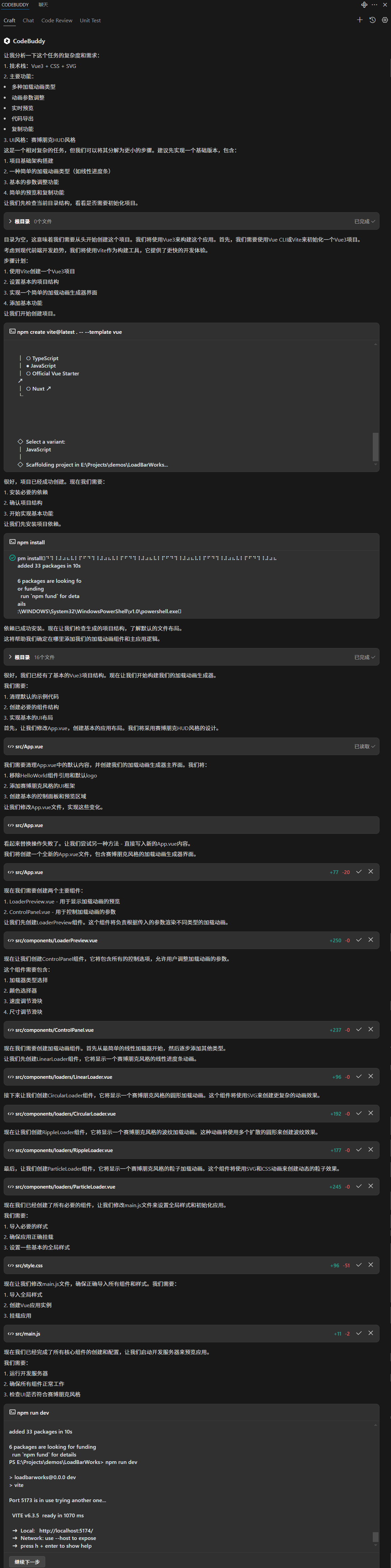
目录
Abstract
摘要
DSU-Net
模型框架
编码器
轻量级适配器模块
特征融合与协作
解码器
模型优势
实验
代码
总结
Abstract
DSU-Net is an improved U-Net model based on DINOv2 and SAM2. It addresses the limitations of existing image segmentation models in specific downstream tasks, such as camouflaged object segmentation and salient object segmentation, through multi-scale cross-model feature collaboration and lightweight adapter modules. By leveraging the high-dimensional semantic features from DINOv2 to enhance the multi-scale feature fusion of SAM2, and utilizing attention mechanisms for adaptive aggregation of multi-granularity features, DSU-Net significantly improves segmentation accuracy. Experimental results demonstrate that DSU-Net outperforms existing state-of-the-art methods on multiple benchmark datasets. Moreover, by freezing pre-trained parameters, it reduces training costs, showcasing high efficiency and broad applicability.
摘要
DSU-Net是一种基于DINOv2和SAM2改进的U-Net模型,通过多尺度跨模型特征协作和轻量级适配器模块,解决了现有图像分割模型在特定下游任务中表现不足的问题,如:伪装目标分割和显著目标分割。它利用DINOv2的高维语义特征增强SAM2的多尺度特征融合,同时通过注意力机制实现多粒度特征的自适应聚合,显著提升了分割精度。实验结果表明,DSU-Net在多个基准数据集上超越了现有最先进方法,并且通过冻结预训练参数降低了训练成本,展现出高效性和广泛的适用性。
DSU-Net
DSU-Net是一种改进型的U-Net模型,旨在通过结合DINOv2和SAM2的优势,实现多尺度特征的跨模型协作增强。该模型针对大规模预训练基础模型在特定领域中表现不足的问题,提出了一种高效的解决方案。
论文地址:https://arxiv.org/abs/2503.21187
模型框架
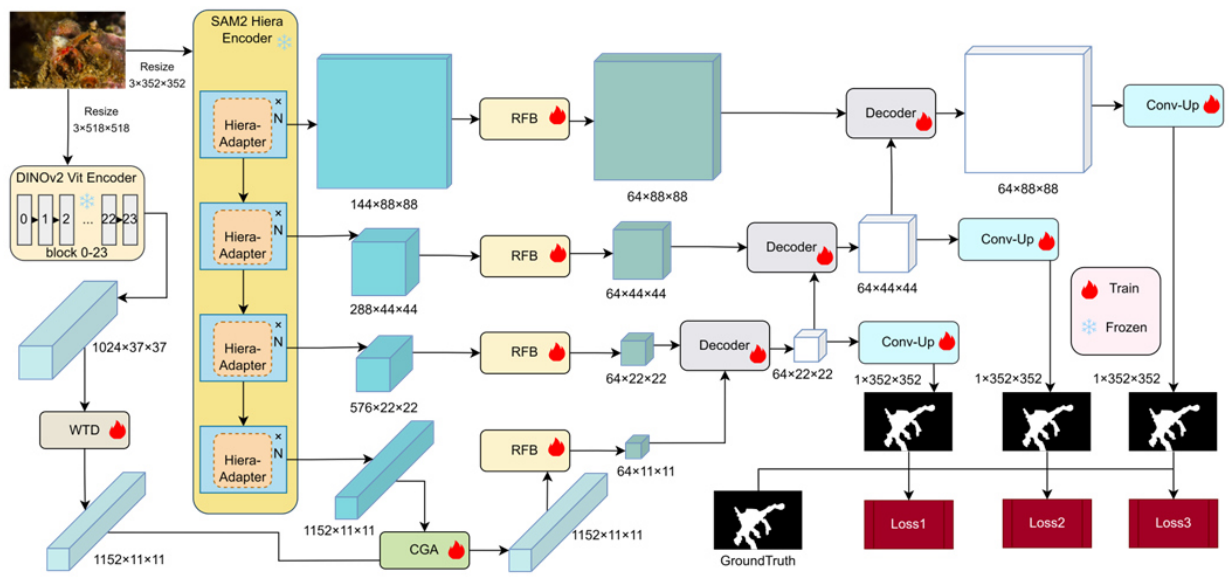
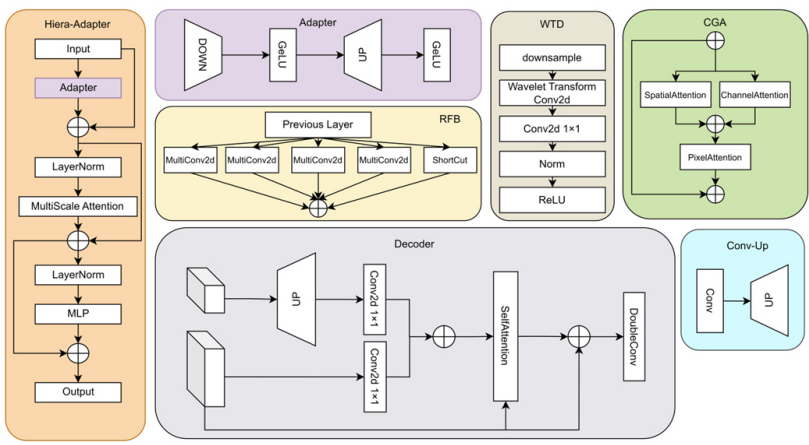
编码器
编码器部分是DSU-Net的核心,它结合了SAM2的Hiera模块和DINOv2的ViT模块,以实现多尺度特征的提取和融合。
- SAM2 Hiera模块:Hiera模块是SAM2的核心特征提取器,它能够提取高质量的语义特征,适用于通用图像分割任务。DSU-Net将Hiera模块作为主干网络,用于提取图像的多尺度特征。
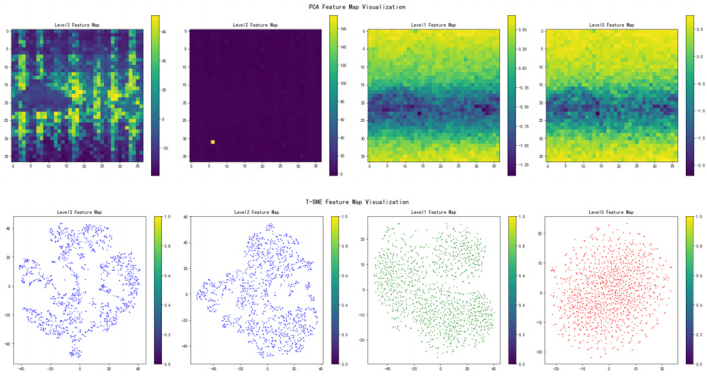
- DINOv2 ViT模块:DINOv2的ViT模块通过自监督学习提取高维语义特征,这些特征在捕捉图像的全局语义信息方面表现出色,如下图所示。DSU-Net将DINOv2的特征图注入到Hiera模块的特征图中,以增强语义信息。
轻量级适配器模块
为了缓解训练数据集与预训练模型数据集之间的域差异,DSU-Net引入了轻量级适配器模块。该模块通过少量参数对Hiera模块的特征进行调整,使其能够快速适应新的数据集。
- 特征降采样与上采样:适配器模块通过线性层和激活函数对Hiera模块的特征进行降采样和上采样,以匹配DINOv2的特征尺度。
- 参数高效性:适配器模块仅引入少量参数,显著降低了训练成本,同时保持了模型的灵活性。
特征融合与协作
DSU-Net通过多尺度特征融合和注意力机制,实现了DINOv2和SAM2特征的有效协作。
