CUDA入门笔记
总览
CUDA是NVIDIA公司对其GPU产品提供的一个编程模型,在2006年提出,近年随着深度学习的广泛应用,CUDA已成为针对加速深度学习算法的并行计算工具。
以下是维基百科的定义:一种专有的并行计算平台和应用程序编程接口(API),它允许软件使用某些类型的图形处理单元(gpu)来加速通用处理,这种方法称为gpu上的通用计算。
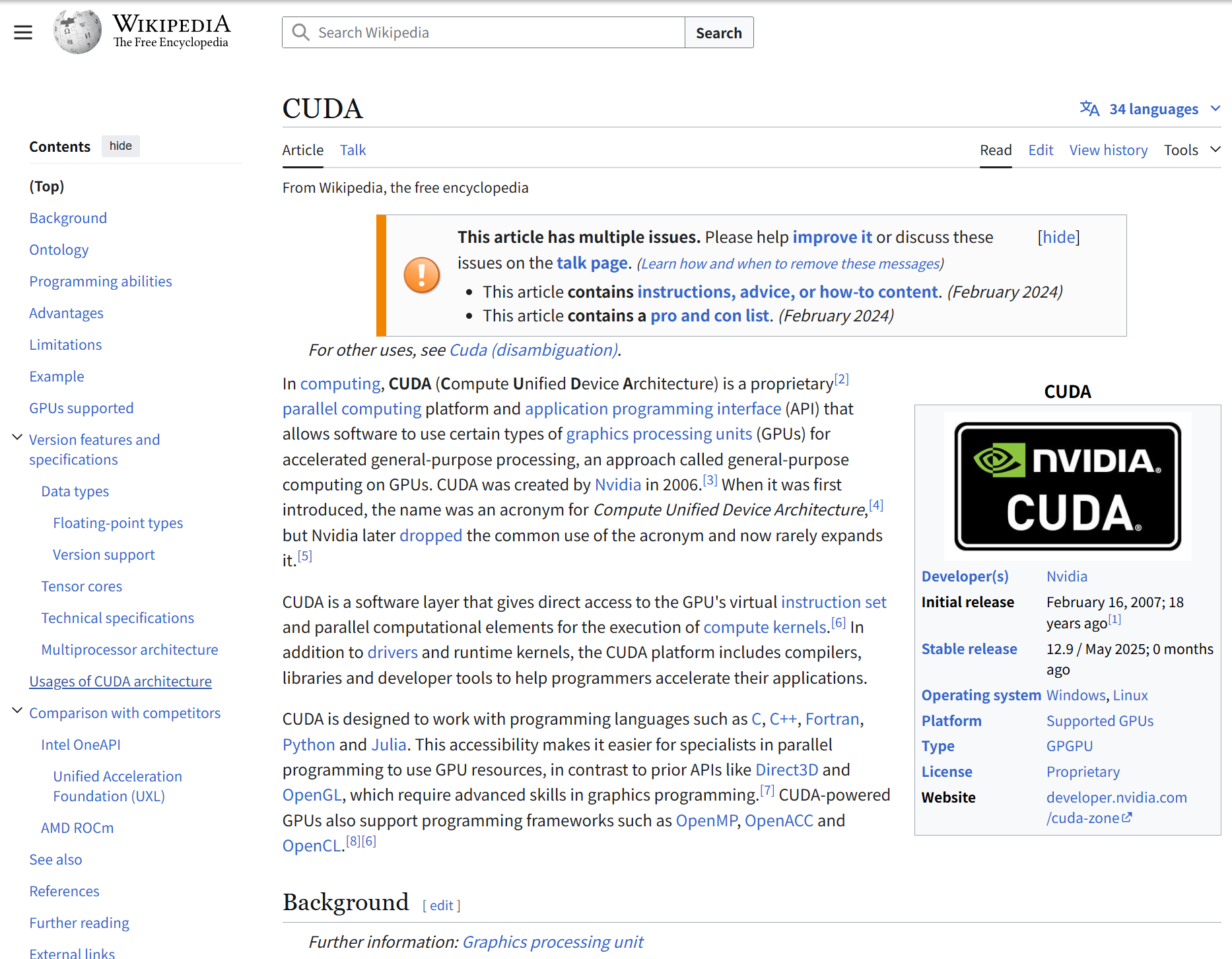
CPU+GPU的异构编程模型
现在的计算平台往往是一块CPU + 多块GPU共同搭建而成,CPU称为host端(主机端),GPU称为device端(设备端)
CPU和GPU之间通信需要通过PCIe总线(GPU之间通信通过PCIe或者是NVLink)
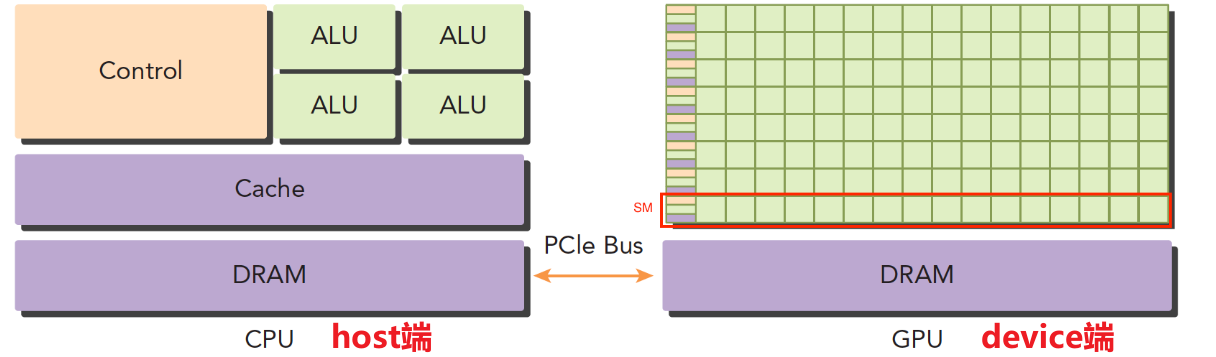
GPU在硬件设计上包含大量的计算单元(ALU),CPU包含相对较少的计算单元,这就天然的导致GPU适合计算密集型任务,CPU适合逻辑复杂型任务,可见,CPU与GPU适合不同的任务,特性上比较互补。
