KNN算法简介
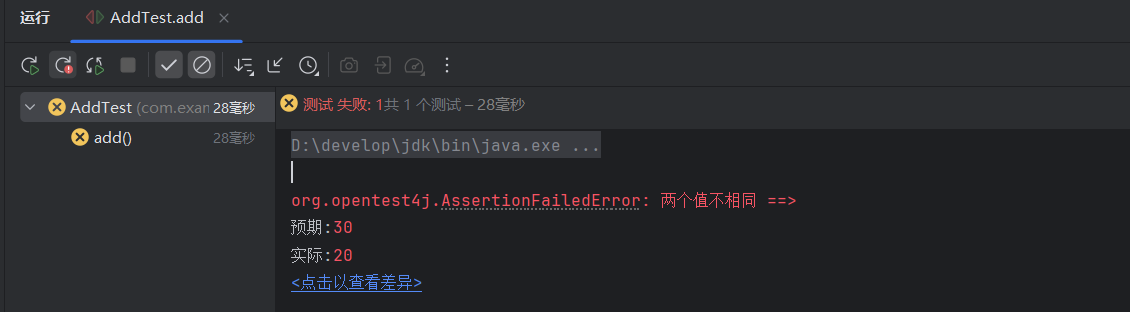
核心思想:通过样本在特征空间中k个最相似样本的多数类别来决定其类别归属。"附近的邻居确定你的属性"是核心逻辑
决策依据:采用"多数表决"原则,即统计k个最近邻样本中出现次数最多的类别
样本相似性度量
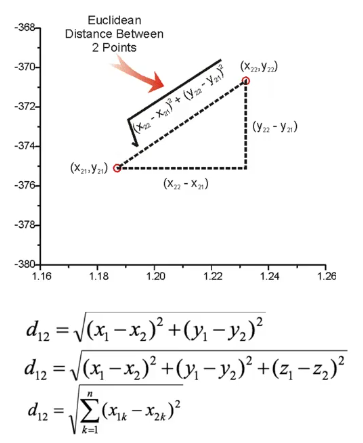
相似性定义:样本距离越近则越相似,距离计算是核心环节
欧式距离:
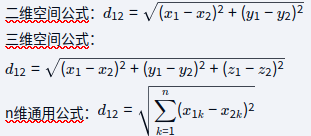
计算特点:采用"差方和开根号"的计算方式,是几何距离的直接推广
K值选择
当K值选择过小:用较小领域的训练实例进行预测
容易收到异常点的影响,K值的减小就意味着整体模型变得复杂,容易发生过拟合。
当K值选择过大:当k值过大时,参考范围过广,容易受到样本不均衡问题影响
导致欠拟合现象,模型变得过于简单,反应迟钝,可能忽略局部特征而偏向多数类
KNN算法
解决问题:分类问题、回归问题
算法思想:若一个样本在特征空间中的k个最相似的样本大多数属于某一个类别,则该样本也属于这个类别
相似性:欧式距离
KNN概括
- 算法类型: 有监督学习,可用于分类和回归
- 核心思想: "物以类聚"——相似样本具有相似属性
- 参数选择:
- 常用交叉验证和网格搜索方法确定最优k值
- 需要平衡过拟合和欠拟合问题
- 优缺点:
- 优点:简单直观,无需训练过程
- 缺点:计算量大,对不平衡数据敏感
KNN算法API使用
KNN分类API
n_neighbors:int,可选(默认=5) 选择最大的k值
from sklearn.neighbors import KNeighborsClassifier
def dm01_knnapi_classification():
estimator = KNeighborsClassifier(n_neighbors=1) # 初始化分类器
x=[[0],[1],[2],[3]]
y=[0,0,1,1]
estimator.fit(x,y)
myret=estimator.predict([[4]])
print(myret)
dm01_knnapi_classification()案例2
from sklearn.neighbors import KNeighborsClassifier
# 数据(特征工程)
# 分类
x=[[0,2,3],[1,3,4],[3,5,6],[4,7,8],[2,3,4]]
y=[0,0,1,1,0]
# 实例化模型
model=KNeighborsClassifier(n_neighbors=3)
