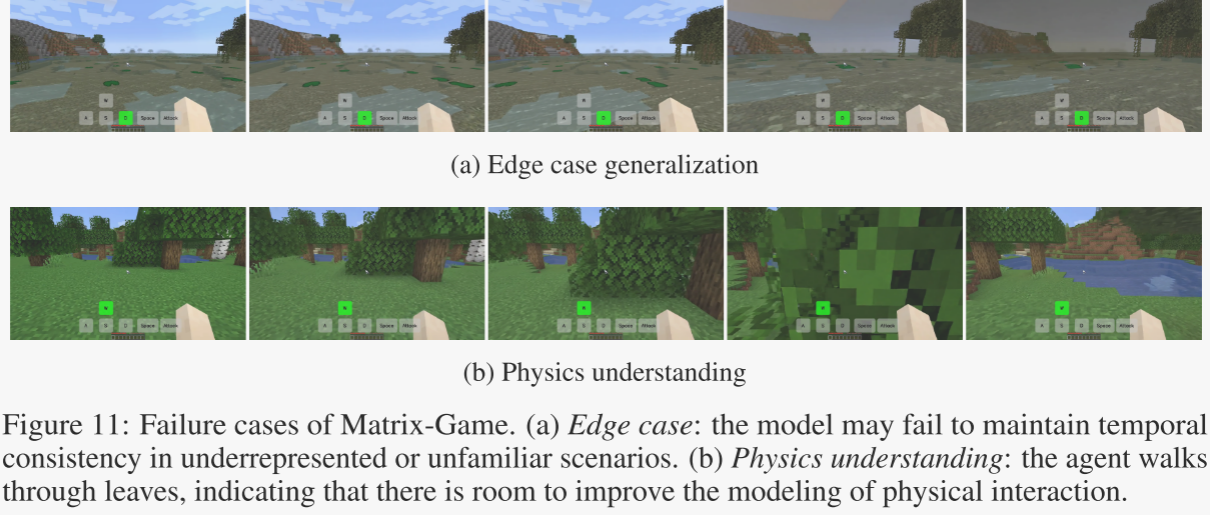
生成对抗网络是深度学习领域最具革命性的生成模型之一。
一 GAN框架
1.1组成
构造生成器(G)与判别器(D)进行动态对抗,实现数据的无监督生成。
G(造假者):接收噪声 ,生成数据
。
D(鉴定家):接收真实数据 和生成数据
,输出概率
或
1.2核心原理
对抗目标:
该公式为极大极小博弈,D和G互为对手,在动态博弈中驱动模型逐步提升性能。
其中:
第一项(真实性强化) 的目标为:
让判别器 D 将真实数据 x 识别为“真”(即让 ),最大化这一项可使D对真实数据的判断置信度更高。
第二项(生成性对抗):的目标为:
生成器G希望生成的假数据被判别器D判为“真”(即让
)从而最小化
,判别器D则希望判假数据为“假”(即让
),从而最大化
。
生成器和判别器在此项上存在直接对抗。
数学原理:
(1)最优判别器理论
固定生成器G时,最大化 得到最优判别器
。
其中, 是生成数据的分布。当生成数据完美匹配真实分布时
,判别器无法区分真假(输出
)。
推导一下:
(1)
转换为积分形式,设真实数据分布为 ,生成数据分布为
,则(1)可以改写为:
(2)
逐点最大化,对于每个样本 x,单独最大化以下函数:
(3)
求导并解方程:
(4)
求得:
(5)
(2) 目标化简:JS散度(Jensen-Shannon Divergence)
将最优判别器 代入原目标函数,可得:
最小化目标即等价于最小化 与
的JS散度。
JS散度特性:对称、非负,衡量两个分布的相似性。
1.3训练过程解释
每个训练步骤包含两阶段:
(1)判别器更新(固定G,最大化 ):
通过梯度上升优化D的参数,提升判别能力。
(2)生成器更新(固定D,最小化 ):
实际训练中常用 代替以增强梯度稳定性。
训练中出现的问题:
(1)JS散度饱和导致梯度消失
(2)参数空间的非凸优化(存在无数个局部极值,优化算法极易陷入次优解,而非全局最优解)使训练难以收敛
二 经典GAN架构
DCGAN(GAN+卷积)
| 特性 | 原始GAN | DCGAN |
|---|---|---|
| 网络结构 | 全连接层(MLPs) | 卷积生成器 + 卷积判别器 |
| 稳定性 | 容易梯度爆炸/消失,难以收敛 | 通过BN和特定激活函数稳定训练 |
| 生成图像分辨率 | 低分辨率(如32x32) | 支持64x64及以上分辨率的清晰图像生成 |
| 图像质量 | 轮廓模糊,缺乏细节 | 细粒度纹理(如毛发、砖纹) |
| 计算效率 | 参数量大,训练速度慢 | 卷积结构参数共享,效率提升 |
(1)生成器架构(反卷积)
class Generator(nn.Module):
def __init__(self, noise_dim=100, output_channels=3):
super().__init__()
self.main = nn.Sequential(
# 输入:100维噪声,输出:1024x4x4
nn.ConvTranspose2d(noisel_dim, 512, 4, 1, 0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 上采样至8x8
nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 输出层:3通道RGB图像
nn.ConvTranspose2d(64, output_channels, 4, 2, 1, bias=False),
nn.Tanh() # 将输出压缩到[-1,1]
)
(2) 判别器架构(卷积)
class Discriminator(nn.Module):
def __init__(self, input_channels=3):
super().__init__()
self.main = nn.Sequential(
# 输入:3x64x64
nn.Conv2d(input_channels, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 下采样至32x32
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
# 输出层:二分类概率
nn.Conv2d(512, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
(3)双重优化问题
保持生成器和判别器动态平衡的核心机制。
for epoch in range(num_epochs):
# 更新判别器
optimizer_D.zero_grad()
real_loss = adversarial_loss(D(real_imgs), valid)
fake_loss = adversarial_loss(D(gen_imgs.detach()), fake)
d_loss = (real_loss + fake_loss) / 2
d_loss.backward()
optimizer_D.step()
# 更新生成器
optimizer_G.zero_grad()
g_loss = adversarial_loss(D(gen_imgs), valid) # 欺诈判别器
g_loss.backward()
optimizer_G.step()
三 应用场景
图像合成引擎(语义图到照片)、医学影像增强、语音与音频合成。
GAN作为生成式AI的基石模型,其核心价值不仅在于数据生成能力,更在于构建了一种全新的深度学习范式——通过对抗博弈驱动模型持续进化。
四 一个完整DCGAN代码示例
MNIST数据集
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 参数设置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
batch_size = 128
image_size = 64
num_epochs = 50
latent_dim = 100
lr = 0.0002
beta1 = 0.5
# 数据准备
transform = transforms.Compose([
transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # MNIST是单通道
])
dataset = datasets.MNIST(root="./data", train=True, transform=transform, download=True)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=4)
# 可视化辅助函数
def show_images(images):
plt.figure(figsize=(8,8))
images = images.permute(1,2,0).cpu().numpy()
plt.imshow((images * 0.5) + 0.5) # 反归一化
plt.axis('off')
plt.show()
# 权重初始化
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0)
# 生成器定义
class Generator(nn.Module):
