第四章 ARM伪指令及编程基础
4.1 伪指令概述
4.1.1 伪指令定义
- 人们设计了一些专门用于指导汇编器进行汇编工作的指令,由于这些指令不形成机器码指令,它们只是在汇编器进行汇编工作的过程中起作用,所以被叫做伪指令。
4.1.2 伪指令特征
- 伪指令是一条指令
- 伪指令没有指令代码。
4.1.3 伪指令作用
- 程序定位的作用
- 为非指令代码进行定义
- 为程序完整性做标注
- 有条件的引导程序段
4.2 通用伪指令
- 在 ARM 汇编程序语言中,有如下几种伪指令:
- 符号定义(Symbol Definition)伪指令
- 数据定义(Data Definition)伪指令
- 汇编控制(Assembly Control)伪指令
- 其它(Miscellaneous)伪指令
4.2.1 为变量定义或赋值的伪指令
- 符号的命名由编程者决定,但必须遵循以下约定:
- 符号区分大小写,同名的大、小写符号会被编译器认为是两个不同的符号
- 符号在其作用范围内必须唯一
- 自定义的符号不能与系统保留字相同
- 符号不应与指令或伪指令同名
一、声明全局变量伪指令GBLA、GBLL和GBLS
- GBLA、GBLL 和 GBLS 伪指令用于定义一个ARM 程序中的全局变量,并将其初始化。
- 指令格式:
GBLA(GBLL和GBLS) <variable>;variable 为变量名称 - 全局变量的变量名在整个程序范围内必须具有唯一性
- 指令格式:
- GBLA 定义一个 全局数字变量,其默认初值为 0
- GBLL 定义一个 全局逻辑变量,其默认初值为 FALSE(假)
- GBLS 定义一个 全局字符串变量,其默认初值为 空 ;
二、声明局部变量伪指令LCLA、LCLL和LCLS
- LCLA、LCLL和LCLS伪指令用于定义一个ARM程序中的局部变量,并将其初始化。
- 格式:
LCLA(LCLL和LCLS) <variable>;variable 为变量名称 - 局部变量 的变量名在变量作用范围内必须具有唯一性
- 在默认情况下,局部变量只在定义该变量的程序段内有效
- 格式:
- LCLA 定义一个 局部数字变量,其默认初值为 0
- LCLL 定义一个 局部逻辑变量,其默认初值为 FALSE(假)
- LCLS 定义一个 局部字符串变量,其默认初值为 空
三、变量赋值伪指令 SETA、SETL和SETS
-
伪指令SETA、SETL和SETS 用于给一个已经定义的全局变量或局部变量进行赋值。 注:要顶格写
- 指令格式:
变量名 SETA(SETL或SETS) 表达式
- 指令格式:
-
SETA伪指令用于给一个数字变量赋值
-
SETL伪指令用于给一个逻辑变量赋值
-
SETS伪指令用于给一个字符串变量赋值
-
示例
- Test1 SETA 0xAA ;将Test1变量赋值为0xAA
- Test2 SETL {TRUE} ;将Test2 变量赋值为真
- Test3 SETS “Testing” ;将Test3变量赋值为“Testing”
四、定义寄存器列表伪指令
- 指令 LDM/STM 需要使用一个比较长的寄存器列表,使用伪指令 RLIST 可对一个列表定义一个统一的名称。
- 格式:
<name> RLIST <{list}>
- 格式:
- 例如:
- LoReg RLIST {R0-R7} ;定义寄存器列表{R0-R7}的名称为LoReg
- STMFD SP!, LoReg ;堆栈操作使用寄存器列表
- RegList RLIST {R0-R5,R8,R10} ;将寄存器列表名称定义为RegList,可在ARM指令LDM/STM中,通过该名称访问寄存器列表
4.2.2 数据定义伪指令
-
LTORG
-
用于声明一个数据缓冲池(文字池)的开始。
- 语法格式:
LTORG
- 语法格式:
-
伪指令 LTORG 用来说明某个存储区域为一个用来暂存数据的数据缓冲区,也叫文字池或数据缓冲池。
- 指令位置:
- 通常把数据缓冲池放在代码段的最后面,或放在无条件转移指令或子程序返回指令之后,这样处理器就不会错误地将数据缓冲池中的数据当作指令来执行
- 指令位置:
-
大的代码段也可以使用多个数据缓冲池。
-
示例:
AREA example, CODE, READONLY Start BL Func1 … Func1 LDR R1,=0x800 MOV PC,LR LTORG ;定义数据缓冲池的开始位置, ;系统会自动设置数据缓冲池的大小 … END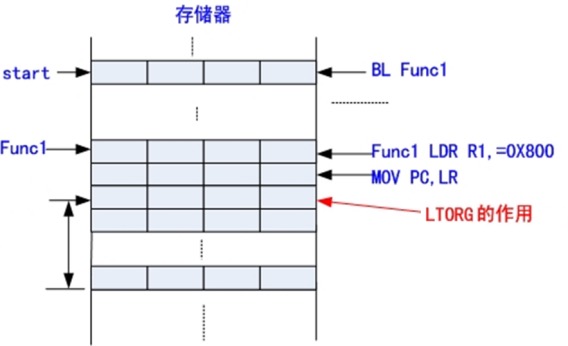
-
指令作用
- 防止在程序中使用LDR之类的指令访问时,可能产生的越界
-
-
MAP和FIELD
-
在应用程序中经常使用一种如下图所示的表:
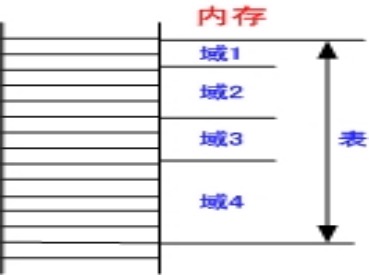
-
MAP 用于定义一个结构化的内存表的首地址。MAP 可以用 “^” 代替。
- 语法格式:
MAP <expr> {,<base_register>} - expr是数字表达式或程序中的标号。当指令中没有base_register时,expr即为结构化内存表的首地址,可以为标号或数字表达式
- base_register为基址寄存器(可选项)。当指令中包含这一项时,结构化内存表的首地址为expr与base_register寄存器值的和
- 示例:
- MAP fun ; fun就是内存表的首地址
- MAP 0x100,R9 ;内存表的首地址为R9+0X100
- 语法格式:
-
MAP 通常和 FIELD 伪指令相配合来定义一个结构化的内存表。
- FIELD 伪指令用于定义一个结构化内存表中的数据域
- 指令格式:
{label} FIELD expr - Label为域标号,要顶格写
- Expr表示本数据域在内存表中所占用的字节数
- 指令格式:
- 功能:FIELD用于定义一个结构化内存表中的数据域,“#”与FIELD同义
- FIELD 伪指令用于定义一个结构化内存表中的数据域
-
示例
- MAP 0X100 ;定义结构化内存表首地址为 0X100
- A FIELD 16 ;定义A的长度为16字节,位置为 0X100
- B FIELD 32 ;定义B的长度为32字节,位置为 0X110
- S FIELD 256 ;定义S的长度为256字节,位置为 0X130
-
注意:MAP 和 FIELD 伪指令仅用于定义数据结构,并不实际分配存储单元
-
-
SPACE
-
SPACE伪指令用于分配一片连续的存储区域并初始化为 0。
-
指令格式:
{label} SPACE expr -
label为内存块起始地址标号
-
Expr为所要分配的内存字节数;
-
SPACE 也可用 “%” 代替。
-
示例
AREA DataRAM,DATA,READWRITE ;声明一数据段,名为DataRAM DataSpace SPACE 100 ;分配连续的100字节的存储单元,并初始化为 0。
-
-
-
DCB
-
分配内存单元并初始化
- 指令格式:
{label} DCB expr{,expr }{,expr }… - label是存块起始地址标号;
- expr可以为0至255的数值或字符串,内存分配的字节数由expr个数决定;
- 指令格式:
-
功能:DCB用于分配一段字节内存单元,并用伪指令中的expr初始化,一般可用来定义数据表格,或文字符串,“=”与DCB同义。
-
示例
DISPTAB DCB 0x43,0x33,0x76,0x12 DCB 120,20,32,44 String DCB “send,data is error!”,0 ;构造字符串 # 使用示例 LDR R1, =DISPTAB ;把DISPTAB的地址值送入R1 LDRB R2, [R1,#2] ;获取地址为[R1+#2]字节单元的值 R2=0x76
-
-
DCD和DCDU分配存储单元并初始化
-
指令格式:
{label} DCD expr{,expr }{,expr }…{label} DCDU expr{,expr }{,expr }…- label是内存块起始地址标号
- expr为常数表达式或程序中标号,内存分配字节数由expr个数决定
-
功能:
- DCD用于分配一段字内存单元,并用伪指令中的expr初始化,字对齐,可定义数据表格或其它常数。“&”与DCD同义。
- DCDU用于分配一段字内存单元,并用伪指令中的expr初始化。DCDU伪指令分配的内存不需要字对齐,可定义数据表格或其它常数
-
示例
AREA blockcopy,CODE,READONLY …… LDR R1,=ftt LDR R2,=ftt2 LDR R3,[R1] ;R3=1 LDR R4,[R2] ;R4=3 LDR R5,[R1, #4] ;R5=2 LDR R6,[R2, #4] ;R6=4 …… Src DCD 1,2,3,4,5,6,7,8, MAP Src ftt FIELD 8 ftt2 FIELD 8 END- 因为FIELD 8所以,ftt在内存中占8个字节,所以ftt2指向3而不是1
- 该例说明了:MAP和FIELD伪指令不分配存储空间,只是给相关存储单元取个名称(标号)。便于程序以结构的方式访问对应的内存单元。
-
4.2.4 其他伪指令
-
定义对齐方式伪指令 ALIGN
-
指令格式:
ALIGN {表达式,{偏移量}} -
ALIGN是边界对齐伪指令,它可以通过添加填充字节的方式,使当前位置满足一定的对齐方式。其中表达式用于指定对齐方式在不同场合有不同的定义
-
对于在代码中单独使用的ALIGN伪指令,表达式的值,就是对齐方式的值,且该值必须是2的幂次方
-
示例
ALIGN 4 ;4字节字对齐,ALIGN后面不能有等号。 thumbcode ALIGN 4 CODE32 ARMCODEAREA OffsetExample, CODE ... ss1 DCB 1 ;假设ss1在0x01000字节 ALIGN 4,3 ;4字节对齐+3偏移量. ss2 DCB 1 ;使用“ALIGN 4,3”以后, ;当前位置会转到0x01003(0x01000+3)。 ;ss1和ss2之间会空2个字节。 ...