# 模型训练
model.fit(x,y)
# 模型预测
print(model.predict([[4,4,5]])) KNN回归API
from sklearn.neighbors import KNeighborsRegressor
def dm02_knnapi_Regression():
estimator = KNeighborsRegressor(n_neighbors=2)
x = [[0, 0, 1], [1, 1, 0], [3, 10, 10], [4, 11, 12]]
y = [0.1, 0.2, 0.3, 0.4]
estimator.fit(x, y)
myret = estimator.predict([[2, 11, 10]])
print(myret)
dm02_knnapi_Regression()这个点与后两个点相近,就取这两个y点的平均值。
from sklearn.neighbors import KNeighborsRegressor
# 数据(特征工程)
# 回归
x=[[0,1,2],[1,2,3],[2,3,4],[3,4,5]]
y=[0.1,0.2,0.3,0.4]
# 实例化模型
model=KNeighborsRegressor(n_neighbors=3)
# 模型训练
model.fit(x,y)
# 模型预测
print(model.predict([[4,4,5]]))距离度量-常见距离公式
欧式距离
直观的距离度量方式,两个点在空间中的距离一般都是欧式距离
曼哈顿距离
也称为“城市街区距离”(City Block distance),曼哈顿城市特点:横平竖直

切比雪夫距离
国际象棋中国王的移动方式(可直行、横行、斜行)

闵可夫斯基距离
其不是一种新的距离的度量方式
是对多个距离度量公式的概括性的表述

特征预处理
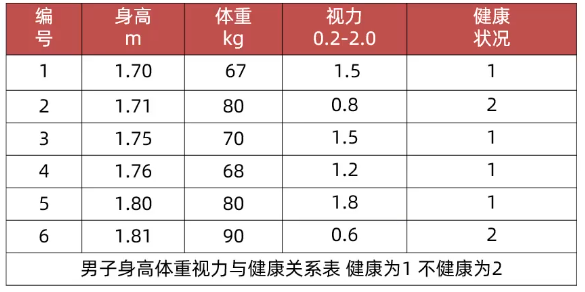
为什么要做归一化和标准化
当特征的单位或大小相差较大时,数值较大的特征会主导模型训练结果,导致模型无法有效学习其他特征。
若某特征的方差比其他特征大几个数量级,会严重影响目标结果,使模型产生偏差。
归一化
通过对原始数据进行变换把数据映射到[mi,mx](默认微[0,1]之间)
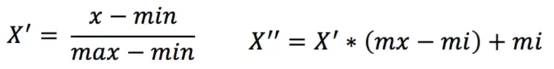
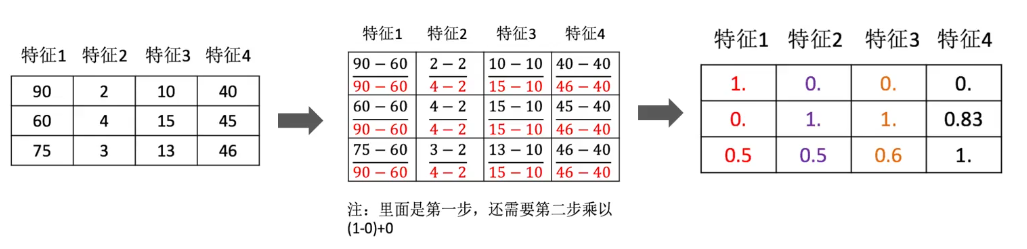
数据归一化API
sklearn.preprocessing.MinMaxScaler(feature_range=(0,1)...)
