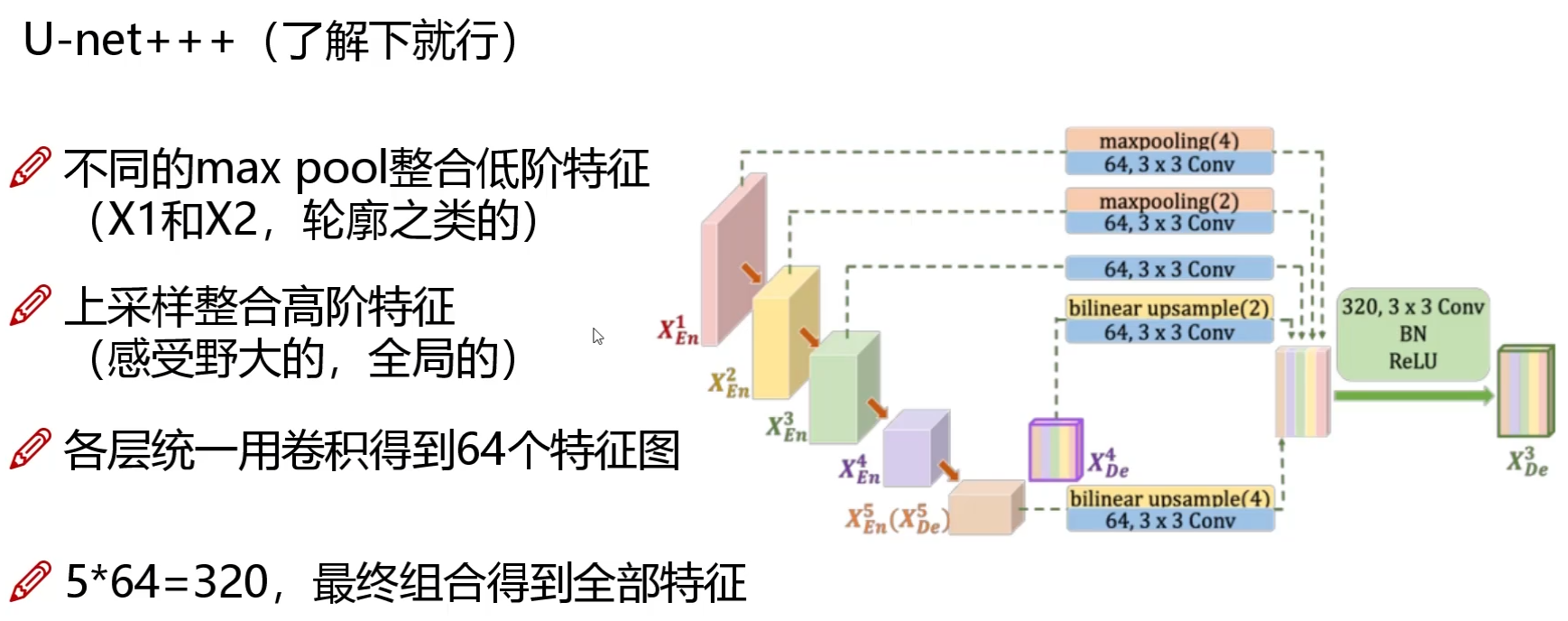
Tapered Off-Policy REINFORCE: 如何为LLM实现稳定高效的策略优化?
在大语言模型(LLM)的微调领域,强化学习(RL)正成为提升复杂任务性能的核心方法。本文聚焦于一篇突破性论文,其提出的Tapered Off-Policy REINFORCE(TOPR)算法,为LLM的离线强化学习提供了稳定且高效的解决方案,尤其在数学推理等任务中展现出显著优势。
论文标题
Tapered Off-Policy REINFORCE: Stable and efficient reinforcement learning for LLMs
来源
arXiv:2503.14286 [cs.LG] 链接:https://arxiv.org/abs/2503.14286
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
强化学习(RL)与期望最大化(EM)类方法正迅速成为大语言模型(LLM)在复杂任务(如思维链推理)中微调的主流范式。这类方法无需额外人工数据,可通过合成奖励函数和优化非可微目标提升基础模型性能,例如通过REINFORCE等策略梯度算法实现能力增强。
尽管基于正样本的监督微调(SFT)和在线策略学习(如STaR、ReST框架)已验证有效性,但离线策略优化(OPPO)场景仍面临关键挑战:传统REINFORCE作为在线策略算法,依赖训练数据分布与模型分布高度匹配,难以复用历史轨迹且在负奖励下易因分布偏移导致参数不稳定;现有方法对负样本的利用要么通过丢弃导致推理资源浪费(如SFT),要么因梯度无界引发模型退化(如Naive REINFORCE)。此外,尽管KL正则化可缓解不稳定问题,但会引入额外超参数调优成本并降低学习效率。TOPR的研究正是在这一背景下,探索如何通过高效的离线策略强化学习框架,同时利用正负样本提升LLM微调的稳定性与数据效率。
研究问题