-
-
段定义伪指令AREA
-
AREA用于定义一个代码段或数据段。
-
指令格式:
AREA sectionname {,attr} {,attr}… -
sectionname是定义的代码段或数据段的名称。
- 若该名称是以数据开头的,则该名称必须用“|”括起来,如|2_datasec|。
- 还有一些代码段的名称是专有名称。
-
Attr表示代码或数据段的属性,多个属性用短号分隔,常用的属性如下:
属性 含义 备注 CODE 代码段 默认读/写属性为READONLY DATA 数据段 默认读/写属性为READWRITE NOINIT 数据段 指定此数据段仅仅保留了内存单元,而没有将各初始值写入内存单元。 READONLY 本段为只读 READWRITE 本段为可读可写 ALIGN表达式 ELF 的代码段和数据段为字对齐 COMMON 多源文件共享段
-
-
示例:
AREA Init, CODE,READONLY ………… ;程序段- 该伪指令定义了一个代码段,段名为 Init ,属性为只读。
- 一个汇编语言程序 至少 要有一个段。
-
-
CODE16和CODE32
-
CODE16告诉汇编编译器后面的指令序列为16位的Thumb指令。
-
CODE32告诉汇编编译器后面的指令序列为32位的ARM指令。
- 语法格式:
CODE16CODE32
- 语法格式:
-
注意:CODE16和CODE32只是告诉编译器后面指令的类型,该伪操作本身不进行程序状态的切换。
-
示例
AREA ChangeState, CODE, READONLY ENTRY CODE32 ;下面为32位ARM指令 LDR R0,=start+1 ;将跳转地址放入寄存器R0 BX R0 ;程序跳转到新的位置执行 …… ;并将处理器切换到Thumb工作状态 CODE16 ;下面为16位Thumb指令 start MOV R1,#10 ……. END
-
-
定义程序入口点伪指令 ENTRY
- 指定程序的入口点。
- 语法格式:
ENTRY
- 语法格式:
- 注意:一个程序(可包含多个源文件)中至少要有一个ENTRY(可以有多个ENTRY,当有多个ENTRY入口时,程序的真正入口点由链接器指定),但一个源文件中最多只能有一个ENTRY(可以没有ENTRY)
- 指定程序的入口点。
-
汇编结束伪指令 END
- END 伪指令用于通知编译器汇编工作到此结束,不再往下汇编了。
- 语法格式:
END
- 语法格式:
- 注意:每一个汇编源程序都必须包含END伪操作,以表明本源程序的结束
- END 伪指令用于通知编译器汇编工作到此结束,不再往下汇编了。
-
外部可引用符号声明伪指令 EXPORT(或GLOBAL)
-
声明一个源文件中的符号,使此符号可以被其他源文件引用。
- 语法格式:
EXPORT/GLOBAL symbol {[weak]} - symbol:声明的符号的名称。(区分大小写)
- [weak]:声明其他同名符号优先于本符号被引用
- 语法格式:
-
示例
AREA example,CODE,READONLY EXPORT DoAdd ;申明一个全局引用的标号DoAdd DoAdd ADD R0,R0,R1
-
-
IMPORT
- 当在一个源文件中需要使用另外一个源文件的外部可引用符号时,在被引用的符号前面,必须使用伪指令 IMPORT 对其进行声明:声明一个符号是在其他源文件中定义的。
- 如果源文件声明了一个引用符号,则无论当前源文件中程序是否真正地使用了该符号,该符号均会被加入到当前源文件的符号表中。
- 语法格式:
IMPORT symbol{[weak]} - symbol:声明的符号的名称
- [weak]:
- 当没有指定此项时,如果symbol在所有的源文件中都没有被定义,则连接器会报告错误。
- 当指定此项时,如果symbol在所有的源文件中都没有被定义,则连接器不会报告错误,而是进行下面的操作:
- 如果该符号被B或者BL指令引用,则该符号被设置成下一条指令的地址,该B或BL指令相当于一条NOP指令。
- 其他情况下此符号被设置成0
- 语法格式:
-
EXTERN
- EXTERN 伪指令与 IMPORT 伪指令的功能基本相同
- 不同点:如果当前源文件中的程序实际并未使用该符号,则该符号不会加入到当前源文件的符号表中。
- 其它与 IMPORT 相同
-
等效伪指令 EQU
-
EQU 伪指令用于为程序中的常量、标号等定义一个等效的字符名字,其作用类似于C语言中的 #define。
- 语法格式:
name EQU expr{,type} - name:为expr定义的字符名称
- expr:基于寄存器的地址值、程序中的标号、32位的地址常量或者32位的常量。表达式,为常量。
- type:当expr为32位常量时,可以使用type指示expr的数据的类型。取值为:
- CODE32
- CODE16
- DATA
- 语法格式:
-
示例:
abcd EQU 2 ;定义abcd符号的值为2 abcd EQU label+16 ;定义abcd符号的值为(label+16) abcd EQU 0x1c, CODE32 ;定义abcd符号的值为绝对地址0x1c,而且此处为ARM指令
-
-
GET(或INCLUDE)
- GET 伪指令用于将一个源文件包含到当前的源文件中,并将被包含的源文件在当前位置进行汇编。
- 语法格式:
GET 文件名 - 可以使用 INCLUDE 代替 GET。
- 语法格式:
- GET 伪指令只能用于包含源文件,包含目标文件则需要使用 INCBIN 伪指令
- 源文件是指 可被汇编器直接处理的文本文件,通常是:
- 汇编代码文件(
.s、.asm) - 宏定义文件(
.inc、.h) - 其他可被汇编器解析的文本文件。
- 汇编代码文件(
- 目标文件是指 已编译的二进制文件,通常是:
- 机器码文件(
.o、.obj) - 二进制数据文件(
.bin、.dat) - 其他非文本格式的原始数据文件。
- 机器码文件(
- 源文件是指 可被汇编器直接处理的文本文件,通常是:
4.3 与ARM指令相关的宏指令
-
MACRO 和 MEND
-
MACRO 和 MEND 伪指令可以为一个程序段定义一个名称。
-
在汇编语言应用程序中,可以通过这个名称来使用它所代表的程序段,即当程序做汇编时,该名称将被替换为其所代表的程序段。
-
语法格式:
