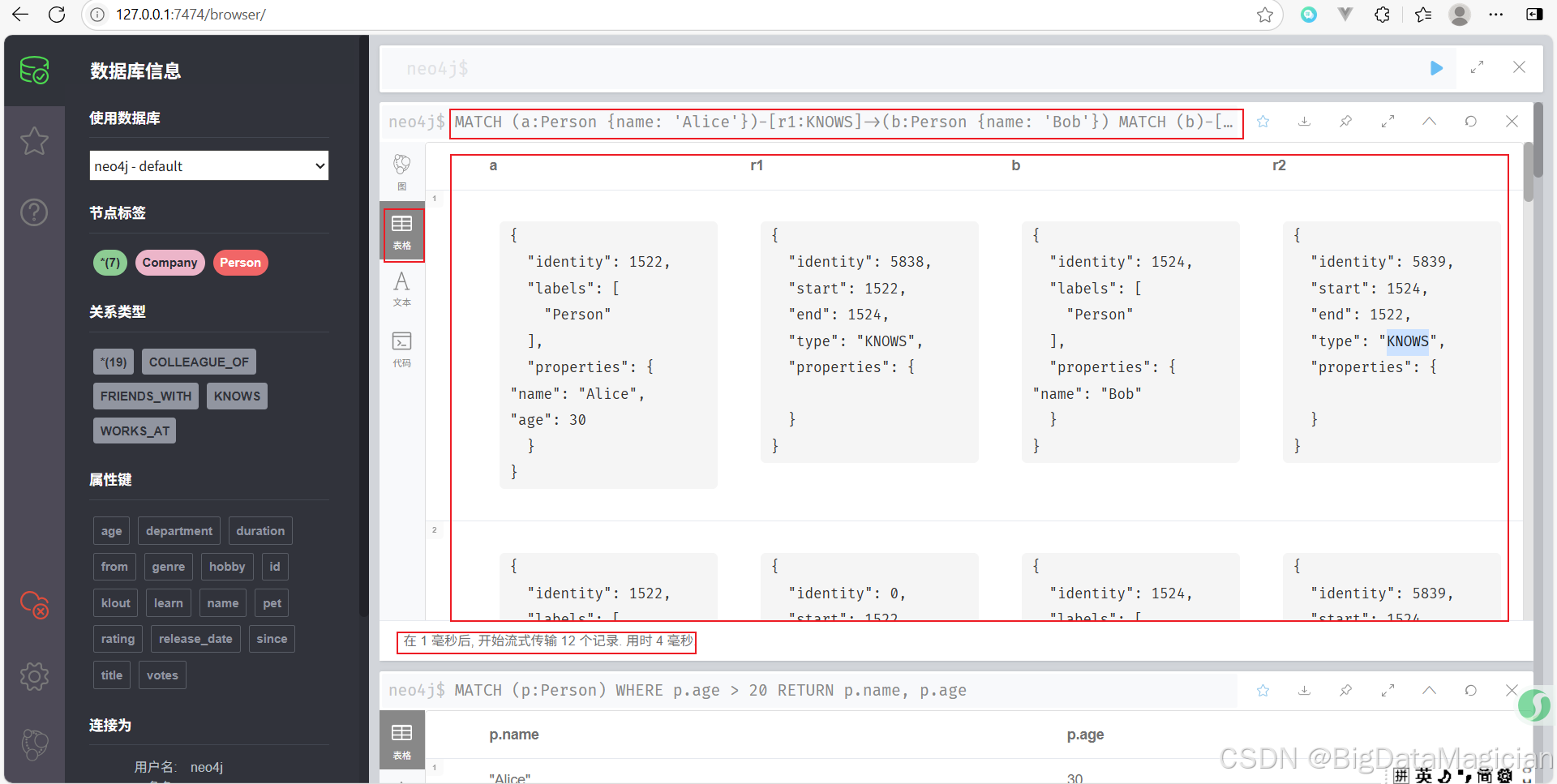
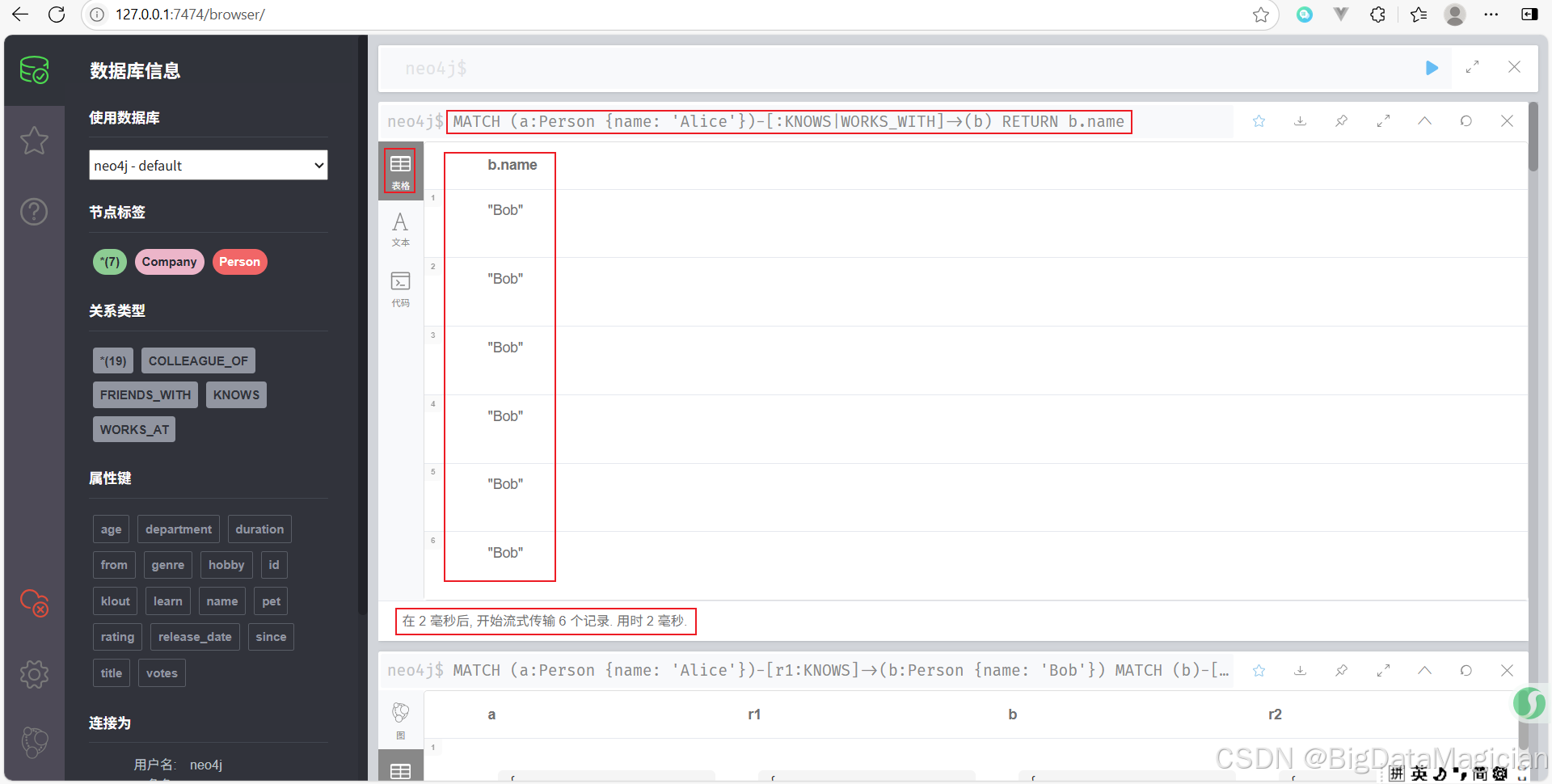
示例 7:模糊匹配多个关系类型
查找 Alice 认识或一起工作的人。
MATCH (a:Person {name: 'Alice'})-[:KNOWS|WORKS_WITH]->(b)
RETURN b.name
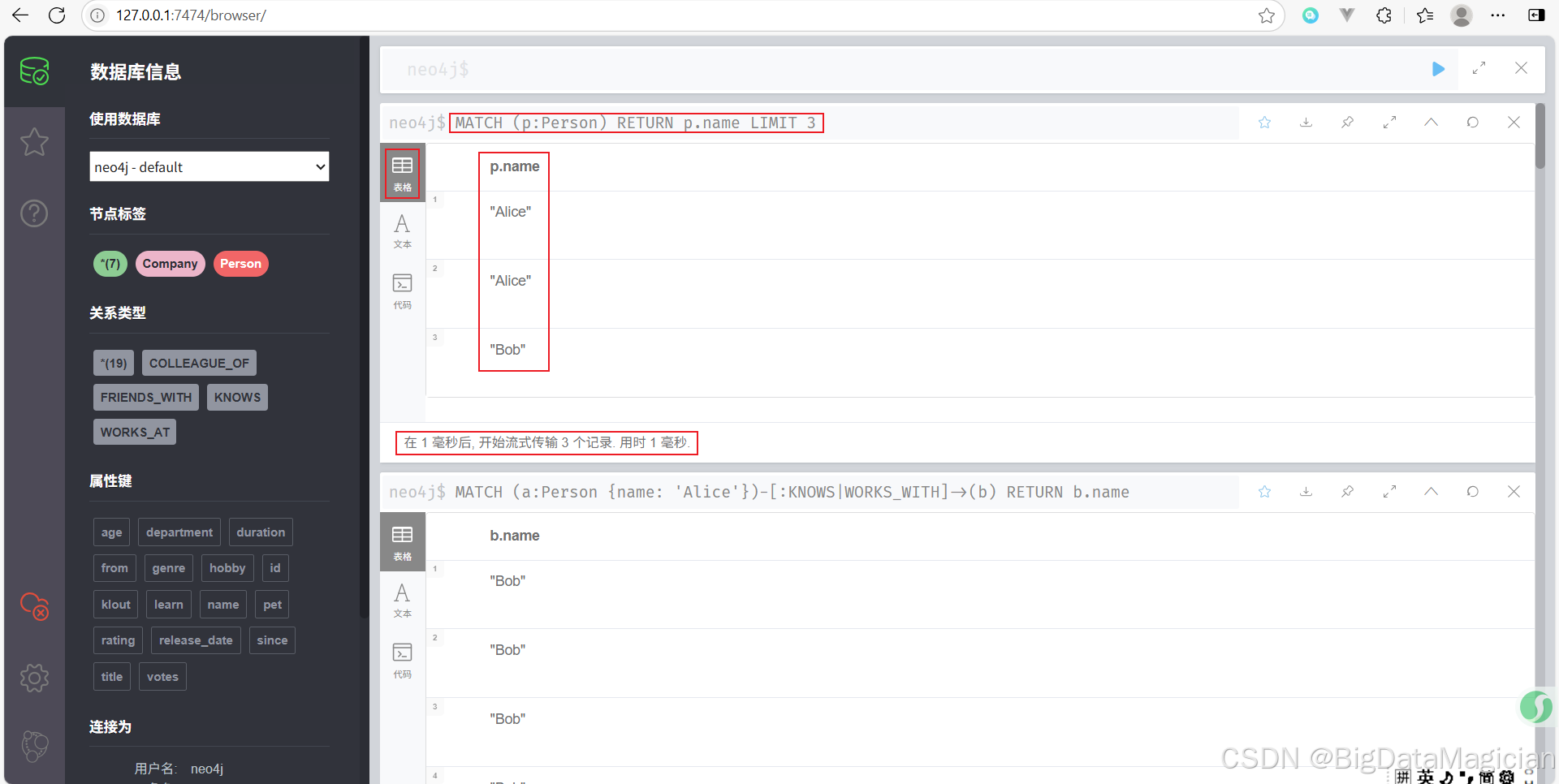
示例 8:限制返回数量
最多只返回 3 个 Person 的名字。
MATCH (p:Person)
RETURN p.name
LIMIT 3
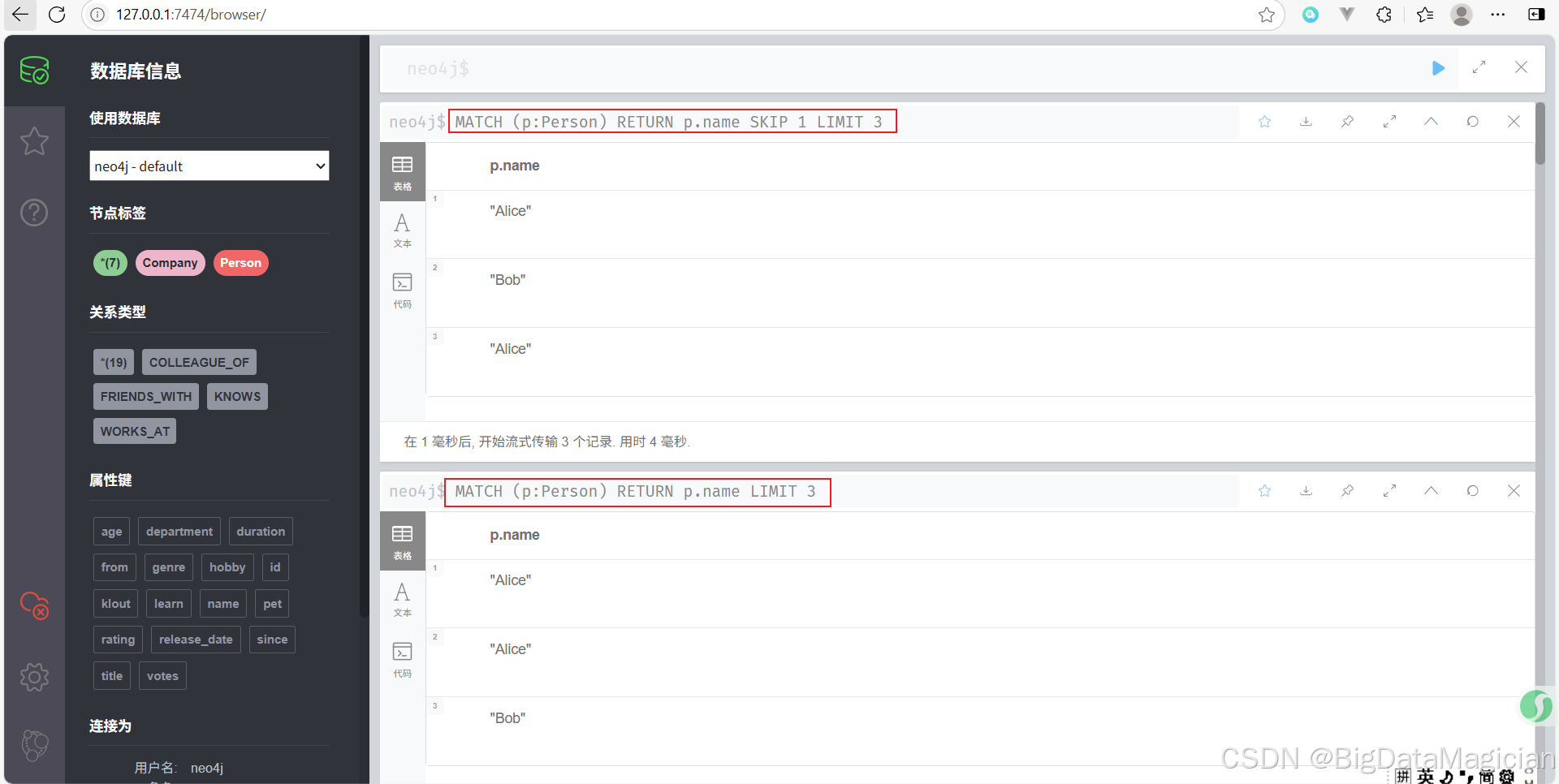
跳过 1 个查询结果并最多返回 3 个 Person 的名字。
MATCH (p:Person)
RETURN p.name
SKIP 1
LIMIT 3
3. 更新数据
在 Neo4j 中,使用 Cypher 可以方便地更新图数据库中的节点(Node)和关系(Relationship)的属性值;可以使用 SET、REMOVE 等命令进行更新操作。
3.1 语法
更新节点属性的语法如下:
MATCH (n:Label {property: value})