feature_range缩放区间
fit_transform(X): 同时计算统计量并执行转换
import numpy as np
from sklearn.preprocessing import MinMaxScaler
def dm01_MinMaxScaler():
# 1.准备数据
data=[[90,2,10,40],
[60,4,15,45],
[75,3,13,46]]
# 2.初始化归一化对象
transformer=MinMaxScaler()
# 3.对原始特征进行变换
data=transformer.fit_transform(data)
# 4.打印归一化后的结果
print(data)标准化
数据标准化:通过对原始数据进行标准化,转换为均值为0,标准差为1的标准正态分布的数据

数据标准化API
sklearn.preprocessing.StandardScaler()
fit_transform(x)将特征进行标准化缩放
from sklearn.preprocessing import StandardScaler
def dm03_StandardScaler():
# 1.准备数据
data=[[90,2,10,40],
[60,4,15,45],
[75,3,13,46]]
# 2.初始化标准化对象
transformer=StandardScaler()
#3.对原始特征进行转换
data=transformer.fit_transform(data)
# 4.打印标准化后的结果
print(data)
# 5.打印每一列数据的均值和方差
print("transformer.mean-->",transformer.mean_)
print("transformer.var-->",transformer.var_)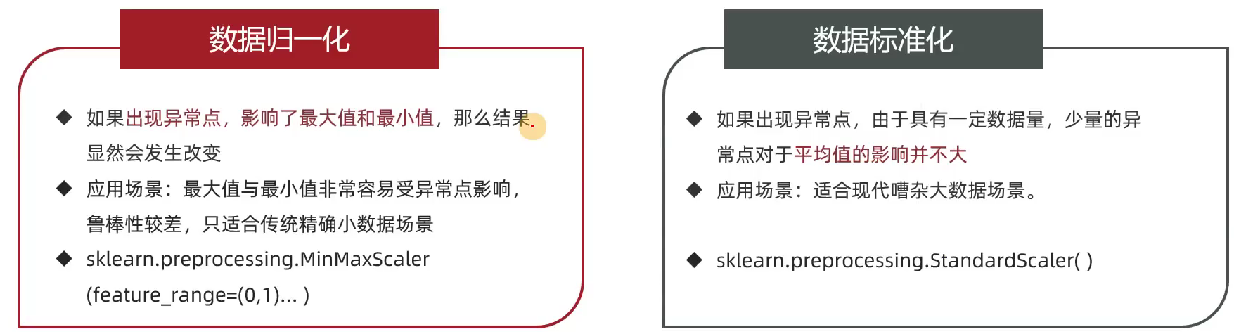
利用KNN算法对鸢尾花分类
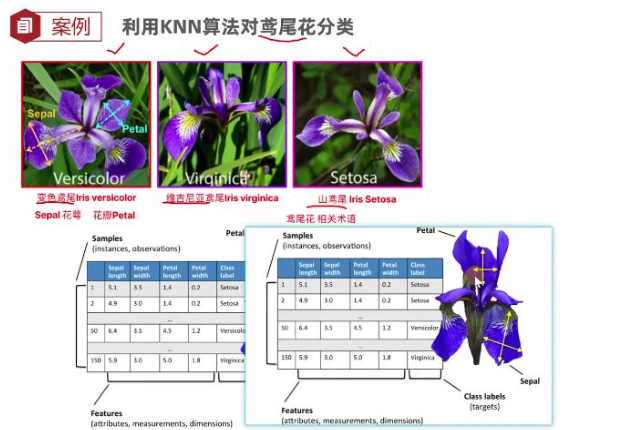
加载鸢尾花数据
# 利用KNN来对鸢尾花分类
from sklearn.datasets import load_iris
def dm01_loadiris():
# 加载数据集
mydataset=load_iris()
# 查看数据集信息
print('查看数据集信息>\n',mydataset.data[:5])
# 查看目标值
print("mydataset.target->\n",mydataset.target)
# 查看目标值名字
print('mydataset.target_names->',mydataset.target_names)
# 查看特征名
print('mydataset.feature_names->',mydataset.feature_names)
# 查看数据集描述
print('mydataset.DESCR->\n',mydataset.DESCR)
鸢尾花数据展示
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
# 显示鸢尾花数据
def dm02_showiris():
# 1载入鸢尾花数据集并显示特征名称feature_names
mydataset=load_iris()
print(mydataset.feature_names)
# 2把数据转化成dataframe格式,设置data,columns属性 目标值名称
iris_d=pd.DataFrame(mydataset['data'],columns=mydataset.feature_names)
iris_d['label']=mydataset.target
print('\niris_d-->\n',iris_d)
col1='sepal length (cm)'
col2='sepal width (cm)'
# 3sns.lmplot()显示
sns.lmplot(x=col1,y=col2,data=iris_d,hue='label',fit_reg=False)
plt.xlabel(col1)
plt.ylabel(col2)
plt.title('iris')
