本博文将教会你如何通过神经网络建立股票模型并对其进行未来趋势估计,尽管博主已通过此方法取得一定利润,但是建议大家不要过分相信AI。本博文仅用于代码学习,请大家谨慎投资。
一、通过爬虫爬取股票往年数据
在信息爆炸的当今时代,股票市场数据蕴含着无尽的价值,而要获取某只股票的往年信息,网络爬虫无疑是一把锋利的利器。首先,得确定目标网站,通常财经类的专业网站、股票交易平台等会存储着海量的股票历史数据,像新浪财经、东方财富网等,这些网站上汇聚了众多股票多年来的开盘价、收盘价、最高价、最低价、成交量等关键信息,宛如一座座数据的宝库等待挖掘。
在选定目标后,便要开展准备工作。得先分析网站的结构,利用浏览器的开发者工具,查看股票数据所在页面的 HTML 代码,识别出存放股票历史数据的表格或标签元素,明确其层级关系和特征属性,这是爬虫精准定位数据的依据。同时,要研究网站的反爬虫机制,部分网站会设置诸如验证码、限制访问频率、要求特定的请求头信息等障碍,这时就需要针对性地制定策略,比如模拟浏览器访问,设置合适的请求头,包括 User - Agent、Referer 等,伪装成正常的浏览器请求,以降低被封禁的风险。
import tushare as ts
import pandas as pd
# 设置 tushare 的 API Token
ts.set_token('your_api_token') # 替换为你的 API Token
# 初始化 tushare 的 API 客户端
pro = ts.pro_api()
# 设置股票代码
stock_code = "000001.SZ" # 平安银行的股票代码(深圳证券交易所)
# 获取股票基础数据
stock_basic = pro.stock_basic(ts_code=stock_code)
print("股票基础数据:")
print(stock_basic)
# 获取股票日线数据(过去 365 天)
df = pro.daily(ts_code=stock_code, start_date='20220101', end_date='20221231')
print("\n股票日线数据(过去 365 天):")
print(df)
# 获取股票复权数据
df_adj = pro.daily_basic(ts_code=stock_code, start_date='20220101', end_date='20221231')
print("\n股票复权数据(过去 365 天):")
print(df_adj)
# 将数据保存到 CSV 文件
df.to_csv("stock_daily_data.csv", index=False)
df_adj.to_csv("stock_adj_data.csv", index=False)
# 打印完成信息
print("\n数据已保存到 stock_daily_data.csv 和 stock_adj_data.csv 文件中")接下来就进入爬虫代码的编写阶段。以 Python 为例,借助强大的第三方库 requests 来发送网络请求,获取网页的 HTML 内容。不过仅仅获取到网页代码还不够,要从里面提取出有价值的股票,信息这就需要用到正则表达式或者更高效的数据解析库如 BeautifulSoup 或 lxml。利用这些工具,依据之前分析好的 HTML 结构,精准地解析出股票的往年数据,像是指定日期下的价格变动情况、交易量等细节。在成功爬取到数据后,后续的数据存储也至关重要。可以将这些数据存储到本地的 CSV 文件,方便后续用 Excel 等工具进行查看和简单分析;或者存储到数据库中,像 MySQL、MongoDB 等,便于进行更复杂的数据查询、统计分析等操作,从而为后续研究深入股票走势、把握投资机会提供坚实的数据基础。整个过程需要耐心、细致地处理各个环节,让爬虫得以顺利穿梭于网络的海洋,将散落的股票往年信息一一收集归拢。
二、使用深度学习训练股票模型
在金融领域,股票市场预测一直是一个极具挑战性但又极具吸引力的研究课题。随着人工智能技术的飞速发展,深度学习为股票预测提供了一种全新的思路和方法。深度学习是一种基于人工神经网络的机器学习技术,它通过构建多层的神经网络结构,能够自动从大量数据中学习到复杂的模式和特征,从而实现对股票市场的预测。