SET n.propertyName = newValue
RETURN n
MATCH:查找要更新的节点。SET:设置或修改某个属性的值。RETURN:返回更新后的结果(可选)。
删除属性或标签语法如下:
MATCH (n:Person {name: 'Alice'})
REMOVE n.age
RETURN n
REMOVE命令可以删除节点或关系的属性或标签。
更新关系属性语法如下:
MATCH ()-[r:RELATIONSHIP_TYPE]->()
SET r.newProperty = 'value'
RETURN r
3.2 示例
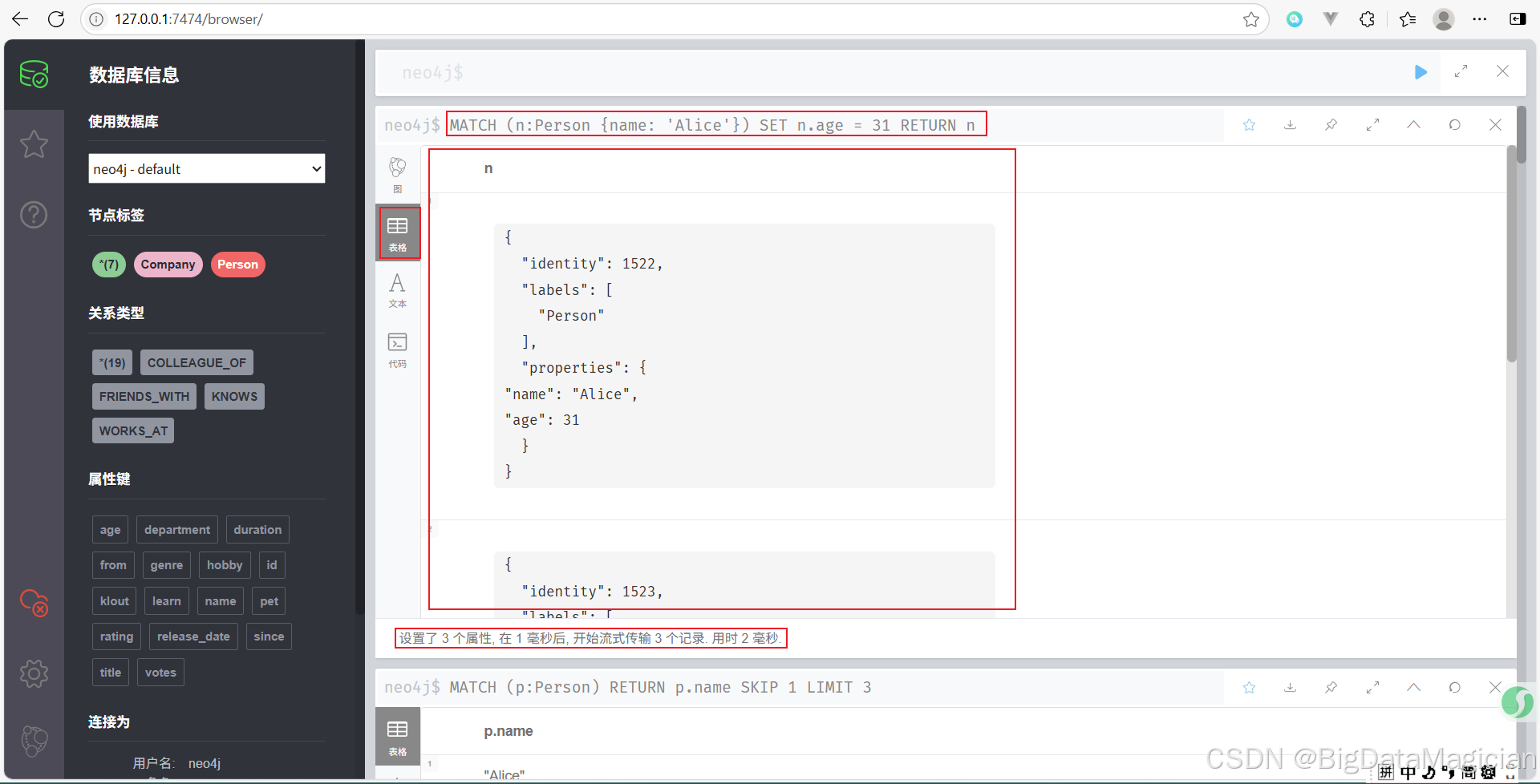
示例 1:更新节点的属性
将名为 Alice 的 Person 节点的年龄改为 31 岁。
MATCH (n:Person {name: 'Alice'})
SET n.age = 31
RETURN n
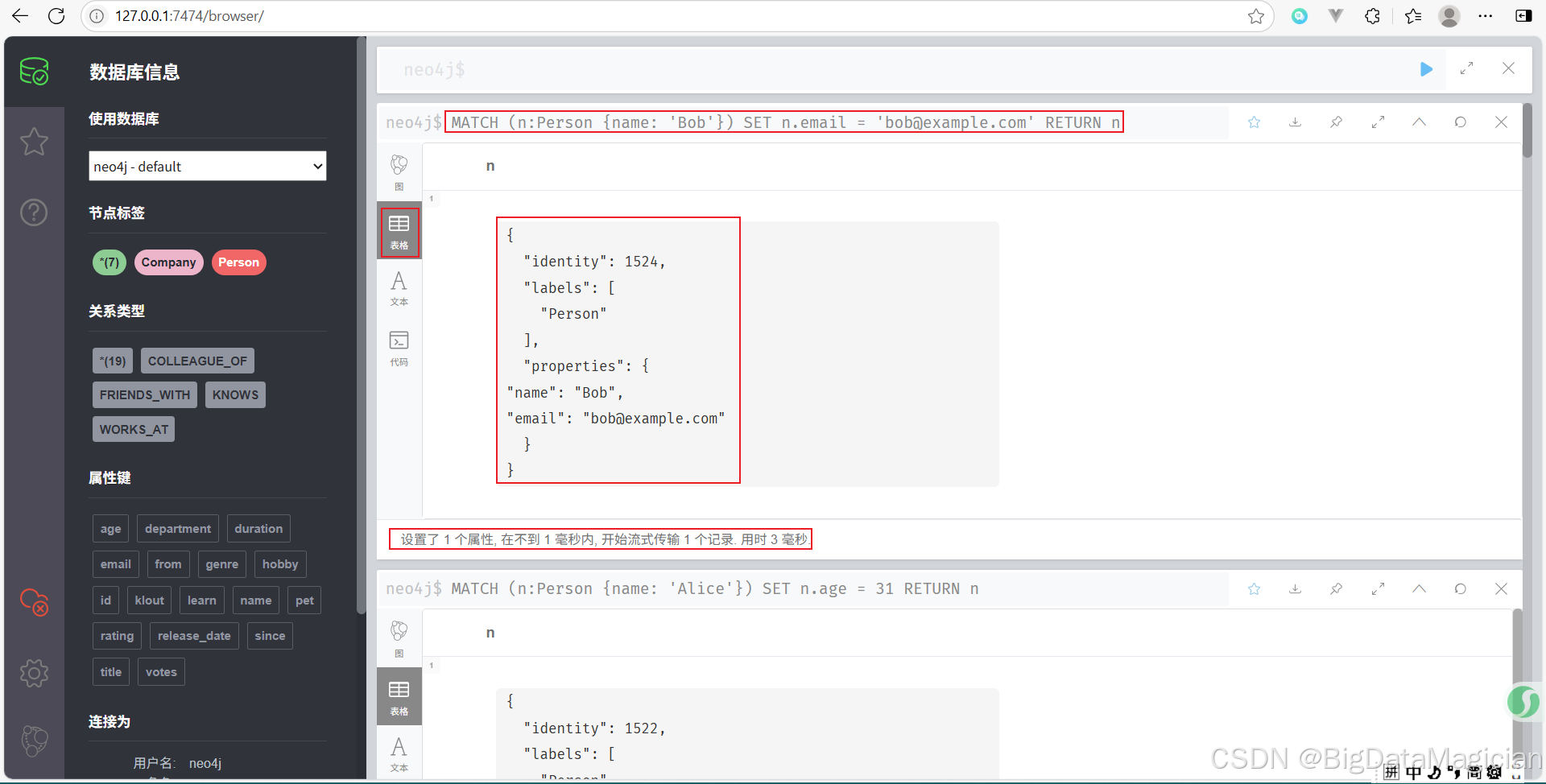
示例 2:添加新的属性
为名为 Bob 的 Person 添加一个新属性 email。
MATCH (n:Person {name: 'Bob'})
SET n.email = 'bob@example.com'
RETURN n