- 内容引导注意力(Content-Guided Attention)模块:CGA模块利用DINOv2的语义特征作为引导,通过注意力机制增强SAM2的特征表示。该模块动态调整特征图的权重,突出重要的语义信息。
- 多尺度特征融合:DSU-Net在多个尺度上融合DINOv2和SAM2的特征,通过特征金字塔网络结构,将不同尺度的特征进行交互和融合,以获得更丰富的语义信息。
解码器
解码器部分负责将编码器提取的多尺度特征上采样并生成最终的分割掩码。
- 空间特征融合模块:SFF模块动态调整不同尺度特征图的权重,通过空间注意力机制增强特征的空间一致性。
- 分割头:分割头采用1x1卷积和双线性插值上采样,将融合后的特征图转换为高分辨率的分割掩码。
模型优势
高效性:通过轻量级适配器模块和冻结预训练参数,DSU-Net显著降低了训练成本,适合在资源受限的设备上高效训练。
适应性:通过多尺度特征融合和注意力机制,DSU-Net能够适应多种复杂的图像分割任务,展现出强大的泛化能力。
高精度:实验结果表明,DSU-Net在多个基准数据集上超越了现有的最先进方法,显著提升了分割精度。
实验
DUTS数据集测试:
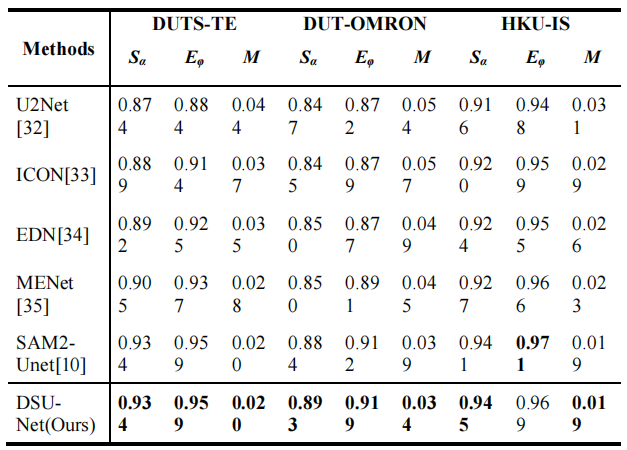
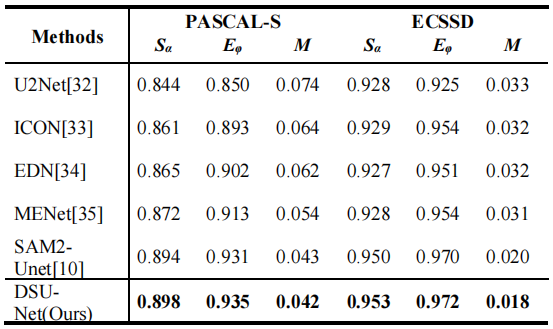
PASCAL数据集测试:
代码
DSU-Net:
import torch
import torch.nn as nn
import torch.nn.functional as F
from backbone import dinov2_extract, sam2hiera
from fusion import CGAFusion, sff
from modules import updown, wtconv, RFB
from torchinfo import summary
class DGSUNet(nn.Module):
def __init__(self,dino_model_name=None,dino_hub_dir=None,sam_config_file=None,sam_ckpt_path=None):
super(DGSUNet, self).__init__()
if dino_model_name is None:
print("No model_name specified, using default")
dino_model_name = 'dinov2_vitl14'
if dino_hub_dir is None:
print("No dino_hub_dir specified, using default")
dino_hub_dir = 'facebookresearch/dinov2'
if sam_config_file is None:
print("No sam_config_file specified, using default")
# Replace with your own SAM configuration file path
sam_config_file = r'G:\MyProjectCode\SAM2DINO-Seg\sam2_configs\sam2.1_hiera_l.yaml'
if sam_ckpt_path is None:
print("No sam_ckpt_path specified, using default")
# Replace with your own SAM pt file path
sam_ckpt_path = r'G:\MyProjectCode\SAM2DINO-Seg\checkpoints\sam2.1_hiera_large.pt'
# Backbone Feature Extractor
self.backbone_dino = dinov2_extract.DinoV2FeatureExtractor(dino_model_name, dino_hub_dir)
self.backbone_sam = sam2hiera.sam2hiera(sam_config_file,sam_ckpt_path)
# Feature Fusion
self.fusion4 = CGAFusion.CGAFusion(1152)
# (1024,37,37)->(1024,11,11)
self.dino2sam_down4 = updown.interpolate_upsample(11)
# (1024,11,11)->(1152,11,11)
self.dino2sam_down14 = wtconv.DepthwiseSeparableConvWithWTConv2d(in_channels=1024, out_channels=1152)
