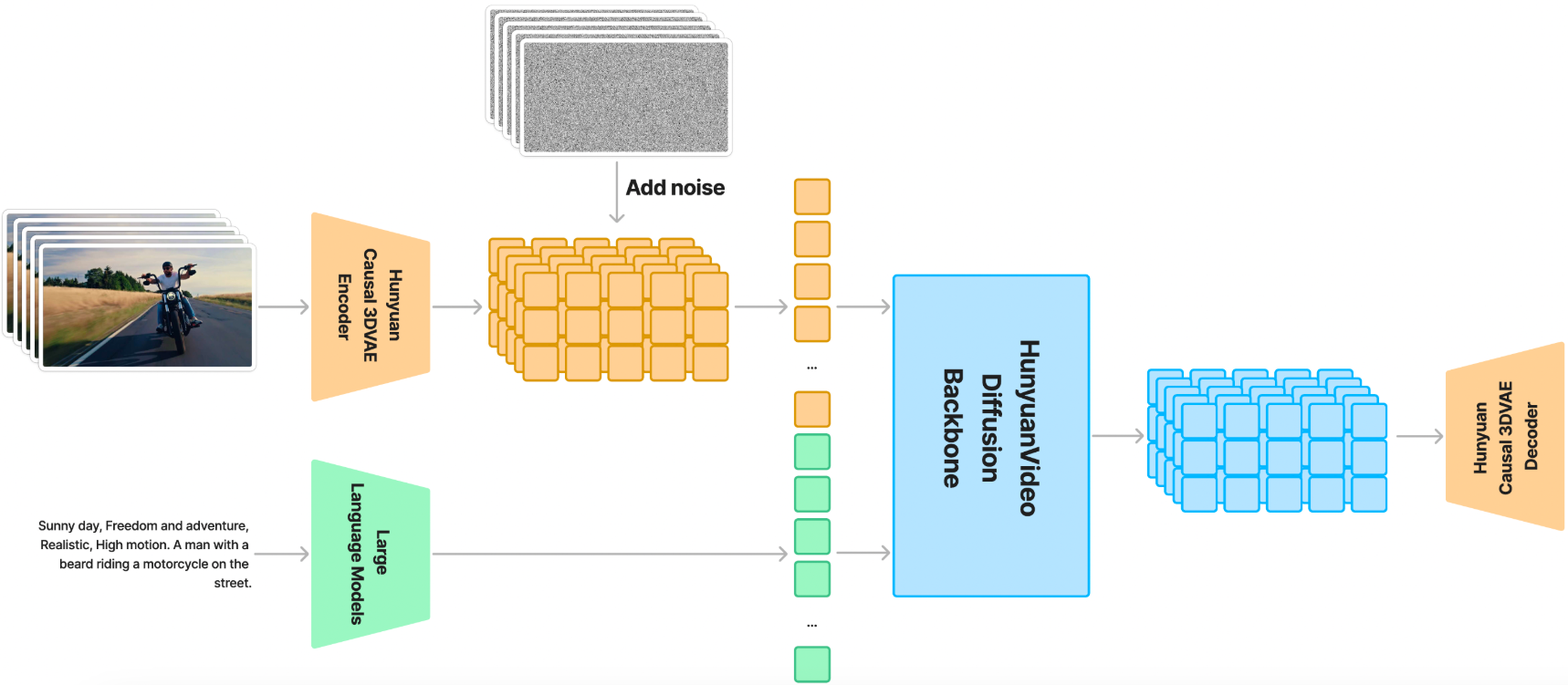
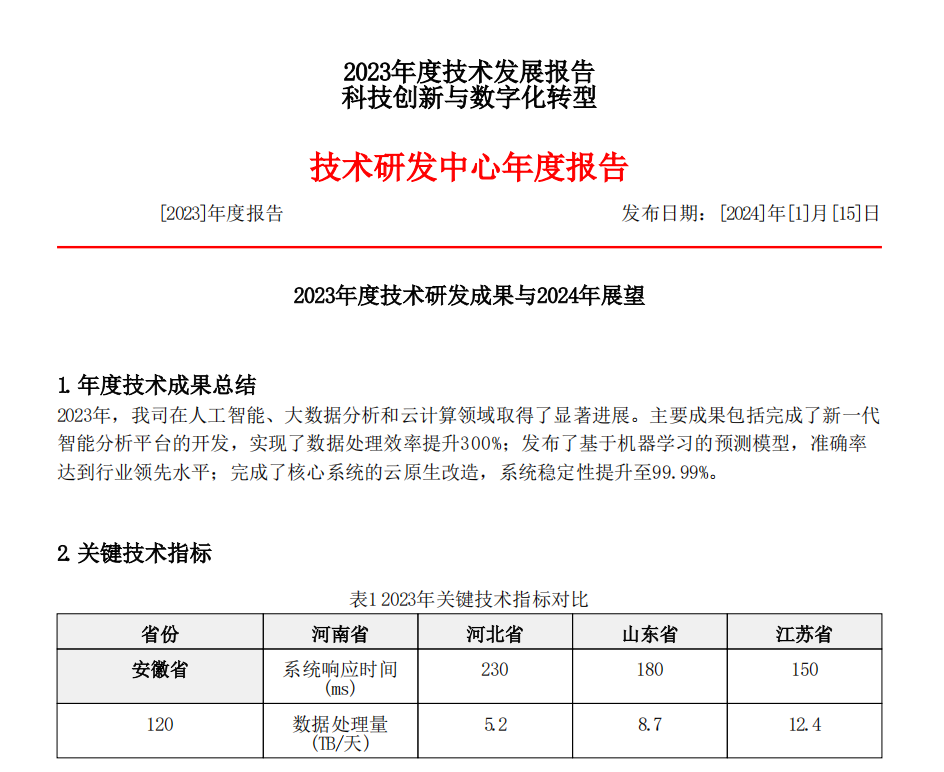
Python Pandas库简介及常见用法
- 一、 Pandas简介
- 1. 简介
- 2. 主要特点
- (一)强大的数据结构
- (二)灵活的数据操作
- (三)时间序列分析支持
- (四)与其他库的兼容性
- 3.应用场景
- (一)金融领域
- (二)数据科学与机器学习
- (三)商业数据分析
- (四)生物医学研究
- 二、Pandas库的常见用法
- 1. 数据读取
- 1.1 读取CSV文件
- 1.2 读取Excel文件
- 1.3 读取数据库数据
- 1.4 读取JSON数据
- 2. 写入数据
- 2.1 写入CSV文件
- 2.2 写入Excel文件
- 2.3 写入数据库
- 3. 数据清洗
- 3.1 处理缺失值
- 3.2 处理重复数据
- 3.3 数据类型转换
- 3.4 重命名列名
- 4. 数据查看与统计
- 4.1 查看数据结构
- 4.2 数据统计
- 5. 数据筛选与过滤
- 5.1 通过布尔表达式筛选
- 5.2 按索引筛选
- 5.3 按列名筛选
- 6. 数据转换与处理
- 6.1 数据排序
- 6.2 数据分组与聚合
- 6.3 数据透视表
- 7. 数据合并与连接
- 7.1 数据合并
- 7.2 数据连接
- 8. 时间序列数据处理
- 8.1 创建时间序列
- 8.2 时间频率转换
- 8.3 时间窗口计算
一、 Pandas简介
1. 简介
Pandas是一个开源的Python数据分析库,它提供了高性能、易用的数据结构和数据分析工具。Pandas的名字来源于“Panel Data”(面板数据),它主要用于处理结构化数据,例如表格数据、时间序列数据等。Pandas是在NumPy库的基础上构建的,它继承了NumPy的高性能数组计算能力,并在此基础上增加了对复杂数据操作的支持。它提供了两种主要的数据结构:Series(一维数组)和DataFrame(二维表格),使得数据处理更加高效和便捷。
Pandas最初由Wes McKinney在2008年创建,目的是为了满足金融数据分析的需求。随着时间的推移,它已经成为Python数据分析生态系统中不可或缺的一部分,被广泛应用于数据科学、机器学习、金融、统计等多个领域。
2. 主要特点
(一)强大的数据结构
- DataFrame:这是Pandas中最核心的数据结构之一,它是一个二维表格型数据结构,类似于Excel中的表格。DataFrame的每一列可以存储不同类型的数据(如数字、字符串等),并且可以通过列名和行索引来访问数据。例如,我们可以创建一个包含员工信息(姓名、年龄、部门等)的DataFrame,通过列名“姓名”来获取所有员工的名字,或者通过行索引来获取特定员工的全部信息。
- Series:Series是一个一维数组,类似于NumPy数组,但它可以带有索引。索引可以是整数、字符串等任何哈希类型。Series在处理单列数据时非常方便,比如对一组时间序列数据(如股票价格)进行操作,可以通过日期索引来快速访问特定时间点的价格。
(二)灵活的数据操作
- 数据清洗:Pandas提供了丰富的数据清洗功能,可以轻松处理缺失值(如填充缺失值、删除缺失值)、重复数据(如删除重复行)、异常值等。例如,对于一个包含缺失值的DataFrame,我们可以使用fillna()方法来填充缺失值,或者使用dropna()方法来删除包含缺失值的行。
- 数据筛选:可以使用布尔索引、标签索引、位置索引等多种方式对数据进行筛选。例如,我们可以通过布尔表达式df[df[‘年龄’] > 30]来筛选出年龄大于30的员工数据。
- 数据合并:Pandas支持多种数据合并操作,如concat()(用于连接多个数据结构)、merge()(类似于SQL中的JOIN操作,可以根据指定的键将两个DataFrame合并在一起)和join()(基于索引进行合并)。这些功能使得在处理多个数据源时可以方便地将它们整合到一起。比如,将员工信息表和员工绩效表根据员工ID进行合并。
- 数据分组与聚合:通过groupby()方法可以对数据进行分组,然后对每个分组应用聚合函数(如求和、求平均、计数等)。例如,对销售数据按照地区分组,然后计算每个地区的总销售额。
