在本次实战中,我们通过Spark的RDD实现了词频统计功能。首先,准备了包含单词的文件并上传至HDFS。接着,采用交互式方式逐步完成词频统计,包括创建RDD、单词拆分、映射为二元组、按键归约以及排序等操作。此外,还通过创建Maven项目,配置依赖、添加Scala SDK、创建日志属性文件和HDFS配置文件,最终编写并运行Scala程序,实现了词频统计并将结果输出到HDFS。整个过程涵盖了从数据准备到程序开发和结果验证的完整流程,加深了对Spark RDD操作和分布式文件处理的理解。

3.8.1 利用RDD实现词频统计
news2026/5/3 14:32:49
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2384104.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
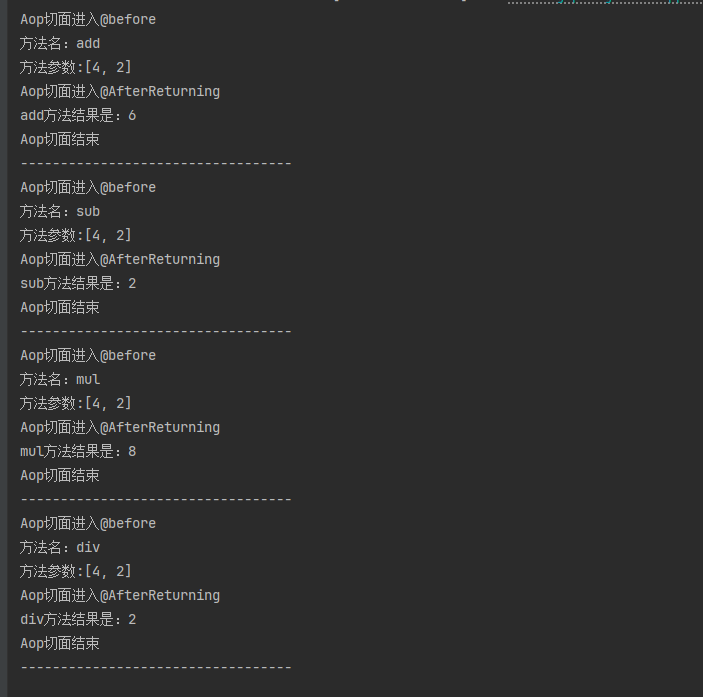
Spring Ioc和Aop,Aop的原理和实现案例,JoinPoint,@Aspect,@Before,@AfterReturning
DAY25.2 Java核心基础
Spring两大核心:Ioc和Aop
IOC