深度学习训练股票模型的第一步是数据收集与预处理。股票市场数据通常包括开盘价、收盘价、最高价、最低价、成交量等多种指标,这些数据可以从金融数据提供商或者是公开的金融市场数据接口中获取。但需要注意的是,原始的股票数据往往存在着缺失值、噪声等问题,因此需要进行清洗和预处理。比如,对缺失值可以通过插值等方法进行填充,对噪声数据可以通过平滑滤波等手段进行处理。此外,为了使数据深度适合学习模型的训练,还需要进行归一化或者标准化等操作,将数据缩放到一定的范围,如 [0,1] 或者 [-1,1]。接下来就是模型的选择与构建。常用的深度学习模型在股票预测中都有应用,例如循环神经网络(RNN)及其变体长短时记忆网络(LSTM)和门控循环单元(GRU)。这些模型在处理时间序列数据方面具有优势,因为股票数据本质上是一种时间序列数据,其未来的走势在一定程度上受到过去历史数据的影响。LSTM 和 GRU 通过巧妙的门控结构,能够更好地捕捉长期依赖关系,从而在股票预测中表现出较好的性能。另外,卷积神经网络CNN()也可以用于股票预测,它可以通过卷积操作提取数据中的局部特征,对于股票数据中的短期波动模式进行捕捉。还有近年来兴起的 Transformer 架构,它依靠自注意力机制,在处理序列数据时能够同时考虑序列中的各个位置的信息,在一些复杂的股票预测任务中也展现出了强大的能力。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
# 设置股票代码和数据路径
stock_code = "000001" # 平安银行的股票代码
data_path = "stock_daily_data.csv" # 假定股票数据已经保存为 CSV 文件
# 加载股票数据
df = pd.read_csv(data_path)
df['date'] = pd.to_datetime(df['date'], format='%Y%m%d')
df.set_index('date', inplace=True)
# 提取收盘价作为目标变量
prices = df['close'].values.reshape(-1, 1)
# 数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_prices = scaler.fit_transform(prices)
# 创建时间序列数据集
def create_dataset(dataset, time_step=60):
dataX, dataY = [], []
for i in range(len(dataset) - time_step - 1):
a = dataset[i:(i + time_step), 0]
dataX.append(a)
dataY.append(dataset[i + time_step, 0])
return np.array(dataX), np.array(dataY)
time_step = 60 # 使用过去 60 天的数据来预测下一天的价格
X, y = create_dataset(scaled_prices, time_step)
# 划分训练集和测试集
train_size = int(len(X) * 0.8)
test_size = len(X) - train_size
X_train, X_test = X[0:train_size], X[train_size:len(X)]
y_train, y_test = y[0:train_size], y[train_size:len(y)]
# 重构输入数据的形状 [samples, time steps, features]
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)
# 构建 LSTM 模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(time_step, 1)))
model.add(Dropout(0.2))
model.add(LSTM(units=50, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=50))
model.add(Dropout(0.2))
model.add(Dense(units=1))
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
model.fit(X_train, y_train, epochs=50, batch_size=32, validation_split=0.1)
