import org.apache.spark.{Partitioner, SparkConf, SparkContext}
object PartitionCustom {
// 分区器决定哪一个元素进入某一个分区
// 目标: 把10个分区器,偶数分在第一个分区,奇数分在第二个分区
// 自定义分区器
// 1. 创建一个类继承Partitioner
// 2. 重写两个方法
// 3. 在创建RDD的时候,partitionBy方法 指定分区器
// 创建一个类继承Partitioner
class MyPartitioner extends Partitioner{
override def numPartitions: Int = 2 // 两个分区,编号就是:0,1
// key - value
override def getPartition(key: Any): Int = {
if(key.asInstanceOf[Int] % 2 == 0){
0
}else{
1
}
}
}
def main(args: Array[String]): Unit = {
// 创建SparkContext
val conf = new SparkConf().setAppName("PartitionCustom").setMaster("local[*]")
val sc = new SparkContext(conf)
// 初始数据
val rdd = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
//val rdd = sc.parallelize(List( (1,1), (2,2))
// 自定义分区器使用的前提:数据是key-value类型
val rdd1 = rdd.map(num =>(num,num))
// 使用自定义分区器
val rdd2 = rdd1.partitionBy(new MyPartitioner)
// 在分区完成之后的基础上,只保留key
val rdd3 = rdd2.map(t => t._1)
rdd3.saveAsTextFile("output6")
}
}
spark小任务
news2026/2/17 7:26:04
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/2379455.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
新电脑软件配置二:安装python,git, pycharm
安装python
地址 https://www.python.org/downloads/ 不是很懂为什么这么多版本 安装windows64位的
这里我是凭自己感觉装的了 然后cmd输入命令没有生效,先重启下?