def __init__(self, latent_dim):
super(Generator, self).__init__()
self.main = nn.Sequential(
# 输入:latent_dim x 1 x 1
nn.ConvTranspose2d(latent_dim, 512, 4, 1, 0, bias=False),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 输出:512 x 4 x 4
nn.ConvTranspose2d(512, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 输出:256 x 8 x 8
nn.ConvTranspose2d(256, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 输出:128 x 16x16
nn.ConvTranspose2d(128, 64, 4, 2, 1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
# 输出:64 x 32x32
nn.ConvTranspose2d(64, 1, 4, 2, 1, bias=False),
nn.Tanh() # 输出范围[-1,1]
# 最终输出:1 x 64x64
)
def forward(self, input):
return self.main(input)
# 判别器定义
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
# 输入:1 x 64x64
nn.Conv2d(1, 64, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 输出:64 x32x32
nn.Conv2d(64, 128, 4, 2, 1, bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
# 输出:128x16x16
nn.Conv2d(128, 256, 4, 2, 1, bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
# 输出:256x8x8
nn.Conv2d(256, 512, 4, 2, 1, bias=False),
nn.BatchNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
# 输出:512x4x4
nn.Conv2d(512, 1, 4, 1, 0, bias=False),
nn.Sigmoid()
)
def forward(self, input):
return self.main(input).view(-1, 1).squeeze(1)
# 初始化模型
generator = Generator(latent_dim).to(device)
discriminator = Discriminator().to(device)
# 应用权重初始化
generator.apply(weights_init)
discriminator.apply(weights_init)
# 损失函数和优化器
criterion = nn.BCELoss()
optimizer_G = optim.Adam(generator.parameters(), lr=lr, betas=(beta1, 0.999))
optimizer_D = optim.Adam(discriminator.parameters(), lr=lr, betas=(beta1, 0.999))
# 训练过程可视化准备
fixed_noise = torch.randn(64, latent_dim, 1, 1, device=device)
# 训练循环
for epoch in range(num_epochs):
for i, (real_images, _) in enumerate(dataloader):
# 准备数据
real_images = real_images.to(device)
batch_size = real_images.size(0)
# 真实标签和虚假标签
real_labels = torch.full((batch_size,), 0.9, device=device) # label smoothing
fake_labels = torch.full((batch_size,), 0.0, device=device)
# ========== 训练判别器 ==========
optimizer_D.zero_grad()
# 真实图片的判别结果
outputs_real = discriminator(real_images)
loss_real = criterion(outputs_real, real_labels)
# 生成假图片
noise = torch.randn(batch_size, latent_dim, 1, 1, device=device)
fake_images = generator(noise)
# 假图片的判别结果
outputs_fake = discriminator(fake_images.detach())
loss_fake = criterion(outputs_fake, fake_labels)
# 合并损失并反向传播
loss_D = loss_real + loss_fake
loss_D.backward()
optimizer_D.step()
# ========== 训练生成器 ==========
optimizer_G.zero_grad()
# 更新生成器时的判别结果
outputs = discriminator(fake_images)
loss_G = criterion(outputs, real_labels) # 欺骗判别器
# 反向传播
loss_G.backward()
optimizer_G.step()
# 打印训练状态
if i % 100 == 0:
print(f"[Epoch {epoch}/{num_epochs}] [Batch {i}/{len(dataloader)}] "
f"Loss_D: {loss_D.item():.4f} Loss_G: {loss_G.item():.4f}")
# 每个epoch结束时保存生成结果
with torch.no_grad():
test_images = generator(fixed_noise)
grid = torchvision.utils.make_grid(test_images, nrow=8, normalize=True)
show_images(grid)
# 保存模型检查点
if (epoch+1) % 5 == 0:
torch.save(generator.state_dict(), f'generator_epoch_{epoch+1}.pth')
torch.save(discriminator.state_dict(), f'discriminator_epoch_{epoch+1}.pth')
print("训练完成!")