# 预测
train_predict = model.predict(X_train)
test_predict = model.predict(X_test)
# 反归一化
train_predict = scaler.inverse_transform(train_predict)
y_train = scaler.inverse_transform(y_train.reshape(-1, 1))
test_predict = scaler.inverse_transform(test_predict)
y_test = scaler.inverse_transform(y_test.reshape(-1, 1))
# 计算均方根误差(RMSE)
train_rmse = np.sqrt(np.mean((train_predict - y_train)**2))
test_rmse = np.sqrt(np.mean((test_predict - y_test)**2))
print(f"训练集 RMSE: {train_rmse}")
print(f"测试集 RMSE: {test_rmse}")
# 绘制结果
plt.figure(figsize=(16, 8))
plt.plot(df.index[time_step + 1:], y_test, label='真实价格')
plt.plot(df.index[time_step + 1:], test_predict, label='预测价格')
plt.xlabel('日期')
plt.ylabel('价格')
plt.title('股票价格预测')
plt.legend()
plt.show()在确定了深度学习模型的类型之后,就需要进行模型的搭建。以 LSTM 为例,首先需要确定网络的层数和每层的神经元数量。一般来说,较浅的网络可能无法充分学习到数据中的复杂特征,而过深的网络又可能会导致训练困难和过拟合等问题。因此,通常会通过实验来确定网络合适的结构。然后,还需要选择合适的激活函数,如 ReLU、sigmoid、tanh 等,激活函数能够为网络引入非线性,使模型具备更强的拟合能力。同时,还需要考虑添加正则化项,如 L1 或 L2 正则化,以及采用 Dropout 等技术来防止模型过拟合,提高模型的泛化能力。在模型搭建完成后,紧接着就是训练过程。训练深度学习模型通常需要用到大量的历史股票数据,将数据分为训练集、验证集和测试集。在训练过程中,使用训练集数据来更新模型的参数,通过定义损失函数来衡量模型的预测结果与真实值之间的差异。常用的损失函数回归在问题中如均方误差(MSE)、平均绝对误差(MAE)等,在分类问题中如交叉熵损失等。然后,通过优化算法,如随机梯度下降(SGD)、Adam 等,来最小化损失函数,从而使得模型在训练数据上能够尽可能准确地进行预测。在训练过程中,还需要不断地在验证集上对模型进行评估,根据验证集的性能来调整模型的超参数,如学习率、批量大小等,以寻找最优的模型参数配置。
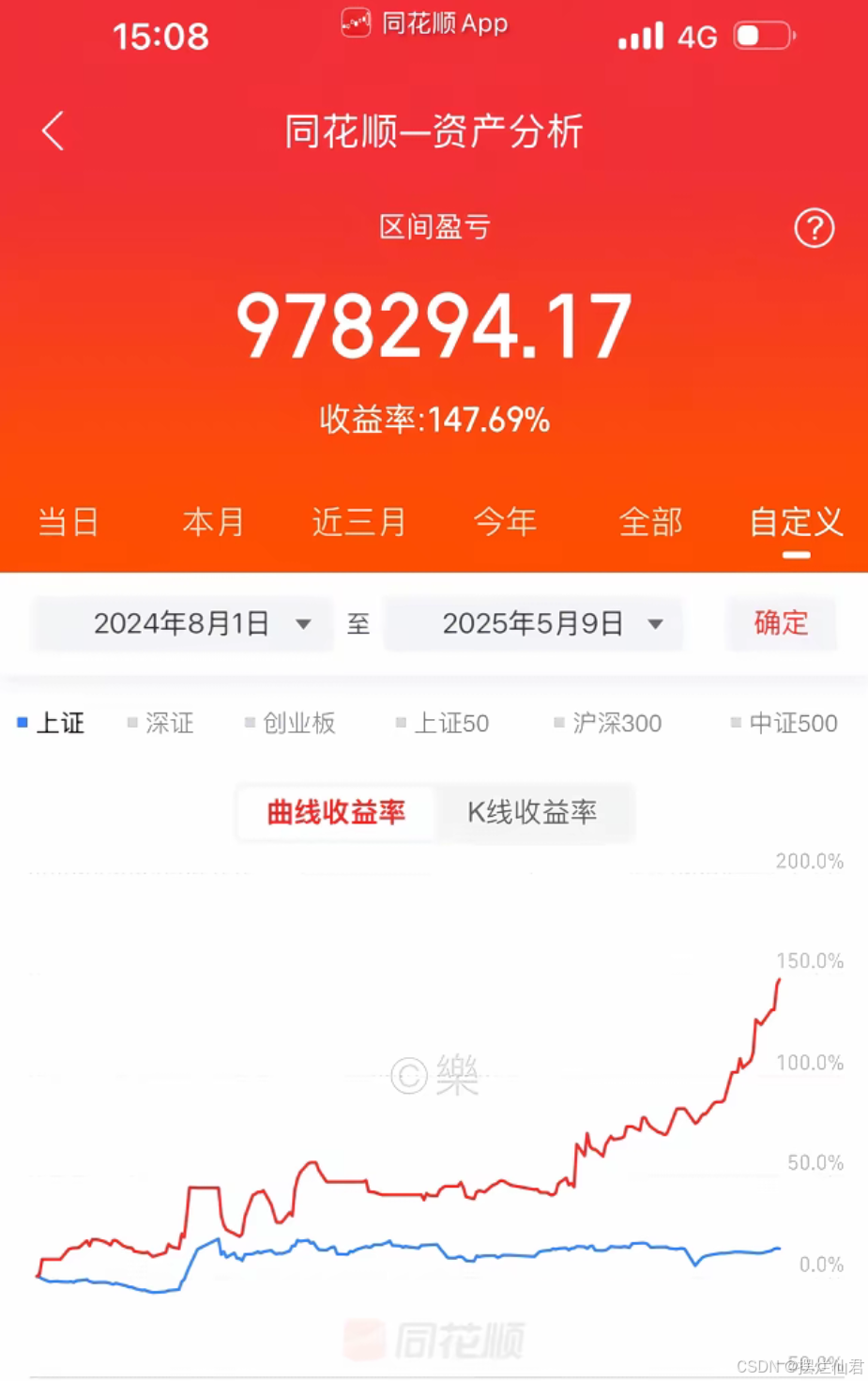
经过一定时间的训练后,当模型在训练集和验证集上的性能都较为稳定且达到预期的效果时,就可以使用测试集来对模型的最终性能进行评估。测试集的结果能够在一定程度上反映模型在实际股票市场预测中的表现,但需要注意的是,股票市场的复杂性和不确定性使得即使是性能较好的模型也无法保证在实际应用中能够始终准确地预测股票的走势。因此,在使用深度学习模型进行股票预测时,还需要结合其他因素和分析方法,如基本面分析、技术分析等,以及密切关注市场动态和宏观经济环境的变化,以做出更为合理的投资决策。
三、对这支股票的未来趋势进行估计
从技术分析的角度来看,我们可以通过观察股票的历史价格走势和交易量等数据,运用各种技术指标来推测其未来可能的走势。例如,移动平均线是一种常用的技术分析工具,短期移动平均线向上穿过长期移动平均线时,通常被视为看涨信号,而向下穿过则可能暗示股价将下跌。相对强弱指标(RSI)可以帮助我们判断股票是否处于超买或超卖状态,当 RSI 值超过 70 时,股票可能被高估,有回调风险;当 RSI 低于 30 时,股票可能被低估,存在上涨机会。此外,趋势线、支撑位和阻力位等概念也常用于技术分析中,股价在支撑位附近可能会获得支撑而反弹,在阻力位附近则可能遇阻回落。通过对这些技术指标的综合分析,我们可以对股票的短期走势形成一定的判断。