self.rfb1 = RFB.RFB_modified(144, 64)
self.rfb2 = RFB.RFB_modified(288, 64)
self.rfb3 = RFB.RFB_modified(576, 64)
self.rfb4 = RFB.RFB_modified(1152, 64)
self.decoder1 = sff.SFF(64)
self.decoder2 = sff.SFF(64)
self.decoder3 = sff.SFF(64)
self.side1 = nn.Conv2d(64, 1, kernel_size=1)
self.side2 = nn.Conv2d(64, 1, kernel_size=1)
self.head = nn.Conv2d(64, 1, kernel_size=1)
def forward(self, x_dino, x_sam):
# Backbone Feature Extractor
x1, x2, x3, x4 = self.backbone_sam(x_sam)
x_dino = self.backbone_dino(x_dino)
# change dino feature map size and dimension
x_dino4 = self.dino2sam_down4(x_dino)
x_dino4 = self.dino2sam_down14(x_dino4)
# Feature Fusion(sam & dino)
x4 = self.fusion4(x4, x_dino4)
# change fusion feature map dimension->(64,11/22/44/88,11/22/44/88)
x1, x2, x3, x4 = self.rfb1(x1), self.rfb2(x2), self.rfb3(x3), self.rfb4(x4)
x = self.decoder1(x4,x3)
out1 = F.interpolate(self.side1(x), scale_factor=16, mode='bilinear')
x = self.decoder2(x,x2)
out2 = F.interpolate(self.side2(x), scale_factor=8, mode='bilinear')
x = self.decoder3(x,x1)
out3 = F.interpolate(self.head(x), scale_factor=4, mode='bilinear')
return out1,out2,out3
######################################################################################################
if __name__ == "__main__":
with torch.no_grad():
model = DGSUNet().cuda()
x_dino = torch.randn(1, 3, 518, 518).cuda()
x_sam = torch.randn(1, 3, 352, 352).cuda()
# print(model)
summary(model, input_data=(x_dino, x_sam))
out, out1, out2 = model(x_dino,x_sam)
print(out.shape, out1.shape, out2.shape)sam2hiera:
import torch
import torch.nn as nn
from sam2.build_sam import build_sam2
from matplotlib import rcParams
from sam2dino_seg.self_transforms.preprocess_image import transforms_image
from sam2dino_seg.modules import adapter
from visualize.features_vis import visualize_feature_maps_mean, visualize_feature_maps_pca, visualize_feature_maps_tsne
# 设置全局字体为 SimHei(黑体)
rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题
class sam2hiera(nn.Module):
