本文旨在通过实例数据,详细解读YOLOv8检测头的网络结构及其代码实现。首先将从检测头的网络架构开始讲解,涵盖代码与网络结构图的对比分析。关键在于深入探讨检测头的输出结果,因为这些输出将直接用于损失函数的计算。由于在不同阶段,检测头的输出有所不同,因此在讲解损失函数的计算之前,我们需要先理解检测头的输出内容以及相关参数的定义。
代码的讲解及数据变换在注释中。
一、检测头/解耦头
2.1 理论框图
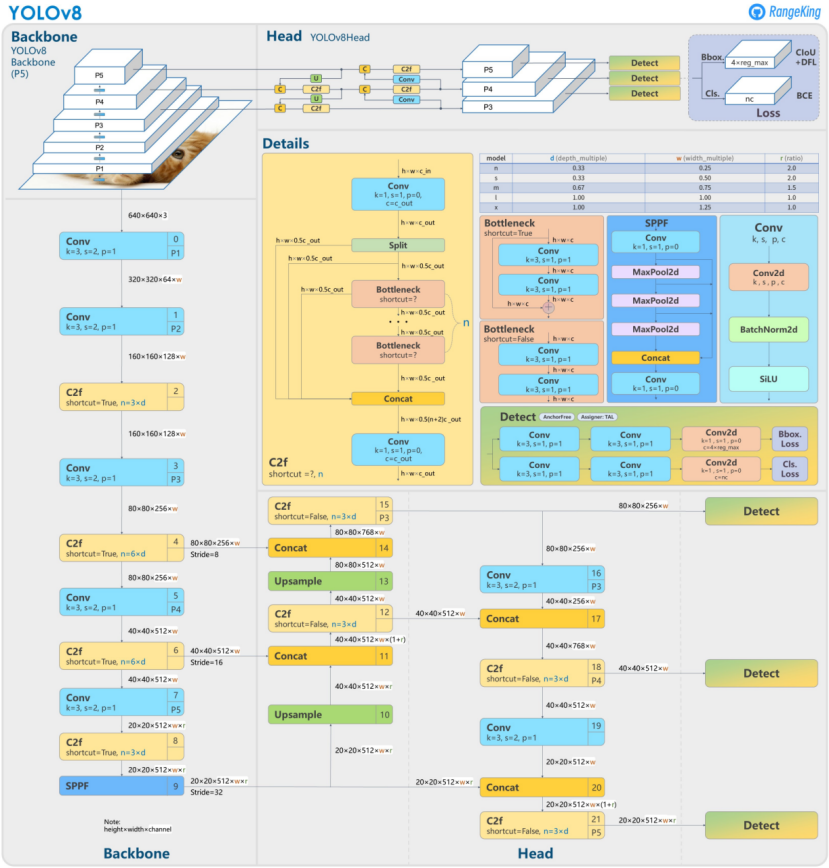
在框图中,我将检测头部分单独截取如下:
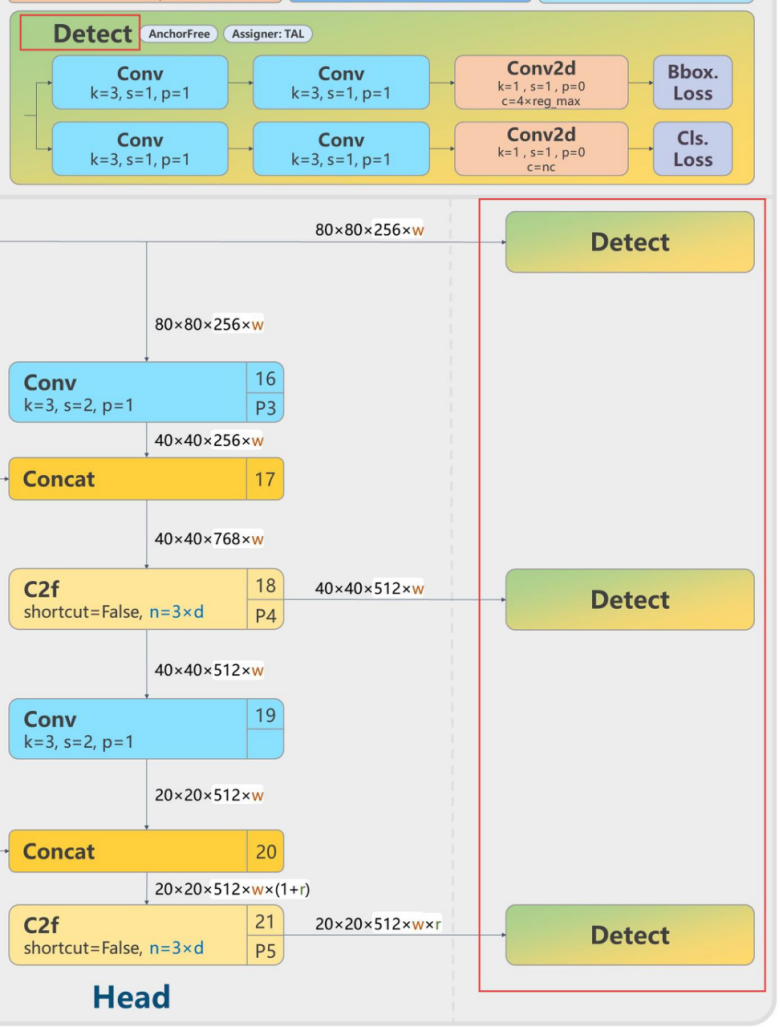
其中包含三个结构,任何一个被选中都将作为我们的解耦头(即分别计算BboxLoss和CIsLoss)。
这三个部分,仅是输入的特征图大小和通道数存在差异,这也是我们所说的大目标检测头和小目标检测头的区别(即20x20和80x80的区别)。因此,大目标检测头和小目标检测头实际上调用的是同一段代码,只是从Neck部分输入给检测头的特征图不同,从而产生了大目标和小目标检测头的定义。
2.2 YOLOv8检测头代码分析
YOLOv8检测头的代码位于项目仓库的'ultralytics/nn/modules/head.py'路径下。虽然现在代码已经更新,但核心内容保持不变,只是新增了一些无关紧要的小功能。
class Detect(nn.Module):
"""YOLO Detect head for detection models.
检测头模块,负责将骨干网络提取的特征转换为检测预测结果
网络结构组成:
- 回归分支(cv2):预测边界框的分布参数
- 分类分支(cv3):预测类别置信度
- DFL模块:将分布参数转换为坐标偏移量
- 解码模块:将偏移量转换为实际坐标
输入特征图示例:
layer1: (1, 128, 80, 80) # 高分辨率特征图,检测小物体
layer2: (1, 256, 40, 40) # 中分辨率特征图
layer3: (1, 512, 20, 20) # 低分辨率特征图,检测大物体
Args:
nc (int): 类别数
ch (list): 输入通道数列表,例如[128, 256, 512]表示三个检测层的输入通道数
"""
dynamic = False # 是否动态重建网格(通常用于动态输入尺寸)
export = False # 导出模式(影响后处理方式)
format = None # 导出格式(tflite/edgetpu等)
end2end = False # 是否端到端模式
max_det = 300 # 每张图最大检测数
shape = None # 输入特征图形状缓存
anchors = torch.empty(0) # 初始化锚点
strides = torch.empty(0) # 各检测层的步长
def __init__(self, nc=80, ch=()):
super().__init__()
self.nc = nc # 检测的类别数量
self.nl = len(ch) # 检测层(输出特征层)的数量,例如 YOLOv8 有3个输出层
self.reg_max = 16 # DFL(Distribution Focal Loss)使用的分布最大值,表示每个坐标回归预测分布的离散区间数(0~15)
self.no = nc + self.reg_max * 4 # 每个“anchor”位置输出的通道数:nc 个分类分数 + 4 个坐标回归分布值(每个坐标 reg_max 个分布值,4 个坐标)
self.stride = torch.zeros(self.nl) # 存储每个检测层的下采样步幅(stride),将在模型构建时赋值,例如[8.0, 16.0, 32.0]
# 构建回归分支和分类分支
# 根据输入通道数计算头部卷积的中间通道数:
# c2 用于回归分支的卷积通道数,至少为16,并取输入通道的1/4与 reg_max*4 之间的较大值,确保足够的容量预测坐标
# c3 用于分类分支的卷积通道数,取输入通道和 min(nc,100) 之间的较大值,避免类别数很多时通道过少(上限100)
c2 = max(16, ch[0] // 4, self.reg_max * 4)
c3 = max(ch[0], min(self.nc, 100))
