Fast Text-to-Audio Generation with Adversarial Post-Training 论文解析
一、引言与背景
-
文本到音频系统的局限性:当前文本到音频生成系统性能虽佳,但推理速度慢(需数秒至数分钟),限制了其在创意领域的应用。
-
研究目标:加速高斯流模型(扩散模型或修正流模型),避免传统蒸馏方法的缺陷。
-
现有加速方法的不足:
-
蒸馏方法需大量资源(在线方法需同时存储多个模型,离线方法需预生成轨迹-输出对),且可能继承教师模型的低多样性和过饱和伪影。
-
非蒸馏的对抗式后训练方法在图像领域有一定探索,但在音频领域尚未有成熟方案。
-
二、ARC 方法论
(一)修正流预训练
-
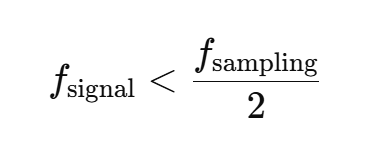
目标:学习在文本条件 c 下,将数据分布 p0 和先验分布 p1(如各向同性高斯噪声)之间的转换模型,以从 p1 生成 p0 样本。
-
前向腐蚀过程:通过添加噪声将数据转化为噪声表示(公式 1)。
-
逆向生成过程:解常微分方程(ODE,公式 2),预测流的瞬时速度(公式 3)进行训练。
(二)对抗相对论-对比后训练(ARC)
-
核心思想:用对抗损失替代基于 l2 的条件均值损失,利用判别器提供分布级反馈,减少所需采样步骤。
-
优势:避免蒸馏方法的高成本,无需生成和存储轨迹-输出对,也无需依赖预训练教师模型性能。
-
联合优化目标(公式 4):结合对抗相对论损失(LR)和对比损失(LC)。
(三)对抗相对论损失(LR)
-
训练流程(图 1):
-
对真实样本 x0 添加噪声得 xt,经生成器得生成样本 ˆx0。
-
再对 ˆx0 和 x0 添加噪声,输入判别器。
-
计算真实样本和生成样本在判别器空间的相对差异(公式 5 至 7)。
-
-
关键特性:与标准 GAN 不同,LR 基于成对数据计算,生成器使生成样本在判别器空间相对真实样本更真实,判别器则相反。因文本条件任务中成对样本共享相同文本提示,提供更强梯度信号。
(四)对比损失(LC)
-
提出背景:对抗损失单独使用会导致文本遵循性变差。
-
实现方式(图 2):将判别器训练为音频-文本对比模型,最大化正确和错误提示对应真实样本在判别器空间的差异(公式 8)。
-
作用:使判别器关注语义特征,提升提示遵循性,且无需使用 Classifier-Free Guidance(CFG),避免其对多样性和输出过饱和的负面影响。
(五)乒乓采样
-
适用场景:ARC 后训练模型直接估计不同噪声水平下的干净输出,而非预测瞬时速度。
-
工作原理:交替进行去噪和重新加噪,逐步优化样本质量。从初始噪声样本开始,反复去噪和加噪,最终逼近干净数据。
(六)加速作为奖励建模
- 与语言模型偏好后训练的联系:ARC 的相对论目标类似于语言模型基于人类偏好对赢得-输掉样本对训练偏好模型。判别器隐式作为奖励模型,生成器则最大化相对奖励。
三、实验与评估
(一)模型架构
-
生成模型:基于 Stable Audio Open(SAO),包含预训练自动编码器、T5 文本嵌入器和在潜在空间操作的扩散 Transformer(DiT)。对 DiT 进行改进以提升效率。
-
判别器:基于预训练修正流初始化,包含输入嵌入层、部分 DiT 块和轻量级判别器头部。
(二)训练与采样细节
-
数据集:使用 Freesound 样本(6,330 小时,472,618 音频),排除长形式 FMA 音乐。
-
训练迭代:修正流模型训练 670k 迭代,每个加速算法在 8 个 H100 GPU 上微调 100k 迭代,批次大小 256,学习率 5×10−7。
-
噪声分布:pgen(t) 为从 -6 到 2 的对数信噪比空间中的均匀分布;pdisc(s) 为移位对数正态分布,侧重中高信噪比区域。
(三)客观评估指标
-
音频质量与语义对齐:采用 FDopenl3、KLpasst 和 CLAP 分数指标。
