图论
基础
图的概念
图的概念
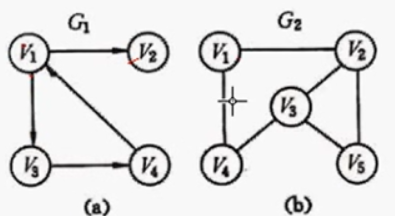
| 概念清单 | 有向图 (a) | 无向图 (b) |
|---|---|---|
| 有向/无向 | 如图 a 所示每条边有指向 | 如图 b 所示每条边没有箭头指向 |
| 权值 | 每条边的权值 | 每条边的权值 |
| 度 | - | 有几条边连到该节点 (eg V 2 V_2 V2 度为 3) |
| 入度/出度 | 出度:从该节点出发的边个数 入度:该节点接收到的边个数 eg. V 1 V_1 V1 入度 1 出度 2 | - |
| 连通图 | 任何节点可到达 | 任何节点都可到达 |
| 强连通图 | 任何节点可互相到达 | 任何节点可互相到达 |
| 连通分量 | - | 无向图的极大连通子图 |
| 强连通分量 | 有向图的极大强连通子图 | - |
图的构造
朴素法
定义一个 n*2 二维数组存储边的连接情况
缺点:查询只能全局遍历才能知道连接情况
邻接矩阵
从节点的角度表示图(空间大小由节点数量决定),使用二维数组表示图结构
如果要查询节点 i 和节点 j 的连接情况使用 grid[i][j] 查询
优点:构造简单、查询快速、适合稠密图(点少边多)
缺点:稀疏矩阵情况效率低
邻接矩阵
![[0-2 基础数据结构Ⅲ 图及其概念-250518-2.png|500]]
从边的角度表视图(空间大小由边的数量决定),使用数组 + 链表方式表达
如果要查询节点 i 与节点 j 连接情况遍历 grid[i] 或 grid[j] 链表
优点:方便节点遍历,空间利用率高
缺点:查询边的情况需要查询一串链表,存在耗时情况,代码实现复杂
图的遍历方式
深度优先搜索 DFS
![[0-2 基础数据结构Ⅲ 图及其概念-250518-3.png|500]]
深度优先搜索:不见黄河不回头,每个分支都尽可能深度搜索
首先选择一个路径一直按照某个元素访问到终点后,回溯最后一步接着继续搜索
深度优先搜索三部曲,类似于回溯三部曲 ![[Day22 回溯Ⅰ 理论 数的组合#回溯法的模板]]
- 确认递归函数的参数与返回值
一般情况,深搜需要 二维数组数组结构保存所有路径,需要一维数组保存单一路径,这种保存结果的数组,我们可以定义一个全局变量,避免让我们的函数参数过多。 - 确定终止条件
- 处理同层搜索节点的逻辑,遍历当前节点的所有节点做搜索
void DFS(param) {
if (终止条件) {
存放结果;
return;
}
for (选择本层节点的所有节点用于搜索) {
节点内容的处理;
DFS(图, 选择的节点);
回溯,撤销结果
}
}
广度优先搜索
广度优先搜索的方向类似于水的涟漪,会从中心点呈现放射状搜索
广度优先搜索的代码类似于二叉树的层序遍历
// 代码模板
vector<vector<int>> levelOrder(TreeNode* root) {
std::queue<TreeNode*> que;
std::vector<std::vector<int>> res;
if (root != nullptr) que.push(root);
while (!que.empty()) {
// 记录每一层的size 控制弹出均为一层一层弹出
int layerSize = que.size();
TreeNode* cur;
std::vector<int> layerRes;
while (layerSize--) {
cur = que.front();
que.pop();
layerRes.push_back(cur->val);
if (cur->left != nullptr) que.push(cur->left);
if (cur->right != nullptr) que.push(cur->right);
}
res.push_back(layerRes);
}
return res;
}
// 递归法
void Order(TreeNode* cur, std::vector<std::vector<int>>& res, int depth) {
if (cur == nullptr) return;
if (depth == res.size()) res.push_back(vector<int>());
res[depth].push_back(cur->val);
Order(cur->left, res, depth + 1);
Order(cur->right, res, depth + 1);
}
vector<vector<int>> levelOrder(TreeNode* root) {
std::vector<std::vector<int>> res;
Order(root, res, 0);
return res;
}
广度搜索的数据记录结构可以使用队列、也可以使用栈、或者普通数组,区别在于遍历顺序不同
队列遍历:一直顺序转圈遍历
栈遍历:顺时针、逆时针交错遍历
默认使用最广的方法就是队列作为数据的记录
代码实现方法
1. 定义队列,定义动作数组用于实现上左下右的操作顺序,队列中存储坐标位置
2. 创建数据入队,设定访问情况标记数组,一直循环遍历队列直到空为止
1. 循环内部取元素并弹出
2. 遍历四个方向内容并加入队列中,期间判定越界情况
3. 访问标记防止重复入队
// 参考代码
int dir[4][2] = {0, 1, 1, 0, -1, 0, 0, -1}; // 表示四个方向
// grid 是地图,也就是一个二维数组
// visited标记访问过的节点,不要重复访问
// x,y 表示开始搜索节点的下标
void bfs(vector<vector<char>>& grid, vector<vector<bool>>& visited, int x, int y) {
queue<pair<int, int>> que; // 定义队列
que.push({x, y}); // 起始节点加入队列
visited[x][y] = true; // 只要加入队列,立刻标记为访问过的节点
while(!que.empty()) { // 开始遍历队列里的元素
pair<int ,int> cur = que.front(); que.pop(); // 从队列取元素