# 回归分支(预测边界框):Conv -> Conv -> 输出reg_max*4通道
# 例如:输入ch[0]=256,经过两个Conv后输出64通道(16*4)
# 最终 1x1 卷积将通道压缩到 4*reg_max(例如 reg_max=16 时输出64通道),表示4个坐标的分布预测
self.cv2 = nn.ModuleList(
nn.Sequential(
Conv(in_channels, c2, k=3), # 第一个卷积模块,提取特征,k=3表示3x3卷积
Conv(c2, c2, k=3), # 第二个卷积模块,继续提取特征
nn.Conv2d(c2, 4 * self.reg_max, 1) # 最终1x1卷积,输出4*reg_max个通道(每个坐标 reg_max 个分布值)
) for in_channels in ch
)
# 分类分支(预测类别):若使用 legacy 模式则用简单的两个卷积,否则采用深度可分离卷积结构提高效率
# 例如:输入ch[0]=256,最终输出80通道(对应80类)
self.cv3 = (
nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
if self.legacy
else nn.ModuleList(
nn.Sequential(
nn.Sequential(DWConv(x, x, 3), Conv(x, c3, 1)),
nn.Sequential(DWConv(c3, c3, 3), Conv(c3, c3, 1)),
nn.Conv2d(c3, self.nc, 1),
)
for x in ch
)
)
# DFL模块(Distribution Focal Loss),用于边界框回归,将离散分布转换为连续坐标的模块
# 如果 reg_max>1 则使用 DFL,将 4*reg_max 分布输出转换为4个坐标回归值;若 reg_max==1 则无需转换直接Identity
# DFL模块内部实现:对每个坐标的 reg_max 个值应用softmax得到概率分布,再与 [0, 1, ..., reg_max-1] 加权求和得到回归输出
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
def forward(self, x):
"""处理输入特征图,输出检测结果
Args:
x (list[Tensor]): 来自不同尺度的特征图列表
示例输入:假设有3个检测层,每个特征图形状为
[(bs, 128, 80, 80), (bs, 256, 40, 40), (bs, 512, 20, 20)]
Returns:
(Tensor): 形状为(bs, num_anchors, 4+nc)的检测结果
"""
# 逐层处理特征图
for i in range(self.nl):
# 将回归分支和分类分支的输出在通道维度拼接
# 输入x[i]形状:例如(bs, 128, 80, 80)
# cv2[i]处理后得到回归结果:(bs, 64, 80, 80)
# cv3[i]处理后得到分类结果:(bs, 80, 80, 80)
# 拼接后得到:(bs, 144=64+80, 80, 80)
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training: # 训练阶段直接返回原始输出
return x
# -------------------- 推理阶段 --------------------
shape = x[0].shape # 取第一个特征图的形状,例如(bs, 144, 80, 80)
# 将多尺度特征图展平并拼接(核心形状变换步骤)
# 示例处理过程:
# 假设原始三个检测层特征图形状:
# [(1, 144, 80,80), (1, 144, 40,40), (1, 144, 20,20)]
# 各层view操作后:
# (1, 144, 80*80=6400) → (1,144,6400)
# (1, 144, 40*40=1600) → (1,144,1600)
# (1, 144, 20*20=400) → (1,144,400)
# 最终沿dim=2拼接 → (1,144,6400+1600+400=8400)
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