-
多样性评估:
-
现有指标:报告 recall 和 coverage 指标(Rpasst 和 Cpasst),衡量 PASST 空间中的分布多样性。
-
新提出指标:CLAP 条件多样性分数(CCDS),计算相同提示生成样本对的 CLAP 余弦距离平均值,距离低表示多样性低,反之则高。
-
-
速度评估:报告实时因子(RTF,生成音频时长除以延迟)和 H100 上的 VRAM 峰值使用量。
(四)主观评估
-
评估方式:使用 webMUSHRA 进行听力测试,参与者对多样性、音频质量和提示遵循性进行 5 分制评分。
-
评估重点:关注与音乐制作相关的提示(如 “拉丁放克鼓组 115 BPM”)和空间复杂场景(如 “跑车经过”),以及更广泛、更模糊的提示(如 “燃烧的火焰” 和 “水”)以评估多样性。
(五)基线模型
-
Stable Audio Open(SAO):质量基线和加速参考点,模型较大且未针对速度优化。
-
预训练修正流(RF):基础加速模型。
-
Presto:基于蒸馏的音频扩散加速方法,使用基模型和辅助分数模型最小化逆向 KL 损失并结合 GAN 损失。
-
消融实验:对 ARC 进行消融,分别省略 LC 或用标准最小二乘对抗损失(LLS)替换 LR。
(六)结果与讨论
-
性能对比:SAO 虽质量最佳但速度慢;加速模型(ARC、Presto 等)速度提升显著(比 SAO 快 100 倍,比预训练 RF 快 10 倍),指标表现相近。
-
Presto 的权衡:提升基 RF 模型质量,但严重损害多样性且恶化 FDopenl3。
-
ARC 的表现:进一步提升生成多样性,FDopenl3 表现最佳,但 MOS 质量评分略低于预训练 RF。其输出多样性更高,但提示遵循性稍低。
-
消融实验结果:
-
仅用 LR 训练导致提示遵循性差,此时多样性高因生成器变成无条件模型。
-
相对论损失在对抗加对比后训练中优于最小二乘损失。
-
模型在 8 步时表现最佳,与小加速模型可能比大模型需要更多步数的发现一致。
-
-
CCDS 指标有效性:CCDS 与听力测试多样性结果完全一致,表明其可用于自动评估多样性。
(七)边缘设备优化
-
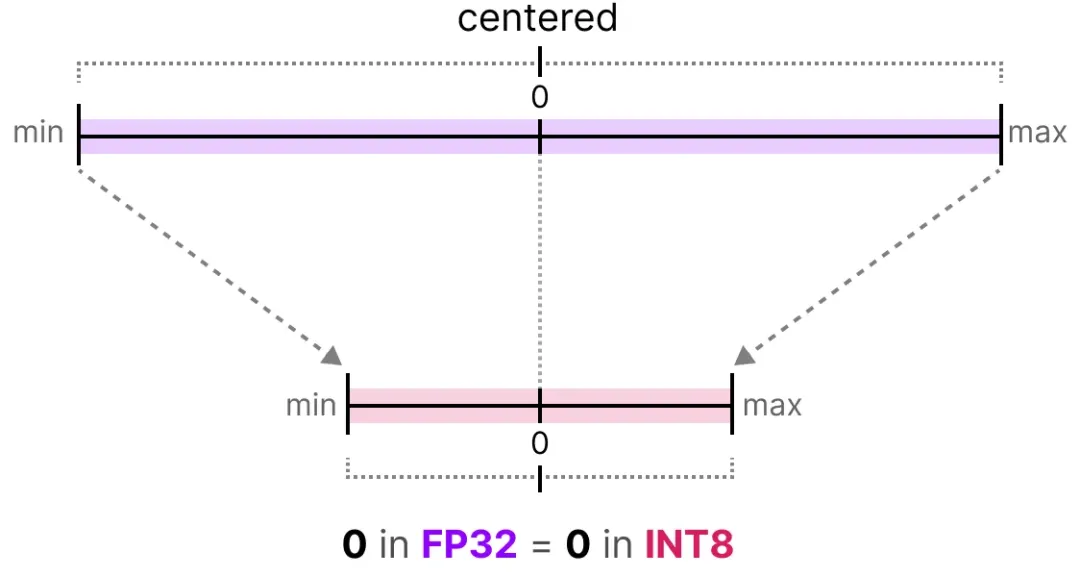
优化手段:使用 Arm 的 KleidiAI 库(通过 XNNPACK 库集成到 LiteRT 运行时),对 Vivo X200 pro 手机进行动态 Int8 量化,仅对部分层进行量化,运行时动态量化激活。
-
优化效果:推理时间从 15.3 秒(原始 F32)降至 6.6 秒,峰值运行时 RAM 使用量从 6.5GB 降至 3.6GB。高端(H100)和消费级(3090)GPU 分别实现 75ms 和 187ms 的速度。
(八)创意应用
-
响应速度要求:为在创意工作流中作为“乐器”,文本到音频模型需响应迅速。降低消费级 GPU 延迟至 200ms 以下,提升音效设计灵感。
-
音频到音频能力:利用乒乓采样实现风格迁移,无需额外训练。可通过语音录音初始化初始噪声样本实现语音到音频控制,或用强节奏录音初始化进行节拍对齐生成。
-
局限性:模型内存和存储需求高(占数 GB RAM 和磁盘空间),对集成到多应用和高效分发构成挑战。
四、结论
-
ARC 的创新性:首个不依赖蒸馏或 CFG 的文本到音频模型加速方法,通过扩展对抗相对论损失并结合新颖对比判别器损失,大幅提升高斯流模型运行速度,同时保持质量并提升生成多样性。
-
评估指标贡献:提出的 CCDS 多样性评估指标与感知评估一致,为自动评估多样性提供合理工具。
-
未来展望:期望更高效和多样性的文本到音频模型能支持更广泛的创意应用。认识到此类模型的创意潜力,论文还探索音频到音频实验,并建议未来工作可聚焦于用针对性数据集微调以实现更精确的声音设计。
五、核心技术汇总表格