1. 前言
并行计算与分布式机器学习是一种使用多机多卡加速大规模深度神经网络训练过程,以减少训练时间的方法。在工业界的训练大语言模型实践中,通常会使用并行计算与分布式机器学习方法来减少训练大语言模型所需的钟表时间。
本文介绍PyTorch中的一种将训练数据划分为多个子集,并使用多台计算服务器上的多个GPU并行处理这些数据子集的同步式并行计算与分布式机器学习策略Distributed Data Parallel(DDP),并实现分布式预训练大语言模型函数ddp_hyper_pretrain_model。
2. Distributed Data Parallel
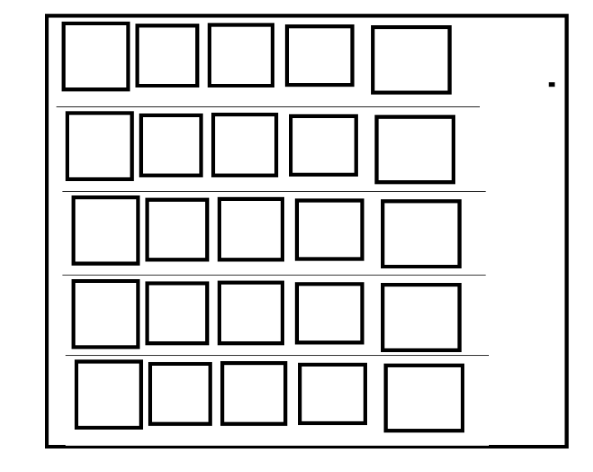
Distributed Data Parallel是一种适用于多机多卡环境的同步式并行计算与分布式机器学习策略,每轮迭代必须等待所有训练进程全部计算完成才能开启下一轮迭代训练流程。使用DDP训练深度神经网络模型,总共会启动world_size个训练进程,每个训练进程都会维护一份模型参数副本。在每轮迭代训练流程中,DDP会将一个batch的训练样本拆分成world_size个交集为空集的minibatch,每个训练进程独立处理一个minibatch的训练样本,其中world_size是多台计算服务器上的GPU总数。如下图所示,假设训练环境中总共有2块GPU,则DDP总共会创建两个训练进程,其中第一个训练进程会使用第一块GPU,第二个训练进程会使用第二块GPU。在每轮迭代训练流程中,其会将一个batch的训练样本拆分成两个交集为空集minibatch,每个训练进程分别独立地处理一个minibatch的训练样本。

在每轮迭代训练流程中,每个训练进程会同时并行地将一个minibatch的训练样本输入深度神经网络模型。前向传播可以计算得到深度神经网络模型输出的logits向量,后向传播流程首先使用损失函数计算神经网络模型的预测输出与训练样本标签之间的损失loss,再通过后向传播算法计算神经网络参数梯度。DDP在所有训练进程均计算得到神经网络参数梯度之后,会使用Ring All-Reduce算法在所有训练进程之间同步神经网络参数梯度,使每个训练进程均具有所有训练进程的神经网络参数梯度信息。最后每个训练进程会同时并行地使用梯度下降算法更新神经网络参数。

DDP不仅适用于多机多卡环境,同样适用于单机多卡环境。如果忽略不同设备之间的同步及通信时间开销,使用DDP策略利用 n n n张GPU卡训练深度神经网络模型,几乎可以将神经网络模型的训练时间缩短为原来的 1 n \frac{1}{n} n1。
3. 实现分布式预训练函数
使用PyTorch中的并行计算与分布式机器学习策略DDP预训练大语言模型GPTModel,需要使用torch.multiprocessing模块中的spawn函数,torch.distributed模块中的init_process_group与destroy_process_group函数,torch.utils.data.distributed模块中的DistributedSampler类,以及torch.nn.parallel模块中的DistributedDataParallel类,共同组成一个并行计算与分布式机器学习系统。
torch.multiprocessing模块中的spawn函数用于在每台训练服务器上启动多个训练进程。torch.distributed模块中的init_process_group函数用于初始化并行计算与分布式机器学习环境,配置所有训练进程之间的通讯和同步方式,destroy_process_group函数会在分布式训练完成后销毁各个训练进程,并释放系统资源。torch.utils.data.distributed模块中的DistributedSampler类可以将一个batch的训练样本拆分成world_size个交集为空集的minibatch,确保每个训练进程处理的各个minibatch的训练样本完全不同。
如下面的代码所示,可以定义一个初始化并行计算与分布式机器学习环境的函数ddp_setup,分别使用os.environ["MASTER_ADDR"]和os.environ["MASTER_PORT"]指定整个并行计算与分布式机器学习系统中主节点的通信IP地址和端口。使用init_process_group初始化分布式训练环境,配置多个GPU之间的通信的backend为"nccl"(NVIDIA Collective Communication Library),指定当前训练进程的序号rank以及整个并行计算与分布式机器学习系统中的训练进程总数world_size。最后使用torch.cuda.set_device函数设置当前训练进程使用的GPU设备:
import os
import math
import torch
import tiktoken
from torch.utils.data import DataLoader
import torch.multiprocessing as mp
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP # noqa
from torch.distributed import init_process_group, destroy_process_group
def ddp_setup(rank, world_size, master_addr, master_port):
os.environ["MASTER_ADDR"] = master_addr
os.environ["MASTER_PORT"] = master_port
init_process_group(backend="nccl", rank=rank, world_size=world_size)
