HunyuanVideo:大规模视频生成模型的系统性框架
- 引言
- HunyuanVideo 项目概述
- 核心技术
- 1. 统一的图像和视频生成架构
- 2. 多模态大语言模型(MLLM)文本编码器
- 3. 3D VAE
- 4. 提示重写(Prompt Rewrite)
- 项目运行方式与执行步骤
- 1. 环境准备
- 2. 安装依赖
- 3. 下载预训练模型
- 4. 单 GPU 推理
- 使用命令行
- 运行 Gradio 服务器
- 5. 多 GPU 并行推理
- 6. FP8 推理
- 执行报错与问题解决
- 1. 显存不足
- 2. 环境依赖问题
- 3. 模型下载问题
- 相关论文与研究
- 1. 扩散模型(Diffusion Models)
- 2. Transformer 架构
- 3. 3D 变分自编码器(3D VAE)
- 4. 多模态大语言模型(MLLM)
- 总结
引言
随着人工智能技术的快速发展,视频生成领域正逐渐成为研究和应用的热点。视频生成技术能够根据文本描述生成相应的视频内容,广泛应用于视频创作、广告制作、教育娱乐等多个领域。腾讯的 HunyuanVideo 项目正是这一领域的前沿成果,它提供了一个系统性的框架,用于大规模视频生成模型的开发和应用。
HunyuanVideo 项目概述
HunyuanVideo 是一个开源的大规模视频生成模型框架,旨在推动视频生成技术的发展。该项目的核心目标是通过系统性的设计和优化,实现高效、高质量的视频生成。HunyuanVideo 的主要特点包括:
- 高性能:HunyuanVideo 在视频生成质量上达到了与领先闭源模型相当甚至更优的水平。
- 统一的图像和视频生成架构:通过 Transformer 设计和全注意力机制,实现图像和视频的统一生成。
- 多模态大语言模型(MLLM)文本编码器:使用预训练的 MLLM 作为文本编码器,提升文本特征的表达能力。
- 3D VAE:通过因果卷积 3D VAE 压缩视频和图像,显著减少后续扩散 Transformer 模型的 token 数量。
- 提示重写(Prompt Rewrite):通过提示重写模型,优化用户提供的文本提示,提升模型对用户意图的理解。
核心技术
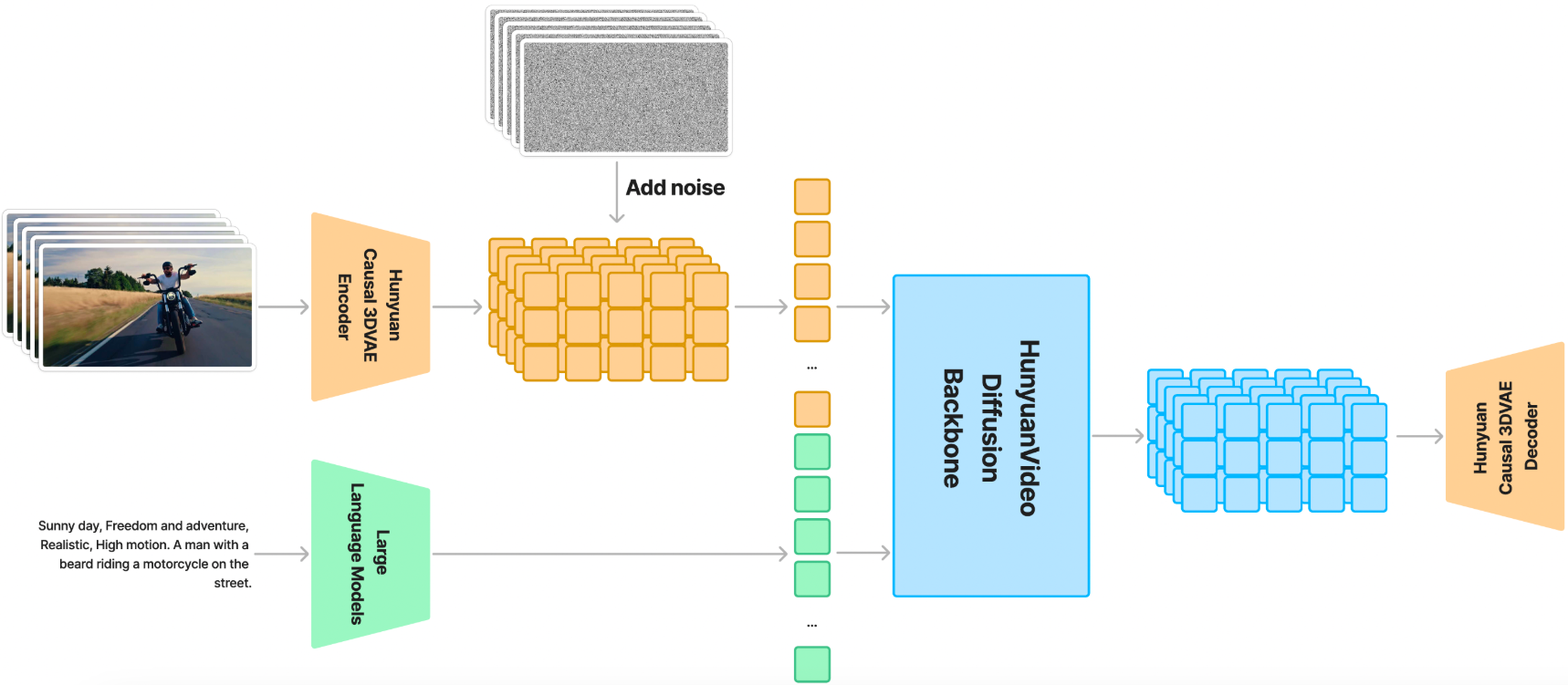
1. 统一的图像和视频生成架构
HunyuanVideo 引入了 Transformer 设计,采用全注意力机制实现图像和视频的统一生成。具体来说,HunyuanVideo 采用了“双流到单流”(Dual-stream to Single-stream)的混合模型设计。在双流阶段,视频和文本 token 通过多个 Transformer 块独立处理,使每种模态都能学习到自己的调制机制,避免相互干扰。在单流阶段,将视频和文本 token 连接起来,输入后续的 Transformer 块,实现有效的多模态信息融合。这种设计能够捕捉视觉和语义信息之间的复杂交互,提升模型的整体性能。
2. 多模态大语言模型(MLLM)文本编码器
HunyuanVideo 使用预训练的多模态大语言模型(MLLM)作为文本编码器,与传统的 CLIP 和 T5-XXL 文本编码器相比,具有以下优势:
- 更好的图像-文本对齐:MLLM 在视觉指令微调后,能够更好地对齐图像和文本的特征空间,减轻扩散模型中指令遵循的难度。
- 更强的图像细节描述和复杂推理能力:MLLM 在图像细节描述和复杂推理方面表现出色,优于 CLIP。
- 零样本学习能力:MLLM 可以作为零样本学习器,通过在用户提示前添加系统指令,帮助文本特征更关注关键信息。
此外,MLLM 基于因果注意力,而 T5-XXL 使用双向注意力,这使得 MLLM 为扩散模型提供了更好的文本引导。因此,HunyuanVideo 引入了一个额外的双向 token 优化器来增强文本特征。
3. 3D VAE
HunyuanVideo 使用因果卷积 3D VAE 压缩像素空间的视频和图像,将其转换为紧凑的潜在空间。具体来说,视频长度、空间和通道的压缩比分别设置为 4、8 和 16。这种压缩可以显著减少后续扩散 Transformer 模型的 token 数量,使模型能够在原始分辨率和帧率下训练视频。
4. 提示重写(Prompt Rewrite)