(三)时间序列分析支持
Pandas对时间序列数据提供了强大的支持。它可以直接解析日期时间字符串,生成时间序列索引。例如,pd.date_range(start=‘2024-01-01’, end=‘2024-12-31’, freq=‘D’)可以生成一个从2024年1月1日到2024年12月31日的每日时间序列索引。此外,Pandas还支持时间频率的转换(如将日数据转换为月数据)、时间窗口计算(如计算移动平均值)等操作,这使得它在金融数据分析、气象数据分析等涉及时间序列的领域非常有用。
(四)与其他库的兼容性
Pandas可以无缝地与Python的其他数据分析和科学计算库配合使用。例如,它可以与NumPy进行高效的数组操作,与Matplotlib进行数据可视化,与Scikit - learn进行机器学习模型的训练和预测。这种良好的兼容性使得Pandas能够融入完整的数据分析工作流中。
3.应用场景
(一)金融领域
在金融数据分析中,Pandas可以用来处理股票价格数据、交易数据等。例如,通过读取股票价格的时间序列数据,可以计算股票的收益率、移动平均线等指标。还可以对多个股票的收益率数据进行合并,分析股票之间的相关性。此外,Pandas也可以用于风险管理,比如通过分析交易数据来识别异常交易行为。
(二)数据科学与机器学习
在数据科学项目中,Pandas是数据预处理的重要工具。数据科学家可以使用Pandas来加载数据(如从CSV文件、数据库等来源加载)、清洗数据(处理缺失值、异常值等)、探索数据(计算描述性统计量、绘制数据分布图等)。在机器学习中,Pandas可以将数据集划分为训练集和测试集,还可以对特征数据进行标准化、归一化等操作,为机器学习模型的训练做好准备。
(三)商业数据分析
商业分析师可以使用Pandas来分析销售数据、客户数据等。例如,通过分析销售数据的时间序列,可以发现销售的季节性规律;通过分析客户数据,可以对客户进行分群(如使用groupby()方法根据客户消费金额分组),并计算每个客户群的特征(如平均消费金额、购买频率等)。这些分析结果可以帮助企业制定营销策略、优化产品布局等。
(四)生物医学研究
在生物医学领域,Pandas可以用于处理实验数据,如基因表达数据、临床试验数据等。研究人员可以使用Pandas来整理数据格式、筛选特定的样本或基因,还可以对数据进行统计分析,如计算基因表达的差异等。
二、Pandas库的常见用法
1. 数据读取
1.1 读取CSV文件
Pandas加载CSV文件并在 Python 中以编程方式操作它。 Pandas的核心是“DataFrame”的对象类型- 本质上是一个值表,每行和每列都有一个标签。用read_csv()方法加载CSV 文件:
import pandas as pd
# 读取CSV文件
df = pd.read_csv('2010-2024年国家经济运行情况.csv',encoding='utf-8')
# 显示前5行数据
print(df.head())
1.2 读取Excel文件
- 使用pd.read_excel()方法可以读取Excel文件(.xls或.xlsx格式)。
import pandas as pd
# 读取Excel文件
df = pd.read_excel('2010-2024年北京市经济运行情况.xlsx',encoding='gbk')
# 显示前5行数据
print(df.head())
1.3 读取数据库数据
- 使用pd.read_sql()方法可以从数据库中读取数据。
import pandas as pd
import sqlite3
# 连接到SQLite数据库
conn = sqlite3.connect('economics_data.db')
# 从数据库表中读取数据
df = pd.read_sql('SELECT * FROM table_name', conn)
1.4 读取JSON数据
- 使用pd.read_json()方法可以读取JSON格式的文件。
import pandas as pd
df = pd.read_json("2025年北京报告数据.json", orient="records")
参数:
- orient:指定JSON文件的格式,常见的有’records’(每行是一个JSON对象)、‘split’(键值对分开存储)等。
- ‘records’:JSON 是一个记录列表,每个记录是一个字典,这是默认值。
- ‘index’:JSON 的键是索引,值是列。
- ‘columns’:JSON 的键是列,值是索引。
- ‘values’:JSON 是一个二维数组,每一行是一个记录。
import pandas as pd
# 示例 JSON 数据
json_data = {
"index": ["row1", "row2"],
"columns": ["col1", "col2"],
"data": [[1, 2], [3, 4]]
}
# 使用 orient='split' 读取
df = pd.read_json(pd.io.json.dumps(json_data), orient='split')
print(df)
2. 写入数据
2.1 写入CSV文件
- 使用DataFrame.to_csv()方法可以将DataFrame保存为CSV文件。
import pandas as pd
# 创建一个 DataFrame
data = {
'name': ['Alice', 'Bob'],
'age': [25, 30]
}
df = pd.DataFrame(data)
# 将数据写入CSV文件
# index=False表示不保存行索引
df.to_csv('output.csv', index=False)
参数说明:
- index:是否保存行索引,默认为True。
- sep:指定分隔符,默认为逗号(,)。
2.2 写入Excel文件
- 使用DataFrame.to_excel()方法可以将DataFrame保存为Excel文件。
import pandas as pd
# 创建一个 DataFrame
data = {
'name': ['Alice', 'Bob', 'Gary', 'Lily'],
'age': [25, 30, 24, 26],
'Grade': [97, 76, 61, 88]
}
df = pd.DataFrame(data)
# 写入Excel文件中
df.to_excel('exam_result.xlsx', sheet_name='Sheet1', index=False)
参数说明:
- sheet_name:指定保存的工作表名称。
- index:是否保存行索引。
2.3 写入数据库
- 使用DataFrame.to_sql()方法可以将DataFrame保存到数据库中。
import pandas as pd
from sqlalchemy import create_engine
# 创建一个 DataFrame
data = {
'name': ['Alice', 'Bob', 'Gary', 'Lily'],
'age': [25, 30, 24, 26],
‘gender’: ['F', 'M', 'M', 'F'],
'Grade': [97, 76, 61, 88]
}
df = pd.DataFrame(data)
# 创建sqlalchemy的数据库连接
conn = create_engine('mysql+pymysql://root:123456@localhost:3306/exam_db?charset=utf8')
# 写入数据库中
df.to_sql('exam_result', conn, if_exists='replace', index=False)
参数说明:
- 第一个参数是目标数据库表的名称。
- conn是数据库连接对象, 必须是sqlalchemy的数据库连接。
- if_exists:指定如果表已存在时的行为,可选值为’fail’(抛出错误)、‘replace’(替换表)、‘append’(追加数据)。
index:是否将行索引作为一列保存到数据库中。
3. 数据清洗
3.1 处理缺失值
(1)检查缺失值
- 使用isnull()或isna()方法可以检查数据中的缺失值。
# 返回一个布尔型DataFrame,缺失值为True
print(df.isnull())
# 统计每列的缺失值数量
print(df.isnull().sum())