对于一个典型的CUDA程序,执行流程逻辑上可以分为:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存;
以下是一个简单的CUDA程序实例:
#include <cuda_runtime.h>
#include <iostream>
// 核函数:在GPU上运行,每个线程执行一次加法运算
__global__ void vectorAdd(const float *A, const float *B, float *C, int N) {
int i = blockIdx.x * blockDim.x + threadIdx.x; // 计算全局线程索引
if (i < N) {
C[i] = A[i] + B[i];
}
}
int main() {
// 定义向量长度
int N = 1024;
size_t size = N * sizeof(float);
// 在host(CPU)上分配内存
float *h_A = (float *)malloc(size);
float *h_B = (float *)malloc(size);
float *h_C = (float *)malloc(size);
// 初始化host端数据
for (int i = 0; i < N; ++i) {
h_A[i] = i;
h_B[i] = i * 2;
}
// 在device(GPU)上分配内存
float *d_A, *d_B, *d_C;
cudaMalloc((void **)&d_A, size);
cudaMalloc((void **)&d_B, size);
cudaMalloc((void **)&d_C, size);
// 将数据从host复制到device
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// 定义线程块和线程网格的大小
int threadsPerBlock = 256;
int blocksPerGrid = (N + threadsPerBlock - 1) / threadsPerBlock;
// 调用核函数(在GPU上执行)
vectorAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// 将结果从device复制回host
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// 简单验证结果
for (int i = 0; i < 10; ++i) {
std::cout << "C[" << i << "] = " << h_C[i] << std::endl;
}
// 释放device内存
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// 释放host内存
free(h_A);
free(h_B);
free(h_C);
return 0;
}
程序中vectorAdd函数(这个函数也可以叫算子,kernel)使用__global__符号声明,这个符号是用来区分host端和device端代码的,CUDA编程中常见的三种标识符号是:
_global_: 说明该函数(kernel)在device上执行,在host端调用;
_device_:说明该函数在device上执行,在device端调用;
_host_:在host端执行和调用,一般省略不写;
CUDA编程核心概念
CUDA 编程中,kernel 是在 GPU 上执行的函数,每个 kernel 通常会启动成千上万个线程来并行执行任务。
在 GPU 中,一个算子由多个线程组成,这些线程会被组织成一个网格(grid),网格由多个线程块(block) 组成,而每个线程块又包含多个线程(thread)。整个结构如下:
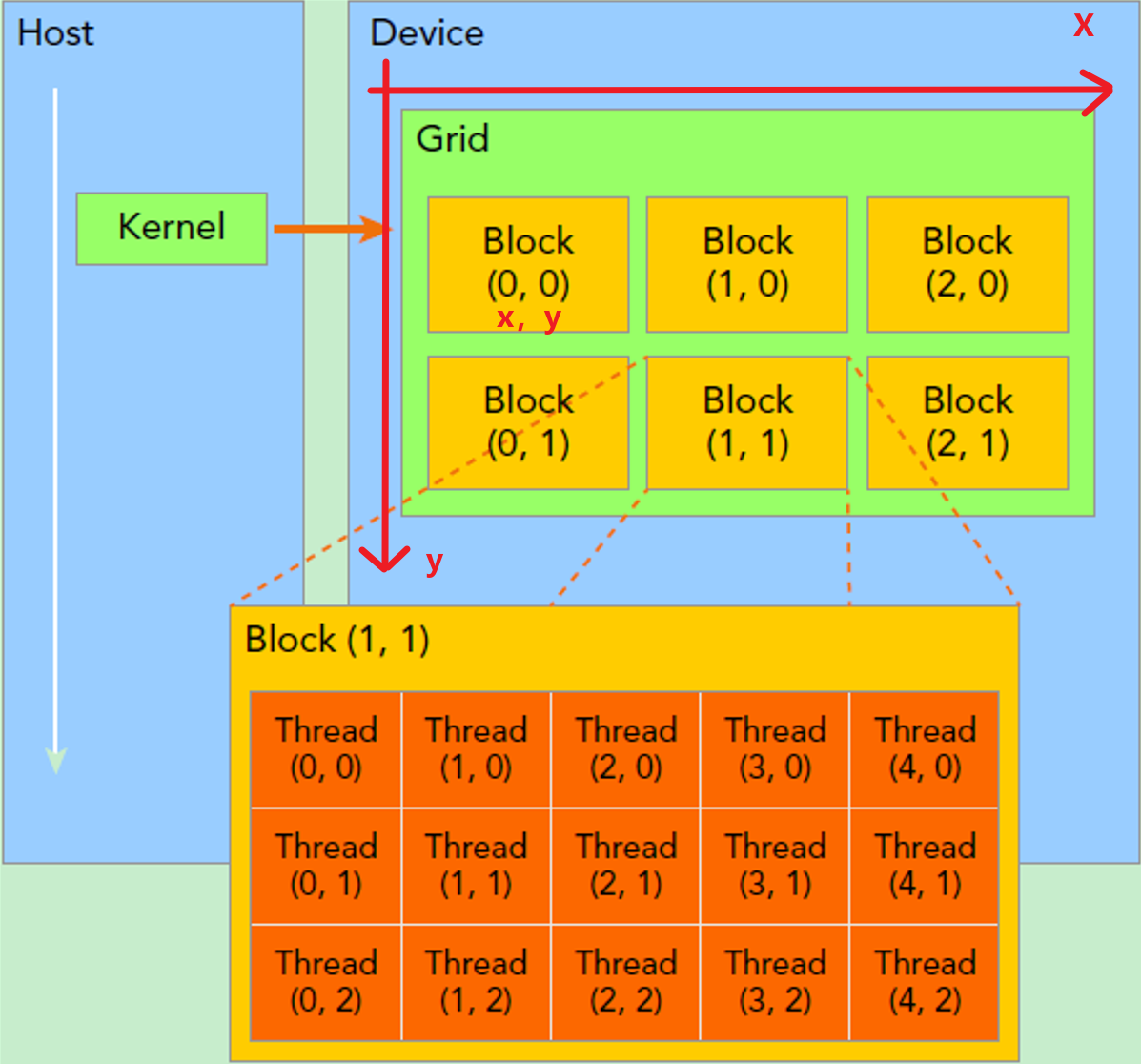
注:网格和线程块只是逻辑划分,在物理层并没有这些概念
我们来看一下GPU A100的硬件架构图:
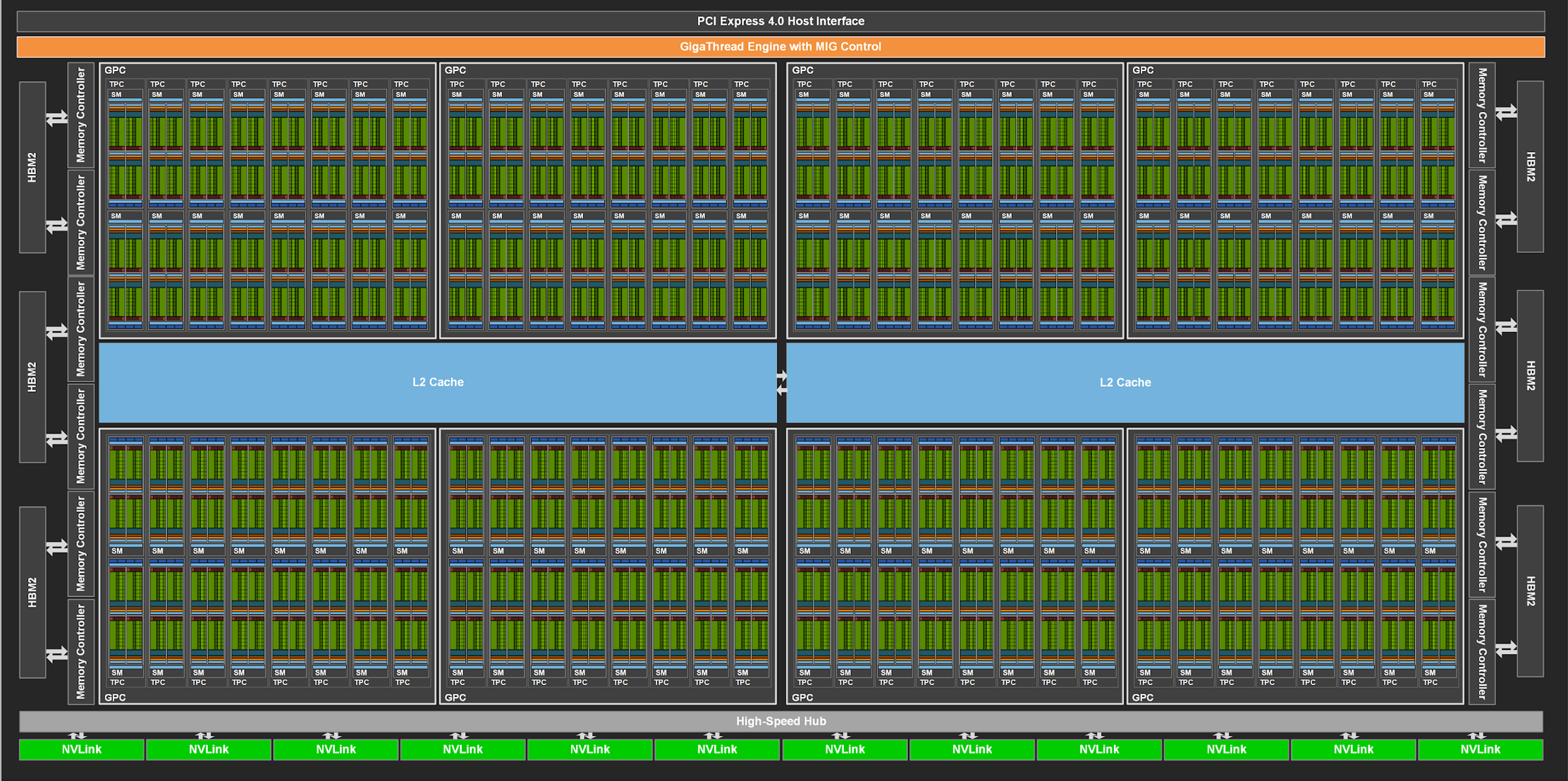
可见A100由108个SM(Streaming Multiprocessor,流式多处理器)构成,SM结构如下:
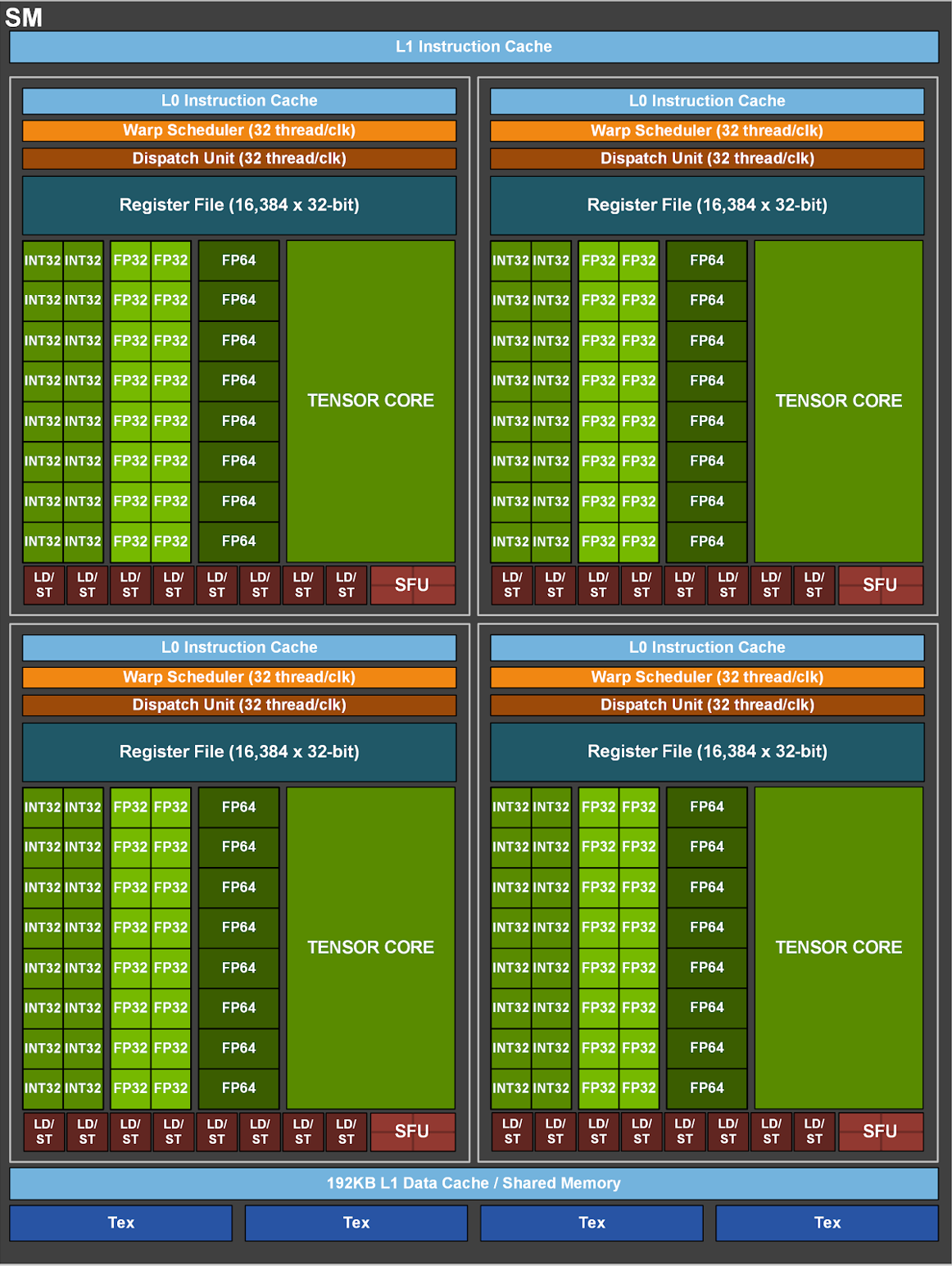
这里面各个部件可以自行百度学习一下,CUDA编程需要对硬件实现有一个基本的认识。