为了应对用户提供的文本提示在语言风格和长度上的多样性,HunyuanVideo 使用 Hunyuan-Large 模型微调的提示重写模型,将原始用户提示适应为模型偏好的提示。HunyuanVideo 提供了两种重写模式:普通模式(Normal mode)和大师模式(Master mode)。普通模式旨在增强视频生成模型对用户意图的理解,而大师模式则增强了对构图、灯光和镜头运动的描述,倾向于生成视觉质量更高的视频。然而,这种强调有时可能会导致一些语义细节的丢失。
项目运行方式与执行步骤
1. 环境准备
在开始运行 HunyuanVideo 之前,需要确保你的开发环境已经准备好。以下是推荐的环境配置:
- 操作系统:推荐使用 Linux,Windows 用户可能需要额外配置 WSL 或虚拟机。
- Python 版本:建议使用 Python 3.10 或更高版本。
- CUDA 和 GPU:确保你的系统安装了 CUDA,并且 GPU 驱动程序是最新的。推荐使用具有 80GB 内存的 GPU 以获得更好的生成质量。
2. 安装依赖
首先,需要克隆项目仓库并安装依赖项:
git clone https://github.com/Tencent/HunyuanVideo.git
cd HunyuanVideo
创建并激活 Conda 环境:
conda create -n HunyuanVideo python==3.10.9
conda activate HunyuanVideo
安装 PyTorch 和其他依赖项:
# For CUDA 11.8
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=11.8 -c pytorch -c nvidia
# For CUDA 12.4
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.4 -c pytorch -c nvidia
安装 pip 依赖项:
python -m pip install -r requirements.txt
安装 Flash Attention v2 以加速推理:
python -m pip install ninja
python -m pip install git+https://github.com/Dao-AILab/flash-attention.git@v2.6.3
安装 xDiT 用于多 GPU 并行推理:
python -m pip install xfuser==0.4.0
3. 下载预训练模型
HunyuanVideo 提供了多种预训练模型,可以通过以下链接下载:
- HunyuanVideo 模型权重
- HunyuanVideo FP8 模型权重
4. 单 GPU 推理
使用命令行
以下是一个简单的命令,用于在单 GPU 上运行视频生成任务:
cd HunyuanVideo
python3 sample_video.py \
--video-size 720 1280 \
--video-length 129 \
--infer-steps 50 \
--prompt "A cat walks on the grass, realistic style." \
--flow-reverse \
--use-cpu-offload \
--save-path ./results
运行 Gradio 服务器
你也可以运行一个 Gradio 服务器,通过 Web 界面进行视频生成:
python3 gradio_server.py --flow-reverse
5. 多 GPU 并行推理
HunyuanVideo 支持使用 xDiT 在多 GPU 上进行并行推理。以下是一个使用 8 个 GPU 的命令示例:
cd HunyuanVideo
torchrun --nproc_per_node=8 sample_video.py \
--video-size 1280 720 \
--video-length 129 \
--infer-steps 50 \
--prompt "A cat walks on the grass, realistic style." \
--flow-reverse \
--seed 42 \