(2)填充缺失值
- 使用fillna()方法可以填充缺失值。
# 将所有缺失值填充为0
df.fillna(value=0, inplace=True)
# 用列的均值填充该列的缺失值
df['列名'].fillna(value=df['列名'].mean(), inplace=True)
(3)删除缺失值
- 使用dropna()方法可以删除包含缺失值的行或列。
# 删除包含缺失值的行
df.dropna(inplace=True)
# 删除包含缺失值的列
df.dropna(axis=1, inplace=True)
3.2 处理重复数据
(1)检查重复数据
- 使用duplicated()方法可以检查重复行。
# 返回布尔型Series,重复行为True
print(df.duplicated())
# 统计重复行的数量
print(df.duplicated().sum())
(2)删除重复数据
- 使用drop_duplicates()方法可以删除重复行。
# 删除重复行
df.drop_duplicates(inplace=True)
3.3 数据类型转换
- 使用astype()方法可以将列的数据类型转换为指定类型。
# 将列转换为整数类型
df['列名'] = df['列名'].astype('int')
# 将列转换为浮点数类型
df['列名'] = df['列名'].astype('float')
# 将列转换为字符串类型
df['列名'] = df['列名'].astype('str')
3.4 重命名列名
- 使用rename()方法可以重命名列名。
- 用法:
df.rename(columns={‘旧列名1’: ‘新列名1’, ‘旧列名2’: ‘新列名2’}, inplace=True)
stock_data_frame = pd.DataFrame(stock_data).rename(
columns={
0: 'SECURITY_CODE',
1: 'SECURITY_NAME',
2: 'LATEST_PRICE',
3: 'PRICES_CHANGE_RATIO',
4: 'PRICES_CHANGE',
5: 'TRADING_COUNT',
6: 'TRADING_VALUE',
7: 'AMPLITUDE',
8: 'TURN_OVER_RATIO',
9: 'PE_RATIO',
10: 'TRADE_RATIO',
11: 'MAX_PRICE',
12: 'MIN_PRICE',
13: 'OPEN_PRICE',
14: 'PRE_CLOSE_PRICE',
15: 'TOTAL_MARKET_VALUE',
16: 'CIRCULATION_MARKET_VALUE',
17: 'PB_RATIO',
18: 'PE_RATIO_TTM',
19: 'UPWARD_RATE',
20: 'MONTH_CHANGE_RATIO',
21: 'YEAR_CHANGE_RATIO',
22: 'INFLOW_FUNDS'
}
)
示例:当前我们有一个包含缺失值和重复值的国家经济运行情况CSV文件,需要进一步清洗数据以便后续分析。
import pandas as pd
# 读取数据
data = pd.read_csv('2010-2024年国家经济运行情况.csv',encoding='utf-8')
# 显示前五行数据
print(data.head())
# 处理缺失值
# 处理1:删除含有缺失值的行
data = data.dropna()
# 处理方式2:将缺失值填充为0
data = data.fillna(0)
# 移除重复值
data = data.drop_duplicates()
# 显示处理后数据的前5条
print(data.head())
4. 数据查看与统计
4.1 查看数据结构
(1)查看DataFrame的前几行
- 使用head()方法可以查看DataFrame的前几行,默认显示前5行。
# 查看前5行
print(df.head())
# 查看前10行
print(df.head(10))
(2)查看DataFrame的后几行
- 使用tail()方法可以查看DataFrame的后几行,默认显示后5行。