重启之后再次验证 环境是成功的 之前是输入的python -version 命令输入错误
安装pyc…
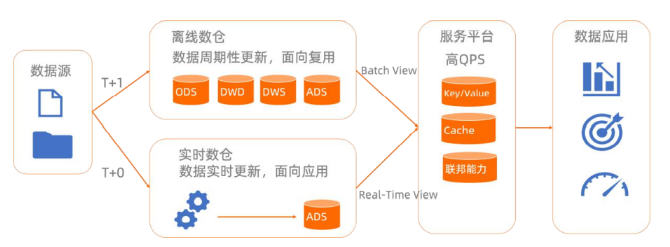
数据仓库:企业数据管理的核心引擎
一、数据仓库的由来 数据仓库(Data Warehouse, DW)概念的诞生源于企业对数据价值的深度挖掘需求。在1980年代,随着OLTP(联机事务处理)系统在企业中的普及,传统关系型数据库在处理海量数据分析时显露出明显瓶…
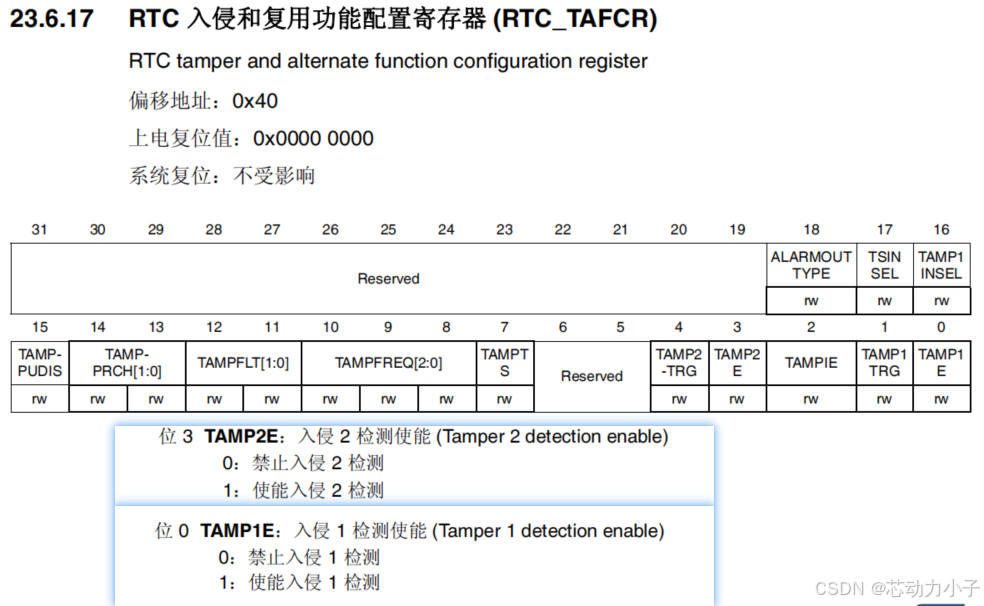
MCU开发学习记录17* - RTC学习与实践(HAL库) - 日历、闹钟、RTC备份寄存器 -STM32CubeMX
名词解释:
RTC:Real-Time Clock 统一文章结构(数字后加*): 第一部分: 阐述外设工作原理;第二部分:芯片参考手册对应外设的学习;第三部分:使用STM32CubeMX进…

C++中的四种强制转换
static_cast
原型:static_cast<type-id>(expression) type-id表示目标类型,expression表示要转换的表达式 static_cast用于非多态类型的转换(静态转换),编译器隐式执行的任何类型转换都可用static_c…
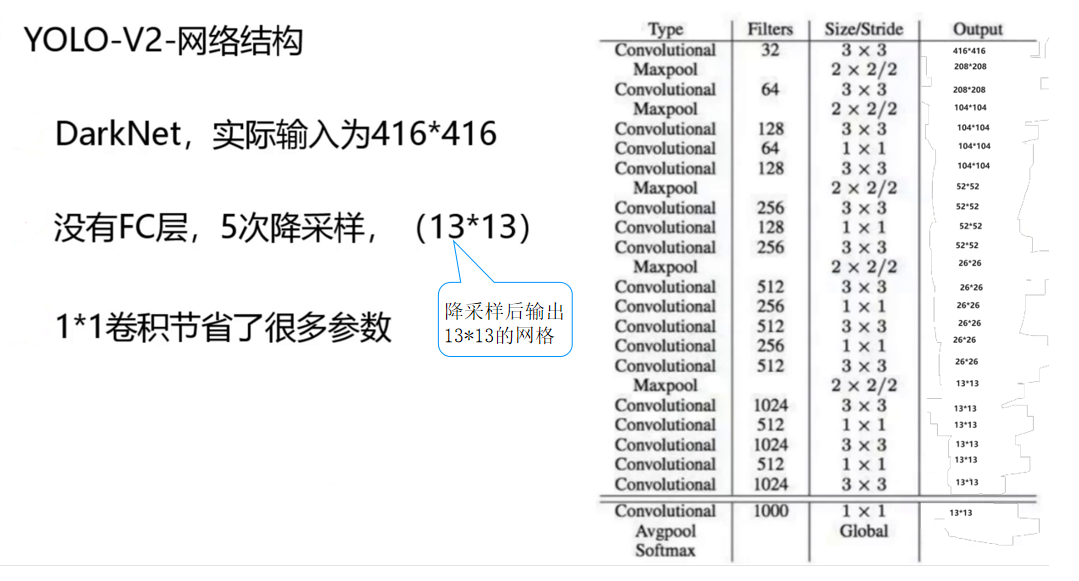
