知识点回归:
- CPU性能的查看:看架构代际、核心数、线程数
- GPU性能的查看:看显存、看级别、看架构代际
- GPU训练的方法:数据和模型移动到GPU device上
- 类的call方法:为什么定义前向传播时可以直接写作self.fc1(x)
①CPU性能查看 :
- 架构代际: cat /proc/cpuinfo 查看型号和flags
- 核心/线程数: lscpu 或Python中 os.cpu_count()
②GPU性能查看 :
import torch
print(torch.cuda.get_device_name(0)) # 型号
print(torch.cuda.get_device_capability(0)) # 计算能力
print(torch.cuda.get_device_properties(0).total_memory/1e9) # 显存(GB)③GPU训练方法 :
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Model().to(device)
data = data.to(device)④类的 __call__ 方法 :
- 当类实现 __call__ 时,实例可以像函数一样调用
- self.fc1(x) 有效是因为PyTorch的 nn.Module 实现了 __call__ ,其内部会调用 forward()
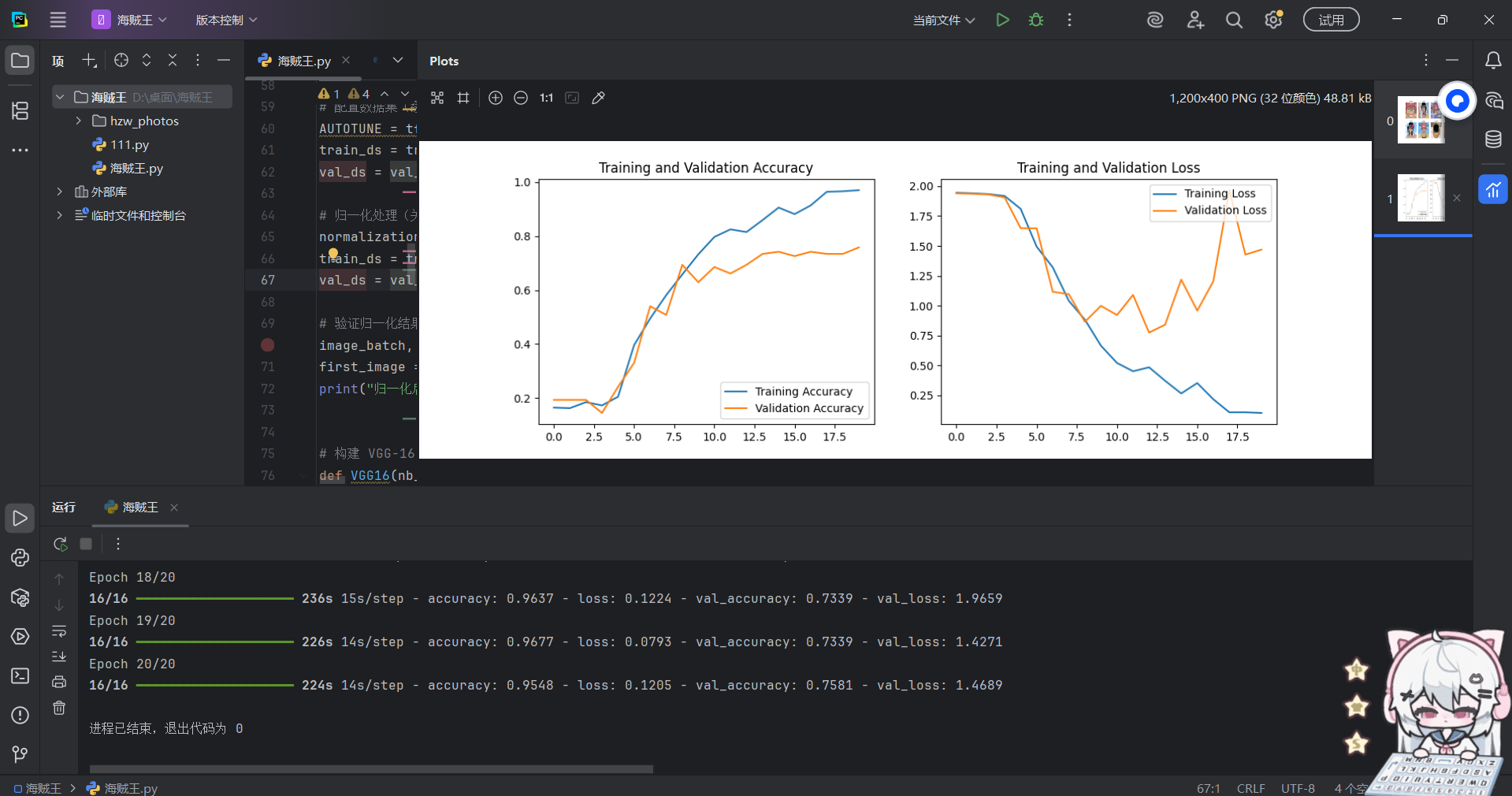
实验现象解释:
一、GPU-CPU交互特性 :
- loss.item() 确实需要同步,但现代GPU有:
- 异步执行能力(计算和传输可重叠)
- 并行流水线(下一个计算可提前开始)
二、瓶颈分析 :
# 典型训练循环中的时间分布
for epoch in range(epochs):
# 数据加载时间(CPU) ← 常被忽视的瓶颈
# GPU计算时间
# 同步记录时间(约0.1-1ms/次)
# 其他开销(梯度清零等)三、实验数据解读 :
- 记录次数从200→10次(20倍变化),但时间仅差0.69秒(6.6%)
- 说明:
- 记录操作本身耗时占比极小(<1ms/次)
- 主要时间消耗在数据加载和GPU计算
四、验证方法建议 :
# 精确测量记录操作耗时
import time
record_times = []
for _ in range(1000):
start = time.perf_counter()
losses.append(loss.item()) # 测试单次记录耗时
record_times.append(time.perf_counter() - start)
print(f"平均记录耗时:{sum(record_times)/len(record_times)*1e6:.2f}微秒")




![[Vue]路由基础使用和路径传参](https://i-blog.csdnimg.cn/direct/afe6ca0f8a054d7a87905ab6ffc410c0.png)