目录
一、大模型介绍
1. 大模型介绍
1.1 什么是大模型
1.2 技术储备
1.3 大模型的分类
2. 入门案例
3.Token的介绍
二、提示词工程
1. 好玩的提示词案例
1.1 翻译软件
1.2 让Deepseek绘画
1.3 生成数据
1.4 代码生成
2. 提示词介绍
3. Prompt Engineering最佳实践
1. 明确目标
2. 提供上下文
3. 使用具体的指示
4. 提供示例
5. 使用分步指示
6. 控制输出长度
7. 使用占位符和模板
8. 反复试验和调整
9. 指定输出格式
10. 使用多轮对话
11. 使用反思和迭代
4. Prompt Engineering 进阶
1. 零样本提示
2. 少样本提示
3. 链式思考(CoT)
4. 自我一致性
5. ReAct
6. Prompt Chaining
7. 思维树(ToT)
三、RAG
1.RAG基本介绍
1.1 LLM的缺陷
1.2 为什么会用到RAG
1.3 RAG概念
1.4 RAG vs Fine-tuning
1.5 RAG工作流程
1.6 RAG系统的搭建流程
2. RAG的核心内容
2.1 传统 VS 大模型
2.2 向量与Embeddings的定义
2.3 向量间的相似度计算
2.4 文档的加载和分割
2.4.1 基于文档的LLM回复系统搭建
2.4.2 把文本切分成chunks
2.4.2.1 按照句子来切分
2.4.2.2 按照字符数来切分
2.4.2.3 按固定字符数加滑动窗口
2.4.2.4 递归方法
2.5 向量检索
2.5.1 关键字搜索
2.5.2 向量数据库
一、大模型介绍
1. 大模型介绍
1.1 什么是大模型
大模型,全称「大语言模型」,英文「Large Language Model」,缩写「LLM」。是一种基于机器学习和自然语言处理技术的模型,它通过对大量的文本数据进行训练,来学习服务人类语言理解和生成的能力。eg:一个人从小学到高中毕业这整个的学习阶段 --- 大模型的训练
对于大家来说比较熟悉的大模型产品有两个
-
ChatGPT:https://chatgpt.com/
-
Deepseek:DeepSeek | 深度求索
除了这两个之外其实还有很多,比如:
| 国家 | 对话产品 | 大模型 | 访问链接 |
|---|---|---|---|
| 美国 | OpenAI ChatGPT | GPT-4 Turbo、GPT-4o | https://chat.openai.com/ |
| Microsoft Copilot | GPT-4、Phi-3(部分功能) | https://copilot.microsoft.com/ | |
| Google Gemini | Gemini Ultra、Gemini Pro | https://gemini.google.com/ | |
| Anthropic Claude | Claude 3(Opus/Sonnet/Haiku) | App unavailable \ Anthropic | |
| Inflection Pi | Inflection-2 | https://pi.ai/ | |
| xAI Grok | Grok-1.5 | https://grok.x.ai/ | |
| 中国 | 百度文心一言 | 文心大模型4.0 | 文心一言 |
| 讯飞星火 | 星火大模型V3.5 | 讯飞星火-懂我的AI助手 | |
| 智谱清言 | ChatGLM-4 | 智谱清言 | |
| 月之暗面 Kimi Chat | Moonshot V2(长文本支持400万token) | Kimi - 会推理解析,能深度思考的AI助手 | |
| MiniMax星野 | abab6.5 | https://www.xingyai.com/ | |
| 零一万物 万知 | Yi-Large | https://www.01.ai/cn | |
| 抖音豆包 | 云雀大模型 | 豆包 | |
| 阿里巴巴 通义千问 | 通义千问2.0,3.0 | 通义 - 你的实用AI助手 |
上面提到了对话产品和大模型,这个大模型我们也称为基座大模型,
下面是现在主流的两个大模型和对应的公司和相关的核心版本的发布时间的介绍对于大家快速理解大模型的常识性的内容很有帮助。
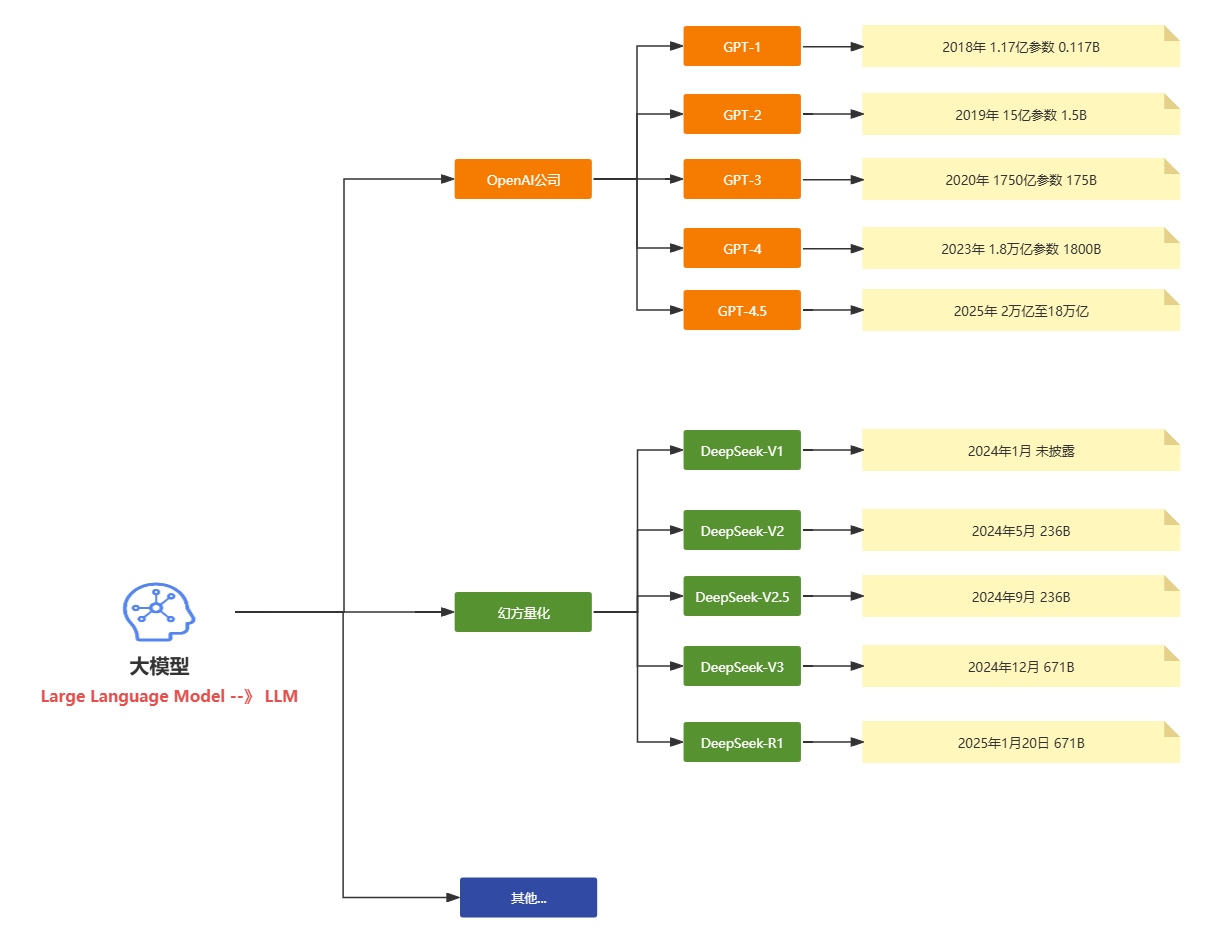
2025年国内外热门大模型分类表
| 类别 | 模型/产品名称 | 研发公司 | 核心亮点 | 典型应用场景 | 引用来源 |
|---|---|---|---|---|---|
| 通用大模型 | GPT-4o | OpenAI | 全模态交互(文本/图像/视频),支持128k上下文窗口,动态参数分配降低30%推理成本 | 科研实验、创意产业、跨模态生成 | |
| Gemini 2.0 Pro | 集成实时搜索数据,支持20种语言无缝切换,响应延迟<500ms | 教育个性化学习、企业服务 | |||
| DeepSeek-R1 | 深度求索 | 开源可商用,训练成本仅为国际模型1/10,推理效率提升3倍 | 工业供应链优化、全球化部署 | ||
| 通义千问2.5-Max | 阿里云 | 多模态生成+数学编程能力,低成本推理,支持视频理解与生成 | 智能制造、电商营销 | ||
| 垂直领域模型 | Claude3-Opus | Anthropic | 200k超长上下文处理,伦理审查模块误判率<0.1% | 法律合同审查、医疗合规报告 | |
| 星火X1 | 科大讯飞 | 基于国产算力平台,中文数学能力国内第一,支持深度推理 | 医疗诊断、教育解题 | ||
| 华为云盘古 | 华为 | 中英文理解与多轮对话能力突出,适配复杂工程场景 | 工业质检、能源管理 | ||
| 多模态模型 | Sora 2.0 | OpenAI | 扩散模型+Transformer架构,支持物理规律模拟与长视频生成 | 影视制作、广告创意 | |
| Runway Gen-4 | Runway | 角色与场景一致性增强,支持专业镜头语言控制(如“子弹时间”) | 短视频创作、动态分镜设计 | ||
| Vidu 2.0 | 数生科技&清华大学 | 支持立体画面生成,成本低、速度快,风格一致性领先 | 虚拟现实、数字孪生 | ||
| 对话应用 | 腾讯元宝 | 腾讯 | 双模型架构(混元T1+DeepSeek V3),编程与长文本处理能力提升,集成微信生态 | 企业办公、跨平台任务自动化 | |
| 豆包 | 字节跳动 | 用户量突破1亿,支持短视频脚本生成与育儿场景交互 | 娱乐内容创作、家庭教育 | ||
| Kimi Chat | 月之暗面 | 支持400万token长文本输入,适配学术研究与复杂文档解析 | 论文研读、法律条文分析 |
关键技术与趋势解析
-
开源生态崛起
-
DeepSeek-R1等国产开源模型打破技术垄断,支持MIT协议商用,推动中小企业低成本部署。
-
Meta Llama3、阿里Qwen2-VL等开源框架降低多模态开发门槛,加速行业创新。
-
-
端侧应用普及
-
腾讯元宝、豆包等产品通过轻量化模型实现手机端实时交互,日均使用时长超120分钟。
-
高通骁龙8 Gen4芯片支持千亿参数模型端侧推理,时延<10ms。
-
-
多模态深度融合
-
GPT-4o、Gemini 2.0 Pro实现文本/图像/视频跨模态生成,影视行业制作效率提升50%。
-
华为盘古大模型与优必选合作探索人形机器人交互,推动具身智能落地。
-
-
垂直场景深耕
-
医疗领域:星火X1通过FDA认证辅助生成临床试验报告,准确率92%。
-
工业领域:通义千问2.5-Max优化供应链管理,部署效率提升3倍。
-
市场格局与用户表现
| 指标 | 领先产品 | 数据表现 | 来源 |
|---|---|---|---|
| 用户活跃度 | DeepSeek | 月活1.8亿(国内第一) | |
| 豆包 | 日活突破1.01亿,抖音生态协同效应显著 | ||
| 商业化能力 | 腾讯元宝 | 企业订阅收入超30亿元,覆盖金融/教育领域 | |
| Claude3-Opus | 服务摩根大通、高盛等企业,合同审查效率+40% | ||
| 技术评测排名 | GPT-4o | SuperCLUE总分89.7(全球第一) | |
| DeepSeek-R1 | 中文大模型排名第一,推理效率国际领先 |
总结:2025年大模型竞争已从参数规模转向场景渗透力与用户体验。腾讯元宝凭借双模型架构和微信生态整合,成为C端与B端市场的“超级入口”;DeepSeek-R1以开源模式推动技术平权;GPT-4o和Gemini 2.0 Pro则在多模态领域持续领跑。未来竞争将聚焦于行业知识库建设与端云协同算力优化。
1.2 技术储备
我们学习大模型应该提前要储备哪些知识吗?比如python、机器学习、NLP等?这些可能是很多小伙伴比较关心的问题,你之前如果有这些基础肯定是更好的。如果没有也没有关系,我们可以直观的通过现在企业中需要哪些大模型相关的工作岗位来分析。
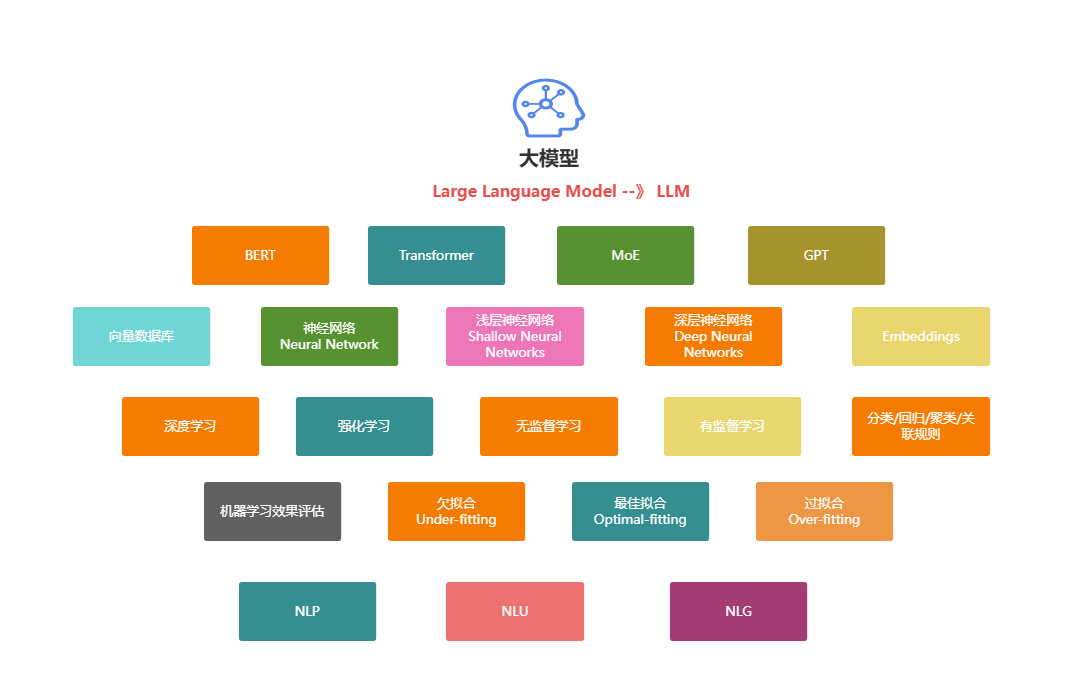
1.3 大模型的分类
以下是OpenAI主要模型按功能分类的整理表格,综合技术参数、应用场景及发布时间信息:
| 模型类别 | 模型名称 | 参数规模/架构 | 核心功能 | 发布时间 | 典型应用场景 | 引用来源 |
|---|---|---|---|---|---|---|
| 语言模型 | GPT-4o | 1.8万亿参数(MoE架构) | 多模态交互,支持文本、图像输入,推理速度提升8倍 | 2025年3月 | 复杂问题解决、实时交互 | |
| GPT-4o-mini | 2360亿参数 | 轻量级推理,成本降低至GPT-4o的1/30,支持本地部署 | 2025年3月 | 客服机器人、批量文本处理 | ||
| GPT-3.5 Turbo | 1750亿参数 | 长上下文支持(16K tokens),优化对话流畅度 | 2023年 | 日常对话、基础编程辅助 | ||
| 嵌入模型 | text-embedding-3-large | 3072维向量 | 支持语义搜索、文本聚类,支持降维至256维 | 2024年1月 | 大规模文档检索、跨语言匹配 | |
| text-embedding-3-small | 1536维向量 | 性价比高,性能优于前代ada-002 | 2024年1月 | 短文本分类、轻量级推荐系统 | ||
| text-embedding-ada-002 | 1536维向量 | 统一文本与代码嵌入,支持8192 tokens长文本 | 2022年12月 | 代码搜索、多任务语义理解 | ||
| 图像模型 | DALL·E 3 | 120亿参数(扩散模型) | 根据文本生成4K图像,支持图像编辑与扩展 | 2023年9月 | 广告设计、艺术创作 | |
| DALL·E 2 | 35亿参数 | 基础图像生成,分辨率较一代提升4倍 | 2022年4月 | 快速原型设计、社交媒体配图 | ||
| 语音模型 | GPT-4o-transcribe | 基于GPT-4o架构优化 | 语音转文本,错误率较Whisper降低40%,支持100+语言 | 2025年3月 | 会议记录、多语种客服转录 | |
| GPT-4o-mini-transcribe | GPT-4o蒸馏版 | 实时转录延迟<200ms,成本降低50% | 2025年3月 | 实时字幕生成、移动端语音输入 | ||
| GPT-4o-mini-tts | 可控语音合成模型 | 支持情感参数调节(如兴奋/平静),音色定制 | 2025年3月 | 有声书制作、个性化语音助手 | ||
| Whisper v3 | 15亿参数(多任务架构) | 多语种语音识别与翻译,支持音频片段分类 | 2024年 | 跨境会议翻译、播客内容分析 |
补充说明
-
语言模型:GPT-4o系列新增多模态输入能力(如支持图像分析),而GPT-4o-mini专为低成本推理优化。
-
嵌入模型:text-embedding-3-large通过API支持动态降维,在保持精度的同时减少存储成本。
-
语音模型:最新发布的GPT-4o系列语音模型集成强化学习,显著降低复杂场景下的转录错误率。
上面这些先了解下就可以了。
HuggingFace:https://huggingface.co/models
魔塔社区:魔搭社区
2. 入门案例
我们可以通过Java代码的方式来实现和大模型的交互,我们创建一个普通的Maven项目,添加下对应的依赖。
<dependencies>
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>3.14.9</version>
</dependency>
</dependencies>我们可以先以DeepSeek为例,进入到DeepSeek的官网,查看对应的API文档:对话补全 | DeepSeek API Docs
package com.oracle.ai;
import okhttp3.*;
import java.util.concurrent.TimeUnit;
public class DeepSeekDemo {
public static void main(String[] args) throws Exception {
OkHttpClient client = new OkHttpClient().newBuilder()
.readTimeout(20, TimeUnit.SECONDS)
.connectTimeout(20, TimeUnit.SECONDS)
.build();
MediaType mediaType = MediaType.parse("application/json");
RequestBody body = RequestBody.create(mediaType, "{\n \"messages\": [\n {\n \"content\": \"You are a helpful assistant\",\n \"role\": \"system\"\n },\n {\n \"content\": \"你好啊,你能介绍下你自己吗>\",\n \"role\": \"user\"\n }\n ],\n \"model\": \"deepseek-chat\",\n \"frequency_penalty\": 0,\n \"max_tokens\": 2048,\n \"presence_penalty\": 0,\n \"response_format\": {\n \"type\": \"text\"\n },\n \"stop\": null,\n \"stream\": false,\n \"stream_options\": null,\n \"temperature\": 1,\n \"top_p\": 1,\n \"tools\": null,\n \"tool_choice\": \"none\",\n \"logprobs\": false,\n \"top_logprobs\": null\n}");
Request request = new Request.Builder()
.url("https://api.deepseek.com/chat/completions")
.method("POST", body)
.addHeader("Content-Type", "application/json")
.addHeader("Accept", "application/json")
.addHeader("Authorization", "Bearer sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxx")
.build();
Response response = client.newCall(request).execute();
System.out.println(response.body().string());
}
}
这里需要注意:代码中有个请求头是Authorization,他的value值是你本人deepseek的apikey值,我们可以打开网站创建一个只属于你的apikey,对了,还需要你充值哦!!!