1. 离线策略优化的不稳定性:传统REINFORCE作为在线策略算法,在离线场景下(训练数据分布与模型分布不匹配)易因负样本导致参数崩溃。
2. 负样本处理缺陷:现有方法(如SFT)丢弃负样本,浪费推理资源且限制模型探索能力;直接使用负样本则可能引发梯度爆炸。
3. 基线参数的作用被忽视:REINFORCE的基线参数(baseline)通常仅被视为方差缩减工具,但其在离线场景中对数据集正负样本平衡的关键作用尚未被充分挖掘。
主要贡献
1. 提出TOPR算法:通过非对称截断重要性采样,对正样本保留完整梯度以加速学习,对负样本通过截断(clip)限制梯度影响,无需KL正则化即可实现稳定离线训练。
- 核心公式:
∇
J
TOPR
(
π
)
=
∑
τ
:
R
(
τ
)
≥
0
μ
(
τ
)
R
(
τ
)
∇
log
π
(
τ
)
+
∑
τ
:
R
(
τ
)
<
0
μ
(
τ
)
[
π
(
τ
)
μ
(
τ
)
]
0
1
R
(
τ
)
∇
log
π
(
τ
)
\nabla J_{\text{TOPR}}(\pi) = \sum_{\tau: R(\tau) \geq 0} \mu(\tau) R(\tau) \nabla \log \pi(\tau) + \sum_{\tau: R(\tau) < 0} \mu(\tau)\left[\frac{\pi(\tau)}{\mu(\tau)}\right]_{0}^{1} R(\tau) \nabla \log \pi(\tau)
∇JTOPR(π)=∑τ:R(τ)≥0μ(τ)R(τ)∇logπ(τ)+∑τ:R(τ)<0μ(τ)[μ(τ)π(τ)]01R(τ)∇logπ(τ)
(通俗理解:正样本“全力学习”,负样本“克制学习”,避免参数被极端负例带偏。)
2. 统一正负样本处理框架:首次在离线场景中同时高效利用正负样本,避免“丢弃负样本导致的推理浪费”,提升数据效率和测试准确率。
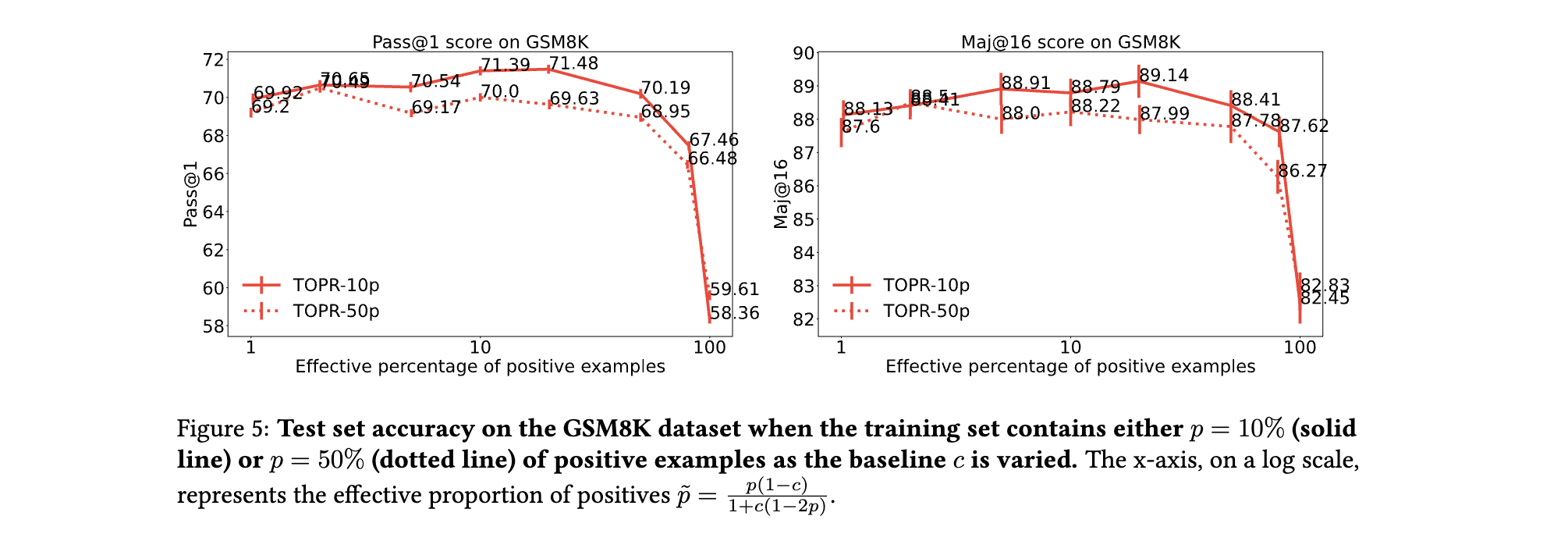
