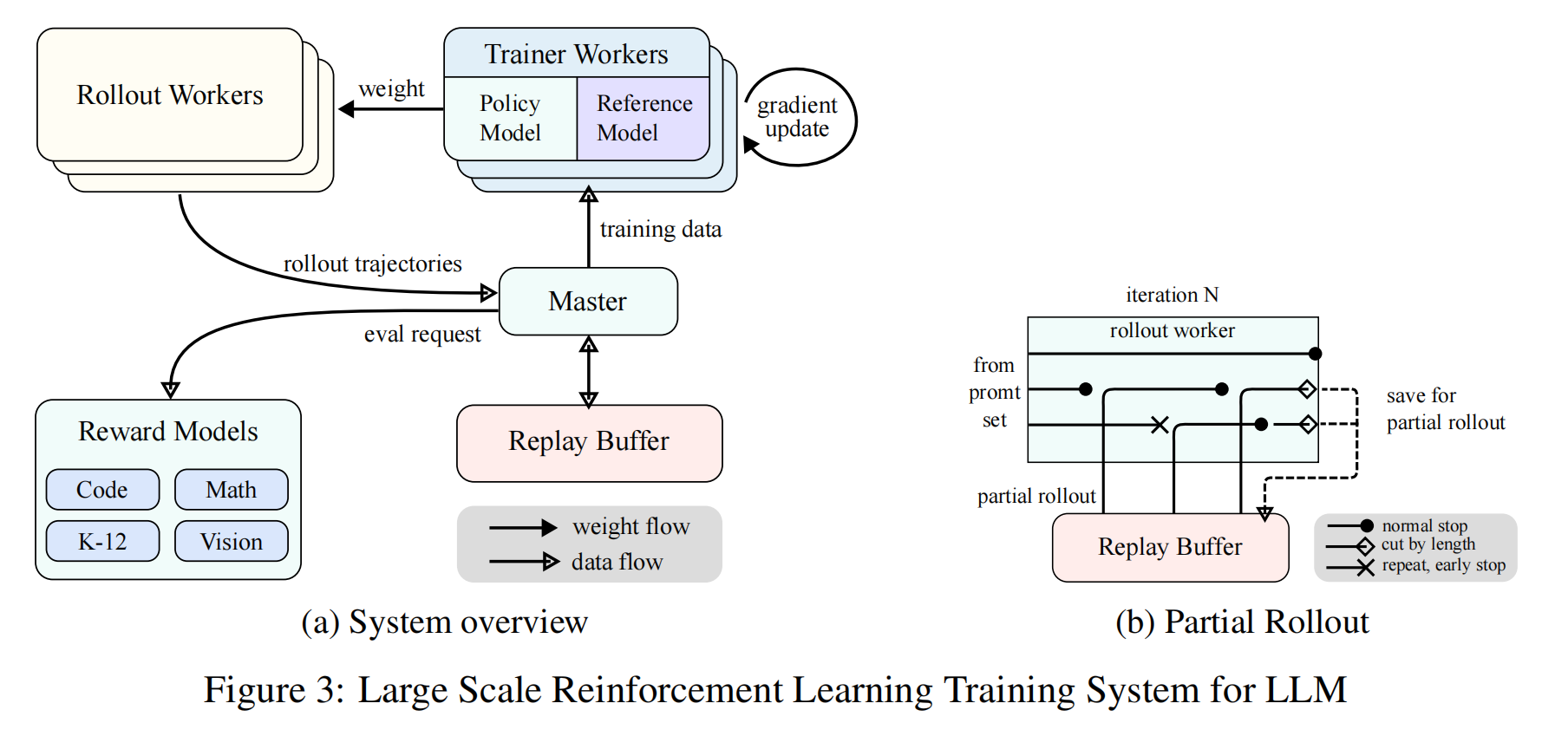
LeetCode 39. 组合总和
需要注意的是题目已经明确了数组内的元素不重复(重复的话需要执行去重操作),且元素都为正整数(如果存在0,则会出现死循环)。
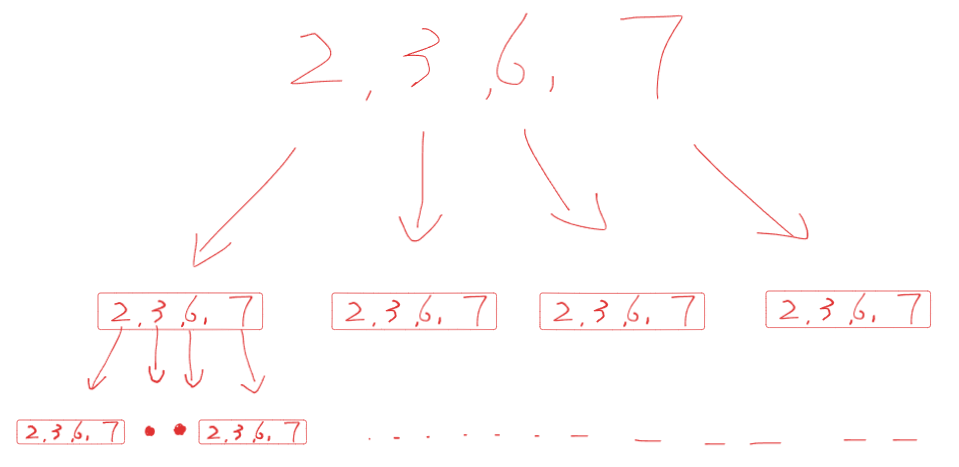
思路1:暴力解法 + 对最后结果进行去重
- 每一层的遍历都是遍历整个数组,深度遍历也是遍历该数组
Code
class Solution(object):
def combinationSum(self, candidates, target):
"""
:type candidates: List[int]
:type target: int
:rtype: List[List[int]]
"""
### candidates:即进行横向遍历,又进行深度遍历
self.result = []
self.path = []
self.sum = 0
if target < 2:
return self.result
sorted_candidates = sorted(candidates)
self.backtracking(sorted_candidates, target)
#return self.result
### 根据输出结果进行去重操作实现的
denums = set()
final_result = []
for sub_array in self.result:
sorted_sub_array = sorted(sub_array)
denums_tuple = tuple(sorted_sub_array)
if denums_tuple not in denums:
denums.add(denums_tuple)
final_result.append(sub_array)
return final_result #### 如何对输出组合进行去重? 又或者如何在回溯的过程中进行去重
def backtracking(self, candidates, target):
if self.sum == target: ### 终止条件
self.result.append(list(self.path))
return
if self.sum > target:
return
for i in range(len(candidates)): ### 横向遍历
self.path.append(candidates[i])
self.sum += candidates[i]
self.backtracking(candidates, target) ### 深度遍历
self.sum -= candidates[i]
self.path.pop() ### 回溯 思路2:对组合出现一样的问题进行优化
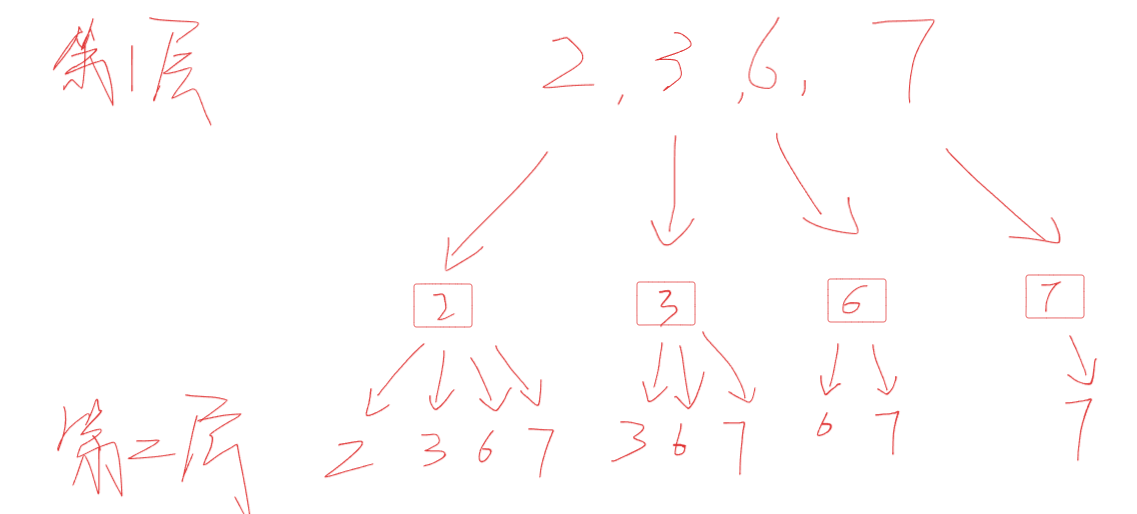
