LLaVA-OneVision: Easy Visual Task Transfer
-
原文摘要
-
研究背景与目标
-
开发动机:
- 基于LLaVA-NeXT博客系列对数据、模型和视觉表征的探索,团队整合经验开发了开源大型多模态模型 LLaVA-OneVision。
-
核心目标:
- 突破现有开源LMM的局限,实现单一模型在三大计算机视觉场景(单图像、多图像、视频)中的高性能表现。
-
关键创新点
-
多场景统一建模:
- 首次实现单一模型在单图像理解、多图像推理和视频理解任务上的全面领先。
-
跨模态迁移学习:
- 模型设计强调模态间知识迁移(如图像到视频),通过共享表征学习,无需针对不同场景单独训练模型。
- 这种设计催生了新兴能力,例如从图像任务中学习到的知识可直接提升视频理解性能。
-
-
-
1. Introduction
-
研究背景与目标
-
AI发展目标:
- 构建 通用多模态助手(General-purpose assistants)是AI领域的核心追求,大型多模态模型(LMM)是实现这一目标的关键技术。
-
LLaVA系列定位:
- LLaVA-OneVision是开源模型,延续了LLaVA系列的研究路线,旨在开发能通过多样化指令完成复杂计算机视觉任务的视觉-语言助手。
-
-
LLaVA系列演进
-
LLaVA初代模型:
- 展示了强大的多模态对话能力,在未见过图像和指令上表现出与GPT-4V相似的行为。
-
LLaVA-1.5:
- 通过纳入更多学术相关指令数据(academic-related instruction data),显著提升能力,在数十个基准测试中达到SOTA性能,且保持数据高效性。
-
LLaVA-NeXT:
- 继承前代优势,通过三项关键技术进一步突破性能边界:
- AnyRes:处理高分辨率图像;
- 扩展高质量指令数据;
- 使用当时最优开源LLM。
- 继承前代优势,通过三项关键技术进一步突破性能边界:
-
-
LLaVA-NeXT的探索
- 原型特性:LLaVA-NeXT提供可扩展和可伸缩的原型,支持多项并行探索:
-
Video blog:
- 发现仅用图像训练的LLaVA-NeXT模型通过零样本模态迁移(zero-shot modality transfer)在视频任务中表现优异,归因于AnyRes将视觉信号处理为图像序列的能力。
-
Stronger blog:
- 验证LLM规模扩展的有效性,仅增大LLM规模即可在部分基准上媲美GPT-4V。
-
Ablation blog:
- 总结除视觉指令数据外的实证探索,包括架构选择(LLM和视觉编码器规模)、视觉表征(分辨率与token数量)、训练策略(可训练模块与高质量数据)。
-
Interleave blog:
- 提出在多图像、多帧(视频)和多视角(3D)新场景中扩展能力的策略,同时保持单图像性能。
-
探索:这些研究在固定计算预算内进行,旨在提供项目推进中的实用见解,而非单纯追求性能极限。
-
- 原型特性:LLaVA-NeXT提供可扩展和可伸缩的原型,支持多项并行探索:
-
LLaVA-OneVision的开发与贡献
-
数据积累与实验:
- 作者团队花了6个月时间,积累并筛选了大量高质量数据集。
- 通过整合前述见解,并在新数据集上执行“yolo run”实验(未对单个组件充分去风险),推出LLaVA-OneVision。
-
模型特点:
- 在现有计算资源下实现,为后续通过数据和模型规模扩展提升能力留有空间。
-
论文贡献总结:
- 大型多模态模型:
- 开发LLaVA-OneVision模型,在单图像、多图像和视频三大视觉场景中提升开源LMM性能边界。
- 任务迁移的新兴能力:
- 通过建模和数据表征设计实现跨场景任务迁移,例如从图像到视频的迁移学习,展现强大的视频理解能力。
- 开源资源:
- 公开多模态指令数据、代码库、模型检查点和视觉聊天演示,推动通用视觉助手发展。
- 大型多模态模型:
-
2. Related Work
-
专有模型与开源模型的现状对比
-
专有LMM的领先性:
- GPT-4V 、GPT-4o 、Gemini 、Claude-3.5 等闭源模型在单图像、多图像和视频场景中均表现卓越,展现了通用多模态能力。
-
开源研究的局限性:
- 单图像场景主导:多数开源工作仅聚焦单图像任务性能提升。
- 多图像探索初期:少数近期研究开始探索多图像场景,但覆盖不足。
- 视频与图像的权衡:现有视频LMM往往以牺牲图像性能为代价优化视频理解,缺乏三场景统一的开放模型。
-
LLaVA-OneVision的定位:
- 旨在填补上述空白,首次实现单一开源模型在三大场景中的SOTA性能,并通过跨场景任务迁移(如图像→视频)展现新兴能力。
-
-
多场景统一模型的早期工作
-
LLaVA-NeXT-Interleave:
- 首次在单图像、多图像和视频三场景中均报告良好性能,LLaVA-OneVision继承其训练方案与数据并进一步优化。
-
其他潜力模型:
- VILA 和 InternLM-XComposer-2.5 虽具备多场景潜力,但未完整评估三场景性能。
-
-
数据策略与知识来源
- 高质量数据的关键作用:
- 模型合成知识:继承LLaVA-NeXT中的知识学习数据。
- 指令调优数据:
- 受 FLAN启发,采用小规模但精细筛选的数据集(与Idefics2、Cambrian-1同期收集但更注重质量)。
- 结论与同行一致:大量视觉指令数据显著提升性能,但LLaVA-OneVision更强调数据质量而非单纯规模。
- 高质量数据的关键作用:
-
LMM设计选择的参考研究
- 相关系统性研究:
- 论文引用近期工作对LMM架构、训练策略的探索,包括:
- 视觉编码器与LLM的连接方式
- 视觉表征(分辨率、token数量)优化
- 数据扩展与模型缩放的影响
- 论文引用近期工作对LMM架构、训练策略的探索,包括:
- 相关系统性研究:
3. Modeling
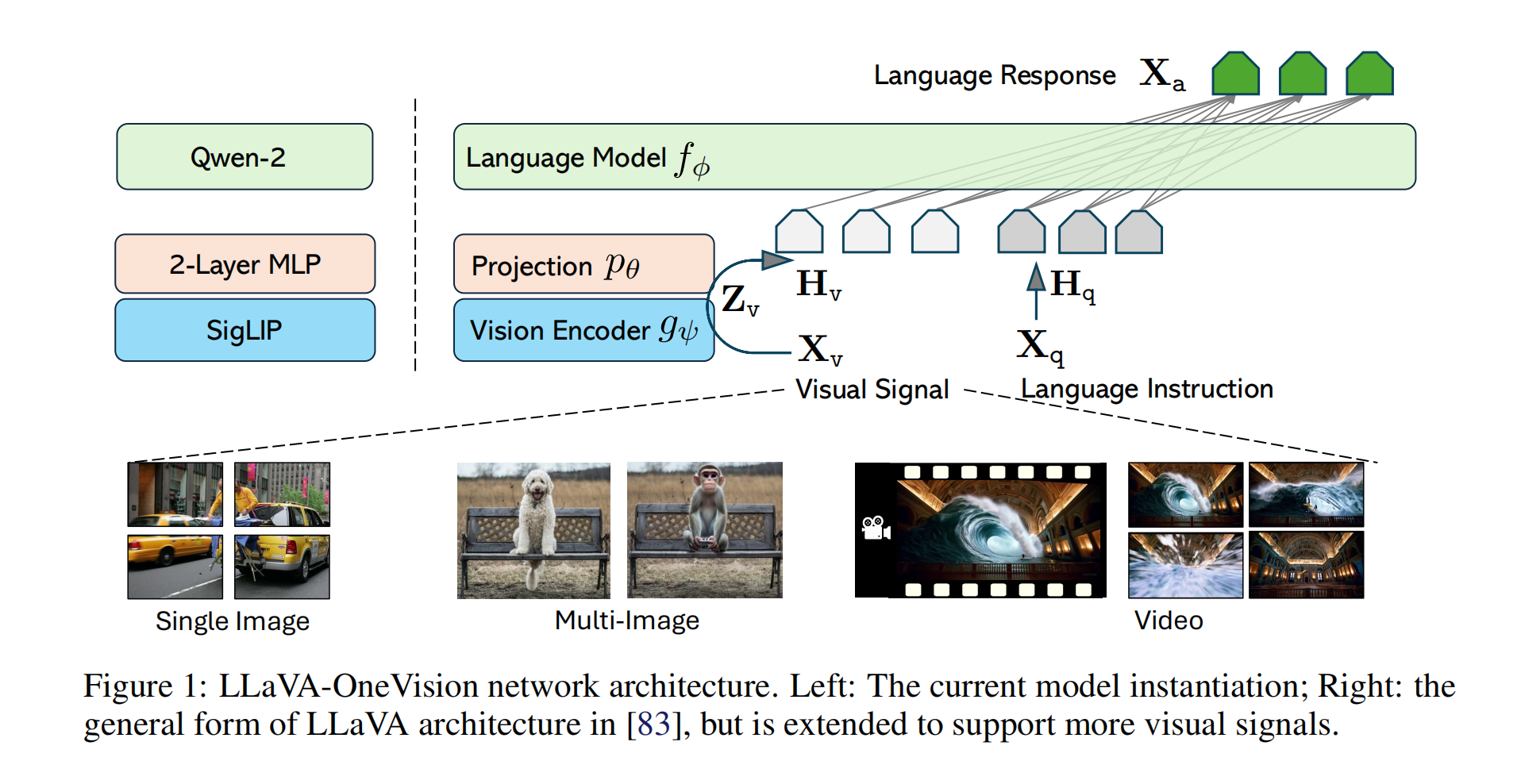
3.1 Network Architecture
-
整体设计原则
- 继承LLaVA系列的极简主义:
- 核心目标:
- 高效利用预训练能力:充分结合LLM与视觉模型的预训练知识。
- 支持数据与模型的强扩展性:确保架构在数据和模型规模增大时性能稳定提升。
- 核心目标:
- 继承LLaVA系列的极简主义:
-
核心组件
-
大型语言模型(LLM)
-
模型选择:
- 采用 Qwen-2 作为语言模型 f ϕ ( ⋅ ) f_\phi(\cdot) fϕ(⋅)(参数为 ϕ \phi ϕ)。
-
选择理由:
- 公开模型中的最优语言能力:在开源检查点中表现最强。
- 多尺寸支持:提供不同参数规模的版本,便于灵活扩展(更强的LLM直接提升多模态能力)。
-
视觉编码器(Vision Encoder)
-
模型选择:
- 使用 SigLIP 作为视觉编码器 g ψ ( ⋅ ) g_\psi(\cdot) gψ(⋅)(参数为 ψ \psi ψ),将输入图像 X v X_v Xv 编码为视觉特征 Z v = g ( X v ) Z_v = g(X_v) Zv=g(Xv)。
-
特征提取策略:
- 同时利用最后一层Transformer之前和之后的网格特征(grid features),以保留不同层级的视觉信息。
-
-
投影器(Projector)
- 结构设计:
- 采用 2层MLP p θ ( ⋅ ) p_\theta(\cdot) pθ(⋅)(参数为 θ \theta θ ),将视觉特征 Z v Z_v Zv 投影到LLM的词嵌入空间,生成视觉token序列 H v = p ( Z v ) H_v = p(Z_v) Hv=p(Zv)。
- 结构设计:
-
-
-
输入输出建模
-
概率计算形式化
-
序列生成公式:
-
对于长度为 L L L 的答案序列 X a X_a Xa,其条件概率为:
p ( X a ∣ X v , X q ) = ∏ i = 1 L p ( x i ∣ X v , X q , < i , X a , < i ) p(X_a | X_v, X_q) = \prod_{i=1}^L p(x_i | X_v, X_{q, <i}, X_{a, <i}) p(Xa∣Xv,Xq)=i=1∏Lp(xi∣Xv,Xq,<i,Xa,<i) -
其中:
- X q , < i X_{q, <i} Xq,<i 和 X a , < i X_{a, <i} Xa,<i 分别表示当前预测token x i x_i xi 之前的所有指令token和答案token。
- **显式引入 X v X_v Xv **:强调所有答案均需基于视觉信号(即视觉特征始终参与解码)。
-
-
-
视觉输入泛化性
- 多场景适配:
- 视觉编码器的输入
X
v
X_v
Xv 形式具有通用性,具体取决于任务场景:
- 单图像:individual image crop。
- 多图像:individual image in a sequence。
- 视频:individual frame in a video sequence。
- 技术实现:通过AnyRes(见3.2节)统一处理不同分辨率和模态的输入。
- 视觉编码器的输入
X
v
X_v
Xv 形式具有通用性,具体取决于任务场景:
- 多场景适配:
-
3.2 Visual Representations
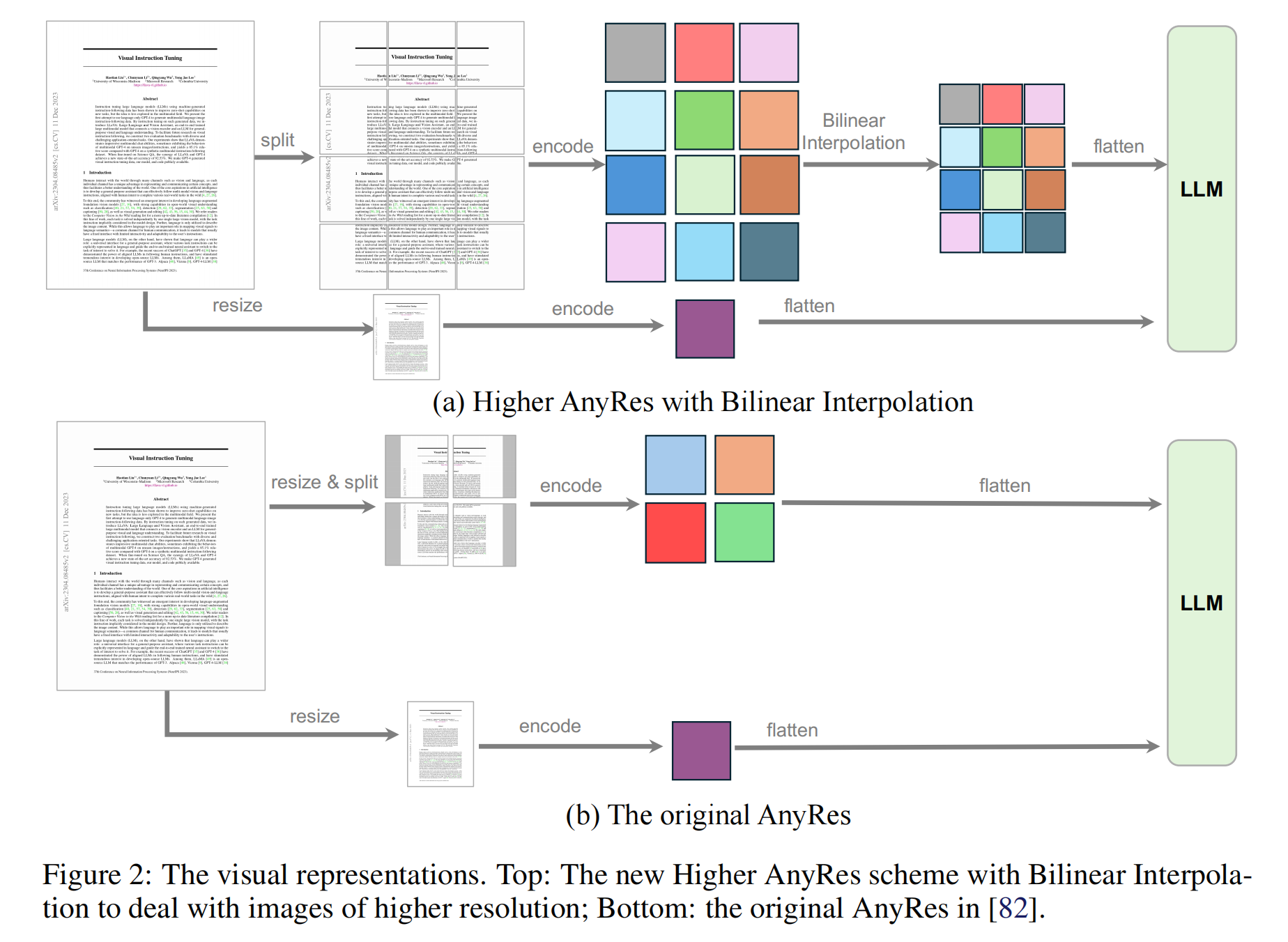
-
视觉表征的核心要素
-
关键因素:视觉信号的表征质量取决于两个变量:
- 原始像素空间的分辨率(resolution)
- 特征空间的token数量(#token)
- 二者共同构成视觉输入表征配置 (resolution, #token)。
-
性能规律:
- 二者规模扩大均可提升性能(尤其依赖视觉细节的任务),但分辨率缩放比token数量更有效。
- 平衡性能与成本:推荐采用带池化的AnyRes策略。
-
-
AnyRes技术实现
- 基础机制
-
图像分块处理:
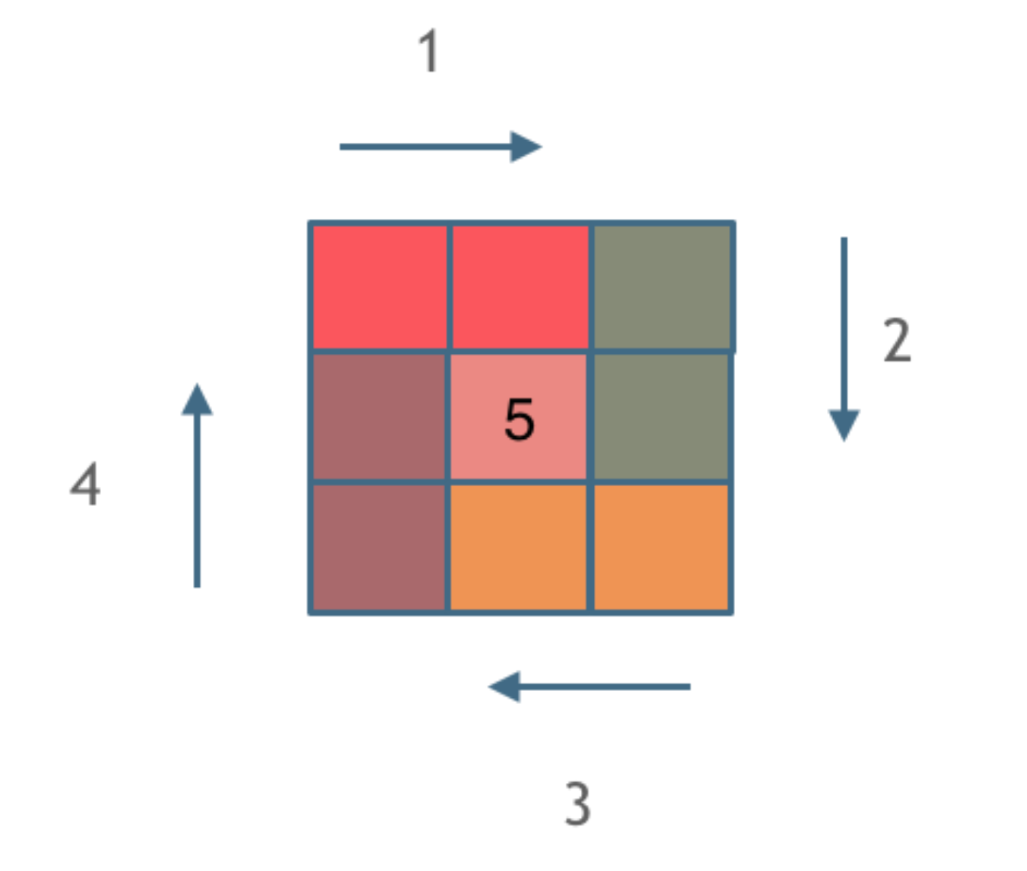
- 对宽高为 (a, b) 的AnyRes配置,图像被划分为 a × b个裁剪块(crops),每块形状为 (a, b)。
- 每块裁剪保持视觉编码器适配的统一分辨率。(如上图F2)
-
Token计算:
- 每裁剪块生成 T个token,总视觉token数 L = ( a × b + 1 ) × T L = (a \times b + 1) \times T L=(a×b+1)×T(+1对应基础图像resize后的全局特征)。
-
动态Token压缩:
- 设定阈值
τ
\tau
τ,若
L
>
τ
L > \tau
L>τ 则按照如下公式压缩每块token数(必要时使用双线性插值):
T new = { τ a × b + 1 if L > τ T if L ≤ τ T_{\text{new}} = \begin{cases} \frac{\tau}{a \times b + 1} & \text{if } L > \tau \\ T & \text{if } L \leq \tau \end{cases} Tnew={a×b+1τTif L>τif L≤τ