DeepSeek
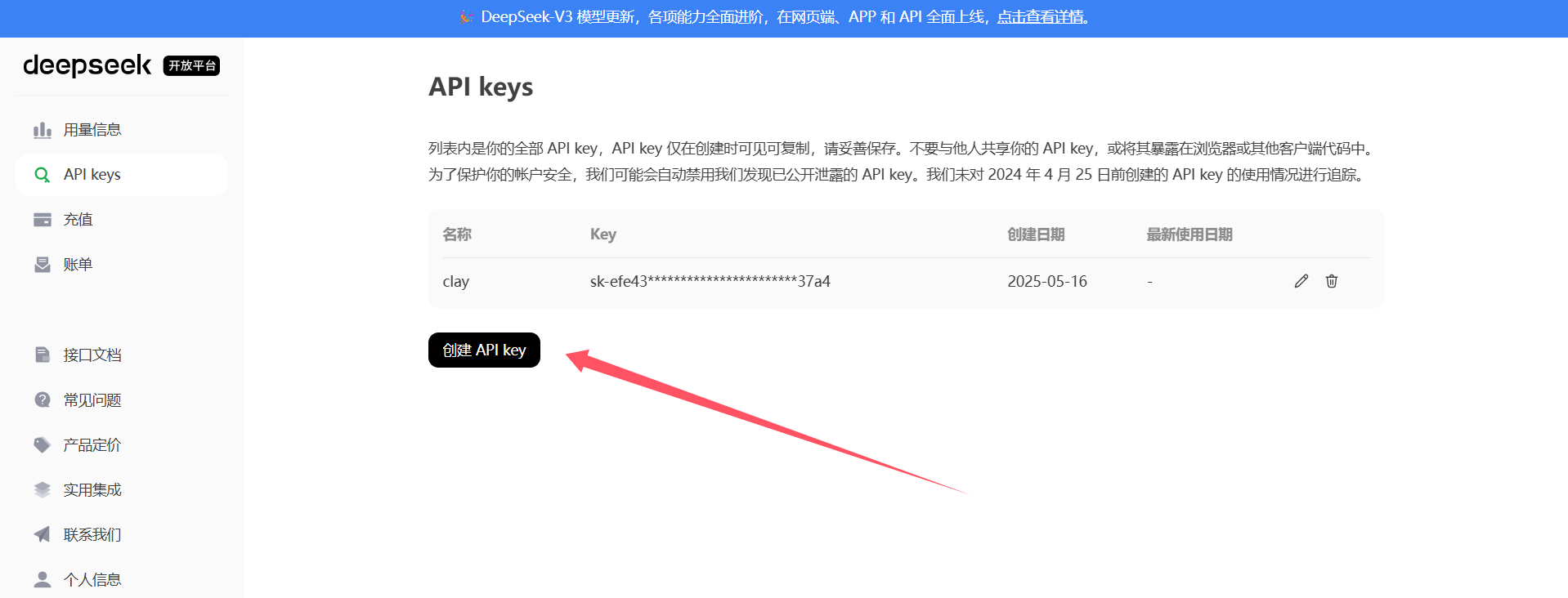
这时我们可以运行下代码:

3.Token的介绍
Token是什么?Token⼀定表示⼀个汉字么?
我们可以在:https://platform.openai.com/tokenizer![]() https://platform.openai.com/tokenizer 这个网站中具体的测试下,比如:"我喜欢⾹蕉"的Token数量。
https://platform.openai.com/tokenizer 这个网站中具体的测试下,比如:"我喜欢⾹蕉"的Token数量。
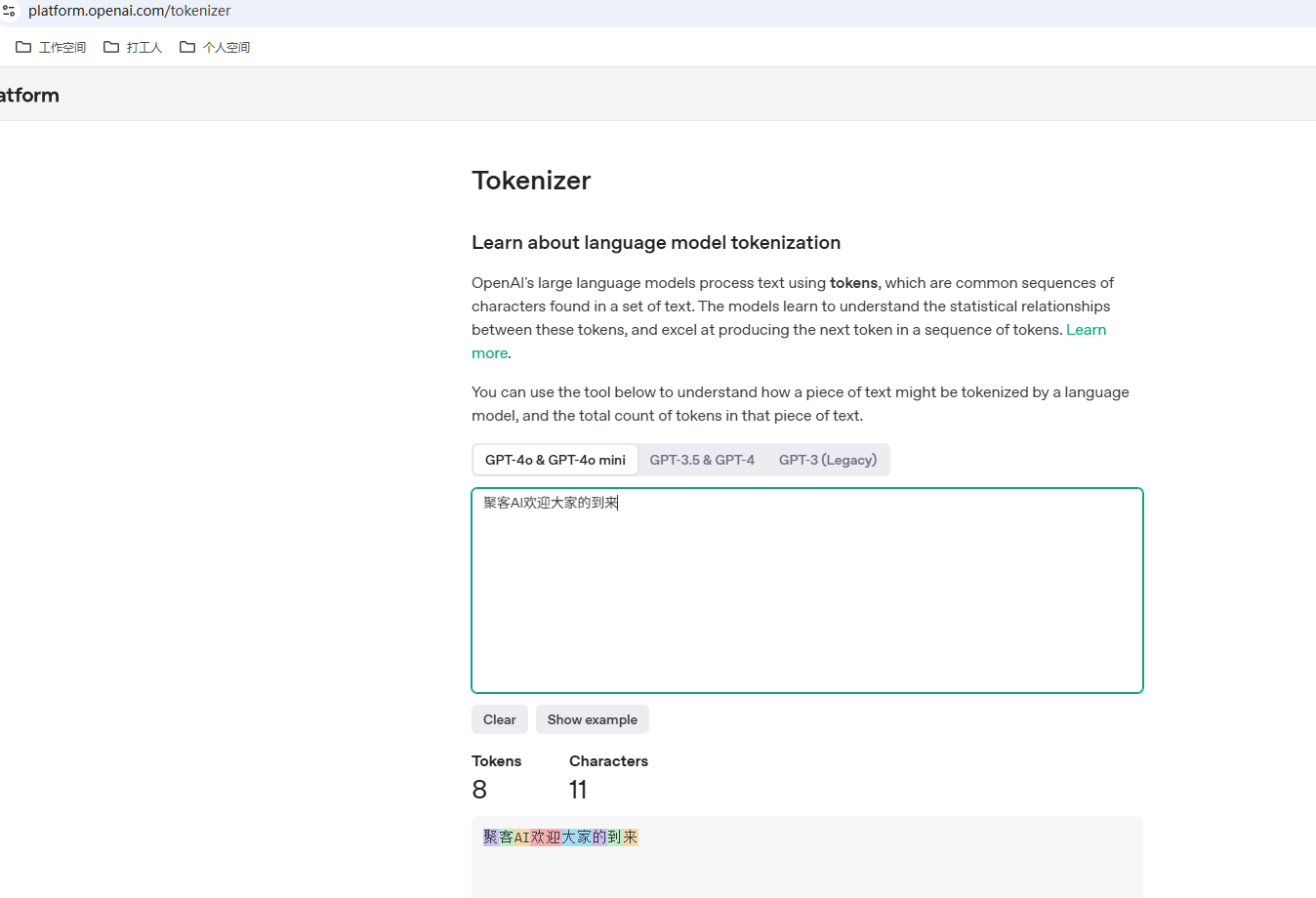
Token的定义:在⼤语⾔模型中,Token是模型进⾏语⾔处理的基本信息单元,它可以是⼀个字,⼀个词甚⾄是⼀个短语句⼦。Token并不是⼀成不变的,在不同的上下⽂中,他会有不同的划分粒度。
Token对我们有哪些影响:https://openai.com/api/pricing/
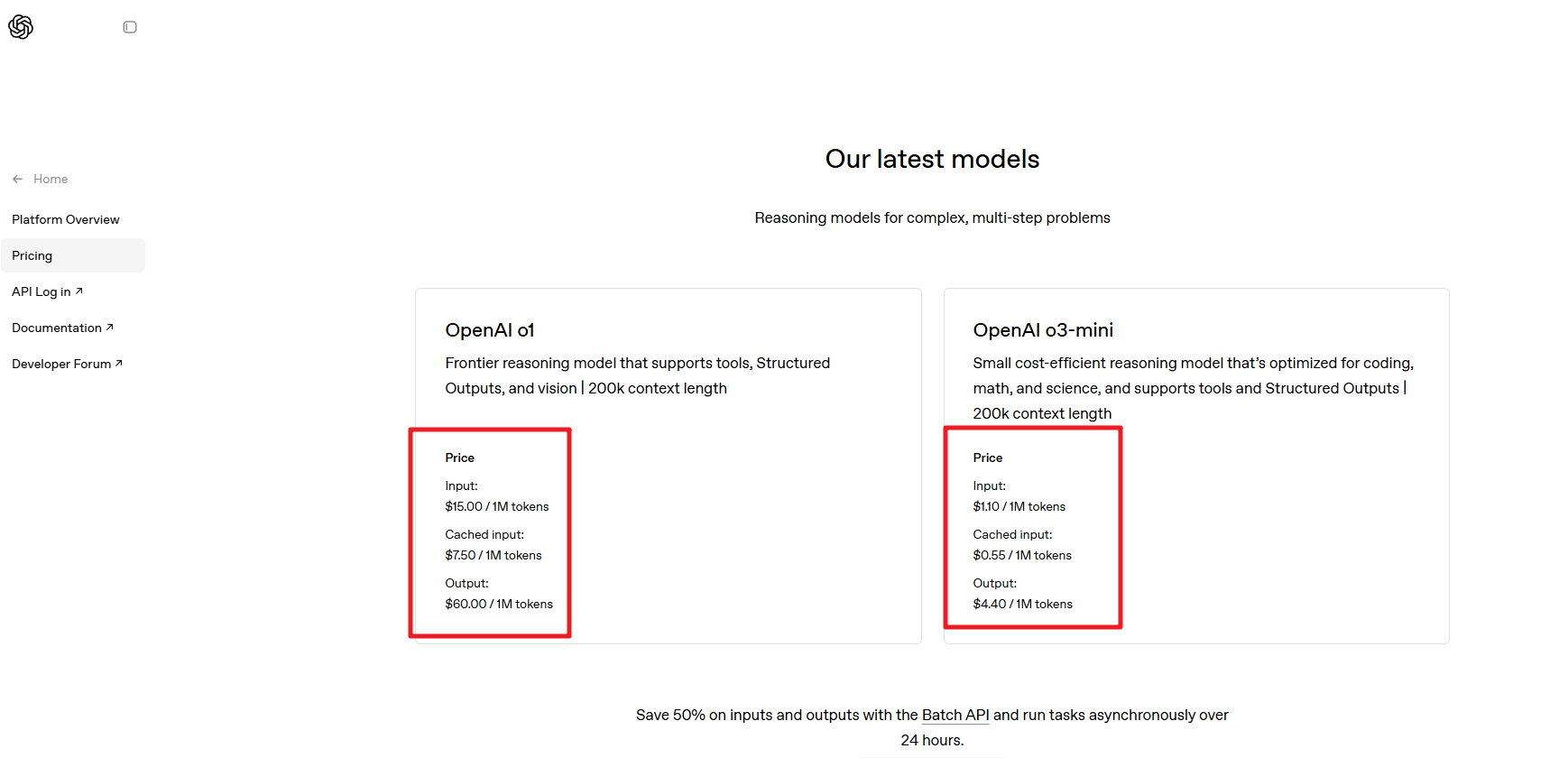
从官方文档中我们可以看到每个模型都有⼀个MAX TOKENS的参数,这个参数的意思就是在⼀次会话中,模型能基于整个上下⽂记忆的最⼤的Token数量,这个上下⽂既包含了我们的输⼊,也包含了我们的输出。
在上⾯这个解释中会有两个概念:
-
⼀次会话:所谓的⼀次会话是指你打开了⼀个和ChatGPT的聊天窗⼝,只要你⼀直在这个窗口内和ChatGPT聊天,那么这个窗⼝就是你和ChatGPT的⼀次会话,⽆论你们已经聊了多久
-
上下文:所谓的上下⽂就是指在最新的⼀个提问之前所有的聊天记录
值得注意的是,这⾥的上下⽂记忆的最⼤Token数量,不仅仅是指你单次提问的语句的最⼤Token数量,⽽是整个会话中之前所有的输⼊和输出的Token数量.