torch.cuda.set_device(rank)
在Windows系统中需要将backend指定为"gloo"。
实现分布式预训练大语言模型函数ddp_hyper_pretrain_model,可以修改前文从零开始实现大语言模型(十四):高阶训练技巧中实现的高阶预训练函数hyper_pretrain_model,在训练开始前,首先使用ddp_setup函数初始化当前训练进程中的并行计算环境,并使用model.to(rank)将模型参数转移到当前训练进程使用的GPU。创建torch.nn.parallel模块中的DistributedDataParallel类对象,使各个训练进程均计算得到神经网络参数梯度之后,可以同步大语言模型model的参数梯度。在训练迭代流程结束后,使用destroy_process_group函数销毁当前训练进程,并释放系统资源。具体代码如下所示:
# from [从零开始实现大语言模型(十二):文本生成策略] import generate_text
# from [从零开始实现大语言模型(十三):预训练大语言模型GPTModel] import calc_loss_batch, calc_loss_loader
def ddp_hyper_pretrain_model(
rank, world_size, master_addr, master_port, learning_rate, weight_decay,
model, train_loader, num_epochs, eval_freq, eval_iter, tokenizer, start_context,
save_freq, checkpoint_dir, warmup_steps=10, initial_lr=3e-05, min_lr=1e-6, max_norm=1.0,
checkpoint=None, val_loader=None
):
ddp_setup(rank, world_size, master_addr, master_port)
model.to(rank)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
if rank == 0:
if not os.path.exists(checkpoint_dir):
os.makedirs(checkpoint_dir, exist_ok=True)
if checkpoint is not None:
model_checkpoint_path = os.path.join(checkpoint_dir, f"model_{checkpoint:06d}.pth")
optimizer_checkpoint_path = os.path.join(checkpoint_dir, f"optimizer_{checkpoint:06d}.pth")
model.load_state_dict(torch.load(model_checkpoint_path))
optimizer.load_state_dict(torch.load(optimizer_checkpoint_path))
else:
checkpoint = -1
model = DDP(model, device_ids=[rank])
train_losses, val_losses, track_tokens_seen, track_lrs = [], [], [], []
tokens_seen, global_step = 0, -1
peak_lr = optimizer.param_groups[0]["lr"]
total_training_steps = len(train_loader) * num_epochs
lr_increment = (peak_lr - initial_lr) / warmup_steps
for epoch in range(num_epochs):
model.train()
for i, (input_batch, target_batch) in enumerate(train_loader):
if global_step % eval_freq == 0:
model.train()
optimizer.zero_grad()
global_step += 1
if global_step < warmup_steps:
lr = initial_lr + global_step * lr_increment
else:
progress = (global_step - warmup_steps) / (total_training_steps - warmup_steps)
lr = min_lr + (peak_lr - min_lr) * 0.5 * (1 + math.cos(math.pi * progress))
for param_group in optimizer.param_groups:
param_group["lr"] = lr
track_lrs.append(lr)
loss = calc_loss_batch(input_batch, target_batch, model, rank)
loss.backward()
if global_step > warmup_steps:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=max_norm)
optimizer.step()
tokens_seen += input_batch.numel()
