
写在前面
大型语言模型(LLM)正以前所未有的速度渗透到各行各业,从智能客服、内容创作到代码生成、企业知识库,其应用场景日益丰富。然而,将这些强大的 AI 能力转化为稳定、高效、可大规模应用的服务,却面临着巨大的挑战,其中高并发处理能力和低响应延迟是衡量服务质量的两个核心痛点。
想象一下,你的 LLM 应用在用户高峰期卡顿、排队甚至崩溃,或者用户每次提问都需要漫长的等待——这无疑会严重影响用户体验,甚至导致用户流失。如何让你的大模型服务既能“扛得住”海量请求,又能“跑得快”及时响应?
这需要一个系统性的优化工程,涉及从模型本身的选型与优化,到推理框架的极致加速,再到服务架构的多层次缓存设计等多个环节。本文将深入探讨实现 LLM 服务高并发与低延迟的核心策略与技术方案,包括:
- 模型优化先行: 参数选型、模型蒸馏、模型量化。
- 推理框架加速: KV 缓存、FlashAttenti

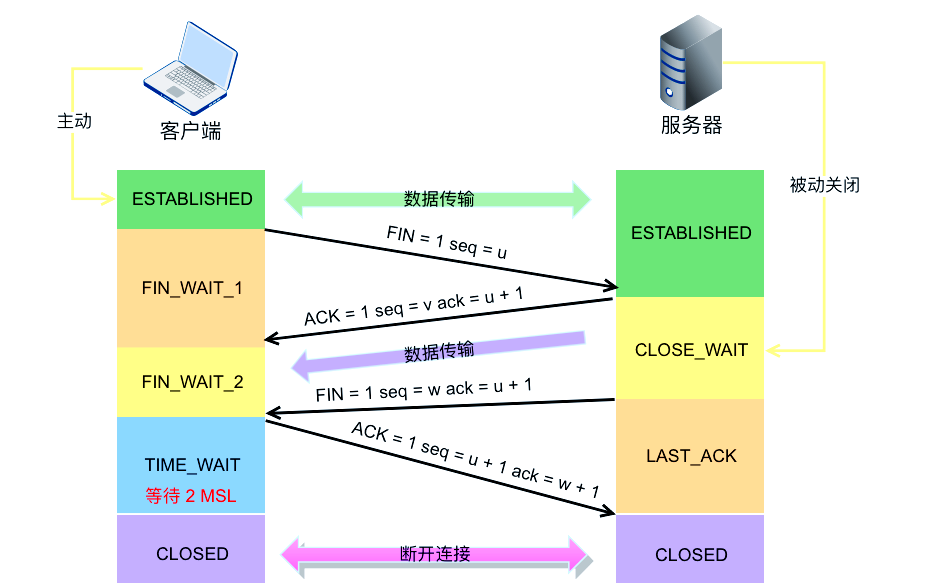
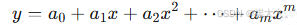
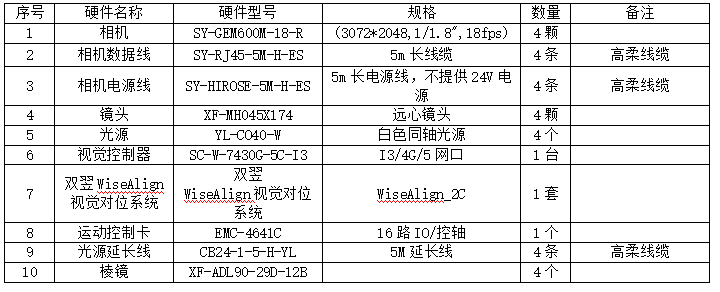
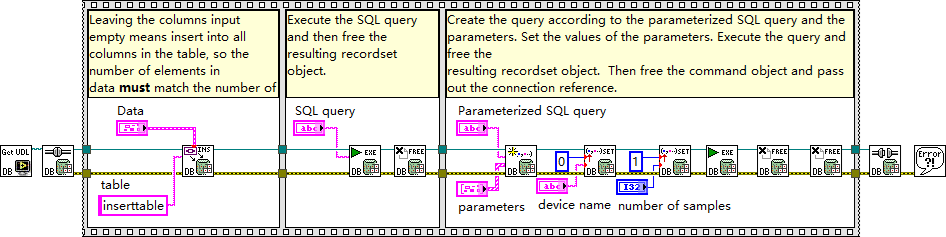








![[ 计算机网络 ] 深入理解TCP/IP协议](https://i-blog.csdnimg.cn/direct/8bde12d22bc74b7fb5f460f07e982168.png)