YOLOv2目标检测算法:速度与精度的平衡之道
一、YOLOv2的核心改进:从V1到V2的蜕变
YOLOv2作为YOLO系列的第二代算法,在继承V1端到端、单阶段检测的基础上,针对V1存在的小目标检测弱、定位精度低等问题进行了全方位升级,成为目标检测领域的重要里程碑。
(一&am…
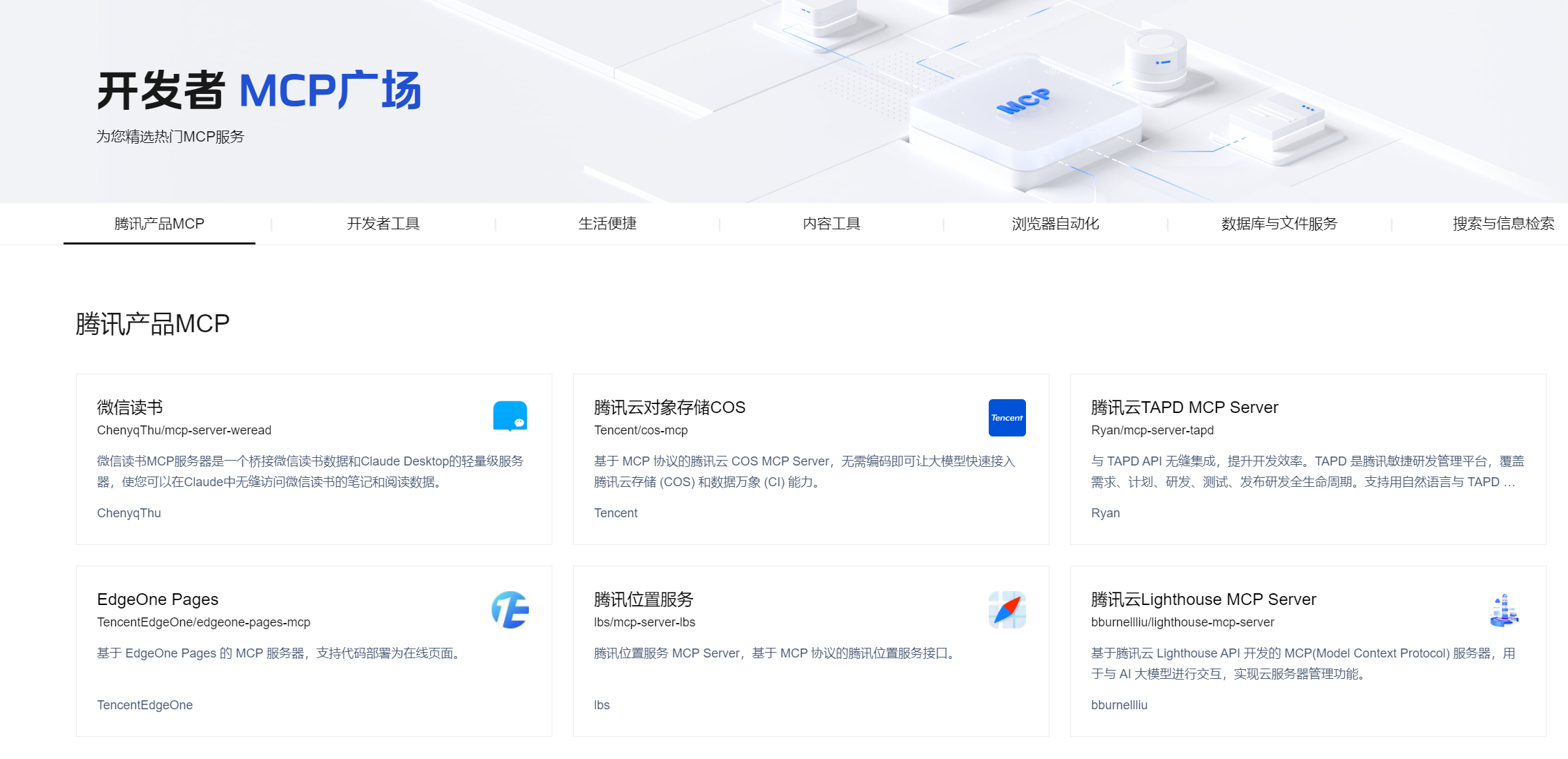
利用腾讯云MCP提升跨平台协作效率的实践与探索
一、场景痛点
在当今这个数字化快速发展的时代,跨平台协作成为了许多企业和团队面临的一个重大挑战。随着企业业务的不断拓展,团队成员往往需要利用多种工具和平台进行沟通、协作和管理。这些平台包括但不限于电子邮件、即时通讯工具、项目管理软件、文…
【Vue篇】数据秘语:从watch源码看响应式宇宙的蝴蝶效应
目录
引言
一、watch侦听器(监视器)
1.作用:
2.语法:
3.侦听器代码准备
4. 配置项 5.总结
二、翻译案例-代码实现
1.需求
2.代码实现
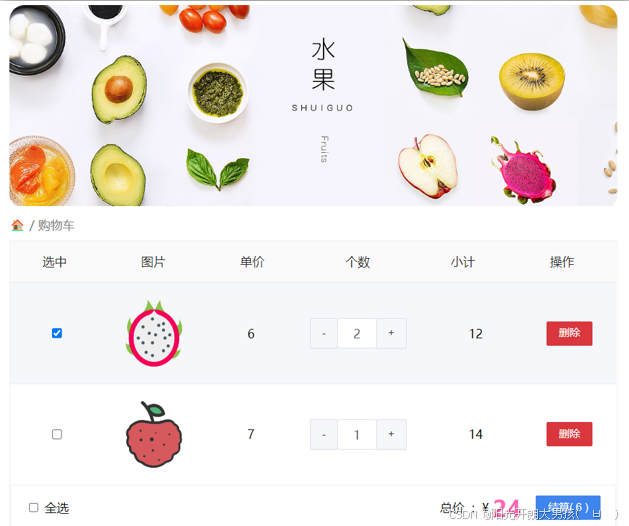
三、综合案例——购物车案例
1. 需求 2. 代码 引言 💬 欢迎讨论&#…
OGGMA 21c 微服务 (MySQL) 安装避坑指南
前言
这两天在写 100 天实战课程 的 OGG 微服务课程: 在 Oracle Linux 8.10 上安装 OGGMA 21c MySQL 遇到了一点问题,分享给大家一起避坑!