思路1为什么会出现重复的组合,因为比如说从第一层到第二层,你第一个节点是选取了2,然后后续2是不是会选取3,那这样就构成了组合[2,3],你如果你第二个节点从3开始还要去从2开始获取,那你就得到了组合[3,2],这样的话[2,3]和[3,2]就重复了,因此某个处理节点时,下一层的处理节点需要从当前元素开始到后续所有节点,而不再去判断之前的节点了,这样的话就重复判断了。
Code
class Solution(object):
def combinationSum(self, candidates, target):
"""
:type candidates: List[int]
:type target: int
:rtype: List[List[int]]
"""
### candidates:即进行横向遍历,又进行深度遍历
self.result = []
self.path = []
self.sum = 0
if target < 2:
return self.result
sorted_candidates = sorted(candidates)
self.backtracking(0, sorted_candidates, target)
return self.result
def backtracking(self, start_index, candidates, target):
if self.sum == target: ### 终止条件
self.result.append(list(self.path))
return
if self.sum > target:
return
for _ in range(start_index, len(candidates)): ### 横向遍历
self.path.append(candidates[start_index])
self.sum += candidates[start_index]
self.backtracking(start_index, candidates, target) ### 深度遍历
self.sum -= candidates[start_index]
self.path.pop() ### 回溯
start_index += 1继续优化,对思路2进行剪枝操作。思路是先对数组进行排序,将self.sum的值进行判断,如果其大于target了,后续的元素就不用进行深度遍历了。比如说一个数组为[2,3,5,7,8],目标target是6,当已遍历组合为[2,3]时,此时[2,3] 再判断把3放进来后是否等于target,但当前2+3+3=8 > target,因此是不成立的,原本的是执行完对3这个元素遍历完后,通过判断self.sum和target的值来退出,并且后续还会再去判断[2,3]跟7,8结合时的情况,但如果数组是有序,你现在就已经知道当前[2,3]跟3结合后已经大于target,那当前3之后的元素就可以不用进行遍历,因为继续遍历的话也是大于target。
Code
class Solution(object):
def combinationSum(self, candidates, target):
"""
:type candidates: List[int]
:type target: int
:rtype: List[List[int]]
