部署结构
Kafka 使用zookeeper来协商和同步,但是kafka 从版本3.5正式开始deprecate zookeeper, 同时推荐使用自带的 kraft. 而从4.0 开始则不再支持 zookeeper。
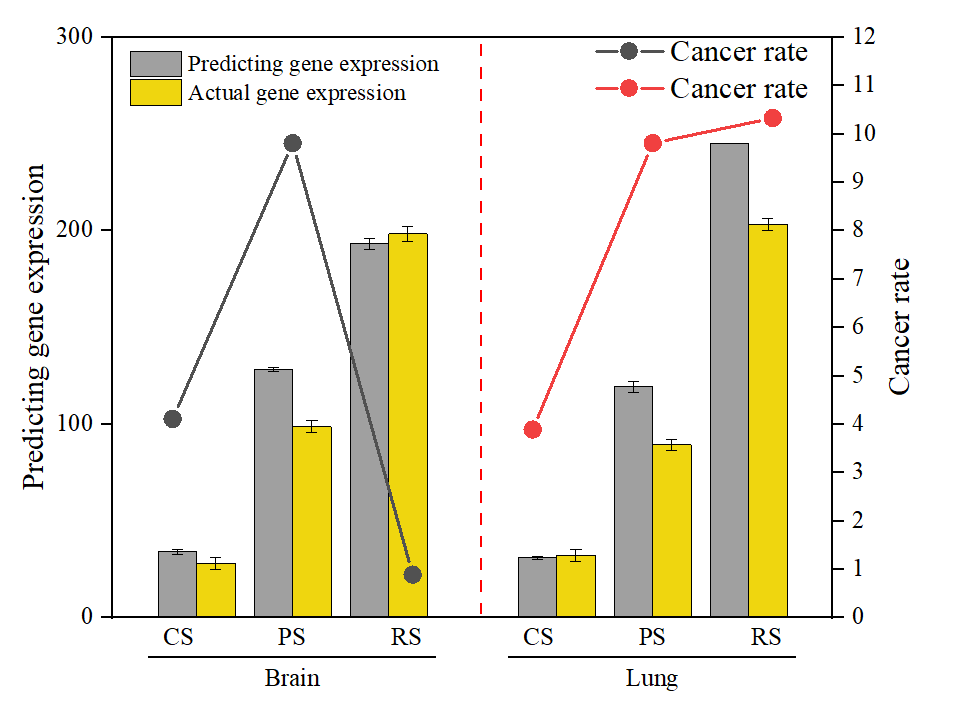
所以 kafka 是有control plane 和 data plane 的。
data plane 就是broker,control plane 旧的就是zookeeper,新的是 kRaft contorller。
kafka cluster的节点(broker)是没有leader 和 follower 之分的。
只是存储messages 的 topic partition 有。
Client只能connect partition 的leader 来写和读。

kafka 术语
Kafka brokers: Brokers refer to each of the nodes in a Kafka cluster
The broker.id property is the unique and permanent name of each node in the cluster
Record:Records are also called messages or events. A Kafka record consists of headers, a key, a value, and a timestamp.
Headers contain metadata consisting of string-value pairs, which can be read by consumers in order to make decisions based on the metadata. Headers are optional.
Key and value pairs in a Kafka record contains data relevant to your business. The key may have some structure, and can be a string, an integer, or some compound value. The value is structured and is likely an object to be serialized.
Every Kafka record has a timestamp. If you don’t provide one, one is provided by default.
Message streams are persistent in Kafka. This means that messages do not disappear once received. This is in contrast with classic “pub-sub” systems such as JMS, which as soon as the message is received by the subscriber, is removed from the system. In Kafka, message retention periods are configurable, usually based on a length of time or the size of the underlying storage.
kafka 的message 是可以被多次消费的,不是消费后就被删除,而是通过 retention policy 来控制的。

Topic:Kafka topics are the categories used to organize messages, messages are sent to and read from specific topics.
Each topic has a name that is unique across the entire Kafka cluster.
And producers write data to topics, and consumers read data from topics.
Kafka topics are multi-subscriber.This means that a topic can have zero, one, or multiple consumers subscribing to that topic and the data written to it. There is a many-to-many relation between producers/consumers and topics.

Partition: Kafka topics are divided into one or more partitions, each of which is a logical segment of the topic’s data.
Each partition holds a subset of the topic’s data, and the producer decides which partition a message is written to, based on factors like a key or round-robin distribution.
client producer根据record 的 key 的hash 来分配topic 的partition. 如果没有key则round-robin 分配partition。
一个partition 只会分配给一个client,但是一个client 可能会handle 多个partition。

A topic can be divided into multiple partitions to enable parallel processing and improve scalability. Each partition is an ordered sequence of immutable records, with messages within a partition guaranteed to maintain their order. Partitions allow Kafka to distribute the workload of writing and reading messages across multiple brokers in the cluster. This enables consumers to read data in parallel, and producers to write data to different partitions simultaneously, increasing throughput and reducing latency.
Within each partition, messages have a unique offset, which is an integer representing their position in the sequence. This helps consumers track their position and retrieve messages in the correct order.

Kafka Transaction: A Kafka transaction is a group of operations (usually message writes or reads + writes) that are treated as a single atomic unit. Either all of the operations succeed, or none of them take effect.
** Transactions: Balance Overhead with Latency **
One thing to consider, specifically in Kafka Streams applications, is how to set the commit.interval.ms configuration. This will determine how frequently to commit, and hence the size of our transactions. There is a bit of overhead for each transaction so many smaller transactions could cause performance issues. However, long-running transactions will delay the availability of output, resulting in increased latency. Different applications will have different needs, so this should be considered and adjusted accordingly.