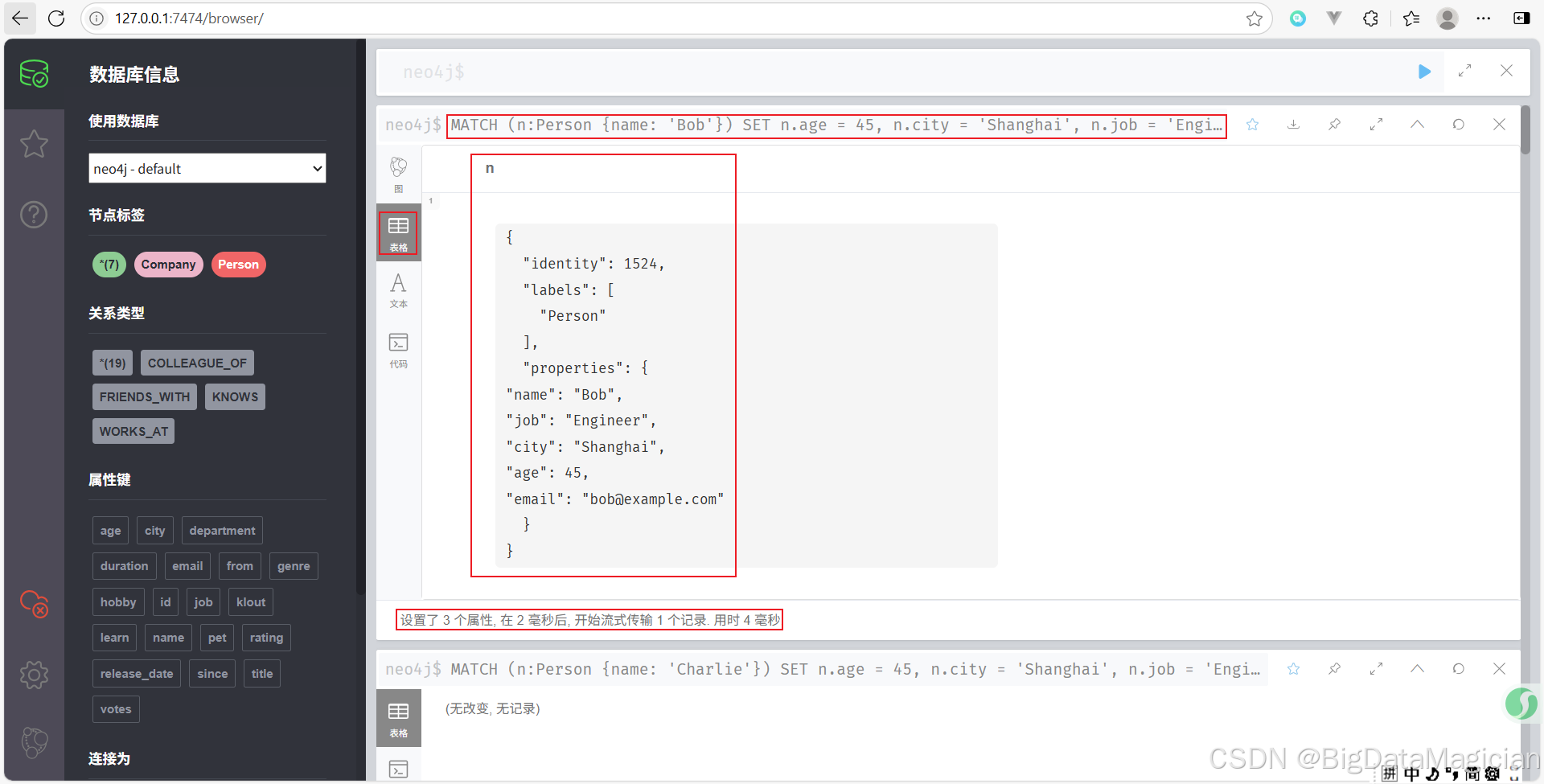
示例 3:一次性设置多个属性
可以在一条 SET 语句中同时设置多个属性。
MATCH (n:Person {name: 'Bob'})
SET n.age = 45, n.city = 'Shanghai', n.job = 'Engineer'
RETURN n
示例 4:删除节点的某个属性
删除名为 Alice 的 Person 的 age 属性。
MATCH (n:Person {name: 'Alice'})
REMOVE n.age
RETURN n
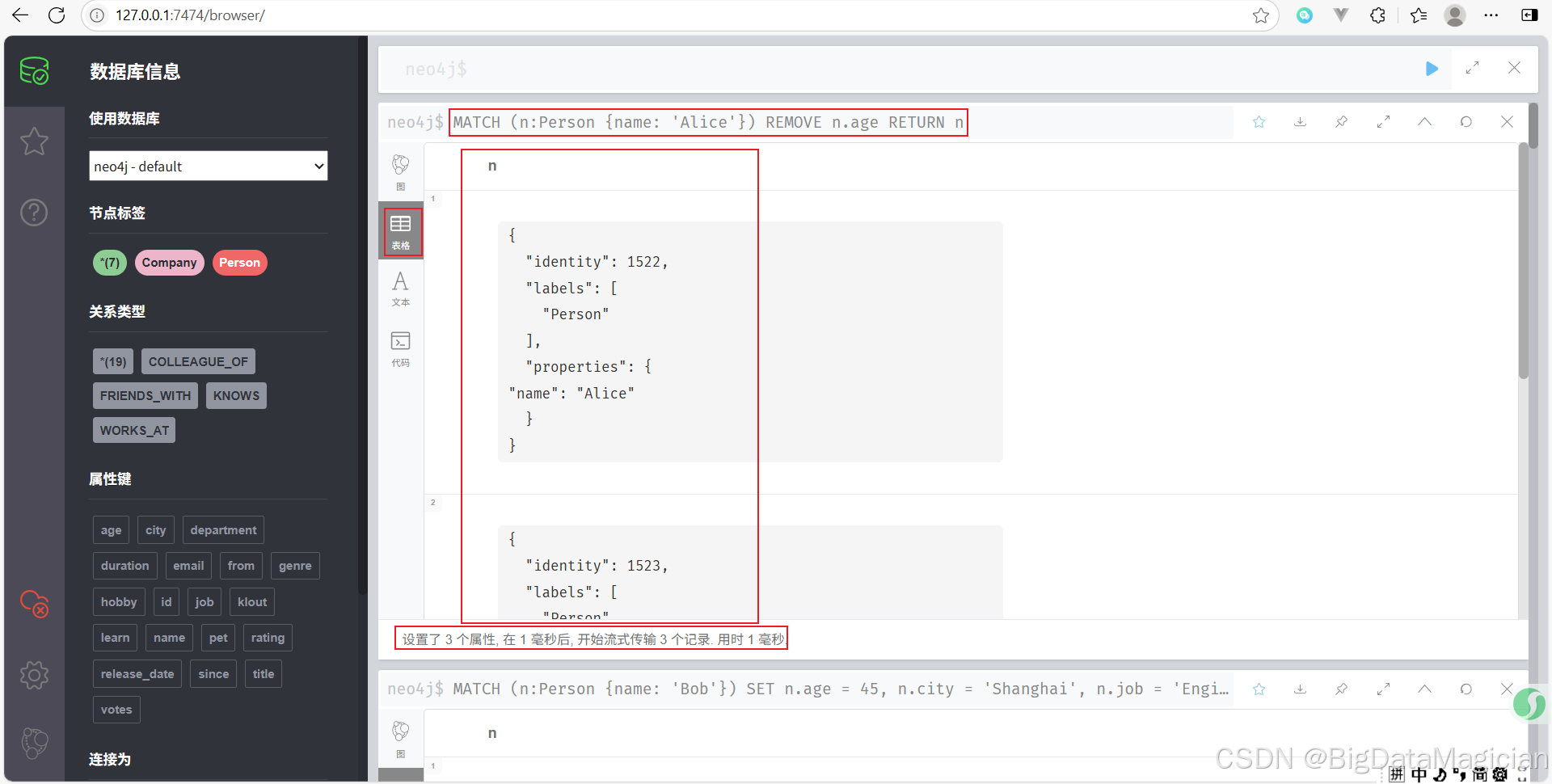
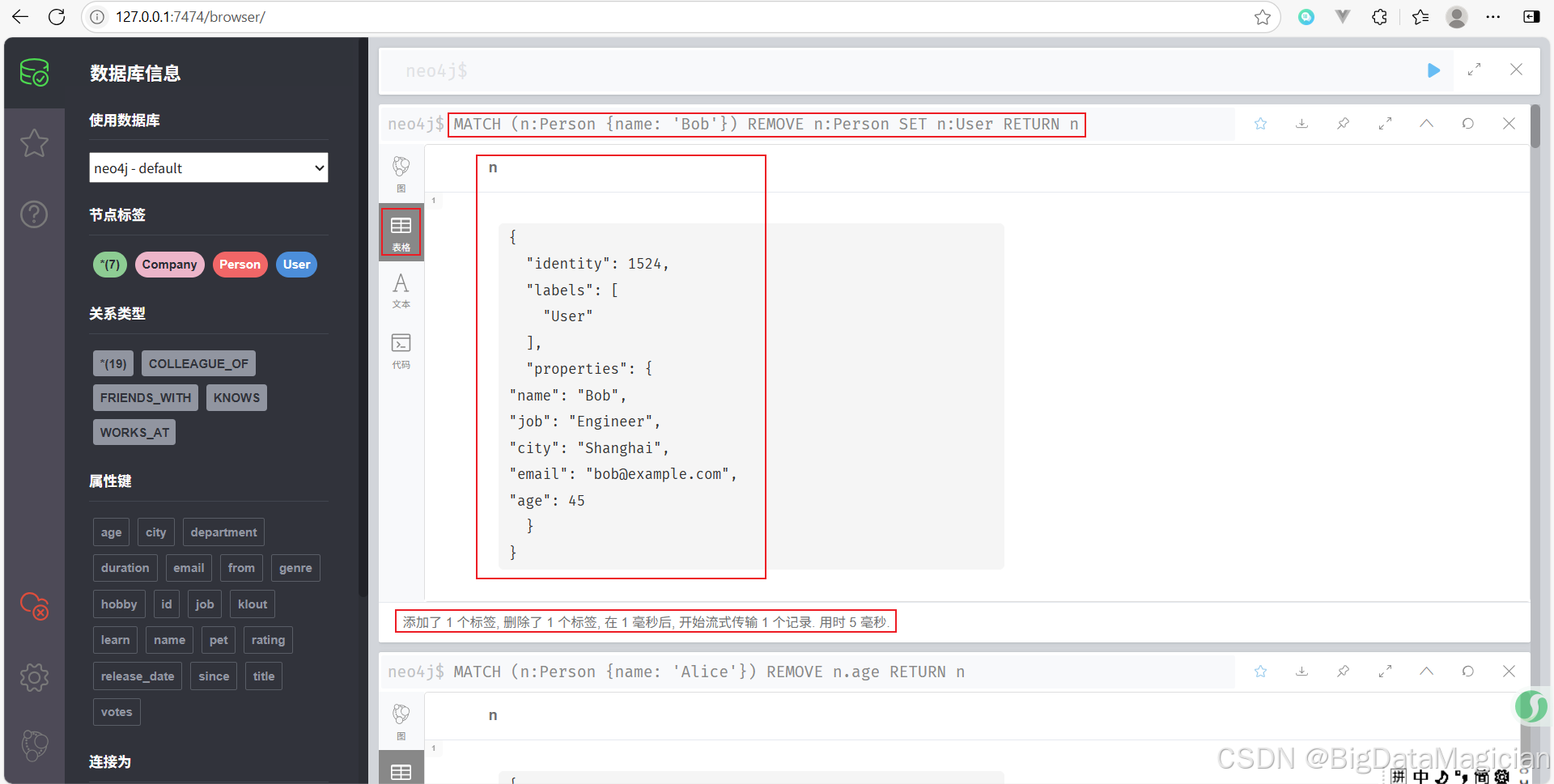
示例 5:删除节点的标签
将名为 Bob 的 Person 节点的标签从 Person 改为 User。
MATCH (n:Person {name: 'Bob'})
REMOVE n:Person
SET n:User
RETURN n
⚠️ 注意:Neo4j 不支持直接重命名标签,只能通过先移除再添加的方式来“更改”标签。
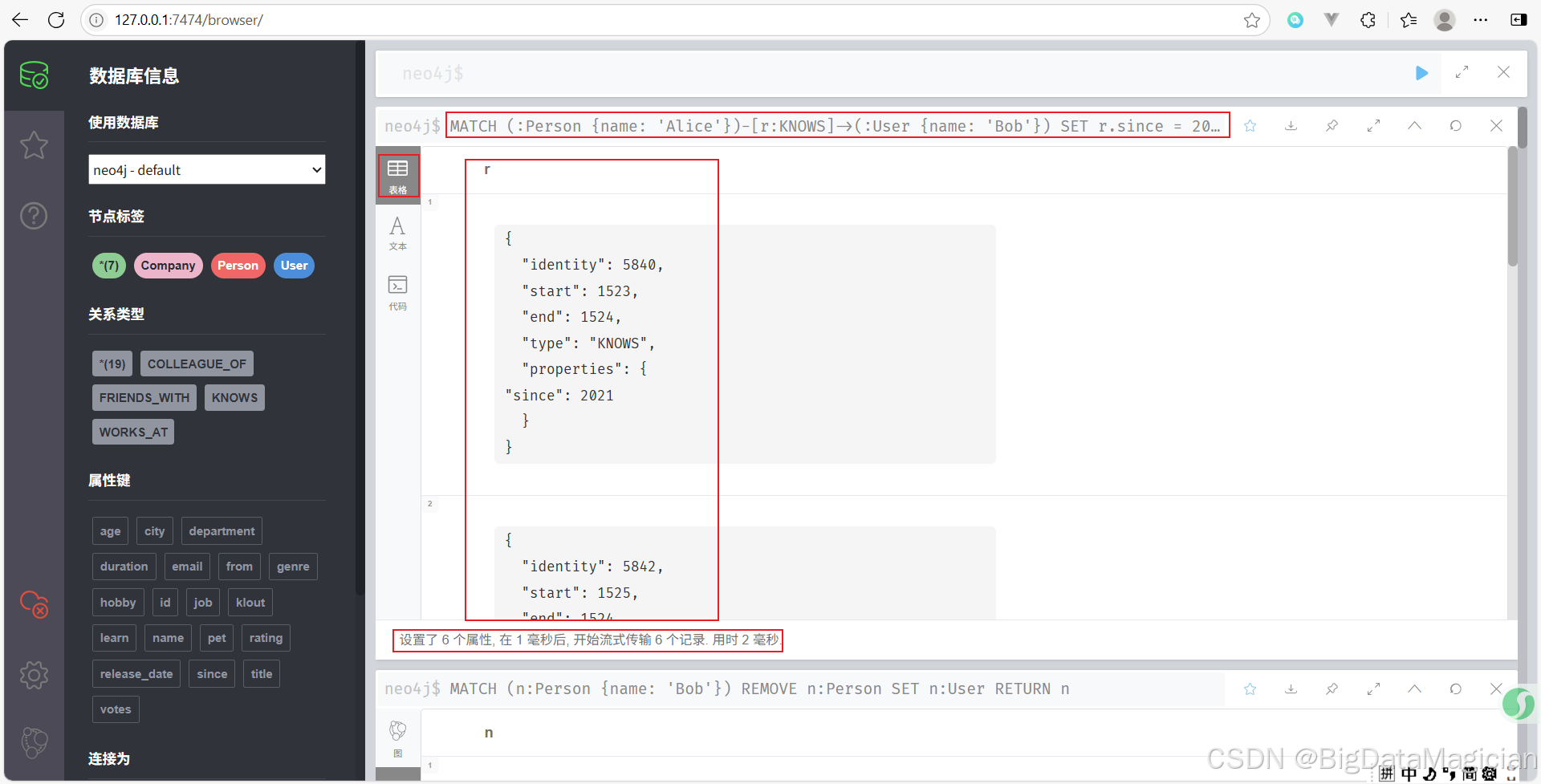
示例 6:更新关系属性