# 动态生成锚点和步长(当输入尺寸变化或首次推理时)
# 条件说明:
# - 非IMX导出格式时生效
# - dynamic标志为True时强制重新生成
# - 当特征图形状发生变化时自动更新
if self.format != "imx" and (self.dynamic or self.shape != shape):
# make_anchors生成网格坐标和对应步长,代码下面会单独讲
# 输入:特征图列表、各层预设stride、偏移量0.5(中心对齐)
# 输出:
# anchors形状:(8400, 2) 每个锚点的(x_center, y_center)
# strides形状:(8400,) 每个锚点对应的特征图层下采样倍数
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
self.shape = shape # 缓存当前形状用于后续比对
# 分割回归分支和分类分支(不同导出格式处理方式不同)
if self.export and self.format in {"saved_model", "pb", "tflite", "edgetpu", "tfjs"}:
# 针对TensorFlow系列格式的特殊处理(避免FlexSplitV算子)
# 直接切片分割:前64通道为回归,后续80通道为分类
box = x_cat[:, : self.reg_max * 4] # 形状:(1, 64, 8400)
cls = x_cat[:, self.reg_max * 4:] # 形状:(1, 80, 8400)
else:
# 常规分割方式(使用split函数)
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1) # 同上形状
# 导出模式特殊处理分支
if self.export and self.format in {"tflite", "edgetpu"}:
# 针对移动端设备的数值稳定性优化(预计算归一化系数)
# 生成网格尺寸参数(适配不同分辨率特征图)
grid_h = shape[2] # 特征图高度(如80)
grid_w = shape[3] # 特征图宽度(如80)
# 构造网格尺寸张量:[grid_w, grid_h, grid_w, grid_h]
# grid_size → tensor([[[80],[80],[80],[80]]], shape=(1,4,1)
grid_size = torch.tensor([grid_w, grid_h, grid_w, grid_h],
device=box.device).reshape(1, 4, 1)
# 计算归一化系数:strides / (基准stride * 网格尺寸)
norm = self.strides / (self.stride[0] * grid_size)
# 解码时应用归一化系数(提升数值稳定性)
dbox = self.decode_bboxes(self.dfl(box) * norm,
self.anchors.unsqueeze(0) * norm[:, :2])
elif self.export and self.format == "imx":
# IMX格式专用解码流程(使用直接缩放方式)
dbox = self.decode_bboxes(
self.dfl(box) * self.strides, # 偏移量乘以步长得到绝对坐标
self.anchors.unsqueeze(0) * self.strides, # 锚点坐标转换
xywh=False # 直接输出xyxy格式
)
# IMX格式需要转置维度:(batch, 4, 8400) → (batch, 8400, 4)
# 分类结果维度调整:(batch, 80, 8400) → (batch, 8400, 80)
return dbox.transpose(1, 2), cls.sigmoid().permute(0, 2, 1)
else:
# 常规推理模式解码流程
dbox = self.decode_bboxes(self.dfl(box), self.anchors.unsqueeze(0)) * self.strides
# 最终结果拼接(坐标+分类置信度)
# dbox形状:(1, 4, 8400) → 转置前需要保持维度
# cls经过sigmoid激活后形状:(1, 80, 8400)
# 拼接后形状:(1, 84, 8400) → 需要转置为(1, 8400, 84)
y = torch.cat((dbox, cls.sigmoid()), 1) # dim=1拼接
# 返回格式处理:导出模式直接返回,否则返回元组
return y if self.export else (y, x)我们已经解释了YOLOv8检测头中各个输出信息的含义,但上述代码中提及的函数:dist2bbox、make_anchors和DFL还没解释。
2.3 DFL
DFL的详细解释在我另一篇博客中,链接如下,这里就不赘述了。
YOLO中的DFL损失函数的理论讲解与代码分析-CSDN博客
2.4 make_anchors
make_anchors的作用是生成特征图锚点坐标及对应步长张量。
def make_anchors(feats, strides, grid_cell_offset=0.5):
"""生成锚点坐标和对应步长张量
参数说明:
feats (list[Tensor]): 特征图列表,每个元素形状为(bs, c, H, W)
strides (list[int]): 各特征图对应的下采样步长(如[8, 16, 32])
grid_cell_offset (float): 网格偏移量(通常为0.5表示中心对齐)
返回:
anchor_points (Tensor): 锚点坐标,形状为(N, 2),N=所有特征图网格点数之和
stride_tensor (Tensor): 步长张量,形状为(N, 1)
示例(以第一个检测层为例):
输入特征图形状:(1, 128, 80, 80)
对应stride=8
---
生成sx范围:[0.5, 1.5, ..., 79.5] 共80个点
生成sy范围:[0.5, 1.5, ..., 79.5] 共80个点
生成网格坐标 → 80x80=6400个点
最终该层输出:
anchor_points形状:(6400, 2)
stride_tensor形状:(6400, 1) 填充值8
"""
anchor_points, stride_tensor = [], []
assert feats is not None
dtype, device = feats[0].dtype, feats[0].device # 获取数据类型和设备信息
# 逐层处理每个特征图
for i, stride in enumerate(strides):
# 获取特征图尺寸(当输入是列表时取真实尺寸,否则取预设尺寸)
if isinstance(feats, list):
h, w = feats[i].shape[2], feats[i].shape[3] # 实际特征图高宽
else:
h, w = int(feats[i][0]), int(feats[i][1]) # 预设尺寸(备用逻辑)
# 生成网格坐标(核心步骤)-------------------------------------------
# 示例:当h=80, w=80时
# sx生成:从0.5到79.5,步长1 → 形状(80,)
sx = torch.arange(end=w, device=device, dtype=dtype) + grid_cell_offset
# sy生成:从0.5到79.5,步长1 → 形状(80,)
sy = torch.arange(end=h, device=device, dtype=dtype) + grid_cell_offset
# 创建网格坐标矩阵(两种版本处理)
if TORCH_1_10:
sy, sx = torch.meshgrid(sy, sx, indexing="ij") # (h, w)
else:
sy, sx = torch.meshgrid(sy, sx) # (h, w)
# 堆叠坐标并展平 → 形状(h*w, 2)
# 示例:h=80,w=80 → 6400个点,每个点包含(x,y)坐标
anchor_points.append(torch.stack((sx, sy), -1).view(-1, 2))