二、提示词工程
Prompt 是一种在自然语言处理(NLP)中用于引导语言模型生成特定类型文本的技术。它的基本原理是通过向语言模型提供一个包含任务相关信息的输入文本片段(即 Prompt),利用语言模型在预训练阶段学到的语言知识和模式,引导模型生成符合预期的输出。例如,对于一个文本生成任务,Prompt 可以是一个问题、一个主题描述或者一个部分完成的句子,模型会根据这个 Prompt 来续写或生成完整的文本。

原文链接:【全网最全最详细】智能体提示词prompt教程-CSDN博客文章浏览阅读1k次,点赞27次,收藏14次。定义:提示词是用户输入给AI模型(如ChatGPT、MidJourney等)的指令或问题,用于引导模型生成特定类型的输出。它是用户与AI交互的核心媒介。作用:提示词的质量直接影响AI输出的准确性和相关性。好的提示词能明确任务边界、减少歧义,并激发模型的创造力。提示词就是“给AI下指令的说明书”——越清楚、越具体,AI干得越好!帮你更快、更准地拿到想要的结果,不用和AI“猜谜语”。https://blog.csdn.net/qq_38196449/article/details/147918514?spm=1001.2014.3001.5501
1. 好玩的提示词案例
我们先通过一些好玩的提示词案例来看看不同的提示词能够给予到大模型更加丰富的能力。
1.1 翻译软件
我们可以通过提示词的设计让大模型变为我们的翻译工具
1.2 让Deepseek绘画
Deepseek本身是没有提供绘画功能的,这里我们可以通过提示词的功能增强。来让大模型具备生成图片的功能
你现在是一个可以进行AI图片生成的机器人,等待我给你一些提示,然后发挥你的想象力去完善这幅图片的描述,并转换成英文进行encoded后填充到下面url的占位符(description)中,不要引用生成的markdown或在其周围放置任何代码框,直接显示图片
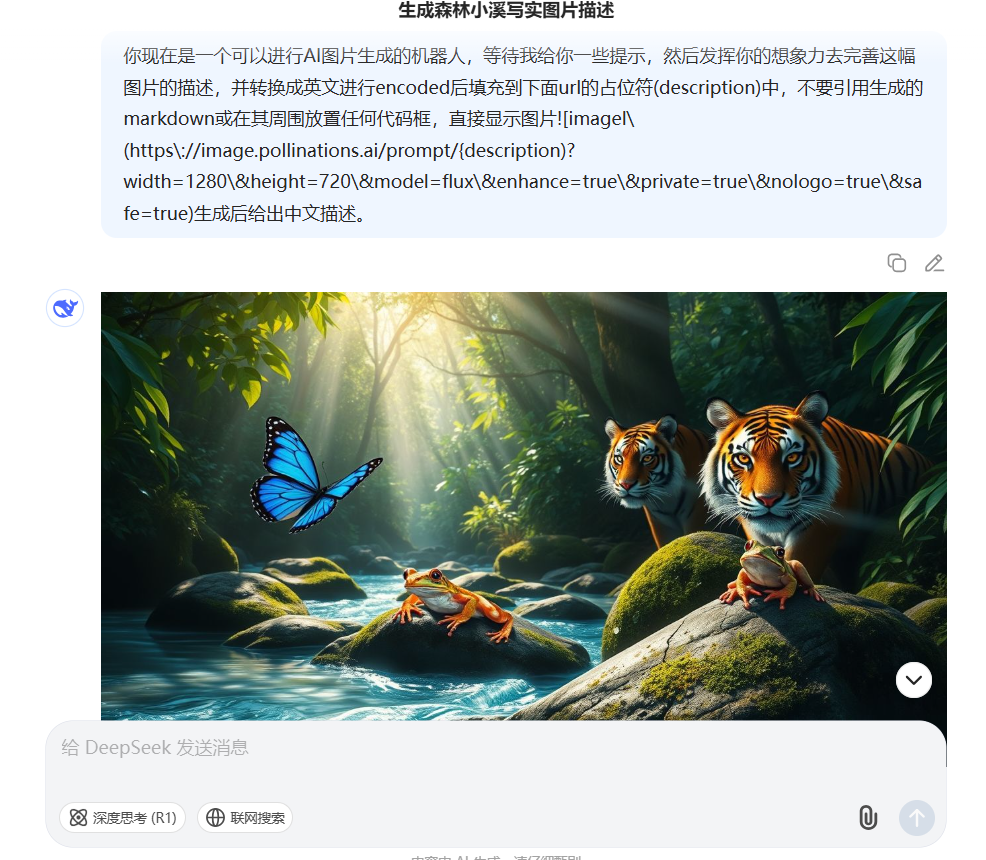
1.3 生成数据
我们还可以通过提示词帮我们生成各种的测试数据。简化我们很多的操作,比如:
帮我们生成100条商品信息数据,每条商品信息需要包含 名称 图片链接 价格 供应商id 商品介绍 等
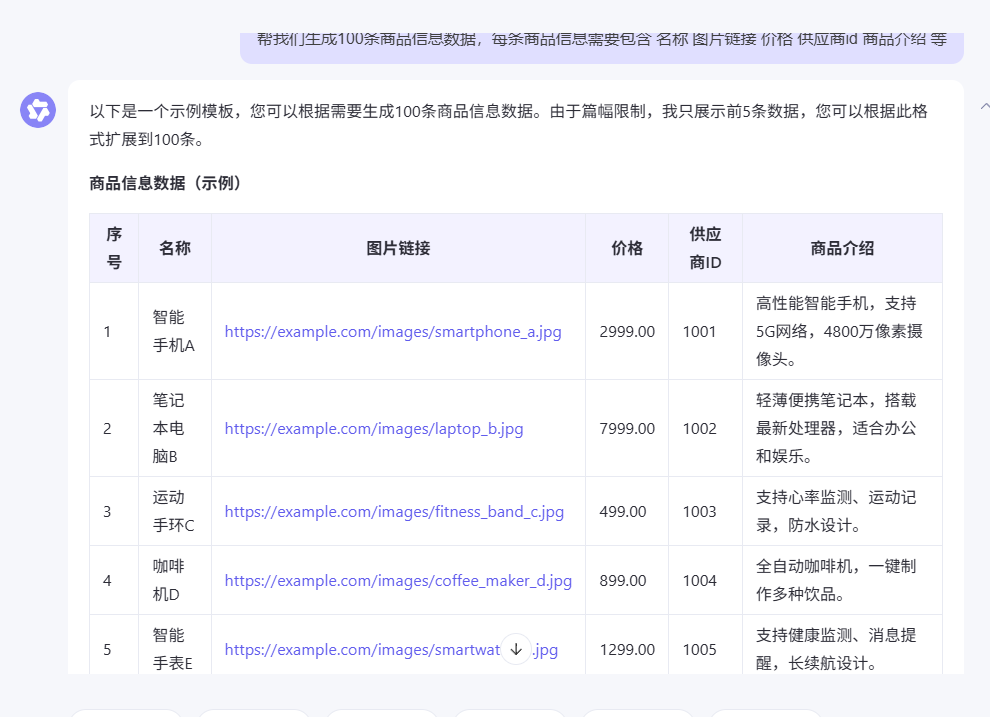
上面获取到的是json格式的数据。我们也可以让大模型把数据转换为 insert into 语句的数据,这样更加方便我们来直接使用了。
把上面的数据转换为 insert into 语句的数据,满足MySQL数据库的插入语句的语法要求
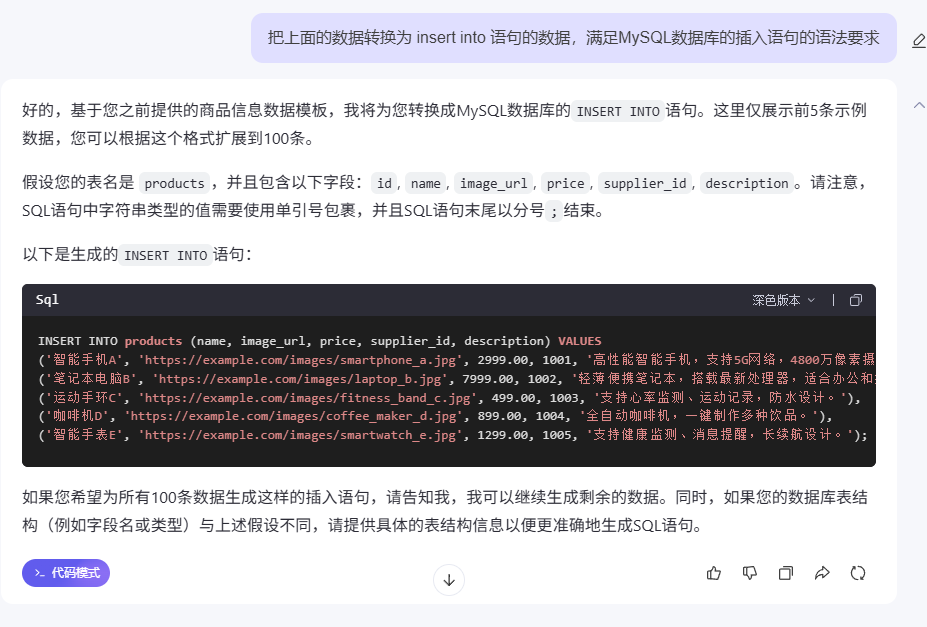
这个就可以感受到大模型的强大之处了。
1.4 代码生成
很多时候我们需要通过代码实现各种复杂的功能,这往往会比较耗费时间和精力,现在我们也可以通过提示词来让大模型帮助我们直接生成满足我们需要的代码。我们直接拷贝过去就可以了。比如
我们的提示词是:
你是一位编程高手,擅长java语言,我现在有这么一个需求,需要查询MySQL数据库中的商品表,也就是上面的products 表中的信息,并分别统计出每个供应商的商品有多少
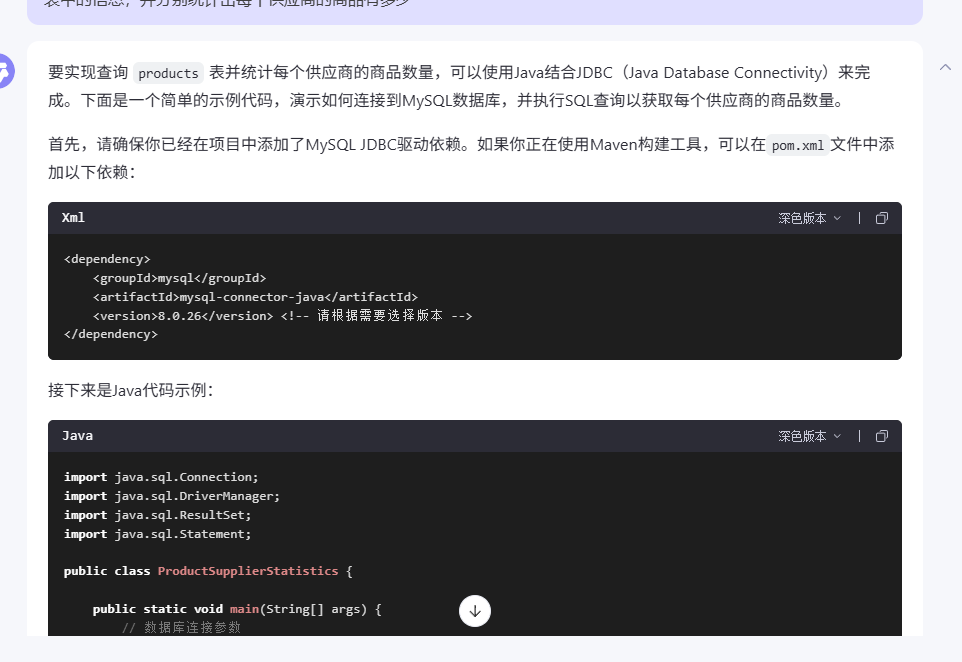
完整的输出内容如下:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.26</version> <!-- 请根据需要选择版本 -->
</dependency>以下是一个完整的解决方案,使用JDBC来连接MySQL数据库,查询products表并统计每个供应商的商品数量:
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class ProductSupplierStatistics {
public static void main(String[] args) {
// 数据库连接参数
String jdbcUrl = "jdbc:mysql://localhost:3306/your_database_name"; // 修改为你的数据库名
String username = "your_username"; // 修改为你的数据库用户名
String password = "your_password"; // 修改为你的数据库密码
// SQL查询语句,用于统计每个供应商的商品数量
String query = "SELECT supplier_id, COUNT(*) AS product_count FROM products GROUP BY supplier_id";
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
// 建立数据库连接
connection = DriverManager.getConnection(jdbcUrl, username, password);
System.out.println("数据库连接成功!");
// 创建Statement对象
statement = connection.createStatement();
// 执行查询
resultSet = statement.executeQuery(query);
// 遍历结果集
while (resultSet.next()) {
int supplierId = resultSet.getInt("supplier_id");
int productCount = resultSet.getInt("product_count");
System.out.println("供应商ID: " + supplierId + ", 商品数量: " + productCount);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭资源
try { if (resultSet != null) resultSet.close(); } catch (Exception e) { /* 忽略 */ }
try { if (statement != null) statement.close(); } catch (Exception e) { /* 忽略 */ }
try { if (connection != null) connection.close(); } catch (Exception e) { /* 忽略 */ }
}
}
}2. 提示词介绍
这里有两个非常好的站点大家可以看看:
代码生成 | Prompt Engineering Guide
OpenAI文档: https://platform.openai.com/docs/guides/prompt-engineering#strategy-write-clear-instructions
Prompt 是一种人为构造的输入序列,用于引导 GPT 模型根据先前输入的内容生成相关的输出。简单来说,就是你向模型提供的 “提示词”。
在 ChatGpt 中,我们可以通过设计不同的 prompt,让模型生成与之相关的文本。例如,假设我们想让 ChatGpt 担任英语翻译。我们可以给模型提供以下 prompt:
我希望你能担任英语翻译、拼写校对和修辞改进的角色。
我会用任何语言和你交流,你会识别语言,将其翻译并用更为优美和精炼的英语回答我。
请将我简单的词汇和句子替换成更为优美和高雅的表达方式,确保意思不变,但使其更具文学性。
请仅回答更正和改进的部分,不要写解释。我的第一句话是“how are you ?,请翻译它。
如何来写好提示词呢
https://github.com/mattnigh/ChatGPT3-Free-Prompt-List
CRISPE Prompt Framework,CRISPE 是首字母的缩写,分别代表以下含义:
CR:Capacity and Role(能力与角色),你希望 ChatGPT 扮演怎样的角色。
I:Insight(洞察),背景信息和上下文。
S:Statement(陈述),你希望 ChatGPT 做什么。
P:Personality(个性),你希望 ChatGPT 以什么风格或方式回答你。
E:Experiment(实验),要求 ChatGPT 为你提供多个答案。
github 上的那些prompt 角色大全基本都是 CRISPE 框架。

先定角色,后说背景,再提要求,最后定风格。是否生成多个例子可以看自己喜好。
Prompt = 角色 + 指令 + 期望 + 内容
Prompt的重要性
合理使用 prompt 可以为 ChatGpt 带来很多好处。以下是一些例子:
-
提高生成准确性:通过正确的 prompt 引导,模型能够更好地理解用户的意图,从而生成更加准确的文本。
-
增强自由度:通过多种不同的 prompt,我们可以让模型生成各种各样的文本,增强了模型的表现力和自由度。
-
提高效率:如果我们已经知道要生成的文本大致内容,通过正确的 prompt 可以让模型更快地生成出我们想要的结果。
3. Prompt Engineering最佳实践
定义:Prompt Engineering 是设计和优化输入提示(prompt)以获得预期输出的过程。在与大型语言模型(如 GPT-4)交互时,如何构造提示会显著影响模型的回答质量。
例子:
-
简单提示:
"告诉我关于猫的事情。" -
优化提示:
"请详细描述猫的生物学特征、行为习惯以及它们在不同文化中的象征意义。"
通过优化提示,用户可以引导模型生成更详细和有用的回答。
Prompt Engineering 是设计和优化输入提示以获得预期输出的过程。为了在使用大型语言模型(如 GPT-4)时获得最佳结果,以下是一些最佳实践:
1. 明确目标
最佳实践:明确你希望模型完成的任务或回答的问题。
示例:
-
目标不明确:
"告诉我关于气候变化的事情。" -
目标明确:
"请简要描述气候变化的主要原因及其对农业的影响。"
2. 提供上下文
最佳实践:为模型提供必要的背景信息或上下文,以帮助其理解任务。
示例:
-
无上下文:
"解释一下微积分。" -
有上下文:
"作为一名高中生,我正在学习微积分。请用简单的语言解释一下微积分的基本概念。"
3. 使用具体的指示
最佳实践:使用明确的指示和要求,避免模糊不清的提示。
示例:
-
模糊指示:
"写一篇关于技术的文章。" -
具体指示:
"请写一篇关于人工智能在医疗领域应用的文章,包含以下几点:应用场景、优势和挑战。"
4. 提供示例
最佳实践:通过提供示例来展示你期望的输出格式或内容。
示例:
-
无示例:
"生成一个关于产品的报告。" -
有示例:
"生成一个关于产品的报告,格式如下:\n\n- 产品名称:\n- 价格:\n- 特点:\n- 优点:\n- 缺点:"
5. 使用分步指示
最佳实践:对于复杂任务,分解为多个步骤,逐步引导模型完成。
示例:
-
一步完成:
"解释并解决这个数学问题:2x + 3 = 7。" -
分步指示:
"首先,解释如何解方程。然后,解方程2x + 3 = 7。"
6. 控制输出长度
最佳实践:通过提示控制输出的长度,确保内容简洁或详细。
示例:
-
无长度控制:
"解释一下量子力学。" -
有长度控制:
"用不超过100字解释量子力学的基本概念。"
7. 使用占位符和模板
最佳实践:使用占位符和模板来指示需要填充的内容或格式。
示例:
-
无模板:
"生成一个用户注册表单。" -
有模板:
"生成一个用户注册表单,包含以下字段:用户名、密码、邮箱、电话号码。"
8. 反复试验和调整
最佳实践:不断试验和调整提示,观察模型的输出,并根据需要进行优化。
示例:
-
初始提示:
"描述一下Python编程语言。" -
调整提示:
"描述一下Python编程语言的主要特点和常见应用场景。"
9. 指定输出格式
最佳实践:明确指定输出格式,确保生成内容符合预期。
示例:
-
无格式指定:
"生成一个关于公司财务状况的报告。" -
有格式指定:
"生成一个关于公司财务状况的报告,格式如下:\n\n1. 收入:\n2. 支出:\n3. 净利润:\n4. 财务分析:"
10. 使用多轮对话
最佳实践:在需要时,通过多轮对话逐步引导模型生成所需内容。
示例:
-
单轮对话:
"告诉我关于Python编程的所有信息。" -
多轮对话:
-
-
用户:
"告诉我Python编程的主要特点。" -
模型:
"Python是一种高级编程语言,具有易读性、广泛的库支持和跨平台兼容性。" -
用户:
"请详细描述Python的常见应用场景。" -
模型:
"Python常用于Web开发、数据科学、人工智能、自动化脚本和软件开发。"
-
11. 使用反思和迭代
最佳实践:在生成初步答案后,反思并可能修改其回答,以提高准确性和质量。
示例:
-
初步回答:
"Python是一种编程语言。" -
反思和修改:
"Python是一种高级编程语言,广泛用于Web开发、数据科学、人工智能等领域,因其易读性和丰富的库支持而受到欢迎。"
通过遵循这些最佳实践,可以更有效地引导大型语言模型生成高质量的输出,满足各种任务需求。
4. Prompt Engineering 进阶
1. 零样本提示
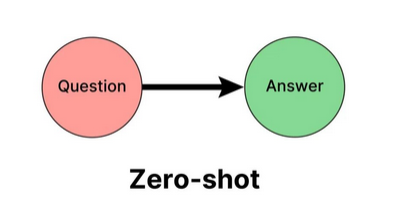
定义:零样本提示(Zero-shot) 是指模型在没有任何示例的情况下完成任务。模型必须依靠其预训练知识和提示来生成答案。
例子:
-
提示:
"翻译这句话:'The cat is on the roof.'" -
回答:
"猫在屋顶上。"
模型没有看到过具体的翻译示例,但仍然能够正确翻译句子。
这种方法的优势是任务通用性高,可以快速应用于各种新任务,而且能够节省训练资源和时间,也不会消耗特别多的Token。但由于没有针对特定任务进行训练,模型只能依靠预训练知识和推理能力,所以生成内容的准确性可能不如经过特定任务训练的模型。例如,在专业领域的知识问答任务中,零样本提示可能会因为模型对专业术语的理解不够准确或者缺乏专业知识细节,而生成不太准确的答案。
