文章目录
- 前言
- 方法 (Methodology)
- 阅读内容和风格图像
- 预处理和后处理
- 抽取图像特征
- 定义损失函数
-
- 内容损失 (Content Loss)
- 风格损失 (Style Loss)
- 全变分损失 (Total Variation Loss)
- 总损失函数
- 初始化合成图像
- 训练模型
- 总结
前言
大家好!欢迎来到我们的深度学习代码学习系列。今天,我们将深入探讨一个非常有趣且富有创意的计算机视觉领域——风格迁移 (Style Transfer)。
想象一下,你能否将梵高的《星夜》的独特笔触和色彩应用到你拍摄的一张城市风景照片上?或者将一幅著名油画的风格赋予你心爱的宠物照片?风格迁移技术正是致力于实现这种艺术融合的魔法。
简单来说,风格迁移的目标是生成一张新的图像,这张图像既保留了内容图像 (Content Image) 的主要结构和物体,又融入了风格图像 (Style Image) 的艺术纹理、色彩和笔触特点。这背后是深度学习,特别是卷积神经网络 (CNN) 的强大能力,它们能够从图像中学习并分离出内容表示和风格表示。
在本篇博客中,我们将一起:
- 理解风格迁移的基本原理和核心思想。
- 逐步分析并实现一个基于 PyTorch 的风格迁移模型。
- 学习如何定义和使用内容损失、风格损失以及全变分损失来指导模型的优化过程。
- 通过代码实践,将一张内容图像和一张风格图像融合成一张全新的艺术作品。
我们将详细解读每一个代码块,确保即使是初学者也能跟上节奏。希望通过这篇博客,你能不仅理解风格迁移的理论,更能亲手实现它,感受深度学习在创意应用上的魅力。
让我们开始这场艺术与代码的探索之旅吧!
完整代码:下载链接
方法 (Methodology)
风格迁移的核心思想是利用预训练的卷积神经网络 (CNN) 来分别提取内容图像的内容特征和风格图像的风格特征。然后,我们以内容图像(或随机噪声)为起点,生成一张初始的合成图像。这个合成图像是整个过程中唯一需要更新和优化的部分。
迭代优化的目标是让合成图像在内容上接近内容图像,在风格上接近风格图像。这是通过定义一个总损失函数来实现的,该损失函数通常包含三个部分:
- 内容损失 (Content Loss):衡量合成图像与内容图像在内容特征上的差异。我们希望合成图像能“看清”内容图像中的物体和场景。
- 风格损失 (Style Loss):衡量合成图像与风格图像在风格特征(如纹理、笔触、色彩分布)上的差异。我们希望合成图像能“模仿”风格图像的艺术风格。
- 全变分损失 (Total Variation Loss):作为一种正则化项,用于减少合成图像中的噪点,使其更加平滑自然。
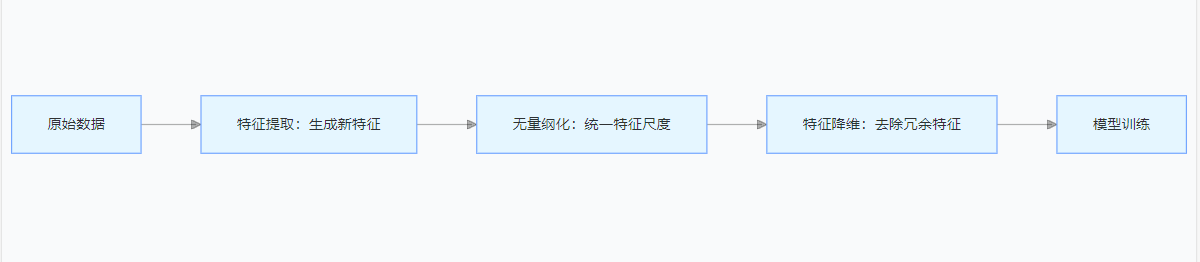
下图展示了风格迁移的基本流程:
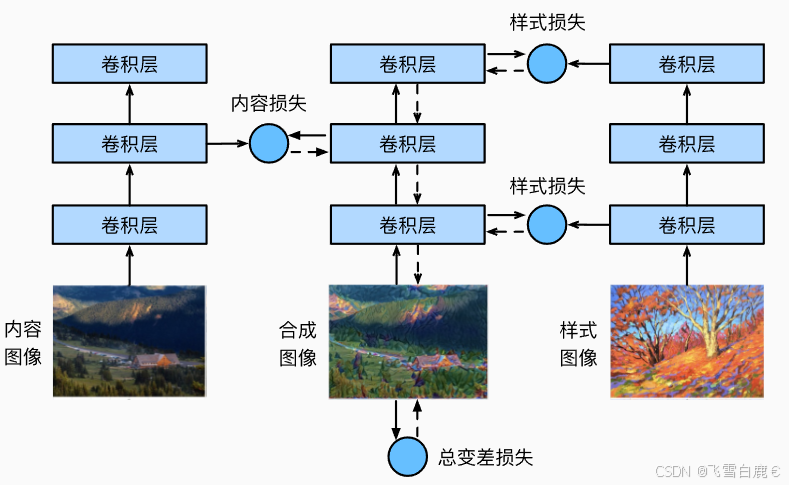
我们首先初始化合成图像,可以将其初始化为内容图像。该合成图像是风格迁移过程中唯一需要更新的变量,即风格迁移所需迭代的模型参数。然后,选择一个预训练的卷积神经网络来抽取图像的特征,其中的模型参数在训练中无须更新。这个深度卷积神经网络凭借多个层逐级抽取图像的特征,我们选择其中某些层的输出作为内容特征或风格特征。例如,上图中,预训练的神经网络含有多个卷积层和池化层,我们选择其中某些层的输出(如 relu4_2 作为内容特征,relu1_1, relu2_1, relu3_1, relu4_1, relu5_1 作为风格特征)。
接下来,通过前向传播计算风格迁移的损失函数,并通过反向传播迭代模型参数,即不断更新合成图像。当模型训练结束时,输出风格迁移的模型参数,即得到最终的合成图像。
阅读内容和风格图像
首先,我们需要加载我们的内容图像和风格图像。这里我们使用 PIL (Pillow) 库来加载图像,并用 Matplotlib 来显示它们。
# 图像风格迁移预处理代码
# 配置 matplotlib 行内显示|
%matplotlib inline
# 导入必要的库
import torch # PyTorch 深度学习框架
import torchvision # PyTorch 的计算机视觉工具包
from torch import nn # 神经网络模块
import utils_for_huitu # 自定义的绘图工具模块
import matplotlib.pyplot as plt # 用于创建和操作 Matplotlib 图表
from PIL import Image # Python 图像处理库
# 设置 matplotlib 图表的默认尺寸
# 该函数可能会设置全局的图表显示参数
utils_for_huitu.set_figsize()