- 设定阈值
τ
\tau
τ,若
L
>
τ
L > \tau
L>τ 则按照如下公式压缩每块token数(必要时使用双线性插值):
-
- 基础机制
-
空间配置优化
-
多配置适应:
- 定义一组空间配置 (a, b) 以支持不同分辨率和长宽比的图像,优先选择需最少裁剪数的配置。
-
Higher AnyRes框架:
-
作为灵活表征框架,可适配多图像和视频场景,通过调整配置平衡性能与成本(如下图F3)。

-
-
-
多场景表征策略
-
单图像场景
-
高分辨率保留:
- 采用最大空间配置 (a, b),避免原始图像resize导致信息损失。
-
长序列token分配:
- 每图像分配大量视觉token,生成长序列以充分表征细节。
-
设计动机:
- 图像的高质量训练样本远多于视频,通过模仿视频的长序列表征,促进图像到视频的能力迁移。
-
-
多图像场景
- 资源优化:
- 仅将基础分辨率图像输入视觉编码器获取特征图,避免高分辨率多裁剪,节省计算资源。
- 资源优化:
-
视频场景
-
帧处理:
- 每帧resize为基础分辨率,经视觉编码器生成特征图。
-
Token-帧数权衡:
- 使用双线性插值减少每帧token数,从而支持更多帧处理,实现性能与成本的更好平衡。
-
-
-
实验设计与扩展性
-
固定计算预算下的设计:
- 当前配置针对跨场景能力迁移优化,在有限算力下最大化多模态性能。
-
算力扩展潜力:
- 若计算资源增加,可提升训练/推理时的每图像(帧)token数以进一步突破性能边界。
-
4. Data
- MLLM训练中采用"质量优于数量"的准则。这一原则之所以关键,源于预训练LLM和视觉Transformer(ViT)中已存储的广博知识。
- 当新的高质量数据可用时,需持续让模型接触这些数据以进行知识补充。
- 本节将探讨高质量知识学习与视觉指令调优的数据来源及策略。
4.1 High-Quality Knowledge
-
核心问题与解决思路
-
低质量数据的局限性:
- 公开网络规模的图像-文本数据(web-scale public image-text data)通常质量低下,导致多模态预训练的数据扩展效率不足。
-
高质量知识学习的必要性:
- 在有限计算预算下,应优先利用预训练LLM和ViT已有的庞大知识库,通过精选数据对其进行精细化增强,而非盲目扩大数据规模。
-
-
高质量知识数据的三大来源
-
重新标注的详细描述数据
-
生成方法:
- 使用当前最强的开源LMM LLaVA-NeXT-34B对以下数据集图像重新生成描述:
- COCO118K
- BLIP558K
- CC3M
- 合并形成350万样本的新数据集。
- 使用当前最强的开源LMM LLaVA-NeXT-34B对以下数据集图像重新生成描述:
-
技术意义:
- 这是self-improvement AI的初步尝试:早期模型生成的数据用于训练后续版本。
-
-
文档/OCR数据
-
构成:
- UReader数据集的文本阅读子集(10万样本):通过PDF渲染获取易处理的文本数据。
- SynDOG EN/CN:合成文档-图像对数据。
- 合并形成110万样本的文档OCR数据集。
-
应用价值:
- 增强模型对文本密集型图像(如扫描文档、海报)的理解能力。
-
-
中文与多语言数据(Chinese and Language Data)
-
中文能力优化:
- 基于ShareGPT4V 原始图像,调用Azure API的GPT-4V生成9.2万条中文详细描述。
-
语言平衡性:
- 从Evo-Instruct 收集14.3万样本,防止模型因过度依赖描述数据而弱化基础语言理解能力。
-
-
-
合成数据的优势与趋势
-
数据构成比例:
- 99.8%的高质量知识数据为合成生成(synthetic data)。
-
合成数据的必然性:
- 成本与版权:真实世界大规模高质量数据收集成本高且受版权限制。
- 可扩展性:合成数据可快速生成且规模可控(如通过GPT-4V生成描述)。
-
行业趋势:
- 随着AI模型能力提升,从大规模合成数据中学习将成为主流范式。
-
4.2 Visual Instruction Tuning Data
-
视觉指令调优的定义与目标
-
概念:
- Visual Instruction Tuning指 MLLM 理解并执行结合视觉媒体(图像/视频)与语言指令的任务,通过整合视觉理解与自然语言处理生成响应。
-
技术目标:
- 使模型能处理开放式指令,而非局限于预定义任务。
-
-
数据收集与分类框架
-
数据来源
- 基础策略:
- 从多样化原始来源收集非平衡比例数据(unbalanced data ratio),结合Cauldron和Cambrian的新子集。
- 高质量维护:延续LLaVA-1.5 等研究结论,强调数据质量对LMM能力的决定性作用。
- 基础策略:
-
三级分类体系
-
视觉输入(Vision Input):
- 按模态分为三类:
- 单图像(Single-image)
- 多图像(Multi-image)
- 视频(Video)
- 按模态分为三类:
-
语言指令(Language Instruction):
-
五大任务类型:
类别 示例任务 技能目标 General QA 图像问答 基础视觉理解 General OCR 文字识别 文本-视觉对齐 Doc/Chart/Screen 文档解析 结构化数据理解 Math Reasoning 数学推理 多模态逻辑推理 Language 多语言描述 跨语言泛化
-
-
语言响应(Language Response):