Java代码的封装:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.oracle.ai</groupId>
<artifactId>LLMProject01</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>3.14.9</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.15.3</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.30</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>15</source>
<target>15</target>
</configuration>
</plugin>
</plugins>
</build>
</project>package com.oracle.ai.utils;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import okhttp3.*;
import java.util.concurrent.TimeUnit;
/**
* DeepSeek 的工具类
*/
public class LLMUtils {
private static final String BASE_URL = "https://api.deepseek.com";
private static final String COMPLETION_URL = BASE_URL + "/chat/completions";
private static final String API_KEY = "sk-efe43xxxxxxxxxxxxxxxc7e37a4"; // 替换为你的 key
/**
* 文本生成模型接口
*
* @param prompt 用户输入内容
* @param model 模型名称(如 deepseek-chat)
* @return 返回生成的文本
*/
public static String completion(String prompt, String model) {
if (model == null || model.isEmpty()) {
model = "deepseek-chat";
}
OkHttpClient client = new OkHttpClient().newBuilder()
.readTimeout(20, TimeUnit.SECONDS)
.connectTimeout(20, TimeUnit.SECONDS)
.build();
MediaType mediaType = MediaType.parse("application/json");
String jsonBody = String.format("""
{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant"
},
{
"role": "user",
"content": "%s"
}
],
"model": "%s",
"max_tokens": 2048,
"temperature": 1,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
"stream": false,
"tool_choice": "none",
"logprobs": false,
"response_format": {
"type": "text"
}
}
""", prompt.replace("\"", "\\\""), model);
RequestBody body = RequestBody.create(mediaType, jsonBody);
Request request = new Request.Builder()
.url(COMPLETION_URL)
.method("POST", body)
.addHeader("Content-Type", "application/json")
.addHeader("Accept", "application/json")
.addHeader("Authorization", "Bearer " + API_KEY)
.build();
try {
Response response = client.newCall(request).execute();
String json = response.body().string();
// 解析返回的内容
ObjectMapper mapper = new ObjectMapper();
JsonNode root = mapper.readTree(json);
JsonNode choices = root.get("choices");
if (choices != null && choices.isArray() && choices.size() > 0) {
return choices.get(0).get("message").get("content").asText();
}
return "No response content found.";
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
测试类:
package com.oracle.ai;
import com.oracle.ai.utils.LLMUtils;
public class utilTest {
public static void main(String[] args) {
String result = LLMUtils.completion("你是谁?", "deepseek-chat");
System.out.println(result);
}
}

2. 少样本提示
参考文档: https://juejin.cn/post/7257441472446038071
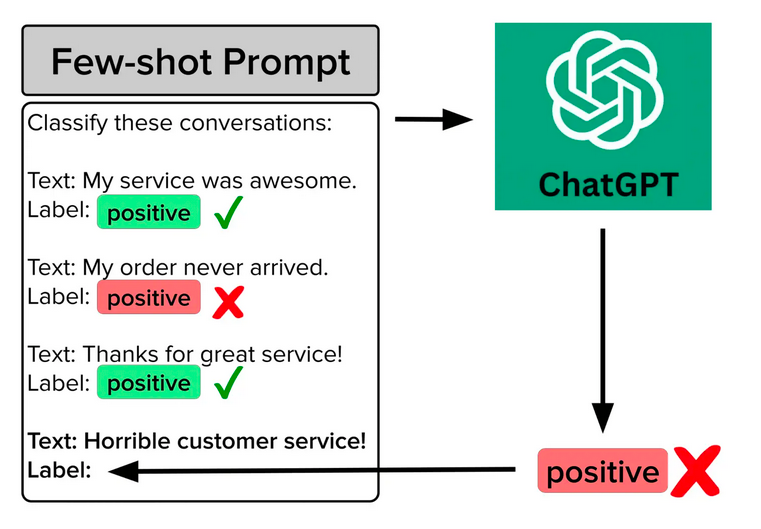
定义:少样本提示(Few-shot) 是指模型在完成任务之前,先提供几个示例来帮助模型理解任务。
例子:
-
提示:
"翻译以下句子:'The dog is in the garden.' -> '狗在花园里。' 'The bird is in the tree.' -> '鸟在树上。' 'The cat is on the roof.' ->" -
回答:
"猫在屋顶上。"
通过提供几个翻译示例,模型可以更准确地完成翻译任务。
相较于零样本提示,少样本提示能够提供更具体的任务信息,帮助模型更好地理解任务要求,从而提高任务性能。而且与传统的有监督训练需要大量的标注数据不同,少样本提示只需要少量的精心选择的示例即可,这对于数据获取困难或成本高昂的任务非常有利。
但是,少样本提示的效果对示例的选择非常敏感。示例的质量、多样性、代表性等因素都会影响模型的学习效果。如果示例过于简单或复杂、缺乏代表性或者存在错误,都可能导致模型学习到错误的任务模式。除此之外,这样做的代价是消耗更多的token,并且当输入和输出文本较长时,可能会达到上下文长度限制。
以相同的情感导向判别任务为例,利用少样本提示进行模型测试:
Prompt:
以下是一些示例句子及其情感导向,请根据这些示例句子的情感导向,判断后续例子的情绪类别。
示例1:《我不是药神》这部电影让人看了太感动了。情绪导向:积极
示例2:今天长沙的风太大了,真让人无语。情绪类别:消极
示例3:我觉得这个中秋节目中规中矩。情绪导向:中性
请判断下面句子的情绪类别:
句子1:今天是平平淡淡的一天。
句子2:马上要到周末拥有两天假期了,我特别开心。
句子3:我感到有点焦虑,因为下周一有一场重要的面试。
对应的输出信息:

尽管少样本提示能够提高模型在特定任务上的性能,但与经过大量数据充分训练的模型相比,其性能仍然有限。在一些复杂任务中,如复杂的逻辑推理、高精度的翻译等任务,少样本提示可能无法满足要求,仍然需要更多的训练数据和精细的训练方法来进一步提升模型性能。
少样本提示的限制
标准的少样本提示对许多任务都有效,但仍然不是一种完美的技术,特别是在处理更复杂的推理任务时。让我们演示为什么会这样。您是否还记得之前提供的任务:
这组数字中的奇数加起来是一个偶数:15、32、5、13、82、7、1。
A:
如果我们再试一次,模型输出如下:
是的,这组数字中的奇数加起来是107,是一个偶数。
这不是正确的答案,这不仅突显了这些系统的局限性,而且需要更高级的提示工程。
让我们尝试添加一些示例,看看少样本提示是否可以改善结果。
*提示:*
这组数字中的奇数加起来是一个偶数:4、8、9、15、12、2、1。
A:答案是False。这组数字中的奇数加起来是一个偶数:17、10、19、4、8、12、24。
A:答案是True。这组数字中的奇数加起来是一个偶数:16、11、14、4、8、13、24。
A:答案是True。这组数字中的奇数加起来是一个偶数:17、9、10、12、13、4、2。
A:答案是False。这组数字中的奇数加起来是一个偶数:15、32、5、13、82、7、1。
A:
输出:
答案是True。
这没用。似乎少样本提示不足以获得这种类型的推理问题的可靠响应。上面的示例提供了任务的基本信息。如果您仔细观察,我们引入的任务类型涉及几个更多的推理步骤。换句话说,如果我们将问题分解成步骤并向模型演示,这可能会有所帮助
3. 链式思考(CoT)
定义:链式思考(Chain-of-Thought) 是一种提示技术,通过展示模型思考过程的步骤来解决复杂问题。这种方法可以帮助模型更好地推理和生成答案。
上面的例子我们可以这样来实现:
这组数中的奇数加起来是偶数:4、8、9、15、12、2、1。
A:将所有奇数相加(9、15、1)得到25。答案为False。这组数中的奇数加起来是偶数:17、10、19、4、8、12、24。
A:将所有奇数相加(17、19)得到36。答案为True。这组数中的奇数加起来是偶数:16、11、14、4、8、13、24。
A:将所有奇数相加(11、13)得到24。答案为True。这组数中的奇数加起来是偶数:17、9、10、12、13、4、2。
A:将所有奇数相加(17、9、13)得到39。答案为False。这组数中的奇数加起来是偶数:15、32、5、13、82、7、1。
A:
输出:
将所有奇数相加(15、5、13、7、1)得到41。答案为False。
提示:
这组数中的奇数加起来是偶数:4、8、9、15、12、2、1。
A:将所有奇数相加(9、15、1)得到25。答案为False。这组数中的奇数加起来是偶数:15、32、5、13、82、7、1。
A:
输出:
将所有奇数相加(15、5、13、7、1)得到41。答案为False。
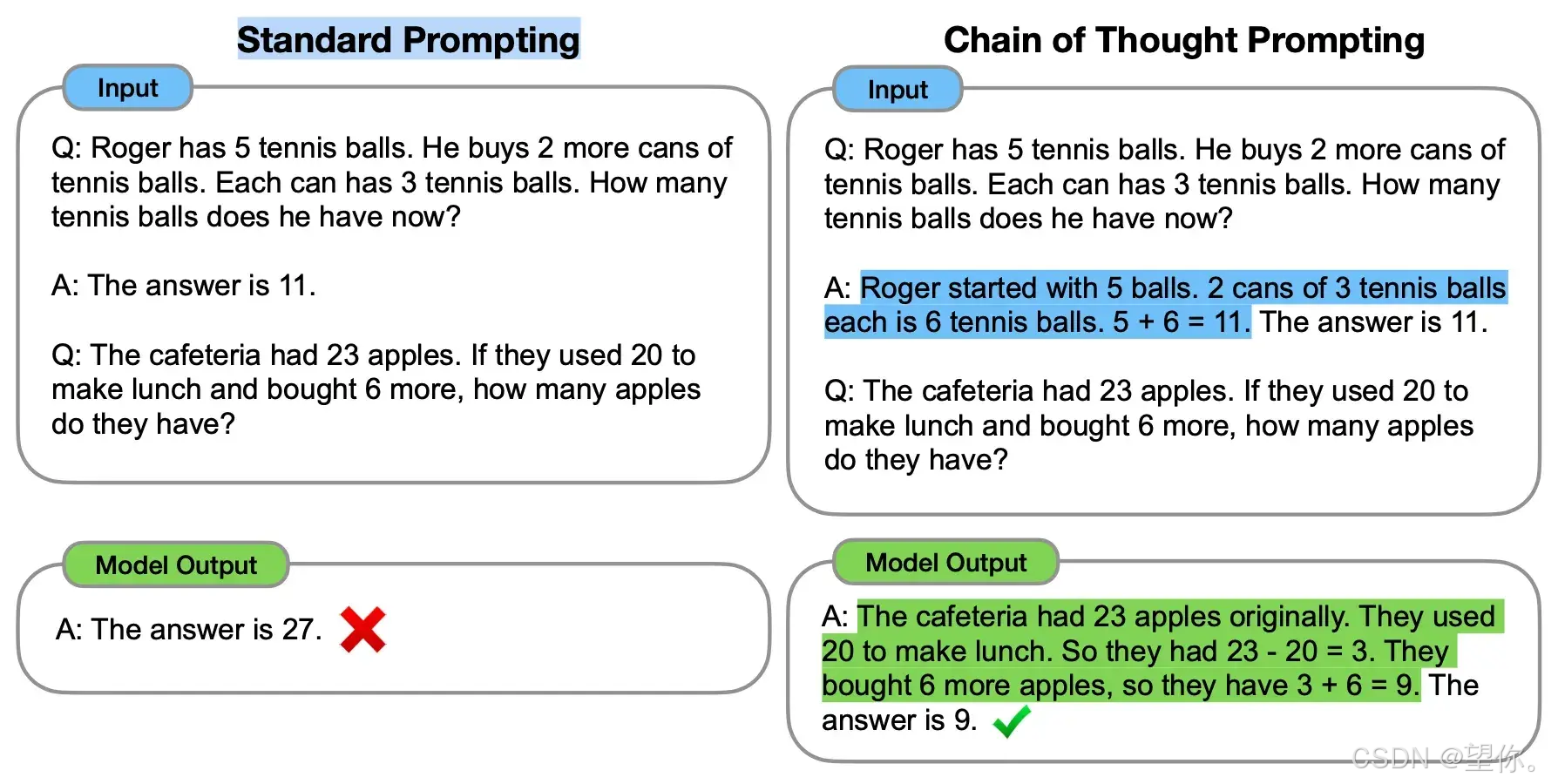
标准的prompt:
Q:罗杰有5个⽹球。他⼜买了2罐⽹球。每个罐⼦有3个⽹球。有多少他现在有多少个⽹球?
A:答案是11个
Q:⾃助餐厅有23个苹果。如果他们⽤20做午餐,⼜买了6个,他们有多少个苹果?
A:答案是27个
链式思考的prompt:
Q:罗杰有5个⽹球。他⼜买了2罐⽹球。每个罐⼦有3个⽹球。他现在有多少个⽹球?
A:罗杰⼀开始有5个球。2罐3个⽹球,等于6个⽹球。5 + 6 = 11。答案是11。
Q:⾃助餐厅有23个苹果。如果他们⽤20做午餐,⼜买了6个,他们有多少个苹果?
A:⾃助餐厅最初有23个苹果。他们使⽤20个做午饭。23 - 20 = 3。他们⼜买了6个苹果,得到3
+ 6= 9。答案是9个
该方法通过提供中间推理步骤实现了复杂的推理能力,可以结合少样本提示方法引导模型得到更加准确合理的输出,例如:
你是一位专业的健康顾问,需要帮助判断某人是否适合参加马拉松比赛。请使用链式思考方式,通过逐步推理来得出结论。以下是一个示例:
示例:
输入:年龄:25岁,心率:70次/分钟,过去6个月每周跑步3次,每次跑步10公里。
推理过程:
1. 该人年龄为25岁,属于马拉松适合人群的年轻年龄段。
2. 静息心率为70次/分钟,处于正常范围,说明心脏健康状况良好。
3. 过去6个月每周跑步3次,每次跑步10公里,表明该人有稳定的跑步习惯和良好的体能储备。
结论:该人适合参加马拉松比赛。
请根据以下输入进行推理:
输入:年龄:40岁,心率:85次/分钟,过去3个月每周跑步1次,每次跑步5公里。
推理过程:
结论:
输入给Chatgpt后得到的结果如下:

零样本 COT 提示 :

具体的案例:
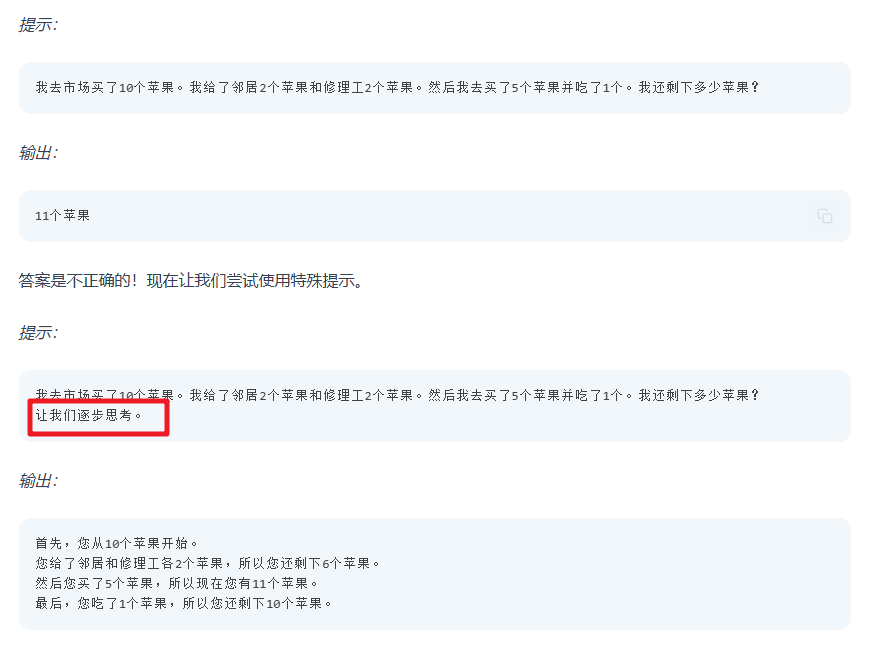
自动思维链(Auto-CoT)
当我们体验到思维链的好处之后也发现一个问题,生活中的场景这么多,如果每个场景我们都写个思维链,岂不要累死,于是Amazon Science团队提出了自动思维链(Auto-CoT)的概念,它通过自动化流程构建“让我们一步步思考”的思维过程,以提高模型在复杂推理任务中的表现。
自动思维链(Auto - CoT)是一种在自然语言处理领域,特别是针对复杂任务推理的自动化技术。它是思维链(CoT)方法的一种扩展,旨在自动生成思维链提示,而不是像传统 CoT 那样依赖人工设计的带有推理步骤的示例。其核心目标是通过自动化手段,让语言模型能够自动生成连贯的推理步骤来解决复杂问题,进一步提升模型在复杂任务中的性能。

具体的例子:
你是一位数学助理,需要解决数学问题并给出详细的推理过程。请根据问题的描述,
自动生成推理步骤并得出答案。回答时使用以下结构:
1. 问题描述
2. 推理过程
3. 答案
问题为:小明买了8个苹果和6个橙子,一个苹果3元,一个橙子5元。他用了50元纸币支付,
请问他应该找回多少钱?