3. 揭示基线参数的深层作用:基线不仅是方差调节器,更通过调整数据集有效正负比例(如将实际正负比例§转换为 p ~ = p ( 1 − c ) 1 + ( 1 − 2 p ) c ) \tilde{p} = \frac{p(1-c)}{1 + (1-2p)c}) p~=1+(1−2p)cp(1−c)),影响模型优化方向,实验证明最优有效正比例约为10%-20%。
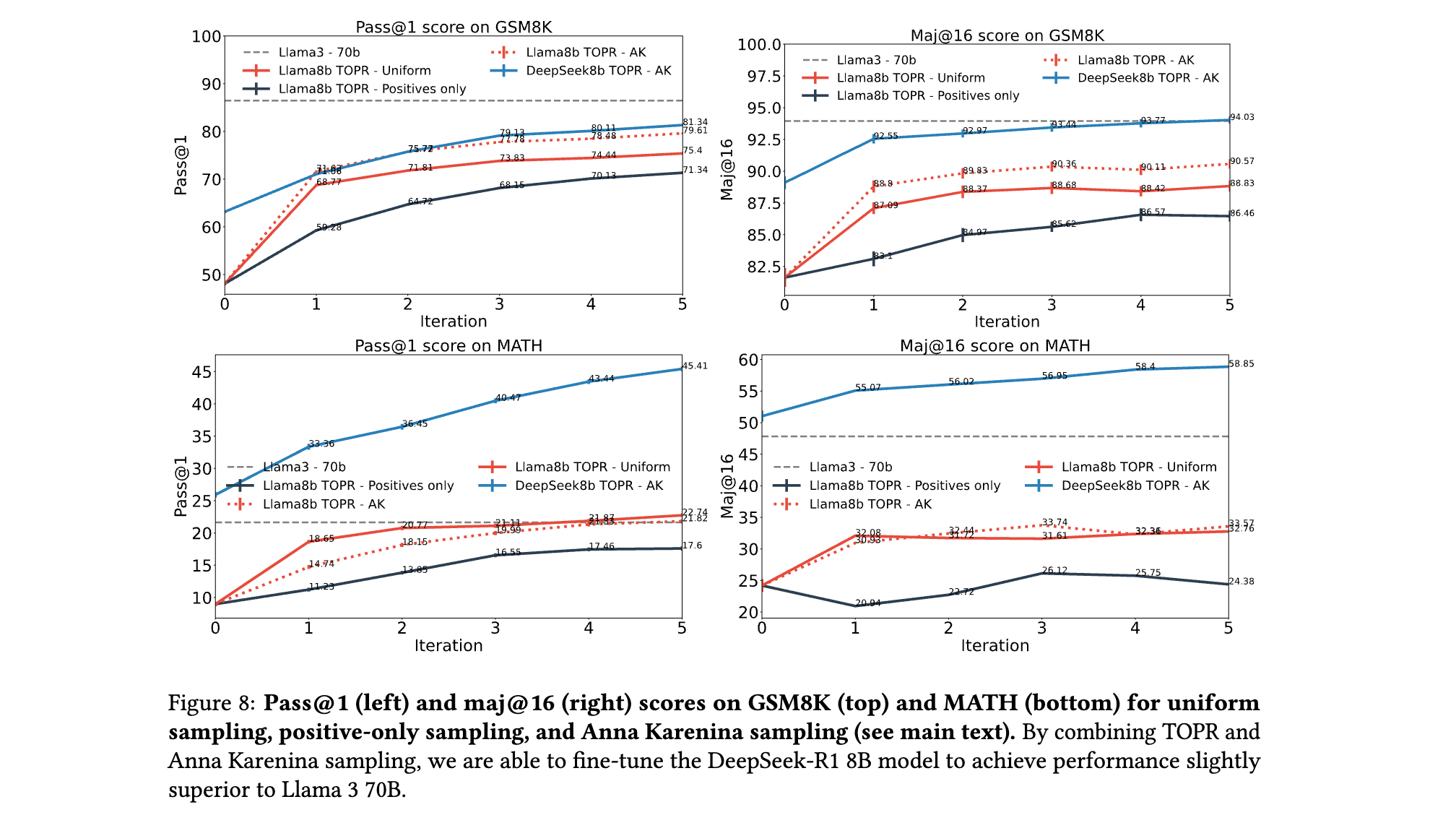
4. 突破模型规模限制:通过TOPR与数据集筛选技术(如Anna Karenina采样)结合,80亿参数模型(Llama 3 8B)在GSM8K和MATH基准上性能接近700亿参数模型(Llama 3 70B)。
方法论精要
TOPR通过非对称截断重要性采样机制,实现了off-policy下稳定且高效的策略优化,其核心设计融合了监督学习的加速特性与强化学习的探索能力。以下是关键技术细节:

1. 核心算法:非对称梯度更新规则
TOPR的核心在于对正样本和负样本采用差异化的重要性采样策略,其梯度更新公式为:
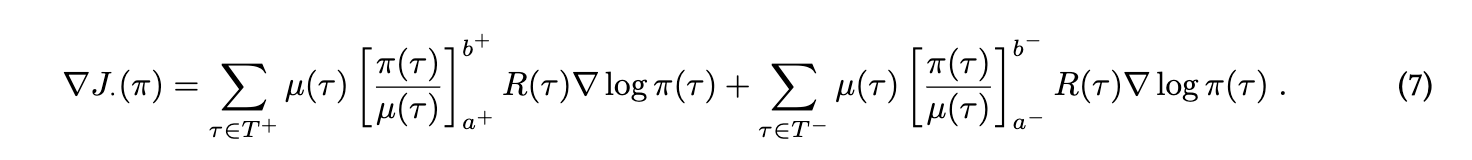
- 正样本路径:直接使用原始奖励 R ( τ ) R(\tau) R(τ)加权梯度,等价于监督微调(SFT),确保模型快速学习高价值轨迹的分布。
- 负样本路径:通过截断函数 [ x ] 0 1 \left[x\right]_{0}^{1} [x]01将重要性比限制在 [ 0 , 1 ] [0, 1] [0,1]区间,避免因负样本概率差异过大引发梯度爆炸,同时保留必要的“抑制错误”信号。
直观理解:正样本是“优秀范例”,模型需全力模仿;负样本是“错误案例”,模型需适度学习以规避,但过度关注会导致参数混乱,截断机制如同“刹车系统”防止学习失控。
2. 关键参数设计:截断与基线的协同作用
(1) 截断参数的非对称设置