环境信息
环境信息:
主机版本主机名实例名MySQL 版本IP 地址数据库字符集Goldengate …
Linux面试题集合(4)
现有压缩文件:a.tar.gz存在于etc目录,如何解压到data目录 tar -zxvf /etc/a.tar.gz -C /data 给admin.txt创建一个软链接 ln -s admin.txt adminl 查找etc目录下以vilinux开头的文件 find /etc -name vilinux* 查找admin目录下以test开头的文件 find admin -name te…

Android Studio 安装与配置完全指南
文章目录 第一部分:Android Studio 简介与安装准备1.1 Android Studio 概述1.2 系统要求Windows 系统:macOS 系统:Linux 系统: 1.3 下载 Android Studio 第二部分:安装 Android Studio2.1 Windows 系统安装步骤2.2 mac…
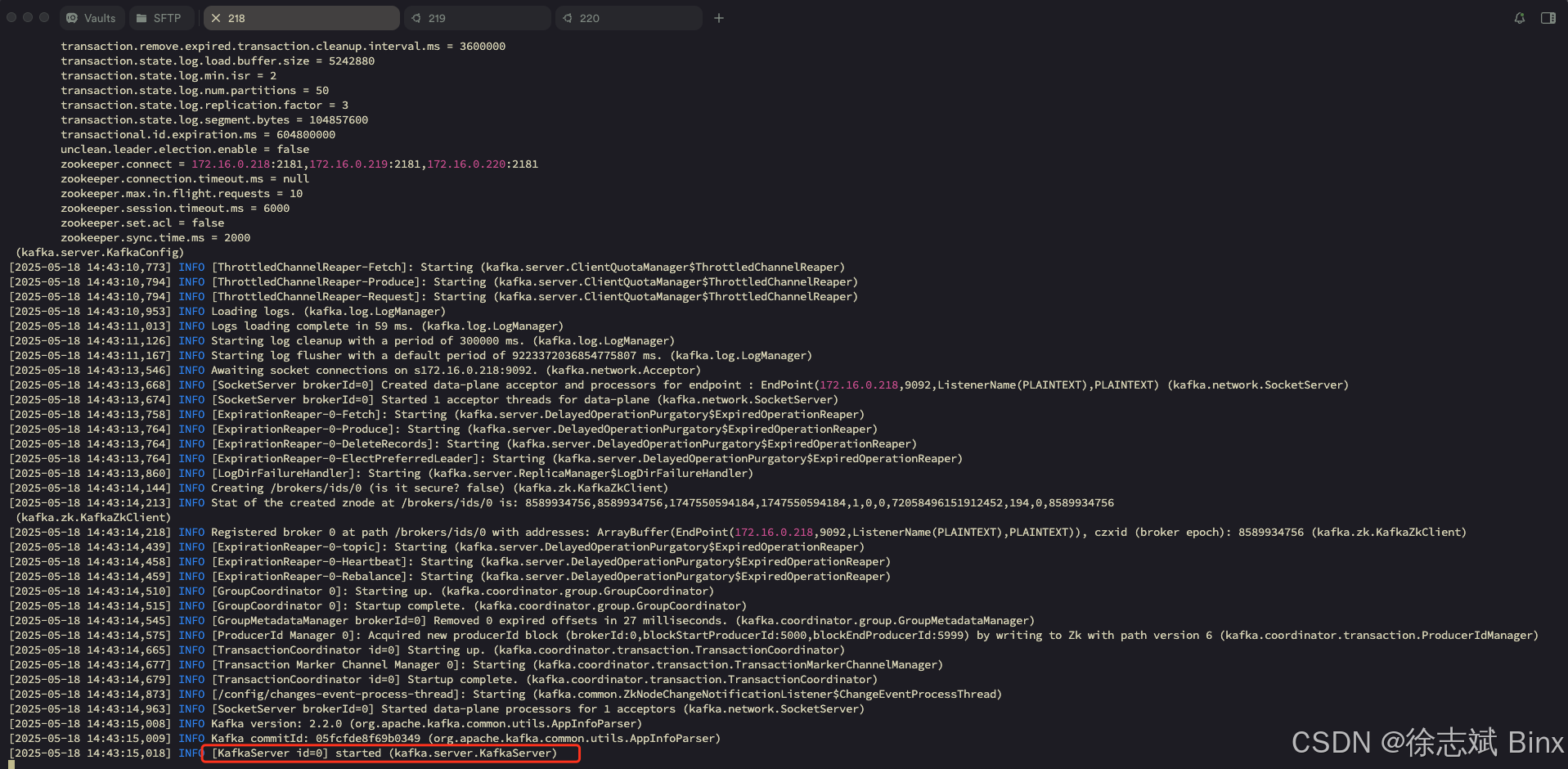
基于 Zookeeper 部署 Kafka 集群
文章目录 1、前期准备2、安装 JDK 83、搭建 Zookeeper 集群3.1、下载3.2、调整配置3.3、标记节点3.4、启动集群 4、搭建 Kafka 集群4.1、下载4.2、调整配置4.3、启动集群 1、前期准备