在逻辑层面上,每个线程有自己的私有本地内存(Local Memory),而每个线程块有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。此外,所有的线程都可以访问全局内存(Global Memory),如下图:
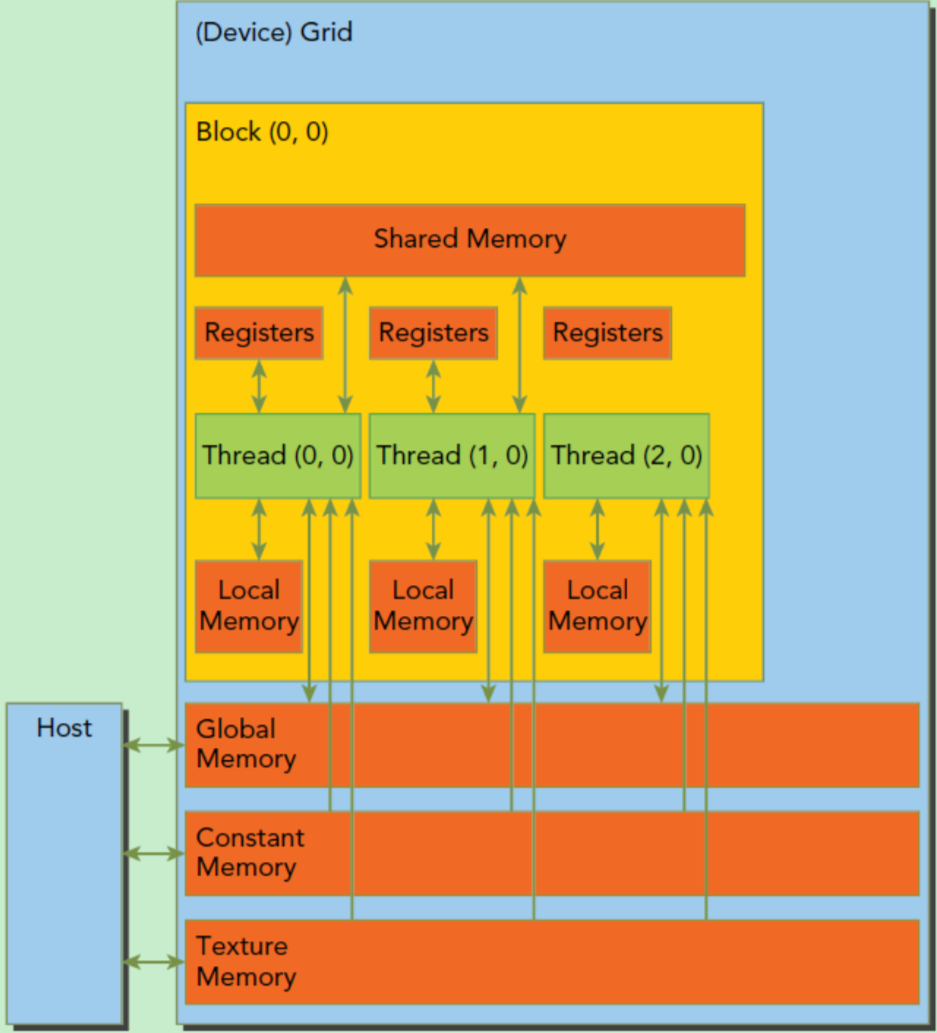
一个算子的执行会启动多个线程,这些线程逻辑上并行执行,但是物理层并不一定并行,当一个算子执行时,它的gird中的一个block会被分配到具体的一个SM上(一个block只能分配到一个SM,但一个SM可以执行调度多个block),SM采用SIMT (Single-Instruction, Multiple-Thread,单指令多线程)架构,基本的执行单元是线程束(warps),线程束包含32个线程,这些线程同时执行相同的指令。当线程块被划分到某个SM上时,它将进一步划分为多个线程束,因为这才是SM的基本执行单元,但是一个SM同时并发的线程束数是有限的。
一个SM能支持多少线程块和并发线程束呢?
