DeepSeek 作为当前最热门的开源大模型之一,其强大的语义理解和生成能力吸引了大量开发者和企业关注。然而在实际部署过程中,无论是本地运行还是云端服务,用户往往会遇到各种技术挑战。本文将全面剖析 DeepSeek 部署中的常见问题,提供从硬件选型到性能优化的系统解决方案,并针对不同应用场景给出专业建议。
一、服务器压力与响应延迟问题
问题表现:
在高峰时段访问官方服务时频繁遭遇 "服务器繁忙" 提示,API 响应时间显著延长,严重影响用户体验。
根本原因分析:
-
DeepSeek 官方服务器承载能力有限,用户请求激增导致资源争抢
-
网络传输路径过长或带宽不足
-
请求未做适当分流和负载均衡
解决方案矩阵:
-
本地部署方案
-
使用 Ollama 或 LM Studio 工具在本地运行蒸馏版模型(如 DeepSeek-R1-1.5B),完全避免依赖云端服务
-
通过 Docker 容器化部署,隔离环境依赖
-
示例命令:ollama run deepseek-r1:7b 下载并运行 7B 参数版本
-
-
云端优化策略
-
选择硅基流动等第三方 API 供应商,分散请求压力
-
实现客户端负载均衡:轮询多个 API 端点
-
设置请求重试机制和指数退避算法
-
-
模型选择优化
-
实时性要求不高的任务(如报告生成)切换至成本更低的 V3 模型
-
关键业务使用 R1 模型时,采用异步处理+回调通知机制
-
实施请求优先级队列,确保核心业务优先响应
-
DeepSeek 模型适用场景对比:
| 模型类型 | 适用场景 | 硬件需求 | 响应时间 |
|---|---|---|---|
| V3 | 通用问答/文案生成 | 低(CPU即可) | <500ms |
| R1-1.5B | 基础代码生成 | 4GB显存 | 1-2s |
| R1-7B | 复杂逻辑推理 | 8GB显存 | 3-5s |
| R1-32B | 专业领域分析 | 24GB+显存 | >10s |
进阶技巧:
对于企业级应用,可结合模型蒸馏技术,将 32B 模型知识迁移到小型化模型,在保持 80%以上准确率的同时将推理速度提升 3-5 倍。
二、本地部署硬件性能瓶颈
典型症状:
模型运行时卡顿、无响应或直接崩溃,日志中出现 CUDA out of memory 错误。
硬件需求深度解析:
-
GPU 显存要求
-
1.5B 模型:至少 4GB 显存(如 GTX 1650)
-
7B 模型:8GB 显存(RTX 3070 级别)
-
14B/32B 模型:需 16GB-24GB 高端显卡(如 RTX 4090 或专业级 A100)
-
-
CPU 与内存配置
-
推荐多核处理器(Intel i9 或 AMD 锐龙 9)
-
内存容量应为模型参数的 2-3 倍:
-
7B 模型:至少 16GB
-
14B 模型:32GB 起步
-
32B 模型:建议 64GB+
-
-
-
存储子系统
-
模型加载速度受 SSD 性能显著影响
-
建议 NVMe SSD(如三星 980 Pro),避免使用机械硬盘
-
预留 2-3 倍模型大小的磁盘空间(如 7B 模型约 14GB)
-
性能优化方案:
-
显存不足的应急处理
# 在加载模型时添加量化参数
model = AutoModelForCausalLM.from_pretrained(
"deepseek-ai/deepseek-r1-7b",
load_in_8bit=True, # 8位量化
device_map="auto"
)8 位量化可减少约 50% 显存占用,4 位量化(bitsandbytes 库)可进一步降低到 25%。
- 批处理参数调优
# config.yml 优化示例
inference:
max_batch_size: 4 # 根据显存调整
max_seq_length: 512 # 缩短序列长度
use_flash_attention: true # 启用注意力优化-
散热系统设计
-
游戏本用户:使用散热底座+限制 Turbo Boost
-
工作站:部署水冷系统,避免硬件过热降频
-
监控工具推荐:GPU-Z、HWMonitor
-
硬件选购指南:
-
入门级:RTX 3060(12GB)+ 32GB DDR4 + i5-13600K
-
专业级:RTX 4090(24GB)+ 64GB DDR5 + i9-13900K
-
企业级:多卡并行(如 2×A100 80GB)+ EPYC 处理器
三、模型选择与功能适配困惑
常见误区:
用户混淆 V3 与 R1 模型的适用场景,导致任务效率低下或资源浪费。
模型特性深度对比:
-
V3 模型家族
-
优势:轻量级、响应快、成本低
-
最佳场景:
-
日常问答("法国的首都是哪里?")