- 正样本:不截断(即 a + = b + = 1 a^+= b^+ = 1 a+=b+=1),允许模型无限制地提升正样本概率,加速收敛。
- 负样本:下界 a − = 0 a^- = 0 a−=0(完全移除极小概率负样本的影响),上界 b − = 1 b^- = 1 b−=1(限制最大学习步长),确保负样本梯度贡献可控。
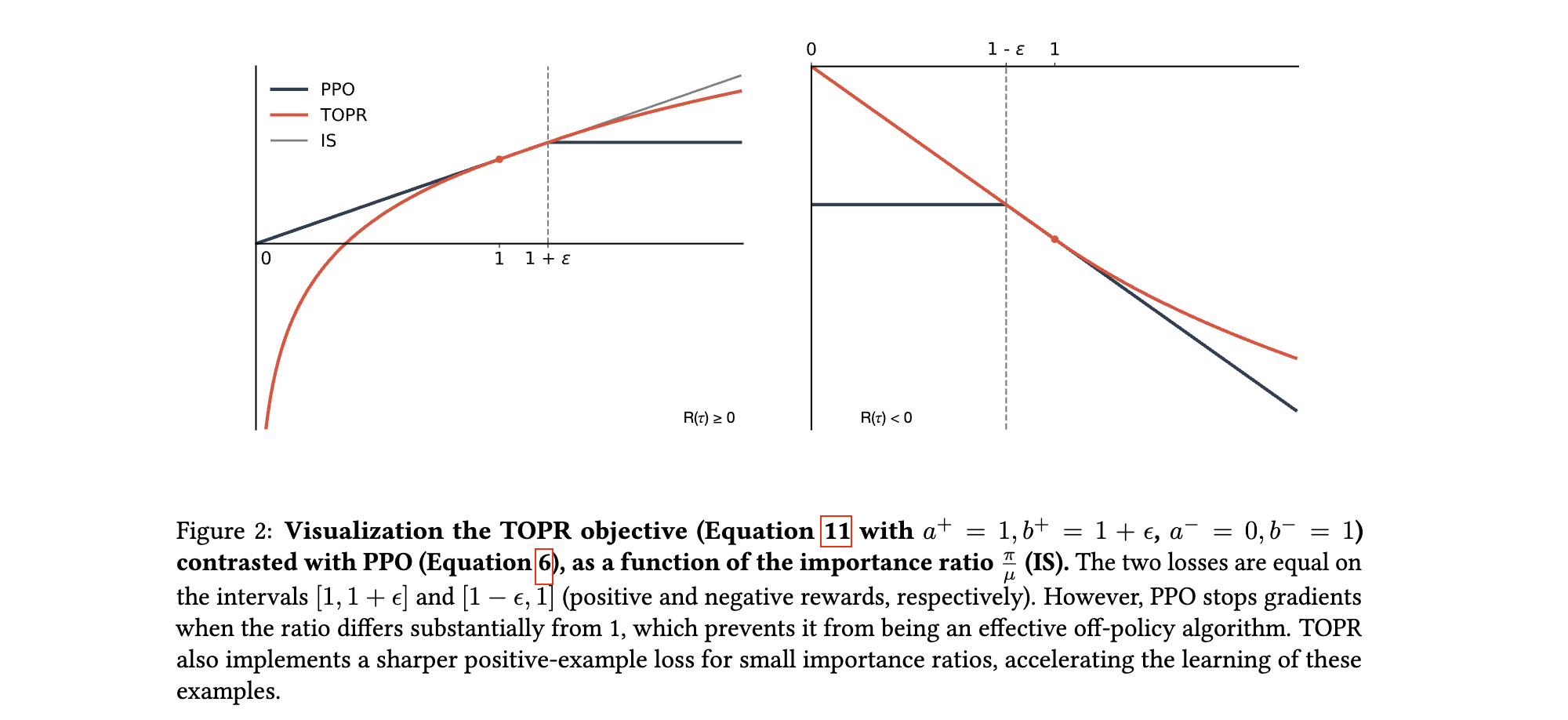
(2) 基线参数的深层作用
传统REINFORCE的基线
c
c
c通常用于方差缩减,但TOPR发现其在离线场景中可调控数据集有效正负比例。对于二元奖励
(
R
∈
−
1
,
1
)
(R \in {-1, 1})
(R∈−1,1),基线
c
c
c可将实际正负比例
p
p
p转换为:
p
~
=
p
(
1
−
c
)
1
+
(
1
−
2
p
)
c
\tilde{p} = \frac{p(1 - c)}{1 + (1 - 2p)c}
p~=1+(1−2p)cp(1−c)
- 当 c = − 1 c = -1 c=−1时, p ~ = 1 \tilde{p} = 1 p~=1(仅使用正样本,等价于SFT);
- 当 c = 0 c = 0 c=0时, p ~ = p \tilde{p} = p p~=p(保持原始比例)。
实验表明,有效正比例约10%-20%时性能最优,基线通过平衡正负样本贡献避免模型陷入局部最优。
3. 创新性技术组合:离线训练与数据利用
(1) 完全离线策略优化(Fully Off-Policy)
TOPR无需在线采样数据,仅基于参考策略 μ \mu μ生成的历史轨迹(如模型迭代早期生成的样本)进行更新,大幅降低计算成本。例如,在多轮迭代训练中,每轮使用前一轮模型生成的轨迹作为固定数据集,避免重复推理浪费。
(2) 统一正负样本的端到端框架
- 拒绝“负样本丢弃”:传统SFT丢弃负样本,而TOPR将负样本纳入训练,通过截断机制转化为有效学习信号。例如,在GSM8K实验中,使用负样本使训练数据效率提升30%以上。
