一、技术背景与需求分析
我们日常在使用AI的时候一定都上传过文件,AI会根据用户上传的文件内容结合用户的请求进行分析,给出用户解答。但是这是怎么实现的呢?在我们开发自己的大模型应用时肯定是不可避免的要思考这个问题,今天我会将从文件上传开始到大模型给出分析的整个流程进行讲解
二、核心技术实现路径
在这里我先将整体的流程说一下:
前端文件上传 → 服务端接收文件 → 解析文件 → 生成唯一Id → 将文件存储(id:content)
| |
—————————————————存储id←———————————————
↓
用户发送请求 → 用户信息+文件id → 服务端接收请求 → 根据id获取文件内容 → 拼接用户消息和文件内容
↓
大模型分析
↓
返回响应1.文件上传于预处理
文件上传的前端部分我不再进行讲解,但是需要说明的是,在前端需要加上对文件的约束和校验,比如文件大小、文件格式等。
后端的编写上首先需要准备一个接口去接收文件。
在这个接口中实现的效果就是流程图中第一行的功能
@RequestMapping(value = "/upload", consumes = MediaType.MULTIPART_FORM_DATA_VALUE)
public UploadFileResultDto upload(@RequestPart("filedata") MultipartFile multipartFile) throws IOException {
if (multipartFile.getSize() > 1024 * 1024 * 10){
throw new RuntimeException("文件大小不能超过10M");
}
//解析文件
String content = fileParseService.parse(multipartFile);
//唯一id
String fileId = UUID.randomUUID().toString();
//存储文件
memoryStorage.save(fileId, content);
UploadFileResultDto uploadFileResultDto = new UploadFileResultDto();
uploadFileResultDto.setFileId(fileId);
return uploadFileResultDto;
}
解析文件类,这个的最佳实践是:通过一个工厂类检测文件类型,将不同文件类型的文件交给不同的解析工具类执行
我这里仅举一个例子,只包含解析txt文件的条件
public interface FileParseService {
String parse(MultipartFile file);
}
中专工厂
@Service
public class FileParseServiceImpl implements FileParseService {
@Override
public String parse(MultipartFile file) {
//根据文件类型解析文件
try {
if (Objects.equals(file.getContentType(), "text/plain")){
return new TxtFileParser().parse(file);
}
} catch (Exception e) {
throw new RuntimeException(e);
}
return null;
}
}
解析工具类
@Component
public class TxtFileParser {
public String parse(MultipartFile file) throws Exception {
StringBuilder Totalline;
try (BufferedReader reader = new BufferedReader(new InputStreamReader(file.getInputStream()))) {
Totalline = new StringBuilder();
Totalline.append("文件【").append(file.getOriginalFilename()).append("】:\n");
String line;
while ((line = reader.readLine()) != null) {
Totalline.append(line);
}
}
return Totalline.toString();
}
}当响应结束后,返回文件的内容,然后在controller中生成一个UUID
以UUID作为key文件内作为value,因为最终是要将文件信息以Map的格式保存
创建一个存储类,用于存储文件信息。
@Component
public class MemoryStorage {
//文件存储
private static final ConcurrentHashMap<String,String> storage = new ConcurrentHashMap<>();
//存储文件
public void save(String fileId, String content) {
storage.put(fileId, content);
System.out.println("文件存储成功"+fileId);
}
//获取文件
public String get(String fileId) {
return storage.get(fileId);
}
//删除文件
public void remove(String fileId) {
storage.remove(fileId);
System.out.println("文件删除成功"+fileId);
}
//清空所有文件
public void clear() {
storage.clear();
System.out.println("文件清空成功");
}
}
执行完这些后,文件的上传工作已经完成
此时前端会收到该文件的唯一Id,其会对这个id进行保存。
当用户发送消息时,会带着文件id的列表一并发送到服务器。
请求体:
@Data
public class GetRequest {
//消息
private String message;
.....其余属性
//文件列表
private List<String> fileIds;如果文件id列表不为空,服务端会从存储类中取得对应的文件内容
然后将文件内容和用户消息进行拼接
//用户消息
String userMessage = request.getMessage();
//文件内容->将用户消息和文件内容进行拼接
if (request.getFileIds() != null){
userMessage = formatFile(request.getFileIds()) + "【用户消息】:\n"+userMessage;
} @Autowired
private MemoryStorage memoryStorage;
public String formatFile(List<String> fileIds){
if (fileIds == null){
return null;
}
StringBuilder fileContent = new StringBuilder();
for (String fileId : fileIds){
String content = memoryStorage.get(fileId);
fileContent.append(content).append("\n");
}
return fileContent.toString();
}最终模型收到的用户消息类似于这样的格式:
文件【xxx】:
...