# 查看后5行
print(df.tail())
# 查看后10行
print(df.tail(10))
(3)查看DataFrame的行列数(形状)
- 使用shape属性可以获取DataFrame的形状(行数和列数)。
# 输出行数与列数
print(df.shape)
(4)查看DataFrame的列名
- 使用columns属性可以获取DataFrame的列名。
# 输出列名
print(df.columns)
(5)查看DataFrame的数据类型
- 使用dtypes属性可以查看每列的数据类型。
# 输出列的数据类型
print(df.dbtypes)
4.2 数据统计
(1)描述性统计
- 使用**describe()**方法可以获取DataFrame的描述性统计信息,包括均值、标准差、最小值、四分位数等。
# 默认只对数值列进行统计
print(df.describe())
# 对所有列进行统计
print(df.describe(include='all'))
(2)特定统计量计算
- 可以使用mean()、median()、std()、sum()、count()等方法计算特定的统计量。
- mean() : 统计均值
- median(): 统计中位数
- std(): 统计标准差
- sum(): 数据求和统计
- count(): 统计数量
# 计算某一列的均值
df['列名'].mean()
# 计算某一列的总和
df['列名'].sum()
(3)计算相关系数
- 使用**corr()**方法可以计算DataFrame中数值列之间的相关系数。
# 输出相关系数矩阵
print(df.corr())
- 示例:
import pandas as pd
import numpy as np
# 创建一个示例 DataFrame
data = {
'A': np.random.randn(100), # 随机生成100个标准正态分布的数
'B': np.random.rand(100), # 随机生成100个在[0,1)区间均匀分布的数
'C': np.random.randint(0, 100, 100), # 随机生成10个[0,10)之间的整数
'D': np.random.randn(100) # 随机生成100个标准正态分布的数
}
df = pd.DataFrame(data)
# 计算 DataFrame 中所有数值型列的相关系数
correlation_matrix = df.corr()
print("Correlation Matrix:")
print(correlation_matrix)
(4)计算数据分布
- 使用value_counts()方法可以统计某一列中各个值的出现次数。
# 统计某一列中各个值的出现次数
print(df['列名'].value_counts())
5. 数据筛选与过滤
5.1 通过布尔表达式筛选
- Pandas支持使用布尔表达式可以对DataFrame进行筛选。
# 筛选某一列大于10的行
filtered_df = df[df['列名'] > 10]
# 使用多个条件进行筛选
filtered_df = df[(df['列名1'] > 10) & (df['列名2'] < 20)]
- 示例:根据条件筛选股票
# 条件选股逻辑:
# - 量比 > 1
# - 换手率 ≥5%且≤10%
# - 振幅 ≥3%且≤10%
# - 流通市值 ≥50亿且≤200亿
# - 动态市盈率>0且<= 30(行业均值×1.5)
# - 资金流 > 500万
filtered = stock_data_frame[
# 量比 > 1
(stock_data_frame['TRADE_RATIO'] > 100) &
# 换手率在5%至10%区间
(stock_data_frame['TURN_OVER_RATIO'] >= 500) &
(stock_data_frame['TURN_OVER_RATIO'] <= 1000) &
# 振幅在3%至10%区间
(stock_data_frame['AMPLITUDE'] >= 300) &
(stock_data_frame['AMPLITUDE'] <= 1000) &