# 生成步长张量 → 形状(h*w, 1)
# 示例:填充6400个8 → 形状(6400,1)
stride_tensor.append(torch.full((h * w, 1), stride, dtype=dtype, device=device))
# 合并所有层的结果 ------------------------------------------------
# 示例:三个检测层分别为80x80,40x40,20x20
# anchor_points形状:
# (6400+1600+400, 2) = (8400, 2)
# stride_tensor形状:
# (8400, 1) → 前6400行是8,中间1600行是16,最后400行是32
return torch.cat(anchor_points), torch.cat(stride_tensor)锚点表示特征图每个单元格的中心位置,通过grid_cell_offset=0.5实现中心对齐。
例如输入图像640x640生成80x80特征图(stride=8时,特征图每个单元格对应输入图像8x8区域, 锚点坐标为(i+0.5, j+0.5),最终输出形状为(N,2)的锚点坐标和(N,1)的步长张量, N为所有特征图层网格点总数(如80x80+40x40+20x20=8400)。
2.5 dist2bbox
dist2bbox 是目标检测中用于将模型预测的偏移量转换为实际边界框坐标的核心解码函数。该函数接收两个关键输入:模型预测的四个方向偏移量(left, top, right, bottom)和预设的锚点坐标,通过简单的线性运算计算出最终检测框的位置。
def dist2bbox(distance, anchor_points, xywh=True, dim=-1):
"""将距离预测(ltrb)转换为边界框坐标(xywh或xyxy格式)
参数说明:
distance (Tensor): 模型预测的偏移量,形状为(batch, 4, num_anchors)或(num_anchors, 4)
ltrb格式:left, top, right, bottom四个方向的偏移量
anchor_points (Tensor): 锚点坐标,形状为(num_anchors, 2)或(batch, num_anchors, 2)
xywh (bool): 输出格式标记,True返回中心坐标+宽高,False返回左上右下坐标
dim (int): 分割和拼接的维度,默认为最后一个维度
返回:
bbox (Tensor): 边界框坐标,形状与输入anchor_points维度匹配,最后一维为4
示例(以单张图像/单批次为例):
输入预测distance形状:(1, 4, 8400) → 表示8400个锚点的4个偏移量
输入锚点anchor_points形状:(8400, 2) → 每个锚点的(x,y)坐标(特征图尺度)
处理流程:
1. 分割偏移量:
lt, rb = distance.chunk(2, dim=1) → 各形状(1,2,8400)
lt = [[[左偏移0, 左偏移1, ...], [上偏移0, 上偏移1, ...]]]
rb = [[[右偏移0, 右偏移1, ...], [下偏移0, 下偏移1, ...]]]
2. 计算坐标边界:
x1y1 = anchor_points - lt → 形状(1,8400,2)
x2y2 = anchor_points + rb → 形状(1,8400,2)
假设某个锚点坐标(6.5,4.5),对应偏移量lt=(0.3,0.2),rb=(0.5,0.4)
则左上坐标:x1y1 = (6.5-0.3,4.5-0.2) = (6.2,4.3)
右下坐标:x2y2 = (6.5+0.5,4.5+0.4) = (7.0,4.9)
3. 格式转换:
if xywh=True → 计算中心点和宽高:
center = (x1y1 + x2y2)/2 → (6.6,4.6)
wh = x2y2 - x1y1 → (0.8,0.6)
输出形状:(1,8400,4) → [[[6.6,4.6,0.8,0.6], ...]]
else → 直接拼接坐标 → [[[6.2,4.3,7.0,4.9], ...]]
