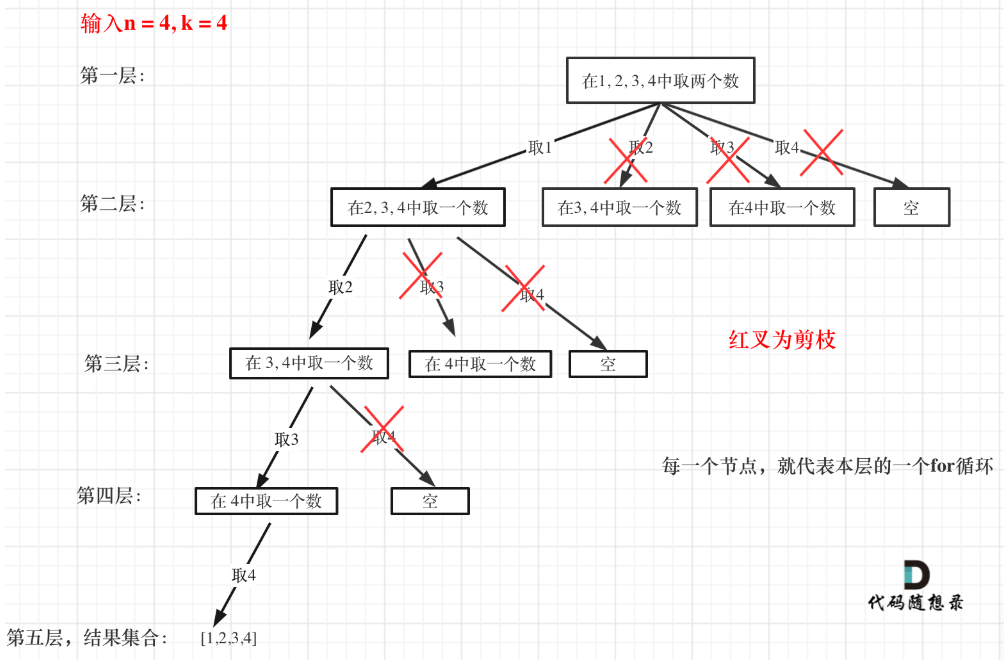
KL散度,也称为相对熵 (Relative Entropy),是信息论中一个核心概念,用于衡量两个概率分布之间的差异。给定两个概率分布 P ( x ) P(x) P(x) 和 Q ( x ) Q(x) Q(x)(对于离散随机变量)或 p ( x ) p(x) p(x) 和 q ( x ) q(x) q(x)(对于连续随机变量),从 Q Q Q 到 P P P 的KL散度定义如下:
1. 定义
-
对于离散概率分布 P ( x ) P(x) P(x) 和 Q ( x ) Q(x) Q(x):
D K L ( P ∥ Q ) = ∑ x ∈ X P ( x ) log ( P ( x ) Q ( x ) ) D_{KL}(P \parallel Q) = \sum_{x \in \mathcal{X}} P(x) \log \left( \frac{P(x)}{Q(x)} \right) DKL(P∥Q)=x∈X∑P(x)log(Q(x)P(x))
其中 X \mathcal{X} X 是随机变量 x x x 所有可能取值的集合。 -
对于连续概率分布 p ( x ) p(x) p(x) 和 q ( x ) q(x) q(x):
D K L ( p ∥ q ) = ∫ − ∞ ∞ p ( x ) log ( p ( x ) q ( x ) ) d x D_{KL}(p \parallel q) = \int_{-\infty}^{\infty} p(x) \log \left( \frac{p(x)}{q(x)} \right) dx DKL(p∥q)=∫−∞∞p(x)log(q(x)p(x))dx在这些定义中,通常使用自然对数 (ln),此时KL散度的单位是“奈特 (nats)”。如果使用以2为底的对数,单位则是“比特 (bits)”。约定 0 log ( 0 / q ) = 0 0 \log(0/q) = 0 0log(0/q)=0 和 p log ( p / 0 ) = ∞ p \log(p/0) = \infty plog(p/0)=∞ (如果 P ( x ) > 0 P(x) > 0 P(x)>0 且 Q ( x ) = 0 Q(x) = 0 Q(x)=0,则KL散度为无穷大,意味着如果 P P P 中有事件发生而 Q Q Q 认为其概率为0,则 Q Q Q 无法良好地逼近 P P P)。
2. 信息论视角
从信息论的角度来看,KL散度有多种解释:
- 期望的对数似然比: D K L ( P ∥ Q ) D_{KL}(P \parallel Q) DKL(P∥Q) 是在真实分布为 P P P 的情况下,使用 P P P 相对于使用 Q Q Q 的对数似然比的期望值。
- 信息增益: 当我们从一个先验分布 Q Q Q 更新到一个后验分布 P P P 时, D K L ( P ∥ Q ) D_{KL}(P \parallel Q) DKL(P∥Q) 量化了我们获得的平均信息量。
- 编码长度的额外代价: 假设数据真实服从分布 P P P。如果我们使用一个基于分布 Q Q Q 的最优编码方案来编码这些数据,而不是使用基于真实分布 P P P 的最优编码方案, D K L ( P ∥ Q ) D_{KL}(P \parallel Q) DKL(P∥Q) 表示我们平均需要多少额外的比特数(或奈特数)来编码样本。也就是说,它衡量了由于使用了一个次优的分布 Q Q Q 来近似真实分布 P P P 所导致的信息损失。
- 相对熵: 它可以表示为交叉熵与熵的差:
D K L ( P ∥ Q ) = H ( P , Q ) − H ( P ) D_{KL}(P \parallel Q) = H(P, Q) - H(P) DKL(P∥Q)=H(P,Q)−H(P)