Ioc容器:装载bean的容器,自动创建bean
三种方式:
1、基于xml配置:通过在xml里面配置bean,然后通过反射机制创建bean,存入进Ioc容器中
…
![[解决conda创建新的虚拟环境没用python的问题]](https://i-blog.csdnimg.cn/direct/8a1fe22c2c0a44d7b72b83618a29c20c.png)
[解决conda创建新的虚拟环境没用python的问题]
问题复现
使用conda create -n env的时候,在对应的虚拟环境的文件里面找不到对应的python文件
为什么
首先,我们来看一下创建环境时的触发链路: 这表明当前环境中找不到Python可执行文件。
解决方法
所以很明显,我们需要指定…
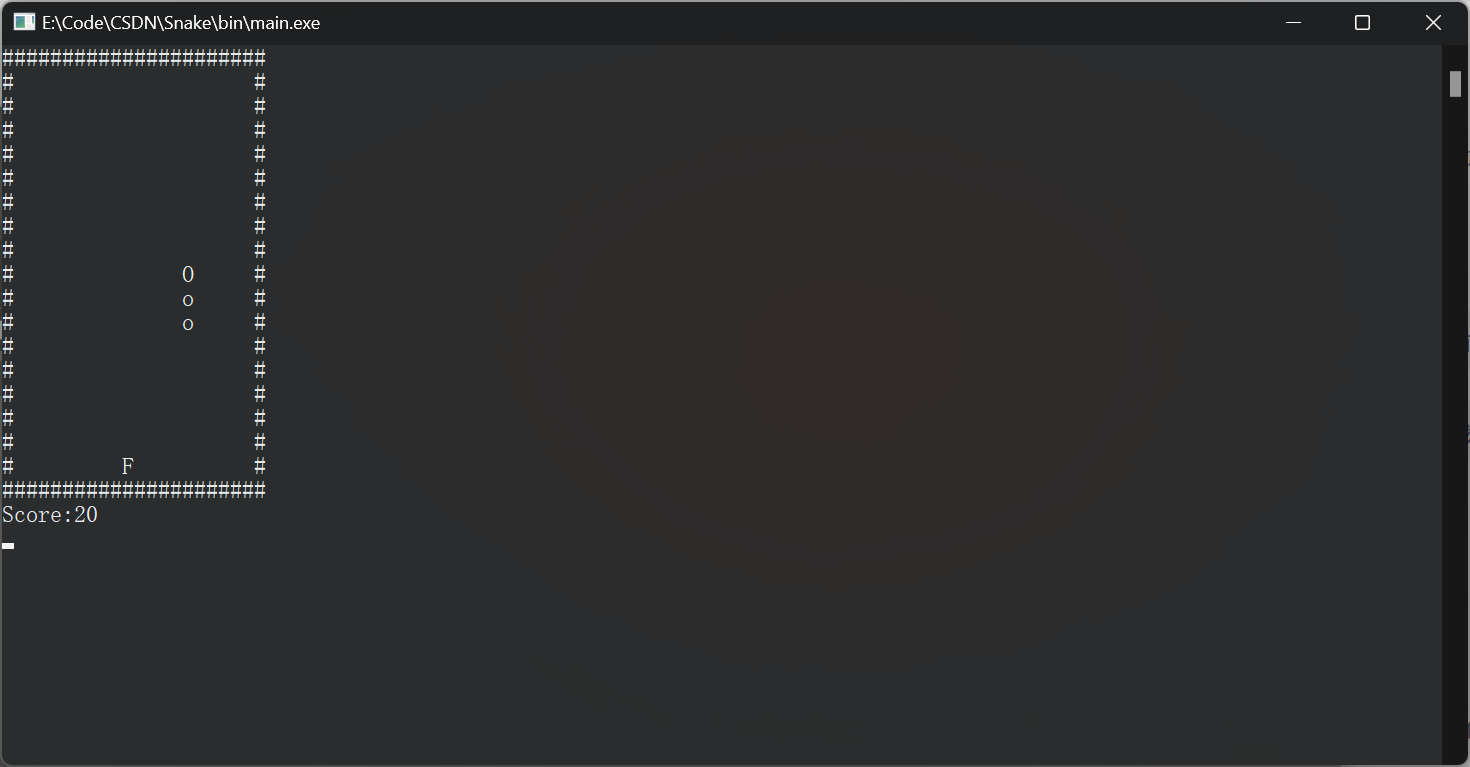
【C++】控制台小游戏
移动:W向上,S上下,A向左,D向右
程序代码:
#include <iostream>
#include <conio.h>
#include <windows.h>
using namespace std;bool gameOver;
const int width 20;
const int height 17;