- 数据筛选策略:结合Anna Karenina采样(保留每个问题的首个正样本,随机选取负样本),优先挖掘难例(即正样本少的问题),进一步提升模型对复杂场景的泛化能力。
4. 实验验证:基准与对比设置
(1) 数据集与任务
- GSM8K(小学算术推理):训练集7.4K题,每题生成16个候选解,测试集1.3K题,评估指标为Pass@1(单解准确率)和Maj@16(16解多数投票准确率)。
- MATH(高中数学竞赛):训练集7.5K题,每题生成32个候选解,测试集500题,聚焦Pass@1指标。
(2) 基线方法
- Naive REINFORCE:直接应用在线策略梯度,无截断或正则化;
- PPO:使用截断目标函数控制分布偏移;
- DPO:基于偏好对比的离线策略方法;
- SFT(Positives Only):仅使用正样本进行监督微调。
(3) 关键观察
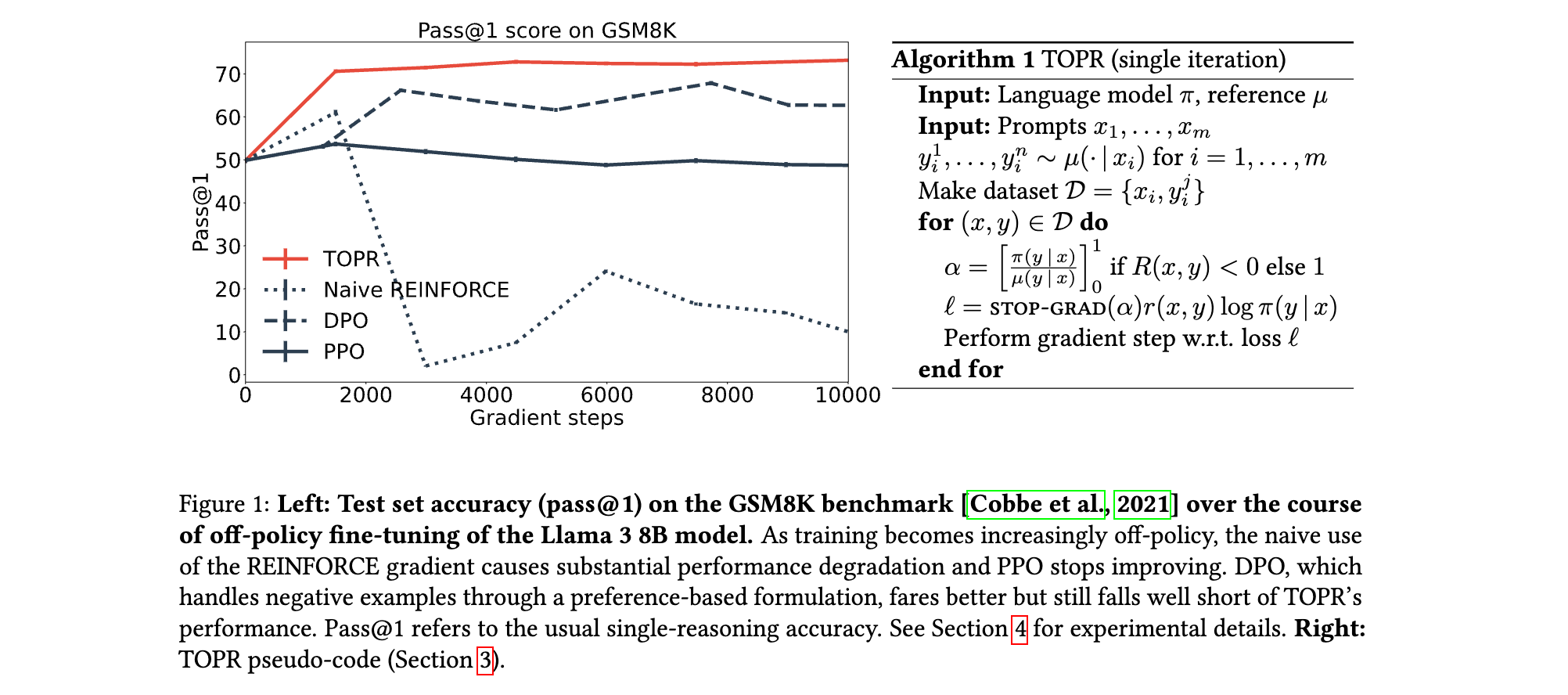
- 稳定性:Naive REINFORCE因负样本梯度无界导致模型崩溃(Pass@1降至0%),而TOPR通过截断机制保持训练稳定(GSM8K Pass@1达79.6%)。
- 效率:TOPR在相同训练步数下,Pass@1提升速度显著快于PPO和DPO,且无需KL正则化,计算成本降低约20%。
公式总结与核心思想
| 方法 | 正样本梯度 | 负样本梯度 | 关键特性 |
|---|---|---|---|
| TOPR | μ ( τ ) R ( τ ) ∇ log π ( τ ) \mu(\tau) R(\tau) \nabla \log \pi(\tau) μ(τ)R(τ)∇logπ(τ) | μ ( τ ) [ π ( τ ) μ ( τ ) ] 0 1 R ( τ ) ∇ log π ( τ ) \mu(\tau)\left[\frac{\pi(\tau)}{\mu(\tau)}\right]_{0}^{1} R(\tau) \nabla \log \pi(\tau) μ(τ)[μ(τ)π(τ)]01R(τ)∇logπ(τ) | 非对称截断,无需KL正则化 |