更新Alice和Bob的 KNOWS 关系的 since 属性。
MATCH (:Person {name: 'Alice'})-[r:KNOWS]->(:User {name: 'Bob'})
SET r.since = 2021
RETURN r
4. 删除节点与关系
在 Neo4j 中,删除图数据库中的 节点(Node) 和 关系(Relationship) 是常见的操作。Cypher 提供了 DELETE 和 DETACH DELETE 等命令来完成这些任务。
由于 Neo4j 的图结构特性:一个节点不能有未删除的关系存在,因此在删除节点前必须先删除它关联的所有关系,否则会报错。
4.1 语法
删除关系的语法如下:
MATCH ()-[r:RELATIONSHIP_TYPE]->()
DELETE r
- 使用
MATCH找到要删除的关系。 - 使用
DELETE删除匹配到的关系。
删除节点的语法(需先删除关系)如下:
MATCH (n:Label {property: value})
DELETE n
⚠️ 如果该节点还有关系存在,将抛出错误。
推荐方式:使用 DETACH DELETE
MATCH (n:Label {property: value})
DETACH DELETE n
DETACH DELETE会自动删除节点及其所有关联的关系,无需手动先删除关系。- 这是最安全、最常用的删除节点的方式。
4.2 示例
示例 1:删除两个特定节点之间的关系
删除 Alice 和 Bob 之间的 KNOWS 关系。
MATCH (a:Person {name: 'Alice'})-[r:KNOWS]->(b:Person {name: 'Bob'})
DELETE r
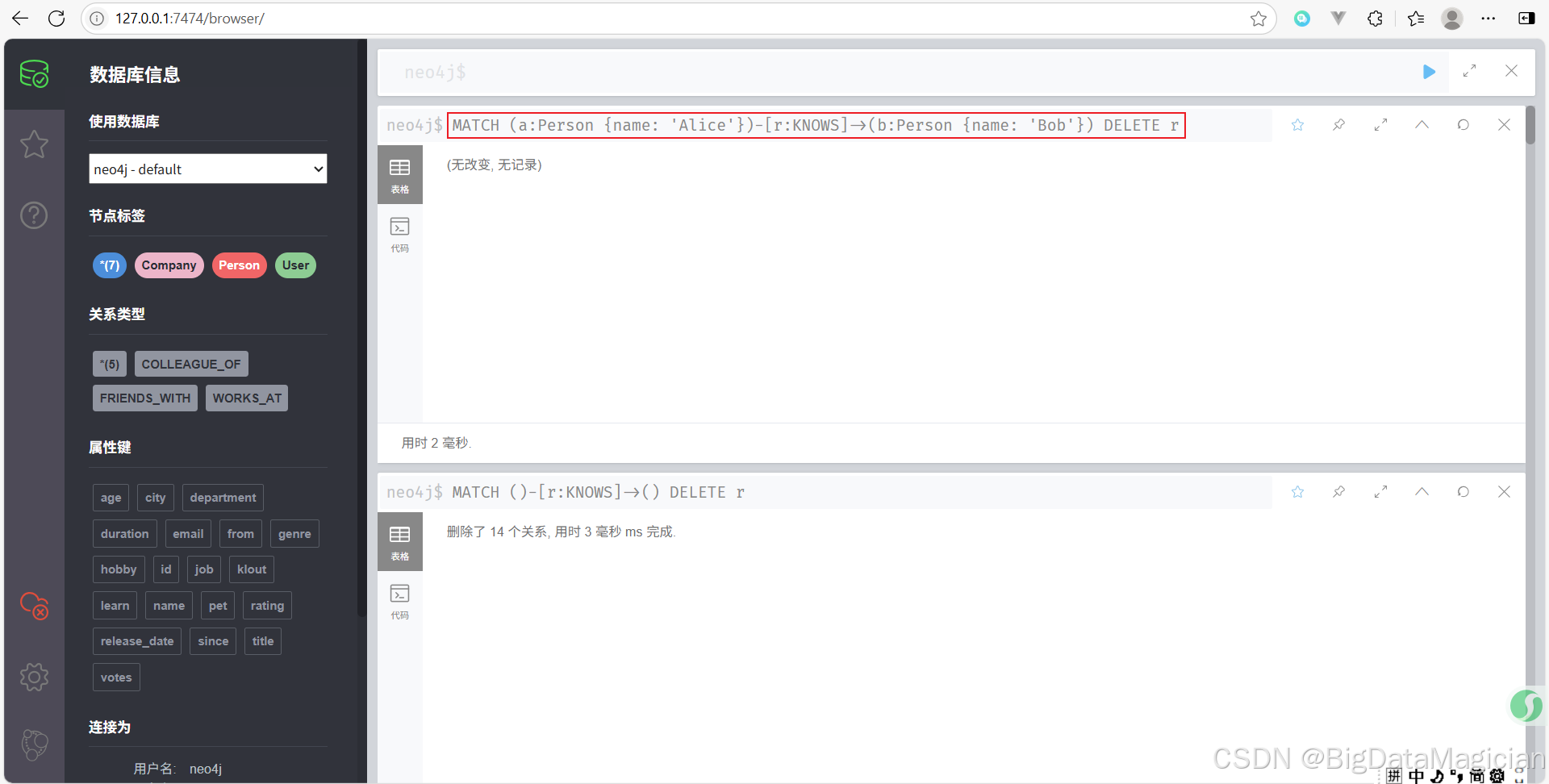
示例 2:删除特定类型的关系
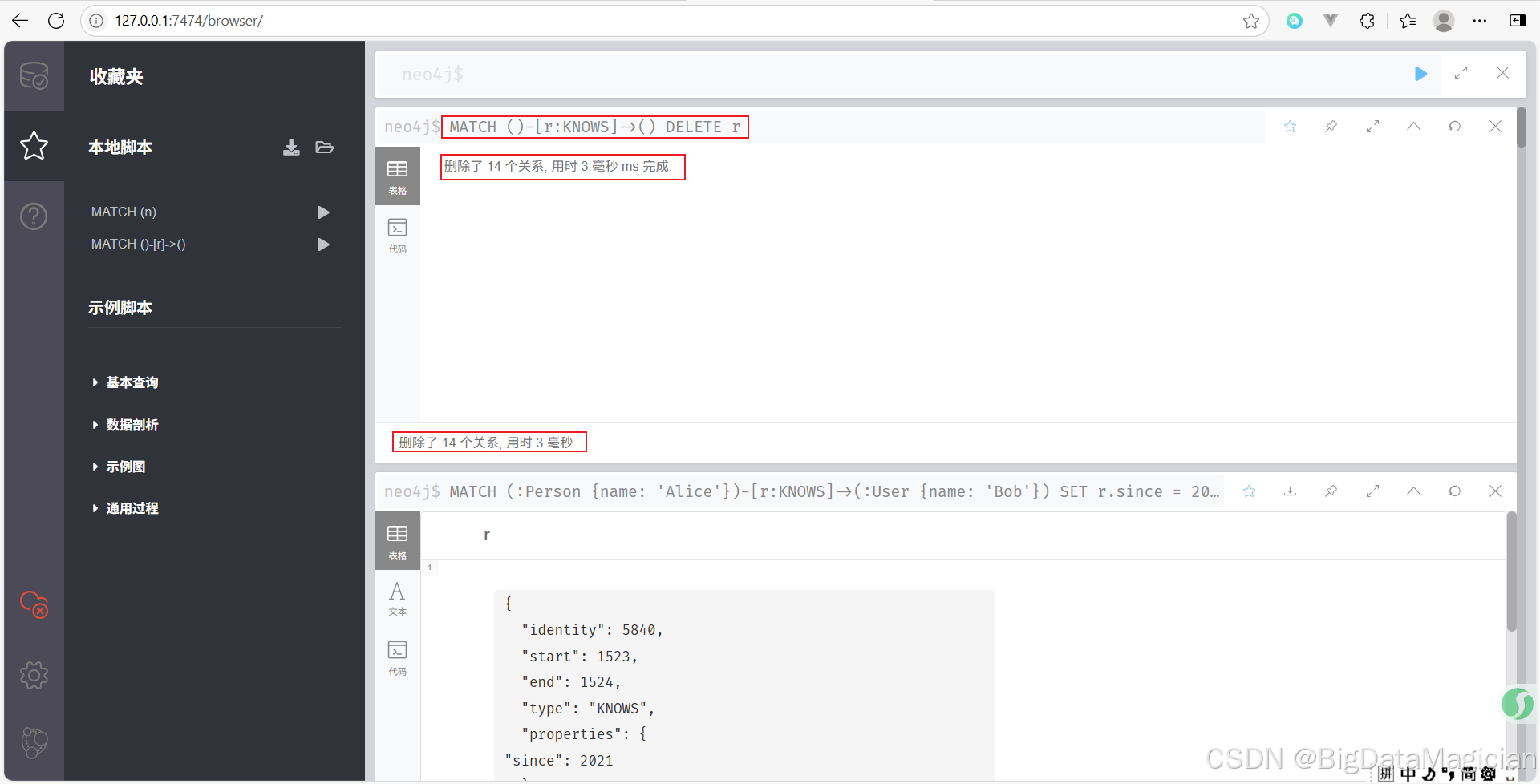
删除所有的 KNOWS 类型关系。
MATCH ()-[r:KNOWS]->()
DELETE r
示例 3:删除某个特定节点(先删除关系)
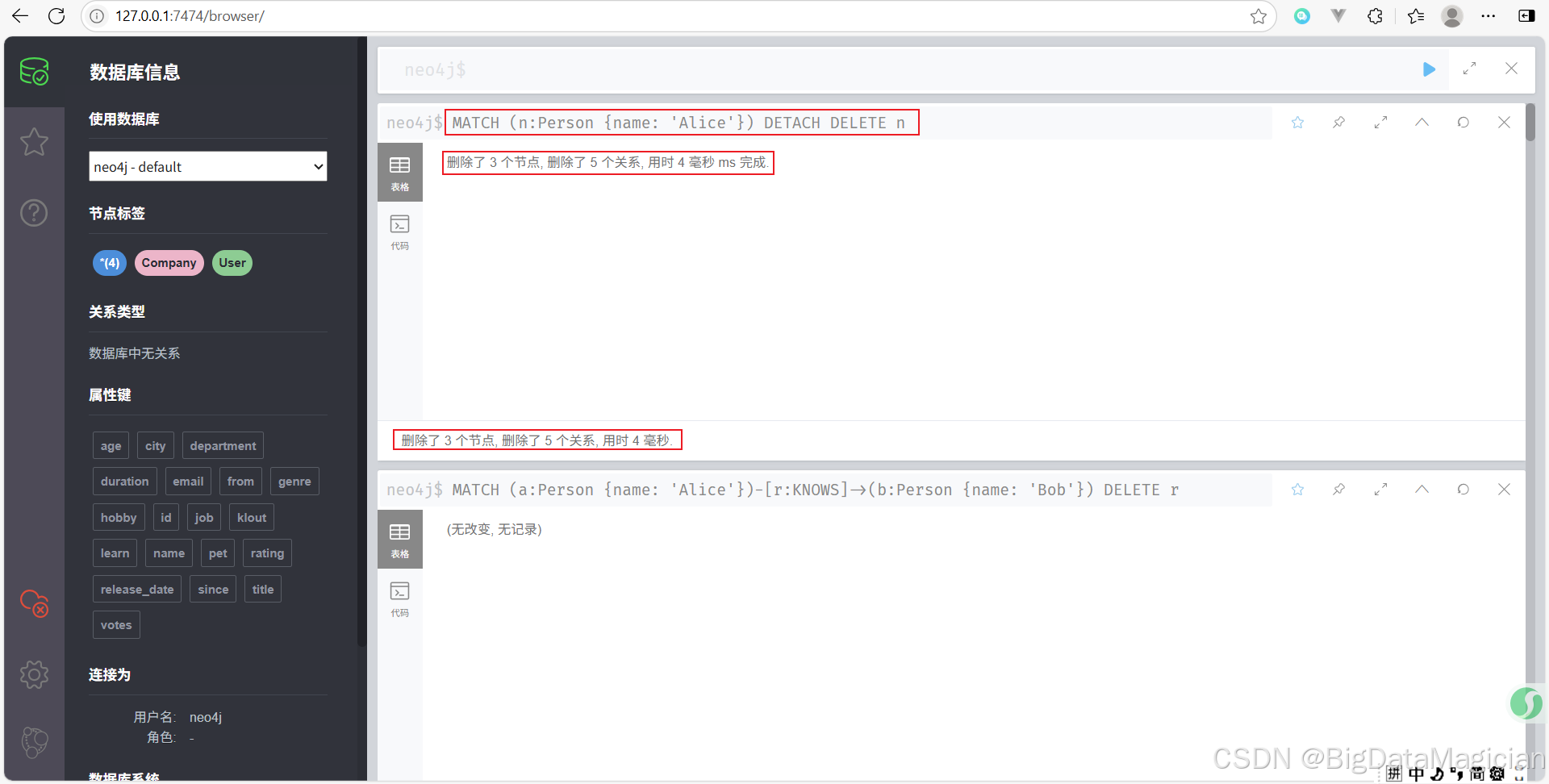
删除名为 Alice 的 Person 节点及其所有关系。
MATCH (n:Person {name: 'Alice'})
DETACH DELETE n
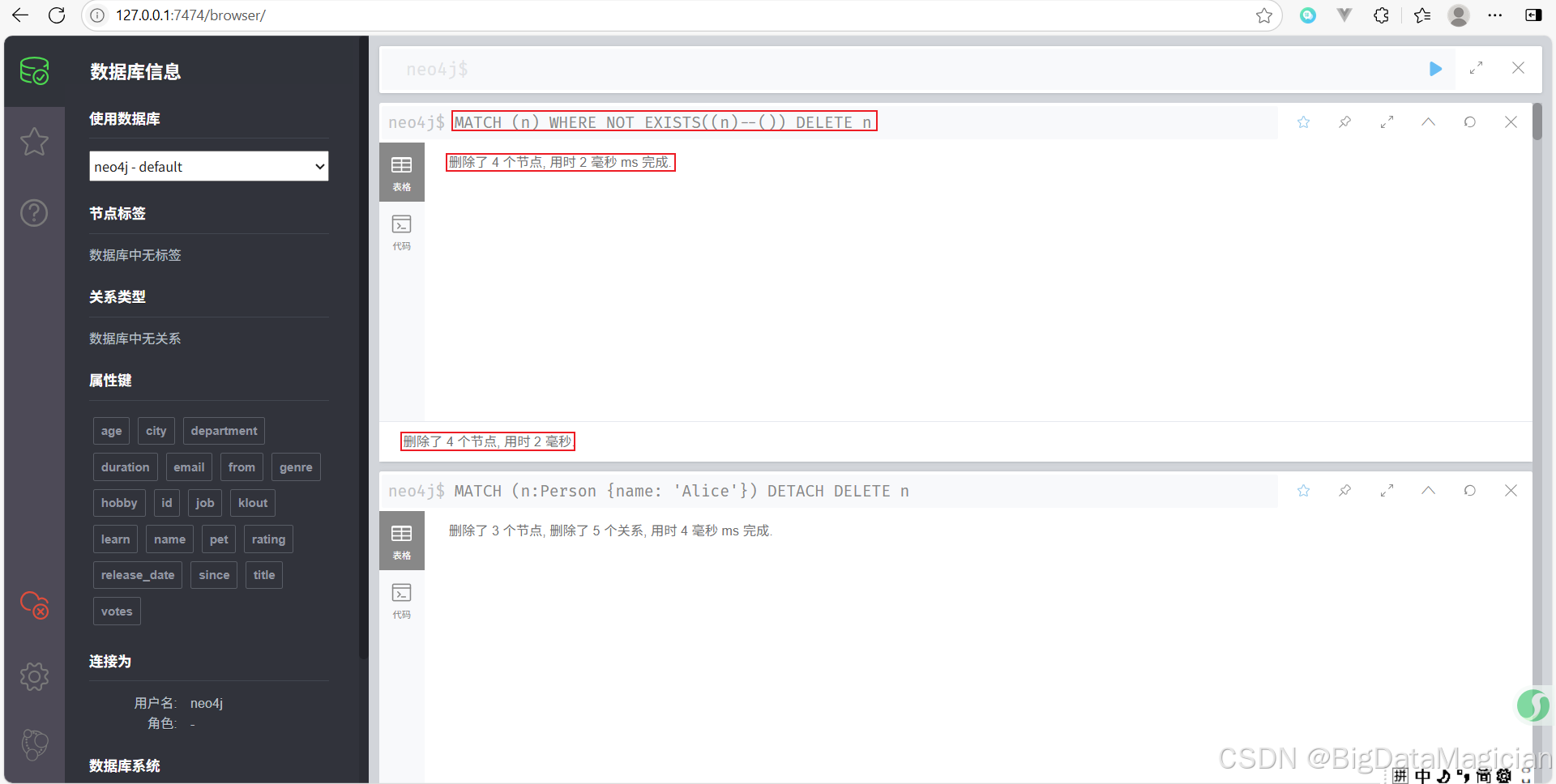
示例 4:删除没有关系的孤立节点
删除“孤立”的节点(即没有关系连接的节点)。
MATCH (n)
WHERE NOT EXISTS((n)--())
DELETE n