int …

配合本专栏前端文章对应的后端文章——从模拟到展示:一步步搭建传感器数据交互系统
对应文章:进一步完善前端框架搭建及vue-konva依赖的使用(Vscode)-CSDN博客
目录
一、后端开发
1.模拟传感器数据
2.前端页面呈现数据后端互通
2.1更新模拟传感器数据程序(多次请求)
2.2🧩 功能目标
…

springboot IOC
springboot IOC IoC Inversion of Control
Inversion 反转
依赖注入 DI (dependency injection )
dependency 依赖 injection 注入
Qualifier 预选赛
一文带你快速理解JavaWeb中分层解耦的思想及其实现,理解 IOC和 DI https://zhuanlan.…
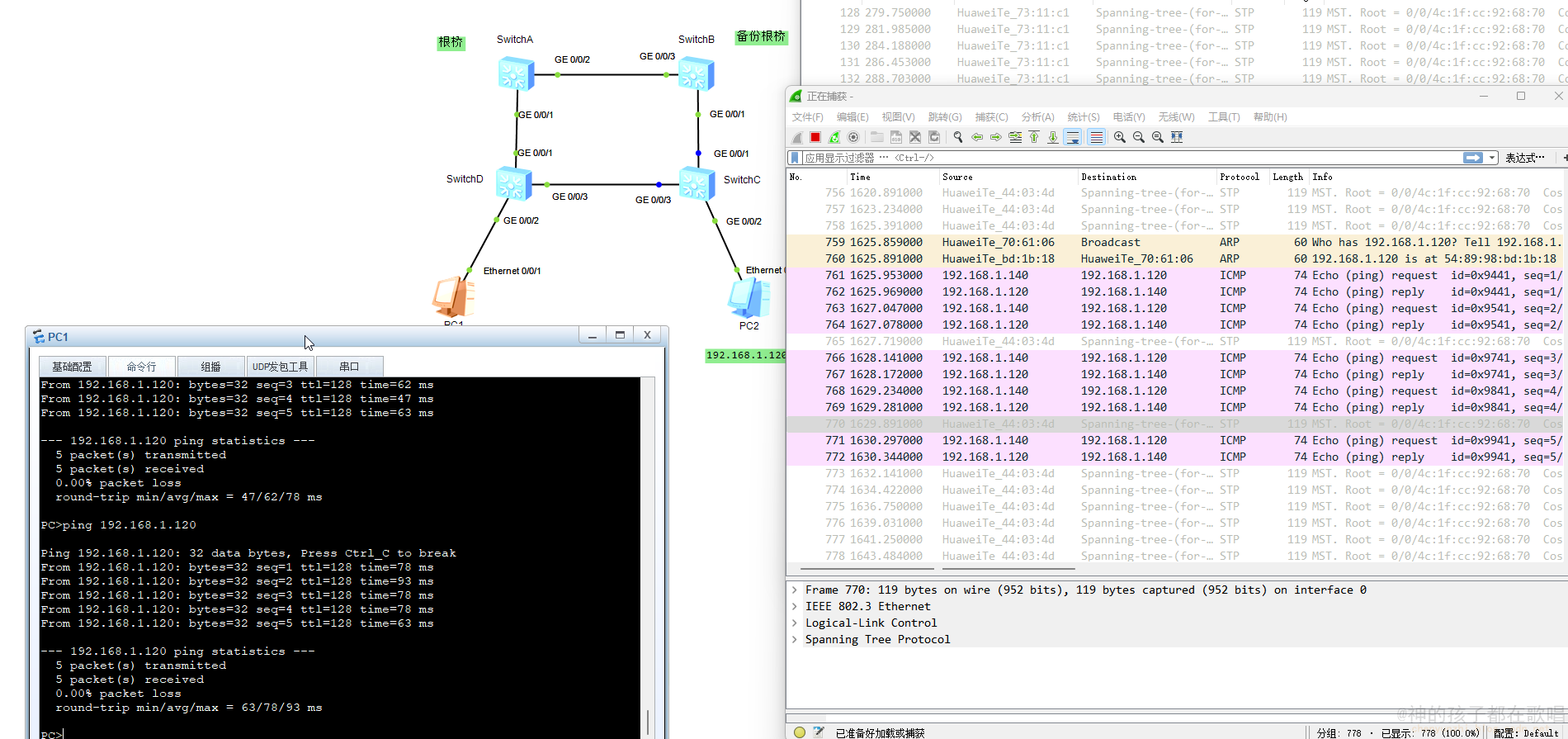
生成树协议(STP)配置详解:避免网络环路的最佳实践
生成树协议(STP)配置详解:避免网络环路的最佳实践 生成树协议(STP)配置详解:避免网络环路的最佳实践一、STP基本原理二、STP 配置示例(华为交换机)1. 启用生成树协议2. 配置根桥3. 查…

面向 C 语言项目的系统化重构实战指南
