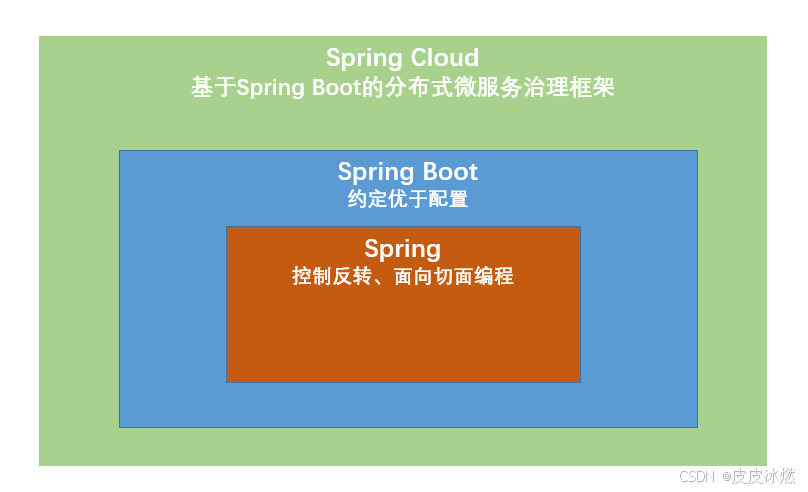
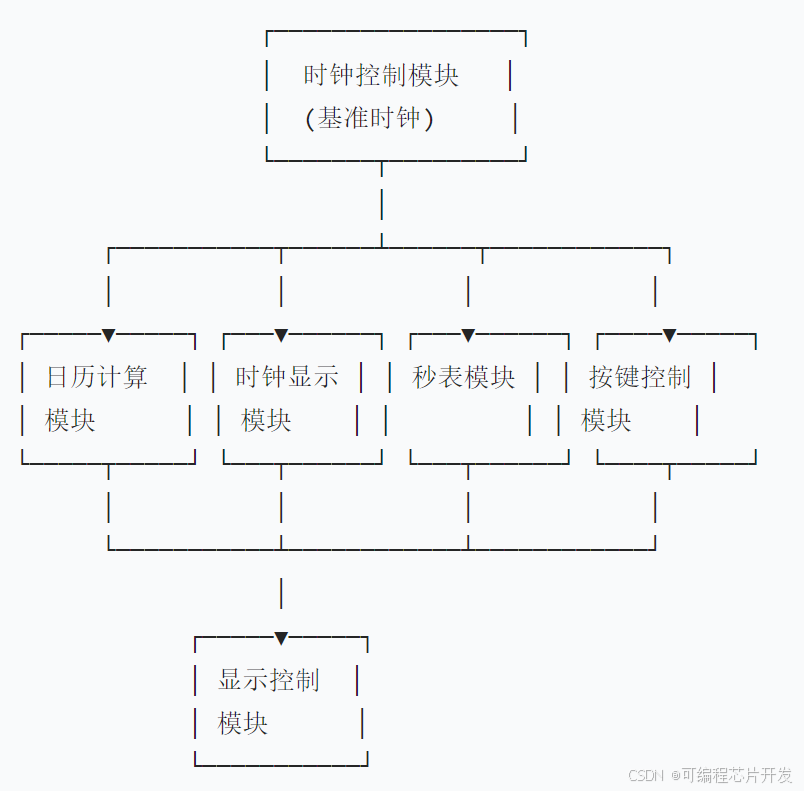
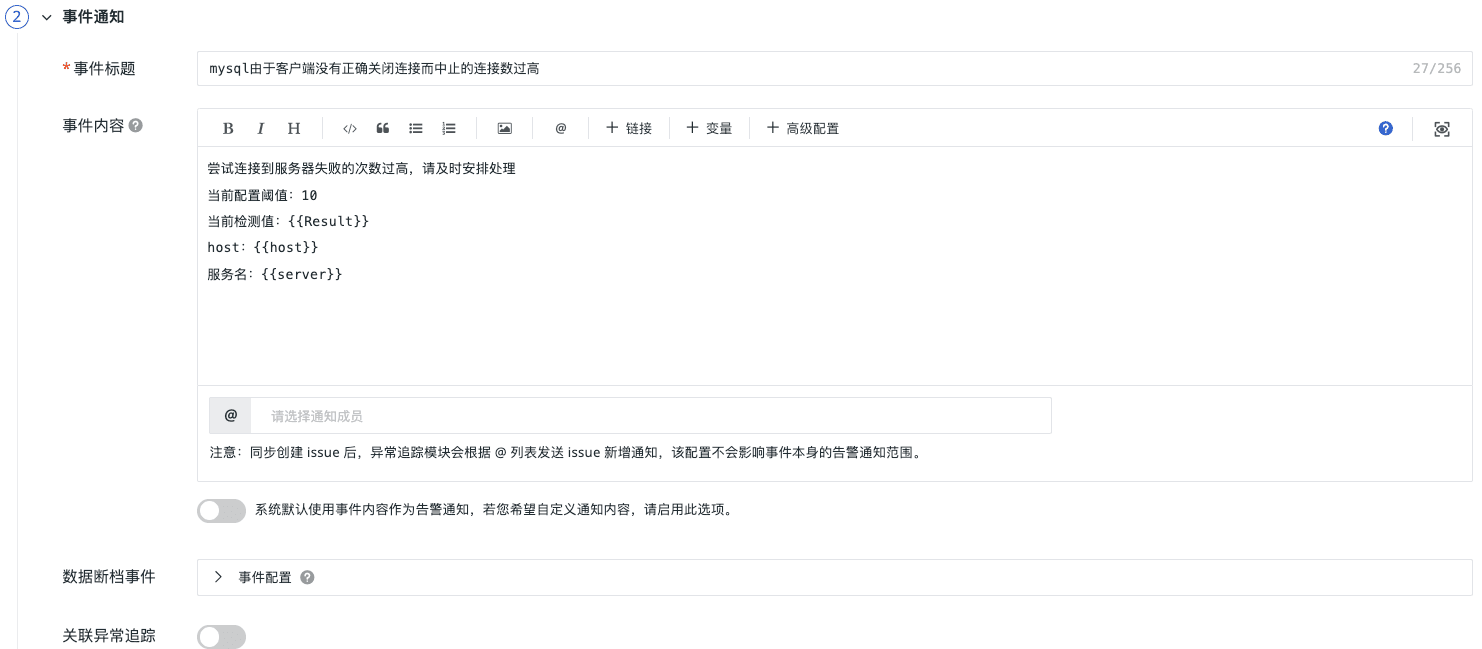
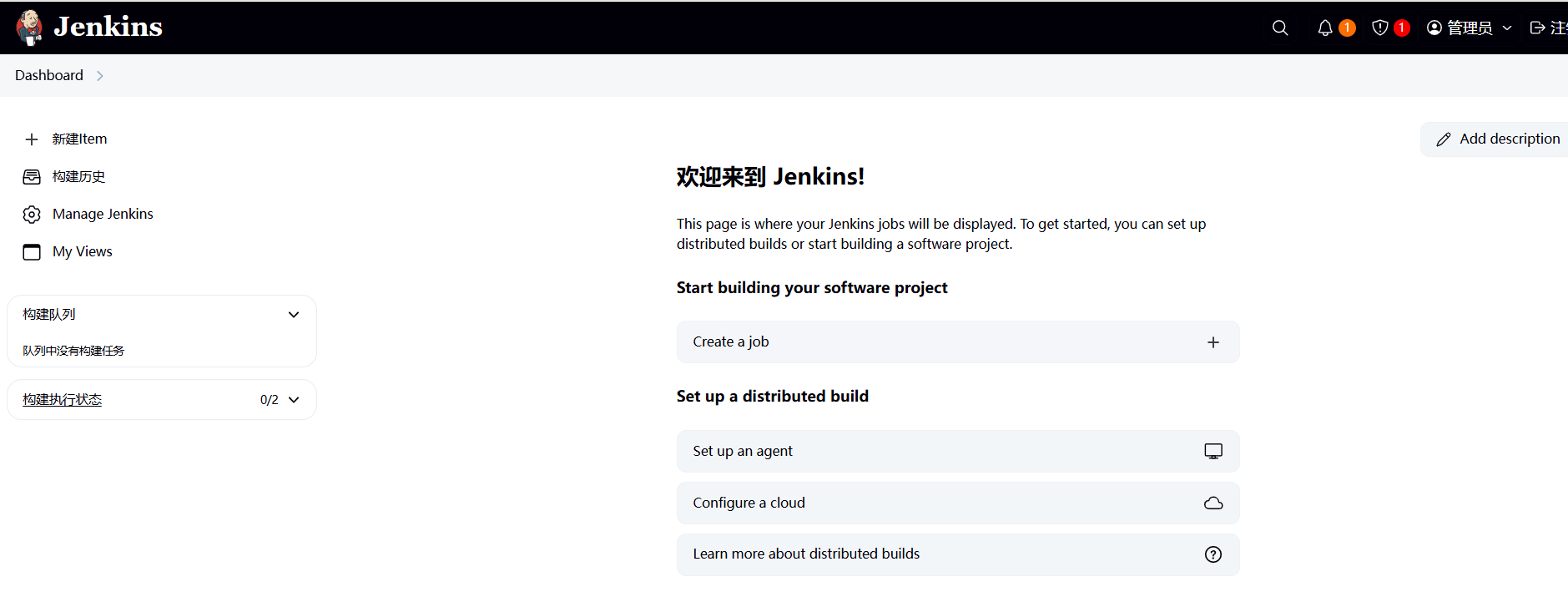
众所周知,一味地学习知识,所学的东西和概念都是空中楼阁,大部分情况下,实战都是很有必要的,今天就通过微调langchain来更深刻地理解它。