取决于SM的资源:SM要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器。
总结:
- 网格和线程块只是逻辑划分,一个kernel的所有线程其实在物理层是不一定同时并发的。
- kernel的grid和block的配置不同,性能会出现差异
- 网格grid中的一个线程块block会被具体的分配到一个SM中
- SM中的基本执行单元是warp线程束,线程束包含32个线程,采用SIMT架构
- 线程块block分配到SM上后,可能会被划分多个warps,然后并行执行,所以block大小一般要设置为32的倍数
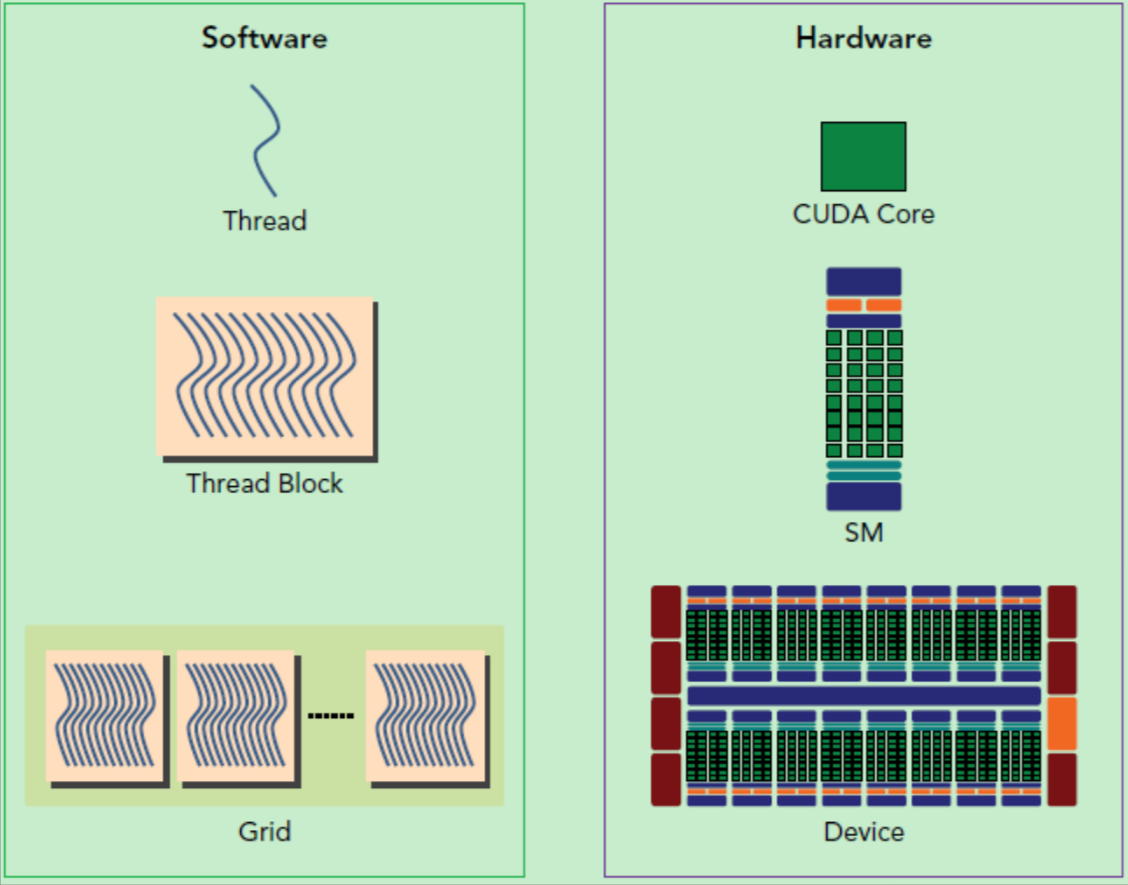
CUDA编程的逻辑层(左,软件层)和物理层(硬件层):
参考
知乎小小将:CUDA编程入门极简教程
Github:LeetCUDA