【用户消息】:
...使得模型能够区分文件内容和具体的指令并进行分析
这是我的实验效果

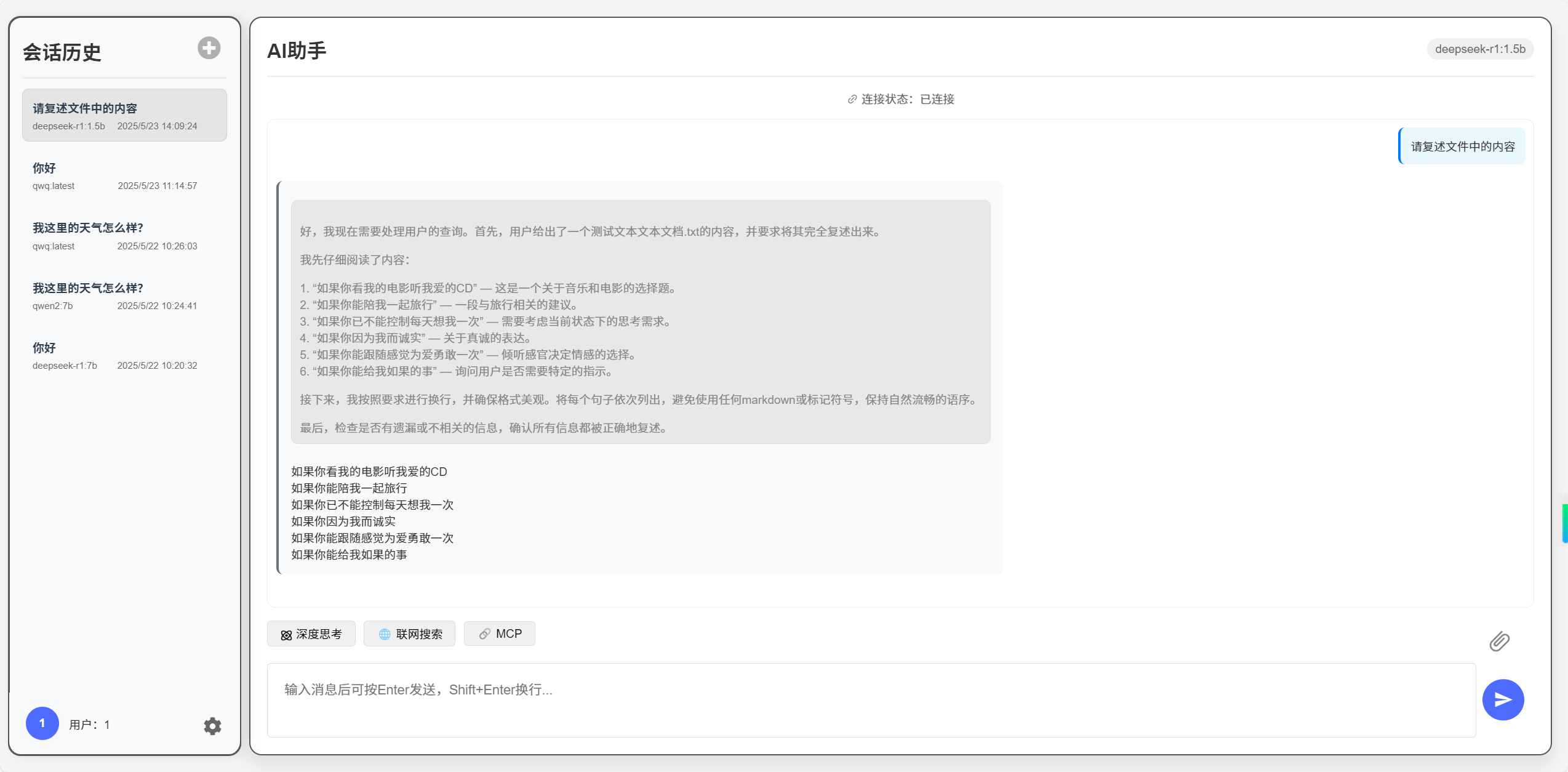
三.优化路线
模型对文件进行分析的操作,大致还会有以下的优化步骤
1.数据脱敏:对敏感信息进行屏蔽再进行分析+尽量在用户本地解析,当然这是针对商业化的需求
2.加密传输:对一些重要的信息和文件,在进行网络传输时需要对其进行加密操作
3.分块传输:一些大的文件一次性无法直接传输,需要进行分块
4.文件处理:在本文中我只介绍了文本文件的处理,这种是可以直接进行读取的,其他类型的文件 例如PDF、EXCEL等还需要进行拓展工具类。甚至是图片、视频、音频等都需要根 据不同的情况和技术选型选择不同的处理方案
开源项目参考
以上代码和技术实现都是根据我的开源项目进行的展示,大家需要详细的了解的可以访问下载我的项目,跪求点个star!!!
Local_Helper: 支持本地大模型的可视化应用