单链表(续)
- 查找
- 在指定位置之前插入结点
- 在指定位置之后插入结点
- 删除pos位置的结点
- 删除pos位置之后的结点
- 销毁
查找
遍历:pcur指向头结点,循环,当pucr不为空进入循环,pucr里面指向的数据为要查找的值的时候就返回pcur否则将pucr下一个结点的地址赋值给pcur然后继续判断,直到找到值。如果为空直接返回。
函数的实现
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x)
{
SLTNode* pcur = phead;
while (pcur)
{
if (pcur->data == x)
{
return pcur;
}
pcur = pcur->next;
}
return NULL;
}
函数的测试运行
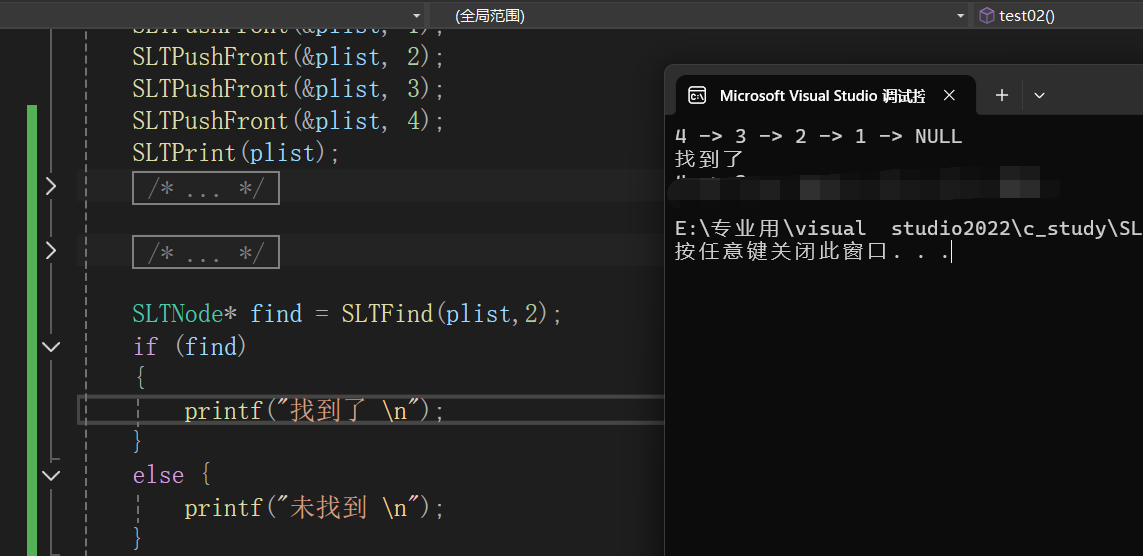
SLTNode* find = SLTFind(plist,2);
if (find)
{
printf("找到了 \n");
}
else {
printf("未找到 \n");
}
在指定位置之前插入结点
时间复杂度:O(N)
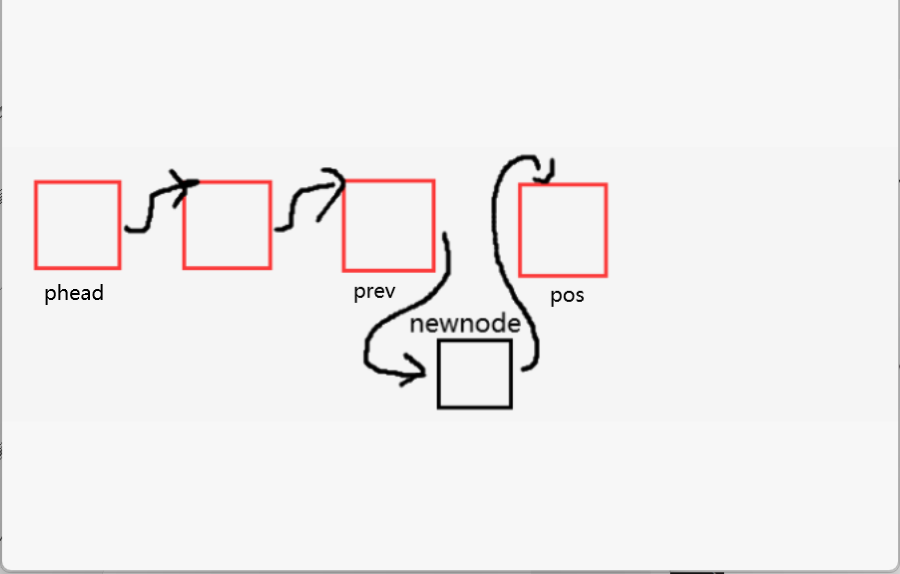
:头文件不能为空,也不能在空之前插入结点,首先要找到pos位置的前一个结点让它的next指针指向newnode,然后让newnode的next指针指向pos。如何找到pos的前一个结点?那就是遍历,从头结点开始,向后遍历,直到prev的next指针指向pos则就是pos的前一个结点。这里要注意,当pos为头结点的时候,执行的操作就变为了头插。
复习一下新结点的创建
SLTNode* SLTbuyNode(SLTDataType x)
{
//根据x创建新结点
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)
{
perror("malloc fail!");
exit(1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
复习一下头插
void SLTPushFront(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
SLTNode* newnode = SLTbuyNode(x);
//链表为空和不为空一样
newnode->next = *pphead;
*pphead = newnode;
}
函数的实现
//在指定位置之前插入结点
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
assert(pphead && pos);//头结点不能为空,也不能在空之前插入结点
//当pos为第一个结点的时候,实现的就是头插
if (pos == *pphead)
{
SLTPushFront(pphead, x);
}
else {
// 实现代码
SLTNode* newnode = SLTbuyNode(x);
//找pos前一个结点
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = newnode;
newnode->next = pos;
}
}
函数的测试和运行
SLTNode* find = SLTFind(plist,9);
SLTInsert(&plist, find, 100);
SLTPrint(plist);
}
在指定位置之后插入结点
时间复杂度:O(1)
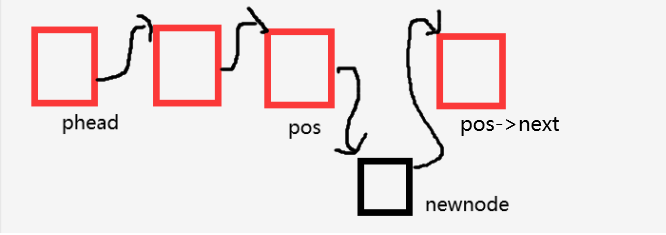
1.newnode->next = pos->next pos->next = newnode
2. pos->next = newnode newnode->next = pos->next
两种方案是否都可行?答案是否定的。