# 流通市值在50亿元至200亿元区间
(stock_data_frame['CIRCULATION_MARKET_VALUE'] >= 5000000000) &
(stock_data_frame['CIRCULATION_MARKET_VALUE'] <= 20000000000) &
# 动态市盈率在0至40之间
(stock_data_frame['PE_RATIO'] > 0) &
(stock_data_frame['PE_RATIO'] <= 4000) &
# 股票收盘价在30元以内
(stock_data_frame['LATEST_PRICE'] <= 3000) &
# 当日资金流入大于500万
(stock_data_frame['INFLOW_FUNDS'] > 5000000)
]
5.2 按索引筛选
- Pandas中使用loc()和iloc()可以按索引进行筛选。
- loc:基于标签索引,可以同时指定行和列。
- iloc:基于位置索引,只能指定行和列的位置。
# 使用loc
# 选择第2到第5行,指定列名
selected_df = df.loc[df.index[1:5], ['列名1', '列名2']]
# 使用iloc
# 选择第2到第5行,第1和第2列
selected_df = df.iloc[1:5, [0, 1]]
5.3 按列名筛选
- Pandas中可以通过列名直接选择列。
# 选择单列
selected_column = df['列名']
# 选择多列
selected_columns = df[['列名1', '列名2']]
6. 数据转换与处理
6.1 数据排序
(1)按列值排序
- 使用sort_values()方法可以按列值对DataFrame进行排序。
# 按某一列升序排序
df.sort_values(by='列名', ascending=True, inplace=True)
# 按多列排序
df.sort_values(by=['列名1', '列名2'], ascending=[True, False], inplace=True)
(2)按索引排序
- 使用sort_index()方法可以按索引对DataFrame进行排序。
# 按索引排序
df.sort_index(inplace=True)
6.2 数据分组与聚合
(1)数据分组
- Pandas中使用groupby()方法可以对数据进行分组。
# 按某一列分组
grouped = df.groupby('列名')
# 按多列分组
grouped = df.groupby(['列名1', '列名2'])
(2)数据聚合
- Pandas中使用聚合函数(如sum()、mean()、count()等)对分组后的数据进行计算。
# 对分组后的数据求和
result = grouped.sum()
# 对分组后的数据求均值
result = grouped.mean()
# 对不同列应用不同的聚合函数
result = grouped.agg({'列名1': 'sum', '列名2': 'mean'})
6.3 数据透视表
(1)数据重塑
- Pandas中使用pivot()用于将长格式数据转换为宽格式。
import pandas as pd
import numpy as np
# 创建示例数据
data = {
'日期': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02'],
'变量': ['A', 'B', 'A', 'B'],
'值': [10, 20, 30, 40]
}
df = pd.DataFrame(data)
# 使用pivot进行重塑
pivot_df = df.pivot(index='日期', columns='变量', values='值')
print("Pivot结果:\n", pivot_df)
输出:

参数说明:
- index: 指定作为行索引的列
- columns: 指定作为列名的列
- values: 指定填充值的列
(2)数据透视
- Pandas中使用pivot_table()方法可以创建数据透视表。
