Qwen 模型学习笔记:RM、SFT 与 RLHF 技术解析
一、Qwen 模型概述
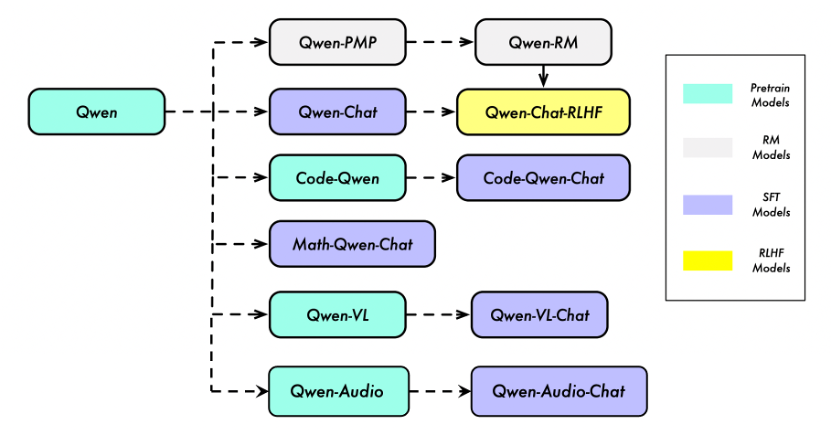
Qwen 是阿里巴巴开源的大型语言模型系列,旨在实现通用人工智能(AGI)。其架构包括基础语言模型(如 Qwen-7B、Qwen-14B、Qwen-72B)和经过后训练的对话模型(如 Qwen-Chat)。后训练主要通过 SFT 和 RLHF 技术进行,以提升模型的对齐性和实用性。
二、SFT(Supervised Fine-Tuning)有监督微调
1. 定义与目的
SFT 是在预训练模型的基础上,利用人工标注的数据集进行微调,使模型更好地理解和执行特定任务或指令。
2. 数据构建与训练策略
- 数据格式:采用 ChatML 格式,区分系统提示、用户输入和助手输出。
- 训练策略:使用 AdamW 优化器,学习率先增后恒定,序列长度限制在 2048,训练步数约 4000 步。
- 目标:使模型能够生成符合人类指令的回答,并具备一定的上下文理解能力。
3. 技术实现
Qwen 使用 MS-SWIFT 框架进行 SFT,支持 LoRA 等参数高效微调技术,兼容多种硬件平台,如 RTX、A100、Ascend NPU 等。
三、RM(Reward Model)奖励模型
1. 定义与作用
RM 是在 SFT 模型的基础上,通过人工标注的答案排名数据,训练一个模型来评估回答的质量,为后续的强化学习提供奖励信号。
2. 架构与训练
- 模型架构:去除 SFT 模型最后一层的 softmax,改为线性层,输入为问题和答案对,输出为一个标量分数。
- 训练数据:人工对多个答案进行排序,构成训练数据集。
- 损失函数:采用 Pairwise Ranking Loss,优化模型的评分能力。
3. 应用与效果
RM 模型能够有效地评估答案的质量,为 RLHF 提供可靠的奖励信号,提升模型生成内容的相关性和准确性。
四、RLHF(Reinforcement Learning from Human Feedback)基于人类反馈的强化学习
1. 定义与目的
RLHF 是通过人类反馈来优化模型的生成策略,使其生成的内容更符合人类的偏好和需求。
2. 训练流程
- 阶段一:使用 SFT 模型生成多个候选答案。
- 阶段二:利用 RM 对候选答案进行评分。
- 阶段三:根据评分结果,使用强化学习算法(如 PPO 或 DPO)调整模型参数,使其生成更优质的答案。
3. 技术实现
Qwen 在 RLHF 阶段,采用了 PPO(Proximal Policy Optimization)算法进行训练,优化模型的生成策略,提升其在对话中的表现。
Qwen2 模型学习笔记:
一、引言
在大语言模型蓬勃发展的当下,Qwen 系列持续迭代更新,Qwen2 由此诞生。它基于 Transformer 架构,经过大规模预训练和优化,致力于提升语言理解、生成、多语言处理等多方面能力,推动 LLMs 技术进步。
二、分词器与模型架构
(一)分词器
Qwen2 沿用字节级字节对编码分词器,词汇表含 151,643 个常规词元与 3 个控制词元。该分词器把文本拆分成小片段即 “词元”,编码效率高,在多语言处理上优势明显,能高效拆分和编码多种语言文本。
具体实现
- 初始化词汇表:收集文本数据集中的字节序列构建初始词汇表。
- 统计字节对频率:遍历训练文本数据集,统计相邻字节对的出现频率。
- 合并高频字节对:将最高频的字节对合并为新词元,更新词汇表。
- 重复合并过程:持续统计和合并,直至达到预设词汇表大小或满足停止条件。
- 文本编码:按字节划分文本,依据词汇表替换为词元,特殊策略处理未知序列。
(二)模型架构
1. 密集模型
密集模型参数密集连接,采用分组查询注意力(GQA)优化推理,通过分组查询共享键和值计算,降低计算成本提升推理速度。结合双块注意力(DCA)与 YARN,扩展上下文窗口,增强长文本处理能力。
- 分组查询注意力(GQA):优化传统多头注意力,减少键值计算重复。
- 双块注意力(DCA)与 YARN:DCA 划分序列块,YARN 改进循环神经网络,协同扩展上下文窗口。
机制细节
- GQA 将查询分组,组内共享键值计算,在推理阶段减少重复运算,提升效率。
- DCA 将输入序列划分成多个块,块内和块间分别进行注意力计算,降低长序列计算复杂度。
- YARN 结合 DCA,使模型在不显著增加计算成本的情况下扩展上下文窗口长度,提升长文本处理能力。
2. 混合专家模型(MoE)
以多个 FFN 为专家,细粒度设计、合理路由及初始化策略,增强模型性能与适应性。
- FFN 专家:多个前馈神经网络作专家,各擅长不同类型信息处理。
- 细粒度专家设计:针对特定任务或数据特征设计专家,发挥专长。
- 合理专家路由:智能调度任务至合适专家,提高效率和准确性。
- 初始化策略:合理初始参数设置,助力模型快速收敛。
专家训练机制
- 数据准备:收集大规模相关数据,分为训练集、验证集和测试集。
- 初始化 FFN 专家:采用随机初始化或基于预训练模型的初始化。
- 定义损失函数:根据任务类型选择合适的损失函数,如分类任务用交叉熵损失函数,回归任务用均方误差损失函数。
- 前向传播:输入数据按 FFN 网络结构依次计算。
- 计算损失和反向传播:根据预测结果和真实标签计算损失,通过反向传播更新参数。
- 专家路由机制参与训练:路由机制根据输入特征学习分配输入至合适的 FFN 专家,引入可学习参数并根据反馈调整。
- 迭代训练:重复前向传播、计算损失和反向传播步骤,优化模型性能。
- 模型评估与调整:使用测试集评估性能,分析原因并调整模型,直至达到满意性能。
专家掌握不同知识的原因
- 细粒度专家设计:不同专家专注于特定任务或数据特征。
- 数据分布差异:专家接触到的数据子集存在差异,学习