看第二种方案,当pos->next = newnode后,newnode->next = pos->next就变成了newnode->next = newnode,所以只能用第一种方案。
函数的实现
//在指定的=位置之后插入数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x)
{
assert(pos);
SLTNode* newnode = SLTbuyNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
因为仅仅根据pos就能够找到下一个结点,不需要遍历,所以只用传两个数据就可,而且当pos为尾结点时插入数据,这个代码也没问题,不需要像pos在头结点前插入时一样重新调用一下头插函数。
函数的测试和运行
void test02()
{
//创建空链表
SLTNode* plist = NULL;
//SLTPrint(plist);
//SLTPushBack(&plist, 1); //plist是指向结点地址的指针,&plist则是指向结点地址指针的地址
SLTPushFront(&plist, 1);
SLTPushFront(&plist, 2);
SLTPushFront(&plist, 3);
SLTPushFront(&plist, 4);
SLTPrint(plist);
SLTNode* find = SLTFind(plist,1);
SLTInsertAfter(find, 100);
SLTPrint(plist);
}
删除pos位置的结点
时间复杂度:O(N)
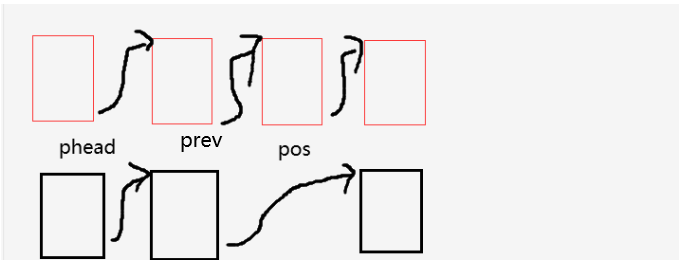
这里还是通过遍历找到prev就是pos的前一个结点,然后让prev->next = pos->next,然后释放掉需要删除的那个结点
当pos为头结点的时候,通过遍历prev->next 并不能找不到pos,所以此时需要进行头删操作的引用
函数的实现
//删除pos结点
void SLTErase(SLTNode** pphead, SLTNode* pos)
{
assert(pphead && pos);
//pos为头结点的时候
if (pos == *pphead)
{
//执行头删操作
SLTPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;
}
}
复习一下头删
void SLTPopFront(SLTNode** pphead)
{
assert(pphead && *pphead);
SLTNode* next = (*pphead)->next; //头结点的下一个结点存下来,然后将头结点删掉
free(*pphead);
*pphead = next;
}
函数的测试和运行
void test02()
{
//创建空链表
SLTNode* plist = NULL;
//SLTPrint(plist);
//SLTPushBack(&plist, 1); //plist是指向结点地址的指针,&plist则是指向结点地址指针的地址
SLTPushFront(&plist, 1);
SLTPushFront(&plist, 2);
SLTPushFront(&plist, 3);
SLTPushFront(&plist, 4);
SLTPrint(plist);
SLTNode* find = SLTFind(plist,1);
SLTErase(&plist, find);
SLTPrint(plist);
}
删除pos位置之后的结点
时间复杂度:O(1)
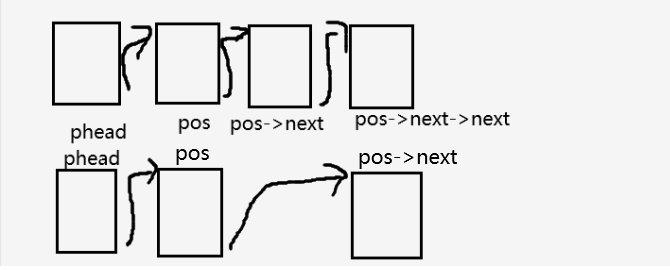
三个结点都能够通过pos来找到,所以只需要一个参数,将pos->next改为pos->next->next,然后将pos->next这个结点释放掉。
思考:此时已经将pos的next指针修改了,已经指向“新结点”了,如图,该怎么释放掉需要删除的那个结点?