MACRO $标号 宏名 $参数1, $参数2,….. 程序段(宏定义体) MEND$标号:为主标号,宏内的所有其它标号必须由主标号组成- 宏名:宏名称,为宏在程序中的引用名;
$参数1,$参数2:宏中可以使用的参数。- 宏中的所有标号必须在前面冠以符号“$”。
- MACRO、 MEND伪指令可以嵌套使用。
-
示例:
MACRO ;宏定义指令 $MDATA MAXNUM $NUM1,$NUM2 ;主标号,宏名,参数 语句段 $MDATA.WAY1 ; 宏内标号,必须写为“主标号.宏内标号” 语句段 $MDATA.WAY2 ; 宏内标号 语句段 MEND ; 宏结束指令 主程序中调用该宏: Lab1 MAXNUM 0x01, 0x02
-
-
MEXIT
- MEXIT 用于从宏定义中跳转出去。
- 语法格式:MEXIT
4.3.2 宏指令
- 在ARM中,还有一种汇编器内置的无参数和标号的宏——宏指令。
- 在汇编时,这些宏指令被替换成一条或两条真正的ARM或 Thumb 指令。
- ARM宏指令有四条,分别是:
- ADR:小范围的地址读取宏指令;
- ADRL:中等范围的地址读取宏指令;
- LDR:大范围的地址读取宏指令;
- NOP:空操作宏指令。
一、ADR
-
小范围的地址读取宏指令
-
ADR 指令用于将一个近地址值传递到一个寄存器中。
- 指令格式:
ADR{cond} <reg>, <expr> - reg 为目标寄存器名称;
- expr 为表达式。该表达式通常是程序中一个表示存储位置的地址标号。
- 指令格式:
-
该宏指令的功能是把标号所表示的地址传递到目标寄存器中。
-
汇编器在汇编时,将把ADR宏指令替换成一条真正的ADD或SUB指令,以当前的PC值减去或加上expr与PC之间的偏移量得到标号的地址,并将其传递到目标寄存器。若不能用一条指令实现,则产生错误,编译失败。
-
示例:
start MOV R0,#10 ADR R4,start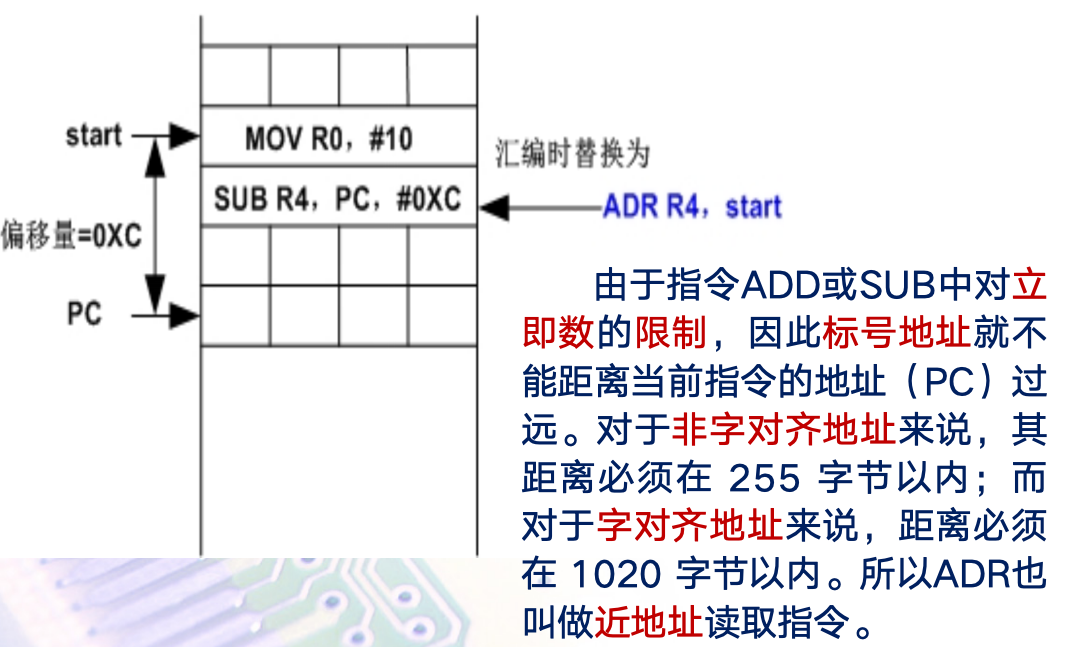
二、ADRL
-
中等范围的地址读取宏指令
-
类似于ADR,但可以把更远的地址赋给目标寄存器。
- 指令格式:
ADRL{cond} <reg>, <expr> - reg 为目标寄存器名称
- Expr 为表达式,必须是64KB以内非字对齐地址,或256KB以内的字对齐地址
- 指令格式:
-
该指令只能在ARM状态下使用,在Thumb状态下不能使用。
-
汇编时,ADRL宏指令由汇编器替换成两条合适的指令;如果汇编器找不到合适的两条指令,将会报错
-
示例:
- start MOV R0,#10
- ADRL R4,start + 60000
- 此时,start为PC-12,则start+60000=PC+59988(0XEA54)
- 其中 ADRL 将被替换为如下两条指令:
- ADD R4,PC,#0XE800
- ADD R4,R4,#0X254
三、LDR
-
大范围的地址读取宏指令
-
指令格式:
LDR{cond} reg,={expr | label - expr}- reg:目标寄存器名称;
- expr:32位常数;
- label – expr:为地址表达式。
-
程序经常用这条指令把一个地址传递到寄存器reg中。
-
汇编器在对这种指令进行汇编时,会根据指令中expr的值的大小来把这条指令替换为合适的指令。
-
与ARM指令的LDR的区别:伪指令LDR的参数有“=”号
-
注意:
- 当 expr 的值未超过 MOV 或 MVN 指令所限定的取值范围时,汇编器用 ARM 的 MOV 或 MVN 指令来取代宏指令 LDR;
- 当 expr 的值超过 MOV 或 MVN 指令所限定的取值范围时,汇编器将常数 expr 放在由 LTORG 定义的文字缓冲池,同时用一条 ARM 的装载指令 LDR 来取代宏指令 LDR ,而这条装载 LDR 指令则用 PC 加偏移量 的方法到文字缓冲池中把该常数读取到指令指定的寄存器。
- 由于这种指令可以传递一个 32 位地址,因此也被叫做全范围地址读取指令
-
示例:

四、NOP
-
空操作
-
汇编器对NOP指令进行汇编时,会将其转换为:MOV R0,R0
-
指令格式:NOP
-
示例
例:延时子程序 Delay NOP ;空操作 NOP SUBS R1,R1,#1 ;循环次数减1 BNE Delay MOV PC,LR
补充:ARM程序设计要点
AREA example,CODE,READONLY ;定义代码段,一个ARM汇编程序至少有一个代码段
ENTRY ;定义程序入口点
……
……
END ;汇编语言程序结束
4.4 汇编语言编程规范
4.4.1 汇编语言的语句格式
- ARM(Thumb)汇编语言的语句格式为:
{<标号>} <指令或伪指令> {;注释}
- 在汇编语言程序设计中,每一条指令的助记符可以全部用大写或全部用小写 ,但不允许在一条指令中大小写混用 。标号要顶格。
- 如果一条语句太长,则可将该长语句分成若干行来书写,每行的末尾用“\”来表示下一行与本行为同一条语句。但是注意:在**”\”之后不能再有其他字符,包括空格和制表符**
4.4.2 汇编语言程序中常用的符号
-
在ARM汇编语言中,符号可以代表地址、变量和数字常量。
-
符号命名规则如下:
-
符号由大小写字母、数字以及下划线组成;
-
除局部标号以数字开头,其他的符号都不能以数字开头;
-
符号是区分大小写的;
-
符号在其作用范围内必须唯一;
-
程序中的符号不能与指令助记符、伪指令、宏指令同名。
-
-
这些规则主要涉及程序中的变量和常量
4.4.3 汇编语言的表达式和运算符
一、运算次序优先级:
- 优先级相同的双目运算符运算顺序为从左到右;
- 相邻的单目运算符的运算顺序为从右到左,且单目运算符的优先级高于其他运算符;
- 括号运算符的优先级最高
二、数字表达式及运算符
- +、-、*、/及MOD算术运算符
- X + Y 表示 X 与 Y 的和
- X - Y 表示X与Y的差
- X * Y 表示X与Y的乘积
- X / Y 表示X除以Y的商
- X :MOD: Y 表示X除以Y的余数
- ROL、ROR、SHL及SHR移位运算符
- X :ROL: Y 表示将X循环左移Y位
- X :ROR: Y 表示将X循环右移Y位
- X :SHL: Y 表示将X左移Y位
- X :SHR: Y 表示将X右移Y位
