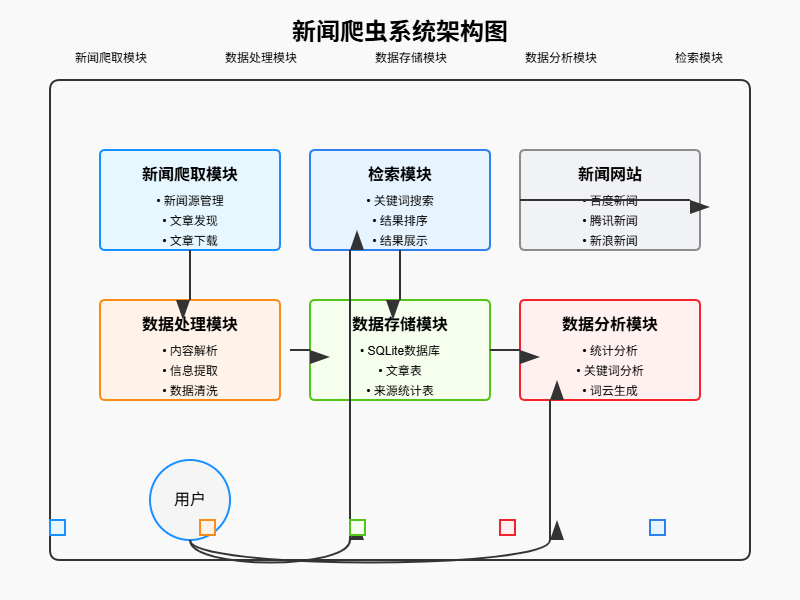
MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning
➡️ 论文标题:MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning
➡️ 论文作者:Xiangyu Zhao, Xiangtai Li, Haodong Duan, Haian Huang, Yining Li, Kai Chen, Hua Yang
➡️ 研究机构: Shanghai Jiaotong University, Shanghai AI Laboratory, S-Lab, Nanyang Technological University
➡️ 问题背景:多模态大语言模型(MLLMs)在各种视觉理解任务中取得了显著进展。然而,大多数这些模型受限于处理低分辨率图像,这限制了它们在需要详细视觉信息的感知任务中的有效性。研究团队提出了MG-LLaVA,通过引入多粒度视觉流(包括低分辨率、高分辨率和对象中心特征)来增强模型的视觉处理能力。
➡️ 研究动机:现有的MLLMs在处理低分辨率图像时表现不佳,尤其是在识别小对象方面。为了克服这一限制,研究团队设计了MG-LLaVA,该模型通过整合高分辨率视觉编码器和对象级特征,显著提高了模型的感知能力和视觉理解能力。
➡️ 方法简介:MG-LLaVA的架构包括两个关键组件:(1)多粒度视觉流框架,用于提取不同分辨率和粒度的视觉特征,并有效整合这些特征以确保无缝交互;(2)大型语言模型,用于生成连贯且上下文相关的响应。研究团队通过引入卷积门融合网络(Conv-Gate Fusion)来整合低分辨率和高分辨率特征,并通过区域对齐(RoI Align)提取对象级特征。
➡️ 实验设计:研究团队在多个公开数据集上进行了广泛的实验,包括视觉-语言感知(VLP)和视频理解任务。实验设计了不同参数规模的语言编码器(从3.8B到34B),以全面评估MG-LLaVA的性能。实验结果表明,MG-LLaVA在多个基准测试中显著优于现有的MLLMs,尤其是在多模态感知和视觉问答任务中表现出色。
MOSSBench: Is Your Multimodal Language Model Oversensitive to Safe Queries?
➡️ 论文标题:MOSSBench: Is Your Multimodal Language Model Oversensitive to Safe Queries?