"""
# 分割左/上、右/下偏移量
lt, rb = distance.chunk(2, dim) # 各形状保持与distance相同维度
# 计算左上(x1,y1)和右下(x2,y2)坐标(自动广播机制处理维度)
x1y1 = anchor_points - lt # 形状适配,如(1,8400,2)
x2y2 = anchor_points + rb # 形状适配,如(1,8400,2)
# 根据格式标记转换输出
if xywh:
# 计算中心坐标和宽高
c_xy = (x1y1 + x2y2) / 2 # 中心点,形状如(1,8400,2)
wh = x2y2 - x1y1 # 宽高,形状如(1,8400,2)
return torch.cat((c_xy, wh), dim) # 拼接后形状(1,8400,4)
return torch.cat((x1y1, x2y2), dim) # 拼接后形状(1,8400,4)下面通过一个具体的例子来说明 dist2bbox 函数的作用和实现细节。
1. 定义变量
我们假设以下参数:
distance 是一个张量,表示边界框的左、上、右、下距离(ltrb),形状为 (4, 4):
distance = torch.tensor([
[2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, 4.0],
[3.0, 4.0, 5.0, 6.0],
[4.0, 5.0, 6.0, 7.0]
])
anchor_points 是一个张量,表示锚点坐标(中心点),形状为 (4, 2):
anchor_points = torch.tensor([
[10.0, 10.0],
[20.0, 20.0],
[30.0, 30.0],
[40.0, 40.0]
])
xywh = True:表示输出格式为 xywh(中心坐标 + 宽高)。
dim = -1:表示沿最后一个维度操作。
2. 分割距离张量
lt, rb = distance.chunk(2, dim)
distance.chunk(2, dim):将 distance 沿 dim 维度分割成两部分,lt 表示左上距离,rb 表示右下距离。
lt:形状为 (4, 2),表示左上距离:
lt = torch.tensor([
[2.0, 3.0],
[1.0, 2.0],
[3.0, 4.0],
[4.0, 5.0]
])
rb:形状为 (4, 2),表示右下距离:
rb = torch.tensor([
[4.0, 5.0],
[3.0, 4.0],
[5.0, 6.0],
[6.0, 7.0]
])
3. 计算边界框坐标
x1y1 = anchor_points - lt
x2y2 = anchor_points + rb
x1y1:左上角坐标,形状为 (4, 2):
x1y1 = torch.tensor([
[10.0 - 2.0, 10.0 - 3.0] = [8.0, 7.0],
[20.0 - 1.0, 20.0 - 2.0] = [19.0, 18.0],
[30.0 - 3.0, 30.0 - 4.0] = [27.0, 26.0],
[40.0 - 4.0, 40.0 - 5.0] = [36.0, 35.0]
])
结果:
x1y1 = torch.tensor([
[8.0, 7.0],
[19.0, 18.0],
[27.0, 26.0],
[36.0, 35.0]
])
x2y2:右下角坐标,形状为 (4, 2):
x2y2 = torch.tensor([
[10.0 + 4.0, 10.0 + 5.0] = [14.0, 15.0],
[20.0 + 3.0, 20.0 + 4.0] = [23.0, 24.0],
[30.0 + 5.0, 30.0 + 6.0] = [35.0, 36.0],
[40.0 + 6.0, 40.0 + 7.0] = [46.0, 47.0]
])
结果:
x2y2 = torch.tensor([
[14.0, 15.0],
[23.0, 24.0],
[35.0, 36.0],
[46.0, 47.0]
])
4. 计算中心坐标和宽高
c_xy = (x1y1 + x2y2) / 2
wh = x2y2 - x1y1
c_xy:中心坐标,形状为 (4, 2):
c_xy = torch.tensor([
[(8.0 + 14.0)/2, (7.0 + 15.0)/2] = [11.0, 11.0],
[(19.0 + 23.0)/2, (18.0 + 24.0)/2] = [21.0, 21.0],
[(27.0 + 35.0)/2, (26.0 + 36.0)/2] = [31.0, 31.0],
[(36.0 + 46.0)/2, (35.0 + 47.0)/2] = [41.0, 41.0]
])
wh:宽高,形状为 (4, 2):
wh = torch.tensor([
[14.0 - 8.0, 15.0 - 7.0] = [6.0, 8.0],
[23.0 - 19.0, 24.0 - 18.0] = [4.0, 6.0],
[35.0 - 27.0, 36.0 - 26.0] = [8.0, 10.0],
[46.0 - 36.0, 47.0 - 35.0] = [10.0, 12.0]
])
5. 返回结果
return torch.cat((c_xy, wh), dim) # xywh bbox
torch.cat((c_xy, wh), dim):将中心坐标和宽高沿最后一个维度拼接,生成形状为 (4, 4) 的张量。
结果:
torch.cat((c_xy, wh), dim=-1) = torch.tensor([
[11.0, 11.0, 6.0, 8.0],
[21.0, 21.0, 4.0, 6.0],
[31.0, 31.0, 8.0, 10.0],
[41.0, 41.0, 10.0, 12.0]
])