"""
### candidates:即进行横向遍历,又进行深度遍历
self.result = []
self.path = []
self.sum = 0
if target < 2:
return self.result
sorted_candidates = sorted(candidates)
self.backtracking(0, sorted_candidates, target)
return self.result
def backtracking(self, start_index, candidates, target):
if self.sum == target: ### 终止条件
self.result.append(list(self.path))
return
if self.sum > target:
return
for _ in range(start_index, len(candidates)): ### 横向遍历
if self.sum + candidates[start_index] > target: ### 剪枝
break
self.path.append(candidates[start_index])
self.sum += candidates[start_index]
self.backtracking(start_index, candidates, target) ### 深度遍历
self.sum -= candidates[start_index]
self.path.pop() ### 回溯
start_index += 1LeetCode 40.组合总和II
思路:
- 每个元素只能使用一次,那递归的start_index 就从 start_index + 1 开始即可满足要求。
- 难点在于如何进行树层的去重,即横向存在相同的元素的话,后续相同元素不需要进行深度遍历,因为遍历结果都已经全部被前面第一个元素给遍历过了。
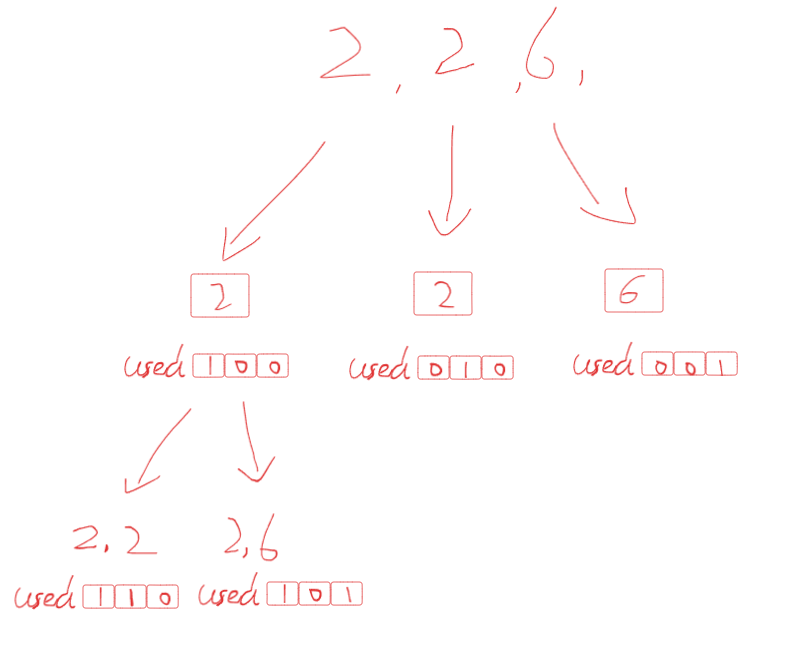
- 那树层如何进行去重呢?可以将数组的去重思想拿过来,但这样的话会存在问题,每个元素只能使用一次不代表不能使用相同的元素,这意味着我在竖向深度遍历的过程中是可以前一个元素和当前元素相同的。因此,如何进行树层的遍历,需要基于一个used数组来进行优化,这个数组与输入数组长度一致,其为布尔类型,当某个位置的元素正在被使用时,其在used中相同索引下标的值为True。
-
used[start_index-1] == False是为了明确当前不是树枝方向上的去重,当前使用的元素跟上一个元素是相等的可以是竖向遍历的情况,而如果上一个元素目前没被使用,而我当前元素的值却跟上一个元素的值一样,那就证明了是在同一层上。
Code:
class Solution(object):
def combinationSum2(self, candidates, target):
"""
:type candidates: List[int]
:type target: int
:rtype: List[List[int]]
"""