中间如何进入到langchain界面请参考结尾视频链接。
首先,进入界面,点击下方设置,我们会看到要选择的精度和模型:
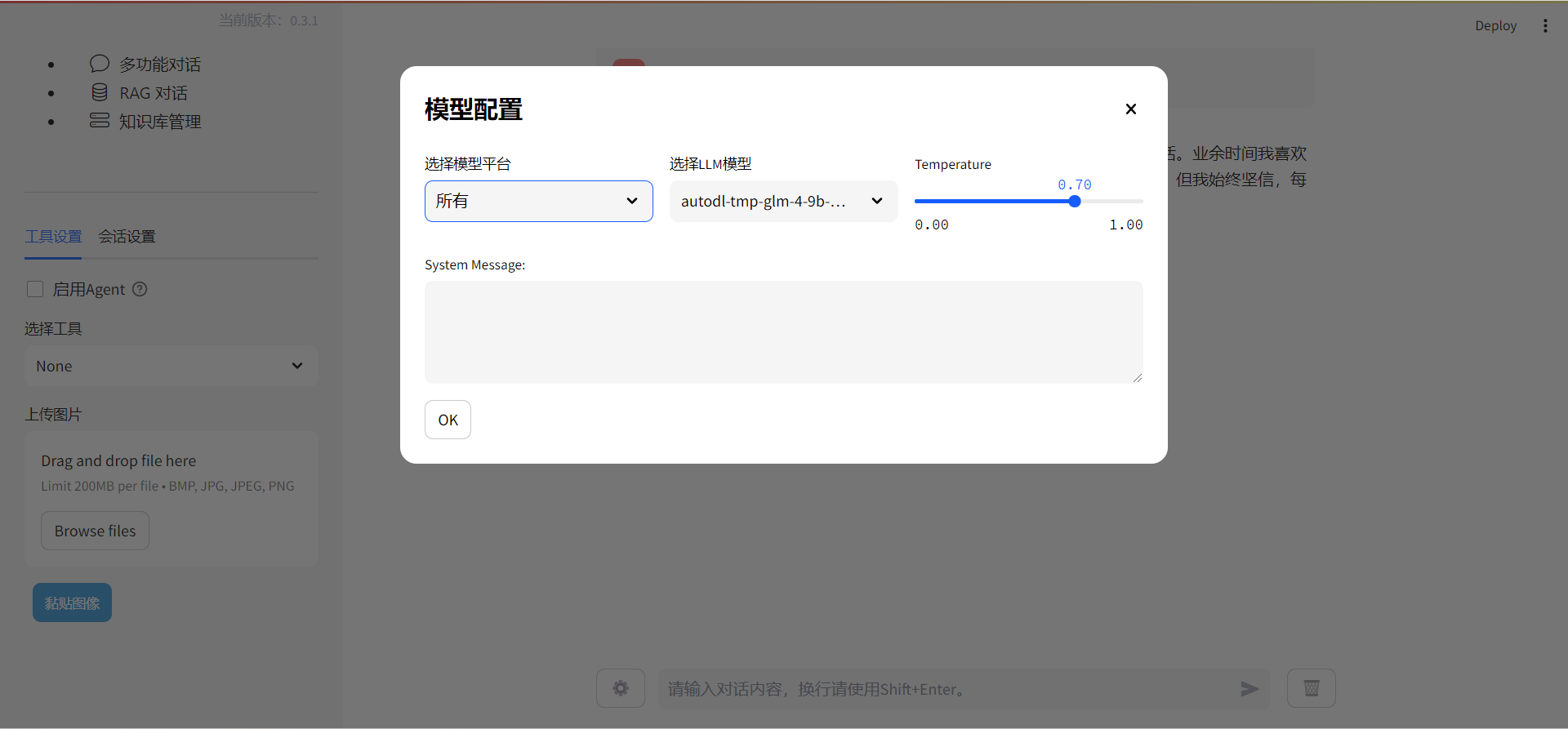
图中值得注意的是右边的Temperature,往左拉是更严谨,往右边拉是更具有创新,简单来说就是越往左,越死板,越往右,越灵活。
如果只是简单的提问,可以像我一样,直接让模型给出答案,比如我让模型续写一句话:

这里我没有给出任何限制,所以模型给出的一直是一个泛泛的例子,如果想要更多,比如我们可以加点限制:

可以看到,给出补充后,续写的内容更饱满,也有了主题。
在最新的langchain-chatchat版本中,我们还可以在左边自由选取不同的知识库,来限定答案的范围,这样,其实就已经是一个简单的从通用到垂直模型的转变了,只是它提前帮我们训练好了而已。但在实际的操作中,我们往往是用我们自己准备好的文件来圈定范围,一是我们所用的专业知识更全面,能够更好地训练模型,使其成为一个垂直于该领域的模型,二是能够减少模型的幻觉带来的错误答案,毕竟其接受的干扰信息更少。但这对我们内部给出的文件要求比较高,也就是我们在学习R语言时所说的数据清洗,在大模型方向明确的情况下,其要投入的精力和资源会更加恐怖。
而像我们前面提到的agent,也是同理,只不过是换成可以指定其指导模型使用对应的工具去查询,我们可以看看制定了用维基百科和不指定的结果:
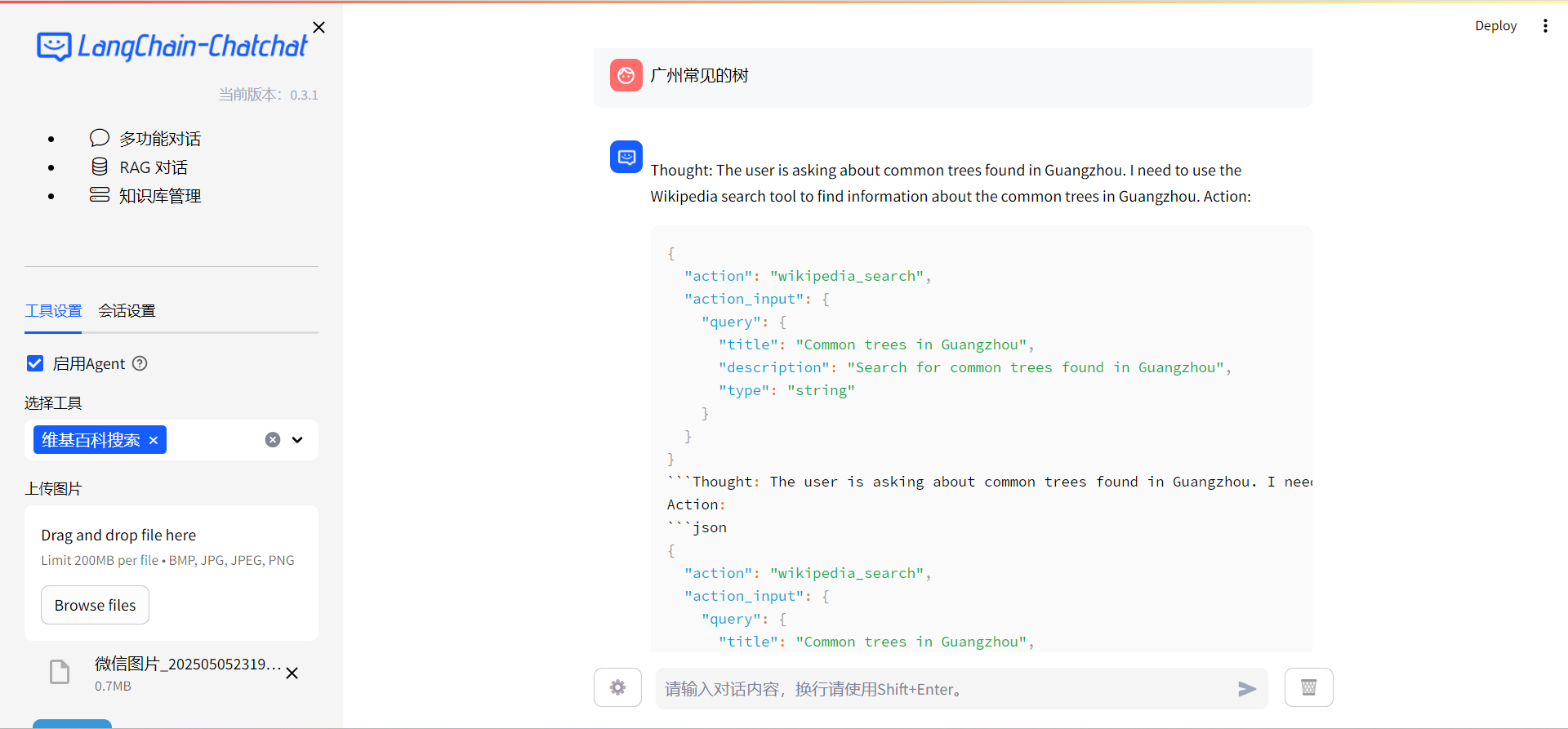
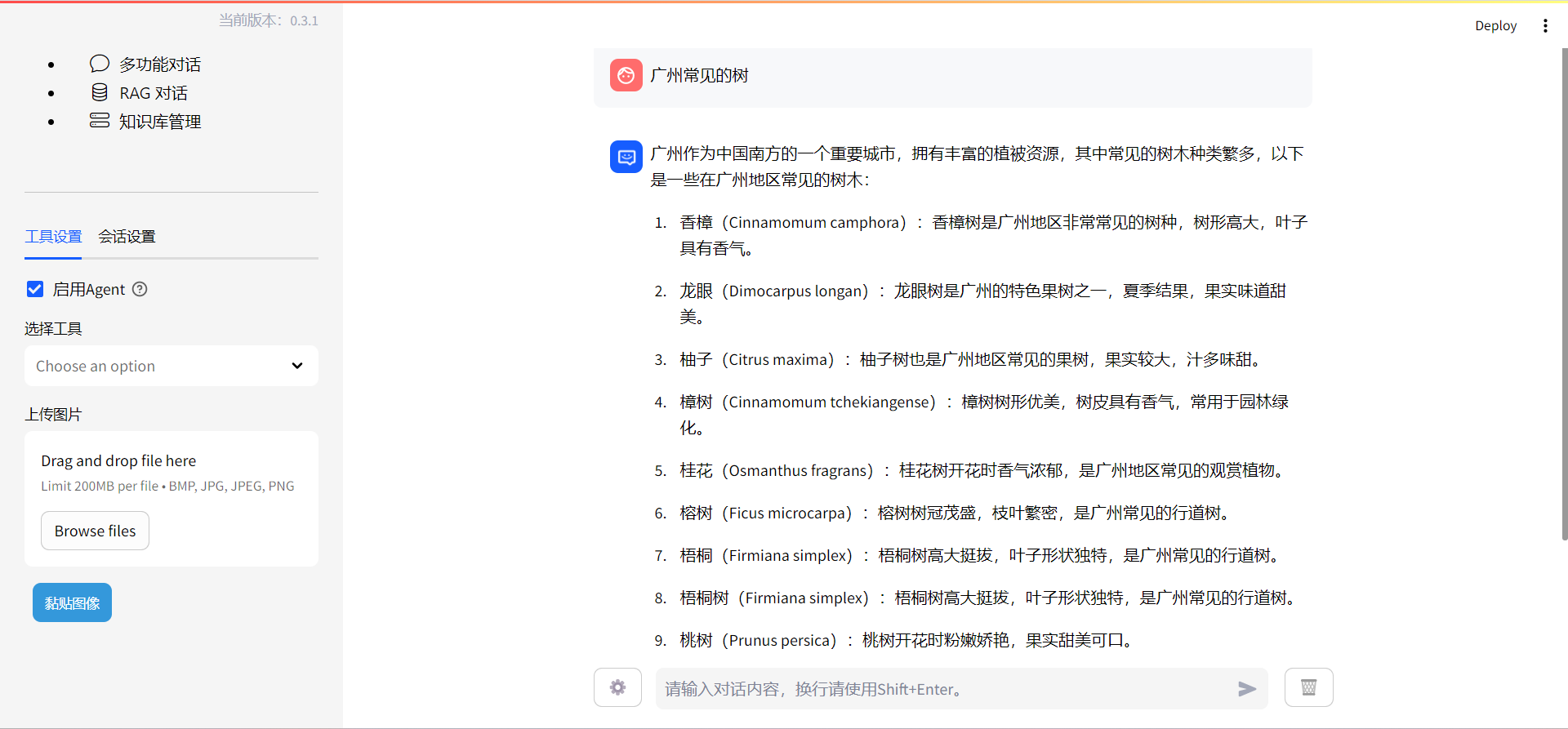
其实这里我们就能看得出,一个通用的大模型,和我们给了方向和限定的大模型,思考的答案是不一样的,解决问题的方式也不一样,所以,我们使用大模型时就要进行微调,这也是下一章节的内容。
学习来源于B站教程:【进阶篇】05.Chatglm2+langchain(参数调节和配置)_哔哩哔哩_bilibili