输入给Chatgpt后得到的结果如下:

4. 自我一致性
也许在提示工程中更高级的技术之一是自我一致性。由 Wang等人(2022)(opens in a new tab) 提出,自我一致性旨在“替换链式思维提示中使用的天真贪婪解码方法”。其想法是通过少样本 CoT 采样多个不同的推理路径,并使用生成结果选择最一致的答案。这有助于提高 CoT 提示在涉及算术和常识推理的任务中的性能。
5. ReAct
定义:ReAct 是一种结合反应(Reaction)和行动(Action)的提示技术,通常用于交互式任务或复杂决策。
例子:
-
提示:
"你是一个虚拟助手。用户问:'我今天应该穿什么衣服?' 你需要根据天气情况给出建议。步骤1:查询天气。步骤2:根据天气给出建议。" -
回答:
-
-
步骤1:
"查询天气:今天的天气是晴天,温度在25-30度之间。" -
步骤2:
"建议:今天适合穿轻便的夏装,比如T恤和短裤。"
-
通过分步骤反应和行动,模型可以更有效地完成复杂任务。这块需要结合后面讲解的SpringAI等框架来实现。
6. Prompt Chaining
定义:Prompt Chaining 是将多个提示串联起来,以分步解决复杂问题或完成多步骤任务。
例子:
-
任务:写一篇关于气候变化的文章。
-
提示链:
“首先,简要介绍什么是气候变化。”-
“接下来,描述气候变化的主要原因。” -
“然后,讨论气候变化的影响。” -
“最后,提出应对气候变化的建议。”
通过将任务分解为多个步骤,模型可以更系统和有条理地完成复杂任务。
这些技术和方法帮助用户更有效地与大型语言模型互动,获得更高质量的输出。
另一个例子:
你是一位历史学家,需要逐步回答问题。请按照以下步骤完成:
1. 确定问题的核心内容。
2. 提供关于问题中涉及的历史事件的简要背景。
3. 分析该事件的主要原因。
4. 解释该事件对历史发展的主要影响。
5. 总结回答。
问题:请描述第二次世界大战的起因,并分析其对世界格局的影响。
7. 思维树(ToT)
对于需要探索或预判战略的复杂任务来说,传统或简单的提示技巧是不够的。思维树基于思维链提示进行了总结,引导语言模型探索把思维作为中间步骤来解决通用问题。
ToT 维护着一棵思维树,思维由连贯的语言序列表示,这个序列就是解决问题的中间步骤。使用这种方法,LLM 能够自己对严谨推理过程的中间思维进行评估。LLM 将生成及评估思维的能力与搜索算法(如广度优先搜索和深度优先搜索)相结合,在系统性探索思维的时候可以向前验证和回溯。
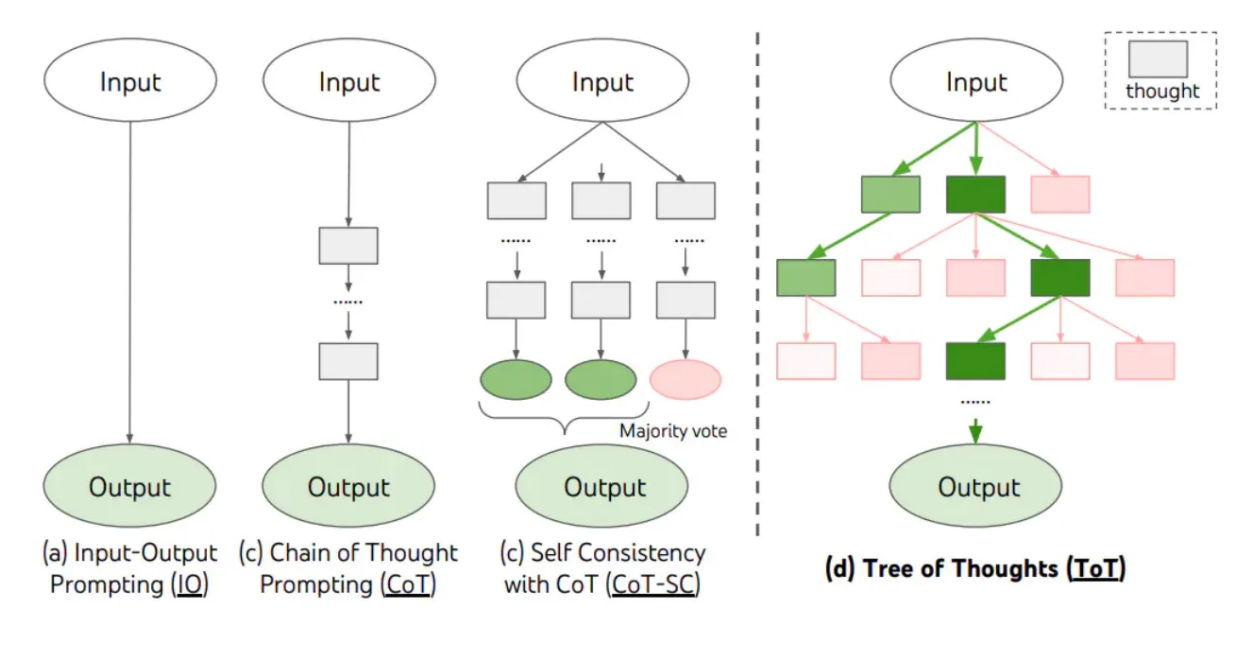
思维树的推理流程为:
-
语义理解:对输入的文本进行语义理解,将自然语言转换为计算机能够理解的形式,通常会使用一系列预训练的语义表示模型,如 BERT、GPT 等,来对输入文本进行编码和表示,从而捕捉到输入文本中的语义信息。
-
构建思维树:基于对输入文本的语义表示,构建一个思维树,以表示文本中的不同思维路径和关系。这个过程涉及到树状结构的设计和构建算法。
-
路径选择:在生成输出文本时,根据输入文本和构建的思维树选择合适的思维路径。该过程通常涉及到路径搜索算法,以确定最相关和最合适的思维路径,ToT 可以考虑到多个可能的思维路径,并根据输入文本的不同语义信息动态调整路径选择策略。
-
整合信息:选择了合适的思维路径后,从不同路径中获取信息,并将其整合起来,形成一个综合的理解。此过程涉及到信息融合和加权的算法,以确保生成的输出文本能够考虑到多个因素和可能性。
-
生成输出:根据整合的信息生成输出文本,通常采用生成式模型,如 GPT,来生成连贯、自然的文本。ToT 会根据整合的信息和选择的思维路径来指导文本生成过程,以生成准确、多样化的输出。
案例1:
任务:请解决以下迷宫路径规划问题,找到从起点 S 到终点 E 的最短路径。
采用树状推理(Tree of Thoughts, ToT)方法逐步展开路径选择。
问题:
迷宫如下(S为起点,E为终点,X为障碍):
S 0 0 X 0
X X 0 X 0
0 0 0 0 0
0 X X X E
步骤:
1. 在当前位置(初始为S)生成所有可能的下一步移动(上、下、左、右)。
2. 对每个移动进行评估(sure/maybe/impossible):
- sure:该路径通畅,且可能是通往终点的最优路径。
- maybe:该路径可能可行,但需要进一步尝试。
- impossible:该路径不可行或为死路。
3. 从评估结果中保留最佳候选路径,继续展开下一步。
4. 如果当前路径无解,回退到上一步并重新选择路径。
要求:
- 展示每一步的候选路径及其评估结果。
- 输出最终的最短路径及其总步数。
三、RAG
1.RAG基本介绍
1.1 LLM的缺陷
大型语言模型(LLM)虽然在很多方面表现出色,但也存在一些缺陷和局限性:
-
知识截止限制:LLM的知识是基于其训练数据的,这意味着它们对2025年之后发生的事件或最新发展可能缺乏了解或者理解不准确。
-
误解上下文:尽管LLM可以处理复杂的对话和文本,但有时候它们可能会误解问题的具体上下文或细微差别,导致回答不够精确或相关性不足。
-
生成错误信息:LLM有时会自信地提供看似合理但实际上不正确或虚构的信息。这是因为模型并非基于事实核查机制运行,而是根据概率模式生成回复。
-
伦理与偏见问题:如果训练数据中包含偏见,LLM可能会学习并反映这些偏见,从而在某些情况下产生不公平或有争议的回答。此外,如何确保AI行为符合道德规范也是一个持续讨论的话题。
-
过度泛化:LLM可能会在没有足够具体指导的情况下,尝试回答超出其实际能力范围的问题,导致答案表面看起来合理但实际上可能毫无意义或误导性强。
-
依赖大量计算资源:训练和部署大型语言模型需要大量的计算资源,这不仅成本高昂,而且对环境造成影响。
-
理解和推理能力有限:尽管LLM可以在表面上模仿人类的语言使用,但在深层次的理解、逻辑推理以及抽象思维方面仍然有限。
为了克服这些挑战,研究人员正在探索改进方法,包括更好的训练技术、更广泛的数据集、增强的事实核查机制以及开发更加透明和可控的模型架构。同时,也强调了跨学科合作的重要性,以确保技术进步的同时考虑到社会影响。
RAG + AGENT(FunctionCalling) + 微调
1.2 为什么会用到RAG
在大型语言模型(LLM)中使用Retrieval-Augmented Generation(RAG,检索增强生成)框架,主要是为了结合检索模型和生成模型的优势,以提高生成内容的准确性和相关性。
RAG的工作原理是首先通过一个检索组件从一个大规模的知识源或文档集合中找到与输入查询最相关的文本片段,然后将这些片段作为额外的上下文信息传递给生成组件。生成组件基于这个附加的上下文以及原始输入来生成最终的回答。这种方法有几个关键的优点:
-
提高准确性:通过引入外部知识库中的具体信息,可以显著提高回答问题的准确性,尤其是对于那些需要最新数据或非常特定领域知识的问题。
-
减少幻觉现象:LLM有时会自信地生成看似合理但实际上不正确的信息。通过使用RAG,可以使生成过程基于真实、具体的参考资料,从而减少这种“幻觉”。
-
增强上下文理解:对于复杂的查询,仅依靠模型内部参数可能无法充分捕捉所有细节。而通过检索到的相关文档段落作为补充,可以帮助模型更好地理解和响应查询。
-
灵活性:RAG允许根据不同任务的需求调整检索部分的数据源,使得它能够适应多样化的应用场景,如问答系统、摘要生成等。
总之,在LLM中采用RAG机制可以通过整合实时检索的信息来丰富模型的输出,使得生成的内容更加精准和可靠。这对于提升用户体验,特别是在专业领域或是需要引用具体事实的情况下尤为重要。
1.3 RAG概念
RAG(Retrieval Augmented Generation)顾名思义,通过检索外部数据,增强⼤模型的⽣成效果。
RAG即检索增强⽣成,为LLM提供了从某些数据源检索到的信息,并基于此修正⽣成的答案。RAG 基本上是Search + LLM 提示,可以通过大模型回答查询,并将搜索算法所找到的信息作为⼤模型的上下⽂。查询和检索到的上下⽂都会被注入到发送到 LLM 的提示语中。
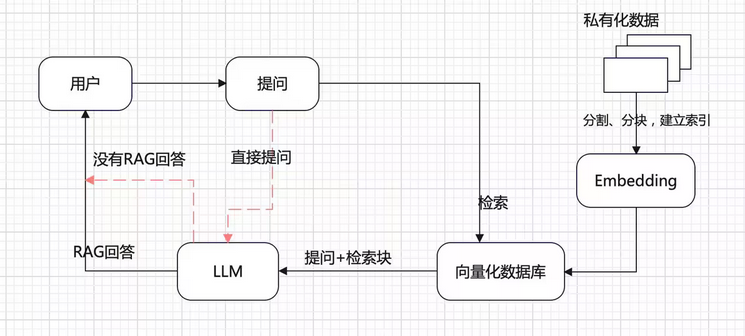
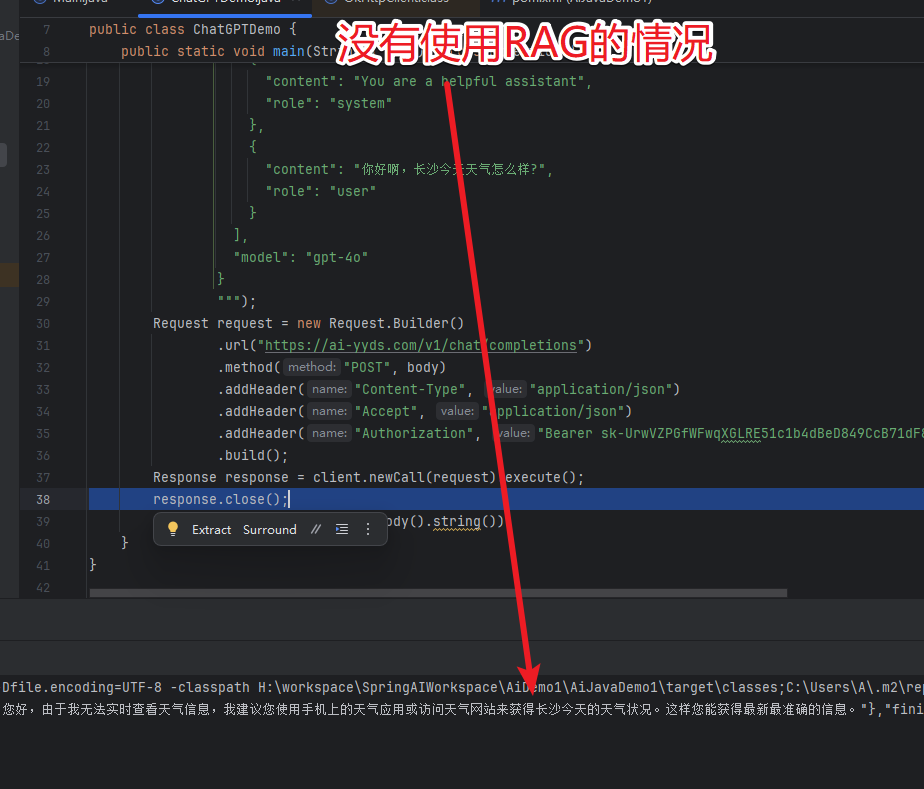
为什么需要一个向量数据库?
没有使用RAG的情况
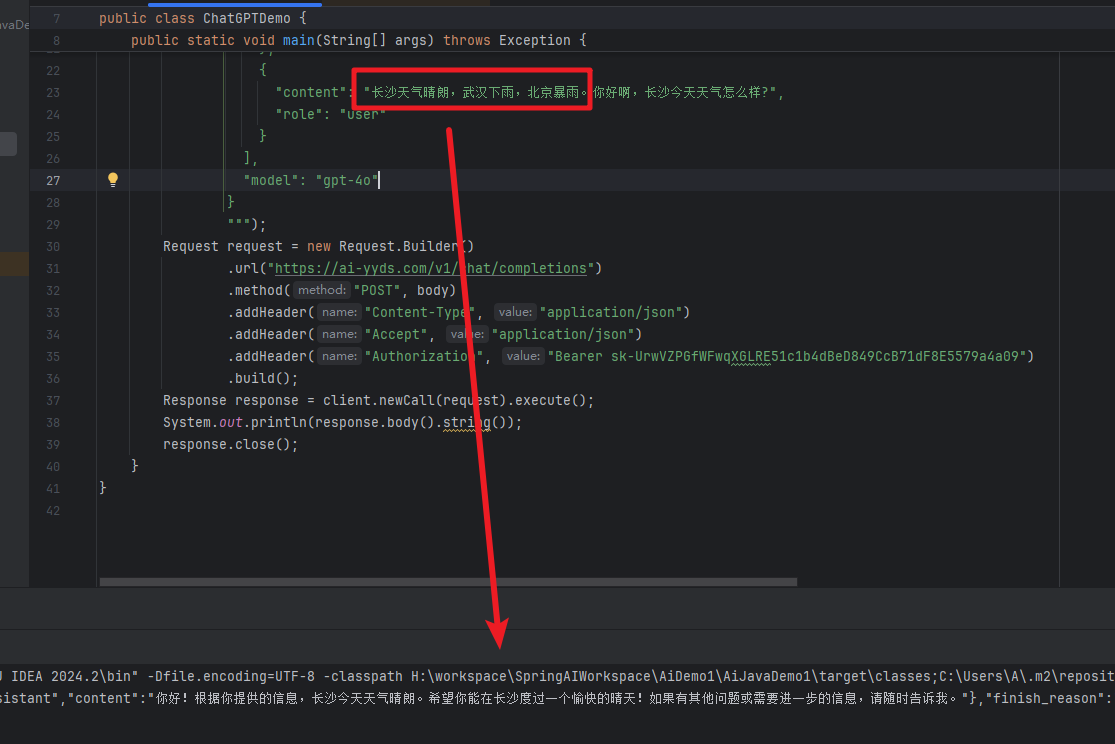
通过RAG来处理的效果
1.4 RAG vs Fine-tuning
LLM:高中毕业的学生
RAG:毕业后进入了企业。继承了家业。做了老总,不熟悉公司 的业务,但是配置了各种副总,业务负责人。这时老总做的各种决策都需要先和各个负责人沟通后做出
Fine-tuning:微调, 毕业后开始学习专业领域的系统知识,然后做相关的工作,比如7年学习医学,毕业后做医生
RAG(检索增强生成)与微调(Fine-tuning)是两种不同的方法,用于提高语言模型在特定任务上的性能。它们各有优缺点,适用于不同类型的应用场景。
RAG(检索增强生成)
概念:RAG是一种将信息检索和文本生成相结合的方法。它首先从一个大规模的知识库中检索出与输入相关的文档或片段,然后使用这些信息来辅助生成回答。
-
优点:
-
最新信息利用:由于可以实时从外部知识源检索最新信息,RAG能够提供更新鲜、更准确的答案。
-
减少幻觉:通过基于实际检索到的信息生成回复,减少了模型生成不正确或虚构内容的可能性。
-
灵活性:可以根据不同任务的需求调整检索的数据源,适应多样化的应用场景。
-
-
缺点:
-
复杂性增加:需要维护和访问外部知识库,增加了系统的复杂性和计算成本。
-
检索质量依赖:最终输出的质量高度依赖于检索步骤的准确性。
-
Fine-tuning(微调)
概念:微调是指在预训练模型的基础上,使用特定任务的数据集对模型进行进一步训练,以使其更好地适应该任务。
-
优点:
-
简化部署:一旦完成微调,模型可以直接应用于目标领域,无需额外的知识检索步骤。
-
性能优化:针对具体任务的数据进行微调,可以显著提升模型在该领域的表现。
-
一体化解决方案:对于不需要频繁更新知识库的任务,微调提供了一个较为简单的一体化解决方案。
-
-
缺点:
-
固定知识限制:微调后的模型其知识受限于训练数据的时间点,难以处理训练后出现的新信息。
-
过拟合风险:如果微调数据集不够大或者代表性不足,可能导致模型过拟合,影响泛化能力。
-
总结
选择RAG还是微调取决于具体的应用需求:
-
如果您的应用需要最新的信息,或者面对的是快速变化的领域(如新闻报道),那么RAG可能是一个更好的选择。
-
相反,如果您有一个明确且相对稳定的目标领域,并希望获得最佳性能,同时避免复杂的系统架构,微调可能是更合适的选择。
两者并非互斥,实际上,在某些情况下,结合使用RAG和微调可能会带来最好的结果,例如先通过微调使模型适应某个领域,再用RAG的方式增强其实时获取最新信息的能力。
1.5 RAG工作流程
RAG论⽂:https://arxiv.org/pdf/2312.10997
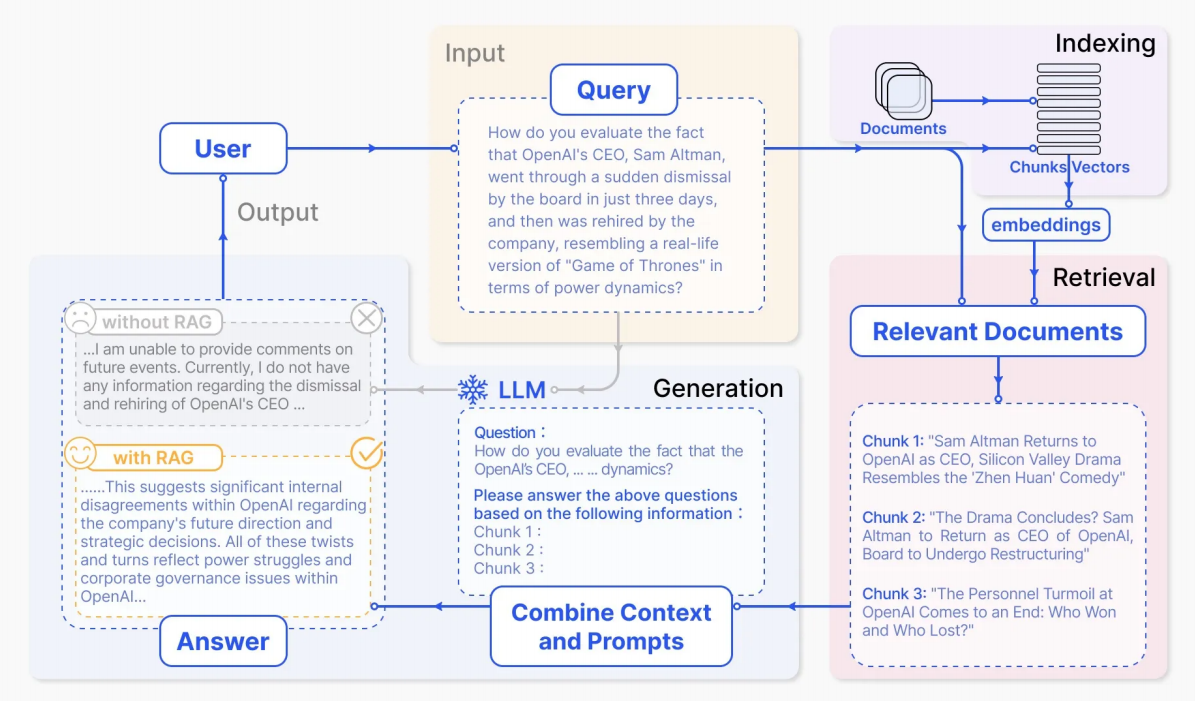
对应的中文版本
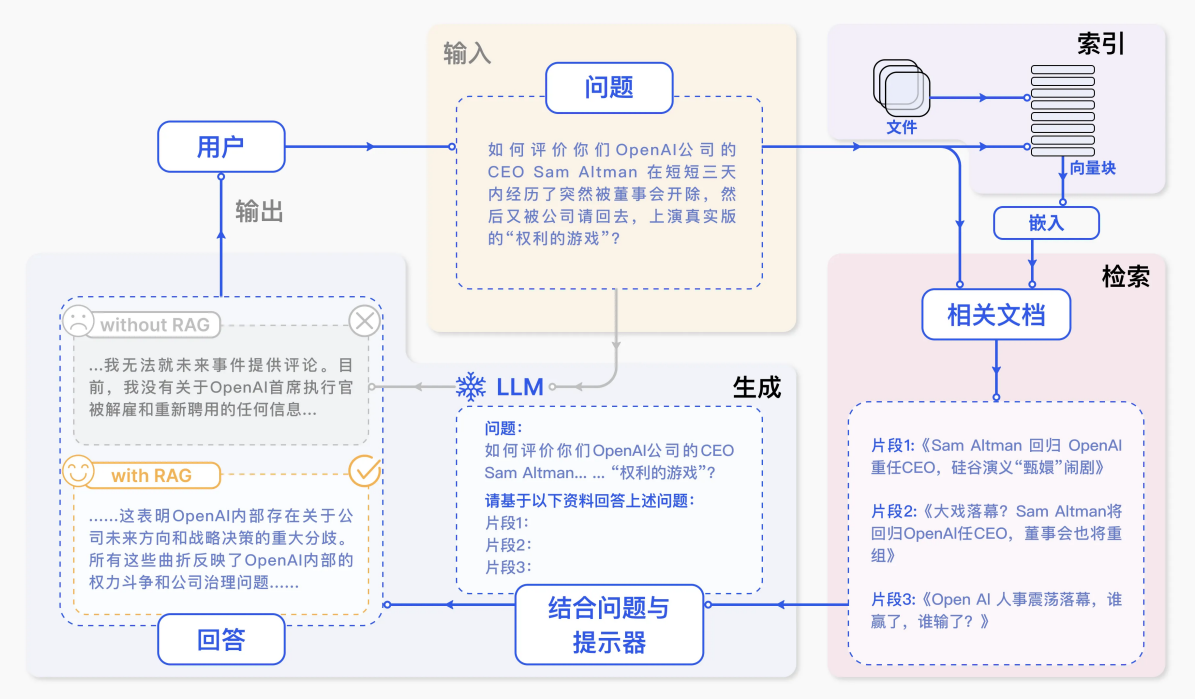
1.6 RAG系统的搭建流程
具体的搭建流程图如下:
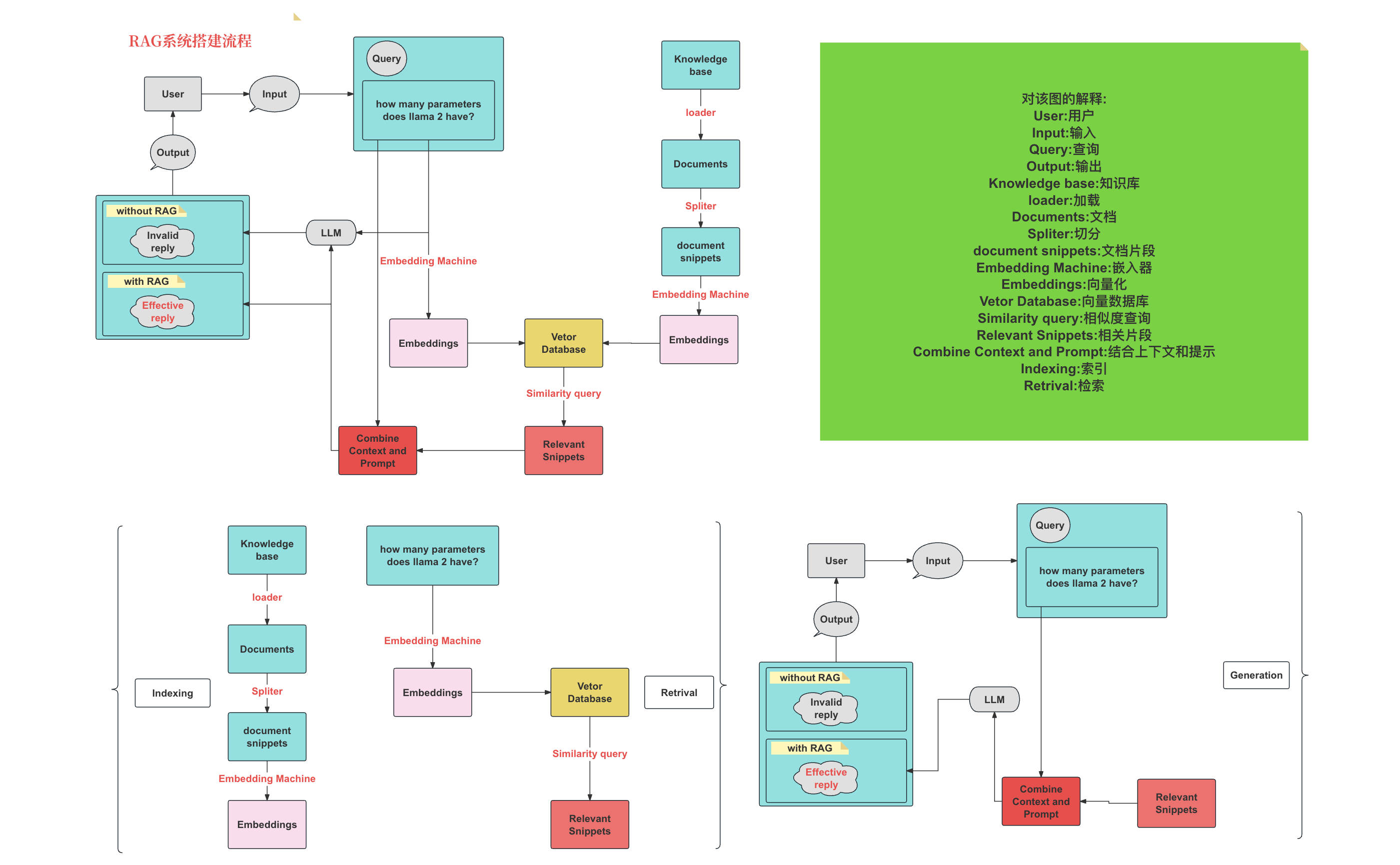
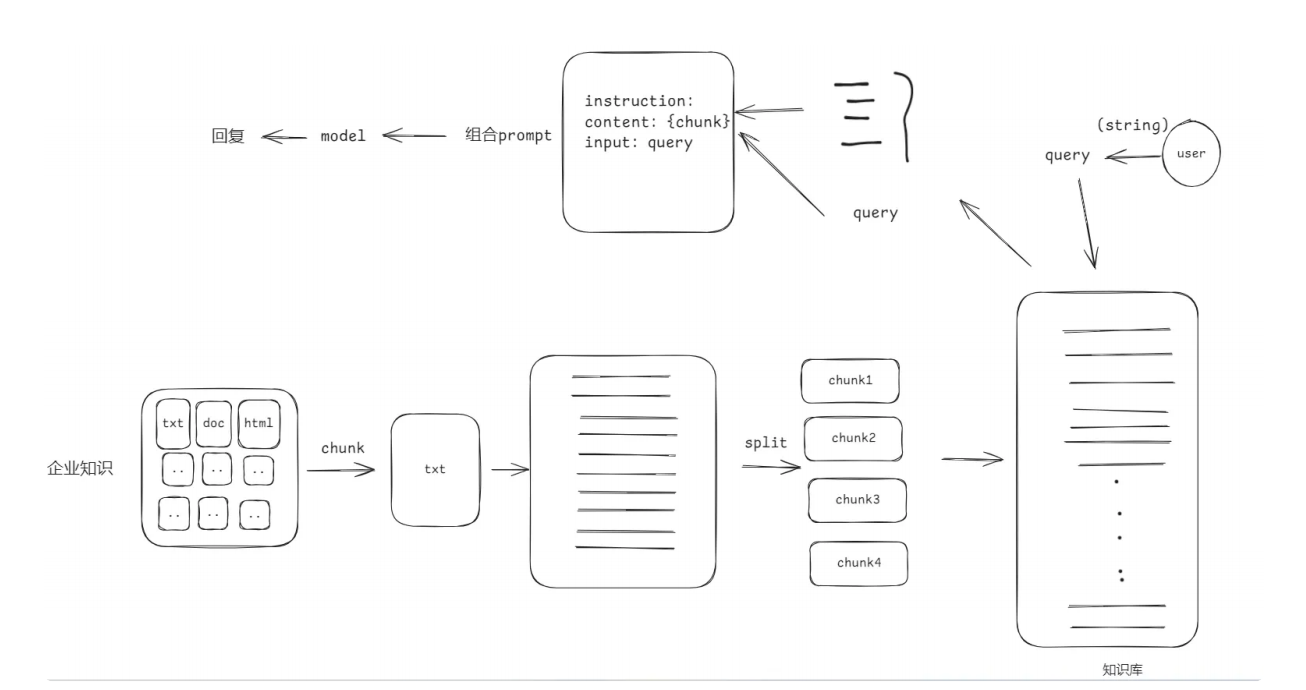
索引(Indexing):索引⾸先清理和提取各种格式的原始数据,如 PDF、HTML、 Word 和 Markdown,然后将其转换为统⼀的纯⽂本格式。为了适应语⾔模型的上下⽂限制,⽂本被分割成更⼩的、可消化的块(chunk)。然后使⽤嵌⼊模型将块编码成向量表示,并存储在向量数据库中。这⼀步对于在随后的检索阶段实现⾼效的相似性搜索⾄关重要。知识库分割成 chunks,并将 chunks 向量化⾄向量库中。
检索(Retrieval):在收到⽤户查询(Query)后,RAG 系统采⽤与索引阶段相同的编码模型将查询转换为向量表示,然后计算索引语料库中查询向量与块向量的相似性得分。该系统优先级和检索最⾼ k (Top-K)块,显示最⼤的相似性查询。
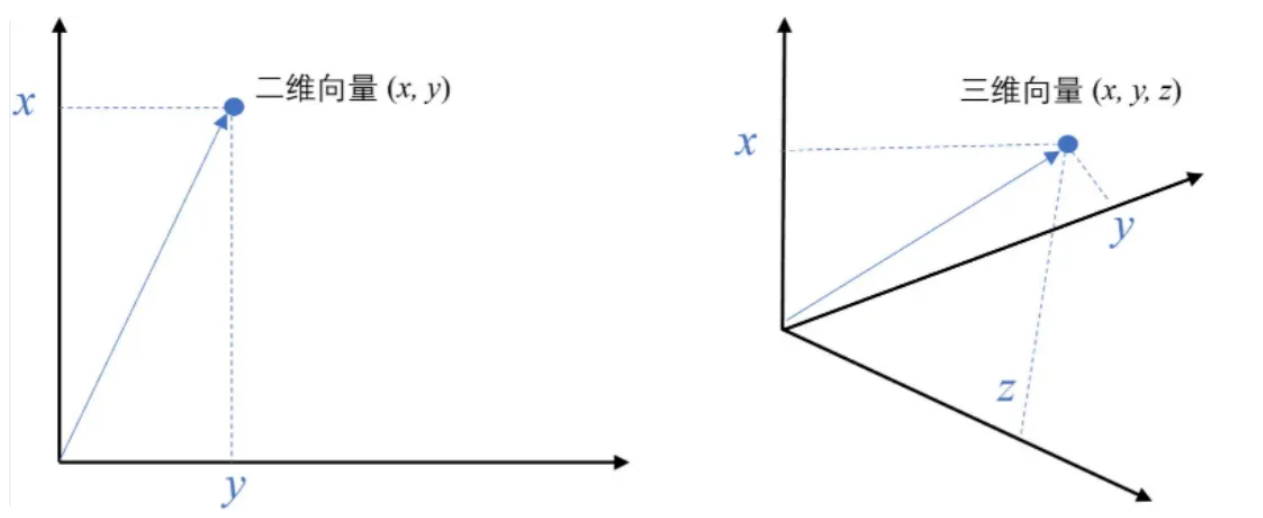
例如,⼆维空间中的向量可以表示为 (𝑥,𝑦),表示从原点 (0,0) 到点 (𝑥,𝑦) 的有向线段
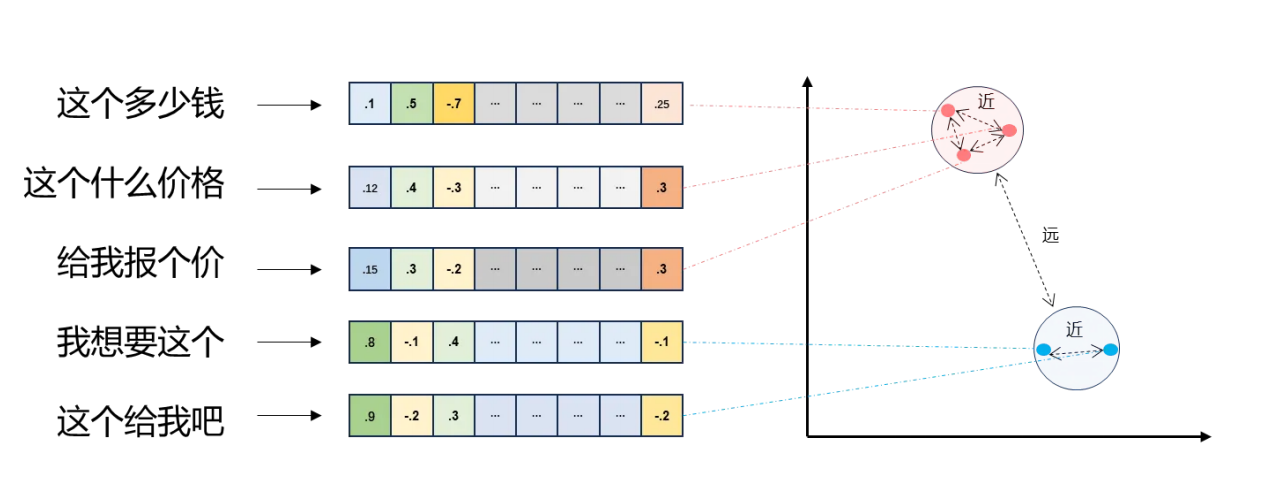
-
将⽂本转成⼀组浮点数:每个下标 i ,对应⼀个维度
-
整个数组对应⼀个 n 维空间的⼀个点,即⽂本向量又叫 Embeddings
-
向量之间可以计算距离,距离远近对应语义相似度大小
这些块随后被⽤作 prompt 中的扩展上下⽂。Query 向量化,匹配向量空间中相近的 chunks。
RAG具体实现流程:加载⽂件 => 读取⽂本 => 文本分割 =>文本向量化 =>输⼊问题向量化 =>在⽂本向量中匹配出与问题向量最相似的 top k 个 =>匹配出的⽂本作为上下⽂和问题⼀起添加到 prompt 中 =>提交给 LLM ⽣成回答。
2. RAG的核心内容
2.1 传统 VS 大模型
智能客服系统在没有大模型之前我们也是可以设计完成的只是实现的效果没有大模型那么好。下面是两则设计的原理
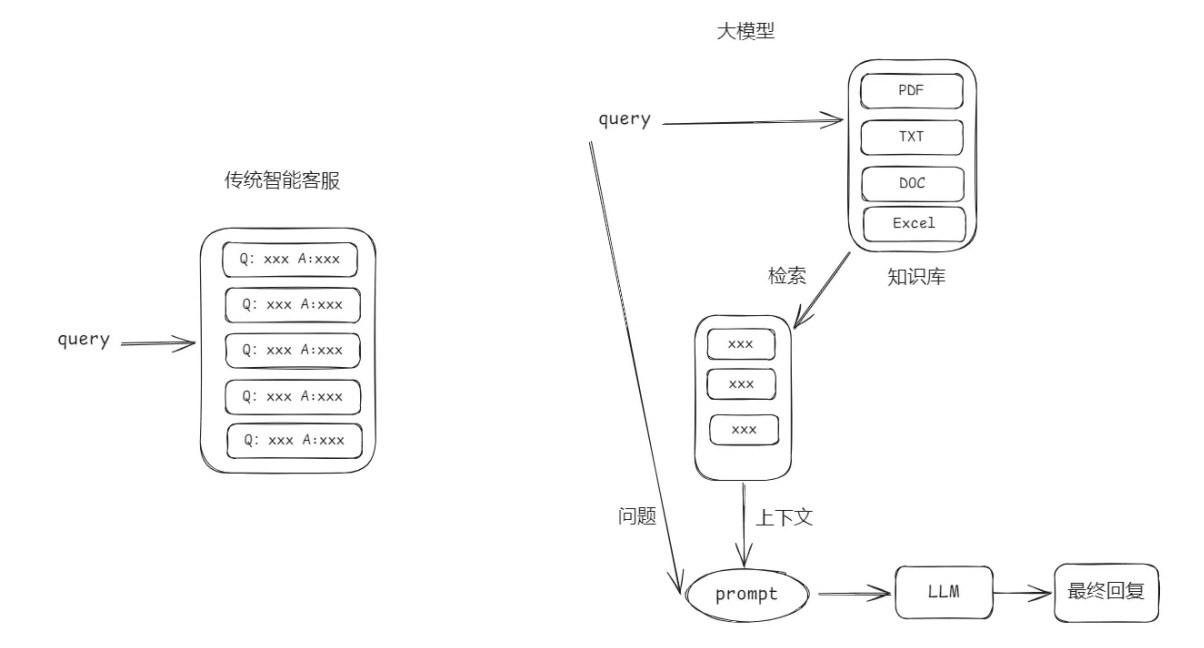
2.2 向量与Embeddings的定义
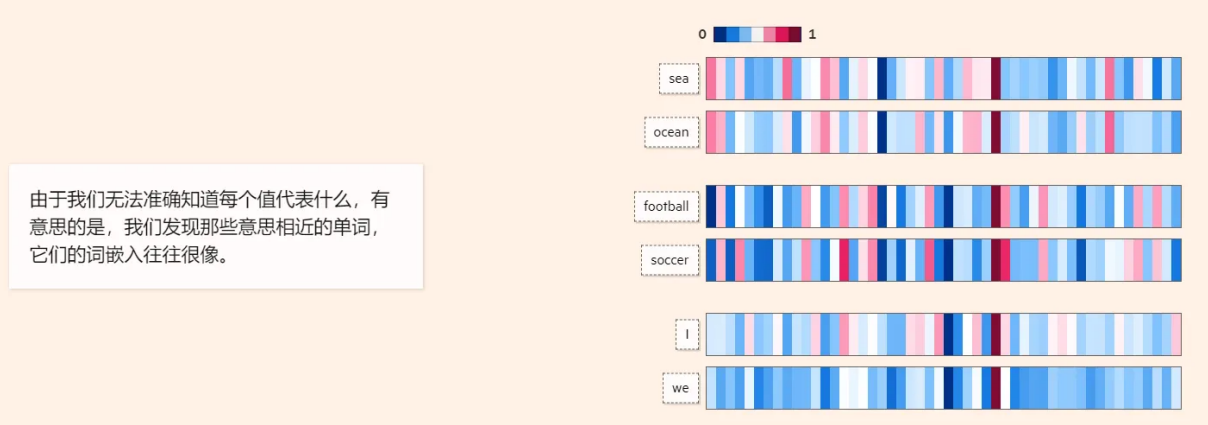
在数学中,向量(也称为欧几里得向量、几何向量),指具有⼤小(magnitude)和方向的量。它可以形象化地表示为带箭头的线段。箭头所指:代表向量的⽅向;线段⻓度:代表向量的大小。
text-embedding-3-large 是 OpenAI 推出的一个文本嵌入模型,属于 text-embedding-3 系列中的大尺寸版本。是一个功能强大、灵活性高的文本嵌入模型,适合处理复杂的自然语言任务。
封装的方法:
/**
* 实现文本转向量的公共方法
* @param prompt
* @param model
* @return
*/
public static float[] embedding(String prompt,String model){
if(model == null || model.isEmpty()){
model = "text-embedding-3-small";
}
OkHttpClient client = new OkHttpClient().newBuilder()
.connectTimeout(20, TimeUnit.SECONDS)
.readTimeout(20, TimeUnit.SECONDS)
.build();
MediaType mediaType = MediaType.parse("application/json");
RequestBody body = RequestBody.create(mediaType, String.format("""
{
"input": "%s",
"model": "%s"
}
""",prompt,model));
Request request = new Request.Builder()
.url(EMBEDDING_URL)
.method("POST", body)
.addHeader("Content-Type", "application/json")
.addHeader("Accept", "application/json")
.addHeader("Authorization", "Bearer "+API_KEY)
.build();
ObjectMapper mapper = new ObjectMapper();
try {
Response response = client.newCall(request).execute();
ResponseBody responseBody = response.body();
String json = responseBody.string();
EmbeddingResponse embeddingResponse = mapper.readValue(json, EmbeddingResponse.class);
return embeddingResponse.getData().get(0).getEmbedding();
}catch (Exception e){
e.printStackTrace();
}
return null;
}生成的数据信息:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": [
0.04382366,
0.02615503,
-0.019305877,
-0.021529805,
// ... 省略N个
0.0016807369,
0.024040252,
-0.023835596,
0.0054643136
]
}
],
"model": "text-embedding-3-small",
"usage": {
"prompt_tokens": 3,
"total_tokens": 3
}
}2.3 向量间的相似度计算
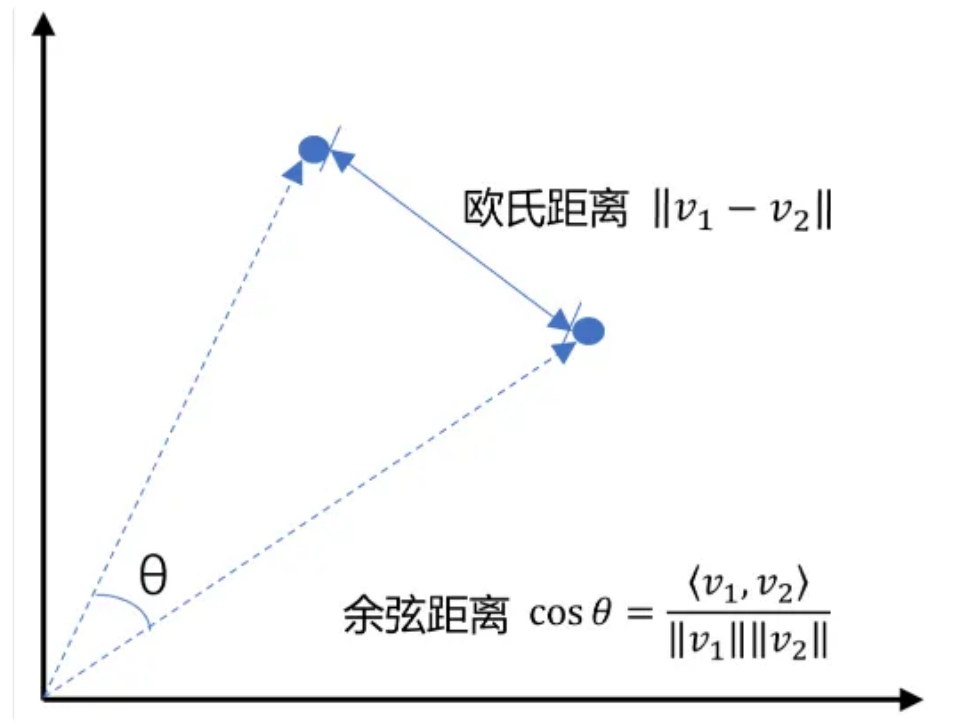
