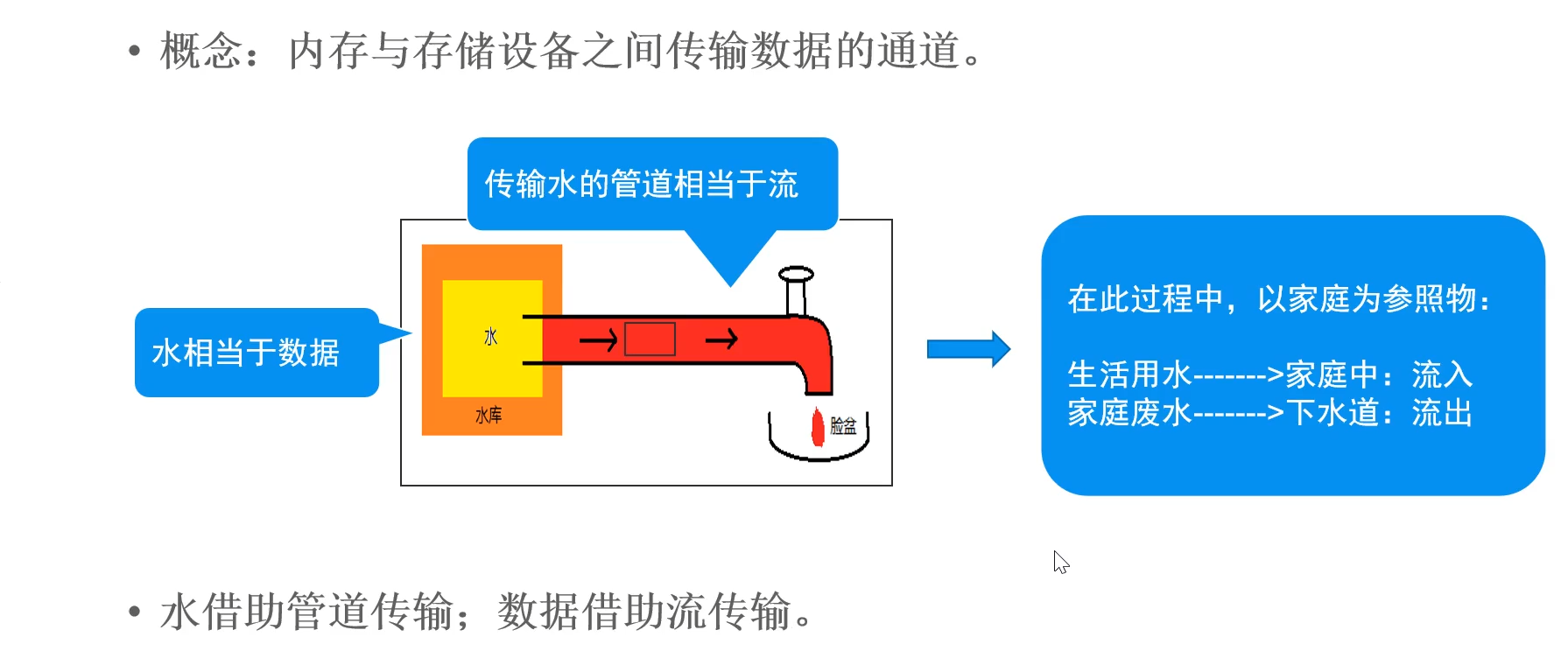
1 导入数据
(1) 文件系统
①表格形式的数据:CSV/Excel
import pandas as pd
# 读取 CSV 文件
data = pd.read_csv('sales_data.csv')
# 读取excel
data2 = pd.read_excel('file.xlsx', sheet_name='Sheet2', skiprows=5, nrows=100)②JSON
# 使用 pandas 库
import pandas as pd
data = pd.read_json('file.json')
# 使用 json 库
import json
with open('city_data.json', 'r', encoding='utf - 8') as file:
data = json.load(file)(2) 数据库
import mysql.connector
import pandas as pd
conn = mysql.connector.connect(
host='localhost',
user='user',
password='password',
database='database_name'
)
cursor = conn.cursor()
query = "SELECT * FROM table_name"
cursor.execute(query)
results = cursor.fetchall()
# 将 results转成列表
column_names = []
for desc in cursor.description:
column_names.append(desc[0])
# 将列表转成 DataFrame
data = pd.DataFrame(results, columns=column_names)
cursor.close()
conn.close()(3) 网络数据
①API 调用
import requests
# 身份验证
headers = {
# API 密钥
'Authorization': 'Bearer your_api_key'
}
response = requests.get('https://api.example.com/data', headers = headers)
if response.status_code == 200:
data = response.json()②网页爬虫
# 获取网页内容
import requests
response = requests.get('http://example.com')
if response.status_code == 200:
content = response.text
# 解析网页内容
from bs4 import BeautifulSoup
soup = BeautifulSoup(content, 'html.parser')
elements = soup.find_all('a') # 查找所有链接2 导出数据
import csv
# 创建示例数据
data = [
['姓名', '年龄', '城市'],
['张三', 25, '北京'],
['李四', 30, '上海'],
['王五', 35, '广州']
]
with open('example.csv', 'w', newline='', encoding='utf - 8') as csvfile:
writer = csv.writer(csvfile)
writer.writerows(data)