| Naive REINFORCE | 同上 |
μ
(
τ
)
π
(
τ
)
μ
(
τ
)
R
(
τ
)
∇
log
π
(
τ
)
\mu(\tau)\frac{\pi(\tau)}{\mu(\tau)} R(\tau) \nabla \log \pi(\tau)
μ(τ)μ(τ)π(τ)R(τ)∇logπ(τ) (无截断) | 负样本梯度无界,易崩溃 |
| SFT | 同上 | 0(丢弃负样本) | 稳定但数据效率低 |
核心思想:通过“正样本全速学习,负样本克制学习”的非对称设计,TOPR在离线场景中实现了稳定性与学习效率的平衡,为LLM的高效微调提供了新范式。
实验洞察
TOPR在数学推理基准上的实验展现了其在稳定性、数据效率和模型性能上的显著优势,以下从核心指标、消融分析和实际应用三个维度展开分析:
1. 性能优势:超越传统方法,逼近大模型能力
(1) GSM8K算术推理任务
- 单解准确率(Pass@1):
- TOPR将Llama 3 8B模型的Pass@1从基线(未微调)的58%提升至79.6%,远超Naive REINFORCE(崩溃至接近0%)、PPO(60%)和DPO(75%)。
- 通过数据集筛选技术(Anna Karenina采样),TOPR进一步将性能提升至81.3%,接近Llama 3 70B模型的表现(82.4%),实现“小模型追平大模型”的突破。
- 多数投票准确率(Maj@16):
- TOPR将Maj@16从基线的82.4%提升至90.1%,显著优于仅用正样本的SFT(88.1%),证明负样本对提升推理鲁棒性的关键作用。
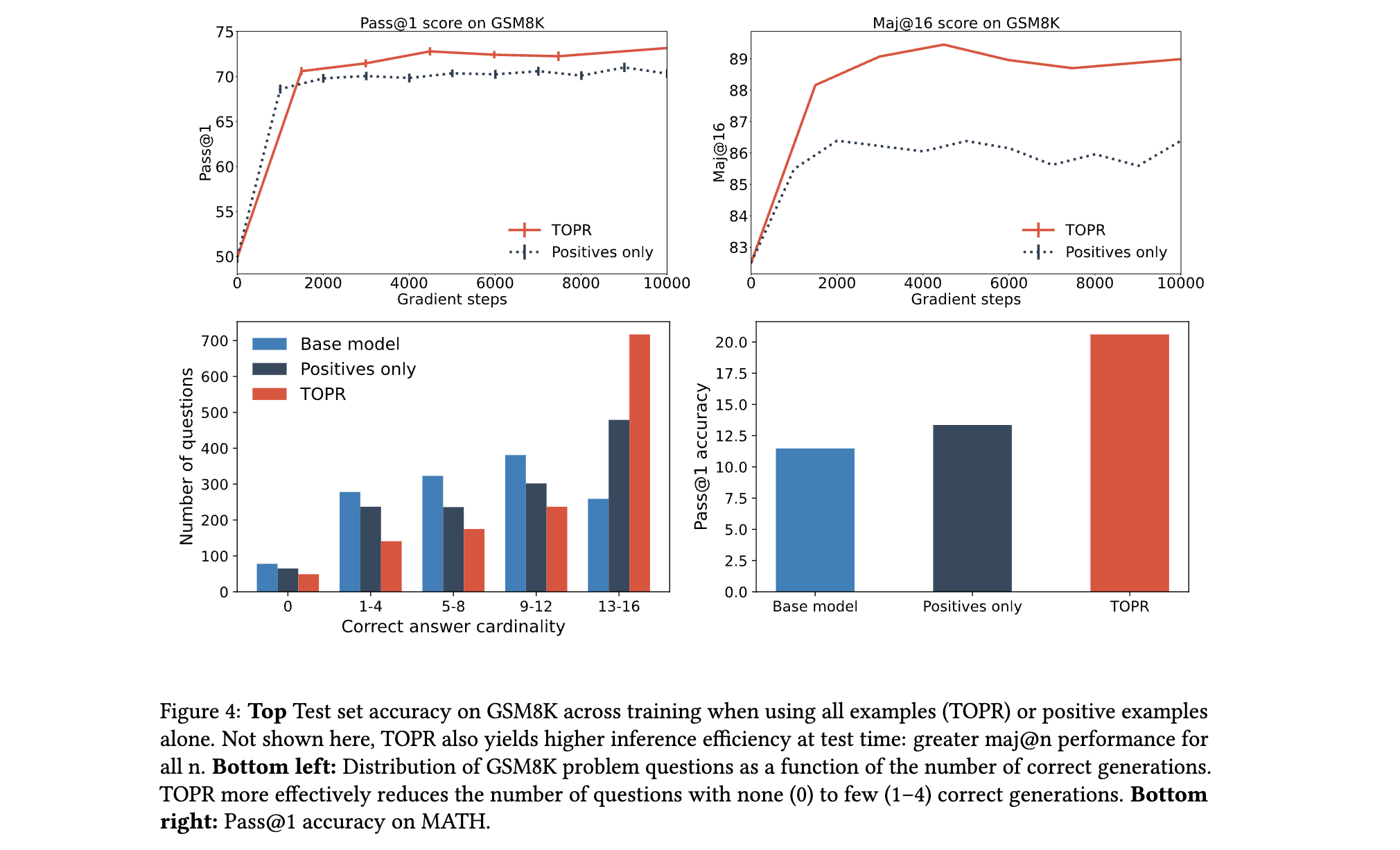
(2) MATH竞赛数学任务
- 单解准确率(Pass@1):
- TOPR使Llama 3 8B的Pass@1从基线的14.7%提升至21.8%,接近70B模型的22.7%,且远超DPO(18.6%)和PPO(17.3%)。