-
文案创作(邮件、营销文案)
-
简单数据处理(格式转换)
-
-
限制:复杂逻辑处理能力弱(准确率 <60%)
-
-
R1 模型系列
-
优势:强大的推理和专业能力
-
专精领域:
-
代码生成与调试(支持 Python/Java/C++)
-
数学证明与解题(IMO 级别)
-
学术论文分析(可处理 LaTeX 公式)
-
-
资源消耗:7B 版本比 V3 高 3-5 倍
-
场景化选择框架:
- 客服机器人部署
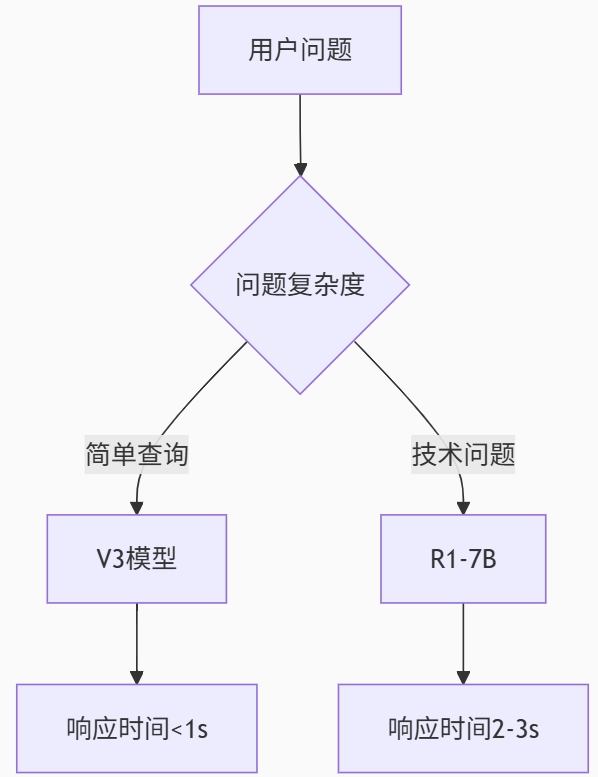
-
金融数据分析
-
报表生成:V3 + 模板引擎
-
风险预测:R1-14B + 微调
-
合规检查:R1-7B + 规则引擎
-
-
教育领域应用
-
作业批改:V3 处理客观题
-
作文评价:R1-7B 深度分析
-
数学辅导:R1-32B 分步讲解
-
混合部署策略:
-
前置路由层判断请求类型
-
热切换机制:根据负载动态调整模型
-
结果融合:简单部分用 V3,复杂部分用 R1
四、API 管理与安全防护
典型风险:
-
API 调用超支(突发流量导致)
-
密钥硬编码泄露
-
未授权访问和数据泄露
企业级解决方案:
-
用量监控体系
# 硅基流动API监控示例
from siliconflow import Monitor
monitor = Monitor(
api_key="sk_...",
budget=1000, # 美元
alerts=[
{"threshold": 80%, "channel": "email"},
{"threshold": 95%, "channel": "sms"}
]
)支持实时查看消耗,设置多级阈值提醒。
- 密钥安全管理
环境变量存储:
# .env 文件
DEEPSEEK_API_KEY=sk_prod_...临时令牌签发:
// AWS Lambda 密钥轮换示例
exports.handler = async (event) => {
const tempKey = generateTempKey(expiry=3600);
return { statusCode: 200, body: tempKey };
};访问控制矩阵:
| 角色 | 权限范围 | 有效期 |
|---|---|---|
| 开发测试 | /v1/chat (只读) | 7天 |
| 生产环境 | /v1/* (读写) | 1小时 |
| 管理后台 | /admin/* | MFA认证 |
高级防护措施:
-
请求签名:HMAC-SHA256 验证
-
速率限制:令牌桶算法实现
-
审计日志:记录所有敏感操作
五、私有化部署专项问题
核心需求:
金融、医疗等行业需确保数据不出域,满足 GDPR/HIPAA 合规要求。
部署架构设计:
- 网络拓扑
[DMZ区]
↑↓ HTTPS
[防火墙] ←→ [反向代理] ←→ [应用服务器] ←→ [模型服务]
↑↓ TLS 1.3
[数据库集群]-
数据安全方案
-
传输加密:TLS 1.3 + 双向证书认证
-
存储加密:AES-256 静态数据加密
-
内存安全:Intel SGX 可信执行环境
-
-
知识库集成
# RAGFlow 集成示例
from ragflow import KnowledgeGraph
kg = KnowledgeGraph(
docs_path="/data/medical_records",
embedding_model="本地BGE"
)
response = deepseek.query(
"患者过敏史?",
context=kg.search("过敏")
)通过 RAG 技术增强语义检索安全性。
合规性检查清单:
-
数据本地化存储
-
访问日志保留 180 天以上
-
敏感信息脱敏处理
-
第三方组件安全审计
六、模型下载与更新问题
常见故障:
-
下载速度慢(<100KB/s)
-
校验失败(哈希不匹配)
-
中断后无法续传
多维度解决方案:
-
网络优化
-
有线网络优先,避免 Wi-Fi 波动
-
关闭带宽竞争应用(视频会议、云盘同步)
-
运营商选择:电信/联通优于移动
-
-
分块下载技术
# Ollama 断点续传示例
ollama pull deepseek-r1:7b --resume-
镜像加速源
平台 加速方式 速度提升 腾讯云 镜像站代理 3-5x 阿里云 内网穿透 2-3x 奇游加速器 专线加速 5-8x -
模型版本管理
# 查看已安装模型
ollama list
# 删除旧版本
ollama rm deepseek-r1:7b
# 拉取最新版
ollama pull deepseek-r1:7b下载异常处理流程:
-
检查磁盘空间(df -h)
-
验证网络连接(ping ollama.com)
-
清除缓存(rm -rf ~/.ollama/cache)
-
更换下载工具(curl → aria2c)
七、环境配置与依赖冲突
报错示例:
-
ImportError: libcudart.so.11.0: cannot open shared object file -
DLL load failed while importing torch
跨平台解决方案:
- 版本匹配矩阵
| DeepSeek版本 | Python | CUDA | cuDNN | PyTorch |
|---|---|---|---|---|