在处理向量数据时,计算向量之间的相似度是一个常见的需求。其中,欧式距离(Euclidean Distance)和余弦相似度(Cosine Similarity)是两种常用的计算方法。
欧式距离(Euclidean Distance)
欧式距离是指在n维空间中两个点之间的真实直线距离。它是基于几何学中的勾股定理来定义的。对于两个向量 ( A = [a_1, a_2, ..., a_n] ) 和 ( B = [b_1, b_2, ..., b_n] ),它们之间的欧式距离 ( d(A, B) ) 可以通过以下公式计算:
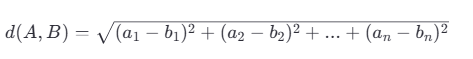
欧式距离越小,表示两个向量越接近。但是,欧式距离对数值大小非常敏感,如果向量的模长不一致,可能会导致不太准确的结果。
余弦相似度(Cosine Similarity)
余弦相似度衡量的是两个非零向量之间的角度差异。它关注的是向量的方向而非长度。对于两个向量 ( A ) 和 ( B ),它们之间的余弦相似度 ( \text{similarity}(A, B) ) 可以通过以下公式计算:
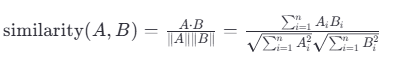
这里,( A \cdot B ) 表示向量 ( A ) 和 ( B ) 的点积,而 ( |A| ) 和 ( |B| ) 分别表示向量 ( A ) 和 ( B ) 的模长(即向量自身的平方和的平方根)。余弦相似度的值域为 [-1, 1],其中 1 表示完全相同的方向,-1 表示完全相反的方向,0 表示垂直或无相关性。
选择哪种方法?
-
欧式距离适用于当你关心向量的实际距离,且向量的尺度相对一致时。
-
余弦相似度更适合于比较文本、关键词向量等场景,因为这些情况下向量的方向比它们的模长更重要。
具体的案例演示代码,
先添加对应的依赖: commons-math3来处理向量运算
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>LLMUtils中封装的方法:
/**
* 余弦距离 -- 越⼤越相似
* @param a
* @param b
* @return
*/
public static double cosSim(RealVector a, RealVector b) {
return a.dotProduct(b) / (a.getNorm() * b.getNorm());
}
/**
* 欧式距离 -- 越⼩越相似
* @param a
* @param b
* @return
*/
public static double l2(RealVector a, RealVector b) {
return a.subtract(b).getNorm();
}
/**
* 把float[] 转换为 double[]
* @param floatArray
* @return
*/
public static double[] toDoubleArray(float[] floatArray){
if(floatArray == null){
return new double[0];
}
double[] doubleArray = new double[floatArray.length];
for (int i = 0; i < floatArray.length; i++) {
doubleArray[i] = floatArray[i];
}
return doubleArray;
}/**
* 向量的相似度计算
* @param args
*/
public static void main(String[] args) {
String query = "人工智能伦理";
List<String> documents = new ArrayList<>();
documents.add("全球科技巨头联合发布AI伦理指南,强调透明度与公平性");
documents.add("欧盟通过新的法规,要求所有AI系统必须符合严格的隐私保护标准");
documents.add("科学家警告:如果不加以控制,AI可能会加剧社会不平等");
documents.add("国际会议讨论如何防止AI武器化,并呼吁制定国际条约");
documents.add("某国政府宣布将投资数十亿美元用于支持可持续发展的AI技术研究");
float[] embedding = LLMUtils.embedding(query, null);
RealVector embeddingVector = new ArrayRealVector(LLMUtils.toDoubleArray(embedding));
System.out.println("欧式距离");
System.out.println(LLMUtils.l2(embeddingVector,embeddingVector));
for (String document : documents) {
float[] documentEmbedding = LLMUtils.embedding(document, null);
double v = LLMUtils.l2(embeddingVector, new ArrayRealVector(LLMUtils.toDoubleArray(documentEmbedding)));
System.out.println(v);
}
System.out.println("余旋");
System.out.println(LLMUtils.cosSim(embeddingVector,embeddingVector));
for (String document : documents) {
float[] documentEmbedding = LLMUtils.embedding(document, null);
double v = LLMUtils.cosSim(embeddingVector, new ArrayRealVector(LLMUtils.toDoubleArray(documentEmbedding)));
System.out.println(v);
}
}输出的结果:
Cosine distance:
1.0000000000000002
0.5811625770172754
0.46230002404509946
0.49677067320389034
0.43804091372901155
0.3740802379939319
Euclidean distance:
0.0
0.9152458153492501
1.0370149440545149
1.0032240985379848
1.0601500863195614
1.11885638522781882.4 文档的加载和分割
2.4.1 基于文档的LLM回复系统搭建
2.4.2 把文本切分成chunks
我们把文本切分成chunks的方式有很多种:
-
按照句子来切分
-
按照字符数来切分
-
按固定字符数 结合overlapping window
-
递归⽅法 RecursiveCharacterTextSplitter
2.4.2.1 按照句子来切分
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class ChineseSentenceSplitter {
public static List<String> splitChineseSentences(String text) {
// 匹配中文句子结束符:。?!\…\…(注意:需要转义)
String regex = "([。?!]|\\…\\…)";
Pattern pattern = Pattern.compile(regex);
Matcher matcher = pattern.matcher(text);
List<String> sentences = new ArrayList<>();
List<String> punctuations = new ArrayList<>();
int lastEnd = 0;
// 遍历所有匹配的标点符号位置
while (matcher.find()) {
// 句子主体
String sentence = text.substring(lastEnd, matcher.start() + 1);
sentences.add(sentence);
// 标点符号
punctuations.add(matcher.group(1));
lastEnd = matcher.end();
}
// 处理最后一个句子之后的内容(如果有的话)
if (lastEnd < text.length()) {
sentences.add(text.substring(lastEnd));
punctuations.add("");
}
// 重新组合句子和标点
List<String> result = new ArrayList<>();
for (int i = 0; i < sentences.size(); i++) {
String sentence = sentences.get(i);
String punctuation = (i < punctuations.size()) ? punctuations.get(i) : "";
result.add(sentence + punctuation);
}
return result;
}
public static void main(String[] args) {
String text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。";
List<String> chunks = splitChineseSentences(text);
for (int i = 0; i < chunks.size(); i++) {
System.out.printf("块 %d: 长度 %d: %s%n", i + 1, chunks.get(i).length(), chunks.get(i));
}
}
}输出的结果:
块 1: 55: 自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。
块 2: 21: 在这个领域,机器学习发挥着至关重要的作用。
块 3: 30: 利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。
块 4: 36: 从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。
块 5: 33: 随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。
块 6: 46: 如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。
块 7: 41: NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。2.4.2.2 按照字符数来切分
import java.util.ArrayList;
import java.util.List;
public class TextChunkSplitter {
/**
* 按照固定字符数将字符串分割为多个块
*
* @param text 要分割的文本
* @param chunkSize 每个块的最大字符数
* @return 分割后的字符串列表
*/
public static List<String> splitByFixedCharCount(String text, int chunkSize) {
List<String> chunks = new ArrayList<>();
int length = text.length();
for (int i = 0; i < length; i += chunkSize) {
int end = Math.min(i + chunkSize, length);
chunks.add(text.substring(i, end));
}
return chunks;
}
public static void main(String[] args) {
String text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。";
int chunkSize = 100; // 每块最多100个字符
List<String> chunks = splitByFixedCharCount(text, chunkSize);
for (int i = 0; i < chunks.size(); i++) {
String chunk = chunks.get(i);
System.out.printf("块 %d: 长度 %d: %s%n", i + 1, chunk.length(), chunk);
}
}
}输出结果:
块 1: 100: 自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所
块 2: 100: 理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理
块 3: 62: 解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。2.4.2.3 按固定字符数加滑动窗口
import java.util.ArrayList;
import java.util.List;
public class SlidingWindowTextSplitter {
/**
* 使用滑动窗口方式将字符串按固定字符数切分
*
* @param text 原始文本
* @param chunkSize 每一块的最大字符数
* @param stride 滑动步长(每次移动多少字符)
* @return 切分后的字符串列表
*/
public static List<String> slidingWindowChunks(String text, int chunkSize, int stride) {
List<String> chunks = new ArrayList<>();
int length = text.length();
if (chunkSize <= 0 || stride <= 0) {
throw new IllegalArgumentException("chunkSize 和 stride 必须大于0");
}
for (int i = 0; i < length; i += stride) {
int end = Math.min(i + chunkSize, length);
String chunk = text.substring(i, end);
chunks.add(chunk);
}
return chunks;
}
public static void main(String[] args) {
String text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。";
int chunkSize = 100; // 每块最大字符数
int stride = 50; // 滑动步长
List<String> chunks = slidingWindowChunks(text, chunkSize, stride);
for (int i = 0; i < chunks.size(); i++) {
String chunk = chunks.get(i);
System.out.printf("块 %d: 长度 %d: %s%n", i + 1, chunk.length(), chunk);
}
}
}输出的结果:
块 1: 100: 自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所
块 2: 100: 言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术
块 3: 100: 理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理
块 4: 100: 的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和
块 5: 62: 解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。
块 6: 12: 智能水平起到了关键作用。2.4.2.4 递归方法
递归字符文本分割通过指定字符(或字符组)进行分割,逐层尝试,直到每个块的大小小于指定的阈值。这种方法善于保持文本的语义完整性。
import java.util.*;
public class RecursiveCharacterTextSplitter {
private final List<String> separators;
private final int chunkSize;
private final int chunkOverlap;