--ulysses-degree 8 \
--ring-degree 1 \
--save-path ./results
6. FP8 推理
HunyuanVideo 还提供了 FP8 量化权重,可以显著减少 GPU 内存占用。以下是一个使用 FP8 权重的命令示例:
cd HunyuanVideo
DIT_CKPT_PATH={PATH_TO_FP8_WEIGHTS}/{WEIGHT_NAME}_fp8.pt
python3 sample_video.py \
--dit-weight ${DIT_CKPT_PATH} \
--video-size 1280 720 \
--video-length 129 \
--infer-steps 50 \
--prompt "A cat walks on the grass, realistic style." \
--seed 42 \
--embedded-cfg-scale 6.0 \
--flow-shift 7.0 \
--flow-reverse \
--use-cpu-offload \
--use-fp8 \
--save-path ./results
执行报错与问题解决
在运行 HunyuanVideo 项目时,可能会遇到一些常见的问题。以下是一些常见问题及其解决方法:
1. 显存不足
如果在运行时遇到显存不足的错误,可以尝试以下方法:
- 使用 CPU 卸载:通过
--use-cpu-offload参数将部分模型参数卸载到 CPU,减少 GPU 内存使用。 - 降低分辨率:降低生成视频的分辨率,例如从 720p 降低到 540p。
- 减少推理步数:通过调整
--infer-steps参数来减少推理步数。 - 使用 FP8 权重:使用 FP8 量化权重可以显著减少 GPU 内存占用。
2. 环境依赖问题
如果在安装依赖时遇到问题,可以尝试以下方法:
- 更新 pip 和 setuptools:确保 pip 和 setuptools 是最新版本。
- 手动安装依赖:对于某些依赖项,可以尝试手动安装,例如
torch和transformers。
3. 模型下载问题
如果在下载模型时遇到问题,可以尝试以下方法:
- 检查网络连接:确保你的网络连接正常,能够访问 Hugging Face。
- 手动下载模型:如果自动下载失败,可以手动下载模型文件并放置到指定目录。
相关论文与研究
HunyuanVideo 的开发基于多项前沿研究,其中一些关键的论文和技术包括:
1. 扩散模型(Diffusion Models)
扩散模型是一种基于噪声扩散和去噪过程的生成模型。其核心思想是通过逐步添加噪声将数据分布转换为先验分布,然后通过去噪过程恢复原始数据分布。HunyuanVideo 使用了扩散模型的框架,结合了 Flow Matching 技术,显著提高了生成视频的质量。
2. Transformer 架构
HunyuanVideo 的模型架构基于 Transformer,这种架构在自然语言处理和计算机视觉领域都取得了巨大成功。Transformer 的自注意力机制能够有效地捕捉长距离依赖关系,使其在视频生成任务中表现出色。
3. 3D 变分自编码器(3D VAE)
HunyuanVideo 使用因果卷积 3D VAE 压缩视频和图像,显著减少了后续扩散 Transformer 模型的 token 数量。这种压缩不仅加速了训练和推理过程,还与扩散过程对压缩表示的偏好相一致。
4. 多模态大语言模型(MLLM)
HunyuanVideo 使用预训练的多模态大语言模型(MLLM)作为文本编码器,显著提升了文本特征的表达能力。MLLM 在图像-文本对齐、图像细节描述和复杂推理方面表现出色,优于传统的 CLIP 和 T5-XXL 文本编码器。
总结
HunyuanVideo 项目以其卓越的性能、高效的实现方式和开源性,为视频生成领域提供了一个强大的工具。通过本文的详细介绍,读者可以全面了解 HunyuanVideo 的技术架构,并掌握如何在实际项目中应用这一模型。无论是研究人员还是开发者,都可以从 HunyuanVideo 中受益,推动视频生成技术的发展和应用。
未来,随着技术的不断进步,HunyuanVideo 有望在更多领域发挥更大的作用,为人类创造更加丰富多彩的视觉内容。