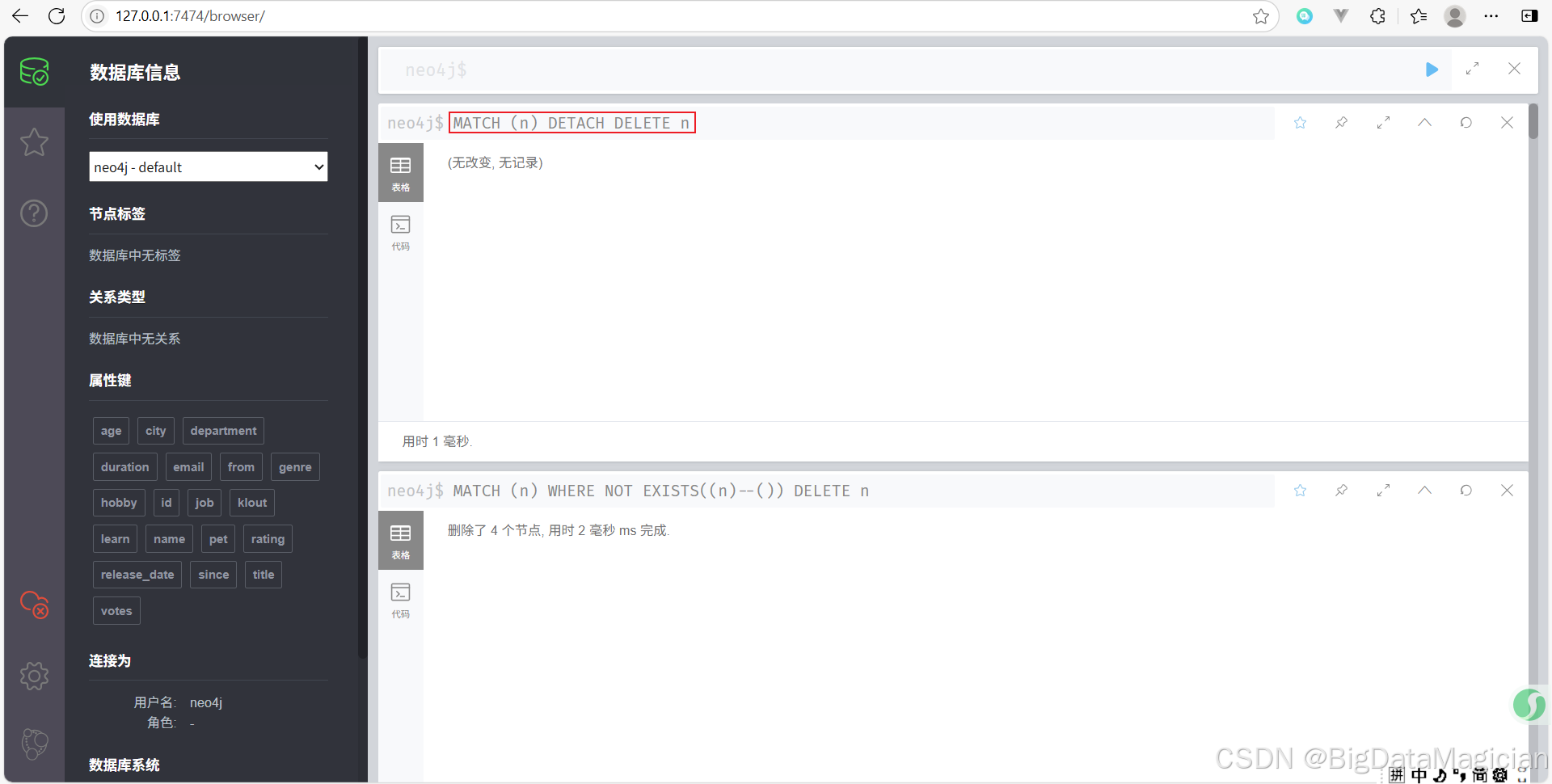
示例 5:删除所有节点和关系(清空整个图数据库)
删除数据库中所有的节点和它们的关系。
MATCH (n)
DETACH DELETE n
5. 合并数据
合并数据用于创建或更新节点或关系,不存在则创建,存在则更新。为了避免数据重复插入,可以使用
MERGE替代CREATE。
在 Neo4j 中,MERGE 是一个非常强大的命令,它用于确保某个图模式存在。如果该模式不存在,则会创建它;如果已经存在,则不会执行任何操作(也可以选择更新某些属性)。这非常适合用来避免重复插入相同的数据。
5.1 语法
基本语法如下:
MERGE (n:Label {uniqueProperty: value})
SET n.otherProperty = otherValue
RETURN n
MERGE:尝试匹配指定的模式(节点或关系)。- 如果没有找到匹配项,则创建新的节点或关系。
- 可以结合
ON CREATE SET和ON MATCH SET来分别设置创建时和匹配到时的操作。
使用 ON CREATE 和 ON MATCH 的完整语法:
MERGE (n:Label {uniqueProperty: value})
ON CREATE SET n.created = timestamp()