摘要: 在实际开发中,C 语言项目往往随着功能演进逐渐变得混乱:目录不清、宏滥用、冗余代码、耦合高、测试少……面对这样的“技术债积累”,盲目大刀阔斧只会带来更多混乱。本文结合 C 语言的特点,从项目评估、目录规划、宏与内联、接口封装、冗余剔除、测试与 CI、迭代重构…
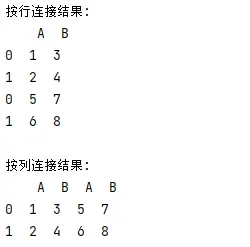
Python Pandas库简介及常见用法
Python Pandas库简介及常见用法 一、 Pandas简介1. 简介2. 主要特点(一)强大的数据结构(二)灵活的数据操作(三)时间序列分析支持(四)与其他库的兼容性 3.应用场景(一&…

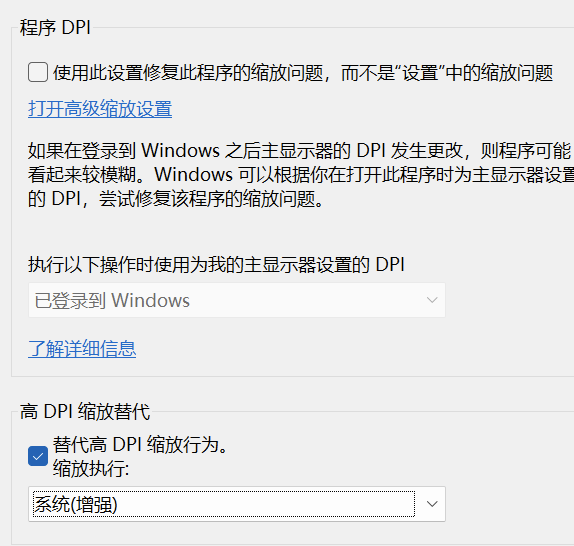
【已解决】HBuilder X编辑器在外接显示器或者4K显示器怎么界面变的好小问题
触发方式:主要涉及DPI缩放问题,可能在电脑息屏有概率触发
修复方式: 1.先关掉软件直接更改屏幕缩放,然后打开软件,再关掉软件恢复原来的缩放,再打开软件就好了 2.(不推荐)右键HBuilder在属性里…

直线型绝对值位移传感器:精准测量的科技利刃