print(f"[GPU{rank}] Epoch {epoch + 1} (Batch {i:06d}): Train loss {loss.item():.3f}")
checkpoint, train_loss, val_loss = val_and_save(
model, optimizer, train_loader, val_loader, epoch, global_step, eval_freq,
eval_iter, start_context, tokenizer, save_freq, checkpoint_dir, checkpoint, rank
)
if train_loss is not None:
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
checkpoint, _, _ = val_and_save(
model, optimizer, train_loader, val_loader, epoch, global_step, 1,
eval_iter, start_context, tokenizer, 1, checkpoint_dir, checkpoint, rank
)
print(f"[GPU{rank}] Epoch {epoch + 1} finished, checkpoint: {checkpoint:06d}")
destroy_process_group()
return train_losses, val_losses, track_tokens_seen, track_lrs
def val_and_save(
model, optimizer, train_loader, val_loader, epoch, global_step, eval_freq,
eval_iter, start_context, tokenizer, save_freq, checkpoint_dir, checkpoint, device
):
train_loss, val_loss = None, None
if global_step % eval_freq == 0:
if val_loader is not None:
train_loss = calc_loss_loader(train_loader, model, device, eval_iter)
val_loss = calc_loss_loader(val_loader, model, device, eval_iter)
print(f"Epoch {epoch + 1} (Step {global_step:06d}): Train loss {train_loss:.3f}, Val loss {val_loss:.3f}")
generated_sample_text = generate_text(
model, start_context, max_new_tokens=50, tokenizer=tokenizer,
context_size=model.pos_emb.weight.shape[0], top_k=1, compact_format=True
)
print(f"Generated Sample Text: {generated_sample_text}")
print("=====================================================================")
if device == 0:
if global_step % save_freq == 0:
checkpoint += 1
model_checkpoint_path = os.path.join(checkpoint_dir, f"model_{checkpoint:06d}.pth")
optimizer_checkpoint_path = os.path.join(checkpoint_dir, f"optimizer_{checkpoint:06d}.pth")
torch.save(model.state_dict(), model_checkpoint_path)
torch.save(optimizer.state_dict(), optimizer_checkpoint_path)
return checkpoint, train_loss, val_loss
使用从零开始实现大语言模型(二):文本数据处理中构建的Dataset创建训练集train_dataset及验证集val_dataset,并通过PyTorch内置的torch.utils.data.DataLoader类创建训练集及验证集对应的DataLoader,并指定train_loader的sampler为DistributedSampler(train_dataset),使多个训练进程可以从train_loader中分别获取相应minibatch的训练样本。实例化大语言模型gpt2_small,并使用torch.multiprocessing模块中的spawn函数启动训练进程。具体代码如下所示:
# from [从零开始实现大语言模型(七):多头注意力机制] import MultiHeadAttention
# from [从零开始实现大语言模型(八):Layer Normalization] import LayerNorm
# from [从零开始实现大语言模型(九):前馈神经网络与GELU激活函数] import GELU, FeedForward
# from [从零开始实现大语言模型(十一):构建大语言模型GPTModel] import TransformerBlock, GPTModel
# from [从零开始实现大语言模型(二):文本数据处理] import LLMDataset
if __name__ == "__main__":