ON MATCH SET n.lastAccessed = timestamp()
RETURN n
ON CREATE SET:仅当节点是新创建的时候才执行。ON MATCH SET:仅当节点已存在时才执行。
5.2 示例
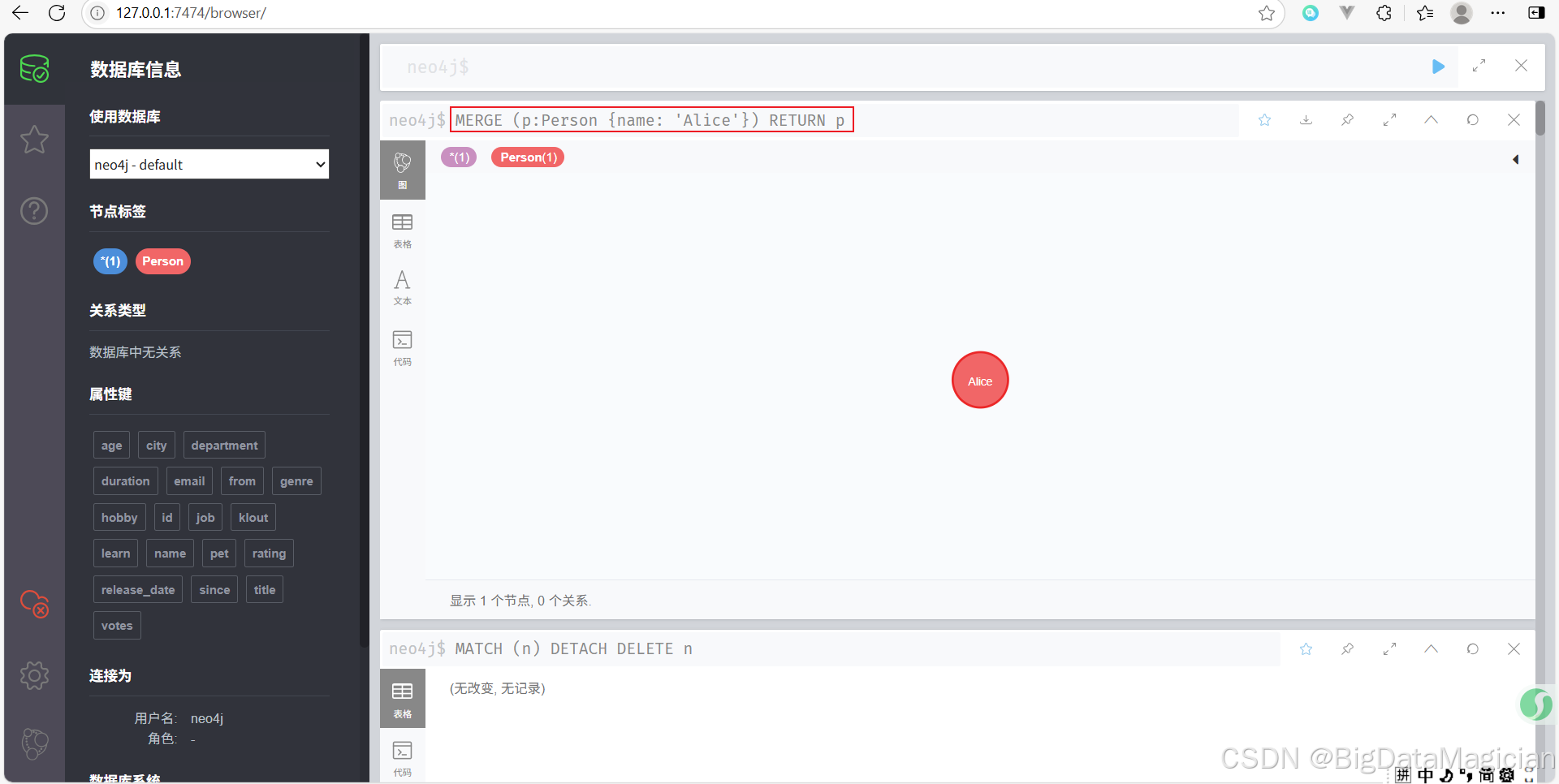
示例 1:确保某节点存在(若不存在则创建)
MERGE (p:Person {name: 'Alice'})
RETURN p
如果数据库中没有名为 Alice 的 Person 节点,则创建一个;如果有,则返回已存在的节点。
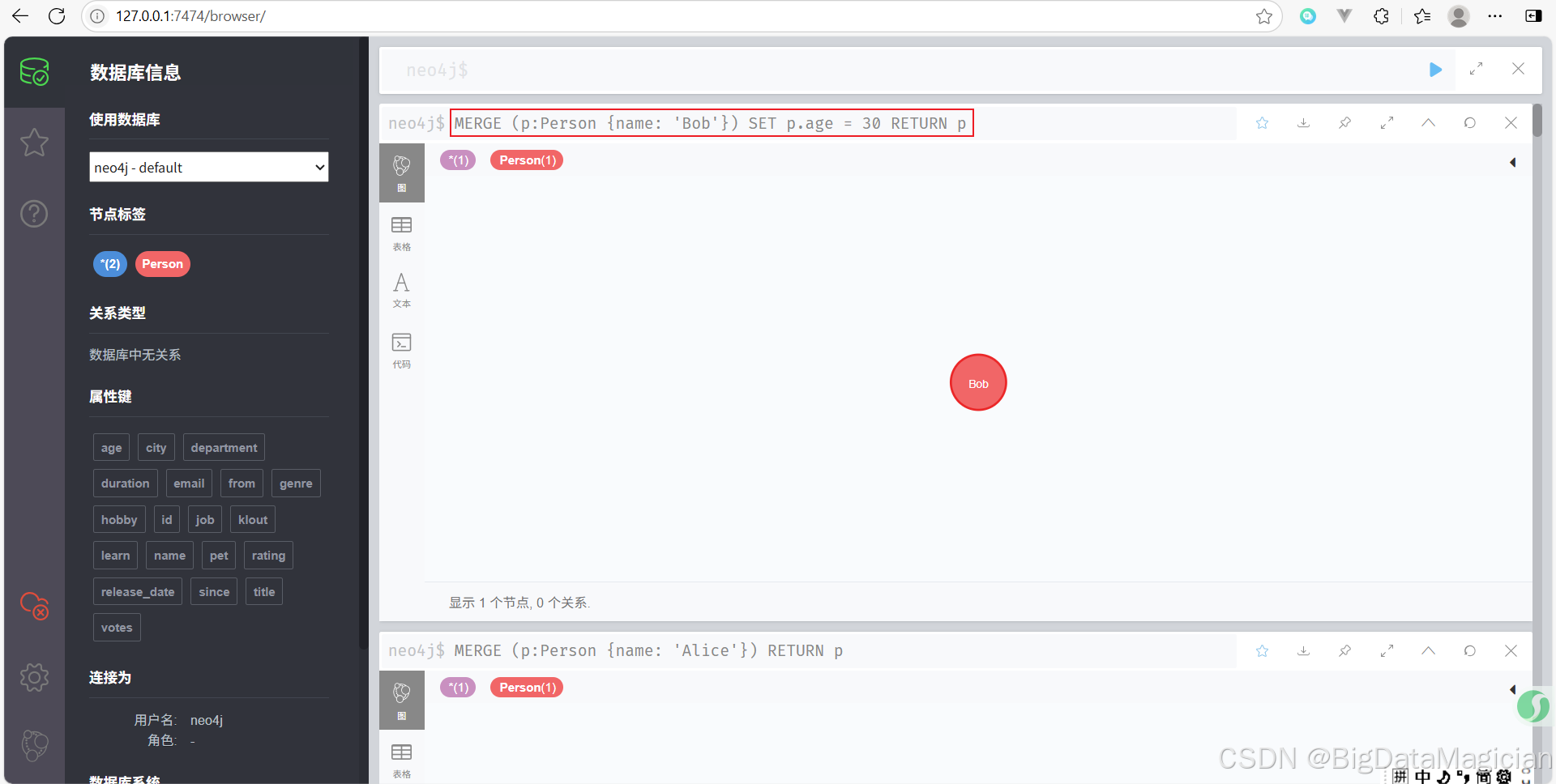
示例 2:确保节点存在,并设置额外属性
MERGE (p:Person {name: 'Bob'})
SET p.age = 30
RETURN p
确保 Bob 存在,并将他的年龄设为 30。如果 Bob 已经存在,则覆盖其 age 属性。
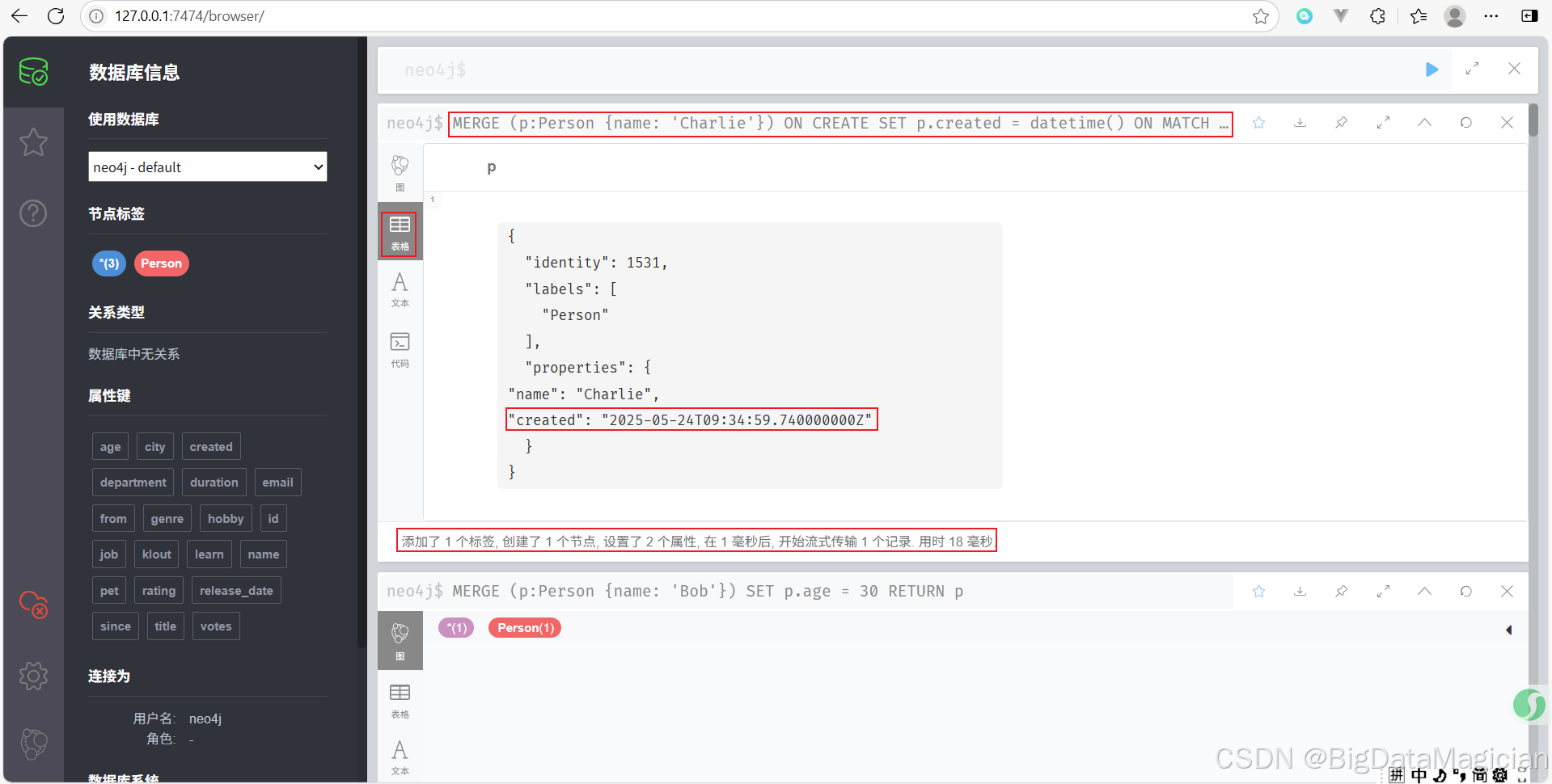
示例 3:使用 ON CREATE 和 ON MATCH 区分创建与更新操作
MERGE (p:Person {name: 'Charlie'})
ON CREATE SET p.created = datetime()