plt.show()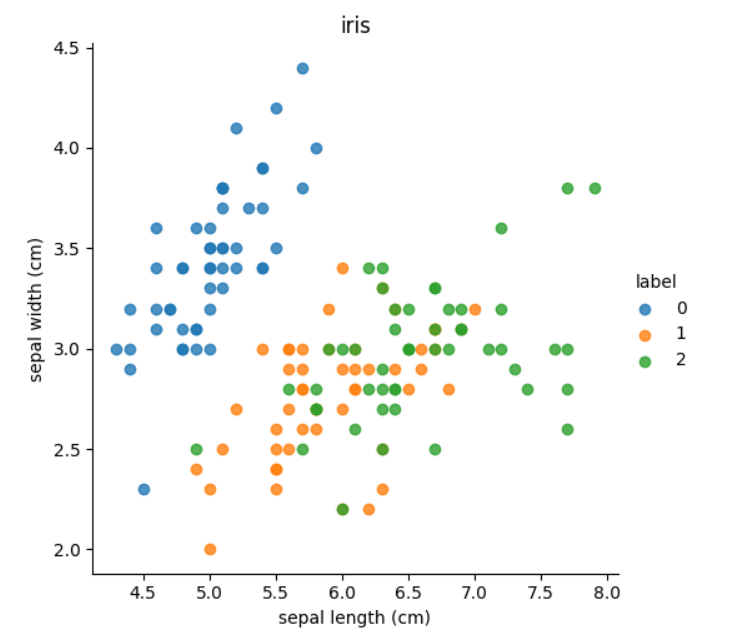
数据集划分
from sklearn.model_selection import train_test_split
# 数据集划分
def dm03_traintest_split():
# 1.加载数据集
mydataset=load_iris()
#2.划分数据集
x_train,x_test,y_train,t_test=train_test_split(mydataset.data,mydataset.target,test_size=0.3,random_state=22)
print("数据总数量",len(mydataset.data))
print('训练集中的x-特征值',len(x_train))
print('测试集中的x-特征值',len(x_test))
print(y_train)模型训练和预测
def dm04():
#1 获取训练集
mydataset=load_iris()
# 2 数据基本处理
x_train,x_test,y_train,y_test=train_test_split(mydataset.data,mydataset.target,test_size=0.2,random_state=22)
# 3 数据集预处理-数据标准化
transfer=StandardScaler()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)
# 模型训练
estimator=KNeighborsClassifier(n_neighbors=3)
estimator.fit(x_train,y_train)
# 模型评估 直接计算准确率100个样本中模型预测对了多少
myscore=estimator.score(x_test,y_test)
print('myscore->',myscore)
#模型预测需要对带预测数据,只是标准化
mydata=[[5.1,3.5,1.4,0.2],
[4.6,3.1,1.5,0.2]]
mydata=transfer.transform(mydata)
mypred=estimator.predict(mydata)
print('mypred->\n',mypred)
mypred=estimator.predict_proba(mydata)
print('mypred-->\n',mypred)超参数选择方法
交叉验证
是一种数据集的分割方式,将训练集划分为n份,拿一份做验证集(测试集),其他n-1份做训练集
原理
将数据集划分为cv=4份
- 第一次:第1份为验证集,其余为训练集
- 第二次:第2份为验证集,其余为训练集
- 循环完成所有划分组合(共4次训练评估)
- 取多次评估的平均值作为最终模型得分
最优模型确认:若k=5模型得分最好,则用全部数据(训练+验证集)重新训练k=5模型,最后用独立测试集评估
网格搜索
为什么需要网格搜索
模型存在大量超参数(如KNN的k值),不同参数组合性能差异显著,预先设置多组超参数(如
k=2/5/7),每组都通过交叉验证评估
- 自动化遍历预设参数空间(如循环测试k从1到20)
- 避免人工单次试验的低效性
网格搜索和交叉验证的强力组合
- 分工协作:
- 交叉验证:解决数据划分问题,确保评估可靠性
- 网格搜索:解决超参数组合优化问题
- 工程实践意义:
- 数据优化:通过交叉验证确定最佳数据划分方式
- 模型优化:通过网格搜索确定最优超参数组合
交叉验证网格搜索API介绍
sklearn.model_selection.GridSearchCV(estimator, param_grid=None, cv=None)
- estimator:需要传入实例化后的模型对象
- param_grid:以字典形式传入超参数组合,例如:{'n_neighbors':[1,3,5]}
- cv:指定交叉验证的折数(如cv=5表示五折交叉验证)
核心返回值
- best_score_:交叉验证中得到的最佳评分
- best_estimator_:包含最优参数的模型对象
- cv_results_:记录每次交叉验证的验证集和训练集准确率结果