print("PyTorch version:", torch.__version__)
print("CUDA available:", torch.cuda.is_available())
print("Number of GPUs available:", torch.cuda.device_count())
torch.manual_seed(123)
world_size = 4
master_addr = "192.168.0.1"
master_port = "16801"
train_data_path = "train_data"
val_data_path = "val_data"
vocabulary = "gpt2"
special_token_id = 50256
context_len = 1024
stride = 1024
batch_size = 2
train_dataset = LLMDataset(train_data_path, vocabulary, special_token_id, context_len, stride)
val_dataset = LLMDataset(val_data_path, vocabulary, special_token_id, context_len, stride)
train_loader = DataLoader(
dataset=train_dataset, batch_size=batch_size, shuffle=False, drop_last=True,
pin_memory=True, sampler=DistributedSampler(train_dataset)
)
val_loader = DataLoader(dataset=val_dataset, batch_size=batch_size, shuffle=False, drop_last=False)
embedding_dim = 768
num_layers = 12
num_heads = 12
context_len = 1024
vocabulary_size = 50257
dropout = 0.1
qkv_bias = False
gpt2_small = GPTModel(
embedding_dim=embedding_dim,
num_layers=num_layers,
num_heads=num_heads,
context_len=context_len,
vocabulary_size=vocabulary_size,
dropout=dropout,
qkv_bias=qkv_bias
)
learning_rate = 0.0006
weight_decay = 0.1
num_epochs = 10
eval_freq = 5
eval_iter = 1
tokenizer = tiktoken.encoding_for_model(vocabulary)
start_context = "萧炎,斗之力,三段"
save_freq = 5
checkpoint_dir = "checkpoint"
warmup_steps = 10
initial_lr = 3e-05
min_lr = 1e-6
max_norm = 1.0
checkpoint = None
mp.spawn(
ddp_hyper_pretrain_model,
args=(
world_size, master_addr, master_port, learning_rate, weight_decay,
gpt2_small, train_loader, num_epochs, eval_freq, eval_iter, tokenizer, start_context,
save_freq, checkpoint_dir, warmup_steps, initial_lr, min_lr, max_norm,
checkpoint, val_loader
),
nprocs=torch.cuda.device_count()
)
将上述代码保存为Python脚本文件ddp_train.py,在多台训练服务器分别使用如下命令启动训练进程:
python ddp_train.py
上述并行计算与分布式机器学习策略DDP代码不能在Jupyter Notebook这样的交互式环境中运行。使用DDP策略训练深度神经网络模型,会启动多个训练进程,每个训练进程都会创建一个Python解释器实例。
如果不想使用一个计算服务器上的全部GPU,可以在启动训练进程的shell命令上通过
CUDA_VISIBLE_DEVICES参数设置可用的GPU设备。假设某台训练服务器上共有4块GPU设备,但是只能使用其中两块GPU训练深度神经网络模型,可以使用如下命令启动训练进程:CUDA_VISIBLE_DEVICES=0,2 python ddp_train.py
4. 结束语
并行计算与分布式机器学习中的计算非常简单,复杂的地方在于怎样通信。并行计算与分布式机器学习领域的通信算法可以分为两大类:同步算法及异步算法。本文原计划详细介绍并行计算与分布式机器学习领域的同步及异步通信算法原理,并解释DDP策略在所有训练进程之间同步神经网络参数梯度的Ring All-Reduce算法,但是后面发现内容实在是太多了,一篇文章根本讲不完。
《从零开始实现大语言模型》系列专栏全部完成之后,我应该会写几篇博客详细并行计算与分布式机器学习领域的通信算法原理,感兴趣的读者可以关注我的个人博客。