# 加载内容图像
# content_img: PIL Image 对象,维度为 (height, width, channels)
# 其中 channels 通常为 3(RGB)或 4(RGBA)
content_img = Image.open('img/test.jpeg')
# 显示内容图像
# plt.imshow() 接受形状为 (H, W, C) 的数组,其中:
# H: 图像高度
# W: 图像宽度
# C: 颜色通道数(RGB为3)
plt.imshow(content_img)
plt.show() # 显示图像
# 获取图像信息(可选)
if hasattr(content_img, 'size'):
# 获取图像的宽度和高度
img_width, img_height = content_img.size # PIL图像的尺寸为 (width, height)
print(f"内容图像尺寸:宽度={
img_width}px, 高度={
img_height}px")
内容图像 img/test.jpeg 显示如下:
内容图像尺寸:宽度=600px, 高度=333px
![[跳过图片具体内容]](https://i-blog.csdnimg.cn/direct/d3923c08085e4ebdbd917eba7f6f5ef8.png)
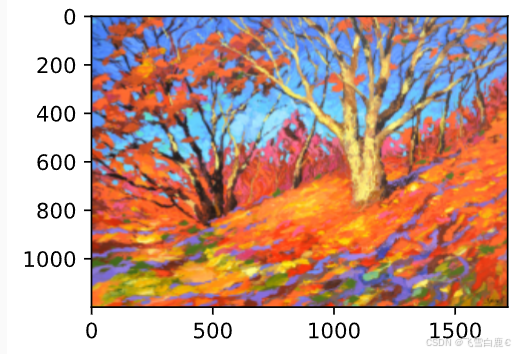
style_img = Image.open('img/06_autumn-oak.jpg')
plt.imshow(style_img);
风格图像 img/06_autumn-oak.jpg 显示如下:
预处理和后处理
接下来,我们定义两个函数:preprocess 和 postprocess。这两个函数负责将我们加载的 PIL 图像转换为神经网络可以处理的张量格式,以及在训练完成后将张量转换回图像格式以便显示。
预处理函数 preprocess 主要执行以下操作:
- 将输入图像的大小调整为指定的
image_shape。 - 将 PIL 图像转换为 PyTorch 张量。这个过程会自动将图像的维度从 (H, W, C) 转换为 (C, H, W),并将像素值从 [0, 255] 的范围归一化到 [0, 1] 的范围。
- 对图像在 RGB 三个通道上分别进行标准化,使用的是 ImageNet 数据集的均值和标准差。
- 在张量的最前面添加一个批次维度,最终输出格式为 (1, C, H, W)。
后处理函数 postprocess 则执行相反的操作:
- 移除批次维度。
- 对标准化的张量进行反标准化,恢复其原始的像素值范围。
- 将像素值裁剪到 [0, 1] 之间,以确保可以正确显示。
- 将张量转换回 PIL 图像格式。
# 图像预处理和后处理函数
import torch
import torchvision
# ImageNet 数据集的 RGB 通道均值
# 维度: [3] - 分别对应 R、G、B 三个通道
rgb_mean = torch.tensor([0.485, 0.456, 0.406])
# ImageNet 数据集的 RGB 通道标准差
# 维度: [3] - 分别对应 R、G、B 三个通道
rgb_std = torch.tensor([0.229, 0.224, 0.225])
def preprocess(img, image_shape):
"""
预处理函数:将 PIL 图像转换为标准化的张量
参数:
- img: PIL Image 对象,维度为 (H, W, C)
- image_shape: 目标图像尺寸,元组格式 (H, W)
返回:
- 处理后的张量,维度为 [1, C, H, W]
其中:1 是批次维度,C=3(RGB通道),H 是高度,W 是宽度
"""
# 定义图像变换流水线
transforms = torchvision.transforms.Compose([
# 1. 调整图像大小到指定尺寸
# 输入: PIL Image (H, W, C)
# 输出: PIL Image (image_shape[0], image_shape[1], C)
torchvision.transforms.Resize(image_shape),
# 2. 将 PIL 图像转换为张量
# 输入: PIL Image (H, W, C),像素值范围 [0, 255]
# 输出: torch.Tensor [C, H, W],像素值范围 [0, 1]
torchvision.transforms.ToTensor(),