基本面分析则侧重于考察与股票相关的公司自身情况以及行业环境。公司的财务状况是基本面分析的核心内容之一,包括营业收入、净利润、资产负债表、现金流量表等数据。连续增长的营业收入和净利润往往表明公司具有良好的盈利能力和发展前景,这对股票价格通常是积极的信号。同时,公司的负债水平、偿债能力和现金流状况也会影响其股价表现。除了财务数据,公司的管理团队、竞争优势、行业地位以及所处行业的发展趋势等也是基本面分析的重要考量因素。例如,一家拥有优秀管理团队和强大技术壁垒的企业,在行业快速发展的情况下,其股票可能会更具投资价值。如果整个行业面临政策利好或市场需求增长,那么该行业内的股票整体上可能会呈现出上升的趋势。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
import tushare as ts
# 设置 Tushare API Token
ts.set_token('your_api_token') # 替换为你的 API Token
pro = ts.pro_api()
# 设置股票代码和时间范围
stock_code = "000001.SZ" # 平安银行的股票代码
start_date = "20180101"
end_date = "20230101"
# 获取股票日线数据
df = pro.daily(ts_code=stock_code, start_date=start_date, end_date=end_date)
df['trade_date'] = pd.to_datetime(df['trade_date'], format='%Y%m%d')
df.set_index('trade_date', inplace=True)
df = df.sort_index()
# 提取收盘价作为目标变量
prices = df['close'].values.reshape(-1, 1)
# 数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_prices = scaler.fit_transform(prices)
# 创建时间序列数据集
def create_dataset(dataset, time_step=60):
dataX, dataY = [], []
for i in range(len(dataset) - time_step - 1):
a = dataset[i:(i + time_step), 0]
dataX.append(a)
dataY.append(dataset[i + time_step, 0])
return np.array(dataX), np.array(dataY)
time_step = 60 # 使用过去 60 天的数据来预测下一天的价格
X, y = create_dataset(scaled_prices, time_step)
# 划分训练集和测试集
train_size = int(len(X) * 0.8)
test_size = len(X) - train_size
X_train, X_test = X[0:train_size], X[train_size:len(X)]
y_train, y_test = y[0:train_size], y[train_size:len(y)]
# 重构输入数据的形状 [samples, time steps, features]
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1], 1)
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1], 1)
# 构建 LSTM 模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(time_step, 1)))
model.add(Dropout(0.2))
model.add(LSTM(units=50, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(units=50))
model.add(Dropout(0.2))
model.add(Dense(units=1))
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