本次集群搭建使用:3 Zookeeper 3 Kafka,所以我在阿里云租了3台ECS用…
IDE/IoT/搭建物联网(LiteOS)集成开发环境,基于 LiteOS Studio + GCC + JLink
文章目录 概述LiteOS Studio不推荐?安装和使用手册呢?HCIP实验的源码呢? 软件和依赖安装软件下载软件安装插件安装依赖工具-方案2依赖工具-方案1 工程配置打开或新建工程板卡配置组件配置编译器配置-gcc工具链编译器配置-Makefile脚本其他配置编译完成 …
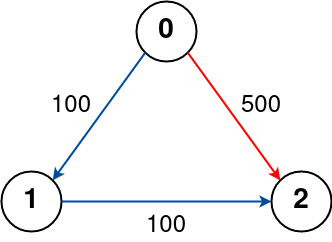
算法加训之最短路 上(dijkstra算法)
目录
P4779 【模板】单源最短路径(标准版)(洛谷)
思路 743. 网络延迟时间(力扣)
思路
1514.概率最大路径(力扣) 思路 1631.最小体力消耗路径 思路
1976. 到达目的地的方案数
…
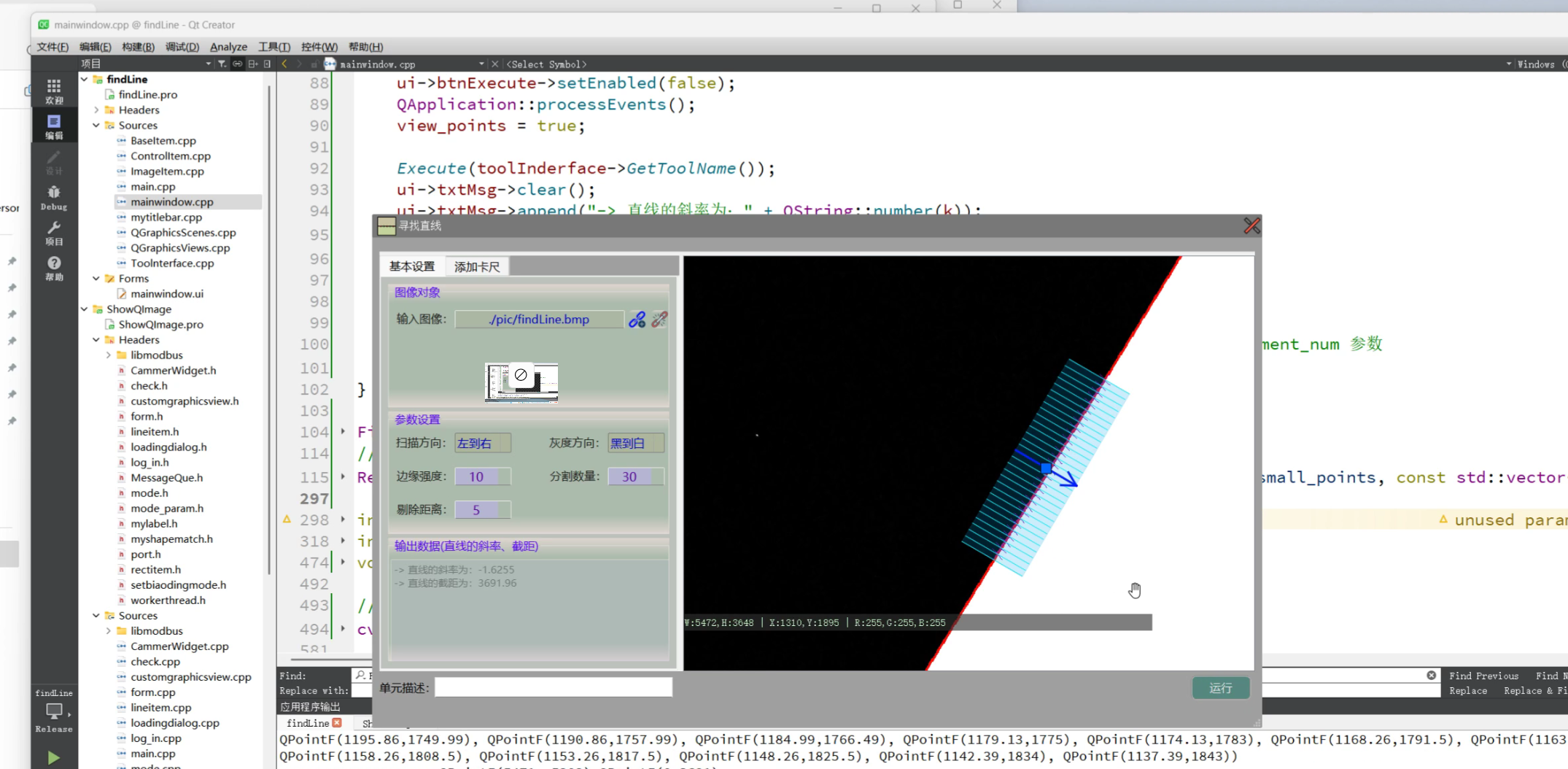
QT+Opencv 卡尺工具找直线
QTOpencv 卡尺工具找直线
自己将别的项目中,单独整理出来的。实现了一个找直线的工具类。