答案:定义一个del保存pos->next
但是当pos为尾结点的时候,pos->next为NULL,所以del->next是对空指针解引用就会报错,所以在assert里面再加入一个条件assert(pos && pos->next)
函数的实现
//删除pos之后结点
void SLTEraseAfter(SLTNode** pphead, SLTNode* pos)
{
assert(pos && pos->next);
SLTNode* del = pos->next;
pos->next = del->next;//pos->next = pos->next->next
free(del);
del = NULL;
}
函数的测试和运行
void test02()
{
//创建空链表
SLTNode* plist = NULL;
//SLTPrint(plist);
//SLTPushBack(&plist, 1); //plist是指向结点地址的指针,&plist则是指向结点地址指针的地址
SLTPushFront(&plist, 1);
SLTPushFront(&plist, 2);
SLTPushFront(&plist, 3);
SLTPushFront(&plist, 4);
SLTPrint(plist);
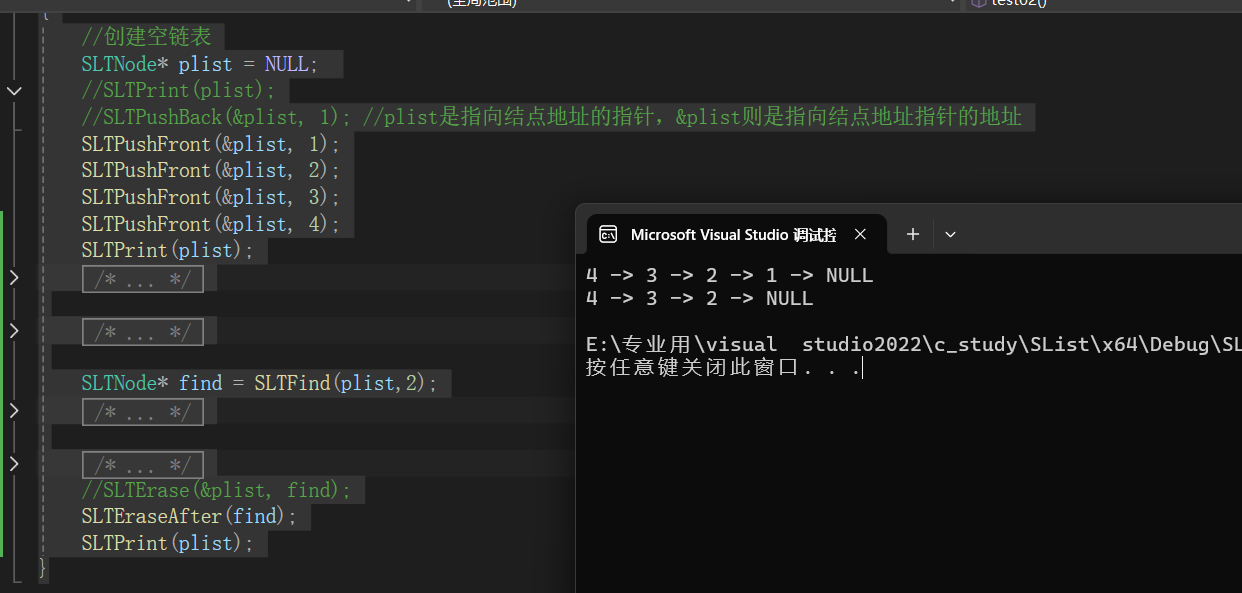
SLTNode* find = SLTFind(plist,2);
SLTEraseAfter(find);
SLTPrint(plist);
}
销毁
链表每个结点都是独立申请的,所以每个结点都需要一个一个的释放(free)掉,当我们从头结点先释放掉,我们先需要将下一个结点存起来,然后将头结点走到存着的这个结点,循环此操作直到free掉所有结点(走到为空)
函数的实现
//销毁链表
void SListDestroy(SLTNode** pphead)
{
SLTNode* pcur = *pphead; //pcur从头结点开始走
while (pcur)//不为空
{
SLTNode* next = pcur->next; //定义next储存pcur的下一个节点
free(pcur);
pcur = next;
}
*pphead = NULL; //手动置空,避免成为野指针
}
顺序表问题与思考:
中间/头部的插入删除,时间复杂度为O(N) 链表头部插入删除O(1)
增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。 链表无需增容
增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到200空间再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。
链表不存在空间的浪费