- AND、OR、NOT及EOR按位逻辑运算符
- X :AND: Y 表示将X和Y按位做逻辑“与”的操作
- X :OR: Y 表示将X和Y按位做逻辑“或”的操作
- :NOT: Y 表示将Y按位做逻辑“非”的操作
- X :EOR: Y 表示将X和Y按位做逻辑“异或”的操作
三、逻辑表达式及运算符
- =、>、<、>=、<=、/=、<>运算符
- X = Y 表示X等于Y
- X > Y 表示X大于Y
- X < Y 表示X小于Y
- X >= Y 表示X大于或等于Y
- X <= Y 表示X小于或等于Y
- X /= Y 表示X不等于Y
- X <> Y 表示X不等于Y
- LAND、LOR、LNOT及LEOR运算符
- X :LAND: Y 表示将X和Y做逻辑“与”的操作
- X :LOR: Y 表示将X和Y做逻辑“或”的操作
- :LNOT: Y 表示将Y做逻辑“非”的操作
- X :LEOR: Y 表示将X和Y做逻辑“异或”的操作
四、字符串表达式及运算符
- 编译器所支持的字符串最大长度为512 字节。
-
LEN 运算符
-
LEN 运算符返回字符串的长度(字符数),以 X 表示字符串表达式。
-
语法格式:
:LEN: X -
示例:
GBLS STR GBLA LEN STR SETS “AAA” LEN SETA :LEN:STR ;LEN=3
-
-
**CHR 运算符 **
- CHR 运算符将 0~255 之间的整数转换为一个字符,以 M 表示一个整数,
- 语法格式:
:CHR: M - 在内存单元中,其值还是没有变。只是经过这种处理后,可以把它当做一个字符,用于字符串处理函数中。
-
STR 运算符
-
STR 运算符将一个数字表达式或逻辑表达式转换为一个字符串。
- 对于数字表达式,STR 运算符将其转换为一个以十六进制组成的字符串
- 对于逻辑表达式,STR 运算符将其转换为 字符串"T"或"F" 。
-
语法格式:
:STR: X;X为数字表达式或逻辑表达式 -
示例
AREA blockcopy,CODE,READONLY CODE32 LDR R0,=TTQ LDR R1,TTQ LDR R4,[R0] TTQ DCB :STR: 0x12345678 END- 该程序执行后,R1的值为0x 34333231 (十六进制), 0x34是4对应的ASCII码,0x31是1对应的ASCII码。
- 因为ARM默认是小端模式–从低地址到高地址存储
- 所以先把字符’1’对应的ascii码放在R1的低字节中
- 因为寄存器只有32位,所以只给4个字节
- 该程序执行后,R1的值为0x 34333231 (十六进制), 0x34是4对应的ASCII码,0x31是1对应的ASCII码。
-
-
LEFT 运算符
-
LEFT 运算符返回某个字符串左端的一个 子集。
-
语法格式:
X :LEFT: Y- X 为源字符串,Y 为一个整数,表示要返回的字符个数
-
示例:
GBLS STR1 GBLS STR2 STR1 SETS “AAABBB” STR2 SETS STR1 :LEFT:3 ; 程序运行完后,STR2为"AAA"
-
-
RIGHT 运算符
-
RIGHT 运算符返回某个字符串右端的一个 子集。
-
语法格式:
X :RIGHT: Y- X 为源字符串,Y 为一个整数,表示要返回的字符个数
-
示例
GBLS STR1 GBLS STR2 STR1 SETS “AAABBB” STR2 SETS STR1 : RIGHT :3 ; 程序运行完后,STR2为”BBB”
-
-
CC 运算符
-
CC 运算符用于将两个字符串连接成一个字符串。
-
语法格式:
X :CC: Y- X为源字符串1,Y为源字符串2,CC运算符将Y连接到X的后面。
-
示例:
GBLS STR1;声明字符串变量STR1 GBLS STR2;声明字符串变量STR2 STR1 SETS “AAACCC”;变量STR1赋值为”AAACCC” STR2 SETS “BBB”:CC:(STR1:LEFT:3) ; 程序运行完后,STR2为”BBBAAA”
-
五、程序中的变量代换
-
程序中的变量可通过代换操作取得一个常量。代换操作符为
$。- 如果在数字变量前面有一个代换操作符
$,则编译器会将该数字变量的值转换为十六进制的字符串,并将该十六进制的字符串代换$后的数字变量。 - 如果在逻辑变量前面有一个代换操作符
$,则编译器会将该逻辑变量代换为它的取值(真或假)。 - 如果在字符串变量前面有一个代换操作符
$,则编译器会将该字符串变量的值代换$后的字符串变量。
- 如果在数字变量前面有一个代换操作符
-
示例:
GBLS s1 ; 定义局部字符串变量S1和S2 GBLS s2 s1 SETS “Test !” s2 SETS “This is a $s1” ; 字符串变量S2的值为“This is a Test !”GBLA Test1 GBLL Test2 GBLL Test3 Test1 SETA 0x66 Test2 SETL {TRUE} Test3 SETL {FALSE} StrMem DCB "12345$Test1$Test2$Test3" ;StrMem存放的内容为字符串:“1234500000066TF”对应的ASCII码- PPT中所有逻辑变量都转换成T或者F,但是gpt说转换成TRUE或者FALSE。。???
-
习题
AREA blockcopy,CODE,READONLY ENTRY LDR R1,=ftt LDR R2,=ftt2 LDR R3,[R1] LDR R4,[R2] LDR R5,[R1, #4] LDR R6,[R2, #4] Src DCD 1,2,3,4,5,6,7,8,1,2,3,4,5,6,7,8,1,2,3,4 StrMem DCB “ABCS”,0 MAP Src ftt FIELD 8 ftt2 FIELD 8 END ;该程序段执行后,R3=1 ,R4=3 ,R5=2 ,R6=4 。AREA blockcopy,CODE,READONLY ENTRY ARM LDR R0,=ss1 LDR R1,=ss2 LDR R4,[R0] ALIGN 4 ss1 DCB 1 ALIGN 4,3 ss2 DCB 3 END ;该段程序执行完成后,假如R0的值为0x10001000,则R1=0x ,R4=0x- 这题有问题!