功能如下:1.添加图片 2.添加卡尺工具 3.鼠标可任意拖动图片和卡尺工具 4.可调整卡尺参数和直线拟合参数 5.程序中包含了接口函数,其他cpp文件传入相…

GraphPad Prism简介、安装与工作界面
《2025GraphPad Prism操作教程书籍 GraphPad Prism图表可视化与统计数据分析视频教学版GraphPad Prism科技绘图与数据分析学术图表 GraphPadPrism图表》【摘要 书评 试读】- 京东图书
GraphPad Prism统计数据分析_夏天又到了的博客-CSDN博客
1.1 GraphPad Prism简介
GraphP…

esp32课设记录(一)按键的短按、长按与双击
课程用的esp32的板子上只有一个按键,引脚几乎都被我用光了,很难再外置按键。怎么控制屏幕的gui呢?这就得充分利用按键了,比如说短按、长按与双击,实现不同的功能。 咱们先从短按入手讲起。 通过查看原理图,…
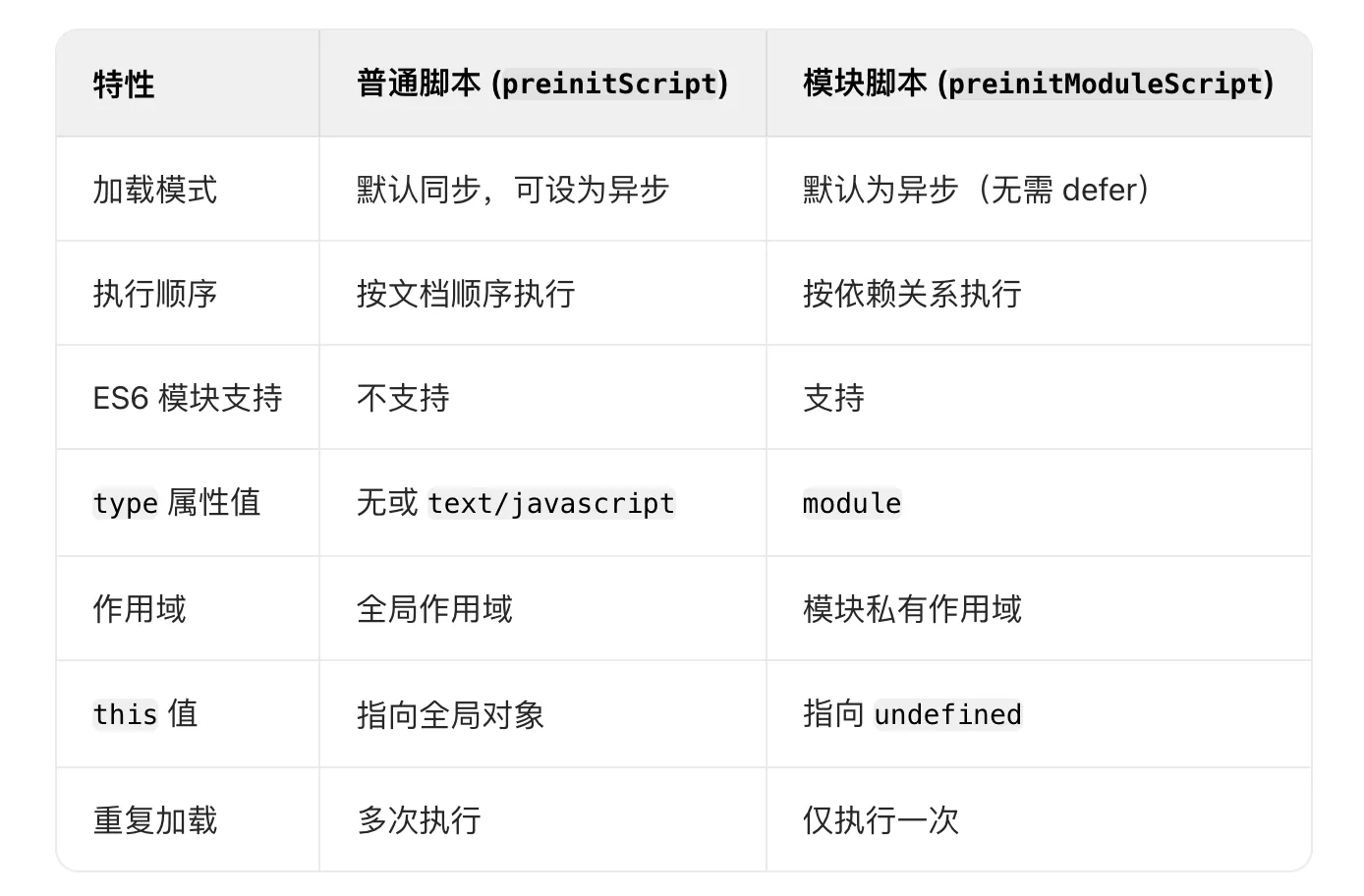
React19源码系列之 API(react-dom)
API之 preconnect
preconnect – React 中文文档
preconnect 函数向浏览器提供一个提示,告诉它应该打开到给定服务器的连接。如果浏览器选择这样做,则可以加快从该服务器加载资源的速度。
preconnect(href)
一、使用例子
import { preconnect } fro…