-
自由形式(Free-form):由GPT-4V/Gemini等生成开放式答案
-
固定形式(Fixed-form):源自学术数据集(如VQAv2、GQA),需人工校正格式
-
-
-
-
数据处理关键步骤
- 对固定形式数据(如多选题),采用LLaVA-1.5提示策略,确保答案格式一致性,避免多源数据冲突。
-
两组训练数据
-
Single-Image Data
-
规模:320万样本
-
平衡策略:
- 从原始数据中筛选各任务类型的代表性样本,避免数据倾斜。
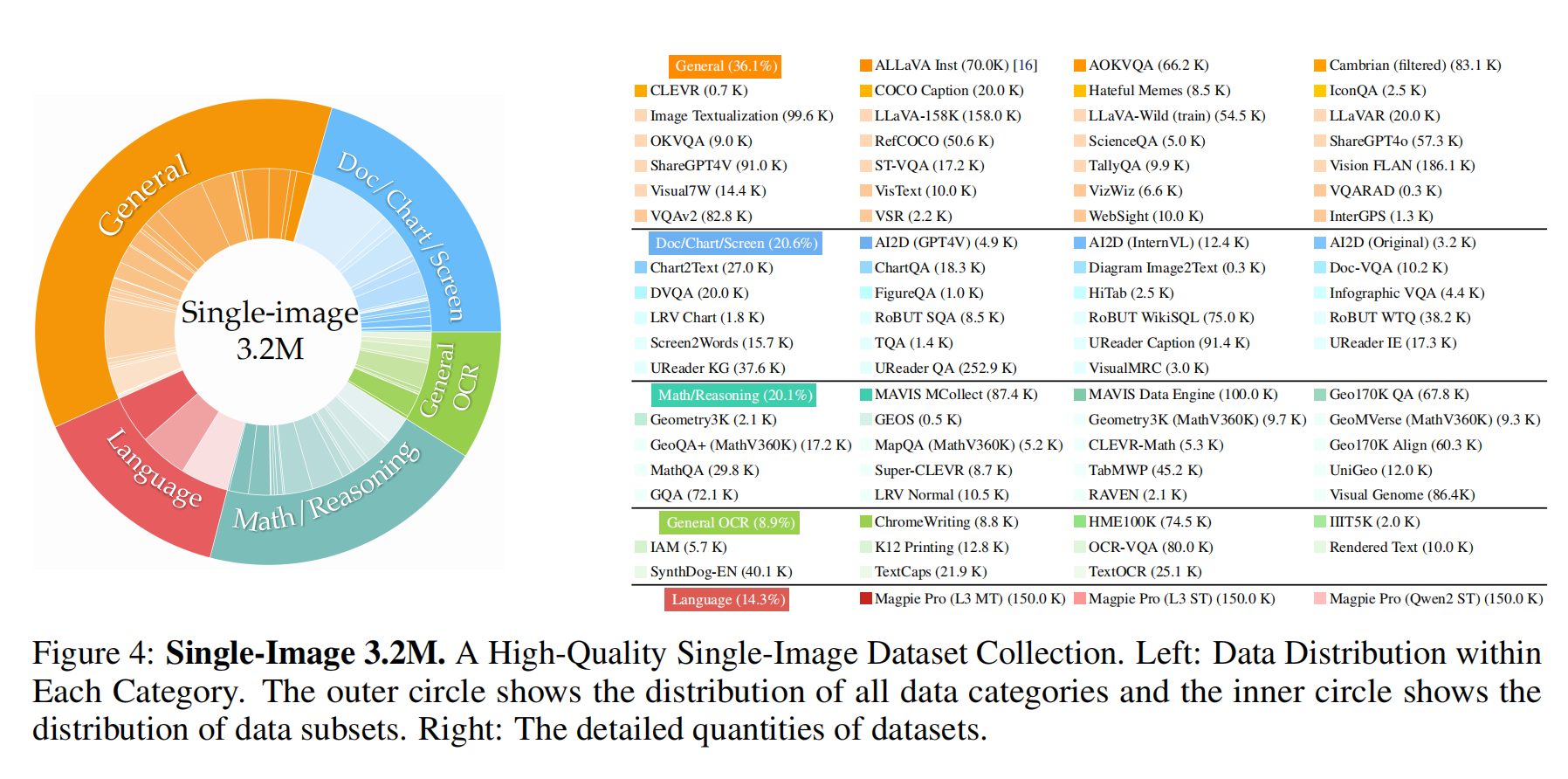
-
-
多模态混合数据(OneVision Data)
- 构成:160万样本
- 多图像:56万
- 视频:35万
- 单图像:80万
- 训练逻辑:
- 不引入新单图像数据,而是复用前期已优化数据,专注于多模态对齐。

- 构成:160万样本
-
5. Training Strategies
-
三阶段课程学习框架
-
设计理念
-
功能解耦:将多模态能力分解为三个关键功能模块,分阶段训练以支持消融研究。
-
Curriculum Learning:
- 采用由易到难的训练策略,在固定计算预算下分阶段生成可复用的模型检查点。
-
-
-
阶段详解
-
Stage-1: 语言-图像对齐
-
技术实现:
- 冻结视觉编码器(SigLIP)和LLM(Qwen-2),仅训练2层MLP投影器。
- 使用基础分辨率图像(729 tokens),避免高计算开销。
-
作用: 建立视觉特征与语言空间的基础映射关系,为后续阶段提供稳定的跨模态接口。
-
-
Stage-1.5: 高质量知识学习
-
数据策略:
- 采用4.1节所述的合成高质量数据(如Re-Captioned数据)。
-
训练配置:
-
解锁全模型参数,但视觉编码器学习率设为LLM的1/5(防止视觉特征被过度破坏)。
-
引入AnyRes技术,token数扩展至5倍(平衡计算成本与知识注入)。
-
-
Stage-2: 视觉指令调优
- 两阶段训练:
- 单图像训练(Single-Image Training):
- 使用320万单图像指令数据,覆盖问答/OCR/推理等任务。
- 目标:建立单图像多任务泛化能力。
- 多模态混合训练(OneVision Training):
- 混合数据:56万多图像 + 35万视频 + 80万单图像(从前期数据重采样)。
- 目标:实现跨场景知识迁移(如图像→视频的零样本能力)。
- 单图像训练(Single-Image Training):
- 技术优化:
- token数扩展至10倍(AnyRes最大化),支持高分辨率输入。
- 保持视觉编码器低学习率(仍为LLM的1/5)。
- 两阶段训练:
-
-
关键训练配置
-