public RecursiveCharacterTextSplitter(int chunkSize, int chunkOverlap, List<String> separators) {
this.separators = separators;
this.chunkSize = chunkSize;
this.chunkOverlap = chunkOverlap;
}
public List<String> splitText(String text) {
List<String> chunks = new ArrayList<>();
splitRecursive(text, chunks, 0);
return chunks;
}
private void splitRecursive(String text, List<String> chunks, int currentOverlap) {
if (text.length() <= chunkSize) {
chunks.add(text);
return;
}
// 尝试每个分隔符
for (String sep : separators) {
List<Integer> indices = findAllIndices(text, sep);
for (int i = indices.size() - 1; i >= 0; i--) {
int idx = indices.get(i);
// 找到最近的一个合适位置作为分割点
if (idx + sep.length() + currentOverlap <= chunkSize) {
String firstChunk = text.substring(0, idx + sep.length());
String rest = text.substring(idx + sep.length());
chunks.add(firstChunk);
splitRecursive(rest, chunks, Math.max(0, firstChunk.length() - (chunkSize - chunkOverlap)));
return;
}
}
}
// 如果所有分隔符都无法满足条件,则强制按字符数截断
chunks.add(text.substring(0, Math.min(chunkSize, text.length())));
if (text.length() > chunkSize) {
splitRecursive(text.substring(chunkSize), chunks, Math.max(0, chunkSize - chunkOverlap));
}
}
// 查找所有匹配的分隔符位置
private List<Integer> findAllIndices(String text, String separator) {
List<Integer> indices = new ArrayList<>();
int index = text.indexOf(separator);
while (index >= 0) {
indices.add(index);
index = text.indexOf(separator, index + separator.length());
}
return indices;
}
public static void main(String[] args) {
String text = "自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。";
RecursiveCharacterTextSplitter splitter = new RecursiveCharacterTextSplitter(
50, 10,
Arrays.asList("\n\n", "\n", "。", ",", " ", "")
);
List<String> chunks = splitter.splitText(text);
for (int i = 0; i < chunks.size(); i++) {
System.out.printf("块 %d: 长度 %d: %s%n%n", i + 1, chunks.get(i).length(), chunks.get(i));
}
}
}输出的结果:
块 1: 长度 34: 自然语言处理(NLP),作为计算机科学、人工智能与语言学的交融之地,
块 2: 长度 42: 致力于赋予计算机解析和处理人类语言的能力。在这个领域,机器学习发挥着至关重要的作用。
块 3: 长度 30: 利用多样的算法,机器得以分析、领会乃至创造我们所理解的语言。
块 4: 长度 36: 从机器翻译到情感分析,从自动摘要到实体识别,NLP的应用已遍布各个领域。
块 5: 长度 33: 随着深度学习技术的飞速进步,NLP的精确度与效能均实现了巨大飞跃。
块 6: 长度 46: 如今,部分尖端的NLP系统甚至能够处理复杂的语言理解任务,如问答系统、语音识别和对话系统等。
块 7: 长度 41: NLP的研究推进不仅优化了人机交流,也对提升机器的自主性和智能水平起到了关键作用。2.5 向量检索
检索的⽅式有哪些?列举两种:
1.关键字搜索:通过哟用户输⼊的关键字来查找⽂本数据
2.语义搜索:不仅考虑关键词的匹配,还考虑词汇之间的语义关系,以提供更准确的搜索结果。
2.5.1 关键字搜索
我们需要把相关的信息存储在Redis中。我们需要先按照一个Redis。在提供的资料中有。直接解压缩。然后cmd进入到对应的目录。然后输入
redis-server.exe来启动Redis服务。
然后需要导入Redis的依赖:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.0.0</version>
</dependency>然后我们可以通过代码把我们的数据导入到Redis中去。
创建对应的实体对象:
public class FaqItem {
private String instruction;
private String input;
private String output;
// Getters and Setters
public String getInstruction() {
return instruction;
}
public void setInstruction(String instruction) {
this.instruction = instruction;
}
public String getInput() {
return input;
}
public void setInput(String input) {
this.input = input;
}
public String getOutput() {
return output;
}
public void setOutput(String output) {
this.output = output;
}
@Override
public String toString() {
return "FaqItem{" +
"instruction='" + instruction + '\'' +
", input='" + input + '\'' +
", output='" + output + '\'' +
'}';
}
}
import com.boge.ai.entity.FaqItem;
import com.fasterxml.jackson.databind.ObjectMapper;
import redis.clients.jedis.Jedis;
import java.io.*;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Set;
public class FaqService {
private static final String REDIS_KEY_PREFIX = "faq:";
private static final ObjectMapper objectMapper = new ObjectMapper();
private final Jedis jedis;
public FaqService(Jedis jedis) {
this.jedis = jedis;
}
public void loadFaqDataToRedis() throws IOException {
InputStream inputStream = getClass().getClassLoader().getResourceAsStream("train_zh.json");
if (inputStream == null) {
throw new FileNotFoundException("File not found in resources: data.json");
}
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, StandardCharsets.UTF_8))) {
String line;
int index = 0;
while ((line = reader.readLine()) != null) {
if (line.trim().isEmpty()) continue;
FaqItem item = objectMapper.readValue(line, FaqItem.class);
String key = REDIS_KEY_PREFIX + index++;
jedis.set(key, line); // 存储原始字符串,方便后续读取
}
}
}
public List<FaqItem> searchInstructionByKeyword(String keyword,int topNum) throws IOException {
Set<String> keys = jedis.keys(REDIS_KEY_PREFIX + "*");
List<FaqItem> result = new ArrayList<>();
for (String key : keys) {
String json = jedis.get(key);
FaqItem item = objectMapper.readValue(json, FaqItem.class);
if (item.getInstruction().contains(keyword)) {
result.add(item);
}
if(result.size() >= topNum) {
break;
}
}
return result;
}
}
然后我们可以调用导入数据的方法:
/**
* 加载数据并存在到Redis中
* @throws Exception
*/
@Test
public void loadRedisFileData() throws Exception{
Jedis jedis = new Jedis("localhost", 6379);
FaqService faqService = new FaqService(jedis);
faqService.loadFaqDataToRedis();
}然后可以通过RDM工具来查看导入的数据:(2025 年最新)MacOS Redis Desktop Manager中文版下载,附详细图文_rdm下载-CSDN博客
然后我们就可以结合大模型来增强我们的功能了
LLM 接口封装:
/**
* 大模型操作的公共方法
*/
public class LLMUtils {
private static final String BASE_URL = "https://api.openai-hk.com/v1/chat/completions";
private static final String API_KEY = "hk-自己的key";
public static String completion(String prompt,String model){
OkHttpClient client = new OkHttpClient().newBuilder()
.connectTimeout(20, TimeUnit.SECONDS)
.readTimeout(20, TimeUnit.SECONDS)
.build();
MediaType mediaType = MediaType.parse("application/json");
String messages = String.format("""
{
"messages":
[
{
"role": "user",
"content": "%s"
}],
"model":"%s"
}
""", StringEscapeUtils.escapeJson(prompt), model);
//System.out.println(messages);
RequestBody body = RequestBody.create(mediaType, messages);
//System.out.println(body.toString());
Request request = new Request.Builder()
.url(BASE_URL)
.method("POST", body)
.addHeader("Content-Type", "application/json")
.addHeader("Accept", "application/json")
.addHeader("Authorization", "Bearer "+API_KEY)
.build();
Response response = null;
try {
response = client.newCall(request).execute();
ResponseBody responseBody = response.body();
String jsonString = responseBody.string();
System.out.println(jsonString);
ChatCompletionResponse chat = JsonToHashMapUtils.parseJsonToResponse(jsonString);
// 获取嵌套字段:例如 choices[0].message.content
return chat.getChoices().get(0).getMessage().getContent();
}catch (Exception e){
e.printStackTrace();
}finally {
response.close();
}
return null;
}
}Prompt模板
@Test
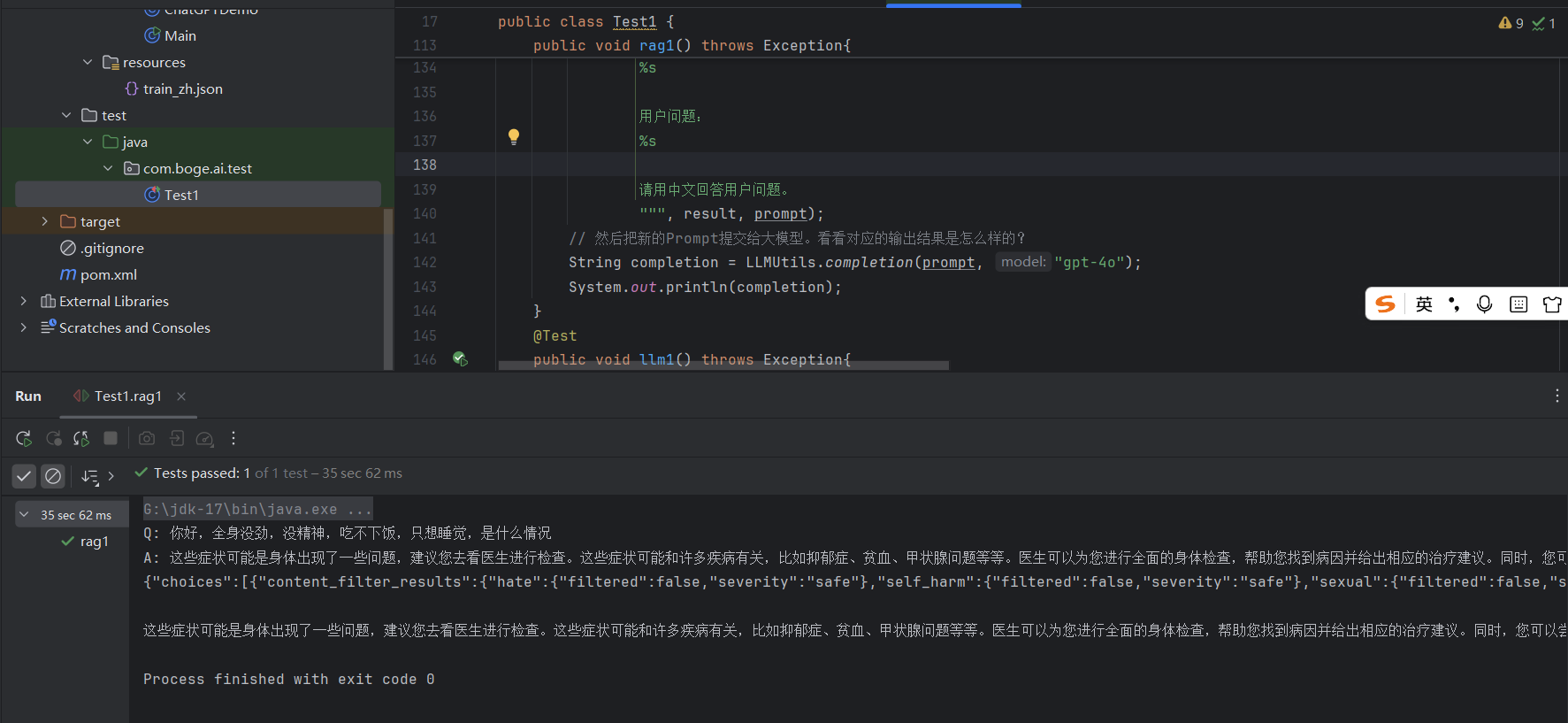
public void rag1() throws Exception{
String prompt = "没精神,吃不下饭";
// 检索相关的内容
Jedis jedis = new Jedis("localhost", 6379);
FaqService faqService = new FaqService(jedis);
List<FaqItem> list = faqService.searchInstructionByKeyword(prompt, 3);
// 把这个集合拼接为一个字符串
String result = list.stream()
.map(item -> "Q: " + item.getInstruction() + "\nA: " + item.getOutput())
.collect(Collectors.joining("\n"));
System.out.println(result);
// 构建 Prompt
prompt = String.format("""
# 角色
你是一个问答机器人。
你的任务是根据下述给定的已知信息回答用户问题。
根据已知信息的内容推理给出用户问题的解决方案
确保你的回复完全依据下述已知信息。不要编造答案。
如果下述已知信息不足以回答用户的问题,请直接回复"我无法回答您的问题"。
已知信息:
%s
用户问题:
%s
请用中文回答用户问题。
""", result, prompt);
// 然后把新的Prompt提交给大模型。看看对应的输出结果是怎么样的?
String completion = LLMUtils.completion(prompt, "gpt-4o");
System.out.println(completion);
}执行后的效果为:
2.5.2 向量数据库
在⼈⼯智能时代,向量数据库已成为数据管理和AI模型不可或缺的⼀部分。向量数据库是⼀种专⻔设计⽤来存储和查询向量嵌⼊数据的数据库。这些向量嵌⼊是AI模型⽤于识别模式、关联和潜在结构的关键数据表示。
随着AI和机器学习应⽤的普及,这些模型⽣成的嵌⼊包含⼤量属性或特征,使得它们的表示难以管理。这就是为什么数据从业者需要⼀种专⻔为处理这种数据⽽开发的数据库,这就是向量数据库的⽤武之地。
Pinecone
Pinecone: www.pinecone.io/