其中 H ( P , Q ) = − ∑ x P ( x ) log Q ( x ) H(P, Q) = - \sum_x P(x) \log Q(x) H(P,Q)=−∑xP(x)logQ(x) 是 P P P 和 Q Q Q 之间的交叉熵,而 H ( P ) = − ∑ x P ( x ) log P ( x ) H(P) = - \sum_x P(x) \log P(x) H(P)=−∑xP(x)logP(x) 是 P P P 的熵(信息熵)。由于 H ( P ) H(P) H(P) 是固定的(对于给定的 P P P),最小化KL散度等价于最小化交叉熵。
3. 重要性质
- 非负性 (Gibbs’ Inequality): D K L ( P ∥ Q ) ≥ 0 D_{KL}(P \parallel Q) \ge 0 DKL(P∥Q)≥0。
- 当且仅当 P = Q P=Q P=Q 时取零: D K L ( P ∥ Q ) = 0 D_{KL}(P \parallel Q) = 0 DKL(P∥Q)=0 当且仅当 P ( x ) = Q ( x ) P(x) = Q(x) P(x)=Q(x) 对于几乎所有 x x x 都成立。
- 不对称性: 通常情况下,
D
K
L
(
P
∥
Q
)
≠
D
K
L
(
Q
∥
P
)
D_{KL}(P \parallel Q) \neq D_{KL}(Q \parallel P)
DKL(P∥Q)=DKL(Q∥P)。这意味着KL散度不是一个真正的度量 (metric),因为它不满足对称性和三角不等式。例如,如果
P
P
P 是一个多峰分布,而
Q
Q
Q 是一个单峰分布,那么
D
K
L
(
P
∥
Q
)
D_{KL}(P \parallel Q)
DKL(P∥Q) 和
D
K
L
(
Q
∥
P
)
D_{KL}(Q \parallel P)
DKL(Q∥P) 会有不同的行为:
- 最小化 D K L ( P ∥ Q ) D_{KL}(P \parallel Q) DKL(P∥Q) 会倾向于使 Q Q Q 覆盖 P P P 的所有模式 (mode-covering or zero-avoiding behavior),即如果 P ( x ) > 0 P(x)>0 P(x)>0,则 Q ( x ) Q(x) Q(x) 也必须大于0。
- 最小化 D K L ( Q ∥ P ) D_{KL}(Q \parallel P) DKL(Q∥P) 会倾向于使 Q Q Q 集中在 P P P 的某个模式上 (mode-seeking or zero-forcing behavior),即如果 P ( x ) P(x) P(x) 很小或为0, Q ( x ) Q(x) Q(x) 也会趋向于很小或为0。
4. 在机器学习中的应用
KL散度在机器学习中有广泛应用:
- 变分推断 (Variational Inference): 在贝叶斯统计中,当后验分布 P ( Z ∣ X ) P(Z|X) P(Z∣X) 难以计算时,我们常常寻找一个简单分布 Q ( Z ) Q(Z) Q(Z) 来近似它。这通过最小化 D K L ( Q ( Z ) ∥ P ( Z ∣ X ) ) D_{KL}(Q(Z) \parallel P(Z|X)) DKL(Q(Z)∥P(Z∣X)) (或者更常见的是最小化 D K L ( Q ( Z ) ∥ P ( Z , X ) ) D_{KL}(Q(Z) \parallel P(Z,X)) DKL(Q(Z)∥P(Z,X)),这等价于最大化证据下界 ELBO)来实现。由于前面提到的不对称性,通常选择最小化 D K L ( Q ∥ P ) D_{KL}(Q \parallel P) DKL(Q∥P) 的形式,这倾向于找到一个能够很好地拟合 P P P 主要模式的 Q Q Q。
- 损失函数与正则化:
- 作为两个概率分布之间差异的度量,它可以直接用作损失函数,例如在生成模型中,我们希望模型生成的分布 Q Q Q 尽可能接近真实数据分布 P P P。
- 作为正则化项,例如在强化学习中,约束策略网络的变化,使其不会与先前的策略或参考策略偏离太远。
5. 在RLHF (Reinforcement Learning from Human Feedback) for LLMs 中的应用