渐进式序列长度扩展
-
动态调整策略:
阶段 最大分辨率 Token数 设计意图 Stage-1 基础 729 低成本初始化对齐 Stage-1.5 中等 ~3,645 平衡知识学习与计算开销 Stage-2 高 ~7,290 支持复杂多模态任务
-
-
理论依据: 逐步增加token数比一次性高分辨率训练更稳定。
-
-
参数更新策略
- 差异化学习:
- 投影器:Stage-1全程训练,后续阶段微调。
- 视觉编码器:Stage-1冻结,Stage-1.5/2以**低学习率(LLM的1/5)**更新,保护预训练特征。
- LLM:Stage-1.5/2全参数微调,激发语言侧多模态适配能力。
- 差异化学习:
-
与现有方法的对比
-
vs 传统端到端训练:
- 传统方法(如Flamingo)联合优化所有模块,易导致模态对齐不稳定。
- LLaVA分阶段策略解耦对齐-知识-泛化,更适配有限算力场景。
-
vs 其他开源LMM:
- VILA 仅聚焦单阶段指令调优,缺乏系统性课程设计。
-
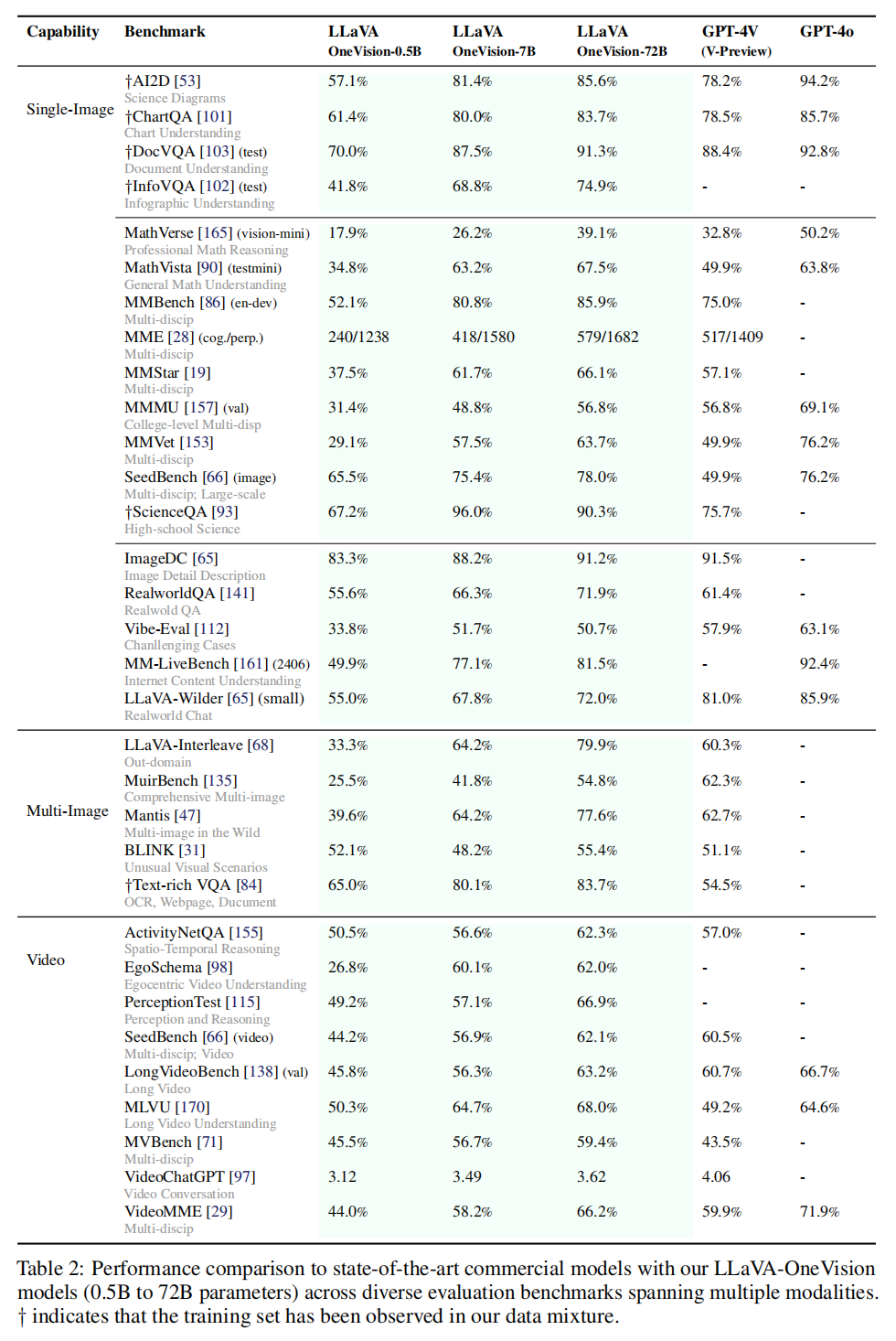
6. Experimental Results
7. Emerging Capabilities with Task Transfer
-
图表联合理解S1
- 模型能够同时理解图表(chart)与示意图(diagram)的组合,尽管训练数据中仅包含单图像图表或示意图任务。
-
GUI操作指导S2
- 通过识别iPhone截图(单图像),生成操作指令,结合OCR与多图像关系推理能力。
-
标记集推理S3
- 首次在开源LMM中实现Set-of-Marks(SoM)推理(如根据图像中的箭头/圆圈标记回答问题),该能力未显式包含于训练数据。
-
图像到视频编辑指令S4
- 根据静态图像生成视频创作提示(如角色动作、场景转换),结合单图像编辑与视频描述任务的知识。
-
视频差异分析S5
- 对比同起点不同结局的两段视频,或同背景不同前景物体的视频,输出细节差异描述。
-
多视角自动驾驶视频理解S6
- 分析四摄像头同步拍摄的自动驾驶视频,描述各视角内容并规划车辆动作。
-
复合子视频理解S7
- 理解垂直分屏视频(如背景一致、前景人物变化的双场景视频),分析布局与叙事(如表13)。
-
视频中的视觉提示理解S8
- 识别视频中半透明圆圈标记的区域,该能力源自单图像视觉提示训练,未使用视频标记数据。
-
视频理解中的图像参照S9
- 回答视频问题时参照外部图像查询,该能力未在LLaVA-NeXT/Interleave中出现。





![[Vue]路由基础使用和路径传参](https://i-blog.csdnimg.cn/direct/afe6ca0f8a054d7a87905ab6ffc410c0.png)