def __init__(self, config_file=None, ckpt_path=None) -> None:
super().__init__()
if config_file is None:
print("No config file provided, using default config")
config_file = "./sam2_configs/sam2.1_hiera_l.yaml"
if ckpt_path is None:
model = build_sam2(config_file)
else:
model = build_sam2(config_file, ckpt_path)
del model.sam_mask_decoder
del model.sam_prompt_encoder
del model.memory_encoder
del model.memory_attention
del model.mask_downsample
del model.obj_ptr_tpos_proj
del model.obj_ptr_proj
del model.image_encoder.neck
self.sam_encoder = model.image_encoder.trunk
for param in self.sam_encoder.parameters():
param.requires_grad = False
# Adapter
blocks = []
for block in self.sam_encoder.blocks:
blocks.append(
adapter.Adapter(block)
)
self.sam_encoder.blocks = nn.Sequential(
*blocks
)
def forward(self, x):
out = self.sam_encoder(x)
return out
if __name__ == "__main__":
config_file = r"G:\MyProjectCode\SAM2DINO-Seg\sam2_configs\sam2.1_hiera_l.yaml"
ckpt_path = r"G:\MyProjectCode\SAM2DINO-Seg\checkpoints\sam2.1_hiera_large.pt"
# 预处理图像
image_path = r"G:\MyProjectCode\SAM2DINO-Seg\data\images\COD10K-CAM-1-Aquatic-3-Crab-29.jpg" # 替换为您的图像路径
x = transforms_image(image_path, image_size=352)
with torch.no_grad():
model = sam2hiera(config_file, ckpt_path).cuda()
if torch.cuda.is_available():
x = x.cuda()
out= model(x)
# 组合为字典
# features = {
# 'high_level': out['backbone_fpn'][2],
# 'mid_level': out['backbone_fpn'][1],
# 'low_level': out['backbone_fpn'][0]
# }
features = {
'top_level': out[3],
'high_level': out[2],
'mid_level': out[1],
'low_level': out[0]
}
# 打印各特征形状
print(f"顶级特征形状 (全局尺度): {features['top_level'].shape}")
# print(f"高级特征形状 (高等尺度): {features['high_level']}")
print(f"高级特征形状 (高等尺度): {features['high_level'].shape}")
print(f"中级特征形状 (中等尺度): {features['mid_level'].shape}")
print(f"低级特征形状 (局部尺度): {features['low_level'].shape}")
# 均值可视化特征
visualize_feature_maps_mean(features,backbone_name='SAM2')
# PCA可视化
visualize_feature_maps_pca(features,backbone_name='SAM2')