### 对数组进行排序,继续按照“组合总和”的思路进行解决.
### 并且每个元素只能使用一次
###但需要执行去重操作,如果当前处理元素跟上一个元素相同的话,则需要跳过当前元素操作,去执行下一个元素。
self.result = []
self.path = []
self.sum = 0
used = [False] * len(candidates) ### used的作用是为了进行树层的去重。在同一层上used为True是数量一定是相等的,不同层之间used为True的数量一定不等,下一层总是比上一层多一个
sorted_candidates = sorted(candidates)
self.backtracking(sorted_candidates, target, 0, used)
return self.result
def backtracking(self, candidates, target, start_index, used):
if self.sum == target: ### 终止条件
self.result.append(list(self.path))
return
if self.sum > target:
return
for _ in range(start_index, len(candidates)): ## 横向遍历
if self.sum + candidates[start_index] > target: ## 剪枝
break
if start_index > 0 and candidates[start_index] == candidates[start_index-1] and used[start_index-1] == False:
### 去重. 如何设计去重只是针对当前横向的遍历而不包含竖向的遍历。(本题的关键也是本题的难点)
### 首先,candidates[start_index] == candidates[start_index-1]只是说明了我当前使用的元素跟上一个元素是相等的,符合每个元素只使用一次。
### used[start_index-1] == False是为了明确当前不是树枝方向上的去重,当前使用的元素跟上一个元素是相等的可以是竖向遍历的情况
start_index += 1 ## 执行下个元素的操作
continue
used[start_index] = True ### 修改used数组,表示我当前used start_index位置的元素是正在使用的
self.path.append(candidates[start_index])
self.sum += candidates[start_index]
self.backtracking(candidates, target, start_index+1, used) ### 每个数字在每个组合中只能使用 一次
self.path.pop()
self.sum -= candidates[start_index]
used[start_index] = False ### 使用完元素后,进行回溯
start_index += 1