GBLL llll GBLS Str1 GBLS Str2 GBLS Str3 GBLS Str4 Str1 SETS "AAAA" Str2 SETS "BCDEFG" llll SETL {False} Str3 SETS Str1 :CC:(Str2:LEFT:3):CC: :STR: llll Str4 SETS Str1 :CC:Str2:LEFT:3:CC: :STR: llll ;该段程段中Str3和Str4对应的字符串分别为: ;Str3对应的字符串为:AAAABCDF ; Str4对应的字符串为:AAAF
4.5 ARM工程
-
由于C语言便于理解,有大量的支持库,所以它是当前 ARM 程序设计所使用的主要编程语言。
-
对硬件系统的初始化、CPU状态设定、中断使能、主频设定以及RAM控制参数初始化等C程序力所不能及的底层操作,还是要由汇编语言程序来完成。
-
用汇编语言或C/C++语言编写的程序叫做源程序,对应的文件叫做源文件。
-
一个ARM工程应由多个文件组成,其中包括扩展名为** .S 的汇编语言源文件**、扩展名为** .C的C语言源文件**,扩展名为 .CPP的C++源文件、扩展名为**.H的头文件**等。
-
ARM工程的各种源文件之间的关系,以及最后形成可执行文件的过程如下:
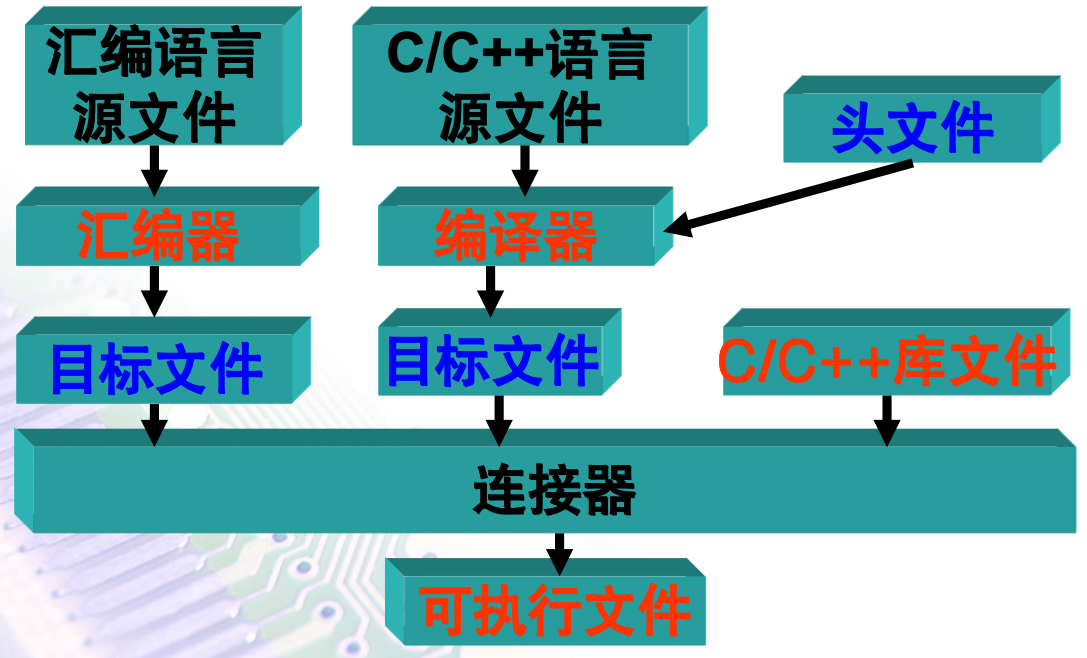
-
编译器
-
编译器负责生成目标文件,它是一种包含了调试信息的ELF格式文件。
- ELF(Executable and Linking Format):可执行连接格式。
- 可执行连接格式是UNIX系统实验室(USL)作为应用程序二进制接口(Application Binary Interface(ABI)而开发和发布的。
-
编译器还要生成列表文件等相关文件:
文件扩展名 说明 .h 头文件 .o ELF 格式的目标文件 .s 汇编代码文件 .lst 错误及警告信息列表文件
-
-
连接器
- 各种源文件先由编译器和汇编器将它们分别编译或汇编成汇编语言文件及目标文件。
- 连接器负责将所有目标文件连接成一个文件并确定各指令的确定地址,从而形成最终可执行文件。
- 连接器有三个功能:
- 根据程序员所指定的选项,为程序分配地址空间;
- 生成与地址相关的代码,把所有文件连接成一个可执行文件;
- 给出连接信息,以说明连接过程和连接结果
4.6 ARM程序框架
-
在应用系统的程序设计中,若所有的编程任务均用汇编语言来完成,其工作量是可想而知的,这样做也不利于系统升级或应用软件移植。
-
通常汇编语言部分完成系统硬件的初始化;高级语言部分完成用户的应用。
-
执行时,首先执行初始化部分,然后再跳转到 C/C++ 部分。整个程序结构显得清晰明了,容易理解。程序的基本结构如下:

4.6.1 初始化程序部分
-
由于在用于完成初始化任务的汇编语言程序中需要在特权模式下做一些诸如修改 CPSR 等特权操作,所以不能过早地进入用户模式。
-
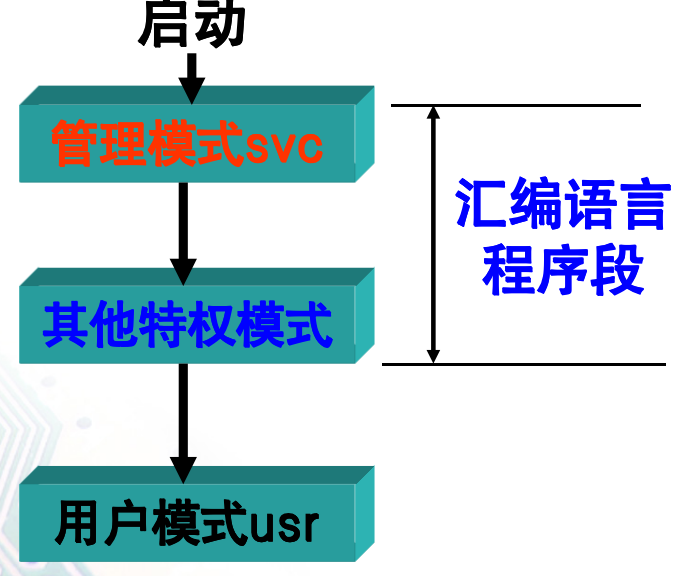
上电复位后进入SVC模式,除用户模式外,其它模式中能任意切换工作模式
-
通常,初始化过程大致会经历如下所示的一些模式变化
4.6.2 初始化部分与主应用程序部分的衔接
-
当所有的系统初始化工作完成之后,就需要把程序流程转入主应用程序。
-
最简单的方法是,在汇编语言程序末尾使用跳转指令 B 或 BL 直接从启动代码转移到 C/C++ 程序入口。
B main;跳转到C/C++程序- 同时在汇编文件中有如下代码:
IMPORT main
-
完整汇编语言程序大致如下:
IMPORT main AREA Init, CODE, READONLY ENTRY LDR SP, =0X3EE1000 B main END-
c语言程序如下
void main(void) { ….. }
-
4.6.3 ARM开发环境提供的程序框架
-
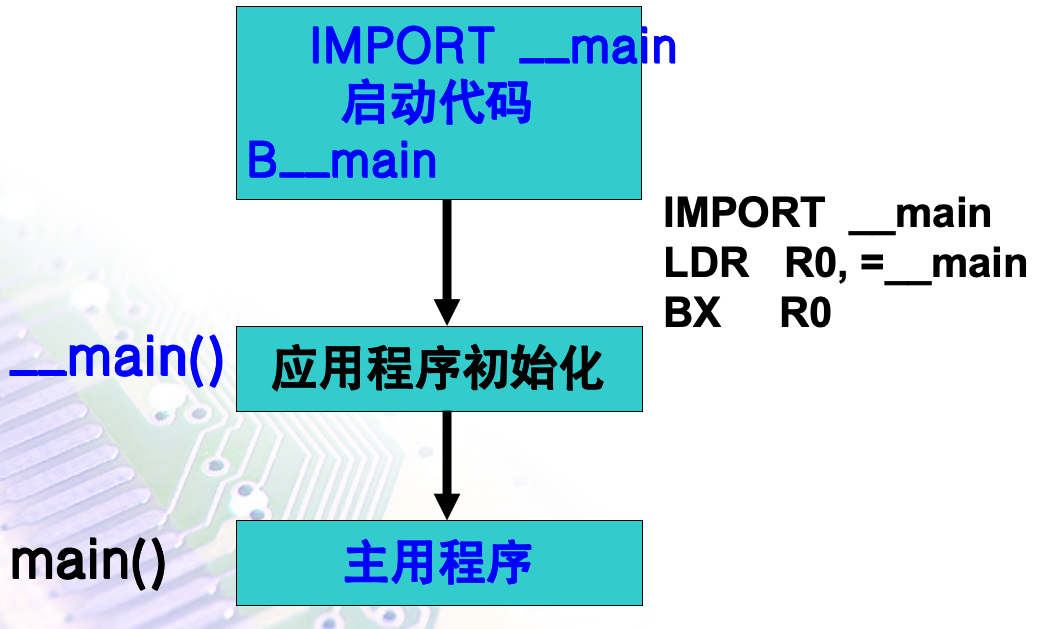
为方便工程开发,ARM 公司的开发环境ARM ADS 为用户提供了一个可以选用的应用程序框架。
-
该框架把为用户程序做准备工作的程序分成了: 启动代码和应用程序初始化两部分。
-
用于硬件初始化的汇编语言部分叫做启动代码;
-
用于应用程序初始化的C部分叫做初始化部分。
-
整个程序如下所示:
-
4.7 ARM汇编语言程序设计
4.7.1 段
- 汇编语言编写的程序叫做汇编语言源程序,包含源程序的文件叫做汇编语言程序文件。
- 一个工程可以有多个源文件,汇编源文件的扩展名为 .S。
- 在ARM(Thumb)汇编语言程序中,通常以段为单位来组织代码。
- 段是具有特定名称且功能相对独立的指令或数据序列。
- 根据段的内容,分为代码段和数据段。
- 一个汇编程序至少应该有一个代码段,当程序较长时,可以分割为多个代码段和数据段。
4.7.2 分支程序设计
具有两个或两个以上可选执行路径的程序叫做分支程序。
一、普通分支程序设计