# T-SNE可视化
visualize_feature_maps_tsne(features, backbone_name='SAM2')
print("Hiera多尺度特征提取完成!")dinov2_extract:
import torch
import torch.nn as nn
import numpy as np
from matplotlib import rcParams
from sam2dino_seg.self_transforms.preprocess_image import transforms_image
# 设置全局字体为 SimHei(黑体)
rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
rcParams['axes.unicode_minus'] = False # 解决负号 '-' 显示为方块的问题
class DinoV2FeatureExtractor(nn.Module):
def __init__(self, model_name=None, hub_dir=None) -> None:
super().__init__()
if hub_dir is None:
print("No hub_dir specified, using default")
hub_dir = 'facebookresearch/dinov2'
if model_name is None:
print("No model_name specified, using default")
model_name = 'dinov2_vitl14'
model = torch.hub.load(hub_dir, model_name, pretrained=True)
self.dino_encoder = model
self.patchsize = 14
for param in self.dino_encoder.parameters():
param.requires_grad = False
def forward(self, x):
output = self.dino_encoder.forward_features(x)
dino_feature = output['x_norm_patchtokens']
# print(dino_feature.shape)
# 转换为空间特征图
img_size = int(x.shape[-1])
batch_size = int(x.shape[0])
feature_size = int((img_size / self.patchsize) ** 2)
# 验证获取的特征大小
assert dino_feature.shape[1] == feature_size, f"特征大小不匹配: {dino_feature.shape[1]} vs {feature_size}"
# 重新构建为2D特征图
side_length = int(np.sqrt(feature_size))
dino_feature_map = dino_feature.reshape(batch_size, side_length, side_length, -1).permute(0, 3, 1, 2)
return dino_feature_map
# 示例使用
if __name__ == "__main__":
# 预处理图像
# image_path = r"G:\MyProjectCode\SAM2DINO-Seg\data\images\R-C.jpg" # 替换为您的图像路径
# x = transforms_image(image_path, image_size=518)
x = torch.randn(12, 3, 518, 518)
with torch.no_grad():
model = DinoV2FeatureExtractor().cuda()
if torch.cuda.is_available():
x = x.cuda()
out = model(x)
print(out.shape)
# print(out)输入图像:

预测结果:

总结
DSU-Net通过结合DINOv2和SAM2的优势,解决了现有图像分割模型在特定下游任务中表现不足的问题。它利用多尺度跨模型特征协作和轻量级适配器模块,显著提升了模型的分割精度和泛化能力,同时降低了训练成本,使其能够在资源受限的设备上高效运行。DSU-Net的成功为未来图像分割领域的研究提供了重要启发,特别是在跨模型协作、轻量级适配器设计以及多尺度特征融合等方面,为开发更高效、更适应多样化任务的模型奠定了基础。