在科技飞速发展的今天,精确测量成为了众多领域不可或缺的关键环节。无论是工业自动化生产线上的精细操作,还是航空航天领域中对零部件位移的严苛把控,亦或是科研实验中对微小位移变化的精准捕捉,都离不开一款高性能的测量设备——…
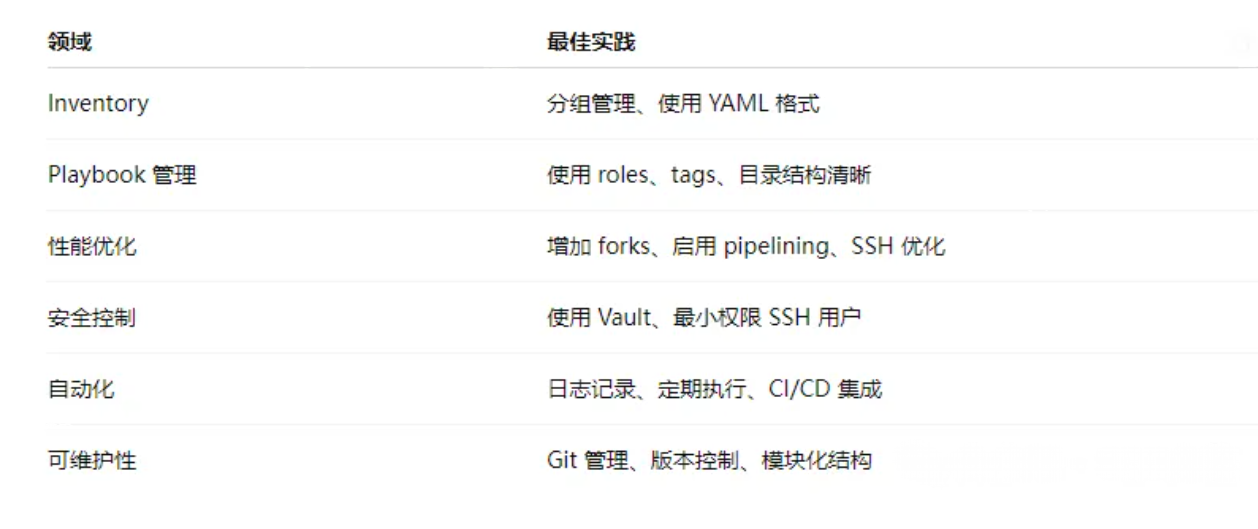
Ansible模块——管理100台Linux的最佳实践
使用 Ansible 管理 100 台 Linux 服务器时,推荐遵循以下 最佳实践,以提升可维护性、可扩展性和安全性。以下内容结合实战经验进行总结,适用于中大型环境(如 100 台服务器): 一、基础架构设计
1. 分组与分层…
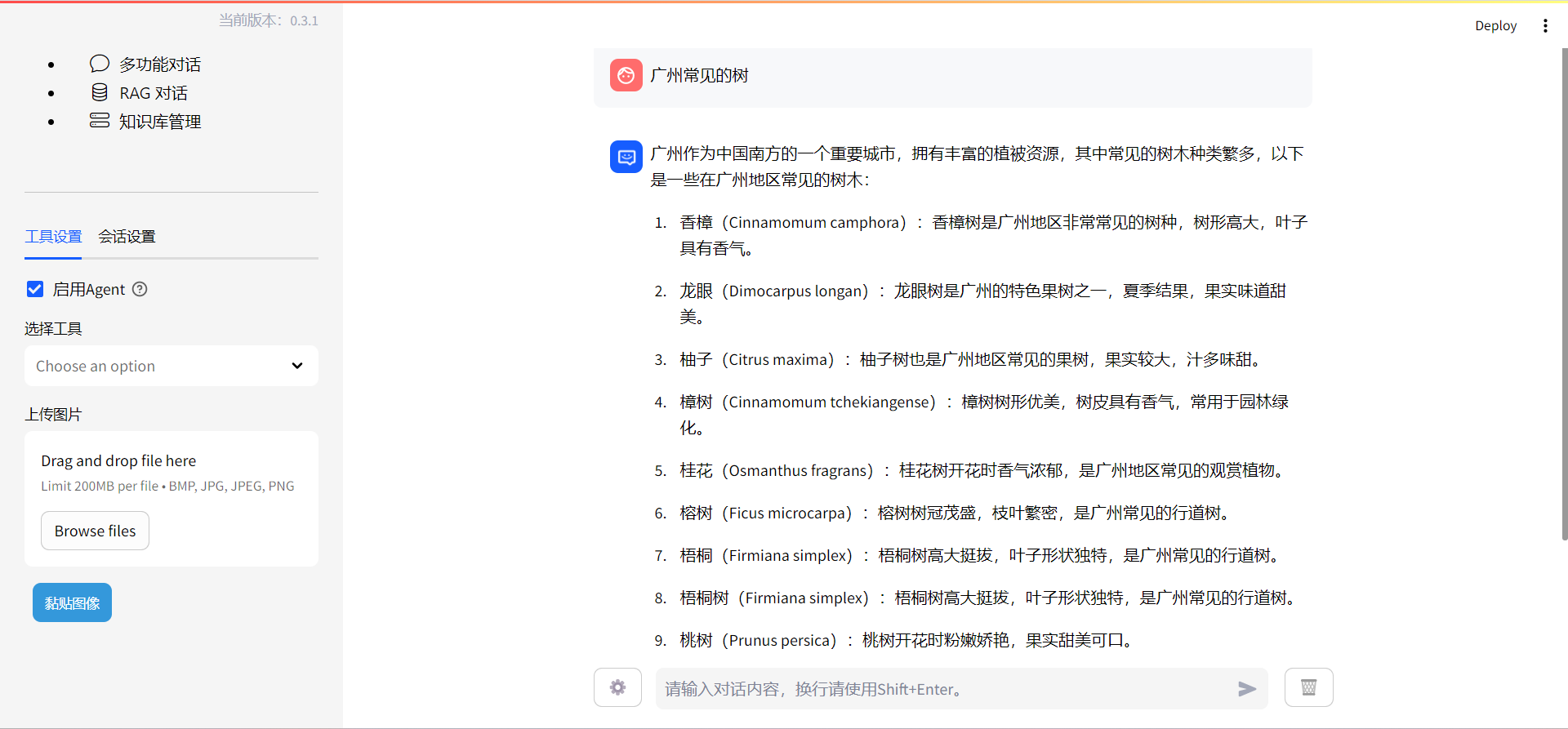
从0开始学习大模型--Day09--langchain初步使用实战
众所周知,一味地学习知识,所学的东西和概念都是空中楼阁,大部分情况下,实战都是很有必要的,今天就通过微调langchain来更深刻地理解它。
中间如何进入到langchain界面请参考结尾视频链接。
首先,进入界面…
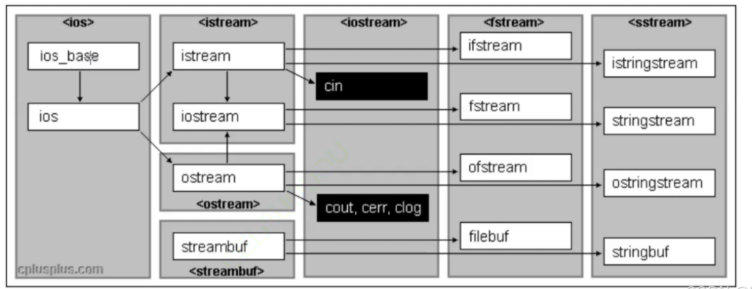
C++中的菱形继承问题
假设有一个问题,类似于鸭子这样的动物有很多种,如企鹅和鱿鱼,它们也可能会有一些共同的特性。例如,我们可以有一个叫做 AquaticBird (涉禽,水鸟的一类)的类,它又继承自 Animal 和 Sw…