pivot_table = df.pivot_table(index='列名1', columns='列名2', values='列名3', aggfunc='sum')
# 创建有重复值的数据
data = {
'日期': ['2024-01-01', '2024-01-01', '2024-01-02', '2024-01-02'],
'变量': ['A', 'B', 'A', 'B'],
'值': [10, 20, 30, 40]
}
df = pd.DataFrame(data)
# 使用pivot_table进行聚合
pivot_table_df = pd.pivot_table(df, values='值', index='日期', columns='变量', aggfunc=np.mean)
print("\nPivot Table结果:\n", pivot_table_df)
输出:

参数说明:
- aggfunc: 指定聚合函数,默认为np.mean
- 可以处理重复值,对相同索引和列的组合进行聚合
7. 数据合并与连接
7.1 数据合并
- Pandas中使用merge()方法可以将两个DataFrame按指定的键合并,类似于SQL中的JOIN操作。
df1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value1': [1, 2, 3]})
df2 = pd.DataFrame({'key': ['A', 'B', 'D'], 'value2': [4, 5, 6]})
# 内连接合并
merged_df = pd.merge(df1, df2, on='key', how='inner')
# 外连接合并
merged_df = pd.merge(df1, df2, on='key', how='outer')
# 左连接合并
merged_df = pd.merge(df1, df2, on='key', how='left')
# 右连接合并
merged_df = pd.merge(df1, df2, on='key', how='right')
输出结果:

7.2 数据连接
- Pandas中使用concat()方法可以将多个DataFrame按行或列连接。
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
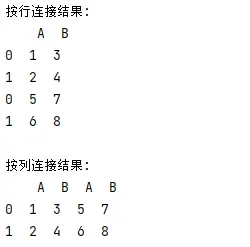
# 按行连接
concatenated_df = pd.concat([df1, df2], axis=0)
# 按列连接
concatenated_df = pd.concat([df1, df2], axis=1)
输出结果:
8. 时间序列数据处理
8.1 创建时间序列
- 使用pd.date_range()可以创建时间序列索引。
# 每日时间序列
date_range = pd.date_range(start='2024-01-01', end='2024-12-31', freq='D')
# 创建一个时间序列DataFrame
df = pd.DataFrame({'value': range(len(date_range))}, index=date_range)
8.2 时间频率转换
- 使用resample()方法可以对时间序列数据进行频率转换。
# 将日数据转换为月数据,并求和
monthly_df = df.resample('M').sum()
8.3 时间窗口计算
- 使用rolling()方法可以对时间序列数据进行窗口计算(如移动平均)。
# 计算7天移动平均值
df['moving_avg'] = df['value'].rolling(window=7).mean()
在股票行情计算时,可使用rolling()方法计算MA移动平均线。
# 计算移动平均线
stock_data['ma5'] = stock_data['close'].rolling(5).mean()
stock_data['ma10'] = stock_data['close'].rolling(10).mean()
stock_data['ma20'] = stock_data['close'].rolling(20).mean()