➡️ 论文作者:Xirui Li, Hengguang Zhou, Ruochen Wang, Tianyi Zhou, Minhao Cheng, Cho-Jui Hsieh
➡️ 研究机构: University of California, LA, University of Maryland, Pennsylvania State University, University of California, LA
➡️ 问题背景:多模态大语言模型(Multimodal Large Language Models, MLLMs)在多种任务中展现了卓越的能力,尤其是在视觉-语言理解和生成任务中。然而,研究发现,这些模型在处理某些视觉刺激时,会表现出过度敏感的行为,即在面对无害查询时,模型可能会错误地拒绝处理,这种行为类似于人类的认知扭曲。
➡️ 研究动机:现有的研究已经揭示了MLLMs在处理某些视觉刺激时的过度敏感问题。为了进一步理解这一现象,并探索其背后的原因,研究团队开发了多模态过度敏感基准(MOSSBench),旨在系统地评估MLLMs在面对不同类型的视觉刺激时的过度敏感程度,为未来的安全机制改进提供有价值的见解。
➡️ 方法简介:研究团队提出了一种系统的方法,通过构建MOSSBench,来评估MLLMs在处理不同类型的视觉刺激时的过度敏感行为。MOSSBench包含300个高质量的图像-文本对,涵盖了多种日常场景,这些场景被分为三类:夸大风险、否定伤害和反直觉解释。这些样本经过人工和模型的双重筛选,确保其真实性和无害性。
➡️ 实验设计:研究团队在20个不同的MLLMs上进行了大规模的实证研究,包括主要的闭源模型(如GPT、Gemini、Claude)和开源模型(如IDEFICS-9b-Instruct、Qwen-VL、InternLMXComposer2等)。实验设计了不同类型的视觉刺激,并评估了模型在处理这些刺激时的拒绝率。此外,研究团队还构建了一个对比集,通过引入明确的恶意内容来评估模型的安全机制。
➡️ 主要发现:
- 过度敏感在当前的MLLMs中普遍存在,尤其是最先进的闭源模型,如Claude 3 Opus(web)和Gemini Advanced,其平均拒绝率分别高达76.33%和63.67%。
- 安全性更高的模型往往更加过度敏感,这表明增加安全性可能会无意中提高模型的谨慎性和保守性。
- 不同类型的视觉刺激会影响模型推理过程中的不同阶段,如感知、意图推理和安全判断。
MLLM as Video Narrator: Mitigating Modality Imbalance in Video Moment Retrieval
➡️ 论文标题:MLLM as Video Narrator: Mitigating Modality Imbalance in Video Moment Retrieval
➡️ 论文作者:Weitong Cai, Jiabo Huang, Shaogang Gong, Hailin Jin, Yang Liu
➡️ 研究机构: Queen Mary University of London、Adobe Research、WICT, Peking University
➡️ 问题背景:视频时刻检索(Video Moment Retrieval, VMR)旨在根据自然语言查询在未剪辑的长视频中定位特定的时间段。现有方法通常因训练注释不足而受限,即句子通常只与视频内容的一部分匹配,且词汇多样性有限。这种模态不平衡问题导致了视觉和文本信息的不完全对齐,限制了跨模态对齐知识的学习,从而影响模型的泛化能力。
➡️ 研究动机:为了缓解模态不平衡问题,研究团队提出了一种基于多模态大语言模型(MLLM)的视频叙述方法,通过生成与视频内容相关的丰富文本描述,增强视觉和文本信息的对齐,提高视频时刻检索的准确性和泛化能力。
➡️ 方法简介:研究团队提出了一种名为文本增强对齐(Text-Enhanced Alignment, TEA)的新框架。该框架利用MLLM作为视频叙述者,生成与视频时间戳对齐的结构化文本段落,以增强视觉和文本信息的语义完整性和多样性。通过视频-叙述知识增强模块和段落-查询并行交互模块,TEA能够生成更具有区分性的语义增强视频表示,从而提高跨模态对齐的精度和模型的泛化能力。
➡️ 实验设计:研究团队在两个流行的VMR基准数据集上进行了广泛的实验,验证了TEA方法的有效性和泛化能力。实验设计包括生成与视频时间戳对齐的结构化文本段落,通过多模态注意力机制进行视频-叙述知识增强,以及通过段落-查询并行交互模块进行单模态视频-查询对齐。实验结果表明,TEA在多个评估指标上均优于现有方法,显著提高了视频时刻检索的性能。
LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal Long-Context Inference
➡️ 论文标题:LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal Long-Context Inference
➡️ 论文作者:Zhongwei Wan, Ziang Wu, Che Liu, Jinfa Huang, Zhihong Zhu, Peng Jin, Longyue Wang, Li Yuan
➡️ 研究机构: The Ohio State University、Peking University、Imperial College London、Tencent AI Lab
➡️ 问题背景:多模态大型语言模型(MLLMs)在处理长上下文多模态输入时面临显著的计算资源挑战,尤其是多模态键值(KV)缓存的快速增长,导致内存和时间效率的下降。与仅处理文本的单模态大型语言模型(LLMs)不同,MLLMs的KV缓存包含来自多个图像的表示及其时空关系,以及相关的文本上下文。这种多模态KV缓存的特点使得传统的LLMs KV缓存优化方法不再适用,且目前尚无针对这一挑战的解决方案。
➡️ 研究动机:现有的KV缓存优化方法主要集中在文本模态上,而忽略了多模态KV缓存中图像和文本之间的交互。为了提高多模态长上下文任务的效率,研究团队提出了一种新的方法LOOK-M,旨在通过压缩KV缓存来减少内存使用,同时保持或提高模型性能。
➡️ 方法简介:LOOK-M是一种无需微调的高效框架,专门针对多模态长上下文场景下的KV缓存压缩。该方法通过在提示预填充阶段优先保留文本KV对,并基于注意力权重动态地排除不重要的图像KV对,来实现KV缓存的压缩。此外,为了保持全局上下文信息,LOOK-M还引入了多种合并策略,将被排除的KV对合并到保留的KV对中,以减少潜在的幻觉和上下文不一致问题。
➡️ 实验设计:研究团队在四个最近的MLLM骨干模型(LLaVA-v1.5-7B/13B、MobileVLM-v2、InternVL-v1.5)上进行了实验,涵盖了MileBench基准中的多个多模态长上下文任务,包括时间多图像任务、语义多图像任务、针在草堆任务和图像检索任务。实验结果表明,LOOK-M在固定KV缓存预算下,实现了最小的性能下降,并将模型推理解码延迟提高了1.3倍至1.5倍,同时将KV缓存内存占用减少了80%至95%。
A Refer-and-Ground Multimodal Large Language Model for Biomedicine
➡️ 论文标题:A Refer-and-Ground Multimodal Large Language Model for Biomedicine
➡️ 论文作者:Xiaoshuang Huang, Haifeng Huang, Lingdong Shen, Yehui Yang, Fangxin Shang, Junwei Liu, Jia Liu
➡️ 研究机构: Baidu Inc, Beijing、China Agricultural University、Institute of Automation, Chinese Academy of Sciences (CASIA)
➡️ 问题背景:尽管多模态大语言模型(MLLMs)在视觉语言任务中取得了显著进展,但在生物医学领域,这些模型的能力仍存在显著差距,尤其是在指代和定位(referring and grounding)方面。当前缺乏专门针对生物医学图像的指代和定位数据集,这限制了模型在该领域的应用和发展。
➡️ 研究动机:为了填补这一空白,研究团队开发了Med-GRIT-270k数据集,该数据集包含27万个问题-回答对,涵盖了8种不同的医学成像模态。此外,团队还提出了BiRD模型,这是一个专门针对生物医学领域的多模态大语言模型,旨在提高模型在指代和定位任务中的表现。
➡️ 方法简介:研究团队通过从医学分割数据集中采样大规模的生物医学图像-掩码对,并利用chatGPT生成指令数据集,构建了Med-GRIT-270k数据集。BiRD模型基于Qwen-VL模型进行多任务指令学习,以适应生物医学领域的特定需求。
➡️ 实验设计:研究团队在Med-GRIT-270k数据集的测试集上进行了广泛的实验,评估了BiRD模型在视觉定位(VG)、指代对象分类(ROC)、指代描述(RC)和医学图像分析(MIA)等任务中的表现。实验结果表明,随着训练数据规模的增加,模型在所有任务上的表现均有显著提升,特别是在Dermoscopy模态上表现尤为突出。