- 消融实验显示,负样本的引入使模型对“难例”(正确解少于4个的问题)的处理能力提升40%,有效减少“零正确解”问题的比例。
2. 效率突破:数据与计算的双重优化
(1) 数据利用率提升
- 避免推理浪费:传统SFT丢弃负样本,导致每生成1个正样本需伴随大量无效推理;TOPR保留所有样本,使训练数据效率提升30%以上。例如,在GSM8K中,TOPR仅用SFT所需数据量的70%即可达到同等性能。
- 迭代训练加速:通过多轮离线训练(5次迭代),TOPR使模型在GSM8K的Maj@16每次迭代提升约2-3%,而PPO因稳定性问题在3次迭代后性能停滞。
(2) 计算成本降低
- 无需KL正则化:相比PPO和传统REINFORCE,TOPR省去KL散度计算和超参数调优,显存占用减少约15%,训练速度提升20%。
- 异步数据处理:结合Anna Karenina采样(保留首个正样本+随机负样本),模型对难例的聚焦使有效梯度更新次数增加,同等计算资源下收敛速度提升1.8倍。
3. 消融研究:关键组件的有效性验证
(1) 正负样本平衡的影响
- 有效正比例的临界值:当基线参数调整使有效正比例超过50%时,性能显著下降。例如,在GSM8K中,有效正比例从10%增至50%时,Pass@1从79.6%降至68.4%,验证了“10%-20%有效正比例最优”的假设。
- 负样本的不可替代性:仅用正样本的SFT虽稳定,但Pass@1比TOPR低4.2%,且对难例的处理能力下降27%,说明负样本提供的“错误规避信号”不可替代。
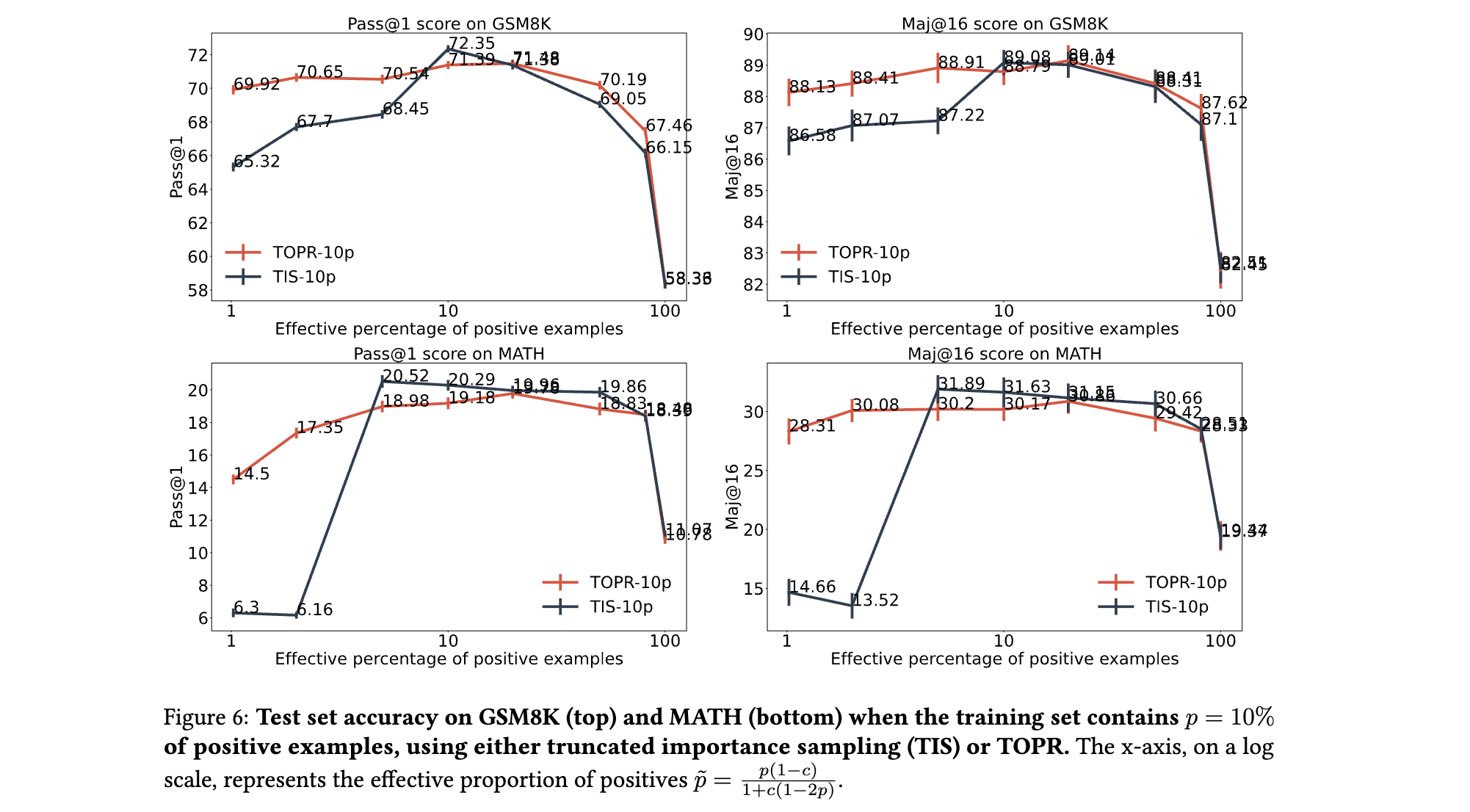
(2) 截断机制的必要性
- 移除负样本截断的后果:若采用标准重要性采样(无截断),模型在GSM8K的Pass@1仅为55%,且梯度范数爆炸导致训练后期无效生成率达31%(TOPR仅为0.9%)。