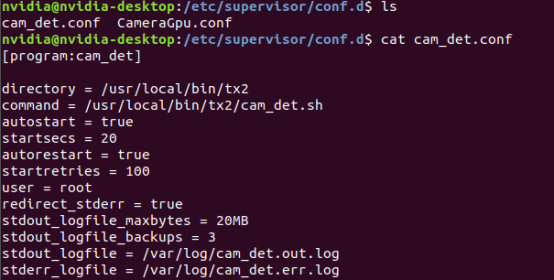
supervisorctl守护进程
supervisorctl守护进程 1 安装
# ubuntu安装: sudo apt-get install supervisor 完成后可以在/etc/supervisor文件夹,找到supervisor.conf。 如果没有的话可以用如下命令创建配置文件(注意必须存在/etc/supervisor这个文件夹)
s…

下载的旧版的jenkins,为什么没有旧版的插件
下载的旧版的jenkins,为什么没有旧版的插件,别急
我的jenkins版本: 然后我去找对应的插件
https://updates.jenkins.io/download/plugins/ 1、Maven Integration plugin: Maven 集成管理插件。
然后点击及下载成功 然后 注意&…

【ALINX 实战笔记】FPGA 大神 Adam Taylor 使用 ChipScope 调试 AMD Versal 设计
本篇文章来自 FPGA 大神、Ardiuvo & Hackster.IO 知名博主 Adam Taylor。在这里感谢 Adam Taylor 对 ALINX 产品的关注与使用。为了让文章更易阅读,我们在原文的基础上作了一些灵活的调整。原文链接已贴在文章底部,欢迎大家在评论区友好互动。 在上篇…