history = model.fit(X_train, y_train, epochs=50, batch_size=32, validation_split=0.1)
# 预测
train_predict = model.predict(X_train)
test_predict = model.predict(X_test)
# 反归一化
train_predict = scaler.inverse_transform(train_predict)
y_train = scaler.inverse_transform(y_train.reshape(-1, 1))
test_predict = scaler.inverse_transform(test_predict)
y_test = scaler.inverse_transform(y_test.reshape(-1, 1))
# 计算均方根误差(RMSE)
train_rmse = np.sqrt(np.mean((train_predict - y_train)**2))
test_rmse = np.sqrt(np.mean((test_predict - y_test)**2))
print(f"训练集 RMSE: {train_rmse}")
print(f"测试集 RMSE: {test_rmse}")
# 绘制训练损失和验证损失
plt.figure(figsize=(12, 6))
plt.plot(history.history['loss'], label='训练损失')
plt.plot(history.history['val_loss'], label='验证损失')
plt.title('模型训练损失')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
# 绘制预测结果
plt.figure(figsize=(16, 8))
plt.plot(df.index[time_step + 1:], y_test, label='真实价格')
plt.plot(df.index[time_step + 1:], test_predict, label='预测价格')
plt.xlabel('日期')
plt.ylabel('价格')
plt.title('股票价格预测')
plt.legend()
plt.show()
# 使用最后 60 天的数据来预测未来趋势
last_60_days = scaled_prices[-time_step:].reshape(1, time_step, 1)
future_predict = model.predict(last_60_days)
future_price = scaler.inverse_transform(future_predict)
print(f"未来预测价格: {future_price[0][0]}")
# 绘制未来趋势预测
plt.figure(figsize=(16, 8))
plt.plot(df.index[-time_step:], scaler.inverse_transform(scaled_prices[-time_step:]), label='过去 60 天价格')
plt.plot(pd.date_range(start=df.index[-1], periods=10, closed='right'),
[future_price[0][0]] * 10, label='未来趋势预测', linestyle='--')
plt.xlabel('日期')
plt.ylabel('价格')
plt.title('股票未来趋势预测')
plt.legend()
plt.show()宏观市场环境同样是影响股票未来趋势的重要因素。经济周期的不同阶段对股票市场的影响截然不同,在经济繁荣时期,企业盈利普遍增长,股票市场往往表现出色;而在经济衰退时,股市可能会面临较大的下行压力。货币政策和利率水平也与股票市场密切相关,宽松的货币政策和低利率环境通常有利于股票市场,因为企业融资成本降低、资金流动性增强,投资者也更倾向于将资金从债券等固定收益资产转移到股票市场。此外,国际政治局势、贸易关系、通货膨胀率等宏观因素也会对股票市场产生不同程度的影响。例如,地缘政治紧张局势可能导致市场避险情绪上升,资金流向黄金等避险资产,从而对股票价格产生负面影响。