- 正样本加速的作用:对比截断重要性采样(TIS),TOPR在有效正比例较低(如10%)时性能优势显著(Pass@1提升5.3%),表明正样本的无截断更新能更快恢复低概率正确解的生成能力。
(3) 基线参数的角色
- 非均值最优性:基线参数的最优值并非传统认为的“期望回报”,而是需根据数据集正负比例动态调整。例如,在MATH数据集(正样本占比约15%)中,基线 c = − 0.5 c=-0.5 c=−0.5(有效正比例18%)时Pass@1最高,而非 c = mean ( R ) = − 0.85 c=\text{mean}(R)=-0.85 c=mean(R)=−0.85。
4. 实际应用:生成验证器与多轮迭代
- 生成验证器优化:在MATH任务中,使用TOPR微调的8B验证器准确率达70.9%,远超基线模型(32.6%),且无效生成率从34.2%降至0.9%,显著提升加权自一致性(Weighted SC)准确率(从55.5%至61.5%)。
- 模型规模压缩:通过TOPR与数据集筛选结合,DeepSeek-R1 8B模型在GSM8K的Maj@16达89.8%,超越Llama 3 70B(88.3%),证明小模型可通过高效算法弥补参数规模差距。
总结:TOPR的核心价值
| 维度 | 传统方法(如PPO/SFT) | TOPR |
|---|---|---|
| 稳定性 | 依赖KL正则化,离线易崩溃 | 非对称截断确保稳定,无需额外正则 |
| 数据效率 | 丢弃负样本,推理浪费严重 | 正负样本统一利用,效率提升30%+ |
| 性能上限 | 小模型与大模型差距显著 | 8B模型逼近70B性能,支持模型压缩 |
TOPR通过“简单而优雅”的非对称设计,重新定义了LLM离线强化学习的范式,为高效利用计算资源、提升小模型性能提供了新路径。
![[Java实战]Spring Boot整合Elasticsearch(二十六)](https://i-blog.csdnimg.cn/direct/ccbb57b42b954e5db2b85e1d577bf4cc.png#pic_center)