参考文章:
Autodl服务器中Faster-rcnn(jwyang)复现(一)_autodl faster rcnn-CSDN博客
Autodl服务器中Faster-rcnn(jwyang)训练自己数据集(二)_faster rcnn autodl-CSDN博客
食用指南:先跟着参考文章一进行操作,遇到问题再来看我这里有没有解决办法,没有的话找AI。如果文章一哪里看不懂就去看文章二,然后遇到问题再来看我写的这篇。
环境配置
我到下载torch这一步老是即将结束的时候自动结束进程,所以还是自己下载安装吧。

如果出现上面的错误说明你没有加显卡,加上显卡就能运行成功了。
如果在安装相关库过程中发生报错,请先升级pip:
pip install --upgrade pip
数据集准备
我的数据集是之前训练yolo的,是我自己混合的Pascalvoc数据集。
查阅了资料说只需要将xml划分就行,我这里主要是8:2划分为训练集和验证集。
import os
import random
from typing import List, Tupledef split_dataset(xml_dir: str, output_dir: str, train_percent: float = 0.8) -> None:
"""
将VOC格式数据集的XML标注文件划分为训练集和验证集
参数:
xml_dir: XML标注文件所在目录
output_dir: 输出txt文件的目录
train_percent: 训练集占总样本的比例
"""
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
# 获取所有XML文件
try:
total_xml = os.listdir(xml_dir)
except FileNotFoundError:
print(f"错误: XML目录 '{xml_dir}' 不存在")
return
if not total_xml:
print(f"错误: XML目录 '{xml_dir}' 为空")
return
# 计算划分点
num = len(total_xml)
print(f"找到 {num} 个XML标注文件")
indices = list(range(num))
random.shuffle(indices) # 随机打乱索引
train_size = int(num * train_percent) # 训练集数量
train_indices = indices[:train_size] # 训练集索引
val_indices = indices[train_size:] # 验证集索引
# 输出划分结果
print(f"数据集划分结果: 训练集 {len(train_indices)}, 验证集 {len(val_indices)}")
# 创建输出文件并写入数据
file_paths = {
'train': os.path.join(output_dir, 'train.txt'),
'val': os.path.join(output_dir, 'val.txt'),
}
# 写入训练集
with open(file_paths['train'], 'w') as f_train:
for i in train_indices:
name = total_xml[i][:-4] + '\n'
f_train.write(name)
# 写入验证集
with open(file_paths['val'], 'w') as f_val:
for i in val_indices:
name = total_xml[i][:-4] + '\n'
f_val.write(name)
print(f"划分完成!训练集和验证集已保存到 {output_dir}")if __name__ == "__main__":
# 配置参数
xml_dir = '/root/faster-rcnn.pytorch-pytorch-1.0/data/xmls'
output_dir = '/root/faster-rcnn.pytorch-pytorch-1.0/data'
# 执行划分 (80% 训练集, 20% 验证集)
split_dataset(xml_dir, output_dir, train_percent=0.8)
代码修改
我主要涉及到五类,先修改如下:

背景不需要更改,只需要更改后面的类别。
跟着博主的描述操作,安装成功!

训练产生的报错以及解决:
发生报错:环境配置问题找 deepseek,涉及代码找豆包。(我最喜欢的搭配)
- 没有安装torchversion
得按照博主的那个指令来才能顺带下载torchvision,
- 找不到数据集路径
因为我数据集格式和博主不一样,最后让ai帮助我修改了pascalvoc.py就没有显示这个错误了。
- 没有预训练模型
本地下载预训练模型(resnet/densenet/vgg等url地址)_resnet预训练模型下载-CSDN博客
下载后要更改模型名称为
vgg16_caffe.pth-
训练指令
运行下面的指令:(这个指令运行后它使用的是trainval.txt文件,如果你的是train得修改名称,不然会报错)
CUDA_VISIBLE_DEVICES=0 python trainval_net.py --dataset pascal_voc --net vgg16 --bs 4 --nw 0 --lr 0.002 --cuda

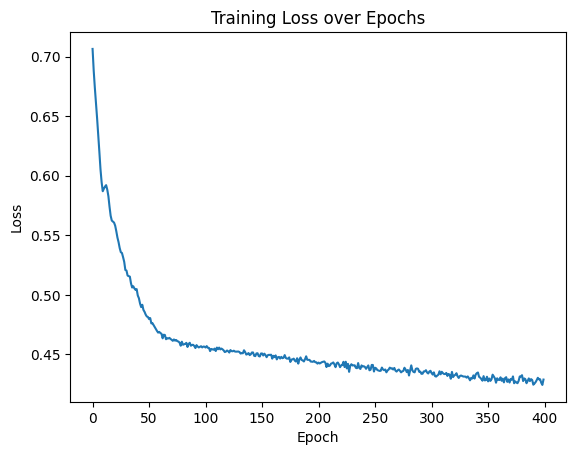
像这样应该就是成功了,可以在文件中修改epoch。
需要各类别的精度以及总体精度的时候执行下面这条命令(需要根据产生的文件名进行修改):
chekepoch代表你要检测哪个文件
checkpoint应该每个人的都不一样,需要进行修改。
python test_net.py --dataset pascal_voc --net vgg16 --checksession 1 --checkepoch 3 --checkpoint 1228 --cudaPS:每一个epoch产生的pth文件非常占存储空间,建议更改存储路径。
现在正在探索如何执行训练后生成的.pth文件输出四个精度指标,如果探索出来将会发布在第二篇。
更新:
精度指标输出代码已经放在第二篇。
Autodl训练Faster-RCNN网络--自己的数据集(二)-CSDN博客