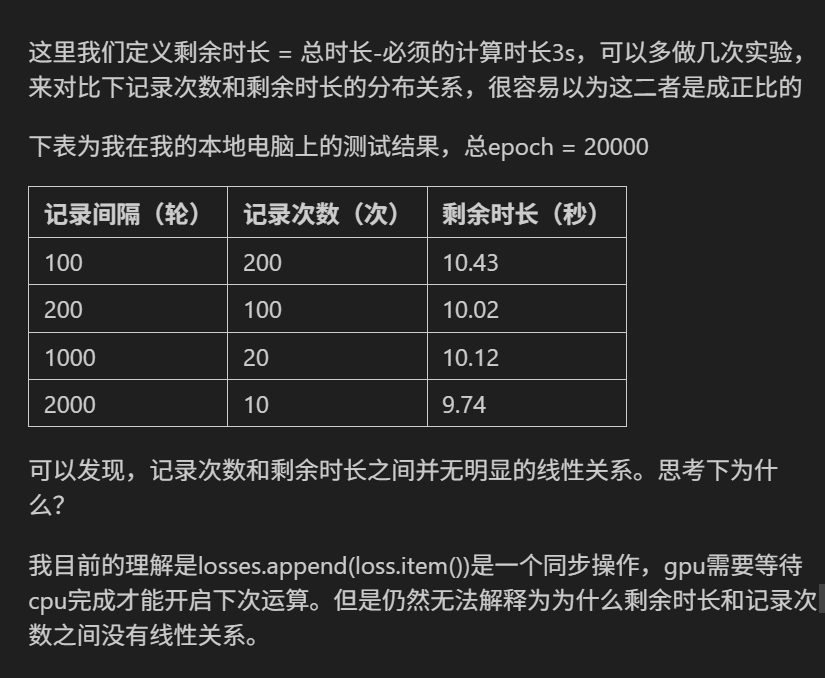
在开发用户搜索功能时,我们通常会将用户信息存储到 Elasticsearch(简称 ES) 中,以提高搜索效率。本篇文章将详细介绍我们是如何实现 MySQL 到 Elasticsearch 的增量同步,以及如何通过 MQ 消息队列实现用户信息实时更新 的机制。
一、整体思路
为了保证用户数据在 MySQL 与 ES 之间保持一致,我们采用了以下 双通道同步策略:
-
定时任务 + 游标机制:实现 MySQL 到 ES 的增量同步
-
通过 MQ(消息队列) 实现实时同步用户更新/删除操作到 ES
二、定时任务增量同步逻辑详解
我们定义了一个定时任务 syncUserDataToESJob,主要用于从 user 表中 增量拉取变动数据,并同步到 ES。
✨ 增量拉取机制
为了避免全量同步的高开销,我们使用了 “更新时间 + 主键 ID”双重游标,实现分页增量同步:
List<User> usersBatch = userClient.selectIncrementalUsers(lastSyncTime, lastMaxId, PAGE_SIZE);
其中:
-
lastSyncTime表示上次同步的最大更新时间 -
lastMaxId用于处理相同更新时间下的并发写入
🧠 同步逻辑核心代码如下:
@XxlJob("syncUserDataToESJob")
@GlobalTransactional
public void syncUserData() {
Date lastSyncTime = syncPointService.getLastSyncTime();
Long lastMaxId = syncPointService.getLastMaxId();
if (lastSyncTime == null) {
lastSyncTime = new Date(0); // 默认从最早开始
lastMaxId = 0L;
}
Date maxUpdateTime = lastSyncTime;
Long maxId = lastMaxId;
boolean hasNewData = false;
while (true) {
List<User> usersBatch = userClient.selectIncrementalUsers(lastSyncTime, lastMaxId, PAGE_SIZE);
if (usersBatch.isEmpty()) break;
hasNewData = true;
List<EsUserDoc> esDocs = usersBatch.stream()
.map(this::convertToEsDoc)
.collect(Collectors.toList());
esClient.bulkIndex(esDocs);
for (User u : usersBatch) {
Date updateTime = u.getUpdateTime();
if (updateTime.after(maxUpdateTime)) {
maxUpdateTime = updateTime;
maxId = u.getId();
} else if (updateTime.equals(maxUpdateTime) && u.getId() > maxId) {
maxId = u.getId();
}
}
lastSyncTime = maxUpdateTime;
lastMaxId = maxId;
}
// 同步删除数据
List<Long> deletedUserIds = userClient.selectDeletedUserIds(syncPointService.getLastSyncTime(), syncPointService.getLastMaxId());
if (!deletedUserIds.isEmpty()) {
esClient.bulkDeleteByIds(deletedUserIds);
}
if (hasNewData) {
log.info("更新同步点:maxUpdateTime = {}, maxId = {}", maxUpdateTime, maxId);
syncPointService.updateLastSyncPoint(maxUpdateTime, maxId);
} else {
log.info("本次没有增量数据,不更新同步点");
}
}
📝 特别说明:
-
syncPointService用于记录上次同步的时间点和 ID,保证每次定时任务可重复安全执行。 -
如果服务中断重启,也不会造成数据丢失或重复。
三、用户修改通过 MQ 实时同步到 ES
虽然定时任务可以周期性同步,但如果用户更新昵称、头像、标签等信息,等待下一次定时任务才能生效,可能会造成 数据延迟。
为此,我们引入了 消息队列机制,实现实时更新:
✅ 使用 MQ 的同步方案
-
用户信息发生变化时,在业务服务中发送一条消息:
UserUpdateMessage message = new UserUpdateMessage(userId);
rabbitTemplate.convertAndSend("user.topic.exchange", "user.update", message);
-
在 ES 同步服务中监听消息并处理:
@RabbitListener(queues = "user.update.queue")
public void onUserUpdate(UserUpdateMessage msg) {
User user = userClient.getUserById(msg.getUserId());
if (user != null) {
EsUserDoc doc = convertToEsDoc(user);
esClient.index(doc);
}
}
💡 好处:
-
实时:用户更新后立即同步到 ES
-
解耦:业务逻辑与搜索逻辑分离
-
高性能:避免频繁更新 ES
四、总结与展望
通过“定时任务 + 增量游标” 和 “消息队列实时更新” 的结合方案,我们实现了对用户数据高效且可靠的同步到 Elasticsearch。
| 同步方式 | 特点 | 使用场景 |
|---|---|---|
| 定时任务 | 批量、容错性强 | 周期性同步新增/修改/删除 |
| MQ 实时 | 快速、解耦 | 用户主动更新资料时快速生效 |
未来我们还可以扩展以下能力:
-
引入 Canal + Binlog 监听实现更彻底的实时同步
-
支持多租户分库分表的场景下数据同步
-
引入失败重试机制保障消息不丢
希望本文对你在做数据同步或 ES 架构设计时有所启发,欢迎点赞、收藏、评论交流!