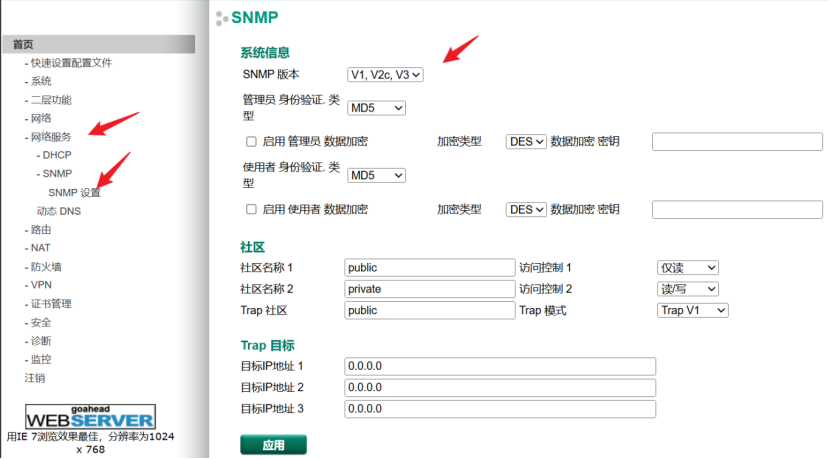
网络-MOXA设备基本操作
修改本机IP和网络设备同网段,输入设备IP地址进入登录界面,交换机没有密码,路由器密码为moxa
修改设备IP地址
交换机 路由器 环网
启用Turbo Ring协议:在设备的网络管理界面中,找到环网配置选项,启用Turb…
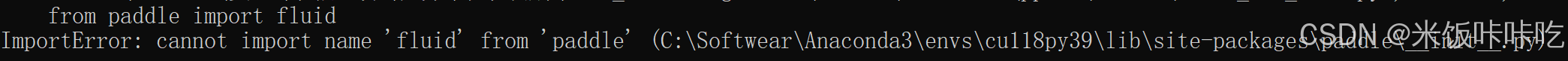
飞桨paddle import fluid报错【已解决】
跟着飞桨的安装指南安装了paddle之后
pip install paddlepaddle有一个验证:
import paddle.fluid as fluid
fluid.install check.run check()报错情况如下,但是我在pip list中,确实看到了paddle安装上了 我import paddle别的包,…

测试工程师要如何开展单元测试
单元测试是软件开发过程中至关重要的环节,它通过验证代码的最小可测试单元(如函数、方法或类)是否按预期工作,帮助开发团队在早期发现和修复缺陷,提升代码质量和可维护性。以下是测试工程师开展单元测试的详细步骤和方法:
一、理…
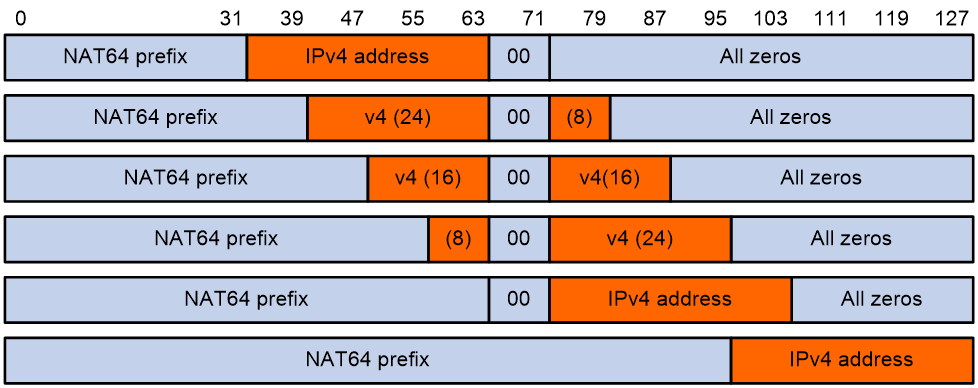
IPv4 地址嵌入 IPv6 的前缀转换方式详解
1. 概述
在 IPv4 和 IPv6 网络共存的过渡期,NAT64(Network Address Translation 64)是一种关键技术,用于实现 IPv6-only 网络与 IPv4-only 网络的互操作。NAT64 前缀转换通过将 IPv4 地址嵌入到 IPv6 地址中,允许 IPv…
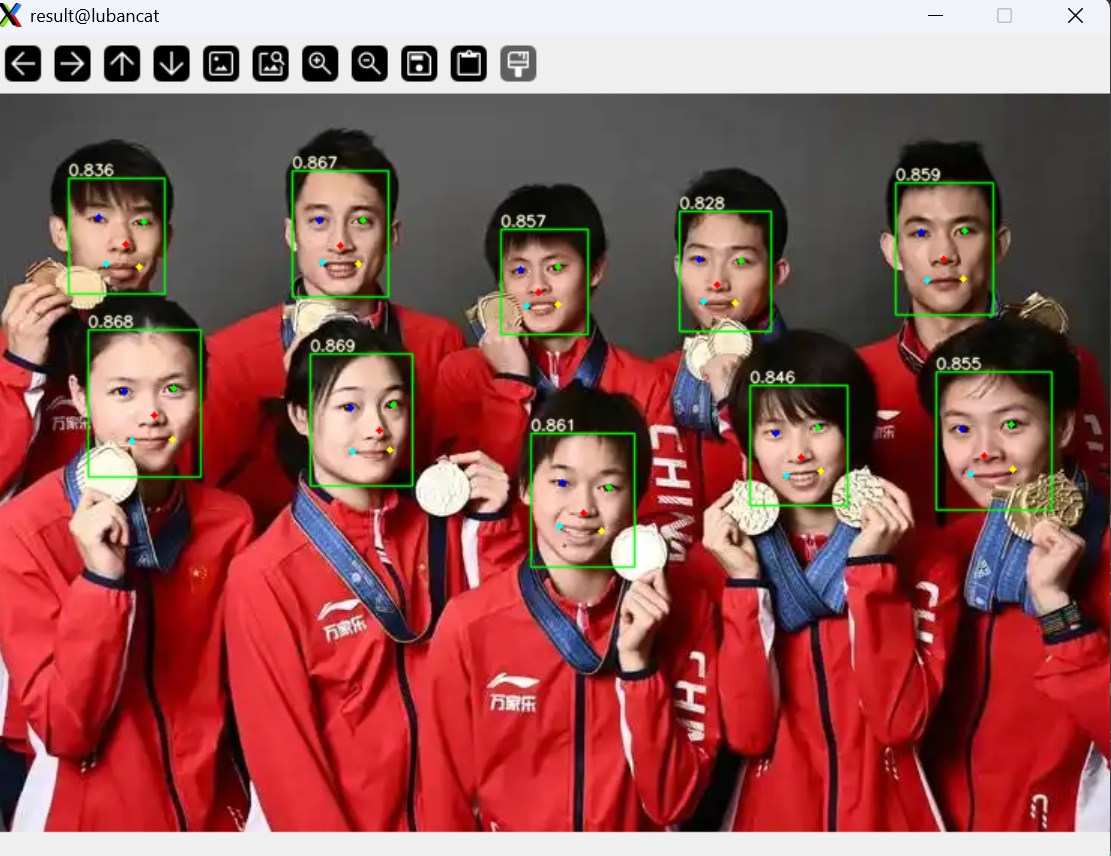
野火鲁班猫(arrch64架构debian)从零实现用MobileFaceNet算法进行实时人脸识别(三)用yolov5-face算法实现人脸检测
环境直接使用第一篇中安装好的环境即可
先clone yolov5-face项目
git clone https://github.com/deepcam-cn/yolov5-face.git
并下载预训练权重文件yolov5n-face.pt
网盘链接: https://pan.baidu.com/s/1xsYns6cyB84aPDgXB7sNDQ 提取码: lw9j
(野火官方提供&am…