ON MATCH SET p.lastSeen = datetime()
RETURN p
- 如果 Charlie 是第一次出现,则设置
created时间;- 如果已存在,则更新
lastSeen时间。
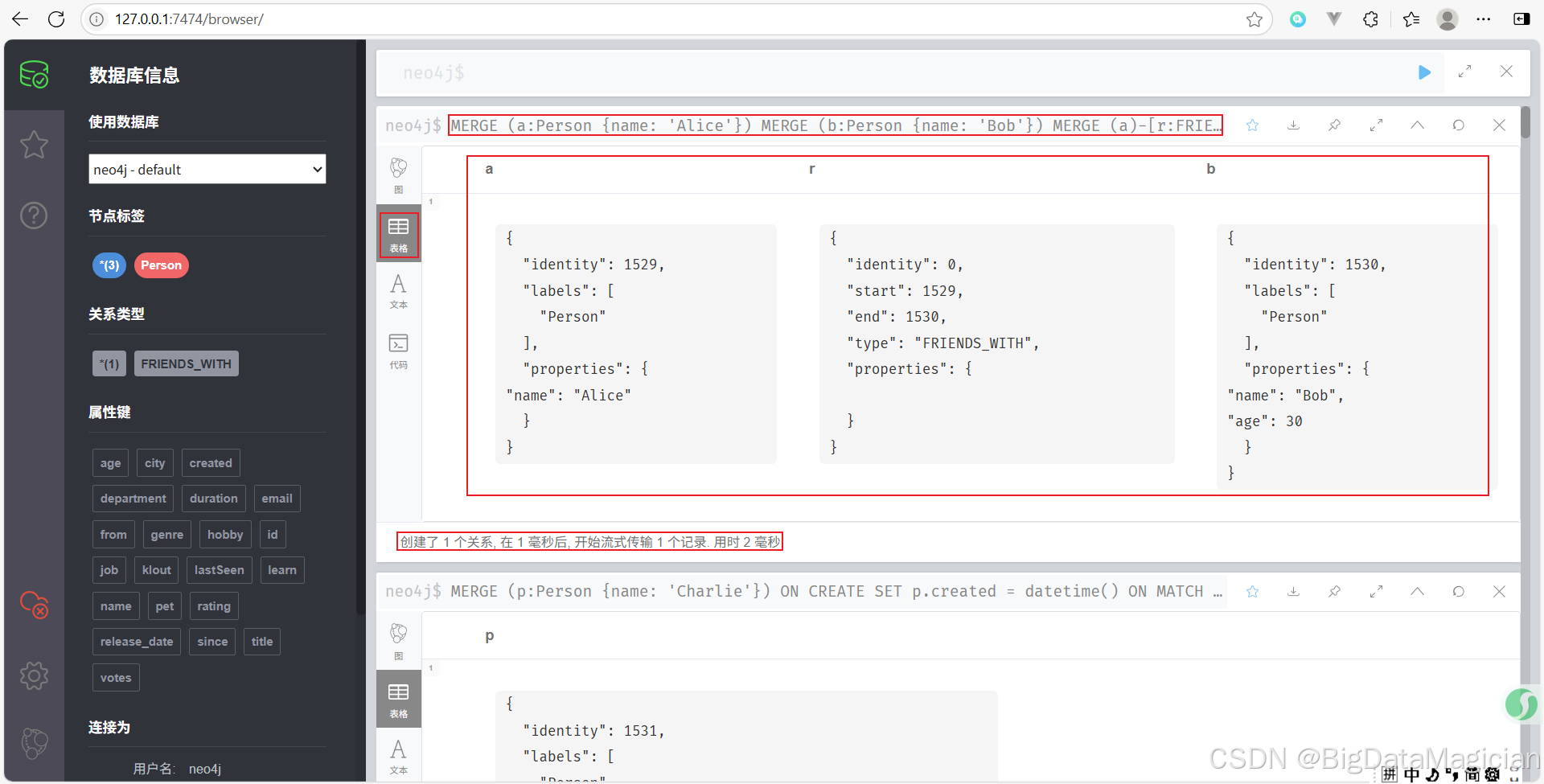
示例 4:合并关系(确保两个节点之间有某种关系)
MERGE (a:Person {name: 'Alice'})
MERGE (b:Person {name: 'Bob'})
MERGE (a)-[r:FRIENDS_WITH]->(b)
RETURN a, r, b
确保 Alice 和 Bob 存在,并且他们之间有一条 FRIENDS_WITH 关系。如果已经存在这条关系,则不重复创建。
示例 5:合并带属性的关系
MERGE (a:Person {name: 'Alice'})
MERGE (b:Person {name: 'Bob'})
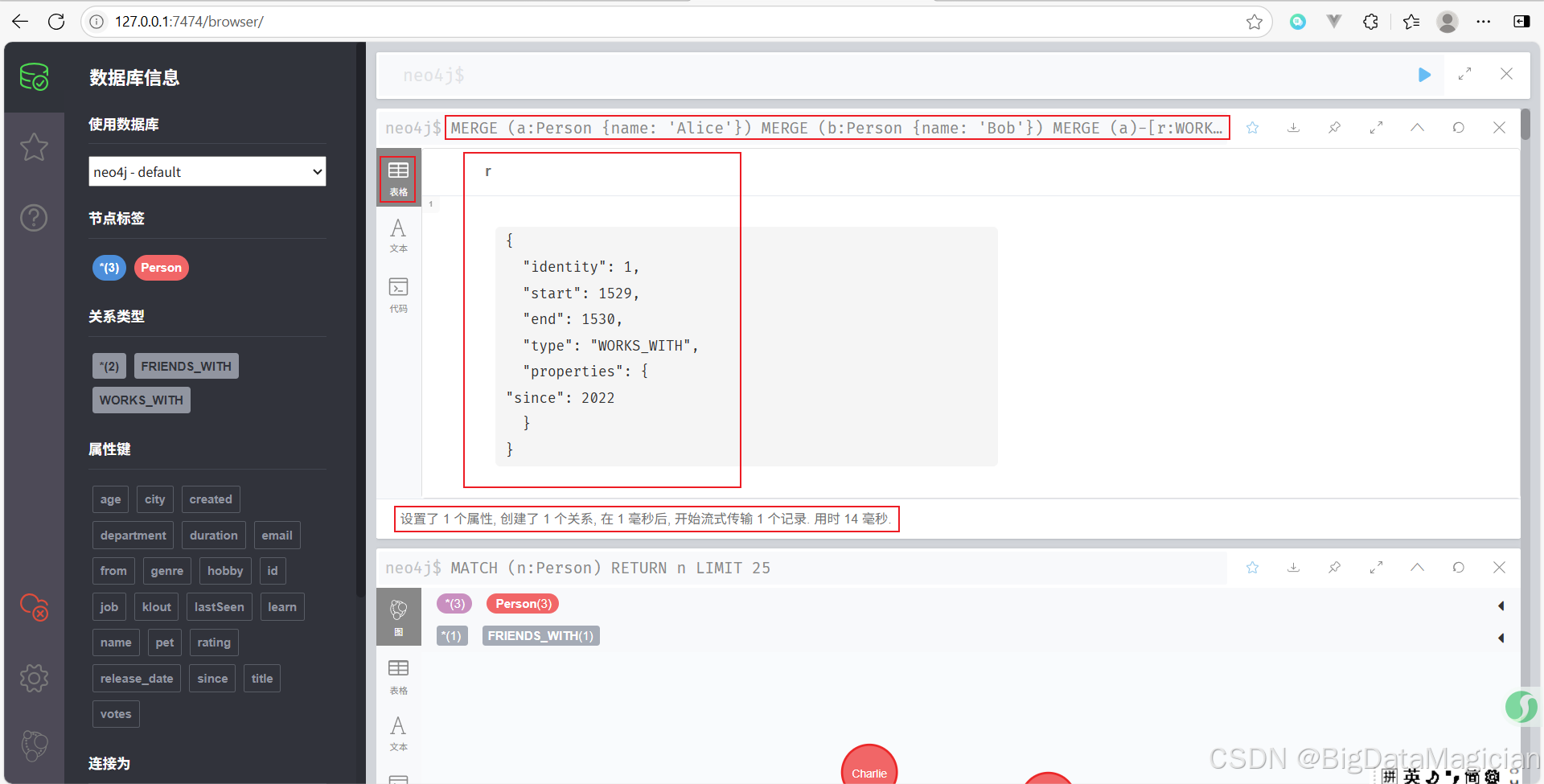
MERGE (a)-[r:WORKS_WITH {since: 2022}]->(b)
RETURN r
确保 Alice 和 Bob 之间有一条 WORKS_WITH 类型的关系,并带有属性
since: 2022。