-
使用带有条件码的指令可以很容易地实现分支程序。
-
示例:
-
编写一个分支程序段,如果寄存器 R5 中的数据等于 10,就把 R5 中的数据存入寄存器 R1;否则把 R5 中的数据分别存入寄存器 R0 和 R1。
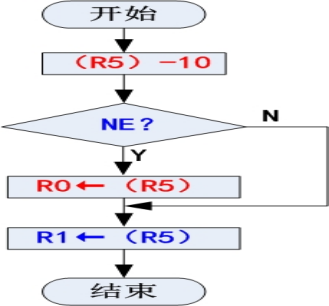
;用条件指令实现的分支程序段 CMP R5,#10 MOVNE R0,R5 MOV R1,R5 ;用条件转移指令来实现分支程序段 CMP R5,#10 BEQ doequal MOV R0,R5 doequal MOV R1,R5 -
编写一个程序段,当寄存器R1中的数据大于R2中数据时,将R2中的数据加10存入寄存器 R1;否则将R2中数据加 5 存入寄存器 R1
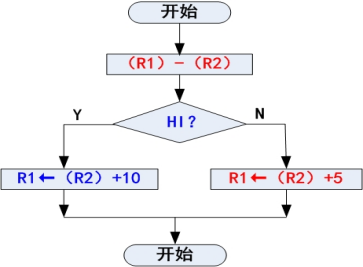
CMP R1,R2 ADDHI R1,R2,#10 ADDLS R1,R2,#5- HI:无符号数大于,LS:无符号数小于或等于;
- GT:带符号数大于,LE:带符号数小于或等于。
-
二、多分支(散转)程序设计
-
程序分支点上有多于两个以上的执行路径的程序叫做多分支程序。
-
利用条件测试指令或跳转表可以实现多分支程序。
-
示例:
-
编写一个程序段,判断寄存器R1中数据是否为10、15、12、22。如果是,则将R0中的数据加1;否则将R0设置为 0XF
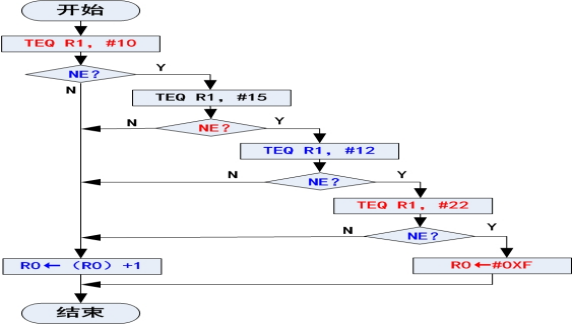
MOV R0,#0 TEQ R1,#10 TEQNE R1,#15 TEQNE R1,#12 TEQNE R1,#22 ADDEQ R0,R0,#1 MOVNE R0,#0XF
-
-
当多分支程序的每个分支所对应的是一个程序段时,常常把各个分支程序段的首地址依次存放在一个叫做跳转地址表的存储区域,然后在程序的分支点处使用一个可以将跳转表中的目标地址传送到PC的指令来实现分支
-
一个具有 3 个分支的跳转地址表示意图如下:
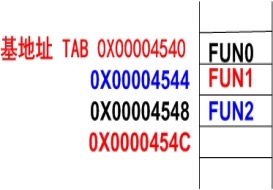
MOV R0,N ;N为表项序号0~2 ADR R5,JPTAB LDR PC,[R5,R0,LSL #2] JPTAB ;跳转表 DCD FUN0 DCD FUN1 DCD FUN2 FUN0 ….. ;分支FUN0的程序段 FUN1 ….. ;分支FUN1的程序段 FUN2 ….. ;分支FUN2的程序段
-
三、带ARM/Thumb状态切换的分支程序设计
-
在ARM程序中经常需要在程序跳转的同时还要进行处理器状态的转移,即从ARM指令程序段跳转到Thumb指令程序段(或相反)
-
为了实现这个功能,系统提供了一条专用的、可以实现4GB空间范围内的绝对跳转交换指令BX
-
看PPT144-145的例子
4.7.3 循环程序设计
-
当条件满足时,需要重复执行同一个程序段做同样工作的程序叫做循环程序。
-
被重复执行的程序段叫做循环体,需要满足的条件叫做循环条件。
-
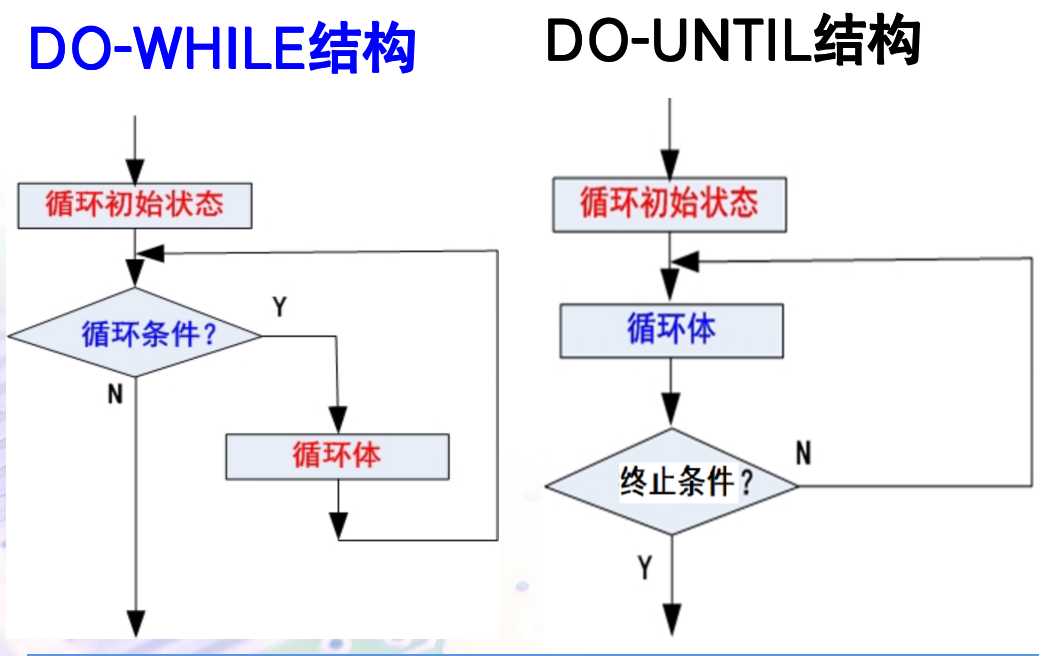
循环程序有两种结构:DO-WHILE结构 和 DO-UNTIL 结构
4.7.4 子程序及其调用
一、子程序的调用与返回
-
人们把可以多次反复调用的、能完成指定功能的程序段称为“子程序”。把调用子程序的程序称为“主程序”。
-
为进行识别,子程序的第1条指令之前必须赋予一个标号,以便其他程序可以用这个标号调用子程序。
-
ARM汇编语言程序中,主程序一般通过BL指令来调用子程序。
-
为使子程序执行完毕能返回主程序的调用处,子程序末尾处应有MOV、B、BX、LDMFD等指令,并在指令中将返回地址重新复制到 PC 中
-
示例:
一个使用 MOV 指令实现返回的子程序。 relay ….. MOV PC, LR 使用 B 指令实现返回的子程序。 relay ….. B LR ;(错误)--开发环境不认这个 ; 可以使用BX LR (正确)
-
二、子程序中堆栈的使用
relay
STMFD R13!,{R0~R12,LR};压入堆栈
…… ;子程序代码
LDMFD R13!,{R0~R12,PC} ;弹出堆栈并返回
4.8 C/C++语言和汇编语言的混合编程
4.8.1 汇编程序访问全局C变量
-
一般来说,汇编语言程序与C语言程序不在同一个文件上,所以实质上这是一个引用不同文件定义的变量问题。解决这个问题的办法就是使用关键字IMPORT和EXPORT。
-
在C程序中声明的全局变量可以被汇编程序通过地址间接访问,具体访问方法如下。
-
使用 IMPORT 伪指令声明该全局变量;
-
使用LDR宏指令读取该全局变量的内存地址,通常该全局变量的内存地址值存放在程序的数据缓冲池中;
-
根据该数据的类型,使用相应的LDR指令读取该全局变量的值;使用相应的STR 指令修改该全局变量的值。
- 各数据类型及其对应的 LDR/STR 指令如下。
- 对于无符号的char类型的变量通过指令LDRB/STRB来读写;