int curx = cur.first;
int cury = cur.second; // 当前节点坐标
for (int i = 0; i < 4; i++) { // 开始想当前节点的四个方向左右上下去遍历
int nextx = curx + dir[i][0];
int nexty = cury + dir[i][1]; // 获取周边四个方向的坐标
if (nextx < 0 || nextx >= grid.size() || nexty < 0 || nexty >= grid[0].size()) continue; // 坐标越界了,直接跳过
if (!visited[nextx][nexty]) { // 如果节点没被访问过
que.push({nextx, nexty}); // 队列添加该节点为下一轮要遍历的节点
visited[nextx][nexty] = true; // 只要加入队列立刻标记,避免重复访问
}
}
}
}
题目
代码随想录图论中的算法题目将统一使用 ACM 模式,为什么要使用ACM模式强化图的构造。
98. 所有可达路径
797. 所有可能的路径 - 力扣(LeetCode)
可到达路径是深度优先搜索的裸题
使用深度优先搜索代码模板实现,给出邻接矩阵与邻接表的实现方式
#include <iostream>
#include <vector>
// 全局变量用于记录路径
std::vector<std::vector<int>> res;
std::vector<int> path;
// 深度优先算法核心
// 第一步 确定dfs的参数 图结构 当前遍历到哪里了 目标遍历位置
void dfs(std::vector<std::vector<int>>& graph, int cur, int fin) {
// 第二步 判断终止条件
if (cur == fin) {
res.push_back(path);
return;
}
// 第三步 单层循环处理逻辑
for (int j = 1; j <= fin; ++j) {
// 寻找当前节点所有可能的连接点
if (graph[cur][j] == 1) {
path.push_back(j);
dfs(graph, j, fin);
path.pop_back();
}
}
}
int main() {
// 输入处理 构建图的过程
int n, m, s, t;
std::cin >> n >> m;
// 采用邻接矩阵实现
std::vector<std::vector<int>> graph(n+1, std::vector<int>(n+1, 0));
for (int i = 0; i < m ;++i) {
std::cin >> s >> t;
graph[s][t] = 1; // 表示s与t连接
}
// 核心调用 求1到n的路径
path.push_back(1);
dfs(graph, 1, n);
// 打印输出结果
if (res.size() == 0) std::cout << -1 << std::endl;
for (int i = 0; i < res.size(); ++i) {
for (int j = 0; j < res[i].size() - 1; ++j) {
std::cout << res[i][j] << " ";
}
std::cout << res[i][res[i].size()-1] << std::endl;
}
return 0;
}
// 邻接表方法 注意访问邻接表的方法 for(int j : xx)
#include<iostream>
#include<vector>
#include<list>
std::vector<std::vector<int>> res;
std::vector<int> path;
int n, m, s, t;
void dfs(std::vector<std::list<int>>& graph, int cur, int fin) {
if (cur == fin) {
res.push_back(path);
return;
}
// 邻接表有数据就代表边 链表只能顺序访问
for (int j : graph[cur]) {
path.push_back(j);
dfs(graph, j, fin);
path.pop_back();
}
}
int main() {
std::cin >> n >> m;
// 定义邻接表
std::vector<std::list<int>> graph(n+1);
for(int i = 0; i < m; ++i) {
std::cin >> s >> t;
graph[s].push_back(t);
}
path.push_back(1);
dfs(graph, 1, n);
if (res.size() == 0) std::cout << -1 << std::endl;
for (int i = 0; i < res.size(); ++i) {
for (int j = 0; j < res[i].size()-1; ++j) {
std::cout << res[i][j] << " ";
}
std::cout << res[i][res[i].size()-1] << std::endl;
}
return 0;
}
// LeetCode 797
vector<vector<int>> res;
vector<int> path;
void dfs(std::vector<vector<int>>& graph, int cur, int fin) {
if (cur == fin) {
res.push_back(path);
return;
}
for (int i : graph[cur]) {
path.push_back(i);
dfs(graph, i, fin);
path.pop_back();
}
}
vector<vector<int>> allPathsSourceTarget(vector<vector<int>>& graph) {
path.push_back(0);
dfs(graph, 0, graph.size()-1);
return res;
}