| R1-1.5B | 3.8-3.10 | 11.7 | 8.5 | 2.0.1 |
| R1-7B | 3.9-3.11 | 11.8 | 8.6 | 2.1.0 |
| V3 | 3.7+ | 可选 | 无需 | 1.13+ |
- 虚拟环境最佳实践
# Conda 环境创建
conda create -n deepseek python=3.10
conda activate deepseek
pip install torch==2.0.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117- 系统级依赖
-
Ubuntu:sudo apt install libgl1-mesa-glx libglib2.0-0 gcc-11
-
Windows:
-
安装 Visual C++ 2015-2022 Redistributable
-
更新 WSL2(Linux子系统)
-
-
依赖树分析工具:
pipdeptree --packages torch,transformers输出冲突报告并自动修复:
pip-autoremove八、服务监控与性能调优
关键指标:
-
吞吐量(requests/sec)
-
延迟(P99 <2s)
-
错误率(<0.1%)
-
GPU 利用率(70-90%)
监控体系搭建:
- Prometheus + Grafana 方案
# prometheus.yml 片段
scrape_configs:
- job_name: 'deepseek'
metrics_path: '/metrics'
static_configs:
- targets: ['localhost:8000']- 性能优化技巧
计算图优化:
model = torch.jit.trace(model, example_inputs)
torch.onnx.export(model, "optimized.onnx")内存池管理:
torch.cuda.set_per_process_memory_fraction(0.8)自动扩展策略:
# AWS Auto Scaling 配置
resource "aws_autoscaling_policy" "deepseek" {
target_tracking_configuration {
predefined_metric_specification {
predefined_metric_type = "ASGAverageCPUUtilization"
}
target_value = 70.0
}
}瓶颈分析工具链:
-
GPU: Nsight Systems
-
CPU: perf + FlameGraph
-
内存: Valgrind Massif
九、进阶应用与生态集成
企业级扩展方案:
-
微调(Fine-tuning)
from transformers import TrainingArguments
args = TrainingArguments(
output_dir="finetuned",
per_device_train_batch_size=8,
gradient_accumulation_steps=4,
optim="adamw_torch_fused",
lr_scheduler_type="cosine",
logging_steps=100
)- 知识图谱融合
from py2neo import Graph
kg = Graph("bolt://localhost:7687")
def enrich_query(text):
entities = kg.run(f"MATCH (e) WHERE e.name CONTAINS '{text}' RETURN e")
return text + " " + " ".join(entities)- 多模态扩展
# 使用 CLIP 处理图像输入
image_features = clip_model.encode_image(uploaded_image)
text_features = model.encode_text("描述此图片")
similarity = cosine_similarity(image_features, text_features)行业解决方案:
-
金融:风控模型 + 财报分析
-
医疗:病历结构化 + 文献检索
-
教育:个性化学习路径规划
十、总结与未来展望
DeepSeek 部署技术栈全景图:
[基础设施]
├─ 本地:Ollama/Docker
├─ 云端:硅基流动/火山方舟
└─ 混合:Kubernetes 编排
[性能优化]
├─ 量化:8bit/4bit
├─ 编译:ONNX/TensorRT
└─ 缓存:Redis/Memcached
[安全合规]
├─ 传输:TLS 1.3
├─ 存储:AES-256
└─ 审计:日志溯源演进趋势预测:
-
模型小型化:1B 参数达到当前 7B 能力
-
硬件专用化:NPU 原生支持 DeepSeek 算子
-
部署自动化:一键生成优化部署方案
给开发者的建议:
-
从小规模开始(1.5B 模型验证)
-
建立完整的监控体系
-
定期评估模型与业务匹配度
通过本文的系统性梳理,相信您已经掌握了 DeepSeek 部署的核心理念和实战技巧。无论是个人开发者还是企业团队,都能找到适合自己的部署路径。随着 DeepSeek 生态的持续完善,我们期待看到更多创新应用落地生根。