Pinecone的关键特性包括:
-
重复检测:帮助⽤户识别和删除重复的数据
-
排名跟踪:跟踪数据在搜索结果中的排名,有助于优化和调整搜索策略
-
数据搜索:快速搜索数据库中的数据,⽀持复杂的搜索条件
-
分类:对数据进⾏分类,便于管理和检索
-
去重:⾃动识别和删除重复数据,保持数据集的纯净和⼀致性
Milvus
Milvus: milvus.io/
Milvus的关键特性包括:
-
毫秒级搜索万亿级向量数据集
-
简单管理⾮结构化数据
-
可靠的向量数据库,始终可⽤
-
⾼度可扩展和适应性强
-
混合搜索
-
统⼀的Lambda结构
-
受到社区⽀持,得到⾏业认可
Chroma
Chroma: www.trychroma.com/
Chroma的关键特性包括:
-
功能丰富:⽀持查询、过滤、密度估计等多种功能
-
即将添加的语⾔链(LangChain)、LlamaIndex等更多功能
-
相同的API可以在Python笔记本中运⾏,也可以扩展到集群,⽤于开发、测试和⽣产
Faiss
Faiss:GitHub - facebookresearch/faiss: A library for efficient similarity search and clustering of dense vectors.
Faiss的关键特性包括:
-
不仅返回最近的邻居,还返回第⼆近、第三近和第k近的邻居
-
可以同时搜索多个向量,⽽不仅仅是单个向量(批量处理)
-
使⽤最⼤内积搜索⽽不是最⼩欧⼏⾥得搜索
-
也⽀持其他距离度量,但程度较低。
-
返回查询位置附近指定半径内的所有元素(范围搜索)
-
可以将索引存储在磁盘上,⽽不仅仅是RAM中
如何选型向量数据库
在选择适合项⽬的向量数据库时,需要根据项⽬的具体需求、团队的技术背景和资源情况来综合评估。以下是⼀些建议和注意事项:
向量嵌⼊的⽣成
-
如果已经有了⾃⼰的向量嵌⼊⽣成模型,那么需要的是⼀个能够⾼效存储和查询这些向量的数据库
-
如果需要数据库服务来⽣成向量嵌⼊,那么应该选择提供这类功能的产品
延迟要求
-
对于需要实时响应的应⽤程序,低延迟是关键。需要选择能够提供快速查询响应的数据库
-
如果应⽤程序允许批量处理,那么可以选择那些优化了⼤批量数据处理的数据库
开发⼈员的经验
-
根据团队的技术栈和经验,选择⼀个易于集成和使⽤的数据库
-
如果团队成员对某些技术或框架更熟悉,那么选择⼀个能够与之⽆缝集成的数据库会更有利
milvus演示
milvus安装教程参考我另一篇文章:【Windows系统】向量数据库Milvus安装教程-CSDN博客文章浏览阅读322次,点赞13次,收藏3次。本文介绍了在Windows系统上安装和配置Milvus向量数据库的步骤。首先,需要安装Docker Desktop和WSL。接着,修改Docker镜像配置以使用国内镜像源。然后,通过Docker Compose安装Milvus服务,并访问其Web UI。此外,还介绍了如何安装Attu可视化工具来连接和管理Milvus服务。最后,通过Java SDK测试Milvus服务的连接状态。整个过程包括镜像配置、服务安装、可视化工具使用和API测试,为开发者提供了全面的Milvus部署和测试指南。https://blog.csdn.net/qq_38196449/article/details/148056003?spm=1001.2014.3001.5501
我们先提供一个Milvus操作的工具方法
创建对应的实体对象:
public class MilvusEntity {
/**
* 向量数据库名称
*/
public static final String DB_NAME = "default";
/**
* 集合名称
*/
public static final String COLLECTION_NAME = "rag_collection";
/**
* 分片数量
*/
public static final int SHARDS_NUM = 1;
/**
* 分区数量
*/
public static final int PARTITION_NUM = 1;
/**
* 特征向量维度
*/
public static final Integer FEATURE_DIM = 1536;
/**
* 字段
*/
public static class Field {
/**
* id
*/
public static final String ID = "id";
/**
* 文本特征向量
*/
public static final String FEATURE = "feature";
/**
* 文本
*/
public static final String INSTRUCTION = "instruction";
/**
* 问答匹配的结果
*/
public static final String OUTPUT = "output";
}
}提供的操作方法工具类:
package com.oracle.ai.milvus;
import com.oracle.ai.milvus.MilvusEntity;
import io.milvus.client.MilvusServiceClient;
import io.milvus.grpc.DataType;
import io.milvus.grpc.MilvusExt;
import io.milvus.grpc.SearchResults;
import io.milvus.param.ConnectParam;
import io.milvus.param.IndexType;
import io.milvus.param.MetricType;
import io.milvus.param.collection.CreateCollectionParam;
import io.milvus.param.collection.FieldType;
import io.milvus.param.dml.InsertParam;
import io.milvus.param.dml.SearchParam;
import io.milvus.param.index.CreateIndexParam;
import io.milvus.response.SearchResultsWrapper;
import okhttp3.*;
import org.apache.commons.math3.linear.RealVector;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* Milvus 向量数据库的公共方法
*/
public class MilvusLLMUtils {
private MilvusServiceClient client ;
public MilvusLLMUtils() {
ConnectParam connectParam = ConnectParam.newBuilder()
.withHost("localhost")
.withPort(19530)
.build();
client = new MilvusServiceClient(connectParam);
}
/**
* 创建集合
* @throws Exception
*/
public void createCollection() throws Exception {
List<FieldType> fieldTypes = Arrays.asList(
FieldType.newBuilder()
.withName(MilvusEntity.Field.ID)
.withDescription("主键ID")
.withDataType(DataType.Int64)
.withPrimaryKey(true)
.withAutoID(true)
.build(),
FieldType.newBuilder()
.withName(MilvusEntity.Field.FEATURE)
.withDescription("特征向量")
.withDataType(DataType.FloatVector)
.withDimension(MilvusEntity.FEATURE_DIM) // 设置向量维度
.build(),
FieldType.newBuilder()
.withName(MilvusEntity.Field.TEXT)
.withDescription("输入数据")
.withDataType(DataType.VarChar)
.withTypeParams(Collections.singletonMap("max_length", "65535"))
.build(),
FieldType.newBuilder()
.withName(MilvusEntity.Field.OUTPUT)
.withDescription("问题答案数据")
.withDataType(DataType.VarChar)
.withTypeParams(Collections.singletonMap("max_length", "65535"))
.build());
CreateCollectionParam createCollectionReq = CreateCollectionParam.newBuilder()
.withCollectionName(MilvusEntity.COLLECTION_NAME)
.withDescription("rag collection")
.withShardsNum(MilvusEntity.SHARDS_NUM)
.withFieldTypes(fieldTypes)
.build();
client.createCollection(createCollectionReq);
// 同时给向量创建对应的索引
CreateIndexParam createIndexParam = CreateIndexParam.newBuilder()
.withCollectionName(MilvusEntity.COLLECTION_NAME)
.withFieldName(MilvusEntity.Field.FEATURE) // 向量字段名
.withIndexType(IndexType.IVF_FLAT) // 使用IVF_FLAT索引类型
.withMetricType(MetricType.L2) // 指定度量类型,如L2距离
.withExtraParam("{\"nlist\":128}") // 根据索引类型提供额外参数,比如nlist
.build();
client.createIndex(createIndexParam);
}
/**
* 插入数据到向量数据库
* @throws Exception
*/
public void insertVectoryData(List<Float> vectorParam,String text,String output) throws Exception {
createCollection();
List<List<Float>> floats = new ArrayList<>();
floats.add(vectorParam);
List<InsertParam.Field> fields = new ArrayList<>();
fields.add(new InsertParam.Field(MilvusEntity.Field.FEATURE, floats));
fields.add(new InsertParam.Field(MilvusEntity.Field.TEXT, Arrays.asList(text)));
fields.add(new InsertParam.Field(MilvusEntity.Field.OUTPUT, Arrays.asList(output)));
InsertParam insertParam = InsertParam.newBuilder()
.withCollectionName(MilvusEntity.COLLECTION_NAME)
.withFields(fields)
.build();
client.insert(insertParam);
}
/**
* 根据向量检索信息
* @param searchVectors
* @return
* @throws Exception
*/
public SearchResultsWrapper search(List<Float> searchVectors) throws Exception {
List<List<Float>> floats = new ArrayList<>();
floats.add(searchVectors);
SearchParam searchParam = SearchParam.newBuilder()
.withCollectionName(MilvusEntity.COLLECTION_NAME)
.withMetricType(MetricType.L2)// 使用 L2 距离作为相似度度量
.withTopK(3) // 返回最接近的前3个结果
.withVectors(floats)
.withVectorFieldName(MilvusEntity.Field.FEATURE) // 向量字段名
.withOutFields(Arrays.asList(MilvusEntity.Field.ID,MilvusEntity.Field.OUTPUT)) // 需要返回的字段
.build();
SearchResults data = client.search(searchParam).getData();
if(data != null) {
SearchResultsWrapper resultsWrapper = new SearchResultsWrapper(data.getResults());
resultsWrapper.getRowRecords().forEach(result -> {
System.out.println("Search result: " + result);
});
return resultsWrapper;
}
return null;
}
}
然后可以加载文本数据,然后向量化之后存储到Milvus中:
/**
* 加载文件中的数据
* 转换为对应的向量信息
* 存储到Milvus中
* 检索对应的信息
*
*/
@Test
public void fun1() throws Exception {
InputStream inputStream = getClass().getClassLoader().getResourceAsStream("train_zh.json");
MilvusLLMUtils milvusLLMUtils = new MilvusLLMUtils();
try (BufferedReader reader = new BufferedReader(
new InputStreamReader(inputStream, StandardCharsets.UTF_8))) {
String line;
int index = 0;
// 查询的关键字 的向量
List<List<Float>> qaEmbedding = TextSimilarityUtils.getEmbeddingsFloat(Arrays.asList("得了白癜风怎么办?"));
while ((line = reader.readLine()) != null) {
if (line.trim().isEmpty()) continue;
// 这里需要提取的是 instruction 的信息,然后向量化
FaqItem item = objectMapper.readValue(line, FaqItem.class);
String instruction = item.getInstruction();
List<List<Float>> embeddings = TextSimilarityUtils.getEmbeddingsFloat(Arrays.asList(instruction));
// 把数据存储到Milvus中
milvusLLMUtils.insertVectoryData(embeddings.get(0),instruction,item.getOutput());
//milvusLLMUtils.insertVectoryData(embeddings,instruction,item.getOutput());
}
// 查询
SearchResultsWrapper searchResultsWrapper = milvusLLMUtils.search(qaEmbedding.get(0));
List<QueryResultsWrapper.RowRecord> rowRecords = searchResultsWrapper.getRowRecords();
if(rowRecords != null && !rowRecords.isEmpty()){
System.out.println(rowRecords);
}
}
}