# 3. 标准化:(x - mean) / std
# 输入: torch.Tensor [C, H, W]
# 输出: torch.Tensor [C, H, W],标准化后的值
torchvision.transforms.Normalize(mean=rgb_mean, std=rgb_std)
])
# 应用变换并添加批次维度
# transforms(img): 维度 [C, H, W]
# unsqueeze(0): 维度 [1, C, H, W]
return transforms(img).unsqueeze(0)
def postprocess(img):
"""
后处理函数:将标准化的张量转换回 PIL 图像
参数:
- img: 标准化的张量,维度为 [B, C, H, W],其中 B 是批次大小
返回:
- PIL Image 对象,维度为 (H, W, C)
"""
# 1. 提取第一个样本(移除批次维度)
# img[0]: 维度从 [B, C, H, W] 变为 [C, H, W]
img = img[0].to(rgb_std.device)
# 2. 反标准化:x * std + mean
# 2.1 permute(1, 2, 0): 维度从 [C, H, W] 变为 [H, W, C]
# 2.2 乘以标准差并加上均值,恢复原始值范围
# 2.3 torch.clamp(..., 0, 1): 将值限制在 [0, 1] 范围内
# 结果维度: [H, W, C]
img = torch.clamp(img.permute(1, 2, 0) * rgb_std + rgb_mean, 0, 1)
# 3. 转换回 PIL 图像
# 3.1 permute(2, 0, 1): 维度从 [H, W, C] 变为 [C, H, W]
# 3.2 ToPILImage(): 将张量转换为 PIL Image
# 输出: PIL Image 对象,维度为 (H, W, C)
return torchvision.transforms.ToPILImage()(img.permute(2, 0, 1))
# 使用示例:
# 预处理
pil_image = Image.open('img/05_rainier.jpg') # PIL Image (H, W, C)
print(pil_image)
tensor = preprocess(pil_image, (224, 224)) # 输出 [1, 3, 224, 224]
print(tensor.shape)
关于 torchvision.transforms.ToTensor() 的关键点总结:
- 维度转换:
- 输入:PIL Image
(H, W, C)或 numpy array。 - 输出:PyTorch Tensor
[C, H, W]。 - 它会自动将通道维度从最后一维移动到第一维。
- 输入:PIL Image
- 设计原因:
- PyTorch 的标准张量格式是
[B, C, H, W](批次、通道、高度、宽度),这是卷积神经网络期望的输入格式。 - 这种内存布局在 GPU 计算时更为高效。
- PyTorch 的标准张量格式是
- 不同图像类型处理:
- RGB图像:
(H, W, 3)→[3, H, W] - 灰度图像:
(H, W)→[1, H, W](自动添加通道维度) - RGBA图像:
(H, W, 4)→[4, H, W]
- RGB图像:
- 同时进行的操作:
- 数据类型转换:
uint8→float32 - 数值范围转换:
[0, 255]→[0, 1]
- 数据类型转换:
抽取图像特征
我们将使用基于 ImageNet 数据集预训练的 VGG-19 模型来抽取图像特征。VGG-19 是一个深度卷积神经网络,因其良好的特征提取能力而常用于风格迁移任务。
首先,我们加载预训练的 VGG-19 模型。为了方便管理模型权重文件,我们先设置了权重的下载路径。PyTorch 会自动从网络下载预训练权重(如果本地不存在的话)。
# VGG19 预训练模型加载与配置
import os
import torch
import torchvision
# 设置预训练模型权重的下载路径
# 注意:这必须在加载模型之前设置,否则权重会下载到默认路径
download_path = './model_weights' # 自定义权重保存路径
# 确保下载目录存在,如果不存在则创建
# exist_ok=True 表示如果目录已存在不会报错
os.makedirs(download_path, exist_ok=True)
# 方法1:使用 torch.hub.set_dir() 设置下载缓存目录
# 这会设置 PyTorch Hub 的默认下载目录
torch.hub.set_dir(download_path)
# 方法2:通过环境变量设置