KL散度可用于约束语言模型的策略更新,具体体现在奖励函数中:
R
(
x
,
y
)
=
r
θ
(
x
,
y
)
−
β
log
(
π
ϕ
R
L
(
y
∣
x
)
π
S
F
T
(
y
∣
x
)
)
R(x,y) = r_{\theta}(x,y) - \beta \log\left(\frac{\pi_{\phi}^{RL}(y|x)}{\pi^{SFT}(y|x)}\right)
R(x,y)=rθ(x,y)−βlog(πSFT(y∣x)πϕRL(y∣x))
这里的
log
(
π
ϕ
R
L
(
y
∣
x
)
π
S
F
T
(
y
∣
x
)
)
\log\left(\frac{\pi_{\phi}^{RL}(y|x)}{\pi^{SFT}(y|x)}\right)
log(πSFT(y∣x)πϕRL(y∣x)) 项直接与KL散度相关。实际上,如果我们在
π
S
F
T
(
y
∣
x
)
\pi^{SFT}(y|x)
πSFT(y∣x) 的期望下看待这一项,它就是
D
K
L
(
π
S
F
T
∥
π
ϕ
R
L
)
D_{KL}(\pi^{SFT} \parallel \pi_{\phi}^{RL})
DKL(πSFT∥πϕRL) 的一部分(或者更准确地说,是
D
K
L
(
π
ϕ
R
L
∥
π
S
F
T
)
D_{KL}(\pi_{\phi}^{RL} \parallel \pi^{SFT})
DKL(πϕRL∥πSFT) 的负相关项,符号和期望对象需要注意)。
在这个公式中:
- π ϕ R L ( y ∣ x ) \pi_{\phi}^{RL}(y|x) πϕRL(y∣x) 是当前通过强化学习更新的策略(语言模型),给定上下文 x x x 生成 y y y 的概率。
- π S F T ( y ∣ x ) \pi^{SFT}(y|x) πSFT(y∣x) 是一个参考策略,通常是经过监督微调 (Supervised Fine-Tuning) 得到的模型,它代表了期望的、较为安全的行为。
- β \beta β 是一个超参数,控制KL惩罚项的强度。
该KL惩罚项(或其变体)的作用:
- 约束探索空间,防止策略漂移过大: 它限制了RL策略 π ϕ R L \pi_{\phi}^{RL} πϕRL 不要与初始的、表现良好的SFT策略 π S F T \pi^{SFT} πSFT 偏离太远。这有助于稳定训练,避免模型探索到非常差的、产生无意义或有害内容的策略空间。
- 缓解奖励模型被“Hacking”: 语言模型可能会找到一些方式来“欺骗”奖励模型 r θ ( x , y ) r_{\theta}(x,y) rθ(x,y) 给出高分,但实际上生成的文本质量不高或者不符合人类偏好。KL惩罚项使得模型在追求高奖励的同时,也必须考虑其行为与参考模型的相似性,从而间接约束了这种“Hacking”行为。
- 充当熵奖励/正则化,鼓励探索(特定形式下): “it acts as an entropy bonus, encouraging the policy to explore and deterring it from collapsing to a single mode.” 虽然上述公式中的形式是惩罚与SFT模型的差异,但在某些RL框架中,KL散度(或者其与熵的联系)可以被用来鼓励策略的随机性,从而促进探索。具体到这里的公式,主要是通过防止模型过于偏离SFT模型来避免模式崩溃到SFT模型未曾覆盖的奇怪区域,而不是直接最大化策略本身的熵。SFT模型本身具有一定的多样性,保持与它的接近间接维持了这种多样性。
KL散度为我们提供了一个量化两个概率分布之间差异的强大工具。在AI和机器学习中,它不仅是理论分析的基础,也是许多算法设计(如变分自编码器VAE、策略优化RL算法如TRPO、PPO等)中的关键组成部分,用于度量信息损失、约束模型行为或指导模型学习。在RLHF中,它扮演了稳定器和安全阀的角色,确保在通过强化学习优化模型以符合人类偏好时,模型不会偏离其已学到的有用知识太远。