- 对于无符号的short类型的变量通过指令LDRH/STRH 来读写;
- 对于 int 类型的变量通过指令LDR/STR 来读写;
- 对于有符号的char类型的变量通过指令LDRSB 来读取;
- 对于有符号的char 类型的变量通过指令 STRB 来写入;
- 对于有符号的short类型的变量通过指令 LDRSH 来读取;
- 对于有符号的short类型的变量通过指令 STRH 来写入;
- 对于小于8个字的结构型变量,可以通过一条 LDM/STM 指令来读/写整个变量;
- 对于结构型变量的数据成员,可以使用相应的 LDR/STR 指令来访问,这时必须知道该数据成员相对于结构型变量开始地址的偏移量。
- 各数据类型及其对应的 LDR/STR 指令如下。
-
示例:
例、下面是一个汇编代码的函数,它引用了一个在其他文件中定义的全局变量globvar,将其加 2 后写回 globvar 。 AREA globals, CODE, READONLY EXPORT asmsubrouttine IMPORT globvar asmsubrouttine LDR R1,=globvar LDR R0,[R1] ADD R0,R0,#2 STR R0,[R1] MOV PC,LR END
-
4.8.2 C与汇编之间的函数调用
- 在ARM工程中,C程序调用汇编函数和汇编程序调用C 函数是经常发生的事情。为此人们制定了ARM-Thumb过程调用标准ATPCS(ARM-Thumb Procedure Call Standard)
一、ATPCS
-
为了使单独编译的C语言程序和汇编语言程序之间能够相互调用,必须为子程序间的调用设置一定的规则。具体包括:
- 在子程序编写时必须遵守相应的ATPCS规则。
- 数据栈的使用要遵守相应的ATPCS规则。
- 在汇编编译器中使用选项
-
堆栈与寄存器在函数调用中的作用
- 函数是通过寄存器和堆栈来传递参数和返回值的
- ARM编译器使用的函数调用规则就是ATPCS标准。ATPCS标准既是ARM编译器的规则,也是设计可被C程序调用的汇编函数的编写规则
-
ATPCS 关于堆栈和寄存器的使用规则
-
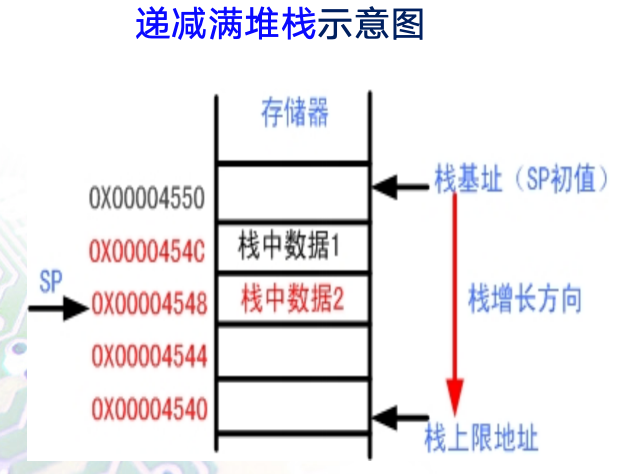
ATPCS规定,ARM的数据堆栈为FD型堆栈,即递减满堆栈。
-
ATPCS 标准规定
-
对于参数个数不多于4的函数,编译器必须按参数在列表中的顺序,自左向右为它们分配寄存器 R0~R3。其中函数返回时,R0还被用来存放函数的返回值
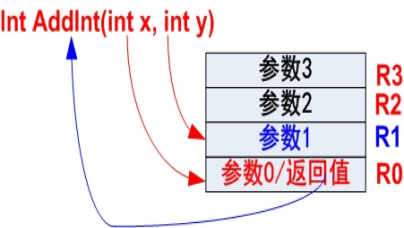
-
如果函数的参数多于4个,那么多余的参数则按自右向左的顺序压入数据堆栈,即参数入栈顺序与参数顺序相反。
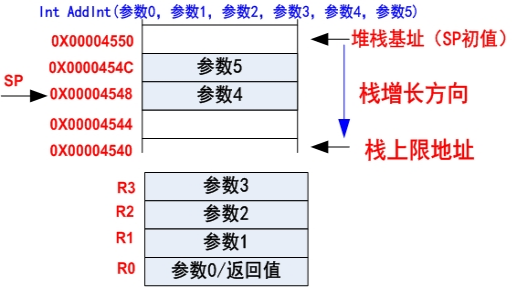
-
下表列举了ARM-Thumb过程调用标准规定的寄存器的名称和使用方法
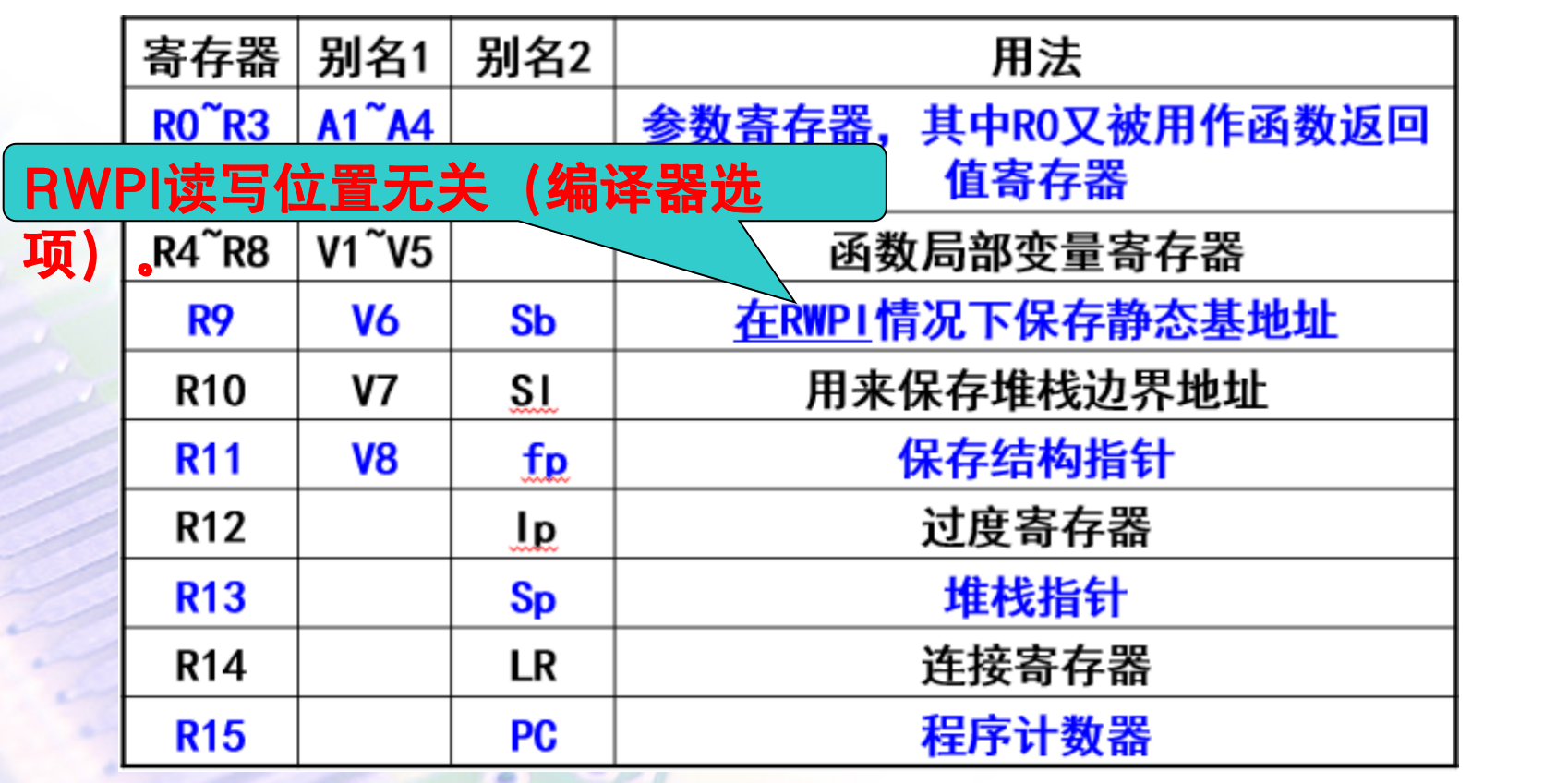
-
-
二、C调用汇编函数实例
-
下面是一个用汇编语言编写的函数,该函数把R1指向的字符串复制到R0指向的存储块。
AREA tt, CODE, READONLY EXPORT strcopy strcopy LDRB R2,[R1],#1 STRB R2,[R0],#1 CMP R2,#0 BNE strcopy MOV PC,LR END- 根据ATPCS的C语言程序调用汇编函数的规则,参数由左向右依次传递给寄存器R0~R3,可知汇编函数strcopy 在 C 程序中原型应该为:
void strcopy(char *d,const char* s);
// 在 C 语言文件中,调用 strcopy 函数的方法如下: extern void strcopy(char *d,const char * s); int main(void) { const char *src = “source”; char dest[10]; ……. strcopy(dest, src); ………. } - 根据ATPCS的C语言程序调用汇编函数的规则,参数由左向右依次传递给寄存器R0~R3,可知汇编函数strcopy 在 C 程序中原型应该为:
-
常量指针
- 表示指针所指向的地址的内容是不可修改的,但指针自身可变。
- const 类型 指针名*
- 表示指针所指向的地址的内容是不可修改的,但指针自身可变。
-
指针常量
- 指针常量表示指针自身不可变,但其指向的地址的内容是可以修改的
- 类型 const 指针名*
- 指针常量表示指针自身不可变,但其指向的地址的内容是可以修改的
三、汇编调用C函数
-
现有 C 函数 g() 如下:
int g(int a, int b, int c, int d, int e){ return a+b+c+d+e; }汇编函数f中调用C函数g(),以实现下面的功能:
int f(int i) {return –g(i, 2*i, 3*i, 4*i,5*i)};整个汇编函数 f 的代码如下: EXPORT f AREA tt, CODE, READONLY IMPORT g ;声名g为外部引用符号 ENTRY f STR LR, [SP,#-4]! ;断点存入堆栈,解决嵌套、返回 ADD R1, R0, R0 ;(R1)= i*2 ADD R2, R1, R0 ;(R2)= i*3 ADD R3, R1, R2 ;(R3)= i*5 STR R3, [SP, #-4]! ;将(R3)即第5个参数i*5存入堆栈 ADD R3, R1, R1 ;(R3)= i*4 BL g ;调用C函数g(),返回值在寄存器R0中 ADD SP, SP, #4 ;清栈,第5个参数 RSB R0, R0, #0 ;函数f的返回值(R0)=0-(R0) LDR PC, [SP],#4 ;恢复断点并返回 END
4.8.3 C和汇编的混合编程
- 除了上面介绍的函数调用方法之外,ARM编译器 armcc 中含有的内嵌汇编器还允许在C程序中内联或嵌入式汇编代码,以提高程序的效率
一、内联汇编
-
定义内联汇编程序
-
所谓内联汇编程序,就是在C程序中直接编写汇编程序段而形成一个语句块,这个语句块可以使用除了 BX 和 BLX之外的全部ARM指令来编写,从而可以使程序实现一些不能从C获得的底层功能。
-
其格式为:
_ _asm { 汇编语句块 }- 汇编语句块中,如果有两条指令占据了同一行,那么必须用分号“ ;”将它们分隔。
- 如果一条指令需要占用多行,那么必须用反斜线符号“ \ ”作为续行符。
- 可以在内联汇编语言块内的任意位置使用 C/C++ 格式的注释。
- 内联汇编代码中定义的标号可被用作跳转或C/C++ goto 语句的目标,同样,在C/C++代码中定义的标号,也可被用作内联汇编代码跳转指令的目标。
-
-
内联汇编的限制
- 内联汇编与真实汇编之间有很大区别,会受到很多限制。
- 它不支持 Thumb 指令;
- 除了程序状态寄存器 CPSR 之外,不能直接访问其他任何物理寄存器等;
- 如果在内联汇编程序指令中出现了以某个寄存器名称命名的操作数,那么它被叫做虚拟寄存器,而不是实际的物理寄存器。编译器在生成和优化代码的过程中,会给每个虚拟寄存器分配实际的物理寄存器,但这个物理寄存器可能与在指令中指定的不同。唯一的一个例外就是状态寄存器PSR ,任何对PSR的引用总是执行指向物理 PSR;
- 在内联汇编代码中不能使用寄存器 PC(R15)、LR(R14)和SP(R13),任何试图使用这些寄存器的操作都会导致出现错误消息;
- 鉴于上述情况,在内联汇编语句块中最好使用C或C++ 变量作为操作数;
- 虽然内联汇编代码可以更改处理器模式,但更改处理器模式会禁止使用C操作数或对已编译C代码的调用,直到将处理器模式恢复为原设置之后。
- 内联汇编与真实汇编之间有很大区别,会受到很多限制。
二、嵌入式汇编
-
嵌入式汇编程序是一个编写在C程序外的单独汇编程序,该程序段可以像函数那样被C程序调用。
-
与内联汇编不同,嵌入式汇编具有真实汇编的所有特性,数据交换符合 ATPCS 标准,同时支持 ARM 和Thumb,所以它可以对目标处理器进行不受限制的低级访问。但是不能直接引用 C/C++ 的变量。
-
用 _ _asm声明的嵌入式汇编程序像C函数那样可以有参数和返回值。定义一个嵌入式汇编函数的语法格式为:
_ _asm return–type function–name(parameter-list) { 汇编程序段 } // return–type:函数返回值类型,C语言中的数据类型; // function–name:函数名; // parameter-list:函数参数列表-
嵌入式汇编在形式上看起来就像使用关键字 _ _asm进行了声明的函数
-
注:
-
ADS环境中不能使用嵌入式汇编。
-
参数名只允许使用在参数列表中,不能用在嵌入式汇编函数体内
-
如下面定义的嵌入式汇编程序是错误的
_ _asm int f(int i) { ADD i, i, #1 //错误 MOV PC, LR } // 按 ATPCS 规定,应该使用寄存器 R0 来代替 i。
-
-
-
在C程序中调用嵌入式汇编程序的方法与调用C函数的方法相同。
-
三、内联汇编和嵌入式汇编之间的差异
-
内联汇编代码使用高级处理器抽象,并在代码生成过程中与 C 和 C++代码集成。因此编译程序将 C 和 C++代码与汇编代码一起进行优化;
-
与内联汇编代码不同,嵌入式汇编代码从 C 和 C++ 代码中分离出来单独进行汇编,产生与 C 和 C++ 源代码编译对象相结合的编译对象;
-
可通过编译程序来内联汇编代码,但无论是显示还是隐式,都无法内联嵌入式汇编代码
-
主要差异:
项目 内联汇编 嵌入式汇编 指令集 仅限于ARM ARM和Thumb ARM汇编程序命令 不支持 支持 C表达式 支持 仅支持常量表达式 优化代码 支持 不支持 内联 可能 从不 寄存器访问 不使用物理寄存器 使用物理寄存器 返回指令 自动生成 显示编写